Kimi最近提出了Kimi Linear ,这是一种混合线性注意力(Hybrid Linear Attention)架构。它首次在公平比较中,于短上下文、长上下文和强化学习(RL)等多种场景下,全面超越了全注意力(Full Attention)架构。
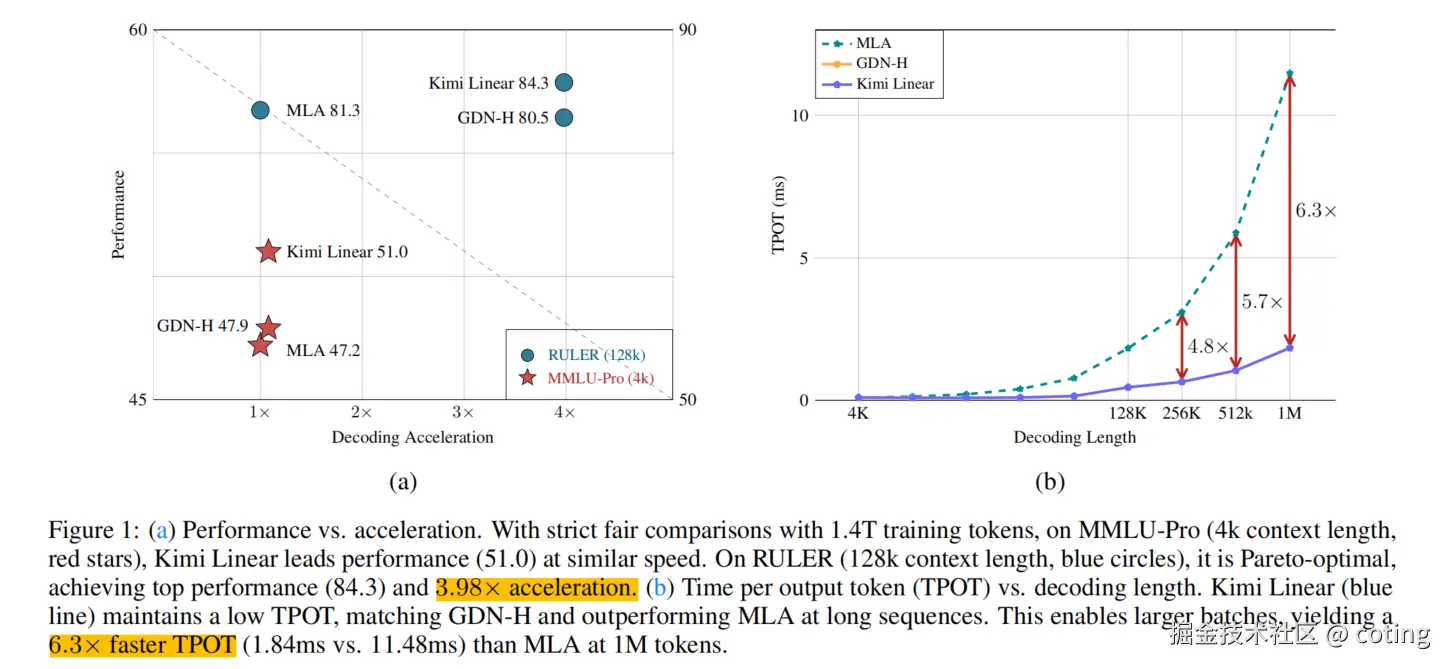
也就是说,Kimi Linear 证明了自己是全注意力架构的"即插即用"替代品,同时提供了更高的效率和更优的性能,下面就让我们具体来看一下怎么个事。
所有相关源码示例、流程图、面试八股、模型配置与知识库构建技巧,我也将持续更新在Github:AIHub,欢迎关注收藏!
