目录
[1. 基本结构](#1. 基本结构)
[2. 核心特点](#2. 核心特点)
[3. 自编码器分类](#3. 自编码器分类)
[判别式模型 VS 生成式模型](#判别式模型 VS 生成式模型)
[1. 生成器编辑](#1. 生成器编辑)
[2. 判别器](#2. 判别器)
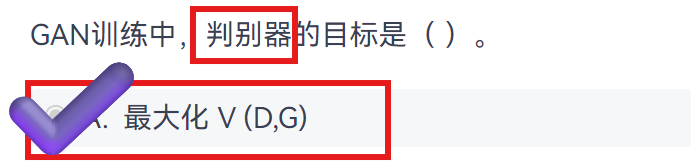
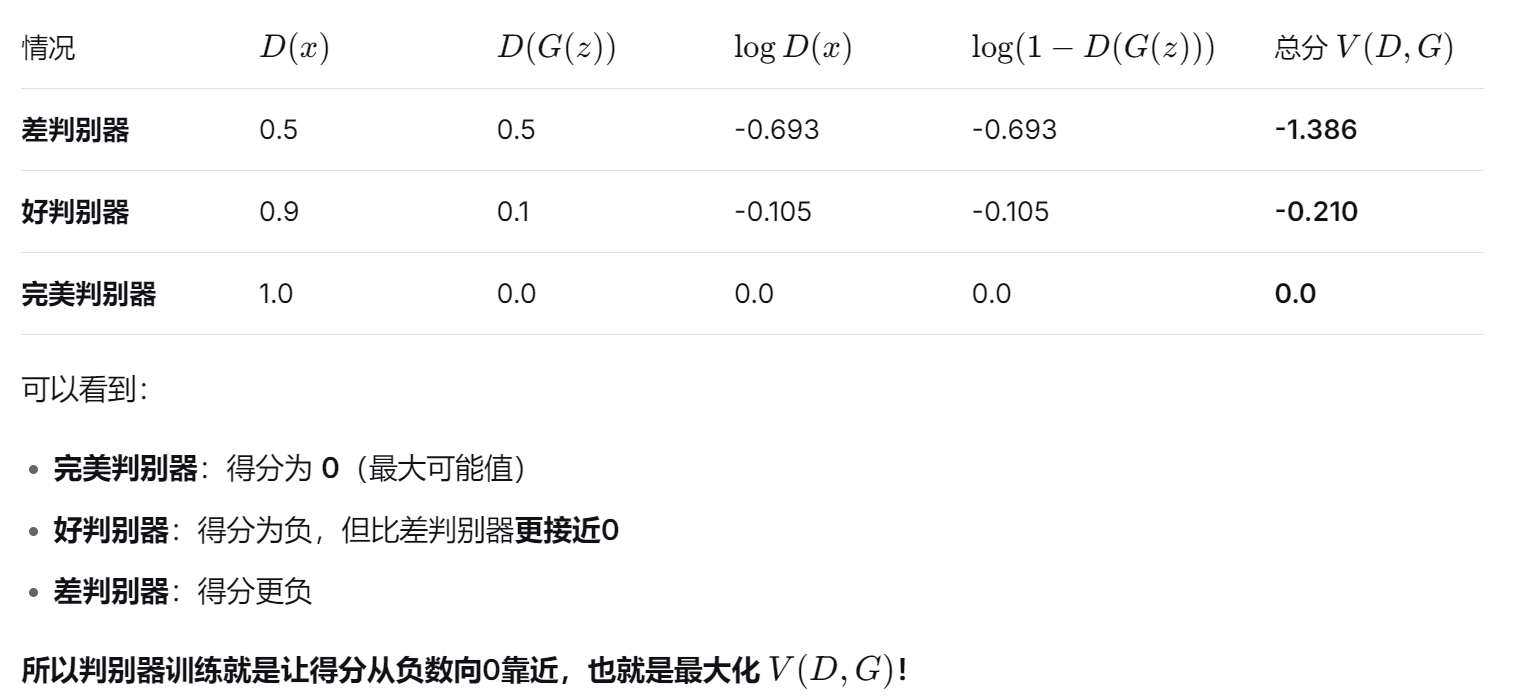
[1、总目标 (极小极大博弈)](#1、总目标 (极小极大博弈))
[2、判别器损失 (二分类任务)](#2、判别器损失 (二分类任务))
[GAN vs 自编码器](#GAN vs 自编码器)
