概要
本文介绍了一个文本驱动的视频目标分割与追踪系统 ,通过自然语言描述即可在视频中定位、分割和追踪任意目标。系统结合了 GroundingDINO(开放词汇目标检测)、EfficientSAM(高效分割)和光流追踪技术,并使用 OpenVINO + NNCF 进行推理加速,最终实现了 8.4 倍的性能提升(从 0.34 FPS 提升到 2.84 FPS)
解决痛点
传统检测器只能识别预定义类别、新场景需要大量标注数据重新训练、SAM 等大模型推理耗时严重、逐帧处理,无法保持目标 ID 一致性
技术原理分解:
1、GroundingDINO:开放词汇目标检测
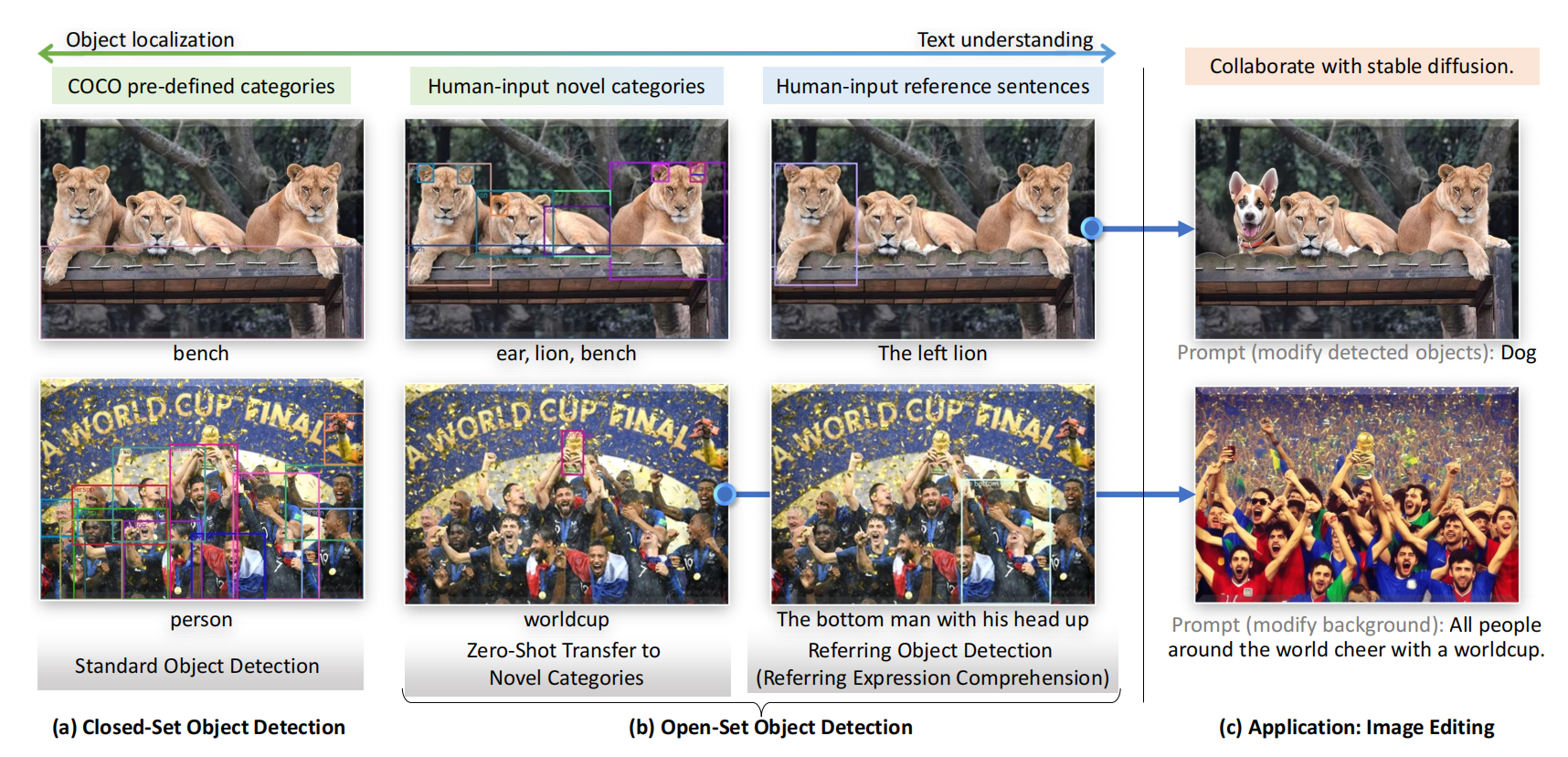
GroundingDINO 是一个文本-图像匹配 的目标检测模型,能够根据自然语言描述定位图像中的任意目标,无需预定义类别。其中双编码器负责特征提取,图像骨干(Swin-T/Swin-L)、文本骨干(BERT-base),提取多尺度视觉 / 语义特征。特征增强器负责跨模态融合,堆叠自注意力、文本 - 图像交叉注意力、图像 - 文本交叉注意力,对齐双模态特征。GroundingDINO的核心创新是① 三阶段紧密融合方案 (特征增强器 + 语言引导查询选择 + 跨模态解码器),实现语言与视觉模态的深度交互;② 子句级文本特征,避免无关类别间的注意力干扰。传统开放集检测痛点:仅在部分阶段融合模态(如 GLIP 仅颈部融合、OV-DETR 仅查询初始化融合),泛化能力有限;文本表示存在细粒度信息丢失或类别干扰,Grounding DINO 通过全流程融合和优化文本表示,提升了开放集泛化的准确性与稳定性。
2、EfficientSAM:高效图像分割
EfficientSAM 是 SAM的轻量级版本,在保持分割质量的同时大幅降低计算量。负责根据GroundingDINO提供的边界框,在特征图上生成具体的分割掩码。它的核心优势是极致轻量化,参数规模较原始 SAM 减少 20 倍,远超 MobileSAM(68M 参数)、FastSAM(68M 参数)的紧凑性。
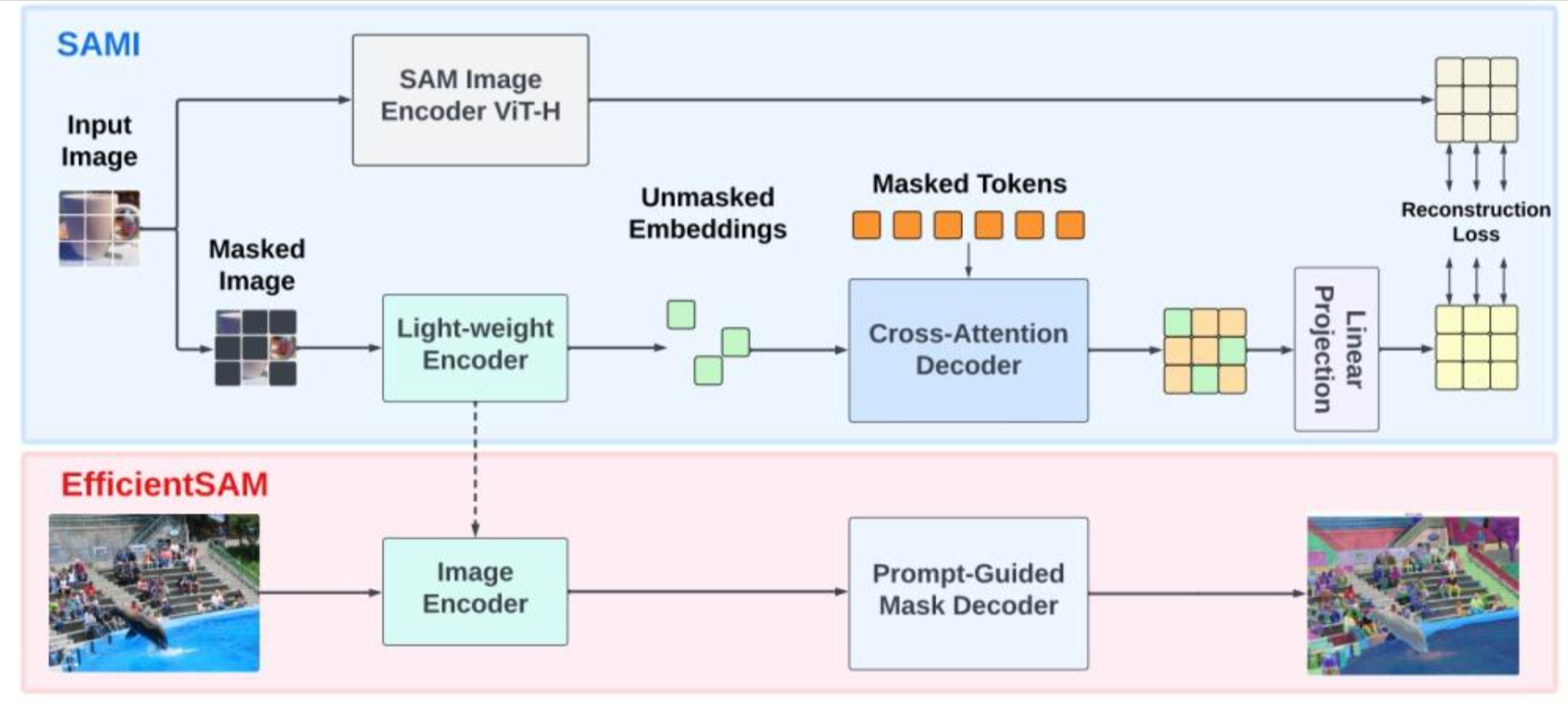
EfficientSAM 用原始 SAM 的大模型(ViT-H 骨干)生成高质量图像特征嵌入,作为 "监督信号";再训练轻量级 ViT 编码器(如 ViT-Tiny/ViT-Small),从这些 SAM 特征中 "重建" 信息,而非直接从原始图像补丁重建。
- 交叉注意力解码器:仅对 "掩码区域的 Token" 进行解码,查询(Query)来自掩码 Token,键(Key)和值(Value)来自编码器的未掩码 / 掩码特征,减少计算量;同时将解码器输出的掩码 Token 特征与编码器的未掩码 Token 特征合并,还原图像原始 Token 顺序;
- 线性投影头:解决轻量级编码器输出特征与原始 SAM 特征的 "维度不匹配" 问题,通过简单线性层对齐特征空间;
- 重建损失:计算轻量级编码器(经线性投影后)与原始 SAM 编码器的特征差异,以 "特征重建误差" 为损失,驱动轻量级模型学习高质量视觉表征
预训练完成后,轻量级编码器(ViT-Tiny/ViT-Small)已具备通用视觉特征提取能力,需结合 SAM 解码器微调,使其适配 "根据提示分割任意物体" 的核心任务:支持点提示(输入坐标 (x,y) 及前景 / 背景标签)、框提示(输入目标边界框)、文本提示(需与 Grounding DINO 等零样本检测模型结合,将文本映射为视觉区域),实现多模态提示驱动的分割。fficientSAM 本身不直接支持文本输入,通过与 Grounding DINO 联动:先用 Grounding DINO 根据文本提示(如 "猫")检测出目标物体的边界框;将边界框作为 "框提示" 输入 EfficientSAM;EfficientSAM 根据框提示生成该物体的像素级分割掩码,实现 "文本→检测→分割" 的端到端流程。
3、OpenVINO 进行推理加速
为了让系统能够在普通硬件上运行,本项目使用 Intel OpenVINO 工具包对 EfficientSAM 的 Image Encoder 进行了深度优化。使用 NNCF(Neural Network Compression Framework)进行 INT8 量化。量化的核心思想是用 8 位整数代替 32 位浮点数进行计算。由于整数运算比浮点运算更快,且现代 CPU 的 VNNI 指令集专门优化了 INT8 矩阵乘法,量化后的模型推理速度可以再提升 2-4 倍。具体步骤为:
1、模型转换:将 EfficientSAM 转换为 OpenVINO IR 格式 2、FP32 → INT8量化加速 3、三级帧调度策略 4、基于光流的追踪:采用 Lucas-Kanade 稀疏光流算法来追踪边界框。估计边界框的平移和缩放,预测目标在新帧中的位置。
4、智能帧调度:减少冗余计算
针对逐帧处理的低效问题,本系统设计了一套三级帧调度策略:
第一级是检测帧,每隔 10 帧执行一次完整的目标检测和分割流程。在检测帧中,GroundingDINO 会重新扫描整个画面,发现新出现的目标或确认已有目标的位置。
第二级是分割帧,在两次检测之间,每隔 3 帧执行一次分割更新。此时不再运行 GroundingDINO,而是利用光流算法预测目标边界框的新位置,然后只运行 EfficientSAM 来更新分割掩码。
第三级是传播帧,这是最轻量的处理方式。对于剩余的帧,系统完全不运行任何深度学习模型,而是使用光流法直接传播上一帧的边界框和掩码。这种基于运动估计的传播方法计算量极小,单帧处理时间仅需约 4 毫秒。
通过这种分级策略,在 10 帧的周期内,只有 1 帧需要完整处理,2-3 帧需要分割更新,其余 6-7 帧都采用轻量传播。这大幅降低了平均每帧的计算量,同时由于视频帧间的连续性,质量损失几乎不可察觉。
5、光流追踪:保持目标 ID 一致性
为了解决目标 ID 不一致的问题,本系统引入了基于光流的追踪机制。光流是描述像素运动的向量场,通过分析相邻帧之间的光流,我们可以估计每个目标的运动轨迹。
具体实现上,系统采用 Lucas-Kanade 稀疏光流算法来追踪边界框。在每个目标的边界框内部,系统会检测若干特征点(角点),然后计算这些特征点在下一帧中的新位置。通过这些特征点的位移,我们可以估计整个边界框的平移和缩放,从而预测目标在新帧中的位置。
