目录
| 分类依据 | 注意力类别 | 核心特征 | 典型代表 |
|---|---|---|---|
| 有 QKV 三元组结构 | 自注意力机制(Self-Attention)(含多头自注意力) | 1. 核心逻辑是通过 Query 与 Key 计算相似度,生成注意力权重,再对 Value 加权求和 2. 支持全局特征依赖建模,不局限于局部感受野3. 权重计算基于特征间的两两相似度,无先验约束 | 1. 标准自注意力(Transformer 核心模块)2. 多头自注意力(Multi-Head Self-Attention)3. 交叉注意力(Cross-Attention,如 ViT 的编码器 - 解码器结构) |
| 无 QKV 三元组结构 | 非自注意力机制(Non-Self-Attention)(又称传统注意力 / 局部注意力) | 1. 不设计 Q/K/V 向量,直接通过池化、卷积、门控等操作 计算特征权重2. 多聚焦局部维度(通道、空间、坐标)的特征增强,结构轻量3. 权重计算依赖先验操作(如全局池化提取通道统计信息),计算开销低 | 1. 通道注意力:SENet、ECA2. 空间 + 通道注意力:CBAM、CA3. 空间注意力:STN(空间变换网络) |
注意力:获取权重 ,图像的某个特征轴
本质:合理权重分配
深度学习中有两类注意力:一种是有QKV的,一种是没有QKV的。本节复习非自注意力机制
都是作用在特征图(H,W,C)上的
SENet
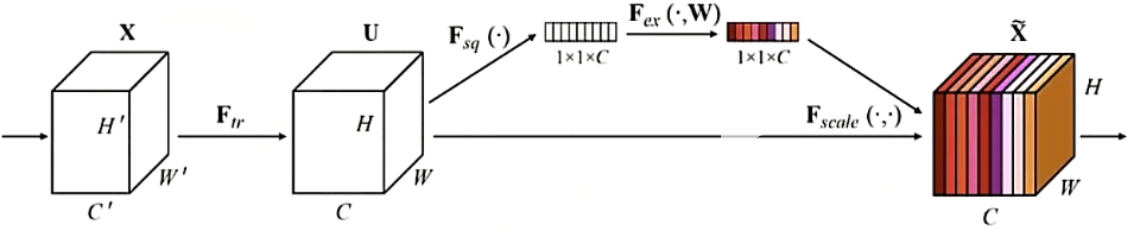
