1. 架构总览:谁负责什么
物化表的创建与运行不是"单点能力",而是一个端到端链路 。
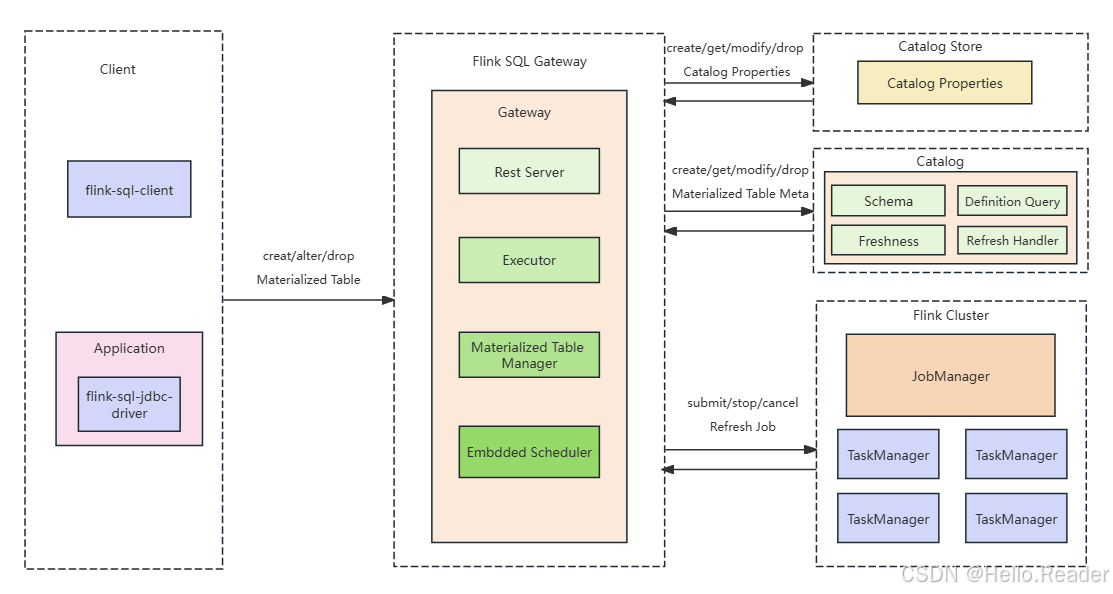
1.1 组件清单(对应架构图)
-
Client(客户端)
-
任何能连 Flink SQL Gateway 的客户端都可以:
flink-sql-client- 应用侧
flink-sql-jdbc-driver(JDBC)
-
-
Flink SQL Gateway(核心入口 + 编排中枢)
- 接收
CREATE/ALTER/DROP MATERIALIZED TABLE - 内部关键模块(架构图中 Gateway 内部):
2.1Rest Server:对外提供 REST 入口
2.2Executor:执行 SQL、协调执行上下文
2.3Materialized Table Manager:管理物化表生命周期、刷新管道
2.4Embedded Scheduler:FULL 模式定时调度刷新作业(当前仅支持内置调度器)
- 接收
-
Catalog(元数据中心)
-
负责物化表元数据的创建/查询/修改/删除
-
物化表元数据关键项(架构图中 Catalog 内):
Schema(从 AS 查询推导)Definition Query(AS 查询定义)Freshness(新鲜度目标)Refresh Handler(刷新处理器/刷新管道关联信息)
-
-
Catalog Store(Catalog 属性持久化)
- 用于持久化 Catalog Properties
- SQL Gateway 启动时可自动初始化 Catalog,从而支撑物化表相关操作的元数据读取
-
Flink Cluster(执行引擎)
-
物化表刷新作业最终都运行在 Flink 集群:
- JobManager + TaskManager
-
SQL Gateway 负责对 Flink Cluster 做:
submit/stop/cancel refresh job
-
2. 部署前准备:集群与能力边界
2.1 Flink Cluster 环境支持
物化表刷新作业目前支持运行在以下集群环境:
- Standalone Cluster
- YARN Cluster
- Kubernetes Cluster
2.2 重要前提:Catalog 支持
-
创建 Materialized Table 的 Catalog 能力是前置条件
-
当前说明里提到:只有 Paimon Catalog 支持创建物化表
也意味着:你要先把 Catalog 选型与配置搞定(Paimon 是当前主线)。
3. SQL Gateway 部署:Catalog Store 与调度器必配
物化表必须通过 SQL Gateway 创建;并且要"可持续运维",就必须把 Catalog 属性持久化 + FULL 定时调度能力配齐。
3.1 配置 Catalog Store(用于持久化 Catalog Properties)
在 config.yaml 增加 catalog-store 配置,例如文件型 store:
yaml
table:
catalog-store:
kind: file
file:
path: {path_to_catalog_store} # 替换成实际路径作用:
- 持久化 catalog properties
- SQL Gateway 重启后仍可自动初始化 catalogs,保证物化表元数据可读、可管、可恢复
3.2 配置 Workflow Scheduler 插件(FULL 模式定时刷新)
在 config.yaml 增加:
yaml
workflow-scheduler:
type: embedded说明:
- 当前仅支持
embedded内置调度器 - FULL 模式的"周期刷新"就是依赖这个调度器触发批作业
3.3 启动 SQL Gateway
使用脚本启动:
bash
./sql-gateway.sh start4. 操作指南:连接 Gateway 与创建物化表
4.1 使用 SQL Client 连接 SQL Gateway
bash
./sql-client.sh gateway --endpoint {gateway_endpoint}:{gateway_port}4.2 创建 Materialized Table(通用姿势)
你可以在连接后执行:
sql
CREATE MATERIALIZED TABLE my_materialized_table
...
