一文读懂深度学习:深度学习的前世今生
作者:Weisian | AI探索者 · 用通俗语言拆解硬核技术,理清深度学习的前世今生
如果你用过 ChatGPT 写文案、用 Midjourney 画插画,或是惊叹于 AI 能精准识别图片里的物体、听懂你的语音指令,那你其实已经在享受深度学习的技术红利了。
很多人觉得深度学习高深莫测,满是复杂的公式和术语,但它的核心逻辑特别简单------让计算机像人类大脑一样,通过多层网络从数据中自主学习规律,而不是靠人类手动编写规则。
今天,我就以"历史脉络 + 核心概念 + 关键突破"的逻辑,带你彻底搞懂深度学习,从它的诞生背景讲到如今的产业格局,再告诉你:它到底难不难?普通人该怎么学?

一、先搞懂核心:什么是深度学习?
在聊历史之前,我们先把最基础的概念掰扯明白,避免后面越听越懵。
1. 深度学习的本质定义
深度学习是机器学习的一个分支,核心是构建"深层神经网络"来模拟人类大脑的神经元连接结构。简单说,它就像一个"数据加工厂":
- 输入:图片、文字、语音等原始数据;
- 加工:通过多层网络(比如卷积层、全连接层)逐层提取特征------从边缘、纹理等简单特征,到物体、语义等复杂特征;
- 输出:分类结果(比如"这是一只猫")、生成内容(比如一首诗)、决策指令(比如自动驾驶的转向信号)。
它和传统编程最大的区别在于:
-
传统编程:人类写规则,计算机执行。
比如识别猫,你要手动写"有两只尖耳朵、圆脸蛋、胡须......"的 if-else 规则。

-
深度学习:人类给数据,计算机自己找规则。
给模型看上万张猫的图片,它会自动总结出"猫"的共性特征,甚至发现人类都忽略的细节。
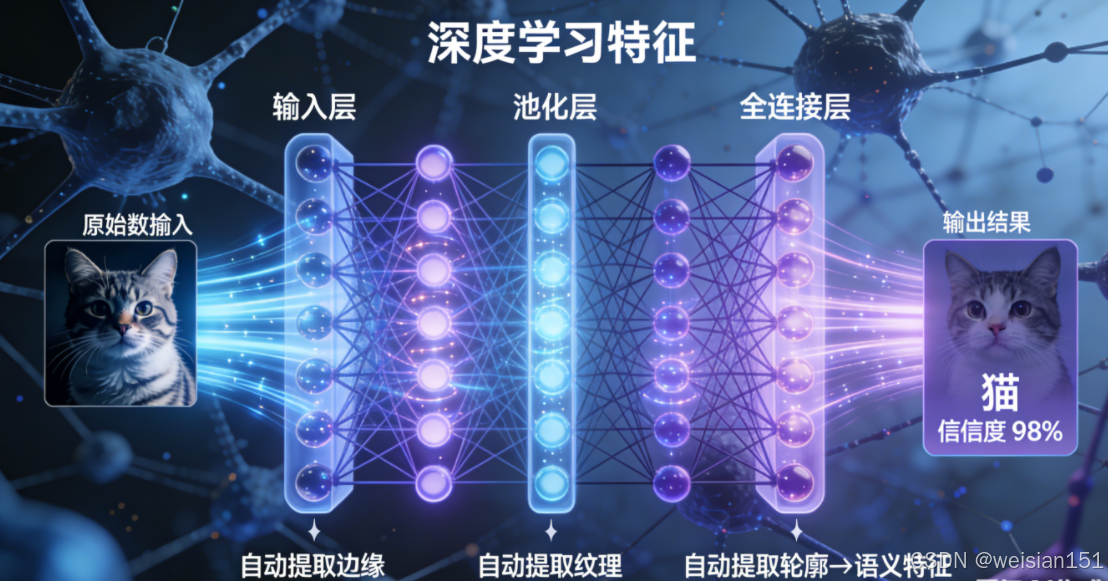