全局平均池化(GAP)

每个通道对应的矩阵求均值
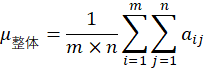
补知识)全连接层
核心特征:是相邻两层的所有神经元之间两两连接,每个神经元的输入是上一层所有神经元输出的加权和
主要功能:全局特征整合、特征映射到输出空间
补知识)隐藏层
核心特征:介于输入层和输出层之间的所有网络层,不直接与外部数据(输入特征、输出标签)交互,是神经网络实现复杂特征学习的核心模块
主要功能:特征提取与非线性变换、调控模型复杂度
ECA
SENet中的全连接设计替换为卷积即为ECA
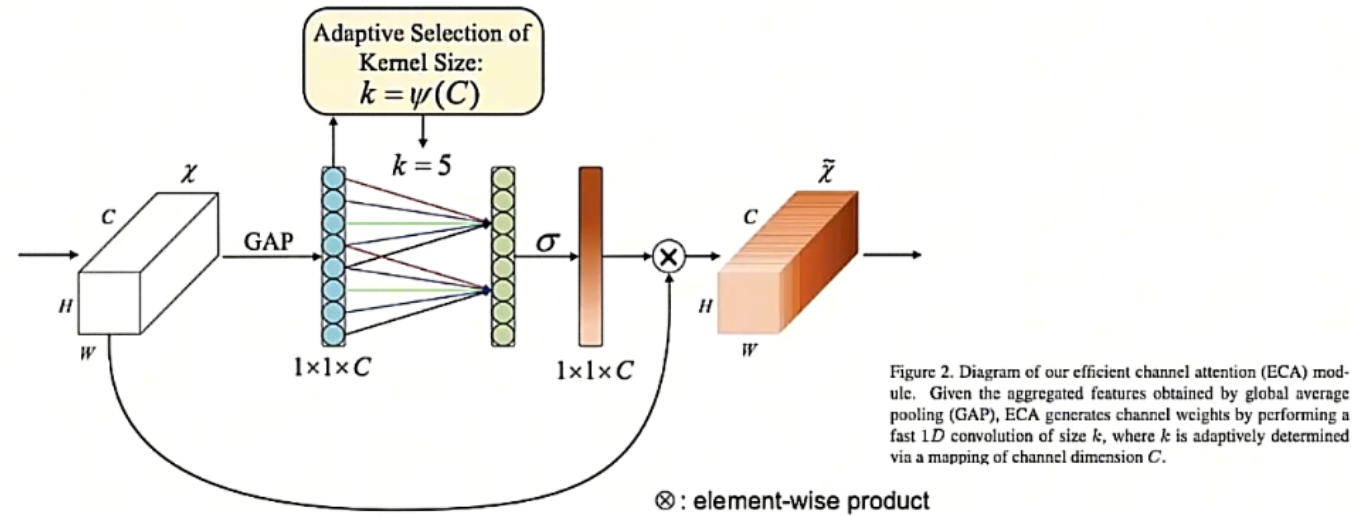
补知识)一维卷积运算
计算步骤
- 将卷积核在一维序列的长度维度上滑动;
- 每滑动到一个位置,计算核与对应局部序列的逐元素乘积和(内积);
- 所有位置的计算结果组成输出序列。
直观例子
假设输入序列为 [1, 2, 3, 4, 5](简化为C_in=1,L=5),卷积核为 [2, 1](K=2,C_out=1),步长 = 1,无填充 (Padding=0):
- 位置 1:
1×2 + 2×1 = 4 - 位置 2:
2×2 + 3×1 = 7 - 位置 3:
3×2 + 4×1 = 10 - 位置 4:
4×2 + 5×1 = 13 - 输出序列:
[4, 7, 10, 13](长度L_out = L - K + 1 = 5-2+1=4)。
二维卷积运算
计算步骤