[WGAN(Wasserstein GAN)](#WGAN(Wasserstein GAN))
[标准卷积 vs 转置卷积](#标准卷积 vs 转置卷积)
自编码器
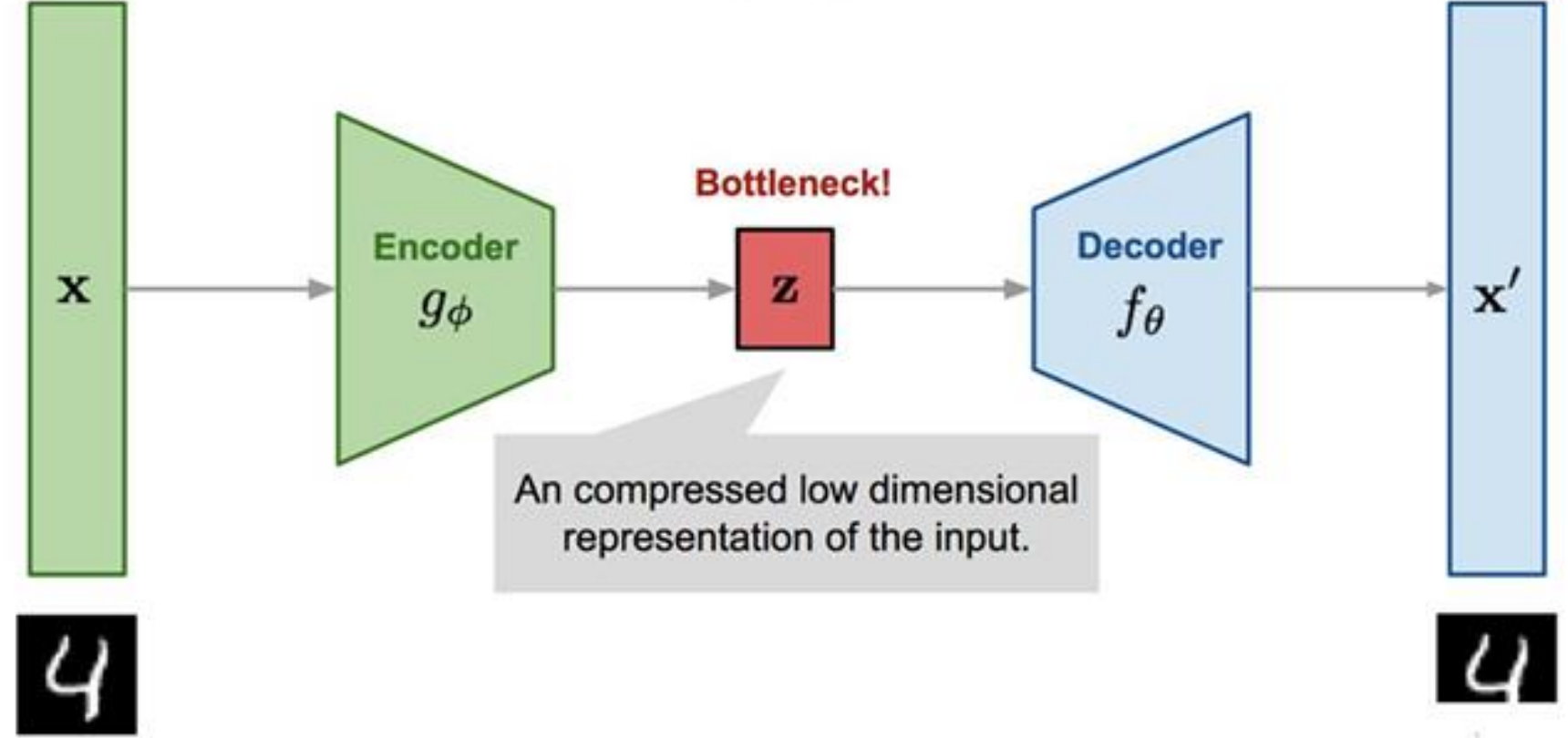
自编码器是一种 **无监督学习(考点)**模型。
- 核心思想:让模型学习数据的压缩表示(编码),并尽可能无损失地重构回原始数据(解码)。
1. 基本结构
编码器 :将高维输入数据压缩为一个低维的潜在向量 。这个过程是
数据 → 特征。解码器 :将潜在向量重构回原始数据维度。这个过程是
特征 → 数据。目标 :最小化重构误差,让输出尽可能接近输入。
【简答】:自编码器由哪两部分组成?它们的功能分别是什么?