当检测帧到来时,系统会将新的检测结果与已有的追踪目标进行匹配。匹配策略基于 IoU(交并比):计算每个检测框与每个追踪框的重叠程度,采用贪婪算法依次选择 IoU 最高的配对。匹配成功的目标保持原有 ID,未匹配的新检测结果被分配新的 ID,长时间未匹配的追踪目标则被移除。
部分核心实现:
1、将 EfficientSAM 的 Image Encoder 转换为 OpenVINO 格式,FP16 压缩,减小模型体积:创建convert_efficientsam.py:
python
import torch
import openvino as ov
import sys
import os
sys.path.append(os.path.join(os.path.dirname(__file__), 'EfficientSAM'))
from efficient_sam.build_efficient_sam import build_efficient_sam_vitt
def export_efficientsam():
print("1. 加载 EfficientSAM (ViT-T)...")
weights_path = "EfficientSAM/weights/efficient_sam_vitt.pt"
model = build_efficient_sam_vitt(checkpoint=weights_path)
model.eval()
print("2. 导出 Image Encoder 到 OpenVINO...")
dummy_input = torch.randn(1, 3, 1024, 1024)
ov_model = ov.convert_model(model.image_encoder, example_input=dummy_input)
output_dir = "ov_models_efficientsam"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
save_path = os.path.join(output_dir, "efficient_sam_vitt_encoder.xml")
ov.save_model(ov_model, save_path, compress_to_fp16=True)
print(f"转换完成!模型保存至: {save_path}")
if __name__ == "__main__":
export_efficientsam()2、具体参数文件GroundingDINO_SwinT_OGC.py:
python
batch_size = 1
modelname = "groundingdino"
backbone = "swin_T_224_1k"
position_embedding = "sine"
pe_temperatureH = 20
pe_temperatureW = 20
return_interm_indices = [1, 2, 3]
backbone_freeze_keywords = None
enc_layers = 6
dec_layers = 6
pre_norm = False
dim_feedforward = 2048
hidden_dim = 256
dropout = 0.0
nheads = 8
num_queries = 900
query_dim = 4
num_patterns = 0
num_feature_levels = 4
enc_n_points = 4
dec_n_points = 4
two_stage_type = "standard"
two_stage_bbox_embed_share = False
two_stage_class_embed_share = False
transformer_activation = "relu"
dec_pred_bbox_embed_share = True
dn_box_noise_scale = 1.0
dn_label_noise_ratio = 0.5
dn_label_coef = 1.0
dn_bbox_coef = 1.0
embed_init_tgt = True
dn_labelbook_size = 2000
max_text_len = 256
text_encoder_type = "bert-base-uncased"
use_text_enhancer = True
use_fusion_layer = True
use_checkpoint = True
use_transformer_ckpt = True
use_text_cross_attention = True
text_dropout = 0.0
fusion_dropout = 0.0
fusion_droppath = 0.1
sub_sentence_present = True3、运行 EfficientSAM 进行图像分割,使用 OpenVINO 推理 仅对 Image Encoder,创建run_efficientsam.py:
python
import time
import cv2
import numpy as np
import torch
from PIL import Image
import openvino as ov
import os
import sys
import torch.nn.functional as F
from torchvision.transforms import ToTensor, Normalize
# --- 路径设置 ---
sys.path.append(os.path.join(os.path.dirname(__file__), '../GroundingDINO_main'))
sys.path.append(os.path.join(os.path.dirname(__file__), '../EfficientSAM'))
from groundingdino.util.inference import load_model, load_image, predict
from efficient_sam.build_efficient_sam import build_efficient_sam_vitt
# --- 配置 ---
IMAGE_PATH = "../rabbit.jpg"
TEXT_PROMPT = "the black rabbit ."