- 将卷积核在特征图的高度和宽度两个维度上滑动;
- 每滑动到一个位置,计算核与对应局部空间区域的逐元素乘积和(内积);
- 所有空间位置的计算结果组成输出特征图,多输出通道则叠加多个核的结果。
直观例子
python
输入特征图 卷积核
[[1,2,3], [[1,0],
[4,5,6], [0,1]]
[7,8,9]]计算过程:
- 位置 (0,0):
1×1 + 2×0 + 4×0 +5×1 = 6 - 位置 (0,1):
2×1 + 3×0 +5×0 +6×1 = 8 - 位置 (1,0):
4×1 +5×0 +7×0 +8×1 = 12 - 位置 (1,1):
5×1 +6×0 +8×0 +9×1 = 14 - 输出特征图:
[[6,8],[12,14]](尺寸H_out=3-2+1=2,W_out=3-2+1=2)。
CA
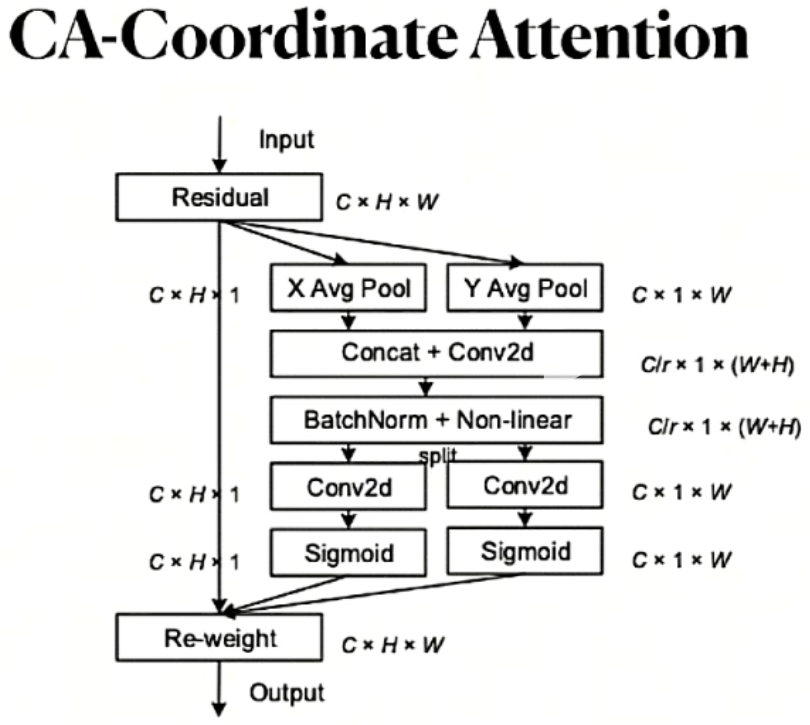
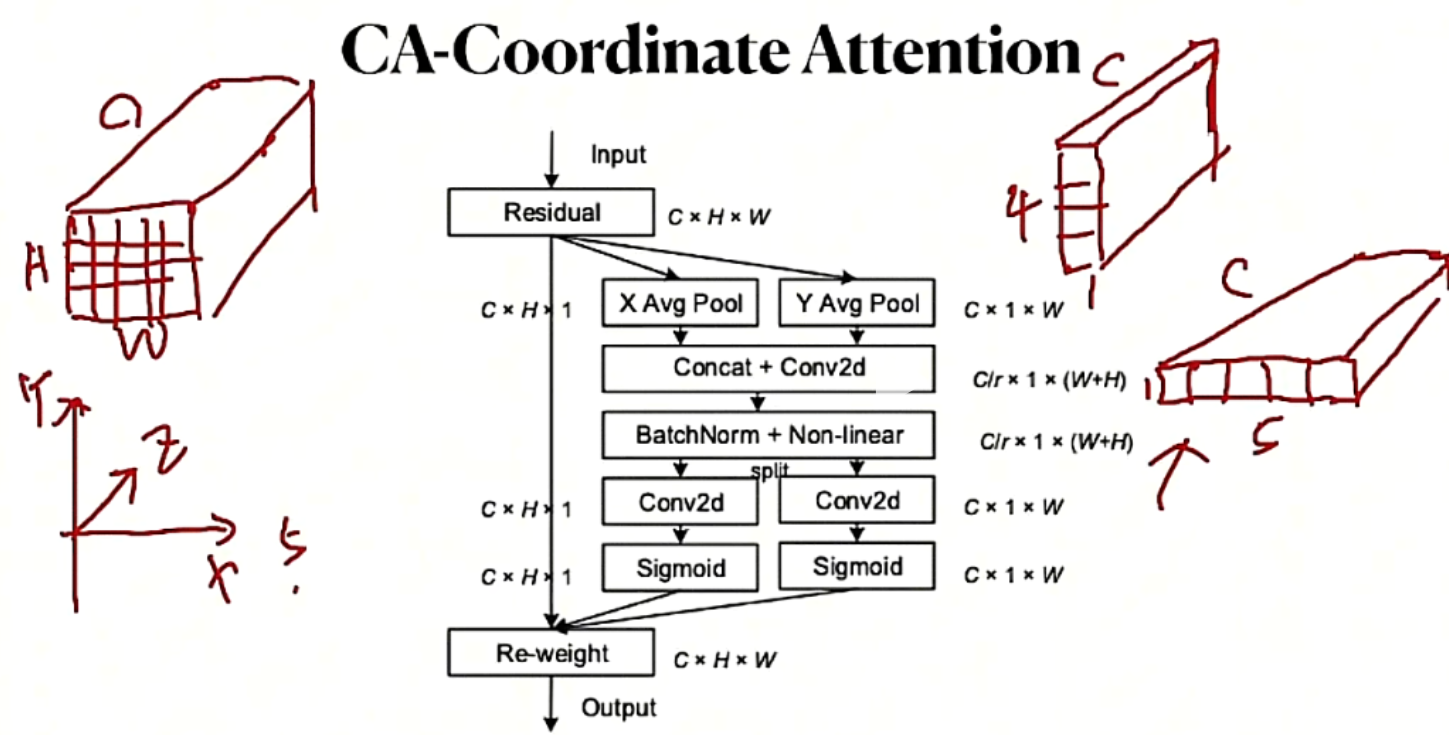
按xyz不同的方向切,计算分配权重
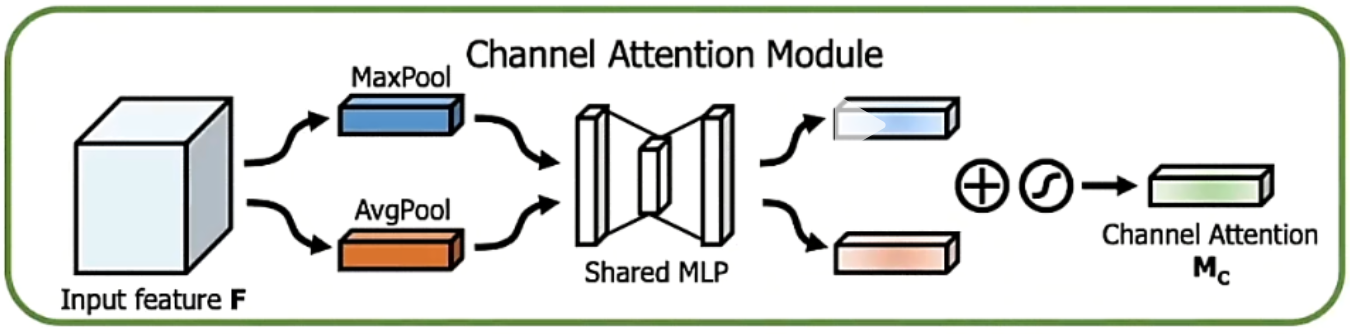
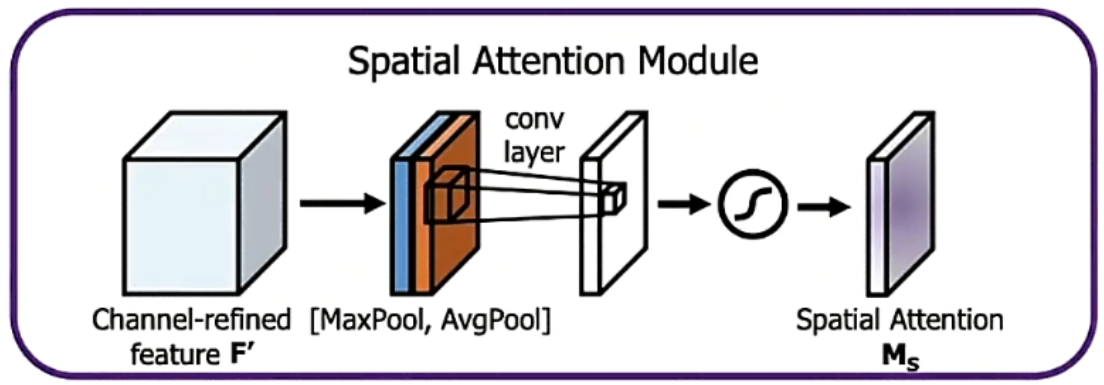
CBAM
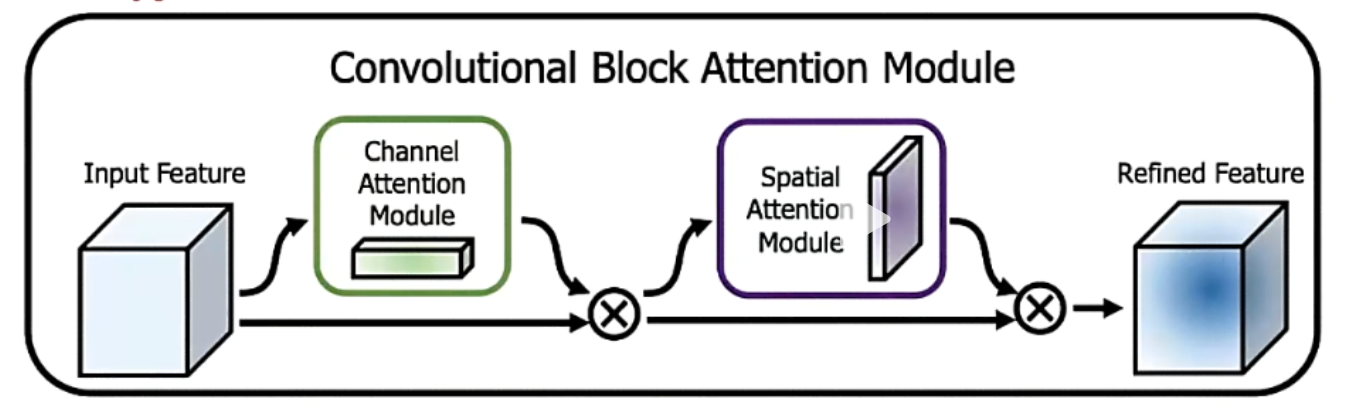
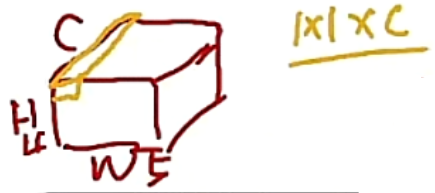
通道最优权重的分配
