
目录
[一、研究平台说明:为什么选择 32 位 Linux 2.6.32?](#一、研究平台说明:为什么选择 32 位 Linux 2.6.32?)
[二、程序地址空间回顾:C 语言程序员的 "刻板印象"](#二、程序地址空间回顾:C 语言程序员的 “刻板印象”)
[2.1 实操:验证程序地址空间布局](#2.1 实操:验证程序地址空间布局)
[2.2 结果分析:地址空间的 "有序分布"](#2.2 结果分析:地址空间的 “有序分布”)
[三、虚拟地址:打破 "物理地址" 的认知误区](#三、虚拟地址:打破 “物理地址” 的认知误区)
[3.1 实操:父子进程的 "地址诡异现象"](#3.1 实操:父子进程的 “地址诡异现象”)
[3.2 诡异结果:地址相同,值却不同?](#3.2 诡异结果:地址相同,值却不同?)
[3.3 虚拟地址的本质:进程的 "内存视角"](#3.3 虚拟地址的本质:进程的 “内存视角”)
[四、进程地址空间:不止是 "地址列表"](#四、进程地址空间:不止是 “地址列表”)
[4.1 进程地址空间的核心:独立性与有序性](#4.1 进程地址空间的核心:独立性与有序性)
[4.2 实操:验证进程地址空间的独立性](#4.2 实操:验证进程地址空间的独立性)
[4.3 为什么是 "进程" 地址空间,而非 "程序"?](#4.3 为什么是 “进程” 地址空间,而非 “程序”?)
[五、虚拟内存管理:内核中的 "地址管家"](#五、虚拟内存管理:内核中的 “地址管家”)
[5.1 核心数据结构 1:mm_struct(内存描述符)](#5.1 核心数据结构 1:mm_struct(内存描述符))
[5.1.1 mm_struct 的核心字段](#5.1.1 mm_struct 的核心字段)
[5.1.2 实操:查看进程的 mm_struct 信息](#5.1.2 实操:查看进程的 mm_struct 信息)
[5.2 核心数据结构 2:vm_area_struct(虚拟内存区域描述符)](#5.2 核心数据结构 2:vm_area_struct(虚拟内存区域描述符))
[5.2.1 vm_area_struct 的核心字段](#5.2.1 vm_area_struct 的核心字段)
[5.2.2 实操:查看进程的 VMA 列表](#5.2.2 实操:查看进程的 VMA 列表)
[5.3 核心数据结构 3:task_struct 与 mm_struct 的关联](#5.3 核心数据结构 3:task_struct 与 mm_struct 的关联)
[6.1 问题 1:物理内存访问的安全风险](#6.1 问题 1:物理内存访问的安全风险)
[6.2 问题 2:物理内存分配的地址不确定性](#6.2 问题 2:物理内存分配的地址不确定性)
[6.3 问题 3:物理内存使用的低效率](#6.3 问题 3:物理内存使用的低效率)
[6.4 虚拟地址空间的核心价值总结](#6.4 虚拟地址空间的核心价值总结)
[面试题 1:父子进程 fork 后,为什么虚拟地址相同但数据不同?](#面试题 1:父子进程 fork 后,为什么虚拟地址相同但数据不同?)
[面试题 2:malloc 申请的内存,什么时候真正分配物理内存?](#面试题 2:malloc 申请的内存,什么时候真正分配物理内存?)
[面试题 3:进程地址空间中的堆和栈有什么区别?](#面试题 3:进程地址空间中的堆和栈有什么区别?)
[面试题 4:为什么需要 VMA(虚拟内存区域)?](#面试题 4:为什么需要 VMA(虚拟内存区域)?)
[面试题 5:虚拟地址空间的优缺点是什么?](#面试题 5:虚拟地址空间的优缺点是什么?)
前言
在 Linux 系统编程中,"地址空间" 是一个贯穿始终的核心概念。你是否曾疑惑过:C 语言中
malloc(10)申请的内存到底存在哪里?父子进程为何会出现 "地址相同但数据不同" 的诡异现象?内核是如何管理进程的内存资源,让多个程序安全共存的?这些问题的答案,都藏在 Linux 程序地址空间的底层设计中。本文将为你层层揭开虚拟地址、进程地址空间、内存管理结构体的神秘面纱,最终让你彻底搞懂 "为什么要有虚拟地址空间" 这一核心问题,全程干货满满,实操性极强!下面就让我们正式开始吧!
一、研究平台说明:为什么选择 32 位 Linux 2.6.32?