编码器和解码器。编码器 将输入数据压缩为低维潜在向量(提取关键特征);解码器将潜在向量重构为与原始数据维度一致的输出。
- bottleneck 瓶颈层/潜在表示
2. 核心特点
无监督:不需要标签,只靠数据本身。
特征学习:学习到的潜在向量是数据的"精华"或"特征表示"。
降噪/去噪:一种常见应用是,输入带噪声的数据,让模型输出清晰的数据,从而学会降噪。
3. 自编码器分类
基础自编码器:使用全连接层,结构简单,适合简单数据。
latent 潜在的
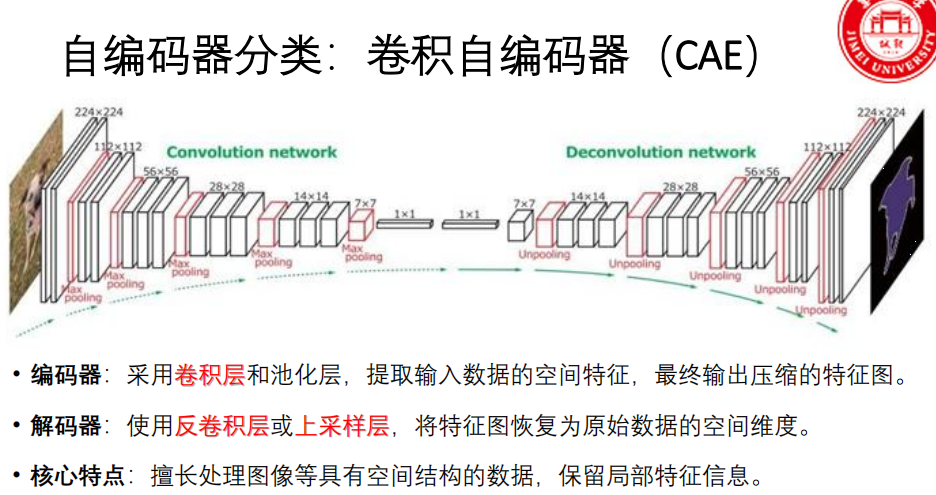
- 卷积自编码器:使用卷积层和池化层(编码器)、反卷积/上采样层(解码器),擅长处理图像等具有空间结构的数据。
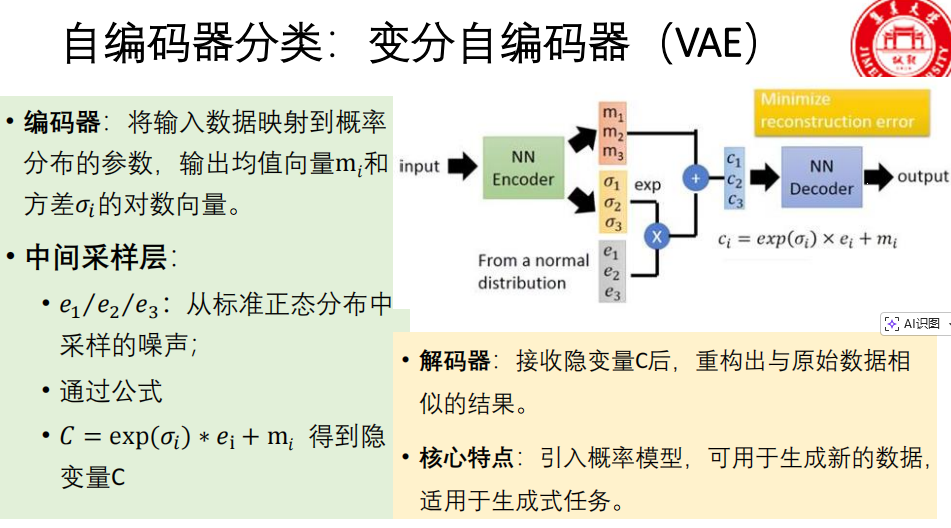
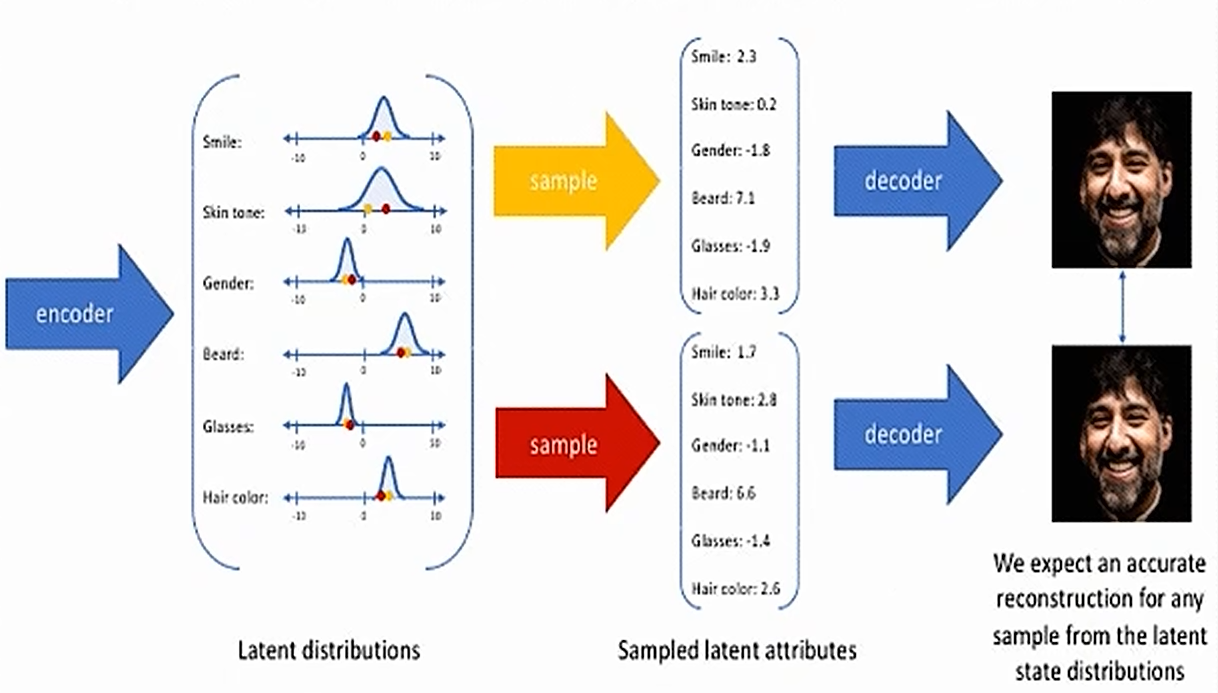
- 变分自编码器(VAE) :引入概率思想,编码器输出分布的参数(均值和方差),通过采样得到潜在变量,可用于生成新数据,是重要的生成式模型。




