💡 糟糕,k8s informer我好像拉一坨大的
近段时间在做云原生AI算力平台,之前提到使用k8s informer机制管控多渠道提交的训练任务。
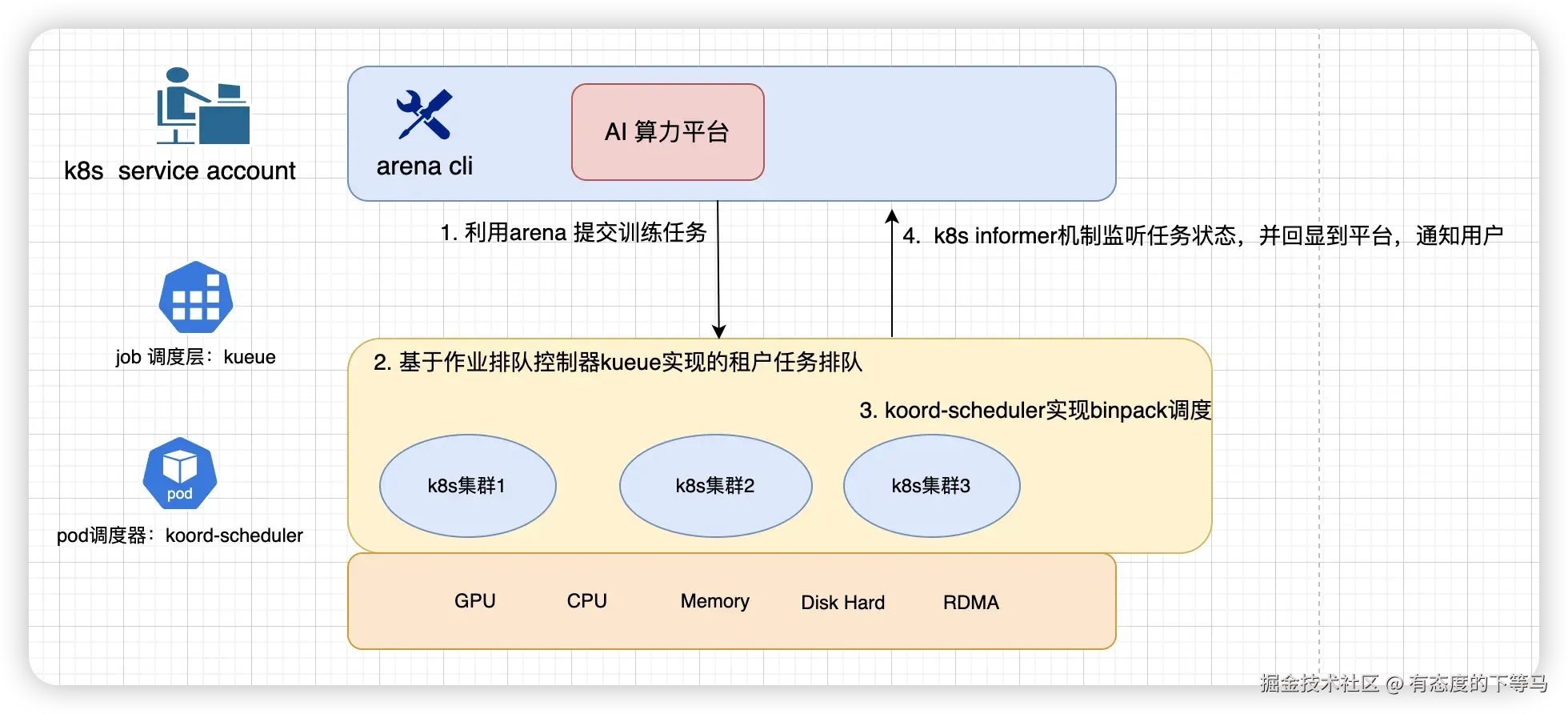
上面第4点:
informer会监听通过cli和网页portal提交的job, 回显到portal平台,并在job发生状态变更时通知用户。
1. informer是实现声明式controller设计的核心
k8s采用声明式设计, 以结果为导向, 实现这一关键能力的组件是k8s各种controller:
定义某对象的期望状态,实时监控并达成这个状态(调谐Reconcile) 就是控制器做的事情, No signal was sent. No webhook fired。
informer是k8s client-go库的一部分:
- ① 监听资源
- ②并本地缓存
- ③通知上层应用发生了一些事件(job创建、job pending、job运行、job完成/失败)
减少了apiserver的调用流量、优化性能、反应式自动化运维 (我当前的需求有点类似于反应式自动化运维😄)。
2. informer核心使用流程
运行一个完整的informer: list ---> watch ---> cache---> react。
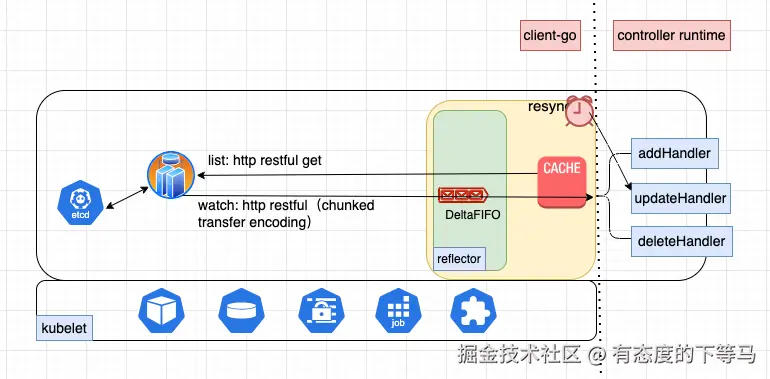
① 从apiserver拉取指定的gvr资源, 形成首次资源快照
② 持续监听资源的变更事件进deltaFIFO队列,这里是通过HTTP/1.1 的Chunked Transfer Encoding(分块传输编码)来实现的
③ 通过上述①②两步得到资源的最新状态并缓存,注意,缓存的是资源对象,而不是资源变更事件, 另外是线程安全的存储。
④ 事件处理,应用在业务层面的动作,可以写日志,可以做controller的Reconcile动作。
