你是否一直对前端性能监控系统的底层原理充满好奇?
想知道那些 FCP、LCP、FID 指标是如何被精准捕获的?
页面卡顿、资源加载缓慢、API 请求耗时过长,这些隐形杀手是如何被 SDK 揪出来的?
与其只做工具的使用者,不如深入底层,探寻背后的实现机制。
本文将从原理角度切入,手把手带你设计并实现一个轻量级、功能完备的性能监控 SDK。
读完这篇,你将收获什么?
通过手写这个 SDK,你不仅能获得一个可用的性能监控工具,更能深入掌握以下核心知识点:
-
浏览器性能底层 API :别光听过没用过!带你彻底搞懂
PerformanceObserver到底怎么用,把Resource Timing、Event Timing这些原生 API 玩出花来,不用重轮子也能精准抓数据。 -
指标体系全覆盖:用户觉得卡,到底卡在哪?是从白屏到出内容的 FCP/LCP?还是图片加载太慢?或者是点击按钮没反应?不管是网络请求慢,还是 JS 任务太长,咱们这次一次性全搞定,给体验做个体检。
-
SDK 架构设计实战:SDK 怎么写才不乱?采集归采集,上报归上报,配置还要灵活。带你设计一个插件化的架构,想加功能随时加,代码干净又好维护。
-
轻量级黑科技封装 :利用简单的 JS
闭包与Proxy,实现同步/异步函数的精准耗时测量。
指标扫盲:别被指标缩写吓跑了
在开始撸代码之前,咱们先灵魂拷问一下:到底啥叫"性能好"?
虽说 Google 搞了一套 Core Web Vitals 标准,web-vitals 库可以直接用,但这次咱们 偏不 。为啥要自讨苦吃手写 SDK?
- 原生掌控 :我们要利用浏览器原生 API ,亲手把快不快、卡不卡、稳不稳这三个维度的"真凶"抓出来。
- 兼容性黑洞 : Web Vitals 的很多高级指标(如 LCP、CLS)在 Firefox 或 Safari 的旧版本上并不完全支持。手写 SDK 让我们能灵活处理这些兼容性差异,做到"能监控的监控,不能监控的静默",而不是直接报错。
1. Loading (加载):别让我等太久!
用户最怕面对一片白屏。这个阶段我们关注三个瞬间:
- FP (First Paint) ------ "屏幕亮了"
- 啥意思:浏览器开始渲染任何东西的时刻(哪怕只是背景色)。
- 场景:你打开一个页面,屏幕从纯白变成浅灰色,虽然啥内容都没有,但你知道"它活着"。
- FCP (First Contentful Paint) ------ "看到东西了"
- 啥意思:浏览器渲染出第一个内容(文字、图片、Logo)的时刻。
- 场景:页面上出现了一个"Loading..."的文字或者导航栏的 Logo。这时候你会稍微安心一点,愿意再等两秒。
- LCP (Largest Contentful Paint) ------ "主角登场了"
- 啥意思:视口内可见的最大图片或文本块渲染完成的时刻。这是 Google 最看重的加载指标。
- 场景:你打开淘宝详情页,标题和价格都出来了,但那张最大的商品主图过了 5 秒才刷出来。这 5 秒内你根本不想买,因为你没看到货。LCP 就是衡量这个"主图"多久出来的。
- 及格线:2.5 秒内算优秀,超过 4 秒就是"慢得离谱"。
2. Interaction (交互):别卡得像 PPT!
东西加载出来了,用户开始点了,这时候最怕卡顿。
-
FID (First Input Delay) ------ "第一下没反应?"
- 啥意思:用户第一次与页面交互(点击按钮、链接)到浏览器真正开始处理这个事件的时间差。
- 场景:你看到页面加载完了,兴奋地去点"登录"按钮,结果点了没反应,过了 1 秒钟按钮才变色。这种"按下去没感觉"的延迟,就是 FID。
-
INP (Interaction to Next Paint) ------ "越用越卡?"
- 啥意思:FID 的升级版。它不仅看第一下,还看你浏览全程中所有交互的延迟,取最慢的那几次。
- 场景:你在填写一个长表单,每输入一个字,输入框都要卡顿一下才能显示出来。这种持续的"粘滞感",会让 INP 分数暴跌。
-
Long Task (长任务) ------ "谁在堵路?"
-
啥意思:任何执行时间超过 50ms 的 JavaScript 任务。
-
场景 :主线程就像一条单行道。如果前面有一辆大卡车(复杂的 JS 计算)走了 200ms,后面的小轿车(点击事件响应)就只能排队等着。我们要做的,就是把大卡车拆成一支灵活的小车队,每辆车之间留出空隙,让紧急车辆(用户交互)能随时插队通过。
-
注 :长任务不光交互期会出现,加载时也常见;它会让白屏更久、把
TBT(总阻塞时间)拉高。我们归到"交互"里讲,是因为它最直接拖慢的是点击/输入的响应(FID、INP)。
-
3. Visual Stability (视觉稳定性):别乱动!
这可能是最让人抓狂的体验。
- CLS (Cumulative Layout Shift) ------ "手滑点错了!"