判别式模型 VS 生成式模型
判别式模型:
学习 输入 → 输出标签 的映射。
关注 "如何区分不同类别"。
例子:逻辑回归、SVM、CNN分类器。
特点:训练快,适合分类,不能生成新样本。
生成式模型:
学习 数据的联合概率分布。
关注 "如何生成类似真实的数据"。
例子:朴素贝叶斯、VAE、GAN。
特点:能生成新样本,训练复杂度高。
判别式模型和生成式模型的根本区别是什么?
- 判别式模型 直接学习输入特征X与输出标签Y之间的条件概率分布 P(Y|X) 。它关注的是"在给定输入下,它最可能属于哪个类别",即学习的是决策边界。
- 生成式模型 则学习输入特征X和输出标签Y的联合概率分布 P(X, Y)。它首先学习每个类别的数据本身是如何分布的(P(X|Y) 和 P(Y)),然后通过贝叶斯定理推导出 P(Y|X)。它关注的是"数据本身是如何生成的"。

GAN基础理论与原理
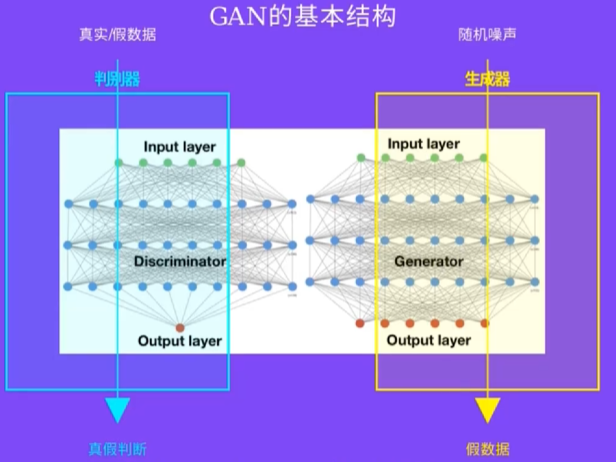
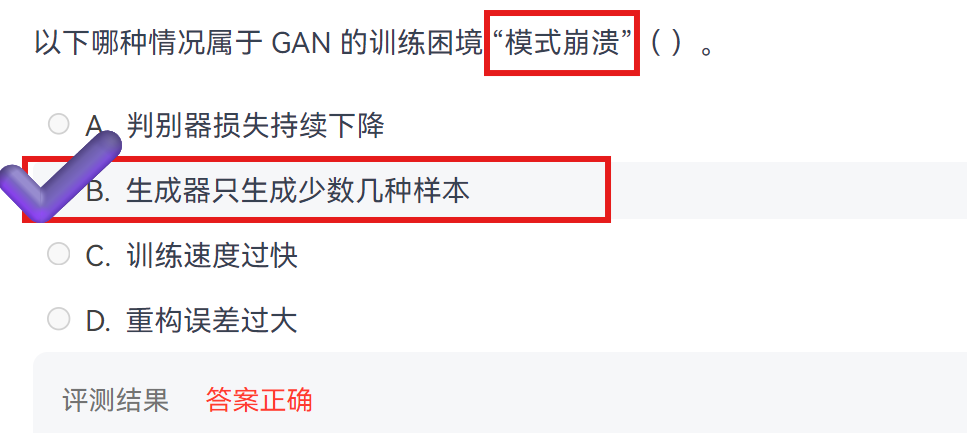