AS
SELECT ...;物化表的刷新作业"跑在哪里",由你当前会话的
execution.mode等参数决定(下一节展开)。
5. 刷新作业运行模式:remote / session / application(YARN & K8s)
关键理解:你创建物化表时的执行模式,会影响刷新作业提交到哪个集群形态 。
同时,相关集群信息会写入 Catalog,后续 suspend/resume 不需要重复设置。
5.1 Standalone(Remote)模式
示例:
sql
SET 'execution.mode' = 'remote';然后创建物化表:
sql
CREATE MATERIALIZED TABLE my_materialized_table
... ;5.2 Session 模式(需要预先创建 Session 集群)
Session 模式要求你先按官方方式启动 session cluster。
5.2.1 Kubernetes Session
sql
SET 'execution.mode' = 'kubernetes-session';
SET 'kubernetes.cluster-id' = 'flink-cluster-mt-session-1';
CREATE MATERIALIZED TABLE my_materialized_table
... ;要求:
kubernetes.cluster-id必须指向一个已存在的 K8s session cluster
5.2.2 YARN Session
sql
SET 'execution.mode' = 'yarn-session';
SET 'yarn.application.id' = 'application-xxxx';
CREATE MATERIALIZED TABLE my_materialized_table
... ;要求:
yarn.application.id必须是一个已存在的 YARN session application
5.3 Application 模式(提交即拉起独立集群)
5.3.1 Kubernetes Application
sql
SET 'execution.mode' = 'kubernetes-application';
SET 'kubernetes.cluster-id' = 'flink-cluster-mt-application-1'; -- 可选,不写会自动生成
CREATE MATERIALIZED TABLE my_materialized_table
... ;5.3.2 YARN Application
sql
SET 'execution.mode' = 'yarn-application';
CREATE MATERIALIZED TABLE my_materialized_table
... ;说明:
- yarn application 模式下 不需要手动设置
yarn.application.id - 提交时会自动生成并运行
5.4 维护友好点:集群信息会被持久化
文档明确指出:
execution.mode、kubernetes.cluster-id等集群信息会写入 catalog- 你后续
SUSPEND/RESUME不需要重新设置这些参数
这对"运维闭环"非常关键:不会因为换了一个终端/会话就恢复不了作业。
6. 运维操作:挂起、恢复、手动刷新、改查询
6.1 Suspend:暂停刷新作业
sql
ALTER MATERIALIZED TABLE my_materialized_table SUSPEND;6.2 Resume:恢复刷新作业
sql
ALTER MATERIALIZED TABLE my_materialized_table RESUME;6.3 Modify Query:修改物化表查询定义(ALTER ... AS)
sql
ALTER MATERIALIZED TABLE my_materialized_table
AS
SELECT
...
;7. 生产实践建议与易踩坑点
7.1 必做清单
- SQL Gateway 必须部署:物化表只能通过 Gateway 创建
- Catalog Store 必配:否则重启后 catalog properties 不可自动初始化,影响物化表运维闭环
- FULL 模式必配 embedded scheduler:否则"周期刷新"无从触发
- 优先使用 Paimon Catalog(当前创建物化表能力要求)
7.2 会话侧参数与持久化边界
- 创建时设置的
execution.mode / cluster-id / yarn app id会被持久化 - 后续 suspend/resume 不需要重复设置
- 建议:把创建物化表的"标准会话参数"固化成脚本/Runbook,减少人为偏差
7.3 运维建议
-
建立统一的"物化表 Runbook":
- 如何连接 gateway
- 如何判断运行模式
- 如何 suspend/resume/改查询
- 如何定位刷新作业在 Flink 集群中的 job 信息(你们内部可结合监控平台/日志体系补齐)