在正式深入前,先明确我们的研究环境 ------32 位 Linux 系统 + 2.6.32 内核,选择这个组合的核心原因的有两点:
- 地址空间大小直观:32 位系统的虚拟地址空间总量为 4GB(2³² 字节),内核空间与用户空间的 1:3 划分(内核 1GB + 用户 3GB)清晰易懂,适合初学者建立直观认知;
- 内核源码简洁经典 :Linux 2.6.32 是长期支持版本(LTS),内存管理模块的核心数据结构(mm_struct、vm_area_struct)设计经典,没有后续高版本的复杂特性,更容易聚焦核心逻辑;
- 兼容性强,实操方便 :32 位程序在现代 64 位 Linux 系统中可通过
ia32-libs等库兼容运行,无需搭建专门的旧环境,Bash 命令和编译工具链无需特殊配置。
我们可以通过以下 Bash 命令验证系统环境(若为 64 位系统,可通过dpkg --add-architecture i386安装 32 位支持库):
bash
# 查看系统位数
getconf LONG_BIT # 输出32或64
# 查看内核版本
uname -r # 若不是2.6.32,可通过虚拟机安装对应版本(如Ubuntu 10.04)
# 安装32位编译工具链(64位系统必备)
sudo apt update && sudo apt install gcc-multilib g++-multilib -y二、程序地址空间回顾:C 语言程序员的 "刻板印象"
刚学 C 语言时,老师都会画一张这样的内存布局图:从低地址到高地址依次是正文代码区、初始化数据区、未初始化数据区(BSS)、堆区、共享区、栈区,最后是命令行参数和环境变量区,内核空间则占据最高的 1GB 地址。
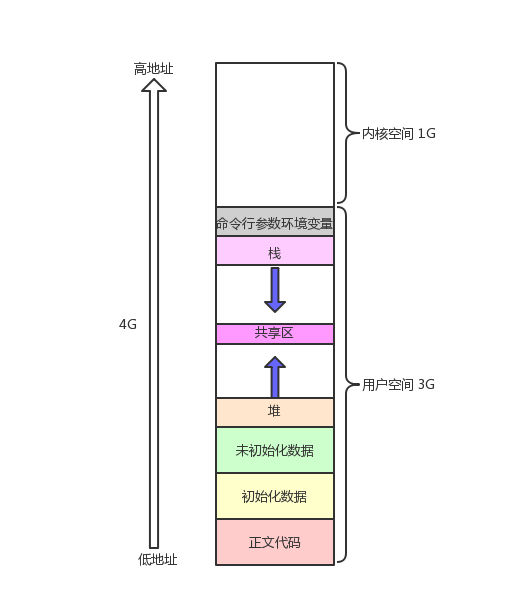
但这张图背后的逻辑的我们真的理解吗?为什么堆区向上增长、栈区向下增长?这些区域在内存中是连续的吗?我们先用 Bash 实操验证这张 "经典布局图",用代码亲眼看看各个区域的地址分布。
2.1 实操:验证程序地址空间布局
编写一个包含所有内存区域的 C 程序,编译后运行查看各区域地址:
bash
# 步骤1:编写测试程序(addr_layout.c)
cat > addr_layout.c << EOF
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
// 初始化全局变量(数据区)
int g_val = 100;
// 未初始化全局变量(BSS区)
int g_unval;
// 静态变量(数据区)
static int static_val = 200;
int main(int argc, char *argv[], char *env[]) {
// 只读字符串常量(代码区/只读数据区)
const char *ro_str = "hello, virtual address!";
// 栈变量
int stack_var1 = 1, stack_var2 = 2, stack_var3 = 3;
// 堆变量(通过malloc申请)
char *heap_var1 = (char*)malloc(10);
char *heap_var2 = (char*)malloc(10);
char *heap_var3 = (char*)malloc(10);
// 打印各区域地址
printf("=== 各内存区域地址分布 ===\n");
printf("1. 代码区(main函数地址): %p\n", main);
printf("2. 只读数据区(字符串常量): %p\n", ro_str);
printf("3. 初始化数据区(全局变量g_val): %p\n", &g_val);
printf("4. 初始化数据区(静态变量static_val): %p\n", &static_val);
printf("5. 未初始化数据区(全局变量g_unval): %p\n", &g_unval);
printf("6. 堆区(malloc分配): %p\n", heap_var1);
printf(" 堆区(malloc分配): %p\n", heap_var2);
printf(" 堆区(malloc分配): %p\n", heap_var3);
printf("7. 栈区(局部变量): %p\n", &stack_var1);
printf(" 栈区(局部变量): %p\n", &stack_var2);
printf(" 栈区(局部变量): %p\n", &stack_var3);
printf("8. 命令行参数(argv[0]): %p\n", argv[0]);
printf("9. 环境变量(env[0]): %p\n", env[0]);
// 防止程序退出,方便观察
sleep(30);
return 0;
}
EOF
# 步骤2:32位编译(关键!确保生成32位程序)
gcc -m32 addr_layout.c -o addr_layout
# 步骤3:运行程序,查看输出
./addr_layout2.2 结果分析:地址空间的 "有序分布"
运行后会得到类似这样的输出(地址值因系统而异,但分布规律一致):
=== 各内存区域地址分布 ===
1. 代码区(main函数地址): 0x804846b
2. 只读数据区(字符串常量): 0x8048760
3. 初始化数据区(全局变量g_val): 0x804a02c
4. 初始化数据区(静态变量static_val): 0x804a030
5. 未初始化数据区(全局变量g_unval): 0x804a034
6. 堆区(malloc分配): 0x804b008
堆区(malloc分配): 0x804b014
堆区(malloc分配): 0x804b020
7. 栈区(局部变量): 0xffd7b8e8
栈区(局部变量): 0xffd7b8e4
栈区(局部变量): 0xffd7b8e0
8. 命令行参数(argv[0]): 0xffd7ba44
9. 环境变量(env[0]): 0xffd7ba50通过 Bash 命令排序地址,更直观地看到分布规律:
bash
# 将输出的地址提取出来排序(简化版,手动复制地址后执行)
echo -e "0x804846b\n0x8048760\n0x804a02c\n0x804a030\n0x804a034\n0x804b008\n0x804b014\n0x804b020\n0xffd7b8e0\n0xffd7b8e4\n0xffd7b8e8\n0xffd7ba44\n0xffd7ba50" | sort排序后会发现地址从低到高的顺序完全符合 C 语言课本上的布局:代码区 → 只读数据区 → 初始化数据区 → 未初始化数据区 → 堆区 → 栈区 → 命令行参数 → 环境变量
两个关键现象值得注意:
- 堆区地址递增 :
heap_var1 < heap_var2 < heap_var3,证明堆区确实是 "向上增长" 的;- 栈区地址递减 :
stack_var1 > stack_var2 > stack_var3,证明栈区是 "向下增长" 的;- 堆与栈之间存在巨大间隙:堆区最高地址(约 0x804b020)与栈区最低地址(约 0xffd7b8e0)之间相差近 255MB,这就是 32 位系统用户空间中留给堆和栈动态增长的 "弹性空间"。
但此时一个疑问涌上心头:这些地址是物理内存的真实地址吗?如果是,那么多个进程同时运行时,会不会出现地址冲突?我们通过父子进程的地址对比实验来寻找答案。
三、虚拟地址:打破 "物理地址" 的认知误区
前面的实验让我们看到了程序地址空间的有序布局,但这只是 "表象"。真正的关键在于:我们看到的这些地址,并不是物理内存的真实地址,而是虚拟地址。
3.1 实操:父子进程的 "地址诡异现象"
编写一个 fork 创建父子进程的程序,观察变量地址和值的变化:
cpp
# 步骤1:编写测试程序(virtual_addr_test.c)
cat > virtual_addr_test.c << EOF
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
// 全局变量
int g_val = 0;
int main() {
pid_t pid = fork();
if (pid < 0) {
perror("fork failed");
return 1;
} else if (pid == 0) {
// 子进程:修改全局变量的值
g_val = 100;
printf("子进程(PID: %d): g_val = %d, 地址 = %p\n", getpid(), g_val, &g_val);
sleep(10); // 保持子进程存活
} else {
// 父进程:延迟3秒后读取全局变量
sleep(3);
printf("父进程(PID: %d): g_val = %d, 地址 = %p\n", getpid(), g_val, &g_val);
sleep(10); // 保持父进程存活
}
return 0;
}
EOF
# 步骤2:32位编译
gcc -m32 virtual_addr_test.c -o virtual_addr_test
# 步骤3:运行程序,观察输出
./virtual_addr_test3.2 诡异结果:地址相同,值却不同?