简答:简述GAN的基本组成部分及其功能。生成对抗网络由两个核心神经网络模块构成:生成器 与判别器。二者通过对抗博弈机制协同训练。
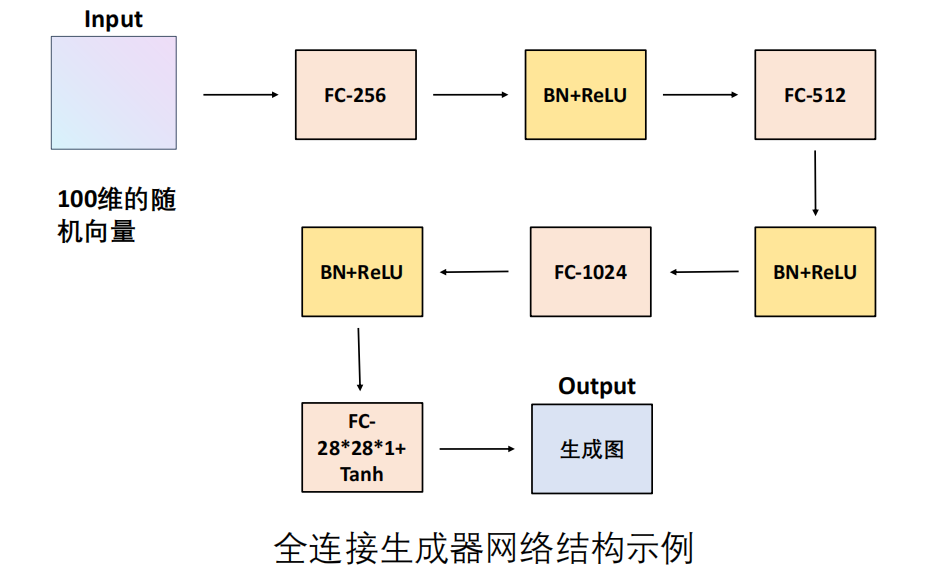
1. 生成器
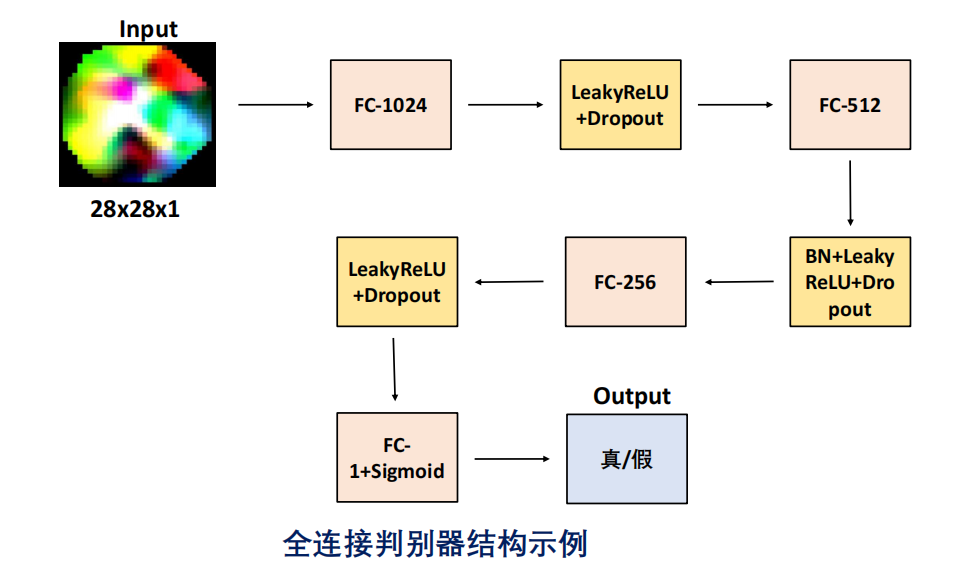
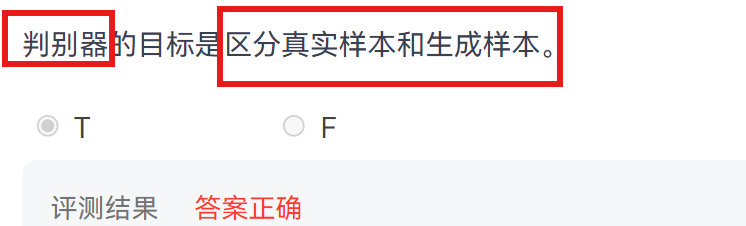
2. 判别器
损失函数
1、总目标 (极小极大博弈)
- log 默认表示自然对数 ln(以 e 为底)
2、判别器损失 (二分类任务)
3、生成器损失
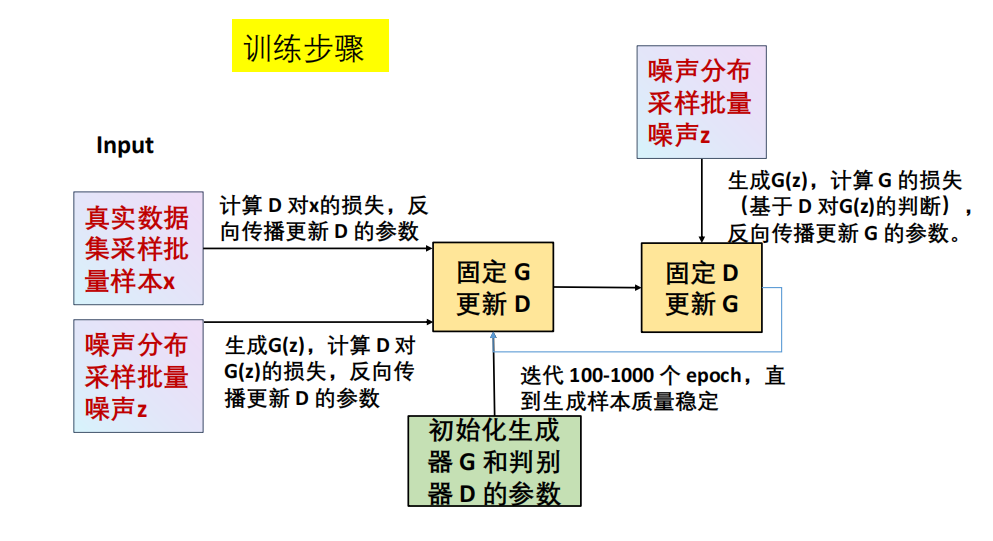
训练流程
!!!PPT例题简述GAN中生成器与判别器的输入与输出分别是什么
生成器 (G)
输入:随机噪声向量 𝑧(通常来自正态分布)。
输出:伪造的数据样本 G(z)(如图像)。
判别器 (D)
输入:真实样本 x 或生成样本 G(z)。
输出:一个概率值 𝐷(⋅),表示输入样本为真的置信度。