开发者主要考量在react(EventHandler)阶段,其余能力client-go sdk会提供。
apiserver-->reflector(拉取/监听)-->DeltaFiFO(队列)--> Process(处理)-->Handler(用户代码)
2.1 Watch机制: chunked transfer encoding
分块传输能力是http1.1 常见功能,不需要像websocket那样升级协议到帧格式,http连接中每个事件是独立的,直到连接关闭。
请求spiserver时查询参数加上watch=true, 会提示服务器本次是监听请求 响应核心特征是响应头包含Transfer-Encoding: chunked
验证
ini
终端1:kubectl proxy --port=8081 : 在主机上8081端口代理aiserver服务
终端2: curl "http://localhost:8081/api/v1/namespaces/team-a/pods?watch=true" --verbose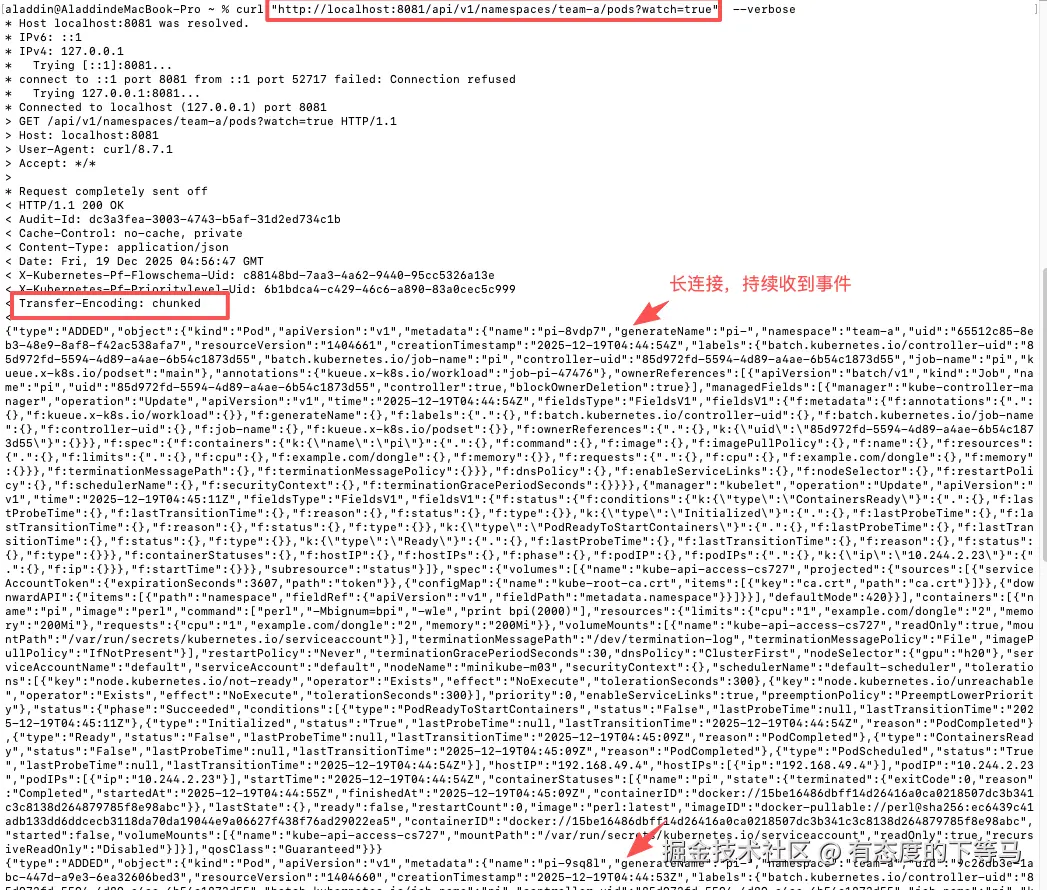
在client-go sdk中会为informer watch建立稳定的长连接(断线重连、重试等)
3. 一个常规的informer实践
利用kubeconfig创建informer(绑定gvr), 启动informer(带终止信道)
go
package main
import (
"fmt"
"time"
v1 "k8s.io/api/core/v1"
"k8s.io/apimachinery/pkg/fields"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/cache"
"k8s.io/client-go/tools/clientcmd"
)
func main() {
config, _ := clientcmd.BuildConfigFromFlags("", "/home/user/.kube/config")
clientset, _ := kubernetes.NewForConfig(config)
podInformer := cache.NewSharedIndexInformer(
cache.NewListWatchFromClient(
clientset.CoreV1().RESTClient(),
"pods",
v1.NamespaceAll,
fields.Everything(),
),
&v1.Pod{},
time.Minute*10, // resync 周期
cache.Indexers{ // cache上的快速过滤器
"byNode": func(obj interface{}) ([]string, error) {
pod := obj.(*v1.Pod)
return []string{pod.Spec.NodeName}, nil
}},
)
podInformer.AddEventHandler(cache.ResourceEventHandlerFuncs{
DeleteFunc: func(obj interface{}) {
pod := obj.(*v1.Pod)
fmt.Printf("[DELETED] Pod: %s/%s\n", pod.Namespace, pod.Name)
},
})
// 启动 informer (必须在独立goroutine中,因为Run方法是同步方法)
stopCh := make(chan struct{})
defer close(stopCh)
go func() {
fmt.Println("Starting PodInformer...")