这种"从数据中自动学习"的能力,正是深度学习颠覆性的根源。

2. 必须分清的三个关键概念(避免混淆)
很多人会把 AI、机器学习、深度学习搞混。其实它们是层层包含的关系:
- 人工智能(AI):最大的范畴,目标是让机器具备人类的智能(思考、判断、创造);
- 机器学习(ML):实现 AI 的核心方法之一,让机器通过数据学习规律,无需手动编码规则;
- 深度学习 (DL):机器学习的进阶版,使用"深层神经网络"(通常 ≥3 层隐藏层)处理高维复杂数据(如高清图像、长文本、语音)。
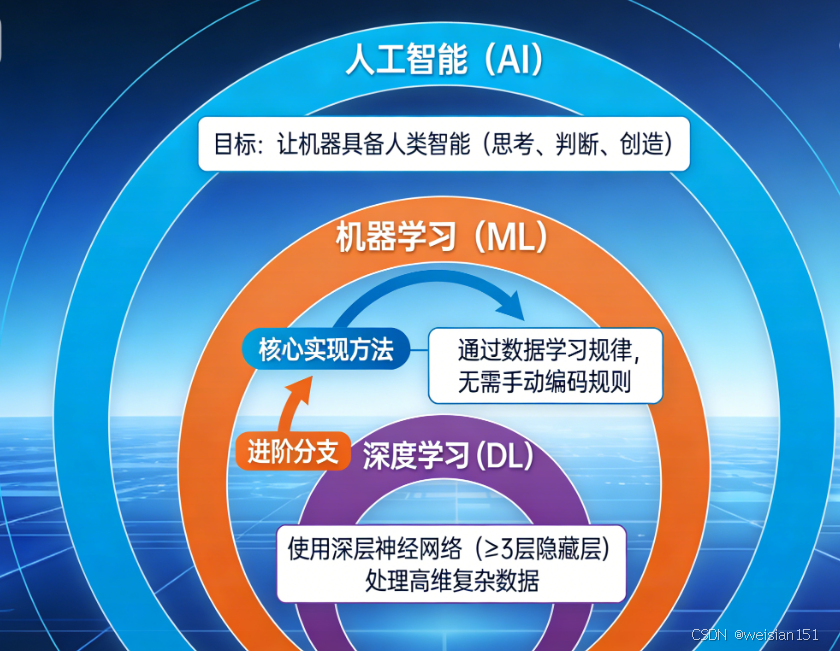
打个比方 :
如果把 AI 比作"打造智能机器人"的大工程,
机器学习就是"给机器人安装学习系统",
而深度学习则是"给它装上能模拟人脑的超级学习引擎"。
3. 深度学习的核心:神经网络到底是什么?
神经网络是深度学习的"骨架"。我们用"类比人脑"的方式理解:
-
人类大脑由数十亿神经元组成,通过突触传递信号;
-
深度学习的"神经网络",就是用数学和代码模拟这一结构:
- 神经元:网络中的基本计算单元,接收输入、加权求和、输出结果;
- 层 (Layer):神经元按功能分组排列,包括:
- 输入层:接收原始数据(如像素值);
- 隐藏层:核心加工区,负责逐层抽象特征("深度"就体现在这里);
- 输出层:给出最终预测(如"猫"或"狗");
- 权重 (Weight):连接神经元的参数,代表"这条信息有多重要"。训练模型的本质,就是不断调整这些权重,让预测越来越准。
而"深度学习"中的"深度",指的就是隐藏层的数量多。早期网络只有 1--2 层,学习能力有限;如今的大模型(如 GPT-4)可达上百层,能捕捉极其复杂的模式。

二、深度学习出现之前,AI 靠什么?