- 啥意思:页面布局在加载过程中发生意外移动的程度。
- 场景:你正准备点"取消订单",突然顶部加载出来一张广告图,把整个页面往下挤了 50 像素,结果你的手指正好点在了"立即支付"上......这种布局的意外位移,就叫 CLS。分数越低,页面越稳。
系统架构与功能设计
为了保证 SDK 的轻量性与可扩展性,我们采用了分层架构设计 。整个系统由 核心采集层 、数据处理层 、数据上报层 和 配置中心 四大模块组成,并通过统一的 PerformanceMonitor 类进行调度。
*简单说,就是把活儿分得明明白白:采集模块只管抓数据,处理模块只管处理数据,上报只管发送数据到服务端,配置只管配置*
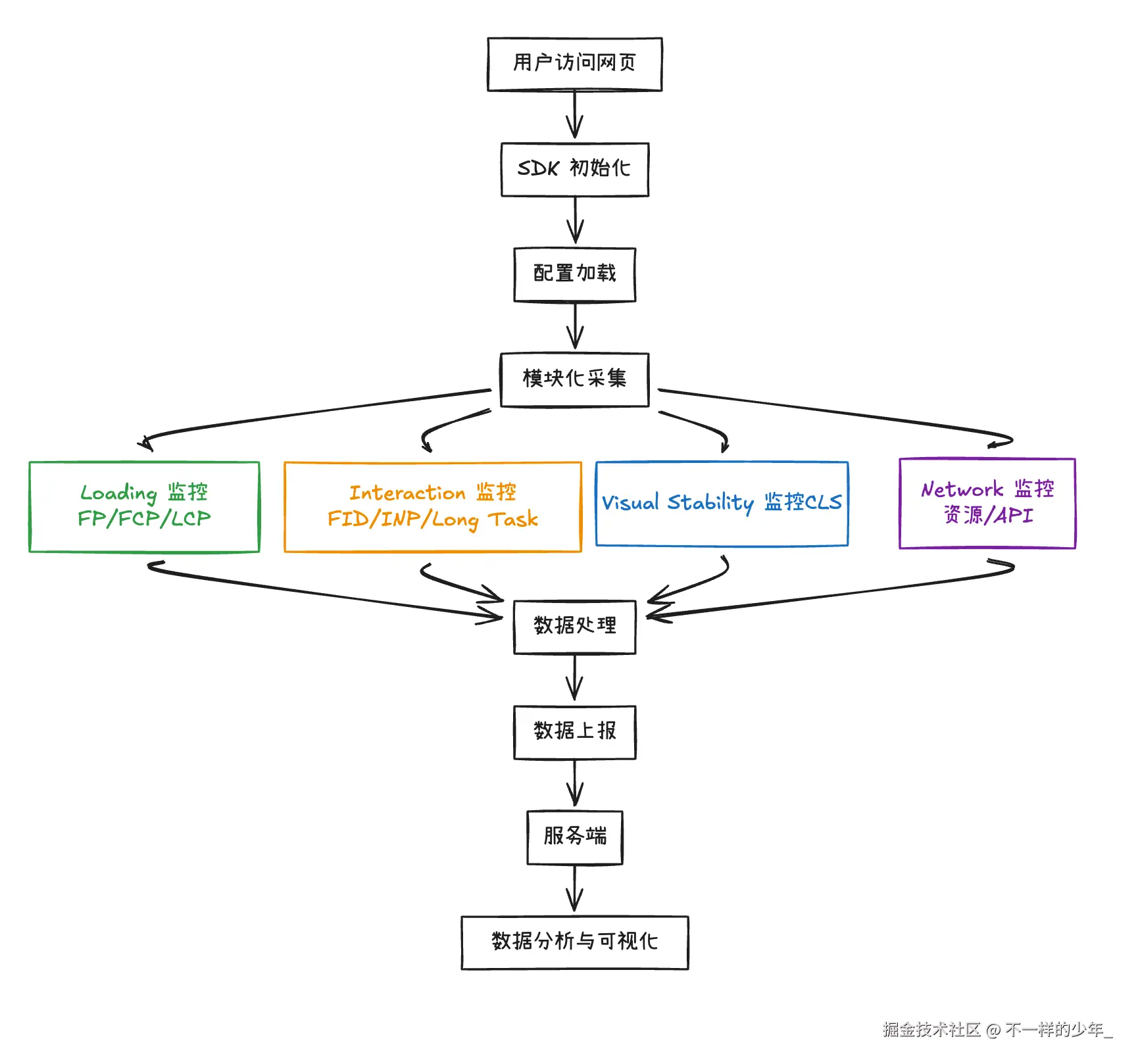
1. 核心采集层 (Collectors) ------ 用户体验三步走
这是 SDK 的心脏。咱们不按技术分类,按用户实际感受 来分(这也是为什么我们的源码目录叫 loading、interaction、network):
-
Step 1: Loading (看得见吗?) ------
src/loading- 核心目标:紧盯白屏时间与关键内容渲染。
- 实现手段 :利用
Paint Timing与Largest Contentful PaintAPI,捕获 FP、FCP、LCP 及页面加载完成时机。
-
Step 2: Interaction & Visual Stability (好用且稳吗?) ------
src/interaction- 核心目标 :同时监控 交互响应速度 与 页面视觉稳定性。
- 实现手段 :
- 交互 :通过
Event Timing监听点击/滚动延迟(FID/INP),并用Long TaskAPI 揪出主线程阻塞元凶。 - 稳定性 :结合
Layout ShiftAPI 计算布局偏移(CLS),防止页面"乱动"。
- 交互 :通过
-
Step 3: Network (为啥慢?) ------
src/network- 核心目标:定位资源加载与接口响应的瓶颈。
- 实现手段 :复用
Resource Timing接口,深度解析静态资源与 XHR/Fetch 请求的 DNS、TCP、TTFB 等关键耗时。
2. 数据处理层 (Processor) ------ 数据清洗工
- 洗数据:浏览器原生的 API 给的数据太杂太乱,咱们得把它洗成干净统一的 JSON 格式,方便后端存。
- 加料 :光知道卡了没用,还得知道哪儿卡了。比如 LCP 慢,我们会自动把那个慢元素的 DOM 选择器加上;长任务卡,我们会尝试解析出是哪个脚本干的。
3. 数据上报层 (Reporter) ------ 快递员
- 使命必达 :用户都要关页面了,数据还没发出去?这时候就得用
Navigator.sendBeacon,它能保证在页面卸载时,数据也能稳稳地发给服务器。 - 省流模式:平时不重要的日志先攒一攒(批量上报),关键的报错立刻发(实时上报),给用户的流量省点钱。
4. 配置中心 (Configurator) ------ 遥控器
- 随心所欲 :通过
options参数控制。开发环境想看日志?开!生产环境只报错误?关!采样率设多少?你说了算。
核心代码实现
主入口 (index.ts)
入口文件负责对外暴露初始化方法,串联各个模块。
-
职责明确 :
init()方法一键启动所有监控,按用户体验生命周期(加载 -> 交互 -> 网络)依次调用。 -
配置中心 :构造函数接收
options,实现配置合并(如开发模式开启日志)。 -
模块解耦 :不直接写监控逻辑,而是通过
import引入loading/interaction/network三大模块的startXXX函数,各司其职。 -
示例代码:
javascript
import { startFP, startFCP, startLCP, startLoad } from './loading';
import {
startCLS,
startFID,
startInteraction,
startLongTask,
} from './interaction';
import { startEntries, startRequest } from './network';
export default class PerformanceMonitor {
constructor(options = {}) {
this.options = {
log: true, // 开发模式下开启日志
...options,
};
}
init() {
// 1. 页面加载与渲染 (Loading & Rendering)
startFP();
startFCP();
startLCP();
startLoad();
// 2. 交互响应 (Interaction)
startFID();
startInteraction(); // INP
startLongTask();
// 3. 视觉稳定性 (Visual Stability)
startCLS();
// 4. 资源与网络 (Resource & Network)
startEntries();
startRequest();
console.log('Performance Monitor Initialized');
}
}2. Loading 监控 (loading/index.js)
这部分主要负责捕捉页面从白屏到内容出现的关键时刻。我们把这个过程拆解为三个关键动作:变色 (FP) -> 有内容 (FCP) -> 主角登场 (LCP)。
- FP (First Paint):屏幕变色了(不白屏了)。
- FCP (First Contentful Paint):看见字或图了(有内容了)。
- LCP (Largest Contentful Paint):主角(大图/正文)出来了。
- Load:资源全加载完了。
(1) FP & FCP:屏幕终于亮了
先讲道理:
- 为什么要一起抓这两个指标是一起抓的? 因为它俩在浏览器眼里都属于
paint(绘制)类型,都是"第一眼"的感觉。 - 怎么抓? 用