podInformer.Run(stopCh) // 同步方法,会阻塞直到 stopCh 关闭
fmt.Println("PodInformer stopped")
}()
// 等待缓存同步就绪
if !cache.WaitForCacheSync(stopCh, podInformer.HasSynced) {
panic("failed to wait for cache sync")
}
<-stopCh
}-
informer有
resync机制: 周期性重放数据,目的是为业务提供补偿机会,上面设置了10分钟重放周期, =0或者不设置则不重放。 -
使用
cache.NewListWatchFromClient设置了informer的local cache, 开发者可以直接把local cache当成监听对象的集合,client-go会确保local cache正确反映当前的资源对象。 -
informer.Run(stopCh)是一个同步的函数,持续执行list-watch-cache-react这个引擎, 在应用层面需要以子goroutine形式,client-go另有informer工厂,informerFactory.Start(stopCh) 内部也是启协程,这里也要认识到信道stopCh在golang中的通信作用。
为加快这个informer cache访问速度,还可以给这个cache加上索引器
Indexers, 后面可直接使用索引器访问cache。
3.1 拉了一坨大的
如果把业务需求都做在EventHandler里面,长此以往会拉一坨大的。
首先这是一个事件队列消费模型 ,Add/Update/Delete变更事件是从一个叫deltaFIFO队列中pop出来的, 既然是队列模型,那么队列消费的高可用、高性能、可扩展问题就避免不了:
-
事件需要同步挨个处理,否则控制器侧拿到的最终资源状态可能不对,那么这种挨个处理也就谈不上高性能。
-
但是应用又是多实例部署, 多个informer都走同样的list-watch-cache-react流程, 客观上围绕informer deltaFIIO又形成多生产者=>多消费者模型,这种局面EventHandler就要考量幂等和资源一致性问题。
-
队列常规的高可用考量:① 消费者宕机时事件丢失 ② 消费失败如何重试(重试又有幂等性问题)
-
informer有
resync机制:会对local cache中的资源构造onUpdate事件,也会走EventHandler, 所以EventHandler做的很重,会很麻烦。
如果业务逻辑很重或者强依赖重试,推荐上[workQueue](https://pkg.go.dev/k8s.io/client-go@v0.35.0/util/workqueue "workQueue"), 支持以下功能:
-
公平:按添加顺序处理元素
-
元素去重:单个item不会被并发消费多次;如果一个item在消费前被多次添加,它只会被消费一次
-
多个消费者和生产者, 支持消费时重排
-
关闭通知
4. controller调谐设计
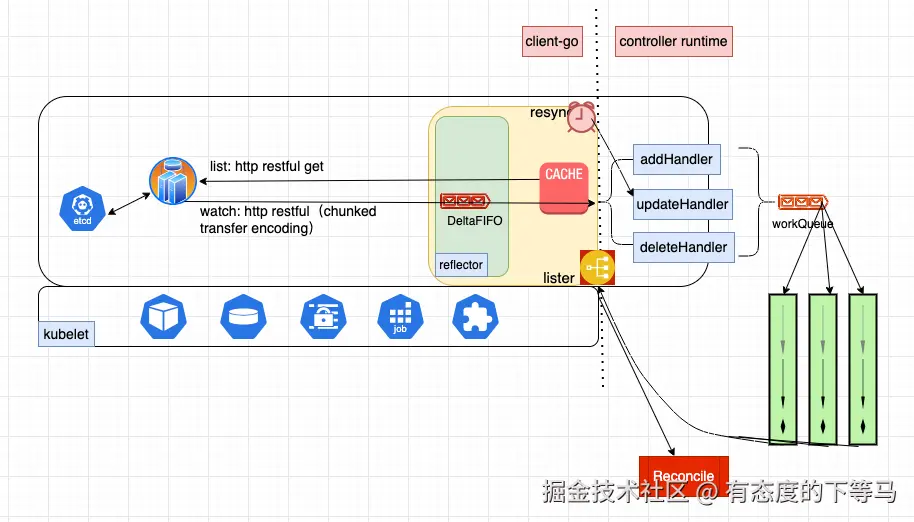
学习controller的设计:除了informer,还提供了额外的工具,帮助开发者高效感知最新的资源,执行调谐工作。
| package | role |
|---|---|
| informer | Eyes(watch and cache them) |
| lister | Memory(read from lcoal cache) |
| workQueue | task list (reconcile work) |
go
type PodController struct {
clientset kubernetes.Interface
queue workqueue.TypedRateLimitingInterface[string]
informer cache.SharedIndexInformer
indexer cache.Indexer
}
func NewPodController(clientset kubernetes.Interface) *PodController {
// 创建 Pod informer
podInformer := cache.NewSharedIndexInformer(
cache.NewListWatchFromClient(
clientset.CoreV1().RESTClient(),
"pods",
v1.NamespaceAll,
fields.Everything(),
),
&v1.Pod{},
time.Minute*10, // resync 周期
cache.Indexers{
"byNode": func(obj interface{}) ([]string, error) {
pod := obj.(*v1.Pod)
return []string{pod.Spec.NodeName}, nil
}},
)
// 创建控制器
controller := &PodController{
clientset: clientset,
queue: workqueue.NewTypedRateLimitingQueue(
workqueue.DefaultTypedControllerRateLimiter[string]( "string"),
),
informer: podInformer,
indexer: podInformer.GetIndexer(),
}
// 注册事件处理器
podInformer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.handleAdd,
UpdateFunc: controller.handleUpdate,
DeleteFunc: controller.handleDelete,
})
return controller
}① Informers: The Eyes on the Cluster
informer是一个管道,当发生变化时,该informer管道可确保:
- 本地缓存local cache已更新
- 任何已注册的事件处理程序(add/update/delete)都会收到通知
informer不会直接调用控制器的Reconcile方法,事件处理程序的唯一工作是将key (namespace/name)入队(workQueue)
为什么使用key?
