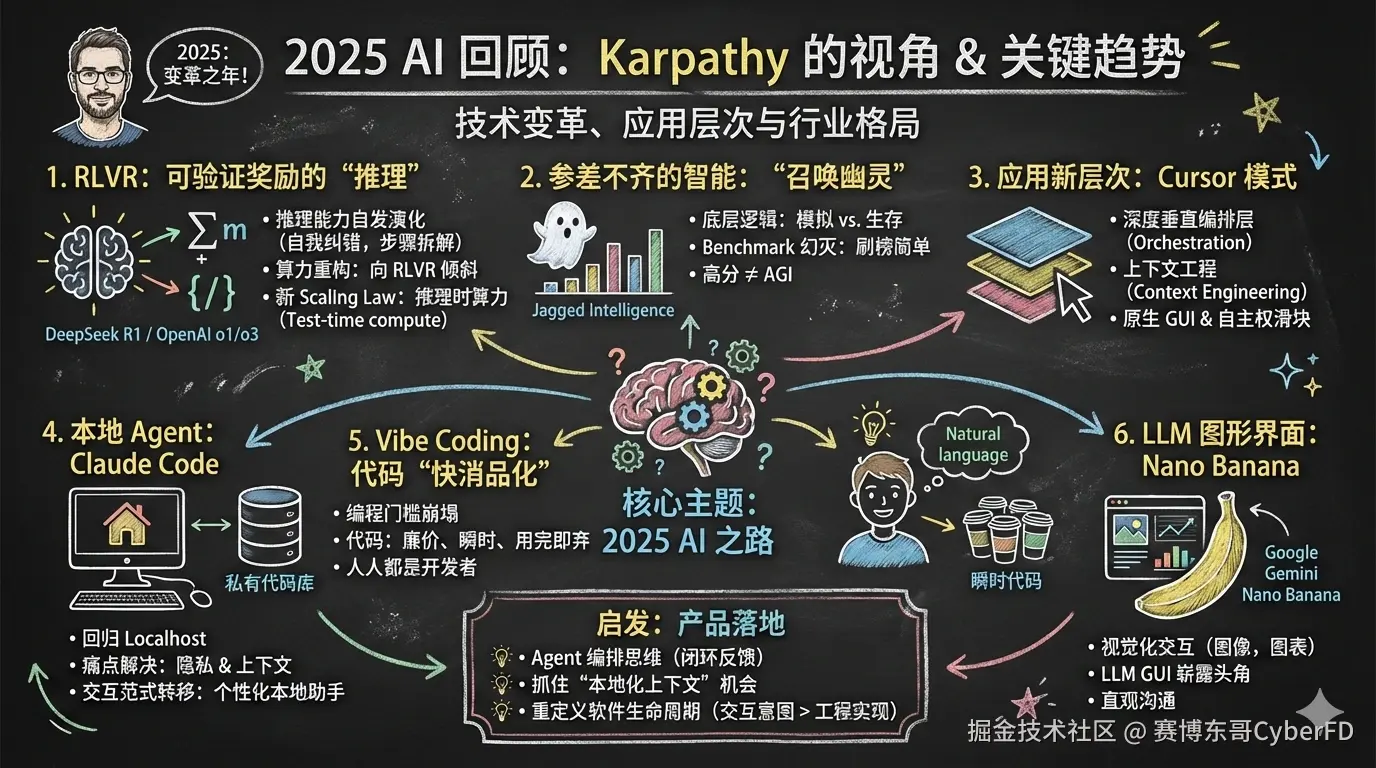
2025 年,无疑是大型语言模型(LLMs)领域的一年,技术进展迅速且充满变革。从训练方法的创新到全新应用层次的诞生,行业格局发生了深刻的变化。AI 领域第一 KOL Andrej Karpathy 发表自己针对 2025 年 AI 发展的回顾
我将从我个人角度,分析文章中提到的关键技术、趋势和实际应用,跟着一起回顾一下 2025 年的 AI 之路
1. RLVR:可验证奖励下的"推理时刻"
在 2025 年初,大模型的标准生产线还是"预训练(Pretraining)+ 指令微调(SFT)+ 人类反馈强化学习(RLHF)"。这套流程虽然稳定,但潜力已近触顶。
今年,RLVR(基于可验证奖励的强化学习) 正式入场,成为大模型训练的新标配。通过在数学、代码等具备"客观真理标准"的环境中进行强化学习,模型自发演化出了类似人类的"推理"能力。它们学会了自我纠错、步骤拆解以及多路径尝试。
核心变化:
- DeepSeek R1 与 OpenAI o1/o3 证明了这一点:推理不再是单纯的文本模仿,而是优化目标驱动下的策略发现。
- 算力分配重构:过去算力主要堆在预训练阶段,现在大量算力向 RLVR 倾斜。业内发现,在可验证领域,RL 的投入产出比(Capability/$)极高。
- 新 Scaling Law :我们拥有了一个控制模型能力的新旋钮------推理时算力(Test-time compute) 。通过增加模型的"思考时间",性能可以实现非线性增长。
2. "召唤幽灵"而非"驯化动物":参差不齐的智能
2025 年,我们终于看清了 AI 智能的底色:我们不是在"养育动物",而是在"召唤幽灵"。
人类大脑的进化是为了在丛林中生存,而 LLM 的神经元是为了模拟人类文本、解决数学谜题、在 LM Arena 中博取人类的好感。这种完全不同的底层逻辑,导致了 "锯齿状智能"(Jagged Intelligence) 的出现:模型可能在量子物理领域是天才,但在处理简单的逻辑陷阱或防御越狱攻击时,却像个心智不全的小学生。
关于 Benchmark 的幻灭: 由于 RLVR 的普及,刷榜(Benchmaxxing)变得空前简单。只要环境可验证,模型就能通过 RL 快速覆盖这些知识盲点。
现在的共识是:高分不代表 AGI。一些实验室正在通过制造大量合成数据来"修剪"这些智能锯齿,试图让模型在某些特定领域呈现出超越常人的统治力。
3. Cursor 与 LLM 应用的新层次
Cursor 的爆发揭示了一个残酷但清晰的现实:纯包装(Wrapper)没有未来,但深度垂直的编排层(Orchestration Layer) 大有可为。
现在的开发者不再只是谈论"接入 API",而是讨论"做一个 X 行业的 Cursor"。这类应用的核心竞争力在于:
- 上下文工程(Context Engineering) :如何更精准地喂入数据。
- 复杂任务编排:将 LLM 调用串联成复杂的 DAG(有向无环图),在性能与成本间走钢丝。
- 原生 GUI 与交互:不再仅仅是对话框,而是为特定场景定制的操作界面。
- 自主权滑块(Autonomy Slider) :让用户在"辅助执行"与"全自动代理"之间自由切换。
从产品视角来看,大模型厂商负责交付"通才大学生",而垂直 App 负责将这些大学生组织成专业的、可交付业务价值的"专业团队"。
4. Claude Code:回归 Localhost 的 Agent