在深度学习崛起前,AI 主要有两大流派,但都存在致命短板。
1. 符号主义(Symbolic AI)------ "规则驱动"
- 核心思想:智能 = 逻辑推理 + 知识库。
- 典型代表:专家系统(如 MYCIN 医疗诊断系统)。
- 致命缺陷 :
- 所有规则需人工编写,成本极高;
- 遇到未覆盖场景就失效;
- 无法处理模糊、噪声、非结构化数据(如图像、语音)。
就像教孩子认猫,你得把"尖耳朵、胡须、尾巴......"全写成 if-else,累死也写不完。
2. 统计学习(Statistical Learning)------ "浅层模型 + 人工特征"
- 代表算法:SVM(支持向量机)、决策树、随机森林等。
- 工作流程:人类先手动设计特征(如图像的边缘、纹理)→ 再用算法分类。
- 核心瓶颈 :
- 特征工程极度依赖专家经验;
- 不同任务需重新设计特征,无法通用;
- 面对高维复杂数据(如自然语言),人工特征根本不够用。
这就像让厨师先自己切菜、调酱,再交给炒锅------效率低,且限制了菜品上限。
深度学习的革命性,就在于它把"特征工程"这件事自动化了。
三、为什么深度学习直到 2010 年代才爆发?
人工神经网络(ANN)的想法早在 1940--50 年代就有了,但沉寂几十年,原因很现实:
| 瓶颈 | 早期困境 | 2010 年代如何解决 |
|---|---|---|
| 算力不足 | CPU 训练慢,深层网络无法收敛 | GPU 并行计算普及(游戏显卡变 AI 引擎) |
| 数据太少 | 缺乏大规模标注数据 | ImageNet(1400 万图)、互联网行为数据爆发 |
| 训练困难 | 梯度消失,深层网络学不动 | ReLU 激活函数 + BatchNorm + 残差连接(ResNet) |
| 理论不成熟 | 不知道"深度"是否有用 | Hinton 2006 年 DBN 证明预训练可行;2012 AlexNet 实证有效 |
深度学习不是突然发明的,而是"天时(数据+算力)+地利(算法突破)+人和(坚持者)"共同促成的结果。
ANN 到底怎么工作?从"直线"到"曲线"的飞跃
✦ 最简单的 ANN:感知机(Perceptron)
想象一个"投票系统":
- 输入:多个信号(比如像素亮度);
- 每个信号有权重(重要性);
- 加权求和后,若超过阈值 → 输出"是";否则"否"。
这其实是一个线性分类器:用一条直线把两类数据分开。
但现实世界的问题(比如区分猫狗)往往是非线性的------你画不出一条直线把它们干净分开。
✦ 多层 ANN:从"直线"到"曲线"
如果我们堆叠多层感知机(即"深度"网络),每一层对输入做一次非线性变换,最终就能拟合任意复杂的边界。
数学上有"万能近似定理":
一个足够宽的单隐藏层神经网络,可以逼近任何连续函数 。而"更深"的网络,则能用更少的参数高效表示复杂函数。
所以,"深度"的价值在于:分层抽象。
- 第一层学边缘;
- 第二层学部件(眼睛、轮子);
- 第三层学整体对象(人脸、汽车)......