PerformanceObserver蹲守。 - 避坑指南(Buffered 标志): 这是一个极其容易被忽略的参数!
- SDK 初始化往往比页面渲染晚。
- 如果你不开启
buffered: true,就像你 10 点才去蹲守 9 点的日出,永远蹲不到。 - 开启后,浏览器会把过去发生过的指标打包补发给你。
代码实战:
javascript
// src/loading/FP.js (FCP 逻辑完全一致,只需改 entry.name)
export function startFP() {
const entryHandler = (list) => {
for (const entry of list.getEntries()) {
// 筛选 'first-paint'
if (entry.name === 'first-paint') {
observer.disconnect(); // FP 一辈子只发生一次,抓到就撤,省内存
const json = entry.toJSON();
console.log('FP Captured:', json);
// 上报数据结构
const reportData = {
...json,
type: 'performance',
name: entry.name,
pageUrl: window.location.href,
};
}
}
};
// 1. 创建观测者
const observer = new PerformanceObserver(entryHandler);
// 2. 开始蹲守 'paint' 频道
// buffered: true 是关键,确保能拿到 SDK 初始化之前的记录
observer.observe({ type: 'paint', buffered: true });
// 3. 返回清理函数
return () => observer.disconnect();
}(2) LCP:主角登场
先讲道理:
-
为什么 LCP 会变? 浏览器渲染是渐进式的。它刚画了一行字,觉得是 LCP;过了一会图片加载出来,它又觉得图片是 LCP。所以 LCP 可能会触发多次,我们通常取最后一次。
-
光有时间够吗? 不够!老板问你"为什么 LCP 慢",你不能光说"慢了",你得告诉他是哪张图 慢了。所以我们需要记录
element并转成选择器。
代码实战:
javascript
// src/loading/LCP.js
import { getElementSelector } from '../../util/index';
export function startLCP() {
const entryHandler = (list) => {
for (const entry of list.getEntries()) {
const json = entry.toJSON();
const reportData = {
...json,
lcpTime: entry.startTime, // 记录时间
// 核心:利用 element 属性计算出 CSS 选择器,帮你定位是哪个元素慢
elementSelector: getElementSelector(entry.element),
type: 'performance',
name: entry.name,
pageUrl: window.location.href,
};
console.log('LCP Update:', reportData);
}
};
const observer = new PerformanceObserver(entryHandler);
// 同样开启 buffered,防止漏掉
observer.observe({ type: 'largest-contentful-paint', buffered: true });
return () => observer.disconnect();
}(3) 加载完成
先讲道理:
- 为什么不用
window.onload? 现在的 SPA(单页应用)和浏览器的"往返缓存"(BFCache)机制,让onload变得不那么靠谱(有时候回退页面不会触发 onload)。 - 为什么用
pageshow? 它能覆盖更多场景,无论你是新打开的,还是后退回来的,它都会触发。 - 为什么套一层
requestAnimationFrame?pageshow触发时,浏览器可能还在忙着处理最后的渲染。我们用rAF往后稍一稍,让主线程先喘口气,获取的时间更精准,也不影响页面交互。
代码实战:
javascript
// src/loading/load.js
export function startLoad() {
const onPageShow = (event) => {
// 往后推一帧,避免抢占主线程
requestAnimationFrame(() => {
['load'].forEach((type) => {
const reportData = {
type: 'performance',
subType: type,
pageUrl: window.location.href,
// 计算相对时间
startTime: performance.now() - event.timeStamp,
};
console.log('Load Captured:', reportData);
});
});
};
window.addEventListener('pageshow', onPageShow, true);
return () => {
window.removeEventListener('pageshow', onPageShow, true);
};
}3. Interaction 监控
交互性能直接决定了用户觉得你的页面"顺不顺手"。这里我们重点关注 FID/INP (响应速度) 和 Long Task (主线程阻塞)。
(1) FID & INP:点击要灵敏
先认个脸:
-
FID (First Input Delay) :首次输入延迟。看的是"第一印象"。用户刚进页面,第一次点按钮或者链接时,浏览器是不是在发呆?延迟了多久才理你?
