一、背景
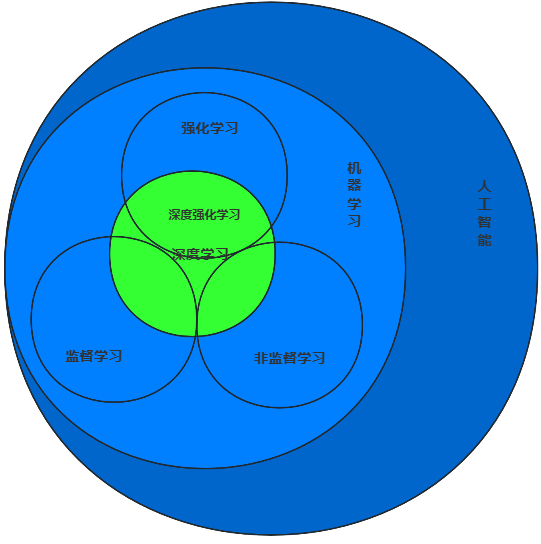
人工智能(AI)的核心是让机器像人一样思考学习,机器学习是AI的核心分支,负责让机器从数据中学规律、做预测决策;机器学习主要分监督、无监督、强化学习三类,深度学习是其重要分支,推动多个领域突破。
监督学习:用带明确标签(输入+对应输出)的数据训练模型,学输入到输出的映射关系。标注数据成本高、模型依赖数据质量、泛化新数据能力可能差。
无监督学习:无标签数据下,自动挖掘数据隐藏结构/模式。结果难解释、无客观评估标准、对数据分布敏感。
深度学习:靠多层神经网络自动学数据的低层到高层特征,提升预测/分类准确性。
强化学习:智能体在环境中试错学习,靠奖励信号找最优策略。
二、通俗的理解
你可以把机器学习想象成教一个外星人认识地球。它有强大的计算能力,但一无所知。我们有四种教法,对应四种学习方式。
2.1. 监督学习:手把手教,像老师带学生
我给你看大量 "带答案的习题集 " ,你去找规律,以后遇到新题就能自己做。
你想教外星人认猫和狗。
你给它看1万张照片,每张都贴上标签"这是猫"或"这是狗"。
外星人自己总结规律:哦,有胡须、脸圆、体型小的经常被叫"猫";脸长、爱吐舌头的常被叫"狗"。
以后你给它一张新照片,它就能猜出是猫是狗。
常用算法(老师的不同教具) :
线性回归: 教它根据"房屋面积"这个题,预测"房价"这个答案。它学会画一条最合适的直线来解题。
逻辑回归: 教它判断"这封邮件是不是垃圾邮件"。它算出一个概率,超过50%就认为是垃圾。
决策树: 教它判断"要不要出去玩"。它学会一连串问题:下雨吗?→是,不出去;→否,有朋友吗?→是,出去......像一棵判断树。
**支持向量机(SVM):**教它把"苹果"和"橙子"图片分开。它努力在两种图片之间划一条最宽的"楚河汉界"。
业界常用场景:
金融:给你消费记录,判断信用卡交易"是不是诈骗"。
医疗:给你化验单数据,预测"患某种病的风险"。
互联网:给你用户历史行为,预测他"会不会点击某个广告/购买某个商品"。
安防:人脸识别门禁、指纹识别解锁。
一句话总结:给数据打标签,让机器学会"对号入座"。
2.2 无监督学习:让机器自己探索,像考古学家
我给你一堆"没有答案的、杂乱的东西",你自己去发现里面有什么"内在结构或分组"。
你扔给外星人一堆"未分类的顾客购物小票",不说任何信息。
外星人自己分析后发现: "咦,这堆人总同时买"啤酒和尿布"(经典案例);那堆人总买"化妆品和裙子";还有一堆专买"奶粉和玩具"。"
它帮你把顾客分成了几个有相似特征的群组,但你得自己琢磨这些群组代表什么(比如"奶爸群体"、"时尚女性群体")。
常用算法(考古学家的不同工具) :
K-Means聚类:最简单粗暴的分组法。你告诉它想分成K组,它就把相似的数据点"抱团"在一起。
主成分分析(PCA):一种"数据瘦身术"。把一堆复杂相关的特征(比如身高、体重、鞋码),压缩成几个核心的"主成分",便于可视化分析。
关联规则(Apriori):专门发现"啤酒和尿布"这种**频繁一起出现**的组合。
业界常用场景:
市场营销:对客户进行"分群",实现精准营销。
推荐系统:发现"买了A商品的人,也常买B商品",进行"捆绑销售"或"交叉推荐"。
异常检测:在成千上万的服务器监控数据中,自动找出"行为异常"的那几台(可能被黑客攻击了)。
一句话总结:不给标签,让机器自己"物以类聚",发现隐藏模式。
2.3. 深度学习:给机器一个"超级大脑",自动学习
模仿人脑神经网络,建立一個多层的复杂模型。给它"海量数据",它能自己从底层(像素、笔画)到高层(物体、语义)"自动提取特征",特别擅长处理图像、声音、文字这类"非结构化数据"。
以前教外星人认猫,你得手工告诉它:看胡须、看圆脸。现在用深度学习,你只需要给它海量猫狗图片和标签。它的"深度大脑"会自己安排:第一层神经元学认"边和角";第二层学认"圆形、条纹";第三层学认"胡须、眼睛"......最后组合起来认出整只猫。整个过程,特征提取是机器自动完成的。
常用模型(不同的"大脑"结构):
卷积神经网络(CNN):"图像处理之王"。专用于识别图片、视频中的物体、人脸等。
循环神经网络(RNN/LSTM):"序列数据专家"。擅长处理有顺序的数据,比如**自然语言(理解一句话)、语音、时间序列预测(股票走势)。
生成对抗网络(GAN):"AI画家/伪造者"。能生成以假乱真的图片、视频,也用于数据增强。
业界常用场景:
计算机视觉:人脸支付、自动驾驶感知(识别行人车辆)、医学影像分析(看CT片)。
自然语言处理:智能客服、机器翻译、搜索引擎。
语音技术:智能音箱、语音输入法、语音合成。
一句话总结:用"深度神经网络"自动学习复杂特征,搞定图像、声音、语言等高级任务。
2.4. 强化学习:让机器在试错中成长,像训练宠物
设定一个"目标和游戏规则",让机器(智能体)在环境里"自己尝试",根据结果(奖励/惩罚)调整策略,目标是"最大化长期累积奖励"。教外星人下围棋。你不教具体每一步(那太复杂了)。你只设定规则:**赢棋=大奖,输棋=惩罚,占棋盘=小奖**。 外星人一开始乱下,但通过和自己下几百万盘,从输赢中总结经验,最终摸索出一套无敌策略。
常用算法:
深度Q网络(DQN):结合了深度学习和强化学习,让AI玩电子游戏超神。
策略梯度:更适用于连续动作空间,比如训练机器人走路。
业界常用场景:
游戏AI:AlphaGo、星际争霸AI。
机器人控制:让机器人自学走路、抓取物品。
自动驾驶:在模拟环境中学习超车、并道等复杂决策。
资源调度:数据中心节能降温、电网负荷分配。
一句话总结:设定奖惩,让机器在"游戏"中自己摸索成为高手。
2.5 简单关系总结
监督学习:【有答案】 预测/分类 -> "这是什么?"
无监督学习:【没答案】发现/分组 -> "这里面有什么规律?"
深度学习:实现以上两种学习的超级工具(尤其是监督),处理图像、语言等复杂数据。
强化学习:【试错】 -> 决策/优化 -> "我下一步该怎么办?"