GD_CONFIG = "GroundingDINO_SwinT_OGC.py"
GD_WEIGHTS = "../grounded_sam_ov/weights/groundingdino_swint_ogc.pth"
ES_WEIGHTS = "../EfficientSAM/weights/efficient_sam_vitt.pt"
ES_OV_MODEL = "../ov_models_efficientsam/efficient_sam_vitt_encoder.xml"
OUTPUT_PATH = "../result_efficientsam_test.jpg"
DEVICE_OV = "GPU"
# ------------
class OpenVINOEfficientSAMPredictor:
def __init__(self, pytorch_model, ov_compiled_encoder):
self.model = pytorch_model
self.ov_encoder = ov_compiled_encoder
self.original_size = None
self.features = None
self.scale = None
self.valid_w = None
self.valid_h = None
self.normalize = Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
def preprocess_image(self, image_pil):
w, h = image_pil.size
self.original_size = (w, h)
# 1. 计算缩放
scale = 1024.0 / max(w, h)
new_w, new_h = int(w * scale), int(h * scale)
self.valid_w = new_w
self.valid_h = new_h
self.scale = scale
# 2. Resize
image_resized = image_pil.resize((new_w, new_h), resample=Image.BICUBIC)
# 3. ToTensor & Normalize
tensor = ToTensor()(image_resized)
tensor = self.normalize(tensor)
# 4. Padding
pad_w = 1024 - new_w
pad_h = 1024 - new_h
tensor = F.pad(tensor, (0, pad_w, 0, pad_h), value=0)
return tensor.unsqueeze(0)
def set_image(self, image_pil):
input_tensor = self.preprocess_image(image_pil)
input_numpy = input_tensor.numpy().astype(np.float32)
# OpenVINO 推理
results = self.ov_encoder(input_numpy)[0]
self.features = torch.tensor(results).reshape(1, 256, 64, 64)
def predict(self, boxes):
"""
预测分割掩码
Args:
boxes: [N, 4] 原图坐标的 xyxy 格式边界框
Returns:
masks: [N, H, W] 布尔掩码
"""
batch_size = boxes.shape[0]
with torch.no_grad():
boxes_1024 = boxes.clone()
boxes_1024[:, 0] = boxes_1024[:, 0] * (1024.0 / self.original_size[0])
boxes_1024[:, 1] = boxes_1024[:, 1] * (1024.0 / self.original_size[1])
boxes_1024[:, 2] = boxes_1024[:, 2] * (1024.0 / self.original_size[0])
boxes_1024[:, 3] = boxes_1024[:, 3] * (1024.0 / self.original_size[1])
box_points = boxes_1024.reshape(-1, 2, 2)
box_labels = torch.tensor([[2, 3]], dtype=torch.float32).repeat(batch_size, 1)
batched_points = box_points.unsqueeze(1)
batched_labels = box_labels.unsqueeze(1)
batched_features = self.features.repeat(batch_size, 1, 1, 1)
low_res_masks, iou_predictions = self.model.predict_masks(
image_embeddings=batched_features,
batched_points=batched_points,
batched_point_labels=batched_labels,
multimask_output=True,
input_h=1024,
input_w=1024,
output_h=1024,
output_w=1024
)
print(f" [DEBUG] low_res_masks 原始形状: {low_res_masks.shape}")
print(f" [DEBUG] iou_predictions 形状: {iou_predictions.shape}")
if low_res_masks.dim() == 5:
best_mask_indices = torch.argmax(iou_predictions[:, :, :], dim=2)
low_res_masks = low_res_masks[torch.arange(batch_size),
torch.zeros(batch_size, dtype=torch.long),
best_mask_indices[:, 0],
:, :].unsqueeze(1)
elif low_res_masks.dim() == 4:
if low_res_masks.shape[1] > 1:
low_res_masks = low_res_masks[:, 0:1, :, :]
elif low_res_masks.dim() == 3:
low_res_masks = low_res_masks.unsqueeze(1)
print(f" [DEBUG] 调整后形状: {low_res_masks.shape}")
masks_cropped = low_res_masks[:, :, :self.valid_h, :self.valid_w]
print(f" [DEBUG] 裁剪后形状: {masks_cropped.shape} (有效区域: {self.valid_h}x{self.valid_w})")
orig_w, orig_h = self.original_size
masks = F.interpolate(
masks_cropped,
size=(orig_h, orig_w),
mode="bilinear",
align_corners=False
)
final_masks = masks.squeeze(1) > 0.5
print(f" [DEBUG] 最终输出形状: {final_masks.shape}")
return final_masks
def run_demo():
print("=" * 50)
print("GroundingDINO + EfficientSAM (OpenVINO)")
print("=" * 50)
# 1. 加载 GroundingDINO
print("1. 加载 GroundingDINO...")
gd_model = load_model(GD_CONFIG, GD_WEIGHTS)
# 2. 加载 EfficientSAM
print("2. 加载 EfficientSAM (OpenVINO Encoder + PyTorch Decoder)...")
core = ov.Core()
if not os.path.exists(ES_OV_MODEL):
print(f"错误: 找不到 {ES_OV_MODEL}")
return
compiled_es_encoder = core.compile_model(ES_OV_MODEL, device_name=DEVICE_OV)
es_pytorch = build_efficient_sam_vitt(checkpoint=ES_WEIGHTS)
es_pytorch.eval()
predictor = OpenVINOEfficientSAMPredictor(es_pytorch, compiled_es_encoder)
image_source, image_tensor = load_image(IMAGE_PATH)
image_pil = Image.fromarray(cv2.cvtColor(image_source, cv2.COLOR_BGR2RGB))
print(f"\n图片尺寸: {image_source.shape[1]}x{image_source.shape[0]}")
print("\n--- 开始推理 ---")
t0 = time.time()
boxes, logits, phrases = predict(
model=gd_model,
image=image_tensor,
caption=TEXT_PROMPT,
box_threshold=0.35,
text_threshold=0.25,
device="cpu"
)
t1 = time.time()
print(f"检测到 {len(boxes)} 个物体. (GD耗时: {t1-t0:.4f}s)")
if len(boxes) == 0:
print("未检测到物体")
return
# B. EfficientSAM Encoder
predictor.set_image(image_pil)
t2 = time.time()
print(f"特征提取完成. (EfficientSAM Encoder耗时: {t2-t1:.4f}s)")
# C. EfficientSAM Decoder
H, W = image_source.shape[:2]
boxes_xyxy = box_convert_gd_to_xyxy(boxes, W, H)
masks = predictor.predict(boxes_xyxy)
t3 = time.time()
print(f"Mask生成完成. (Decoder耗时: {t3-t2:.4f}s)")
print(f"总耗时: {t3-t0:.4f}s")
save_result(image_source, masks, boxes_xyxy, OUTPUT_PATH)
def box_convert_gd_to_xyxy(boxes, width, height):
"""GroundingDINO (cx, cy, w, h) norm -> (x1, y1, x2, y2) abs"""
boxes = boxes * torch.Tensor([width, height, width, height])
xyxy = torch.zeros_like(boxes)
xyxy[:, 0] = boxes[:, 0] - boxes[:, 2] / 2
xyxy[:, 1] = boxes[:, 1] - boxes[:, 3] / 2
xyxy[:, 2] = boxes[:, 0] + boxes[:, 2] / 2
xyxy[:, 3] = boxes[:, 1] + boxes[:, 3] / 2
return xyxy
def save_result(image, masks, boxes, output_path):
plt_image = image.copy()
if masks is not None:
for mask in masks:
if len(mask.shape) == 3:
mask = mask[0]
mask_np = mask.cpu().numpy().astype(bool)
color = np.random.randint(0, 255, (3,)).tolist()
plt_image[mask_np] = plt_image[mask_np] * 0.5 + np.array(color) * 0.5
for box in boxes:
cv2.rectangle(plt_image, (int(box[0]), int(box[1])), (int(box[2]), int(box[3])), (0, 255, 0), 2)
cv2.imwrite(output_path, plt_image.astype(np.uint8))
print(f"结果已保存到: {output_path}")
if __name__ == "__main__":
run_demo()结果示例:输入:

输出:

4、对视频进行检测+分割+追踪:创建GroundingDINO+EfficientSAM+ByteTrack.py:
python
#!/usr/bin/env python3
"""
视频分割方案:GroundingDINO + EfficientSAM + 光流追踪
实现:文本驱动的视频物体追踪与分割
优化策略:
1. 减少 SAM Encoder 调用(跳帧分割)
2. 使用光流进行 Box/Mask 传播
"""
import cv2
import numpy as np
import torch
from PIL import Image
import time
import os
import sys
import torch.nn.functional as F
from torchvision.transforms import ToTensor, Normalize
from collections import defaultdict
# --- 路径设置 ---
sys.path.append(os.path.join(os.path.dirname(__file__), '../GroundingDINO_main'))
sys.path.append(os.path.join(os.path.dirname(__file__), '../EfficientSAM'))
# --- 导入模块 ---
from groundingdino.util.inference import load_model, load_image, predict
from efficient_sam.build_efficient_sam import build_efficient_sam_vitt
import openvino as ov
class OpenVINOEfficientSAMPredictor:
"""OpenVINO 加速的 EfficientSAM 预测器"""
def __init__(self, pytorch_model, ov_compiled_encoder):
self.model = pytorch_model
self.ov_encoder = ov_compiled_encoder
self.original_size = None
self.features = None
self.scale = None
self.valid_w = None
self.valid_h = None
self.normalize = Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
def preprocess_image(self, image_pil):
w, h = image_pil.size
self.original_size = (w, h)
scale = 1024.0 / max(w, h)
new_w, new_h = int(w * scale), int(h * scale)
self.valid_w = new_w