-
INP (Interaction to Next Paint) :交互到下一次绘制。看的是"全程表现"。不管你是刚来还是快走,只要在页面上点的任何一下卡了,INP 都会记下来,最后取最慢的那几次算总账。
三句话讲明白
- 相亲 vs 过日子:FID 就像相亲,只要第一眼(第一次交互)没问题,后面拉胯它也不管;INP 就像过日子,日久见人心,它会盯着你全程的每一次表现,哪怕你前面表现再好,最后一下卡了,分也高不了。
- 只管排队 vs 全程跟踪:FID 只管"排队时间"(你点下去到浏览器开始处理的时间);INP 管得更宽,它包括"排队 + 处理 + 渲染"的全过程。所以 INP 更能代表用户的真实感受。
- 谁在堵路:想象你去餐厅吃饭(点击),服务员(主线程)正忙着给隔壁桌上菜(执行 JS),没空理你。你等服务员转过身来理你的这段时间,就是 FID。如果服务员理你了,但做菜慢(处理逻辑复杂),上菜也慢(渲染慢),这整个过程太久,INP 就会炸。
直接上代码:FID
javascript
// src/interaction/FID.js
export function startFID() {
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
// 核心公式:处理开始时间 - 点击时间 = 延迟时间
const delay = entry.processingStart - entry.startTime;
console.log('FID:', delay, entry.target);
observer.disconnect(); // FID 只看第一下,拿到就撤
}
});
observer.observe({ type: 'first-input', buffered: true });
}代码怎么理解?
processingStart - startTime:startTime是你手指按下的瞬间,processingStart是代码终于开始跑的瞬间。这中间的差值,就是浏览器因为"忙不过来"而让用户等待的时间。disconnect():FID 全称是 First Input Delay,既然是 First,抓到一次就可以收工了,省点内存。buffered: true:防止 SDK 加载晚了。万一用户手快,脚本还没加载完就点了,这个参数能把那次点击记录补发给你。
直接上代码 INP:
javascript
// src/interaction/INP.js
export function startINP() {
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
// 不断收集,因为我们要找最慢的那个
// 这里只是简单的打印,实际开发中需要一个算法来取 top 几位
console.log('Interaction Latency:', entry.duration, entry.target);
}
});
// 注意:INP 监听的是 'event' 类型,不是 'first-input'
observer.observe({ type: 'event', durationThreshold: 16, buffered: true });
}代码怎么理解?
- INP 代码 :
type: 'event'。这里我们不断监听,不断打 log。实际场景里,你需要维护一个数组,把耗时最长的几次交互存下来,最后上报那个最慢的。 - durationThreshold: 16:这是个优化参数。意思是"小于 16ms(一帧)的交互我就不看了",省得数据太多刷屏。
踩坑提醒
-
及格线在哪?(Google 标准)
- FID (第一印象) :100ms 100ms 以内都是优秀,超过 300ms 用户就会觉得"破网站怎么点不动"。
- INP (全程体验) :200ms 以内算优秀,超过 500ms 用户就想砸键盘了。
为啥 FID 和 INP 的标准不一样?
- 因为 FID 只算排队时间 (你还在门口等服务员),而 INP 算的是全套服务时间(排队 + 吃饭 + 买单)。INP 包含的阶段更多(处理 + 渲染),所以 Google 给的宽容度自然也更高。
-
INP 才是未来 :Google 已经在 2024 年正式用 INP 取代了 FID。想监控 INP?把
type改成event,然后别断开 (disconnect),一直记到页面走人就行。 -
谁在堵路:通常是因为主线程在忙着执行巨大的 JS 脚本(Long Task),导致没空搭理用户的点击。
(2) Long Task:主线程别堵车
先认个脸:
- Long Task (长任务) :只要执行时间超过 50 毫秒 的任务,都叫长任务。
- 危害:浏览器的主线程是"单线程"的,一次只能干一件事。如果一个任务霸占了主线程太久,其他的点击、滚动、渲染就都得排队,用户就会觉得"卡死"了。
三句话讲明白
- 独木桥效应:主线程就像一座独木桥。平时过的小车(短任务)很快,大家都有路走。突然来了一辆大卡车(长任务),把桥堵得死死的,后面的车(用户交互)全被堵住了。
- 50ms 分界线 :为啥是 50ms?