一、核心技术创新点
Kimi Linear 架构的优越性来自于两个主要创新:Kimi Delta Attention (KDA) 模块和高效的硬件优化。
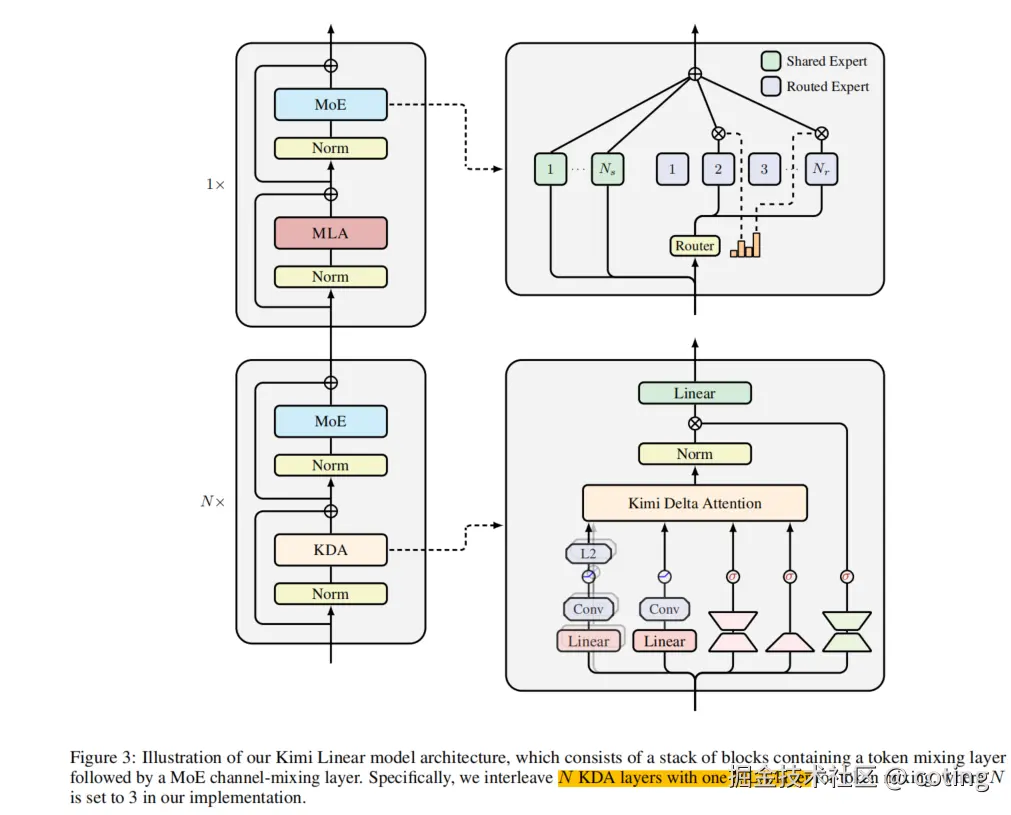
1. Kimi Delta Attention (KDA):更精细的门控机制
KDA 是 Kimi Linear 的核心线性注意力模块。

它建立在 Gated DeltaNet 的基础上,并进行了关键的改进:
- 精细化门控(Finer-Grained Gating): KDA 扩展了 DeltaNet,引入了更精细的门控机制。这使得模型能更有效地利用有限的 有限状态 RNN 内存(finite-state RNN memory)。这种改进对于捕获和处理长序列信息至关重要。
- 表达能力的增强: KDA 的设计目标是最大化线性注意力的表达能力,使其能够媲美甚至超越全注意力在各种任务上的表现。
2. 混合架构:KDA + 多头潜在注意力(MLA)
Kimi Linear 采用了一种层级混合 (layerwise hybrid)架构,将 KDA 与 Multi-Head Latent Attention (MLA) 结合起来:
- 协同作用: 这种混合设计旨在结合线性注意力的高效性 和全注意力(或其变体如 MLA)的强大表示能力。
- 模型配置: 预训练了一个 Kimi Linear 模型,其激活参数(Activated Params)为 3B ,总参数(Total Params)为 48B。这证明了其在大型模型训练中的可行性。
3. 硬件效率提升:定制的分块算法
为了实现实际部署中的高性能,开发了定制的分块算法(bespoke chunkwise algorithm):
- DPLR 变体: 该算法通过利用 Diagonal-Plus-Low-Rank (DPLR) 转换矩阵的一种专门变体来实现高硬件效率。