| 注意力机制 | 核心思想 | 实现方式 | 关注维度 |
|---|---|---|---|
| SENet(Squeeze-and-Excitation) | 通道重校准:学习通道间依赖关系,增强重要通道,抑制次要通道 | 全局平均池化→两个全连接层 (含降维)→Sigmoid→通道加权 | 仅通道维度 |
| ECA(Efficient Channel Attention) | 高效通道注意力:简化 SENet,避免降维损失,捕获局部跨通道交互 | 全局平均池化→一维卷积 (无降维)→Sigmoid→通道加权 | 仅通道维度 |
| CA(Coordinate Attention) | 将位置信息嵌入通道注意力,增强空间感知和定位能力 | 分别沿水平和垂直方向全局池化→特征编码→合并→Sigmoid→通道加权 | 通道 + 空间 (坐标) 维度 |
| CBAM(Convolutional Block Attention) | 双通道注意力:同时考虑通道和空间维度的重要性 | 通道注意力 (全局池化 + 全连接)→空间注意力 (7×7 卷积)→权重相乘 | 通道 + 空间维度 |
| 对比项 | SENet | ECA | CA | CBAM |
|---|---|---|---|---|
| 参数量 | 中等 (C×C/r×2) | 极小 (约 80) | 中等 (C×(H+W)) | 较高 (通道 + 空间两部分) |
| 计算复杂度 | O(C²) | O(C) | O(C(H+W)) | O(C²+H×W) |