- 100ms 法则 :心理学上,用户点击后 100ms 内有反应就算"即时"。
- 对半分 :Google 把这 100ms 切成两半:50ms 给你跑代码 ,50ms 留给浏览器画画。这样加起来刚好 100ms。
- 高刷屏怎么办:虽然 120Hz 屏幕每帧只有 8ms,但在 Web 标准里,50ms 依然是那个平衡了"体验"和"代码复杂度"的安全及格线。
- 抓元凶:监控 Long Task 不光是为了知道"卡了",更是为了知道"谁卡了"。API 会告诉你是因为哪个 iframe 或者哪个脚本文件导致的。
直接上代码:
javascript
// src/interaction/longTask.js
export function startLongTask() {
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
if (entry.duration > 50) {
// 抓到个慢的!看看是谁
// attribution 里面藏着"罪魁祸首"的名字
console.log('LongTask:', entry.duration, entry.attribution);
}
}
});
// 开启监听,buffered 同样重要
observer.observe({ type: 'longtask', buffered: true });
}代码怎么理解?
entry.duration > 50:虽然 API 只会返回长任务,但为了保险(或者你想设置更严格的 100ms 阈值),可以再判断一下。entry.attribution:这是个数组,里面会告诉你这个任务来自哪个container(比如是当前窗口,还是广告 iframe),有的浏览器还能精确到scriptURL(脚本文件路径)。
踩坑提醒
- 拆分任务 :遇到 Long Task 咋办?拆! 把一个大函数拆成几个小函数,用
setTimeout或者requestIdleCallback分批执行,给主线程留出喘息的机会(让"大卡车"变成"小车队")。 - 广告背锅:很多时候你会发现 Long Task 都是广告脚本(iframe)带来的。这种时候......你可以甩锅给广告商,或者延迟加载广告。
- 兼容性:这个 API 兼容性还不错,但还是老规矩,Safari 可能比较高冷(较新版本才支持)。
4. Visual Stability (视觉稳定性) 监控
这可能是最让人抓狂的体验。
CLS:页面别乱动
- 别冤枉好人:用户点了个按钮展开菜单,布局肯定会变,这叫"符合预期"
- 聚沙成塔:CLS 不是一次性的,它是"积分制"。用户在页面上待多久,这期间所有的小抖动都要加起来,算总账。
- 秋后算账:千万别抖一下报一下!CLS 是"长跑比赛",不到终点(页面关闭/隐藏)不知道最终成绩。必须等用户关页面或者切后台的时候,把最后的总分一次性报上去。
javascript
// src/interaction/CLS.js
export function startCLS() {
let clsValue = 0;
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
// 核心:剔除用户交互(点击/输入)导致的预期偏移
if (!entry.hadRecentInput) {
clsValue += entry.value;
}
}
});
observer.observe({ type: 'layout-shift', buffered: true });
const report = () => console.log('CLS Final:', clsValue);
// 双重保险:兼容各类浏览器的卸载场景
window.addEventListener('pagehide', report, { once: true });
document.addEventListener(
'visibilitychange',
() => {
if (document.visibilityState === 'hidden') report();
},
{ once: true }
);
}代码怎么理解?
-
怎么区分是"好动"还是"乱动"?
刚刚我们说用户交互(比如点按钮展开菜单)导致的布局变化不能算 CLS。那怎么判断呢? 浏览器提供了
hadRecentInput字段。只要用户最近 500ms 内有过点击或按键,浏览器就会把这个字段标为true。咱们代码里必须把这些"良民"过滤掉,只抓那些"莫名其妙"的抖动。 -
分数怎么算?
entry.value就是每一次抖动的分数。比如一张大图突然插进来,把文字挤下去 100px,可能就贡献了 0.05 分。我们要做的就是一个无情的"加法器",把这些分数全加起来。 -
为啥要监听两个卸载事件?
visibilitychange和pagehide都是用来监听页面关闭/隐藏的。为啥要搞两个?因为浏览器脾气不一样:有的喜欢pagehide(比如 Safari),有的推荐visibilitychange。为了保证数据不丢,咱们搞个"双保险",谁先触发就算谁的。- 为啥不用 beforeunload? 早年间确实流行用
beforeunload或unload,但现在它们不靠谱 了,尤其是在手机上。用户直接划掉 App、切后台,这些事件经常不会触发 。而且它还会阻止浏览器做"往返缓存"(BFCache),拖慢页面后退速度。所以现在的标准姿势就是visibilitychange+pagehide。
- 为啥不用 beforeunload? 早年间确实流行用
踩坑提醒
- 成绩线:CLS < 0.1 很好,> 0.25 需要重点优化
- 动态内容要"留坑位":骨架屏/固定尺寸,能明显降低位移
- 广告/懒加载图片经常是元凶,优先排查
5. Network 监控:查查谁在拖后腿
先认个脸:
- Resource Timing (资源计时):专门管资源加载的。不管是图片、CSS、JS 文件,还是接口请求 (XHR/Fetch),只要是从网络下载的东西,它都能记一笔。
- 核心指标 :除了总耗时 (
duration),还能细到 DNS 解析多久、TCP 建连多久、首字节时间 (TTFB) 等等。
三句话讲明白
- 查快递:你买东西(请求资源),想知道为什么这么慢?是卖家发货慢(TTFB),还是路上堵车(下载慢)?Resource Timing 就是那个详细的物流单。
- 不只是图片 :别被名字骗了,它不光管图片 CSS,你的
fetch请求、axios请求,只要走了网络,它都能监控到。 - 严防死守:浏览器为了安全,对于跨域的资源(比如你用了百度的图片),默认只告诉你"用了多久",不告诉你"怎么用的"(DNS/TCP 细节),除非对方给了通行证。
直接上代码:
javascript
export function startEntries() {
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
// resource 类型包含了 img, script, css, fetch, xmlhttprequest, link 等
if (entry.entryType === 'resource') {
console.log(
'Resource:',
entry.name,
entry.initiatorType,
entry.duration
);
}
}
});
// 同样记得 buffered: true,防止漏掉页面刚开始加载的那些资源
observer.observe({ type: 'resource', buffered: true });
}代码怎么理解?