这种层次化特征学习,正是深度学习碾压传统方法的关键。
四、历史脉络:深度学习的百年萌芽与三次浪潮
深度学习的发展,是一部"理论奠基 → 技术突破 → 产业爆发"的螺旋上升史,跨越近百年,经历三次浪潮。
第一阶段:理论萌芽期(1940s--1990s)------从数学模型到早期网络
▶ 1943:MCP 模型 ------ 神经网络的"雏形"
McCulloch & Pitts 提出首个神经元数学模型:输入加权求和 → 判断阈值 → 输出信号。
意义:首次将"模拟大脑"变为可计算的数学问题。
▶ 1949:Hebbian 学习规则
Donald Hebb 提出:"一起激活的神经元,连接会增强。"
意义:为"神经网络如何学习"提供生物学启发。
▶ 1958:感知器(Perceptron)
Frank Rosenblatt 发明首个可学习的神经网络,能处理简单二分类。
局限:只能解决线性可分问题。
▶ 1969:第一次寒冬
Minsky & Papert 在《感知器》一书中指出其无法解决非线性问题。
后果:科研经费锐减,神经网络研究陷入停滞。
▶ 1986:反向传播算法(BP)
Geoffrey Hinton 团队提出 BP 算法:通过误差反向传播,自动调整各层权重。
意义:让多层网络真正可训练,掀起第一波热潮。
▶ 1998:LeNet-5 ------ CNN 的先驱
Yann LeCun 提出首个商用卷积神经网络,用于手写数字识别(准确率 >99%)。
应用 :美国邮政自动识别邮编。
遗憾:受限于算力与数据,未能大规模推广。
▶ 1990s 末:第二次寒冬
数据少、算力弱、梯度消失问题严重,研究者转向 SVM 等浅层模型。
第二阶段:爆发崛起期(2006--2016)------深度学习的黄金十年
▶ 2006:深度信念网络(DBN)------ "深度学习"正式命名
Hinton 提出"逐层预训练"策略,缓解梯度消失,并首次使用"深度学习"一词。
同年,NVIDIA 推出 CUDA,GPU 成为 AI 训练加速器。
▶ 2009:ImageNet 数据集发布
李飞飞团队构建 1400 万张标注图像,覆盖 1000 类别。
意义:为深度学习提供"燃料",解决"无米之炊"。

▶ 2012:AlexNet ------ 引爆革命
在 ImageNet 竞赛中,错误率从 26% 降至 15.3%,断崖式领先。
三大创新:
- ReLU 激活函数 → 解决梯度消失;
- Dropout → 防止过拟合;
- GPU 并行训练 → 效率提升数十倍。
影响 :CNN 成为主流,GPU 成为 AI 标配,深度学习进入大众视野。

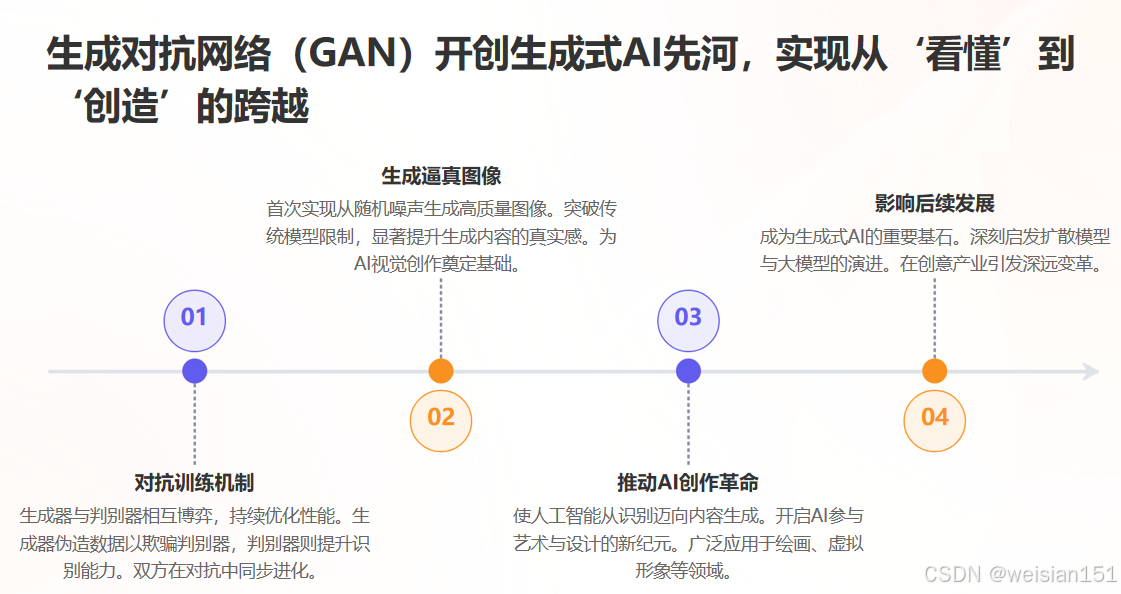
▶ 2014:GAN 与 ResNet ------ 生成与深度的突破
- GAN(生成对抗网络):开启生成式 AI 时代;
- ResNet(残差网络):引入"跳跃连接",使网络可训练上千层。
▶ 2015:DQN 与 LSTM ------ 从感知到决策
- DQN:深度强化学习,在 Atari 游戏中超越人类;
- LSTM:解决长序列记忆问题,推动 NLP 发展。
▶ 2016:AlphaGo 击败李世石
结合深度学习 + 强化学习 + 蒙特卡洛树搜索,攻克围棋这一"AI 最后堡垒"。
全球影响:引爆公众关注,各国启动 AI 国家战略。
第三阶段:普惠爆发期(2017--至今)------从技术突破到产业落地