运行后会得到这样的输出:
子进程(PID: 12345): g_val = 100, 地址 = 0x804a02c
父进程(PID: 12344): g_val = 0, 地址 = 0x804a02c这是一个颠覆认知的结果:
- 父子进程中g_val的地址完全相同(都是 0x804a02c);
- 但变量的值却不同(子进程 100,父进程 0)。
如果这个地址是物理地址,这是绝对不可能的 ------ 同一个物理地址不可能存储两个不同的值。这就证明了:我们看到的地址不是物理地址,而是虚拟地址。
3.3 虚拟地址的本质:进程的 "内存视角"
虚拟地址是操作系统为每个进程分配的 "逻辑地址",每个进程都有自己独立的虚拟地址空间,就像每个程序员都有自己的 "代码笔记本",笔记本上的页码(虚拟地址)相同,但里面的内容(数据)可以不同。
操作系统通过页表(Page Table) 和内存管理单元(MMU) 实现虚拟地址到物理地址的映射:
- 进程访问虚拟地址时,CPU 会将虚拟地址发送给MMU;
- MMU 查询该进程的页表,将虚拟地址转换为物理地址;
- CPU 通过物理地址访问实际的内存单元。
父子进程的g_val虚拟地址相同,但页表将其映射到了不同的物理地址,因此值不同 ------ 这就是 "写时拷贝(Copy-On-Write)" 机制:fork 创建子进程时,父子进程共享物理内存,直到子进程修改数据时,操作系统才为子进程分配新的物理内存,并更新页表映射。
我们可以通过 Bash 命令查看进程的页表信息(需要 root 权限):
bash
# 假设进程PID为12344(父进程)
sudo cat /proc/12344/maps # 查看虚拟地址空间的映射关系
sudo cat /proc/12344/smaps # 查看更详细的内存映射信息(包括物理页框)运行cat /proc/12344/maps后,会看到类似这样的输出(关键部分):
08048000-08049000 r-xp 00000000 08:01 1234567 /home/user/virtual_addr_test # 代码区
08049000-0804a000 r--p 00000000 08:01 1234567 /home/user/virtual_addr_test # 只读数据区
0804a000-0804b000 rw-p 00001000 08:01 1234567 /home/user/virtual_addr_test # 数据区(g_val所在区域)
...
ffd7a000-ffd9b000 rw-p 00000000 00:00 0 [stack] # 栈区其中**0804a000-0804b000** 就是g_val所在的虚拟地址区间,rw-p表示该区域可读写、私有(Private),这也解释了为什么子进程修改数据后会触发写时拷贝。
四、进程地址空间:不止是 "地址列表"
通过前面的实验,我们知道了每个进程都有独立的虚拟地址空间,但这个 "空间" 到底是什么?它不是物理内存的镜像,而是操作系统为进程构建的 "逻辑视图"------ 准确来说,应该叫做 "进程地址空间",而不是 "程序地址空间"。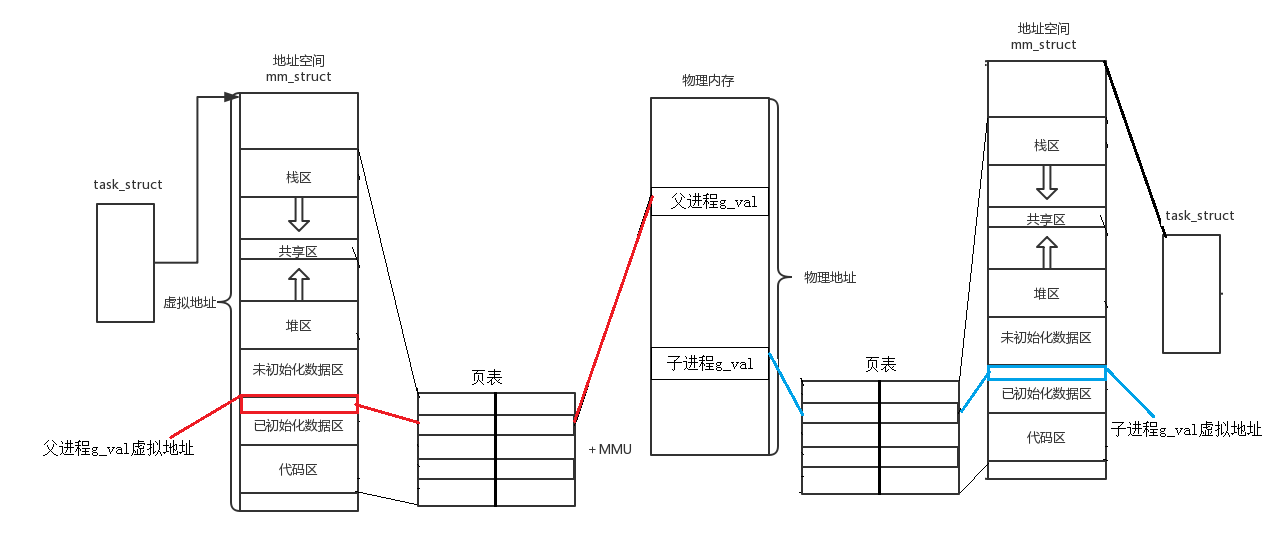
4.1 进程地址空间的核心:独立性与有序性
进程地址空间的两大核心特性:
- 独立性:每个进程的虚拟地址空间相互隔离,进程只能访问自己的虚拟地址,无法直接访问其他进程的虚拟地址(除非通过共享内存等特殊机制),这保证了进程的安全性;
- 有序性 :每个进程的虚拟地址空间都遵循**"代码区→数据区→堆区→栈区"**的固定布局,即使物理内存中的数据是分散的,进程也会认为自己的内存是有序且连续的。
用一个生动的类比理解:
- 进程地址空间就像一个 "快递仓库",每个进程都有自己的仓库编号(虚拟地址);
- 物理内存是 "实际的货架",货架编号(物理地址)可能杂乱无章;
- 页表就是 "快递单号对照表",将仓库编号(虚拟地址)映射到货架编号(物理地址);
- 快递员(CPU/MMU)根据对照表派送快递(访问数据),仓库管理员(操作系统)负责维护对照表和货架秩序。