资源对象变化很快→键更稳定→更适合数据去重。
go
func (c *PodController) handleAdd(obj interface{}) {
key, err := cache.MetaNamespaceKeyFunc(obj)
if err != nil {
klog.Errorf("Couldn't get key for object %+v: %v", obj, err)
return
}
c.queue.Add(key)
}② key一旦入队,就由workQueue接管
- 去重
- 重试、出队消费失败重排: 队列行为增强系统可用性
- 限速: 弹性设计,增强可用性和效率
③ lister:其实就是Indexers索引器
使用lister从local cache 读取最新的资源状态(不需要从api server读取),
最终执行控制器的Reconcile逻辑。

通过workQueue将架构从基于资源事件的队列转换为基于资源的队列 。
注意:这个时候的workQueue有事件压缩的效果: 在被消费之前,如果该资源有多个变更事件,只会保留首次入队(更新时间戳)。
Controller不关心对象如何到达当前状态,只关心当前状态是否与期望状态一致,并采取行动使其一致。
go
func (c *PodController) Run(workers int, stopCh <-chan struct{}) {
defer c.queue.ShutDown()
klog.Info("Starting Pod controller")
go c.informer.Run(stopCh)
if !cache.WaitForCacheSync(stopCh, c.informer.HasSynced) {
klog.Error("Timed out waiting for caches to sync")
return
}
for i := 0; i < workers; i++ {
go wait.Until(c.runWorker, time.Second, stopCh)
}
<-stopCh
klog.Info("Stopping Pod controller")
}
func (c *PodController) runWorker() {
for c.processNextWorkItem() {
}
}
func (c *PodController) processNextWorkItem() bool {
key, quit := c.queue.Get()
if quit {
return false
}
defer c.queue.Done(key)
err := c.syncPod(key)
if err != nil {
klog.Errorf("Error syncing pod %s: %v", key, err)
c.queue.AddRateLimited(key)
return true
}
c.queue.Forget(key)
return true
}
func main() {
// 创建 clientset
// config, _ := rest.InClusterConfig()
homepath := homedir.HomeDir()
kubeconfig := filepath.Join(homepath, ".kube", "config")
config, err := clientcmd.BuildConfigFromFlags("", kubeconfig) // 集群外认证访问 apiserver
if err != nil {
klog.Errorf("Error building kubeconfig: %v", err)
}
clientset, _ := kubernetes.NewForConfig(config)
controller := NewPodController(clientset)
stopCh := make(chan struct{})
controller.Run(3, stopCh)
}4.1 屎上雕花
上文产生的"一坨大的"是一个重度的事件处理行为:sync到mysql并做出通知。
咱就缺一个队列,可以使用workQueue, 但是本次需求要跟踪每次状态变更,于是要规避workQueue的事件压缩行为。
于是本次将(原资源key+ 资源版本+ 资源状态)整体作为入队元素。
css
item := QueueItem{
Key: fmt.Sprintf("%s/%s", pod.Namespace, pod.Name),
Version: pod.ResourceVersion,
Status : pod.Status,
}利用队列削峰填谷,满足了业务的需求和高可用、可扩展要求。
注意出队消费时仍要保证幂等操作, 可采用(资源key+资源version) 作为幂等键实现幂等的判定。
这就是某企业项目屎上雕花的经历, 老鸟轻喷。
🤖 🚀 👑 🛠️ 💡 🌟 🤖 ☕ 🔗 📄 📖 🌏 💼 🗣️