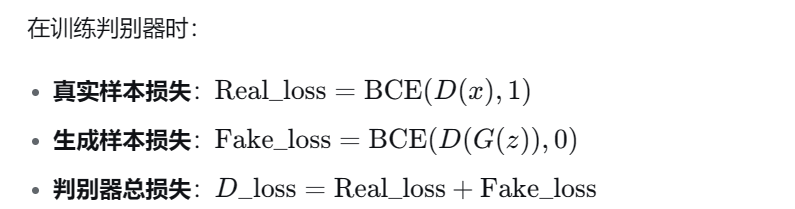

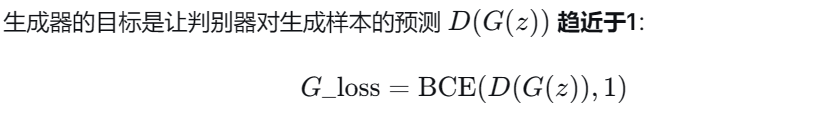





GAN vs 自编码器
DCGAN(深度卷积生成对抗网络)
(1)提出背景
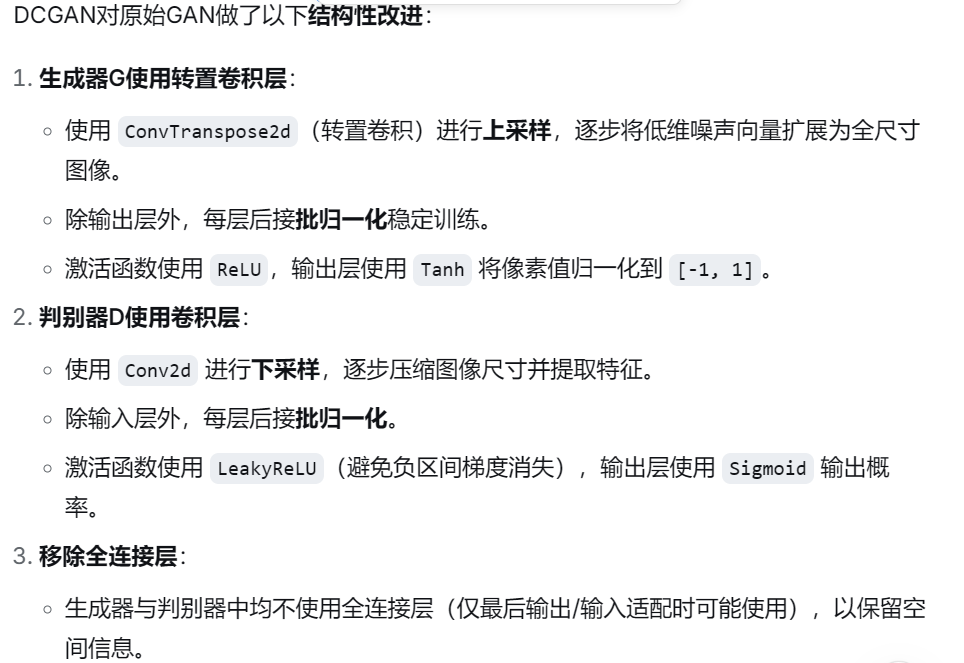
(2)DCGAN的核心架构特点
DCGAN的训练优化策略
标签平滑:
真实标签设为
0.9,生成标签设为0.1,防止判别器过于自信导致梯度消失。损失平均:
判别器损失取
(real_loss + fake_loss) / 2,降低训练震荡。学习率衰减:
训练后期逐步降低学习率,使模型收敛更稳定。
数据增强:
使用随机水平翻转、随机裁剪等扩充数据集,减轻过拟合。
模型保存策略:
按生成器损失保存"最佳模型",而非定期保存。
【总结】DCGAN核心考点
三大改进(PPT P37):
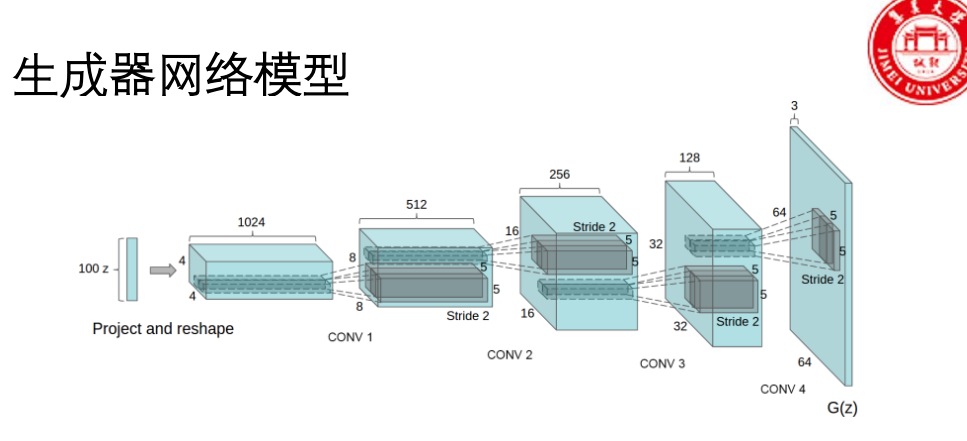
生成器使用转置卷积(ConvTranspose2d) 进行上采样。