▶ 2017:Transformer 架构 ------ 大模型的"心脏"
Google 提出《Attention Is All You Need》,用自注意力机制 替代 RNN/CNN。
优势:
- 完全并行训练,速度极快;
- 能捕捉长距离依赖(如文章首尾关联)。
意义 :成为 GPT、BERT 等所有大模型的底层架构。

自注意力机制通俗理解 :
就像你读"他赢了比赛"时,会自动把"他"和前文提到的人关联起来。
Transformer 能自动判断"哪些词更重要",从而精准理解语义。
▶ 2018:预训练范式成熟 ------ GPT 与 BERT
- GPT-1:基于 Transformer 解码器,提出"无监督预训练 + 微调";
- BERT :基于编码器,双向预训练刷新 NLP 记录。
影响:NLP 进入"预训练时代",开发成本大幅降低。
▶ 2020:GPT-3 ------ "规模即智能"
1750 亿参数,首次展现上下文学习(In-Context Learning)能力:
只需在提示中给几个例子,就能完成翻译、写诗、编程,无需微调。
验证"缩放定律":模型越大、数据越多,性能越好,甚至涌现新能力。
▶ 2021:多模态与科学突破
- DALL·E:文本生成图像;
- AlphaFold 2:精准预测蛋白质结构,革新生物医药;
- Stable Diffusion:开源扩散模型,推动生成式 AI 平民化。
▶ 2022:ChatGPT ------ 全民 AI 时代开启
结合 RLHF(人类反馈强化学习),实现安全、流畅、人性化的对话。
- 2 个月用户破 1 亿,史上最快消费级应用;
- 全球科技公司"All in AI",资本疯狂涌入。
▶ 2023--2025:百花齐放与产业深耕
- 多模态融合:GPT-4、Gemini 支持图文音视频理解;
- 开源崛起:DeepSeek、Llama 等以低成本高性能打破垄断;
- 行业落地:金融、医疗、制造专用大模型大规模应用;
- 端侧部署:模型压缩技术让大模型跑在手机、PC 上。
五、深度学习发展关键事件总结
| 时间 | 关键事件 | 核心技术/突破 | 行业影响 |
|---|---|---|---|
| 1943 | MCP 模型提出 | 首个神经元数学模型 | 奠定神经网络理论基础 |
| 1958 | 感知器发明 | 首个可学习网络 | 证明神经网络可行性 |
| 1969 | 《感知器》出版 | 指出非线性局限 | 引发第一次 AI 寒冬 |
| 1986 | 反向传播算法 | 解决多层训练难题 | 掀起神经网络热潮 |
| 1998 | LeNet-5 提出 | 首个商用 CNN | 推动图像识别落地 |
| 2006 | 深度信念网络 | 提出"深度学习"术语 | 结束第二次寒冬 |
| 2009 | ImageNet 发布 | 1400 万标注图像 | 解决数据瓶颈 |
| 2012 | AlexNet 夺冠 | ReLU + Dropout + GPU | 引爆深度学习革命 |
| 2014 | GAN / ResNet | 生成式 AI + 深层网络 | 拓宽应用场景 |
| 2016 | AlphaGo 胜李世石 | 深度学习 + 强化学习 | 引发全球 AI 热潮 |
| 2017 | Transformer 提出 | 自注意力机制 | 成为大模型核心骨架 |
| 2018 | GPT-1 / BERT | 预训练范式 | NLP 进入新纪元 |