self.valid_h = new_h
self.scale = scale
image_resized = image_pil.resize((new_w, new_h), resample=Image.BICUBIC)
tensor = ToTensor()(image_resized)
tensor = self.normalize(tensor)
pad_w = 1024 - new_w
pad_h = 1024 - new_h
tensor = F.pad(tensor, (0, pad_w, 0, pad_h), value=0)
return tensor.unsqueeze(0)
def set_image(self, image_pil):
input_tensor = self.preprocess_image(image_pil)
input_numpy = input_tensor.numpy().astype(np.float32)
results = self.ov_encoder(input_numpy)[0]
self.features = torch.tensor(results).reshape(1, 256, 64, 64)
def predict(self, boxes):
"""预测分割掩码"""
if len(boxes) == 0:
return torch.zeros((0,) + self.original_size[::-1], dtype=torch.bool)
batch_size = boxes.shape[0]
with torch.no_grad():
boxes_1024 = boxes.clone()
boxes_1024[:, 0] = boxes_1024[:, 0] * (1024.0 / self.original_size[0])
boxes_1024[:, 1] = boxes_1024[:, 1] * (1024.0 / self.original_size[1])
boxes_1024[:, 2] = boxes_1024[:, 2] * (1024.0 / self.original_size[0])
boxes_1024[:, 3] = boxes_1024[:, 3] * (1024.0 / self.original_size[1])
box_points = boxes_1024.reshape(-1, 2, 2)
box_labels = torch.tensor([[2, 3]], dtype=torch.float32).repeat(batch_size, 1)
batched_points = box_points.unsqueeze(1)
batched_labels = box_labels.unsqueeze(1)
batched_features = self.features.repeat(batch_size, 1, 1, 1)
low_res_masks, iou_predictions = self.model.predict_masks(
image_embeddings=batched_features,
batched_points=batched_points,
batched_point_labels=batched_labels,
multimask_output=True,
input_h=1024,
input_w=1024,
output_h=1024,
output_w=1024
)
if low_res_masks.dim() == 5:
best_mask_indices = torch.argmax(iou_predictions[:, :, :], dim=2)
low_res_masks = low_res_masks[torch.arange(batch_size),
torch.zeros(batch_size, dtype=torch.long),
best_mask_indices[:, 0],
:, :].unsqueeze(1)
elif low_res_masks.dim() == 4:
if low_res_masks.shape[1] > 1:
low_res_masks = low_res_masks[:, 0:1, :, :]
elif low_res_masks.dim() == 3:
low_res_masks = low_res_masks.unsqueeze(1)
masks_cropped = low_res_masks[:, :, :self.valid_h, :self.valid_w]
orig_w, orig_h = self.original_size
masks = F.interpolate(
masks_cropped,
size=(orig_h, orig_w),
mode="bilinear",
align_corners=False
)
final_masks = masks.squeeze(1) > 0.5
return final_masks
class OpticalFlowPropagator:
"""光流传播器 - 用于传播边界框和掩码"""
def __init__(self):
self.prev_gray = None
# Lucas-Kanade 光流参数
self.lk_params = dict(
winSize=(21, 21),
maxLevel=3,
criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 30, 0.01)
)
# 稠密光流参数(用于 mask 传播)
self.use_dense_flow_for_mask = True
def update_frame(self, frame):
"""更新当前帧(每帧都要调用)"""
self.prev_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
def propagate_box(self, prev_frame, curr_frame, prev_box):
"""
使用光流传播边界框
Args:
prev_frame: 上一帧 (BGR)
curr_frame: 当前帧 (BGR)
prev_box: 上一帧的边界框 [x1, y1, x2, y2] (torch.Tensor)
Returns:
new_box: 传播后的边界框
"""
prev_gray = cv2.cvtColor(prev_frame, cv2.COLOR_BGR2GRAY)
curr_gray = cv2.cvtColor(curr_frame, cv2.COLOR_BGR2GRAY)
# 在边界框内提取特征点
x1, y1, x2, y2 = map(int, prev_box.tolist())
# 确保坐标在有效范围内
h, w = prev_gray.shape
x1, y1 = max(0, x1), max(0, y1)
x2, y2 = min(w, x2), min(h, y2)
if x2 <= x1 or y2 <= y1:
return prev_box
# 创建 ROI mask
roi_mask = np.zeros_like(prev_gray)
roi_mask[y1:y2, x1:x2] = 255
# 检测特征点
prev_pts = cv2.goodFeaturesToTrack(
prev_gray,
maxCorners=100,
qualityLevel=0.01,
minDistance=7,
mask=roi_mask
)
if prev_pts is None or len(prev_pts) < 4:
# 特征点太少,使用框的四个角点
prev_pts = np.array([
[[x1, y1]], [[x2, y1]], [[x1, y2]], [[x2, y2]],
[[(x1+x2)/2, y1]], [[(x1+x2)/2, y2]],
[[x1, (y1+y2)/2]], [[x2, (y1+y2)/2]]
], dtype=np.float32)
# 计算光流
curr_pts, status, _ = cv2.calcOpticalFlowPyrLK(
prev_gray, curr_gray, prev_pts, None, **self.lk_params
)
# 筛选有效的跟踪点
if status is None:
return prev_box
good_prev = prev_pts[status.flatten() == 1]
good_curr = curr_pts[status.flatten() == 1]
if len(good_prev) < 2:
return prev_box
# 计算位移(使用中位数更鲁棒)
displacements = good_curr - good_prev
median_dx = np.median(displacements[:, 0, 0])
median_dy = np.median(displacements[:, 0, 1])
# 计算缩放因子(可选)
if len(good_prev) >= 4:
# 计算点云的尺度变化
prev_std = np.std(good_prev.reshape(-1, 2), axis=0)
curr_std = np.std(good_curr.reshape(-1, 2), axis=0)
scale_x = curr_std[0] / (prev_std[0] + 1e-6)
scale_y = curr_std[1] / (prev_std[1] + 1e-6)
# 限制缩放范围
scale_x = np.clip(scale_x, 0.9, 1.1)
scale_y = np.clip(scale_y, 0.9, 1.1)
else:
scale_x, scale_y = 1.0, 1.0
# 更新边界框
new_box = prev_box.clone().float()
# 计算中心点
cx = (new_box[0] + new_box[2]) / 2
cy = (new_box[1] + new_box[3]) / 2
bw = new_box[2] - new_box[0]
bh = new_box[3] - new_box[1]
# 更新中心点
new_cx = cx + median_dx
new_cy = cy + median_dy
# 更新尺寸
new_bw = bw * scale_x
new_bh = bh * scale_y
# 转回 xyxy 格式
new_box[0] = new_cx - new_bw / 2
new_box[1] = new_cy - new_bh / 2
new_box[2] = new_cx + new_bw / 2
new_box[3] = new_cy + new_bh / 2
# 确保在图像范围内
new_box[0] = max(0, new_box[0])
new_box[1] = max(0, new_box[1])
new_box[2] = min(w, new_box[2])
new_box[3] = min(h, new_box[3])
return new_box
def propagate_mask(self, prev_frame, curr_frame, prev_mask):
"""
使用稠密光流传播掩码
Args:
prev_frame: 上一帧 (BGR)
curr_frame: 当前帧 (BGR)
prev_mask: 上一帧的掩码 (torch.Tensor, bool)
Returns:
new_mask: 传播后的掩码
"""
prev_gray = cv2.cvtColor(prev_frame, cv2.COLOR_BGR2GRAY)
curr_gray = cv2.cvtColor(curr_frame, cv2.COLOR_BGR2GRAY)
# 计算稠密光流
flow = cv2.calcOpticalFlowFarneback(
prev_gray, curr_gray, None,
pyr_scale=0.5,
levels=3,
winsize=15,
iterations=3,
poly_n=5,
poly_sigma=1.2,
flags=0
)
h, w = curr_gray.shape
# 创建重映射网格
flow_x = flow[:, :, 0]
flow_y = flow[:, :, 1]
# 创建坐标网格
grid_x, grid_y = np.meshgrid(np.arange(w), np.arange(h))
# 反向映射(从当前帧到上一帧)
map_x = (grid_x - flow_x).astype(np.float32)
map_y = (grid_y - flow_y).astype(np.float32)
# 转换 mask 格式
prev_mask_np = prev_mask.cpu().numpy().astype(np.float32)
# 重映射
warped_mask = cv2.remap(
prev_mask_np,
map_x,
map_y,
interpolation=cv2.INTER_LINEAR,
borderMode=cv2.BORDER_CONSTANT,
borderValue=0
)
# 二值化并转回 tensor
new_mask = torch.from_numpy(warped_mask > 0.5)
return new_mask
def propagate_mask_simple(self, prev_box, curr_box, prev_mask):
"""
简单的掩码传播(基于边界框变换)
比稠密光流快很多
"""
# 计算变换参数
prev_cx = (prev_box[0] + prev_box[2]) / 2
prev_cy = (prev_box[1] + prev_box[3]) / 2
prev_w = prev_box[2] - prev_box[0]
prev_h = prev_box[3] - prev_box[1]
curr_cx = (curr_box[0] + curr_box[2]) / 2
curr_cy = (curr_box[1] + curr_box[3]) / 2
curr_w = curr_box[2] - curr_box[0]
curr_h = curr_box[3] - curr_box[1]
# 计算位移和缩放
dx = (curr_cx - prev_cx).item()
dy = (curr_cy - prev_cy).item()
sx = (curr_w / (prev_w + 1e-6)).item()
sy = (curr_h / (prev_h + 1e-6)).item()
# 限制缩放范围
sx = np.clip(sx, 0.8, 1.2)
sy = np.clip(sy, 0.8, 1.2)
h, w = prev_mask.shape
# 中心点变换
M = np.float32([
[sx, 0, dx + prev_cx.item() * (1 - sx)],
[0, sy, dy + prev_cy.item() * (1 - sy)]
])
# 应用变换
prev_mask_np = prev_mask.cpu().numpy().astype(np.float32)
warped_mask = cv2.warpAffine(
prev_mask_np, M, (w, h),
flags=cv2.INTER_LINEAR,
borderMode=cv2.BORDER_CONSTANT,
borderValue=0
)
return torch.from_numpy(warped_mask > 0.5)
def apply_nms(boxes, scores, iou_threshold=0.5):
"""
应用非极大值抑制去除重叠框
"""
if len(boxes) == 0:
return []
if isinstance(boxes, torch.Tensor):
boxes_np = boxes.numpy()
scores_np = scores.numpy() if isinstance(scores, torch.Tensor) else scores
else:
boxes_np = np.array(boxes)