4.2 实操:验证进程地址空间的独立性
我们通过两个独立进程访问相同虚拟地址,验证它们的物理地址是否不同:
cpp
# 步骤1:编写一个循环访问固定虚拟地址的程序(addr_indep.c)
cat > addr_indep.c << EOF
#include <stdio.h>
#include <unistd.h>
int main() {
// 定义一个变量,记录其虚拟地址
int var = 0;
printf("进程PID: %d, 变量var的虚拟地址: %p, 值: %d\n", getpid(), &var, var);
// 循环等待,方便观察
while (1) {
sleep(1);
var++; // 不断修改值,避免被优化
}
return 0;
}
EOF
# 步骤2:32位编译
gcc -m32 addr_indep.c -o addr_indep
# 步骤3:打开两个终端,分别运行程序
# 终端1
./addr_indep
# 终端2
./addr_indep运行后会发现,两个进程的var变量虚拟地址完全相同(例如都是 0xffd7b8e4),但值各自递增,互不干扰 ------ 这正是进程地址空间独立性的直接证明。
我们可以通过ps命令查看两个进程的状态,并通过pmap命令查看它们的内存映射:
bash
# 查看进程PID
ps aux | grep addr_indep | grep -v grep
# 查看进程的内存映射(以PID 12345为例)
pmap -x 12345 pmap输出中会显示每个虚拟地址区间的权限、大小、物理页框号等信息,两个进程的相同虚拟地址区间会对应不同的物理页框号,进一步验证了地址空间的独立性。
4.3 为什么是 "进程" 地址空间,而非 "程序"?
程序是存放在磁盘上的可执行文件(如a.out),是静态的;而进程是程序的执行实例,是动态的。只有当程序被加载到内存运行时,操作系统才会为其创建进程地址空间 ------ 同一个程序可以被多个进程加载,每个进程都会有自己独立的进程地址空间,这就是为什么多个用户可以同时运行同一个软件(如 Chrome 浏览器),却不会相互干扰。
用指令查看磁盘上的程序和内存中的进程的区别:
bash
# 查看程序文件(静态)的大小和结构
ls -l addr_indep # 查看文件大小
objdump -h -m i386 addr_indep # 查看程序的段结构(代码段、数据段等)
# 查看进程(动态)的内存占用
ps aux | grep addr_indep | grep -v grep # 查看进程的VSZ(虚拟内存大小)和RSS(物理内存大小)输出会显示:程序文件的大小(如几 KB)远小于进程的虚拟内存大小(如几 MB),因为进程地址空间包含了动态分配的堆、栈、共享库等内容,而程序文件只包含静态的代码和数据。
五、虚拟内存管理:内核中的 "地址管家"
进程地址空间的构建和维护,依赖于 Linux 内核中的三个核心数据结构:task_struct(进程控制块)、mm_struct(内存描述符)、vm_area_struct(虚拟内存区域描述符)。它们就像 "地址管家团队",共同管理进程的虚拟地址空间。
进程地址的分布情况如下:
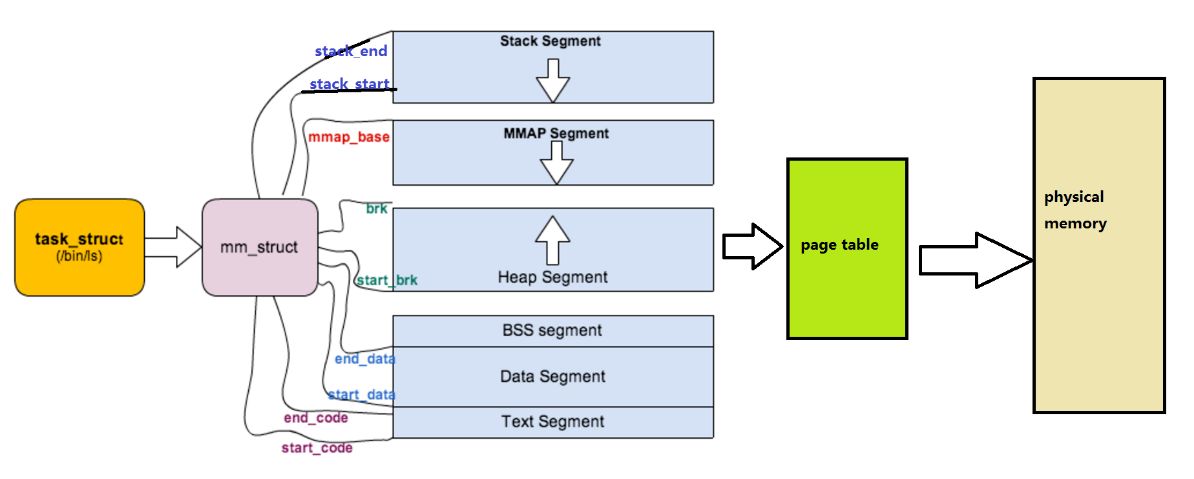
5.1 核心数据结构 1:mm_struct(内存描述符)
mm_struct是进程地址空间的 "总管家",每个进程的task_struct(PCB)中都有一个指向mm_struct的指针,它记录了进程地址空间的整体信息。
5.1.1 mm_struct 的核心字段
我们通过查看 Linux 2.6.32 内核源码,了解mm_struct的关键字段(源码路径:include/linux/mm_types.h):
bash
# 下载Linux 2.6.32内核源码并查看mm_struct定义
wget https://mirrors.edge.kernel.org/pub/linux/kernel/v2.6/linux-2.6.32.tar.bz2
tar -xjvf linux-2.6.32.tar.bz2