| 实现难度 | ★★☆☆☆ 简单 | ★★☆☆☆ 简单 | ★★★☆☆ 中等 | ★★★☆☆ 中等 |
| 即插即用性 | ★★★★★ 优秀 | ★★★★★ 优秀 | ★★★★☆ 良好 | ★★★★☆ 良好 |
| 空间感知 | ❌ 无 | ❌ 无 | ✅ 有 (坐标编码) | ✅ 有 (专门空间模块) |
| 全局建模 | 有限 (仅通道) | 有限 (局部通道) | 强 (长距离依赖) | 强 (通道 + 空间) |
| 轻量化适配 | ★★★★☆ 良好 | ★★★★★ 优秀 | ★★★★★ 优秀 | ★★★☆☆ 一般 |
| 最适合场景 | ・图像分类 (如 ImageNet) ・通道特征丰富的任务 ・资源受限但需精度提升 | ・实时性要求高的任务 ・超轻量级模型・移动端应用 ・需保持低延迟的检测系统 | ・目标检测与定位・语义分割 ・小目标识别 ・移动设备视觉应用 | ・需精确空间定位的任务 ・复杂背景下的目标识别 ・高精度要求的分类 / 检测 ・学术研究 (效果稳定) |
代码实现
代码结构
python
class BlockName(nn.Module):
def _init_(self,channels: int,reduction: int = 16):
super()._init_()
"""
定义运算步骤中的小类运算
"""
def forward(self,x:torch.Tensor) -> torch.Tensor:
b,c,_,....
"""
forward确定函数的运算步骤
"""