1. Transformer 网络架构
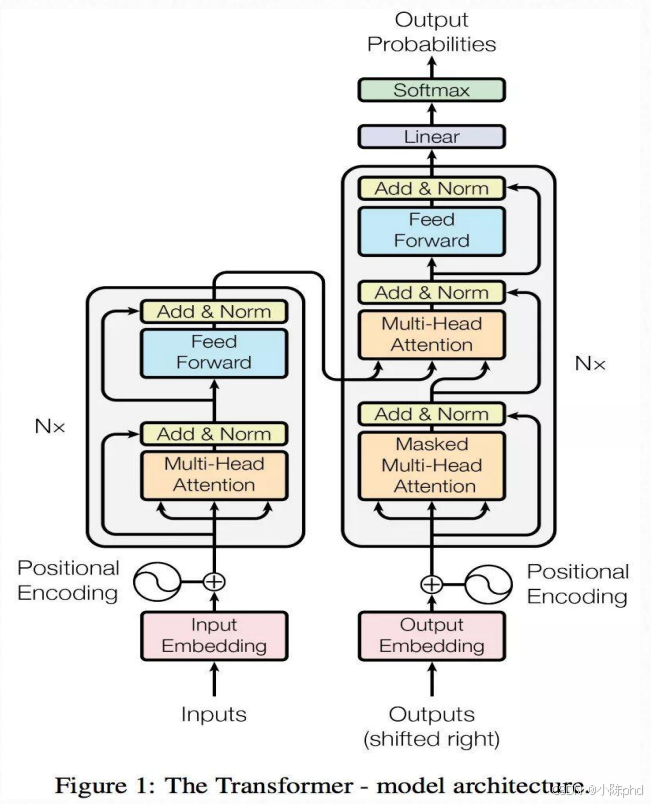
这幅图是Transformer模型的核心架构图(源自经典论文《Attention Is All You Need》),同时补充了自注意力机制的计算逻辑,完整展示了Transformer的结构组成与核心模块的工作原理,是大语言模型(如GPT、BERT)的基础架构。
1.1 整体结构:Encoder-Decoder(编码器-解码器)框架
Transformer由**左侧的Encoder(编码器)和右侧的Decoder(解码器)**两部分组成,是一个"输入→编码→解码→输出"的序列转换模型(常用于机器翻译、文本生成等任务):
- Encoder(左侧):接收原始输入序列(如待翻译的句子),将其编码为包含语义信息的向量表示;
- Decoder(右侧):接收Encoder的输出向量,结合已生成的部分输出序列(如已翻译的前半部分句子),生成最终的目标序列。
1.2 Encoder(编码器)的内部结构
Encoder由N个相同的层堆叠而成(论文中N=6),每一层包含2个核心子模块:
- Multi-Head Attention(多头注意力) :
- 核心作用:让模型同时关注输入序列的不同位置(如翻译时,同时关注"主语"和"修饰语");
- "多头":将输入分成多个子空间分别计算注意力,再合并结果,提升模型对复杂语义的捕捉能力。
- Feed Forward(前馈神经网络) :
- 核心作用:对多头注意力的输出做非线性变换,进一步提取特征;
- 结构:由两层线性层+ReLU激活函数组成,每一层的参数在不同位置共享。
- Add & Norm(残差连接+层归一化) :
- 每个子模块(多头注意力/前馈网络)的输出都会与模块的输入做"残差连接"(避免梯度消失),再通过"层归一化"(加速训练、稳定模型)。
- Positional Encoding(位置编码) :
- Transformer本身没有序列位置信息(不像RNN有时间步),因此在输入Embedding后添加"位置编码",让模型感知输入序列的顺序。
1.3 Decoder(解码器)的内部结构
Decoder同样由N个相同的层堆叠而成(论文中N=6),每一层包含3个核心子模块:
- Masked Multi-Head Attention(掩码多头注意力) :
- 核心作用:在生成输出序列时,只允许模型关注"已生成的部分"(如生成第3个词时,只能看前2个词),避免"提前看到未来的词";
- "掩码":通过遮挡未来位置的注意力权重,强制模型按顺序生成序列。
- Multi-Head Attention(多头注意力) :
- 核心作用:让Decoder同时关注Encoder输出的全局语义信息(如翻译时,结合原句的整体语义);
- 输入:Q(来自Decoder的掩码注意力输出)、K/V(来自Encoder的输出)。
- Feed Forward(前馈神经网络):与Encoder的前馈网络结构一致,对注意力输出做非线性变换。
- Add & Norm:与Encoder的残差连接+层归一化逻辑一致。
1.4 自注意力机制的计算逻辑
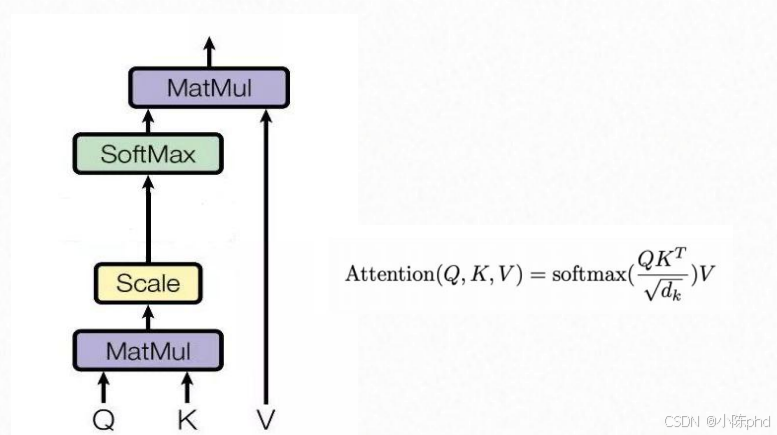
图展示了自注意力(Attention)的核心计算公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V
- Q(Query)、K(Key)、V(Value):由输入向量通过线性变换得到的三个矩阵,分别代表"查询""键""值";
- Q K T QK^T QKT:计算每个查询与所有键的相似度(注意力得分);
- 1 d k \frac{1}{\sqrt{d_k}} dk 1 :缩放因子( d k d_k dk是K的维度),避免相似度得分过大导致softmax后梯度消失(图中文字详细解释了其作用);
- softmax:将注意力得分转换为概率分布,代表每个位置的重要程度;
- 乘V:按注意力概率对V加权求和,得到最终的注意力输出。
缩放因子是为了归一化注意力得分的方差,防止 softmax 输出过于极端,保证模型训练的稳定性和注意力机制的有效性。
1.5 最终输出流程
Decoder的最后一层输出会经过:
- Linear(线性层):将Decoder的输出向量映射到目标词汇表的维度;
- Softmax:将线性层的输出转换为词汇表中每个词的概率,取概率最大的词作为最终输出。