grep -A 50 "struct mm_struct" linux-2.6.32/include/linux/mm_types.h核心字段解析(简化版):
cpp
struct mm_struct {
struct vm_area_struct *mmap; // 指向虚拟内存区域(VMA)的单链表
struct rb_root mm_rb; // 指向VMA的红黑树(用于快速查找)
unsigned long task_size; // 进程虚拟地址空间的大小(32位系统为0xc0000000,即3GB)
unsigned long start_code, end_code; // 代码段的起始和结束虚拟地址
unsigned long start_data, end_data; // 数据段的起始和结束虚拟地址
unsigned long start_brk, brk; // 堆区的起始和当前结束虚拟地址
unsigned long start_stack; // 栈区的起始虚拟地址
unsigned long arg_start, arg_end; // 命令行参数的起始和结束虚拟地址
unsigned long env_start, env_end; // 环境变量的起始和结束虚拟地址
// 其他字段...
}; mm_struct的核心作用:
- 记录进程地址空间各区域的虚拟地址范围;
- 通过链表(
mmap)和红黑树(mm_rb)组织所有虚拟内存区域(VMA);- 为进程提供统一的内存管理接口(如堆扩展、栈扩展)。
5.1.2 实操:查看进程的 mm_struct 信息
Linux 系统通过/proc/[PID]/status文件暴露了mm_struct的部分关键信息,我们可以通过 Bash 命令查看:
bash
# 假设进程PID为12345
cat /proc/12345/status | grep -E "VmSize|VmRSS|VmData|VmStk|VmExe|VmLib"输出字段解析:
VmSize:虚拟内存大小(对应task_size);VmRSS:物理内存常驻大小(实际占用的物理内存页数);VmExe:代码段大小(对应end_code - start_code);VmData:数据段 + 堆区大小(对应brk - start_data);VmStk:栈区大小;VmLib:共享库占用的虚拟内存大小。
5.2 核心数据结构 2:vm_area_struct(虚拟内存区域描述符)
进程地址空间中的每个 "连续区间"(如代码区、数据区、堆区的某一段)都由一个vm_area_struct结构体描述,简称 VMA。它是进程地址空间的 "区域管家",每个 VMA 代表一段权限相同、用途相同的虚拟地址区间。
5.2.1 vm_area_struct 的核心字段
查看 Linux 2.6.32 内核源码中vm_area_struct的定义:
bash
grep -A 60 "struct vm_area_struct" linux-2.6.32/include/linux/mm_types.h核心字段解析(简化版):
cpp
struct vm_area_struct {
unsigned long vm_start; // 该VMA的起始虚拟地址
unsigned long vm_end; // 该VMA的结束虚拟地址(左闭右开区间)
struct vm_area_struct *vm_next, *vm_prev; // 链表指针,连接其他VMA
struct rb_node vm_rb; // 红黑树节点,用于快速查找
struct mm_struct *vm_mm; // 指向所属的mm_struct
pgprot_t vm_page_prot; // 该VMA的访问权限(如只读、可读写、可执行)
unsigned long vm_flags; // 标志位(如VM_READ、VM_WRITE、VM_EXEC、VM_SHARED)
struct file *vm_file; // 若该VMA映射到文件(如共享库、内存映射文件),指向对应的文件
// 其他字段...