entryType === 'resource':这个频道包罗万象。图片 (img)、样式 (css)、脚本 (script) 甚至你的接口调用 (fetch/xmlhttprequest) 都在这儿。initiatorType:这个字段告诉你资源是谁发起的。是<img src="...">发起的?还是fetch()发起的?一看便知。
进阶用法:监控接口 (API) 耗时详情
有时候我们不关心图片资源,而是重点关注后端接口的响应耗时 。通过过滤 fetch 和 xmlhttprequest,我们不仅能知道接口慢不慢,还能知道慢在哪里(是 DNS、TCP 还是服务端处理)。
javascript
export function startRequest() {
const entryHandler = (list) => {
const data = list.getEntries();
for (const entry of data) {
// 过滤出 API 请求 (Fetch 和 XHR)
if (
entry.initiatorType === 'fetch' ||
entry.initiatorType === 'xmlhttprequest'
) {
const reportData = {
name: entry.name, // 请求地址
type: 'performance',
subType: entry.entryType,
sourceType: entry.initiatorType,
duration: entry.duration, // 请求总耗时
dns: entry.domainLookupEnd - entry.domainLookupStart, // DNS 解析耗时
tcp: entry.connectEnd - entry.connectStart, // TCP 连接耗时
ttfb: entry.responseStart - entry.requestStart, // 首字节响应时间 (服务端处理时间)
transferSize: entry.transferSize, // 传输字节数
startTime: entry.startTime, // 请求开始时间
pageUrl: window.location.href,
};
console.log('Network Request:', reportData);
}
}
};
// 这里不调用 disconnect(),以便持续监听后续产生的网络请求
const observer = new PerformanceObserver(entryHandler);
observer.observe({ type: 'resource', buffered: true });
}代码怎么理解?
-
TTFB (首字节时间) ------ "厨师做菜慢"
- 公式:
responseStart - requestStart。 - 大白话:你点完菜(发送请求)到服务员端上第一盘菜(收到第一个字节)的时间。
- 谁背锅 :这时间长,说明后端处理慢(查数据库慢、业务逻辑太复杂)。跟网速没啥关系,纯粹是"后厨"忙不过来。赶紧截图甩给后端开发!
- 公式:
-
TCP & DNS ------ "找路和打招呼"
- DNS :就像查电话本。要把
api.example.com变成 IP 地址。如果这块慢,说明用户离你的服务器太远,该上 CDN 了。 - TCP:就像见面握手。客户端和服务器得先"握手"建立连接才能说话。如果是 HTTPS,还得再加一轮 SSL 握手(查身份证)。这一套下来也得耗不少时间。
- DNS :就像查电话本。要把
-
TransferSize (传输大小) ------ "运货量"
- 大白话:接口到底吐了多少数据给你?
- 场景 :有时候接口慢,不是因为后端慢,而是因为数据量太大。比如一个列表接口,一下子返回了 10000 条数据,足足 5MB。光是下载这 5MB 就得好几秒。这时候就得让后端搞"分页"了。
踩坑提醒
- 跨域拿不到细节 :这是最常见的坑。看到 DNS 时间是 0 别奇怪,八成是跨域了且没加
Timing-Allow-Origin头。这是浏览器为了保护隐私。 - 别全报:一个页面可能有上百个资源,全报上去服务器受不了。建议设个门槛(比如只报 > 1 秒的),或者只报核心的 JS/CSS。
- 接口监控 :很多人不知道
fetch请求也能在这里抓到。其实用它来监控后端接口性能,比自己封装axios拦截器要准得多,因为它算的是浏览器底层的真实时间。
6. 必备工具函数:定位神器 (util/index.js)
最后,我们得有个工具能帮我们"指路"。只告诉老板"图片慢"没用,你得告诉他是"哪个图片慢"。
getElementSelector 就是这个"定位神器"。它能把一个 DOM 元素转换成 CSS 选择器(比如 body > div#app > h1),让你直接在代码里找到它。
javascript
// src/util/index.js
export function getElementSelector(element) {
if (!element || element.nodeType !== 1) return '';
// 如果有 id,直接返回 #id
if (element.id) {
return `#${element.id}`;
}
// 递归向上查找
let path = [];
while (element) {
let name = element.localName;
if (!name) break;
// 如果有 id,拼接后停止
if (element.id) {
path.unshift(`#${element.id}`);
break;
}
// 加上 class
let className = element.getAttribute('class');
if (className) {
name += '.' + className.split(/\s+/).join('.');
}
path.unshift(name);
element = element.parentElement;
}
return path.join(' > ');
}7. 自定义指标:代码秒表
除了浏览器给的指标,有时候我们想知道某个具体函数到底跑了多久 ,或者滚动列表卡不卡。这时候就需要我们自己造个"秒表"。
(1) 函数耗时监控 (Wrapper)
三句话讲明白
- 不改业务代码 :不用在每个函数里写
start和end,用这个"高阶函数"包一下就行。 - 支持异步 :不管是普通的
for循环,还是await数据库查询,都能监控。 - 自动抓报错:如果函数跑挂了,它还能顺便把错误信息记下来。
直接上代码:
javascript
/**
* 同步函数计时器
* 用法:const newData = timeFunction('处理数据', processData, rawData);
*/
export const timeFunction = (name, fn, ...args) => {
const start = performance.now();
try {
const result = fn(...args);
const duration = performance.now() - start;
console.log(`Function [${name}]:`, duration.toFixed(2) + 'ms');
return result;
} catch (error) {
console.error(`Function [${name}] Error:`, error);
throw error; // 别吞掉错误,继续抛出
}
};
/**
* 异步函数计时器 (Promise)
* 用法:const user = await timeAsyncFunction('获取用户', fetchUser, id);
*/
export const timeAsyncFunction = async (name, fn, ...args) => {
const start = performance.now();
try {
const result = await fn(...args); // 等待异步完成
const duration = performance.now() - start;
console.log(`Async Function [${name}]:`, duration.toFixed(2) + 'ms');
return result;
} catch (error) {
console.error(`Async Function [${name}] Error:`, error);
throw error;
}
};(2) 滚动流畅度监控
三句话讲明白
- 不看帧率看延迟 :算 FPS 太复杂。我们就看最朴素的道理:我划了一下屏幕,浏览器多久才画出下一帧?