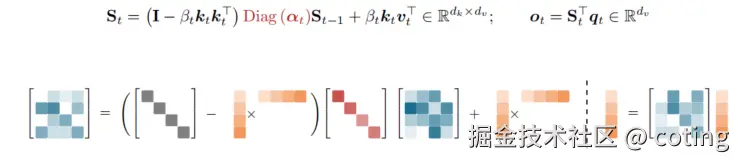
- 计算量大幅减少: 相比于通用 DPLR 公式,这种定制变体大幅减少了计算量 ,同时保持了与经典
 规则的一致性。
规则的一致性。 - 部署优势: 这种优化是实现 KV 缓存使用减少 75% 和 1M 上下文解码吞吐量提高 6 倍的关键。
二、性能基准
下表展示了 Kimi Linear-Base(MoE 48B Total Params)与 Moonlight-Base(MoE 16B Total Params)在多个基准测试中的性能对比。
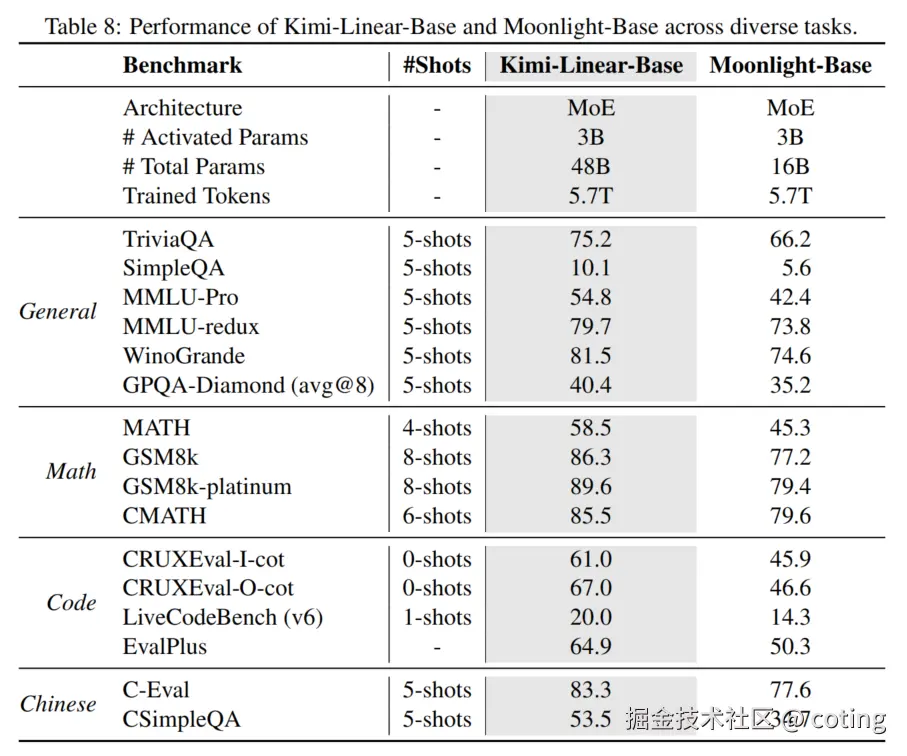
其中Kimi-Linear-Base 和 Moonlight-Base 均使用相同的 5.7T 训练 tokens。
可以看到Kimi Linear-Base 在所有评估的任务上均显著优于 Moonlight-Base(使用全注意力架构),这有力地证明了 KDA 和其混合架构的强大表示能力。
并且在性能上也大幅优于全注意力。
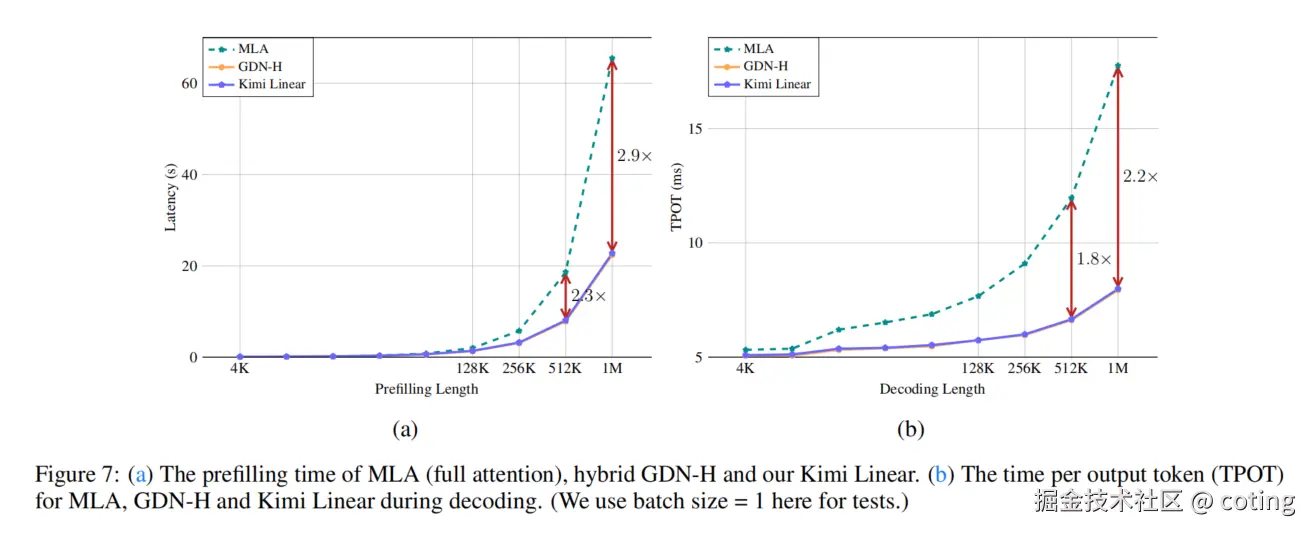
总结一下,Kimi Linear 的核心是 Kimi Delta Attention (KDA) 模块,它结合了创新的分块算法 (chunkwise algorithm)和硬件优化,不仅在所有评估任务上以显著优势击败了全注意力架构,还将 KV 缓存使用量减少了高达 75%,并在百万(1M)上下文长度下实现了高达 6 倍的解码吞吐量提升。
Kimi Linear 架构的诞生标志着语言模型架构进入了一个新阶段,我们不再需要在性能 (全注意力)和效率(线性注意力)之间做取舍。Kimi Linear 是一款高性能、高效率的线性注意力架构,可以作为全注意力架构的直接替代品。
关于AI和大模型相关的知识和前沿技术更新,请关注公众号 coting!