scores_np = np.array(scores)
x1 = boxes_np[:, 0]
y1 = boxes_np[:, 1]
x2 = boxes_np[:, 2]
y2 = boxes_np[:, 3]
areas = (x2 - x1) * (y2 - y1)
order = scores_np.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
if order.size == 1:
break
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1)
h = np.maximum(0.0, yy2 - yy1)
inter = w * h
iou = inter / (areas[i] + areas[order[1:]] - inter + 1e-6)
inds = np.where(iou <= iou_threshold)[0]
order = order[inds + 1]
return keep
class OptimizedVideoTracker:
"""优化版视频分割追踪器"""
def __init__(self, gd_model, sam_predictor,
detection_interval=10,
segmentation_interval=3,
iou_threshold=0.5,
nms_threshold=0.5, # 新增:NMS阈值
box_threshold=0.35, # 新增:检测置信度阈值
use_dense_flow_for_mask=False):
"""
Args:
detection_interval: 目标检测间隔(帧数)
segmentation_interval: 分割间隔(帧数)
iou_threshold: IoU 匹配阈值
use_dense_flow_for_mask: 是否使用稠密光流传播 mask(更准确但更慢)
"""
self.gd_model = gd_model
self.sam_predictor = sam_predictor
self.detection_interval = detection_interval
self.segmentation_interval = segmentation_interval
self.iou_threshold = iou_threshold
self.nms_threshold = nms_threshold # NMS阈值
self.box_threshold = box_threshold # 检测阈值
self.use_dense_flow_for_mask = use_dense_flow_for_mask
# 追踪状态
self.tracks = {}
self.next_id = 0
self.frame_count = 0
# 光流传播器
self.flow_propagator = OpticalFlowPropagator()
# 保存上一帧
self.prev_frame = None
# 统计信息
self.stats = {
'detection_frames': 0,
'segmentation_frames': 0,
'propagation_frames': 0,
'detection_time': 0,
'segmentation_time': 0,
'propagation_time': 0
}
def process_video(self, video_path, text_prompt, output_path):
"""处理视频"""
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(output_path, fourcc, fps, (width, height))
print(f"视频信息: {width}x{height} @ {fps}fps, 总帧数: {total_frames}")
print(f"文本提示: {text_prompt}")
print(f"检测间隔: {self.detection_interval} 帧")
print(f"分割间隔: {self.segmentation_interval} 帧")
print("-" * 50)
total_time = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
start_time = time.time()
# 处理帧
result_frame = self.process_frame(frame, text_prompt)
processing_time = time.time() - start_time
total_time += processing_time
out.write(result_frame)
if self.frame_count % 30 == 0:
current_fps = 1.0 / (processing_time + 1e-6)
avg_fps = self.frame_count / (total_time + 1e-6)
progress = self.frame_count / total_frames * 100 if total_frames > 0 else 0
print(f"进度: {progress:.1f}% | 帧: {self.frame_count}/{total_frames} | "
f"追踪物体: {len(self.tracks)} | "
f"当前FPS: {current_fps:.2f} | 平均FPS: {avg_fps:.2f}")
cap.release()
out.release()
# 打印统计信息
self._print_stats(total_time)
print(f"\n视频保存至: {output_path}")
def process_frame(self, frame, text_prompt):
"""
处理单帧
根据帧类型选择不同的处理策略:
1. 检测帧:运行 GroundingDINO + SAM
2. 分割帧:只运行 SAM(使用光流传播的框)
3. 传播帧:只使用光流传播(最快)
"""
self.frame_count += 1
image_pil = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
# 判断帧类型
is_detection_frame = (self.frame_count % self.detection_interval == 1) or len(self.tracks) == 0
is_segmentation_frame = (self.frame_count % self.segmentation_interval == 1) and not is_detection_frame
start_time = time.time()
if is_detection_frame:
# 检测帧:完整的检测 + 分割流程
detections = self._detect(frame, text_prompt)
self._update_tracks_with_detection(detections, image_pil)
self.stats['detection_frames'] += 1
self.stats['detection_time'] += time.time() - start_time
elif is_segmentation_frame:
# 分割帧:先用光流传播框,再用 SAM 分割
if self.prev_frame is not None:
self._propagate_boxes(frame)
self._update_masks_with_sam(image_pil)
self.stats['segmentation_frames'] += 1
self.stats['segmentation_time'] += time.time() - start_time
else:
# 传播帧:只用光流传播框和 mask
if self.prev_frame is not None:
self._propagate_all(frame)
else:
# 没有上一帧,需要完整处理
detections = self._detect(frame, text_prompt)
self._update_tracks_with_detection(detections, image_pil)
self.stats['propagation_frames'] += 1
self.stats['propagation_time'] += time.time() - start_time
# 保存当前帧供下一帧使用
self.prev_frame = frame.copy()
# 可视化
return self._visualize(frame)
def _detect(self, frame, text_prompt):
"""目标检测"""
image_source, image_tensor = load_image_from_frame(frame)
boxes, logits, phrases = predict(
model=self.gd_model,
image=image_tensor,
caption=text_prompt,
box_threshold=self.box_threshold, # 使用可配置的阈值
text_threshold=0.25,
device="cpu"
)
H, W = frame.shape[:2]
boxes_xyxy = self._box_convert(boxes, W, H)
# ========== 添加 NMS ==========
keep_indices = apply_nms(boxes_xyxy, logits, self.nms_threshold)
boxes_xyxy = boxes_xyxy[keep_indices]
logits = logits[keep_indices]
phrases = [phrases[i] for i in keep_indices]
# ==============================
return {
'boxes': boxes_xyxy,
'scores': logits,
'classes': phrases
}
def _update_tracks_with_detection(self, detections, image_pil):
"""使用检测结果更新追踪"""
if len(detections['boxes']) == 0:
self._age_tracks()
return
# 设置图像并生成掩码
self.sam_predictor.set_image(image_pil)
masks = self.sam_predictor.predict(detections['boxes'])
# 匹配检测与现有追踪
matched, unmatched_dets, unmatched_tracks = self._match_detections(
detections['boxes'],
list(self.tracks.keys())
)
# 更新匹配的追踪
for det_idx, track_id in matched:
self.tracks[track_id]['box'] = detections['boxes'][det_idx]
self.tracks[track_id]['mask'] = masks[det_idx]
self.tracks[track_id]['class'] = detections['classes'][det_idx]
self.tracks[track_id]['age'] = 0
self.tracks[track_id]['lost_count'] = 0
# 创建新追踪
for det_idx in unmatched_dets:
self.tracks[self.next_id] = {
'box': detections['boxes'][det_idx],
'mask': masks[det_idx],
'class': detections['classes'][det_idx],
'age': 0,
'lost_count': 0,
'color': tuple(np.random.randint(50, 255, 3).tolist())
}
self.next_id += 1
# 处理未匹配的追踪
for track_id in unmatched_tracks:
self.tracks[track_id]['lost_count'] += 1
if self.tracks[track_id]['lost_count'] > 15:
del self.tracks[track_id]
def _update_masks_with_sam(self, image_pil):
"""只使用 SAM 更新 mask(框已经通过光流传播)"""
if len(self.tracks) == 0:
return
boxes = torch.stack([t['box'] for t in self.tracks.values()])
self.sam_predictor.set_image(image_pil)
masks = self.sam_predictor.predict(boxes)
for i, track_id in enumerate(self.tracks.keys()):
self.tracks[track_id]['mask'] = masks[i]
self.tracks[track_id]['age'] += 1
def _propagate_boxes(self, curr_frame):
"""使用光流传播边界框"""
for track_id, track in self.tracks.items():
new_box = self.flow_propagator.propagate_box(
self.prev_frame, curr_frame, track['box']
)
track['box'] = new_box
def _propagate_all(self, curr_frame):
"""使用光流传播框和 mask"""
for track_id, track in self.tracks.items():
# 传播框
new_box = self.flow_propagator.propagate_box(
self.prev_frame, curr_frame, track['box']
)
# 传播 mask
if self.use_dense_flow_for_mask:
# 使用稠密光流(更准确但更慢)
new_mask = self.flow_propagator.propagate_mask(
self.prev_frame, curr_frame, track['mask']
)
else:
# 使用简单的仿射变换(更快)
new_mask = self.flow_propagator.propagate_mask_simple(
track['box'], new_box, track['mask']
)
track['box'] = new_box
track['mask'] = new_mask
track['age'] += 1
def _age_tracks(self):
"""老化追踪"""
for tid in list(self.tracks.keys()):
self.tracks[tid]['age'] += 1
self.tracks[tid]['lost_count'] += 1
if self.tracks[tid]['lost_count'] > 15:
del self.tracks[tid]
def _match_detections(self, det_boxes, track_ids):
"""基于 IoU 匹配检测和追踪"""
if len(track_ids) == 0:
return [], list(range(len(det_boxes))), []
if len(det_boxes) == 0:
return [], [], track_ids
