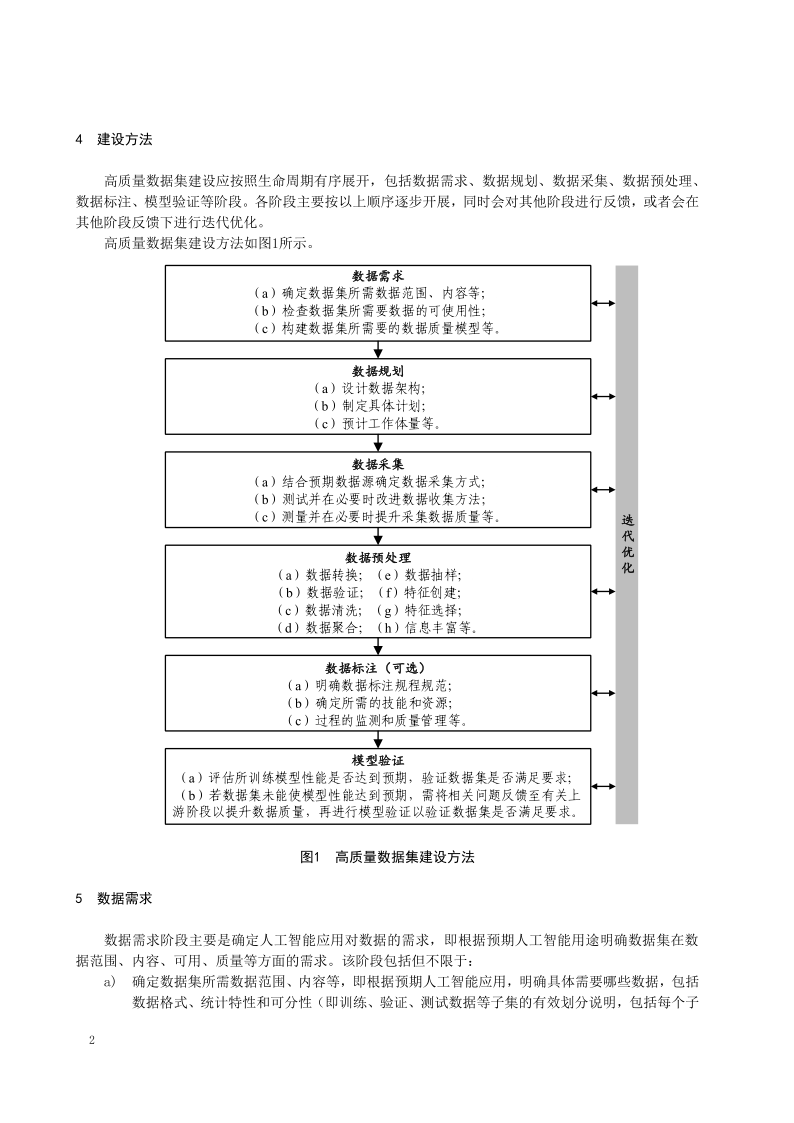
高质量数据集建设需遵循全生命周期管理,涵盖需求、规划、采集、预处理、标注、验证等阶段^6^。强调数据完整性、准确性、一致性,注重标注规范与合规性,通过体系化思维、设施化手段和生态化环境构建全流程建设格局^11011^。
详答
**一、高质量数据集建设的核心框架**
- **政策与标准引领**
-
**《高质量数据集建设指引》**:由国家数据局发布,提出"1+1"参考路径(建设方法论+运营体系),覆盖全流程建设格局^1^。
-
**《人工智能高质量数据集建设指南》**:由中国信通院等机构联合发布,界定高质量数据集为用于训练、验证和优化AI大模型的数据集合,强调数据质量、标注规范与合规性^48^。
-
**系列标准发布**:全国数据标准化技术委员会推动研制《高质量数据集建设指南》《格式要求》《分类指南》《质量评测规范》等标准,规范建设流程。
- **全生命周期管理**
-
**需求管理**:精准捕捉AI模型与业务部门需求,规范需求描述,分析优先级与合理性。
-
**设计管理**:构建数据集标准、质量、安全、合规框架,明确采集、标注、存储规则^10^。
-
**数据采集**:建立数据来源审查机制,关注合法性基础(如医疗数据需伦理审查、用户授权),避免敏感信息泄露^11^。
-
**数据预处理**:清洗噪声数据,处理缺失值(均值填充、插值法、模型预测),统一数据格式(如日期格式"2023-08-20")。
-
**数据标注**:结合领域知识(如医疗数据由医生标注),采用AI预标注+人工复核模式,提升标注准确率(如某电网将设备缺陷图像标注准确率从85%提升至95%)^13^。
-
**模型验证**:通过交叉验证、混淆矩阵等方法评估数据集对模型性能的影响,确保数据集有效性。
**二、高质量数据集的核心标准**
- **标注规范**
-
**领域知识融合**:医疗、法律等敏感领域需专业人员参与标注,避免主观偏差^13^。
-
**标注工具与流程**:采用标准化标注工具(如LabelImg、CVAT),制定标注规范文档,明确标注类别、属性与边界条件。
- **完整性(Completeness)**
-
**维度覆盖**:数据集需包含业务所需全部维度(如电商用户画像涵盖年龄、消费习惯、设备信息等)^13^。
-
**缺失值处理**:通过均值填充、插值法或模型预测补全缺失数据,并明确标注处理方式^1315^。
- **一致性(Consistency)**
-
**格式统一**:同一字段保持相同格式(如日期统一为"YYYY-MM-DD"),避免混合使用多种格式^15^。
-