Claude Code(CC)的出现,给"什么才是真正的 Agent"打了个样。与 OpenAI 执着于云端容器(Cloud-based)的思路不同,CC 选择运行在用户的本地环境(Localhost) 。
这种"接地气"的做法解决了两个痛点:隐私与上下文。
Agent 可以直接读取你的私有代码库、调用本地编译器、感受你的开发环境。
它不再是浏览器里一个冰冷的网页,而是一个"住"在你电脑里的数字精灵,与你并肩作战。这标志着 AI 交互范式的转移:从"去中心化的云服务"回归到"个性化的本地助手"。
5. Vibe Coding:代码的"快消品化"
2025 年,"Vibe Coding"(氛围感编程)从一个推特热梗变成了现实。 当 AI 的生成能力跨过临界点,编程的门槛崩塌了。你不需要精通 Rust 或 C++,只要逻辑清晰,通过自然语言就能指挥 AI 编织出复杂的程序。
这带来了软件生产逻辑的巨变:
- 代码不再"昂贵" :过去写一个工具需要权衡 ROI,现在代码是廉价的、瞬时的、用完即弃的。
- 人人都是开发者:这种技术扩散让普通人的获益远超专业人士,它打破了技能壁垒。
- 软件地貌重塑:我们会看到大量"一次性软件"或"极度个性化软件"的诞生。
6. Nano Banana 与 LLM 的图形界面
2025 年,Google Gemini Nano Banana 的推出展示了 LLM 的另一个革命性进展。
在过去的计算机发展历程中,图形用户界面(GUI)为计算机操作提供了直观和高效的交互方式。同样,
LLM 的图形界面(GUI)也开始崭露头角,呈现出多种形式的互动方式,如图像生成、信息图表、幻灯片和视频等。这种图形化的交互模式,让用户能够更加自然地与 LLM 进行互动。
Nano Banana 的出现只是这一趋势的开始,它通过图像生成、文本生成和知识整合的结合,预示了未来 LLM 图形界面可能的多样性。
最终,LLM 可能不再仅仅是通过文本输入来进行交互,而是通过更加直观和视觉化的方式与用户沟通。
总结
2025 年对于 LLM 领域来说,是充满变革的一年。从 RLVR 的引入到 Vibe Coding 的普及,从本地 AI Agent 到 LLM 应用的层次化发展,技术的每一次突破都为未来的人工智能发展奠定了更深的基础。虽然 LLM 的能力已经取得了显著进展,但从技术的深度和实际应用的广度来看,LLM 领域仍然有着巨大的发展空间。在未来,我们不仅可以期待技术进步的加速,还将见证 AI 与我们的生活、工作方式更加紧密地融合。
最后,谈谈对 AI 产品落地的启发
- 从"对话框"思维转向"Agent 编排"思维:不要再执着于如何调优 Prompt 让模型回答得更好,而要思考如何构建一套闭环的反馈环境(Verifiable Environment),利用 RL 的思路让模型在特定业务场景下进行"自我进化",不一定是技术上闭环,也可以是业务上的闭环,只要能持续推动 Agent 应用迭代进步。
- 抓住"本地化上下文"的机会:Claude Code 的成功提醒我们,真正的杀手级 Agent 可能不需要跑在云端,而是需要深度嵌入用户的工作流和本地数据。私域数据和本地环境的操作权,是对抗大模型厂商"收割"的护城河。
- 重新定义软件的生命周期 :如果代码已经变成"瞬时且免费"的资源,我们的重心应从"如何交付稳定的功能"转向"如何提供更精准的交互意图理解"。在 Vibe Coding 时代,审美、逻辑抽象能力和对用户痛点的洞察,比工程实现能力更重要。