}; vm_flags是 VMA 的核心标志位,常见取值:
VM_READ:可读取;VM_WRITE:可写入;VM_EXEC:可执行;VM_SHARED:共享 VMA(多个进程可共享该区域的物理内存);VM_PRIVATE:私有 VMA(进程独占,修改时触发写时拷贝)。
5.2.2 实操:查看进程的 VMA 列表
/proc/[PID]/maps文件就是进程所有 VMA 的列表,我们可以通过 Bash 命令分析:
bash
# 以之前的addr_layout进程为例(PID 12346)
cat /proc/12346/maps | awk '{print "虚拟地址区间:", $1, " 权限:", $2, " 用途:", $6}'输出类似这样(关键 VMA):
虚拟地址区间: 08048000-08049000 权限: r-xp 用途: /home/user/addr_layout # 代码区(可执行、只读、私有)
虚拟地址区间: 08049000-0804a000 权限: r--p 用途: /home/user/addr_layout # 只读数据区(只读、私有)
虚拟地址区间: 0804a000-0804b000 权限: rw-p 用途: /home/user/addr_layout # 数据区(可读写、私有)
虚拟地址区间: 0804b000-0806c000 权限: rw-p 用途: [heap] # 堆区(可读写、私有)
虚拟地址区间: ffd7a000-ffd9b000 权限: rw-p 用途: [stack] # 栈区(可读写、私有)
虚拟地址区间: ffffe000-fffff000 权限: r-xp 用途: [vdso] # 虚拟动态共享对象(共享库)每个 VMA 都是连续的虚拟地址区间,权限和用途相同,进程的地址空间就是由这些 VMA "拼接" 而成的 ------ 虽然物理内存中这些区域可能是分散的,但进程视角中是连续且有序的。
5.3 核心数据结构 3:task_struct 与 mm_struct 的关联
task_struct(PCB)是进程的 "身份证",其中包含了指向mm_struct的指针,将进程的调度信息与内存信息关联起来:
cpp
struct task_struct {
// ... 其他字段 ...
struct mm_struct *mm; // 指向进程的内存描述符(用户空间)
struct mm_struct *active_mm; // 内核线程使用的内存描述符
// ... 其他字段 ...
};对于普通用户进程,mm指向其专属的mm_struct;对于内核线程(如kthreadd),mm为 NULL,active_mm指向某个用户进程的mm_struct(因为内核线程不需要用户空间,可共享其他进程的内核空间映射)。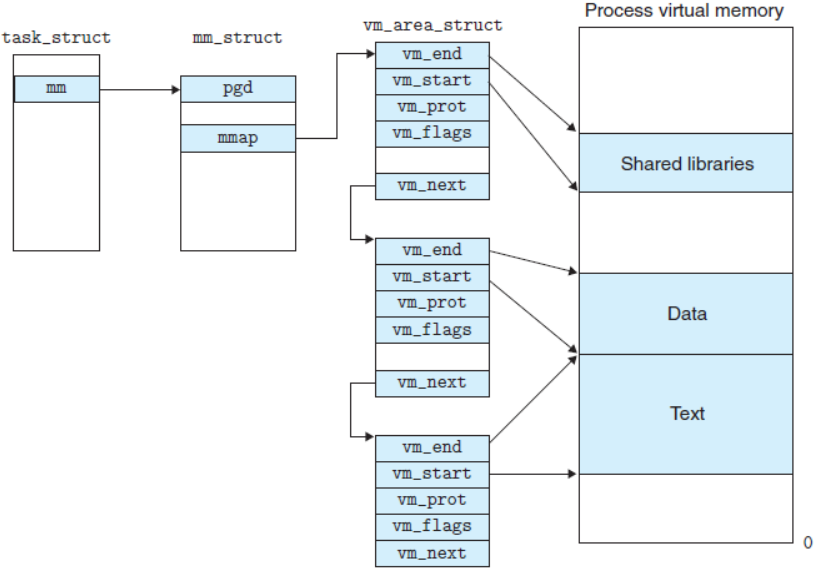
我们可以通过 Bash 命令查看进程的task_struct中mm字段的地址(需要内核调试工具):
bash
# 安装内核调试工具
sudo apt install gdb linux-image-$(uname -r)-dbg -y
# 启动gdb,附加到进程(PID 12346)
gdb -p 12346
# 在gdb中查看task_struct的mm字段(32位系统,task_struct中mm的偏移量可通过内核源码查询)
# 注意:不同内核版本偏移量可能不同,2.6.32中mm的偏移量约为0x180(需根据实际情况调整)
(gdb) p ((struct task_struct *)0xc1234567)->mm # 0xc1234567为进程的task_struct物理地址(需通过内核工具查询)虽然直接查看内核数据结构需要一定的调试技巧,但通过/proc文件系统,我们已经能间接获取大部分关键信息 ------ 这也是 Linux 系统的设计哲学:通过用户态工具暴露内核状态,方便开发者和运维人员排查问题。
如上所述,我们最终可以将架构图补充如下: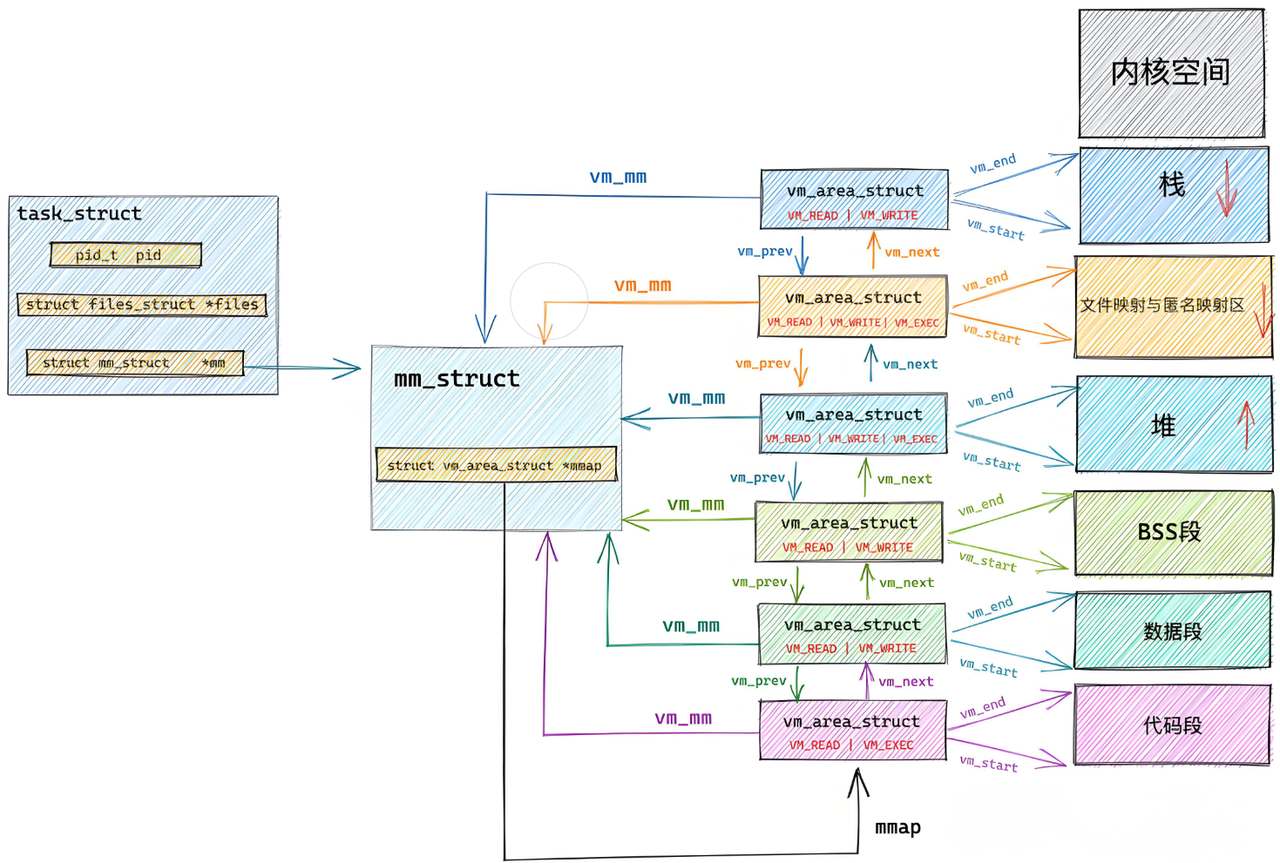
六、为什么要有虚拟地址空间?解决三大核心问题
看到这里,你可能会问:操作系统为什么要搞这么复杂的虚拟地址空间?直接让进程访问物理内存不行吗?答案是:不行!虚拟地址空间是为了解决直接访问物理内存的三大核心问题。
6.1 问题 1:物理内存访问的安全风险
如果进程直接访问物理内存,会导致严重的安全问题:
