1. Materialized Table 是什么?
Materialized Table 是 Flink SQL 引入的一种新表类型,目标是:
- 简化批处理与流处理的数据管道
- 统一开发体验(同一套 SQL 描述,按新鲜度自动决定跑流还是跑批)
- 把"刷新策略"变成表的属性,而不是散落在各种作业/调度系统里
创建时的关键要素只有两类:
- 数据新鲜度 Freshness:你希望物化表最多落后源表多久
- Query Definition:用一条 Flink SQL 查询定义物化结果
2. 四大核心概念
Materialized Table 由四个核心概念组成:
- Data Freshness(数据新鲜度)
- Refresh Mode(刷新模式:CONTINUOUS / FULL)
- Query Definition(查询定义:任意 Flink SQL Query)
- Schema(Schema:从 Query 自动推导,可声明 PK/分区)
下面重点讲前两个,因为它们决定作业形态与刷新频率。
3. Data Freshness:物化表的"时间目标"
3.1 新鲜度是什么?
数据新鲜度 定义:物化表内容允许 落后基础表更新的最大时间(目标值)。
注意:Freshness 不是强保证,而是 Flink 尽力达成的目标。
你可以把它理解为:"我希望这张物化表尽量在 X 时间内反映上游变化"。
3.2 Freshness 可选,默认值由刷新模式决定
创建物化表时 Freshness 是可选的,如果不指定,系统会按刷新模式使用默认值:
- CONTINUOUS 模式默认 :
materialized-table.default-freshness.continuous(默认 3 分钟) - FULL 模式默认 :
materialized-table.default-freshness.full(默认 1 小时)
4. Freshness 的两大作用
4.1 作用一:决定 Refresh Mode(连续 or 全量)
目前刷新模式有两种:
- CONTINUOUS :启动 Flink Streaming 作业,持续增量刷新
- FULL :由调度器定期触发 Flink Batch 作业,每次全量覆盖刷新
系统会根据 Freshness 推断模式,推断逻辑由配置项控制:
materialized-table.refresh-mode.freshness-threshold
同时你也可以显式指定 refresh mode ,一旦指定,将覆盖基于 Freshness 的推断。
4.2 作用二:决定 Refresh Frequency(刷新频率)
Freshness 会被转换为具体的"执行节奏":
- CONTINUOUS 模式 :Freshness → Streaming 作业的 checkpoint interval
- FULL 模式 :Freshness → 工作流调度周期(例如 cron 表达式)
这点非常关键:
你不再需要分别去设置 streaming 的 checkpoint 和 batch 的 cron,只要统一用 freshness 描述"我希望多新"。
5. Refresh Mode:两种刷新模式到底差在哪?
5.1 CONTINUOUS:持续增量刷新(Streaming Job)
-
Flink 会启动一个 流作业,增量更新物化表
-
数据可见性依赖于 Connector 行为:
- 可能是立即可见
- 也可能在 checkpoint 完成后才可见(更偏向一致性语义)
适用场景:实时/准实时看板、分钟级指标、近线特征表等。
5.2 FULL:周期性全量覆盖(Batch Job)
- 调度器会定期触发一个 批作业
- 每次执行会把 Query 结果 覆盖写入 物化表
- 刷新周期与工作流调度周期一致(Freshness → cron/周期)
适用场景:小时级/天级汇总、离线报表、成本敏感且不要求实时的结果表。
6. FULL 模式的覆盖策略:表级覆盖 vs 分区覆盖
FULL 模式默认覆盖行为是 表级覆盖(table-level overwrite)。
如果满足以下条件,则会变成 分区覆盖(by partition):
- 物化表声明了 partition fields
- 并且时间分区字段配置了格式:
partition.fields.#.date-formatter
此时每次刷新将只覆盖 最新分区,而不是整表重算全覆盖。
这对大表非常重要:
- 表级覆盖:简单但成本高
- 分区覆盖:更经济,适合按天/小时分区的汇总类物化表
7. Query Definition:用 SQL 定义物化内容
物化表的 Query Definition 支持所有 Flink SQL Queries。物化表的数据就是 Query 的结果。
- CONTINUOUS:Query 结果持续更新到物化表
- FULL:每次执行用 Query 结果覆盖写入物化表
一句话总结:
Query 决定"算什么",Freshness/Mode 决定"怎么刷"。
8. Schema:自动推导,但你仍能声明主键/分区
Materialized Table 的 Schema 规则:
-
列名与类型由 Query 自动推导
-
用户不能手动指定列定义(避免你定义的 schema 与 query 输出不一致)
-
但可以像普通表一样声明:
- Primary Key
- Partition Keys
这也意味着:
- 你只要保证 Query 输出正确,Schema 就稳定可控
- 同时又能通过 PK/分区让下游存储与覆盖策略更可落地
9. 一个"落地心智模型"
你可以用下面这张"脑内流程图"理解 Materialized Table:
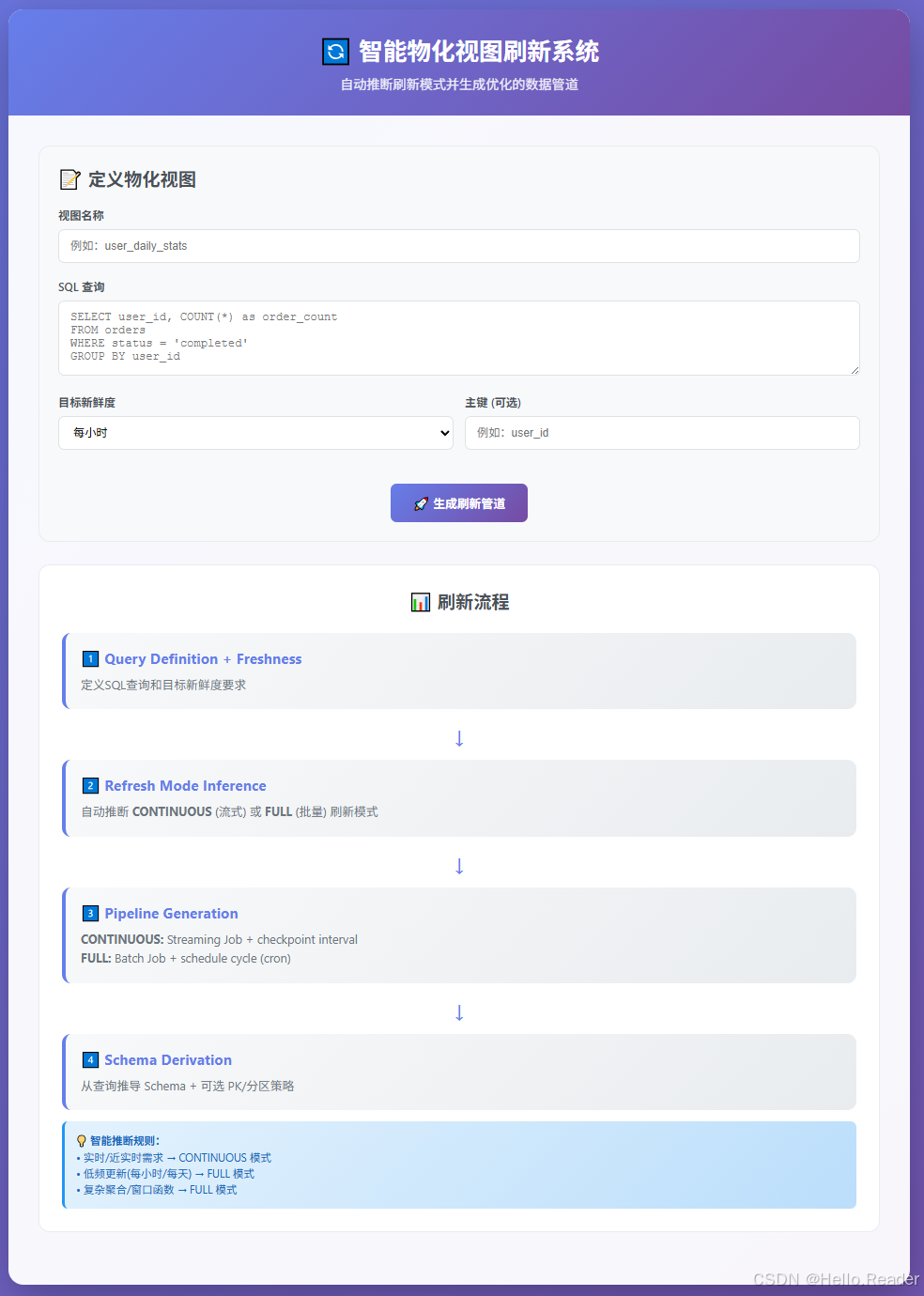
10. 实战建议与踩坑点
10.1 什么时候用 CONTINUOUS?
- 你要分钟级甚至更快
- 你希望增量更新、低延迟
- 你能接受"可见性可能在 checkpoint 后"的语义差异(取决于 connector)
10.2 什么时候用 FULL?
- 你更关心成本与稳定性
- 你可以接受小时级/天级延迟
- 你希望每次结果可解释、便于审计(全量覆盖更直观)
10.3 FULL 模式强烈建议做分区覆盖
如果你的结果天然按时间组织(天/小时),优先:
- 声明 partition fields
- 配好
partition.fields.#.date-formatter
否则表级覆盖在数据量上来后会非常"贵"。
10.4 Freshness 是"目标",不是"承诺"
Freshness 不是 SLA。影响是否能达成的因素很多:
- 上游延迟、反压
- checkpoint 时间
- sink 写入吞吐
- scheduler 的触发抖动(FULL)
所以在设计时要留 buffer,不要把 Freshness 当绝对保证。