| 2020 | GPT-3 发布 | 1750 亿参数,涌现能力 | 开启大模型时代 |
| 2022 | ChatGPT 发布 | RLHF + 自然对话 | 推动全民 AI 普惠 |
| 2023--2025 | 开源 + 多模态 + 行业落地 | MoE、RAG、端侧部署 | 深度学习融入千行百业 |
六、深度学习的现在与未来
当前三大趋势:
- 从"规模竞赛"到"效率优先":企业更关注推理成本与能效比(如 DeepSeek 用 MoE 架构降本 95%);
- 从"单一模态"到"多模态融合":模型能同时理解文本、图像、音频、视频;
- 从"通用模型"到"行业深耕":金融、医疗、制造等领域专用模型加速落地。
未来四大方向:
- 更高效:通过架构优化、量化压缩,让更多人用得起;
- 更通用:AI Agent 能自主规划、调用工具,完成复杂任务;
- 更安全:可解释性 + 监管框架(如欧盟 AI Act)保障可信 AI;
- 更普惠:端侧部署让 AI 能力融入手机、手表、家电,实现"智力在线"。
七、深度学习难不难?普通人如何入门?
这是很多读者最关心的问题。我的答案是:入门不难,精通不易,但每一步都有路可走。
✅ 1. 先明确目标:你想用 AI 做什么?
- 只想用工具(如写文案、画图)→ 直接上手 ChatGPT、Midjourney,无需懂原理;
- 想做应用开发(如接入 API、微调模型)→ 学 Python + Hugging Face + LangChain;
- 想深入研究(如改进算法、训练模型)→ 需系统学习数学、编程、框架。

✅ 2. 推荐学习路径(零基础友好)
📌 阶段一:建立直觉(1--2 周)
- 看视频:3Blue1Brown《神经网络》系列(B站有中字);
- 玩交互:TensorFlow Playground(在线可视化神经网络训练);
- 读文章:本文 + 李沐《动手学深度学习》前两章。
📌 阶段二:动手实践(1--3 个月)
- 学 Python 基础(变量、函数、循环);
- 用 PyTorch 或 TensorFlow 训练第一个 CNN(识别手写数字);
- 在 Kaggle 或天池参加入门竞赛。
📌 阶段三:深入理解(3--12 个月)
- 学线性代数、微积分、概率论(重点:矩阵运算、梯度);
- 精读经典论文(AlexNet、Transformer、BERT);
- 复现开源项目,尝试微调 Llama 或 DeepSeek。
✅ 3. 关键心态建议
- 不要怕数学:深度学习的数学本质是"加权平均 + 链式求导",远没有想象中可怕;
- 先跑通,再理解:很多概念(如反向传播)只有亲手调参后才真正明白;
- 加入社区:知乎、GitHub、Discord 有很多中文学习群,提问不丢人。
记住 :Hinton 在 AI 寒冬坚持了 30 年,李飞飞为 ImageNet 手动标注百万图片。
今天的你,站在巨人的肩膀上,只需迈出第一步。
写在最后
深度学习的价值,不仅在于"让 AI 更聪明",更在于"让智能变得可及"。
它正在从实验室走向工厂、医院、教室,甚至你的手机相册和购物推荐。
理解它,不是为了成为科学家,而是为了在这个智能时代,知道自己手中的工具从何而来,又能去向何方。

互动时间
你第一次接触深度学习相关的产品是什么?
是 ChatGPT、AI 绘画,还是手机的人像模式?
你对深度学习还有哪些想了解的问题?欢迎在评论区留言!
我是 Weisian,持续用通俗语言拆解 AI 硬核技术。
记得点赞、关注,和 AI 一起成长 🌟