track_boxes = torch.stack([self.tracks[tid]['box'] for tid in track_ids])
iou_matrix = self._compute_iou(det_boxes, track_boxes)
matched = []
unmatched_dets = list(range(len(det_boxes)))
unmatched_tracks = list(track_ids)
while True:
if iou_matrix.numel() == 0 or len(unmatched_dets) == 0 or len(unmatched_tracks) == 0:
break
max_iou = iou_matrix.max()
if max_iou < self.iou_threshold:
break
max_idx = iou_matrix.argmax()
det_idx = (max_idx // iou_matrix.shape[1]).item()
track_idx = (max_idx % iou_matrix.shape[1]).item()
matched.append((det_idx, track_ids[track_idx]))
unmatched_dets.remove(det_idx)
unmatched_tracks.remove(track_ids[track_idx])
iou_matrix[det_idx, :] = 0
iou_matrix[:, track_idx] = 0
return matched, unmatched_dets, unmatched_tracks
def _compute_iou(self, boxes1, boxes2):
"""计算 IoU 矩阵"""
x1 = torch.max(boxes1[:, None, 0], boxes2[None, :, 0])
y1 = torch.max(boxes1[:, None, 1], boxes2[None, :, 1])
x2 = torch.min(boxes1[:, None, 2], boxes2[None, :, 2])
y2 = torch.min(boxes1[:, None, 3], boxes2[None, :, 3])
inter = (x2 - x1).clamp(min=0) * (y2 - y1).clamp(min=0)
area1 = (boxes1[:, 2] - boxes1[:, 0]) * (boxes1[:, 3] - boxes1[:, 1])
area2 = (boxes2[:, 2] - boxes2[:, 0]) * (boxes2[:, 3] - boxes2[:, 1])
union = area1[:, None] + area2[None, :] - inter
return inter / (union + 1e-6)
def _visualize(self, frame):
"""可视化结果"""
result = frame.copy()
for track_id, track in self.tracks.items():
color = track['color']
# 绘制掩码
mask = track['mask'].cpu().numpy().astype(bool)
colored_mask = np.zeros_like(result)
colored_mask[mask] = color
result = cv2.addWeighted(result, 0.7, colored_mask, 0.3, 0)
# 绘制边界框
box = track['box'].int().tolist()
cv2.rectangle(result, (box[0], box[1]), (box[2], box[3]), color, 2)
# 绘制ID和类别
label = f"ID:{track_id} {track['class']}"
label_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.6, 2)[0]
cv2.rectangle(result, (box[0], box[1] - label_size[1] - 10),
(box[0] + label_size[0], box[1]), color, -1)
cv2.putText(result, label, (box[0], box[1] - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 255, 255), 2)
# 显示帧信息
info_text = f"Frame: {self.frame_count} | Objects: {len(self.tracks)}"
cv2.putText(result, info_text, (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2)
# # 显示帧类型
# if self.frame_count % self.detection_interval == 1:
# frame_type = "DETECT"
# type_color = (0, 0, 255)
# elif self.frame_count % self.segmentation_interval == 1:
# frame_type = "SEGMENT"
# type_color = (0, 255, 255)
# else:
# frame_type = "PROPAGATE"
# type_color = (0, 255, 0)
# cv2.putText(result, frame_type, (10, 60),
# cv2.FONT_HERSHEY_SIMPLEX, 0.6, type_color, 2)
return result
def _box_convert(self, boxes, width, height):
"""转换边界框格式"""
if len(boxes) == 0:
return torch.zeros((0, 4))
boxes = boxes * torch.Tensor([width, height, width, height])
xyxy = torch.zeros_like(boxes)
xyxy[:, 0] = boxes[:, 0] - boxes[:, 2] / 2
xyxy[:, 1] = boxes[:, 1] - boxes[:, 3] / 2
xyxy[:, 2] = boxes[:, 0] + boxes[:, 2] / 2
xyxy[:, 3] = boxes[:, 1] + boxes[:, 3] / 2
return xyxy
def _print_stats(self, total_time):
"""打印统计信息"""
print("\n" + "=" * 50)
print("处理统计")
print("=" * 50)
total_frames = self.frame_count
print(f"总帧数: {total_frames}")
print(f"总处理时间: {total_time:.2f}s")
print(f"平均帧率: {total_frames / (total_time + 1e-6):.2f} FPS")
print("-" * 50)
print("帧类型分布:")
print(f" 检测帧: {self.stats['detection_frames']} "
f"({self.stats['detection_frames']/total_frames*100:.1f}%)")
print(f" 分割帧: {self.stats['segmentation_frames']} "
f"({self.stats['segmentation_frames']/total_frames*100:.1f}%)")
print(f" 传播帧: {self.stats['propagation_frames']} "
f"({self.stats['propagation_frames']/total_frames*100:.1f}%)")
print("-" * 50)
print("各类型平均耗时:")
if self.stats['detection_frames'] > 0:
avg_det = self.stats['detection_time'] / self.stats['detection_frames']
print(f" 检测帧: {avg_det:.4f}s/帧 ({1/avg_det:.2f} FPS)")
if self.stats['segmentation_frames'] > 0:
avg_seg = self.stats['segmentation_time'] / self.stats['segmentation_frames']
print(f" 分割帧: {avg_seg:.4f}s/帧 ({1/avg_seg:.2f} FPS)")
if self.stats['propagation_frames'] > 0:
avg_prop = self.stats['propagation_time'] / self.stats['propagation_frames']
print(f" 传播帧: {avg_prop:.4f}s/帧 ({1/avg_prop:.2f} FPS)")
def load_image_from_frame(frame):
"""从视频帧加载图像"""
import groundingdino.datasets.transforms as T
image_pil = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
transform = T.Compose([
T.RandomResize([800], max_size=1333),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
image_transformed, _ = transform(image_pil, None)
image_np = np.array(image_pil)
return image_np, image_transformed
# ==================== 配置 ====================
VIDEO_PATH = "test.avi" # 输入视频路径
TEXT_PROMPT = "A child is riding a bicycle." # 文本提示
OUTPUT_PATH = "output_optimized.mp4" # 输出视频路径
# 模型配置
GD_CONFIG = "GroundingDINO_SwinT_OGC.py"
GD_WEIGHTS = "../grounded_sam_ov/weights/groundingdino_swint_ogc.pth"
ES_WEIGHTS = "../EfficientSAM/weights/efficient_sam_vitt.pt"
ES_OV_MODEL = "../ov_models_efficientsam/efficient_sam_vitt_encoder.xml"
DEVICE_OV = "GPU"
# 优化参数
DETECTION_INTERVAL = 10 # 每10帧检测一次
SEGMENTATION_INTERVAL = 3 # 每3帧分割一次
USE_DENSE_FLOW = False # 是否使用稠密光流传播 mask
BOX_THRESHOLD = 0.45
NMS_THRESHOLD = 0.3
def run_video_segmentation():
print("=" * 60)
print(f"优化策略:")
print(f" 1. 检测间隔: 每 {DETECTION_INTERVAL} 帧检测一次")
print(f" 2. 分割间隔: 每 {SEGMENTATION_INTERVAL} 帧分割一次")
print(f" 3. 其余帧: 使用光流传播")
print(f" 4. 稠密光流传播 mask: {'启用' if USE_DENSE_FLOW else '禁用(使用仿射变换)'}")
print("=" * 60)
# 1. 加载 GroundingDINO
print("\n1. 加载 GroundingDINO...")
gd_model = load_model(GD_CONFIG, GD_WEIGHTS)
# 2. 加载 EfficientSAM
print("2. 加载 EfficientSAM (OpenVINO)...")
core = ov.Core()
if not os.path.exists(ES_OV_MODEL):
print(f"错误: 找不到 {ES_OV_MODEL}")
return
compiled_es_encoder = core.compile_model(ES_OV_MODEL, device_name=DEVICE_OV)
es_pytorch = build_efficient_sam_vitt(checkpoint=ES_WEIGHTS)
es_pytorch.eval()
predictor = OpenVINOEfficientSAMPredictor(es_pytorch, compiled_es_encoder)
# 3. 创建优化版追踪器
print("3. 初始化优化版追踪器...")
tracker = OptimizedVideoTracker(
gd_model=gd_model,
sam_predictor=predictor,
detection_interval=DETECTION_INTERVAL,
segmentation_interval=SEGMENTATION_INTERVAL,
nms_threshold=NMS_THRESHOLD, # 添加NMS
box_threshold=BOX_THRESHOLD, # 提高检测阈值
use_dense_flow_for_mask=USE_DENSE_FLOW
)
# 4. 处理视频
print("4. 开始处理视频...\n")
tracker.process_video(
video_path=VIDEO_PATH,
text_prompt=TEXT_PROMPT,
output_path=OUTPUT_PATH
)
print("\n" + "=" * 60)
print("处理完成!")
print("=" * 60)
if __name__ == "__main__":
run_video_segmentation()输出:
output_optimized
为了简要对比原始 EfficientSAM 和 OpenVINO 加速版本的推理速度,做了个脚本:
python
#!/usr/bin/env python3
"""
对比原始 EfficientSAM 和 OpenVINO 加速版本的推理速度 输出 speed_comparison_results、efficientam_speed_comparison.txt
"""
import time
import cv2
import numpy as np
import torch
from PIL import Image
import openvino as ov
import os
import sys
from torchvision.transforms import ToTensor, Normalize
# --- 路径设置 ---
sys.path.append(os.path.join(os.path.dirname(__file__), '../GroundingDINO_main'))
sys.path.append(os.path.join(os.path.dirname(__file__), '../EfficientSAM'))
from groundingdino.util.inference import load_model, load_image, predict
from efficient_sam.build_efficient_sam import build_efficient_sam_vitt
# --- 配置 ---
IMAGE_PATH = "test.jpg"
TEXT_PROMPT = "horses ."