**逻辑无矛盾**:数据集内部各字段间无逻辑冲突(如用户年龄与出生日期需匹配)。
- **准确性(Accuracy)**
-
**误差率控制**:数据误差率需严格控制在极小范围内(如不超过0.1%),确保数据真实反映对象或现象。
-
**异常值处理**:对数据中的错误或异常值进行纠正或合理解释(如天气预测数据集中的极端气候样本)。
**三、建设模式与实施路径**
- **研发管理**
-
**需求管理**:通过访谈、问卷、竞品分析等方式收集需求,建立需求跟踪矩阵(RTM),确保需求可追溯^10^。
-
**设计管理**:制定数据集设计文档(DDS),明确数据结构、字段定义、标注规则与质量标准^10^。
- **设施化手段**
-
**数据标注基地建设**:国家数据局统筹建设7大数据标注基地,覆盖524个行业数据集,形成生态体系^17^。
-
**平台化工具支持**:利用数据标注平台(如DataLoop、Label Studio)实现标注流程自动化,提升标注效率^10^。
- **生态化环境**
-
**跨部门协同机制**:国家数据局牵头,27个部委参与,建立跨部门协同机制,系统谋划工作思路与落实举措^5^。
-
**多方协作生态**:培育数据提供方、标注方、使用方与监管方多方协作生态,促进数据集共享与复用^1^。
**四、典型案例与行业实践**
- **教育领域**
- **北京师范大学"数字教育"数据集**:入选首批高质量数据集典型案例,聚焦教育信息化难题,提供算法学习所需的高质量数据支撑^3^。
- **能源领域**
- **某电网设备缺陷图像数据集**:通过AI预标注+人工复核模式,将标注准确率从85%提升至95%,支撑设备缺陷检测模型优化。
- **区域实践**
- **江苏、贵州等地政策支持**:苏州、北京国际大数据交易所等打造特色案例,推动区域数据集建设与交易^7^。
**五、挑战与突破路径**
- **现存短板**
-
**数据开放度不足**:部分行业数据未充分开放,限制数据集规模与多样性^1^。
-
**标准体系不完善**:数据质量评测、分类标准等需进一步细化。
- **突破措施**
-
**搭建行业知识索引框架**:构建覆盖全行业的知识图谱,提升数据集发现与利用效率^1^。
-
**构建"平台+数据集+模型"服务设施**:通过平台化工具整合数据集与模型资源,提供一站式服务^1^。
-
**培育多方协同生态**:鼓励数据提供方、标注方与使用方共建共享,形成良性循环^1^。
延展
-
**查询建议**:若需深入了解特定领域(如医疗、金融)的高质量数据集建设实践,可进一步检索"行业+高质量数据集建设案例"。
-
**思考方向**:可关注数据集隐私保护技术(如联邦学习、差分隐私)与数据集版本管理(如DVC、MLflow)等延伸主题。