- 恶意进程可以直接修改其他进程的物理内存数据(如篡改密码、窃取数据);
- 进程误操作可能覆盖内核的物理内存数据,导致系统崩溃。
虚拟地址空间通过 "隔离性" 解决了这个问题:
- 进程只能访问自己的虚拟地址,无法直接访问其他进程的虚拟地址;
- 虚拟地址到物理地址的映射由操作系统控制,进程无法修改页表,因此无法访问未授权的物理内存;
- 内核空间的虚拟地址(32 位系统中 0xc0000000~0xffffffff)只有内核态进程才能访问,用户态进程无法访问,保护了内核的安全。
我们可以通过一个实验验证用户态进程无法访问内核空间:
cpp
# 步骤1:编写一个尝试访问内核空间虚拟地址的程序(access_kernel.c)
cat > access_kernel.c << EOF
#include <stdio.h>
#include <string.h>
int main() {
// 32位系统内核空间起始地址:0xc0000000
void *kernel_addr = (void *)0xc0000000;
char buf[10];
printf("尝试访问内核空间虚拟地址:%p\n", kernel_addr);
// 尝试读取内核空间数据
if (memcpy(buf, kernel_addr, 10) == NULL) {
perror("读取内核空间失败");
}
return 0;
}
EOF
# 步骤2:32位编译
gcc -m32 access_kernel.c -o access_kernel
# 步骤3:运行程序,观察结果
./access_kernel运行后会输出:
尝试访问内核空间虚拟地址:0xc0000000
读取内核空间失败: Segmentation fault (core dumped)这就是 "段错误"(Segmentation Fault),操作系统阻止了用户态进程访问内核空间,保护了系统安全。
6.2 问题 2:物理内存分配的地址不确定性
如果进程直接访问物理内存,会面临 "地址不确定" 的问题:
- 程序编译时无法知道自己会被加载到物理内存的哪个位置(因为物理内存的使用状态是动态变化的);
- 例如,第一次运行
a.out时,物理内存空闲,加载到 0x00000000;第二次运行时,物理内存已被其他进程占用,可能加载到 0x10000000------ 这会导致程序中的绝对地址引用失效(如跳转指令、指针操作)。
虚拟地址空间通过 "固定的逻辑布局" 解决了这个问题:
- 无论程序被加载到物理内存的哪个位置,其虚拟地址空间的布局都是固定的(代码区在 0x8048000,数据区在 0x804a000 等);
- 程序编译时使用的是虚拟地址,无需关心物理内存的实际位置,链接器会根据虚拟地址布局调整指令和数据的地址引用;
- 操作系统通过页表将虚拟地址映射到任意物理地址,实现了 "程序地址固定,物理地址灵活"。
我们可以通过 Bash 命令查看程序的编译地址:
bash
# 查看addr_layout程序的代码段起始地址(编译时确定的虚拟地址)
objdump -f addr_layout | grep "start address"输出会显示:
start address 0x0804846b这个地址就是程序编译时确定的虚拟地址,无论物理内存如何分配,这个虚拟地址都不会改变。
6.3 问题 3:物理内存使用的低效率
直接使用物理内存会导致内存利用率低下,主要体现在两个方面:
- 内存浪费:程序必须一次性加载到物理内存才能运行,即使程序只需要执行其中一小部分(如初始化代码),也会占用大量物理内存;
- 交换效率低:当物理内存不足时,需要将整个进程的物理内存数据交换到磁盘(交换分区),恢复时再全部加载回物理内存,耗时很长。
虚拟地址空间通过 "分页机制" 和 "延迟分配" 解决了这个问题:
- 分页机制:将虚拟地址空间和物理内存划分为固定大小的 "页"(32 位系统默认 4KB),只有程序需要访问的页才会被加载到物理内存,未访问的页可以留在磁盘上(如程序的代码段、数据段);
- 延迟分配 :进程调用malloc申请内存时,操作系统只是在虚拟地址空间中预留一段区间,并未实际分配物理内存;只有当进程真正写入数据时(如
*ptr = 1),才会触发 "缺页异常",操作系统才会分配物理内存并建立页表映射。
我们可以通过 Bash 命令验证延迟分配机制:
cpp
# 步骤1:编写一个申请内存但不写入数据的程序(lazy_alloc.c)
cat > lazy_alloc.c << EOF