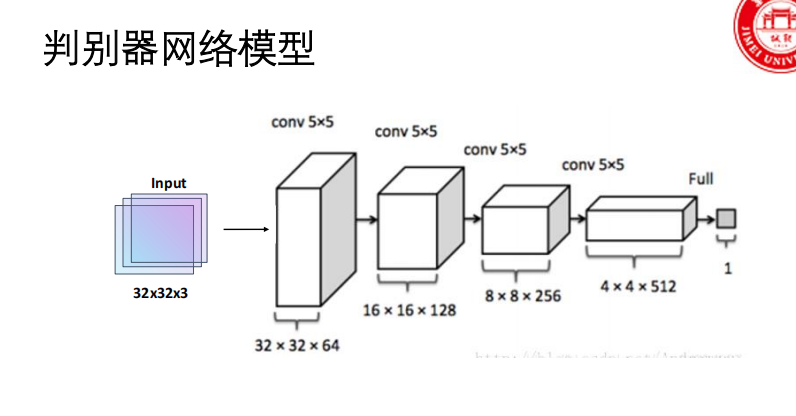
判别器使用卷积层(Conv2d) 进行下采样。
在生成器和判别器中广泛使用批归一化(BatchNorm) 来稳定训练。
激活函数 :生成器用
ReLU(输出层用Tanh),判别器用LeakyReLU。利用CNN擅长处理图像局部特征和空间结构的特性,显著提升了生成图像的质量。
WGAN(Wasserstein GAN)
核心改进 :用 Wasserstein距离(Earth-Mover距离) 替代原始GAN的 JS散度 作为分布距离度量。
Wasserstein距离:又称"推土机距离",衡量两个分布之间转换的最小"工作量"。
Lipschitz约束:限制函数变化速度,确保梯度不超过某个上界。
WGAN-GP
WGAN的问题
WGAN通过权重裁剪强制实现Lipschitz约束,但带来两个明显问题:
容量限制 :裁剪使评论家网络表达能力下降,导致生成图像模糊。
训练敏感:裁剪阈值 c 需精心调参,过大过小均会导致训练不稳定或失效。