GD_CONFIG = "GroundingDINO_SwinT_OGC.py"
GD_WEIGHTS = "../grounded_sam_ov/weights/groundingdino_swint_ogc.pth"
ES_WEIGHTS = "../EfficientSAM/weights/efficient_sam_vitt.pt"
ES_OV_MODEL = "../ov_models_efficientsam/efficient_sam_vitt_encoder.xml"
DEVICE_OV = "CPU" # 使用GPU加速
test_iterations = 30 # 每个测试运行的迭代次数
# --- 辅助类 ---
class OriginalEfficientSAMPredictor:
"""原始 EfficientSAM 预测器"""
def __init__(self, model):
self.model = model
self.normalize = Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
self.original_size = None
self.features = None
def set_image(self, image_pil):
"""设置输入图像"""
self.original_size = image_pil.size
# 预处理
tensor = ToTensor()(image_pil.resize((1024, 1024), resample=Image.BICUBIC))
tensor = self.normalize(tensor).unsqueeze(0)
# 提取特征
with torch.no_grad():
self.features = self.model.image_encoder(tensor)
def predict(self, boxes):
"""预测掩码"""
batch_size = boxes.shape[0]
# 转换边界框到 1024x1024 空间
boxes_1024 = boxes.clone()
boxes_1024[:, 0] = boxes_1024[:, 0] * (1024.0 / self.original_size[0])
boxes_1024[:, 1] = boxes_1024[:, 1] * (1024.0 / self.original_size[1])
boxes_1024[:, 2] = boxes_1024[:, 2] * (1024.0 / self.original_size[0])
boxes_1024[:, 3] = boxes_1024[:, 3] * (1024.0 / self.original_size[1])
box_points = boxes_1024.reshape(-1, 2, 2)
box_labels = torch.tensor([[2, 3]], dtype=torch.float32).repeat(batch_size, 1)
batched_points = box_points.unsqueeze(1)
batched_labels = box_labels.unsqueeze(1)
with torch.no_grad():
# 为每个检测到的物体复制一份图像特征
batched_features = self.features.repeat(batch_size, 1, 1, 1)
low_res_masks, _ = self.model.predict_masks(
image_embeddings=batched_features,
batched_points=batched_points,
batched_point_labels=batched_labels,
multimask_output=False,
input_h=1024,
input_w=1024,
output_h=1024,
output_w=1024
)
# 后处理 - 调整形状
low_res_masks = low_res_masks.squeeze(1)
if low_res_masks.dim() == 4:
low_res_masks = low_res_masks[:, 0, :, :]
masks = torch.nn.functional.interpolate(
low_res_masks.unsqueeze(1),
size=self.original_size[::-1],
mode="bilinear",
align_corners=False
)
masks = masks.squeeze(1) > 0.5
return masks
class OpenVINOEfficientSAMPredictor:
"""OpenVINO 加速的 EfficientSAM 预测器"""
def __init__(self, pytorch_model, ov_encoder):
self.model = pytorch_model
self.ov_encoder = ov_encoder
self.normalize = Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
self.original_size = None
self.features = None
self.scale = None
self.valid_w = None
self.valid_h = None
def preprocess_image(self, image_pil):
w, h = image_pil.size
self.original_size = (w, h)
# 计算缩放
scale = 1024.0 / max(w, h)
new_w, new_h = int(w * scale), int(h * scale)
self.valid_w = new_w
self.valid_h = new_h
self.scale = scale
# 预处理
image_resized = image_pil.resize((new_w, new_h), resample=Image.BICUBIC)
tensor = ToTensor()(image_resized)
tensor = self.normalize(tensor)
# 填充到 1024x1024
pad_w = 1024 - new_w
pad_h = 1024 - new_h
tensor = torch.nn.functional.pad(tensor, (0, pad_w, 0, pad_h), value=0)
return tensor.unsqueeze(0)
def set_image(self, image_pil):
input_tensor = self.preprocess_image(image_pil)
input_numpy = input_tensor.numpy().astype(np.float32)
# OpenVINO 推理
results = self.ov_encoder(input_numpy)[0]
self.features = torch.tensor(results).reshape(1, 256, 64, 64)
def predict(self, boxes):
batch_size = boxes.shape[0]
with torch.no_grad():
# 转换边界框到 1024x1024 空间
boxes_1024 = boxes.clone()
boxes_1024[:, 0] = boxes_1024[:, 0] * (1024.0 / self.original_size[0])
boxes_1024[:, 1] = boxes_1024[:, 1] * (1024.0 / self.original_size[1])
boxes_1024[:, 2] = boxes_1024[:, 2] * (1024.0 / self.original_size[0])
boxes_1024[:, 3] = boxes_1024[:, 3] * (1024.0 / self.original_size[1])
box_points = boxes_1024.reshape(-1, 2, 2)
box_labels = torch.tensor([[2, 3]], dtype=torch.float32).repeat(batch_size, 1)
batched_points = box_points.unsqueeze(1)
batched_labels = box_labels.unsqueeze(1)
# 为每个检测到的物体复制一份图像特征
batched_features = self.features.repeat(batch_size, 1, 1, 1)
# 解码 Mask
low_res_masks, iou_predictions = self.model.predict_masks(
image_embeddings=batched_features,
batched_points=batched_points,
batched_point_labels=batched_labels,
multimask_output=False,
input_h=1024,
input_w=1024,
output_h=1024,
output_w=1024
)
# 后处理
# 后处理 - 调整形状
low_res_masks = low_res_masks.squeeze(1)
if low_res_masks.dim() == 4:
low_res_masks = low_res_masks[:, 0, :, :]
# 裁剪到有效区域
masks_cropped = low_res_masks[:, :self.valid_h, :self.valid_w].unsqueeze(1)
masks = torch.nn.functional.interpolate(
masks_cropped,
size=self.original_size[::-1],
mode="bilinear",
align_corners=False
)
masks = masks.squeeze(1) > 0.5
return masks
def box_convert_gd_to_xyxy(boxes, width, height):
"""GroundingDINO (cx, cy, w, h) norm -> (x1, y1, x2, y2) abs"""
boxes = boxes * torch.Tensor([width, height, width, height])
xyxy = torch.zeros_like(boxes)
xyxy[:, 0] = boxes[:, 0] - boxes[:, 2] / 2
xyxy[:, 1] = boxes[:, 1] - boxes[:, 3] / 2
xyxy[:, 2] = boxes[:, 0] + boxes[:, 2] / 2
xyxy[:, 3] = boxes[:, 1] + boxes[:, 3] / 2
return xyxy
def visualize_and_save_result(image_source, boxes_xyxy, masks, version, iteration, save_folder):
"""可视化并保存推理结果图"""
# 创建副本以避免修改原图
image = image_source.copy()
# 为每个掩码使用不同颜色
colors = [(255, 0, 0), (0, 255, 0), (0, 0, 255), (255, 255, 0), (255, 0, 255)]
for i, (box, mask) in enumerate(zip(boxes_xyxy, masks)):
color = colors[i % len(colors)]
# 绘制边界框
x1, y1, x2, y2 = map(int, box)
cv2.rectangle(image, (x1, y1), (x2, y2), color, 2)
# 绘制掩码
mask_np = mask.cpu().numpy().astype(np.uint8)
colored_mask = np.zeros_like(image)
colored_mask[mask_np == 1] = color
image = cv2.addWeighted(image, 0.8, colored_mask, 0.2, 0)
# 添加标签
cv2.putText(image, f"Object {i+1}", (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
# 添加版本信息
cv2.putText(image, f"Version: {version}", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
# 保存图像
filename = f"{version}_iteration_{iteration+1}.jpg"
save_path = os.path.join(save_folder, filename)
cv2.imwrite(save_path, image)
print(f" 结果已保存到: {save_path}")
def main():
"""主函数"""
# 创建保存结果的文件夹
save_folder = "speed_comparison_results"
os.makedirs(save_folder, exist_ok=True)
print("=" * 60)
print("EfficientSAM 推理速度对比 (原始 vs OpenVINO 加速)")
print("=" * 60)
print(f"测试图片: {IMAGE_PATH}")
print(f"测试迭代次数: {test_iterations}")
print(f"使用设备: {DEVICE_OV}")
print(f"结果保存文件夹: {save_folder}")
print("=" * 60)
# 1. 加载 GroundingDINO 用于目标检测
print("1. 加载 GroundingDINO...")