- 搭便车 (rAF) :
requestAnimationFrame(rAF) 是浏览器的"渲染末班车"。我们在滚动事件里跳上这趟车,等车到站了(渲染完成了),看看表,就知道这一路花了多久。 - 抽查机制:滚动事件触发频率极高(一秒几百次)。我们没必要次次都查,每隔半秒(500ms)抽查一次"末班车"准不准点就行了。
直接上代码:
javascript
// src/interaction/scroll.js
export function startScroll() {
let lastScrollLog = 0;
const scrollMinInterval = 500; // ms,限流,每半秒检查一次
const onScroll = () => {
const start = performance.now();
// 没到时间就别折腾,省点 CPU
if (start - lastScrollLog < scrollMinInterval) return;
lastScrollLog = start;
// 核心逻辑:预约下一帧渲染
// 就像你对浏览器说:"兄弟,画完这帧叫我一声。"
requestAnimationFrame(() => {
const afterRAF = performance.now();
const duration = afterRAF - start; // 这一帧到底花了多久?
// 16ms 是 60Hz 屏幕的标准一帧时间
// 如果超过 16ms,说明浏览器忙不过来了,这就叫"掉帧"
if (duration > 16) {
console.log('Scroll Lag:', duration.toFixed(2) + 'ms');
}
});
};
// passive: true 告诉浏览器"我不阻止滚动",能让滚动更丝滑
window.addEventListener('scroll', onScroll, { passive: true });
}代码怎么理解?
- 为什么要用
requestAnimationFrame?- JS 是单线程的。当你触发
scroll事件时,浏览器可能正忙着处理别的事(比如重排重绘)。 requestAnimationFrame会把你的代码放到浏览器准备画下一帧的时候执行。- 所以,
start是你触发滚动的时间,afterRAF是画面终于画出来的时间。这俩的差值 (duration) 越大,说明浏览器卡得越久,你感觉到的"顿挫感"就越强。
- JS 是单线程的。当你触发
8. 数据上报(sender.ts)
收集到数据后,如何发给后端?这看似简单,实则暗藏玄机。
1. 核心痛点:页面关了,请求还没发完怎么办?
用户看完网页直接关掉(或者刷新跳转),这时候浏览器会无情地杀掉当前页面进程里所有正在跑的异步请求(XHR/Fetch)。
结果就是:监控数据还没发出去,就死在半路上了。
2. 解决方案
为了确保数据必达,我们采用一套组合拳:
-
首选 Navigator.sendBeacon:
它是专门为"页面卸载上报"设计的。
特点:浏览器会在后台默默把数据发完,不阻塞页面关闭,也不会被杀掉。
-
次选 fetch + keepalive:
如果浏览器不支持 Beacon,或者你需要自定义 Header(Beacon 不支持自定义 Header),就用 fetch 并开启 keepalive: true。
特点:告诉浏览器"这个请求很重要,页面关了也请帮我发完"。
3. 代码实现
ts
export const sendBehaviorData = (data: Record<string, any>, url: string) => {
// 1. 包装数据:加上一些公共信息(比如 UserAgent,屏幕分辨率等)
const dataToSend = {
...data,
userAgent: navigator.userAgent,
// screenWidth: window.screen.width, // 可选
};
// 2. 优先使用 sendBeacon (最稳,且不阻塞)
// 注意:sendBeacon 不支持自定义 Content-Type,默认是 text/plain
// 这里用 Blob 强制指定为 application/json
if (navigator.sendBeacon) {
const blob = new Blob([JSON.stringify(dataToSend)], {
type: 'application/json',
});
// sendBeacon 返回 true 表示进入队列成功
navigator.sendBeacon(url, blob);
return;
}
// 3. 降级方案:使用 fetch + keepalive
// 即使页面关闭,keepalive 也能保证请求发出
fetch(url, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(dataToSend),
keepalive: true, // <--- 关键参数!防止页面关闭时请求被杀
}).catch((err) => {
console.error('上报失败:', err);
});
};3. 工程化构建配置
既然是 SDK,最好的分发方式当然是发布到 NPM。这样其他项目只需要一行命令就能接入你的前端错误监控系统。
这里我们选择 Rollup对代码进行打包,因为它比 Webpack 更适合打包库(Library),生成的代码更简洁。
3.1 package 配置 (package.json)
package.json 不仅仅是依赖管理,它还定义了你的包如何被外部使用。配置不当会导致用户引入报错或无法获得代码提示。
json
{
"name": "performance-sdk",
"version": "1.0.0",
"description": "A lightweight performance monitoring SDK",
"main": "dist/index.cjs.js",
"module": "dist/index.esm.js",
"browser": "dist/index.umd.js",
"type": "module",
"scripts": {
"build": "rollup -c",
"dev": "rollup -c -w"
},
"keywords": ["performance", "monitor", "sdk"],
"license": "MIT",
"files": ["dist"],
"devDependencies": {
"rollup": "^4.9.0",
"@rollup/plugin-typescript": "^11.1.0",
"@rollup/plugin-terser": "^0.4.0",
"typescript": "^5.3.0",
"tslib": "^2.6.0"
}
}💡 关键字段解读:
name: 包的"身份证号"。在 NPM 全球范围内必须唯一,发布前记得先去搜一下有没有重名。- 入口文件"三剑客" (决定了别人怎么引用你的包):
main: CommonJS 入口。给 Node.js 环境或老旧构建工具(如 Webpack 4)使用的。module: ESM 入口。给现代构建工具(Vite, Webpack 5)使用的。支持 Tree Shaking(摇树优化),能减小体积。browser: UMD 入口 。给浏览器直接通过<script>标签引入使用的(如 CDN)。
files: 发布白名单 。指定npm publish时只上传哪些文件(这里我们只传编译后的dist目录)。源码、测试代码等不需要发上去,以减小包体积。
3.2 TypeScript 配置 (tsconfig.json)
我们需要配置 TypeScript 如何编译代码,并生成类型声明文件(.d.ts),这对使用 TS 的用户非常友好。
json
{
"compilerOptions": {
"target": "es5", // 编译成 ES5,兼容旧浏览器
"module": "esnext", // 保留 ES 模块语法,交给 Rollup 处理
"declaration": true, // 生成 .d.ts 类型文件 (关键!)