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
// 申请100MB内存
char *ptr = (char*)malloc(100 * 1024 * 1024);
printf("申请100MB内存成功,虚拟地址区间:%p - %p\n", ptr, ptr + 100*1024*1024);
printf("进程PID: %d,等待10秒...\n", getpid());
sleep(10); // 此时未写入数据,物理内存未分配
// 写入数据,触发物理内存分配
memset(ptr, 0, 100 * 1024 * 1024);
printf("写入数据完成,等待10秒...\n");
sleep(10); // 此时物理内存已分配
free(ptr);
return 0;
}
EOF
# 步骤2:32位编译
gcc -m32 lazy_alloc.c -o lazy_alloc
# 步骤3:运行程序,同时在另一个终端监控物理内存占用
# 终端1:运行程序
./lazy_alloc
# 终端2:每2秒查看一次物理内存占用(PID为程序输出的PID)
watch -n 2 "ps aux | grep -E 'PID|lazy_alloc' | grep -v grep"监控结果会显示:
- 程序刚申请内存时,
RSS(物理内存占用)很小(仅几 KB);- 执行memset写入数据后,
RSS迅速增长到约 100MB------ 这就是延迟分配的直接证明。
6.4 虚拟地址空间的核心价值总结
虚拟地址空间通过 "隔离性、有序性、灵活性" 解决了直接访问物理内存的安全、地址不确定、效率低三大问题,其核心价值在于:
- 安全隔离:进程间内存隔离,防止恶意访问和误操作;
- 地址抽象:为进程提供固定、有序的逻辑地址布局,简化程序编译和链接;
- 高效利用:通过分页、延迟分配、交换机制,提高物理内存利用率和系统响应速度;
- 模块解耦:进程管理模块和内存管理模块解耦,进程无需关心物理内存分配,操作系统统一管理。
七、高频面试题解答
面试题 1:父子进程 fork 后,为什么虚拟地址相同但数据不同?
答:因为 fork 创建子进程时,父子进程共享物理内存和页表,虚拟地址相同;当子进程修改数据时,会触发写时拷贝(COW),操作系统为子进程分配新的物理内存,更新子进程的页表映射,因此虚拟地址相同但物理地址不同,数据也不同。
面试题 2:malloc 申请的内存,什么时候真正分配物理内存?
答:malloc 申请内存时,操作系统仅在虚拟地址空间中预留区间,并未分配物理内存;当进程首次向该内存写入数据时(如*ptr = 1),会触发缺页异常,操作系统才会分配物理内存并建立页表映射 ------ 这就是延迟分配机制。
面试题 3:进程地址空间中的堆和栈有什么区别?
答:核心区别有 4 点:
- 增长方向:堆向上增长(地址递增),栈向下增长(地址递减);
- 分配方式:堆由程序员手动分配(malloc/free),栈由编译器自动分配(局部变量、函数参数);
- 大小限制 :堆大小受限于虚拟地址空间剩余容量和物理内存,栈大小有固定限制(默认 8MB,可通过
ulimit -s修改); - 分配效率:栈分配效率高(只需移动栈指针),堆分配效率低(需要操作系统维护空闲内存链表)。
面试题 4:为什么需要 VMA(虚拟内存区域)?
答:VMA 将进程的虚拟地址空间划分为多个权限相同、用途相同的连续区间,便于操作系统管理:
- 权限控制:不同 VMA 可设置不同权限(如代码区只读可执行,数据区可读写),提高安全性;
- 高效查找:通过链表和红黑树组织 VMA,操作系统可快速查找某个虚拟地址所属的 VMA;
- 内存优化:同一 VMA 的页面具有相同的属性(如是否共享、是否可交换),便于操作系统进行分页管理和优化。
面试题 5:虚拟地址空间的优缺点是什么?
答:
- 优点:进程隔离安全、地址布局固定、内存利用率高、模块解耦;
- 缺点:增加了地址转换的开销(MMU 和页表查询),内核内存管理复杂度提高。但这些开销相对于其带来的优势可以忽略不计,是现代操作系统的必然选择。
总结
希望通过本文的学习,你不仅能记住 "进程地址空间是独立的""虚拟地址需要映射到物理地址" 这些结论,更能理解其背后的设计思想 ------ 操作系统的每一个机制,都是为了解决实际问题而存在的。
如果本文对你有帮助,欢迎点赞、收藏、转发,也欢迎在评论区交流你遇到的内存管理问题!后续我们还会深入讲解其他进话题,敬请关注!