gd_model = load_model(GD_CONFIG, GD_WEIGHTS)
# 2. 加载测试图片并检测目标
image_source, image_tensor = load_image(IMAGE_PATH)
image_pil = Image.fromarray(cv2.cvtColor(image_source, cv2.COLOR_BGR2RGB))
print("2. 目标检测...")
boxes, logits, phrases = predict(
model=gd_model,
image=image_tensor,
caption=TEXT_PROMPT,
box_threshold=0.35,
text_threshold=0.25,
device="cpu"
)
print(f" 检测到 {len(boxes)} 个物体: {set(phrases)}")
H, W = image_source.shape[:2]
boxes_xyxy = box_convert_gd_to_xyxy(boxes, W, H)
# 3. 初始化原始 EfficientSAM
print("3. 初始化原始 EfficientSAM...")
original_sam = build_efficient_sam_vitt(checkpoint=ES_WEIGHTS)
original_sam.eval()
original_predictor = OriginalEfficientSAMPredictor(original_sam)
# 4. 初始化 OpenVINO 加速的 EfficientSAM
print("4. 初始化 OpenVINO 加速的 EfficientSAM...")
core = ov.Core()
if not os.path.exists(ES_OV_MODEL):
print(f"错误: 找不到 {ES_OV_MODEL}")
print("请先运行 convert_efficientsam.py 转换模型")
return
compiled_es_encoder = core.compile_model(ES_OV_MODEL, device_name=DEVICE_OV)
ov_sam = build_efficient_sam_vitt(checkpoint=ES_WEIGHTS)
ov_sam.eval()
ov_predictor = OpenVINOEfficientSAMPredictor(ov_sam, compiled_es_encoder)
# 5. 预热运行
print("\n5. 预热运行...")
original_predictor.set_image(image_pil)
original_predictor.predict(boxes_xyxy)
ov_predictor.set_image(image_pil)
ov_predictor.predict(boxes_xyxy)
# 6. 速度对比测试
print("\n6. 速度对比测试...")
print(" -" * 30)
# 原始 EfficientSAM 测试
original_times = []
for i in range(test_iterations):
print(f" 原始 EfficientSAM - 迭代 {i+1}/{test_iterations}...")
# 特征提取时间
start = time.time()
original_predictor.set_image(image_pil)
feature_time = time.time() - start
# Mask 生成时间
start = time.time()
masks = original_predictor.predict(boxes_xyxy)
mask_time = time.time() - start
total_time = feature_time + mask_time
original_times.append((feature_time, mask_time, total_time))
print(f" 特征提取: {feature_time:.4f}s")
print(f" Mask 生成: {mask_time:.4f}s")
print(f" 总耗时: {total_time:.4f}s")
# 保存推理结果图
visualize_and_save_result(image_source, boxes_xyxy, masks, "Original", i, save_folder)
print(" -" * 30)
# OpenVINO 加速版本测试
ov_times = []
for i in range(test_iterations):
print(f" OpenVINO 加速 - 迭代 {i+1}/{test_iterations}...")
# 特征提取时间
start = time.time()
ov_predictor.set_image(image_pil)
feature_time = time.time() - start
# Mask 生成时间
start = time.time()
masks = ov_predictor.predict(boxes_xyxy)
mask_time = time.time() - start
total_time = feature_time + mask_time
ov_times.append((feature_time, mask_time, total_time))
print(f" 特征提取: {feature_time:.4f}s")
print(f" Mask 生成: {mask_time:.4f}s")
print(f" 总耗时: {total_time:.4f}s")
# 保存推理结果图
visualize_and_save_result(image_source, boxes_xyxy, masks, "OpenVINO", i, save_folder)
# 7. 计算统计数据
print("\n7. 性能分析...")
print(" -" * 30)
# 原始版本统计
original_feature_avg = np.mean([t[0] for t in original_times])
original_mask_avg = np.mean([t[1] for t in original_times])
original_total_avg = np.mean([t[2] for t in original_times])
# OpenVINO 版本统计
ov_feature_avg = np.mean([t[0] for t in ov_times])
ov_mask_avg = np.mean([t[1] for t in ov_times])
ov_total_avg = np.mean([t[2] for t in ov_times])
# 加速比
feature_speedup = original_feature_avg / ov_feature_avg if ov_feature_avg > 0 else 0
mask_speedup = original_mask_avg / ov_mask_avg if ov_mask_avg > 0 else 0
total_speedup = original_total_avg / ov_total_avg if ov_total_avg > 0 else 0
# 结果输出
print(f" {'性能指标':<25} {'原始版本 (平均值)':<20} {'OpenVINO 版本 (平均值)':<25} {'加速比':<10}")
print(f" {'-'*65}")
print(f" {'特征提取时间':<25} {original_feature_avg:.4f}s {' ':>4} {ov_feature_avg:.4f}s {' ':>10} {feature_speedup:.2f}x")
print(f" {'Mask 生成时间':<25} {original_mask_avg:.4f}s {' ':>4} {ov_mask_avg:.4f}s {' ':>10} {mask_speedup:.2f}x")
print(f" {'总推理时间':<25} {original_total_avg:.4f}s {' ':>4} {ov_total_avg:.4f}s {' ':>10} {total_speedup:.2f}x")
print(f" {'-'*65}")
# 8. 总结
print("\n8. 总结")
print(" -" * 30)
print(f" 测试图片分辨率: {W}x{H}")
print(f" 检测到的物体数量: {len(boxes)}")
print(f" 平均总加速比: {total_speedup:.2f}x")
if total_speedup > 1.5:
print(f"OpenVINO 加速效果显著,总推理时间减少了 {((total_speedup-1)/total_speedup*100):.1f}%")
elif total_speedup > 1.0:
print(f"OpenVINO 实现了 {total_speedup:.2f}x 的加速")
else:
print(f"OpenVINO 加速效果不明显")
print(f"详细结果已保存到: efficientam_speed_comparison.txt")
# 保存详细结果到文件
with open("efficientam_speed_comparison.txt", "w") as f:
f.write("EfficientSAM 推理速度对比报告\n")
f.write("=" * 60 + "\n")
f.write(f"测试图片: {IMAGE_PATH}\n")
f.write(f"图片分辨率: {W}x{H}\n")
f.write(f"检测到的物体数量: {len(boxes)}\n")
f.write(f"测试迭代次数: {test_iterations}\n")
f.write(f"使用设备: {DEVICE_OV}\n")
f.write("=" * 60 + "\n\n")
f.write("原始 EfficientSAM 详细结果:\n")
f.write("迭代 | 特征提取 (s) | Mask 生成 (s) | 总耗时 (s)\n")
f.write("-" * 50 + "\n")
for i, (ft, mt, tt) in enumerate(original_times):
f.write(f"{i+1:3d} | {ft:14.4f} | {mt:13.4f} | {tt:10.4f}\n")
f.write("-" * 50 + "\n")
f.write(f"平均 | {original_feature_avg:14.4f} | {original_mask_avg:13.4f} | {original_total_avg:10.4f}\n\n")
f.write("OpenVINO 加速 EfficientSAM 详细结果:\n")
f.write("迭代 | 特征提取 (s) | Mask 生成 (s) | 总耗时 (s)\n")
f.write("-" * 50 + "\n")
for i, (ft, mt, tt) in enumerate(ov_times):
f.write(f"{i+1:3d} | {ft:14.4f} | {mt:13.4f} | {tt:10.4f}\n")
f.write("-" * 50 + "\n")
f.write(f"平均 | {ov_feature_avg:14.4f} | {ov_mask_avg:13.4f} | {ov_total_avg:10.4f}\n\n")
f.write("性能对比:\n")
f.write("指标 | 原始版本 | OpenVINO 版本 | 加速比\n")
f.write("-" * 45 + "\n")
f.write(f"特征提取 | {original_feature_avg:.4f}s | {ov_feature_avg:.4f}s | {feature_speedup:.2f}x\n")
f.write(f"Mask 生成 | {original_mask_avg:.4f}s | {ov_mask_avg:.4f}s | {mask_speedup:.2f}x\n")
f.write(f"总耗时 | {original_total_avg:.4f}s | {ov_total_avg:.4f}s | {total_speedup:.2f}x\n")
f.write("-" * 45 + "\n")
f.write(f"加速比: {total_speedup:.2f}x\n")
f.write(f"推理时间减少: {((total_speedup-1)/total_speedup*100):.1f}%\n")
if __name__ == "__main__":
main()openvino优化前后模型推理速度对比:

本文工作总结:
- 端到端文本驱动:用户只需输入自然语言描述,无需标注
- 混合推理架构:OpenVINO 加速 Encoder + PyTorch Decoder
- 智能帧调度:根据计算复杂度动态分配资源
- 光流追踪融合:结合传统 CV 与深度学习优势
- 完整的评估体系:速度对比、统计分析、可视化输出
以上为全部内容!