"declarationDir": "./dist", // 类型文件输出目录
"strict": true, // 开启严格模式,代码更健壮
"moduleResolution": "node" // 按 Node 方式解析模块
},
"include": ["src/**/*"] // 编译 src 下的所有文件
}3.3 Rollup 打包配置 (rollup.config.js)
为了兼容各种使用场景,我们配置 Rollup 输出三种格式:
- ESM (
.esm.js): 给现代构建工具(Vite, Webpack)使用,支持 Tree Shaking。 - CJS (
.cjs.js): 给 Node.js 或旧版工具使用。 - UMD (
.umd.js) : 可以直接在浏览器通过<script>标签引入,会挂载全局变量。
javascript
import typescript from '@rollup/plugin-typescript';
import terser from '@rollup/plugin-terser';
export default {
input: 'src/index.ts',
output: [
{ file: 'dist/index.cjs.js', format: 'cjs', sourcemap: true },
{ file: 'dist/index.esm.js', format: 'es', sourcemap: true },
{
file: 'dist/index.umd.js',
format: 'umd',
name: 'PerformanceSDK',
sourcemap: true,
plugins: [terser()],
},
],
plugins: [
typescript({
tsconfig: './tsconfig.json',
declaration: true,
declarationDir: 'dist',
}),
],
};4. 发布到 NPM (保姆级教程)
4.1 准备工作
- 注册账号 :去 npmjs.com 注册一个账号(记得验证邮箱,否则无法发布)。
- 检查包名 :在 NPM 搜一下你的
package.json里的name,确保没有被占用。如果不幸重名,改个独特的名字,比如performance-sdk-vip。
4.2 终端操作三步走
打开终端(Terminal),在项目根目录下操作:
第一步:登录 NPM
bash
npm login- 输入命令后按回车,浏览器会弹出登录页面。
- 或者在终端根据提示输入用户名、密码和邮箱验证码。
- 登录成功后会显示
Logged in as <your-username>. - 注意:如果你之前切换过淘宝源,发布时必须切回官方源:
npm config set registry https://registry.npmjs.org/
第二步:打包代码
确保 dist 目录是最新的,不要发布空代码。
bash
npm run build第三步:正式发布
bash
npm publish --access public--access public参数用于确保发布的包是公开的(特别是当包名带@前缀时)。- 看到
+ performance-sdk-vip@1.0.0字样,恭喜你,发布成功!
现在,全世界的开发者都可以通过 npm install performance-sdk-vip 来使用你的作品了!
5. 如何使用
SDK 发布后,支持多种引入方式,适配各种开发场景。
- NPM + ES Modules(推荐)
bash
npm install performance-sdk
typescript
import PerformanceMonitor from 'performance-sdk';
const monitor = new PerformanceMonitor({
/* 可选:log, sampleRate, reportUrl */
});
monitor.init();- CDN 直接引入(UMD)
html
<script src="https://unpkg.com/performance-sdk@x.x.x/dist/index.umd.js"></script>
<script>
const monitor = new PerformanceSDK.PerformanceMonitor({
/* 可选配置 */
});
monitor.init();
</script>6. 总结与展望
恭喜你!到这里,你已经亲手打造了一套麻雀虽小,五脏俱全的性能监控 SDK。
咱们再回头看看这四大支柱:
- Loading (加载):FP/FCP/LCP 负责盯着**"快不快"**。白屏时间短,用户才愿意留下来。
- Interaction (交互):FID/INP 负责盯着**"顺不顺"**。点击有反馈,用户才觉得好用。
- Visual Stability (稳定性):CLS 负责盯着**"稳不稳"**。页面不乱跳,用户才不心烦。
- Network (网络):Resource Timing 负责盯着**"通不通"**。接口响应快,体验才有底气。
下一步可以玩点啥?
性能监控只是前端监控体系的三分之一。如果你想打造一个无死角的监控系统,光看性能是不够的:
- 报错了咋办? JS 挂了、接口 500 了、资源加载失败了......这些需要错误监控来兜底。
👉 传送门: 《【错误监控】别只做工具人了!手把手带你写一个前端错误监控 SDK》(https://juejin.cn/post/7580674010837549102)
- 用户在干啥? 用户点了哪个按钮?在哪个页面停留最久?这些需要行为监控来分析。
👉 传送门:《【用户行为监控】别只做工具人了!手把手带你写一个前端埋点统计 SDK》(https://juejin.cn/post/7583612559443279923)
当然,你还可以结合:
- 可视化大屏:光有数据不行,得画成图表(ECharts/Grafana)。看着曲线波动,才有成就感。
- 报警机器人:LCP 超过 4 秒了?接口报错率飙升了?直接钉钉/飞书群里 @ 全体成员,把问题扼杀在摇篮里。
性能优化是一场没有终点的马拉松 。希望这篇文章能是你打造专属监控系统的起点。Happy Coding!
如果觉得对您有帮助,欢迎点赞 👍 收藏 ⭐ 关注 🔔 支持一下!