WGAN-GP 的全称是 WGAN with Gradient Penalty 。其核心是用 梯度惩罚 替代 权重裁剪,作为实现Lipschitz约束的更优方法。
梯度惩罚 :直接在损失函数中增加一个正则项,用于惩罚评论家梯度范数偏离1的情况。
理论依据 :函数满足 1-Lipschitz 约束 等价于 其梯度范数几乎处处不超过1。







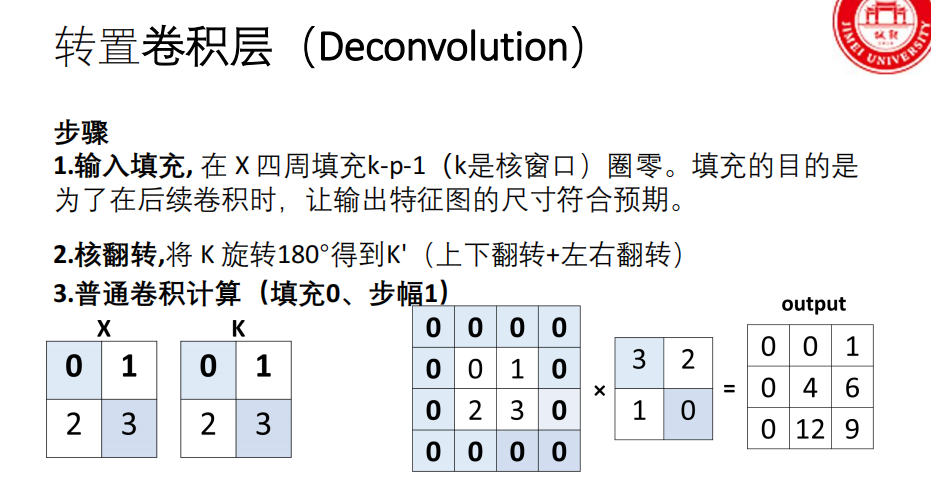
转置卷积
转置卷积的定义与目的
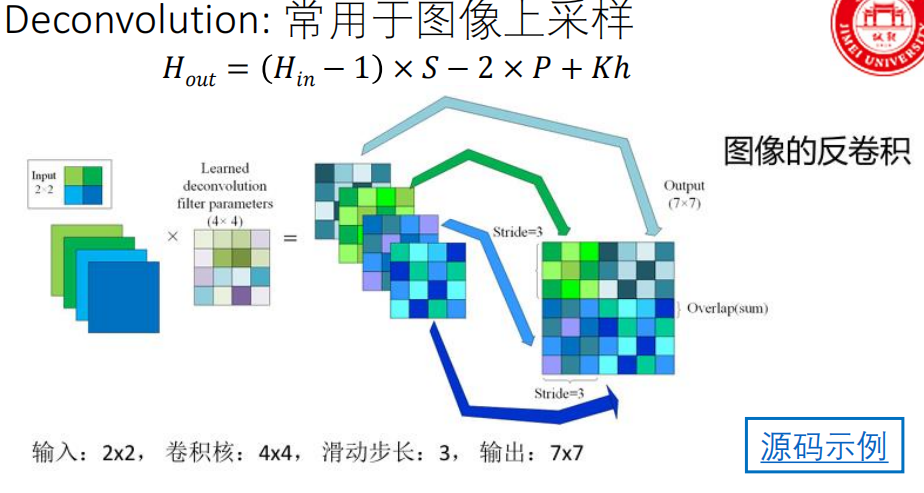
定义 :转置卷积是一种上采样操作(考点) ,用于将小尺寸的特征图扩展为大尺寸的特征图。
目的 :在生成器(DCGAN)和语义分割解码器等网络中,需要将低维潜在表示或压缩的特征图恢复至原始图像尺寸。
关键特性 :与双线性插值等固定上采样方法不同,转置卷积的 参数是可学习(考点)的,能通过训练优化其上采样方式。
标准卷积 vs 转置卷积
转置卷积的计算步骤
- k 是核尺寸,p 是原始卷积的填充数
转置卷积输出尺寸计算公式
- kernel_size = Kh = Kw