智能体学习记录二之发展史
一、基于符号和逻辑的早期智能体
在那个时代,研究者们普遍持有一种信念:人类的智能,尤其是逻辑推理能力,可以被形式化的符号体系所捕捉和复现。
-
物理符号系统假说
- 1976年由艾伦·纽厄尔(Allen Newell)和 赫伯特·西蒙(Herbert A. Simon)共同提出的物理符号系统假说(PhysicalSymbol SystemHypothesis, PSSH)
- 核心论断
- 充分性论断:任何一个物理符号系统,都具备产生通用智能行为的充分手段。
- 必要性论断:任何一个能够展现通用智能行为的系统,其本质必然是一个物理符号系统。
-
专家系统
-
专家系统的核心目标,是模拟人类专家在特定领域内解决问题的能力。通过将专家的知识和经验编码成计算机程序,使其能够在面对相似问题时,给出媲美甚至超越人类专家的结论或建议。
-
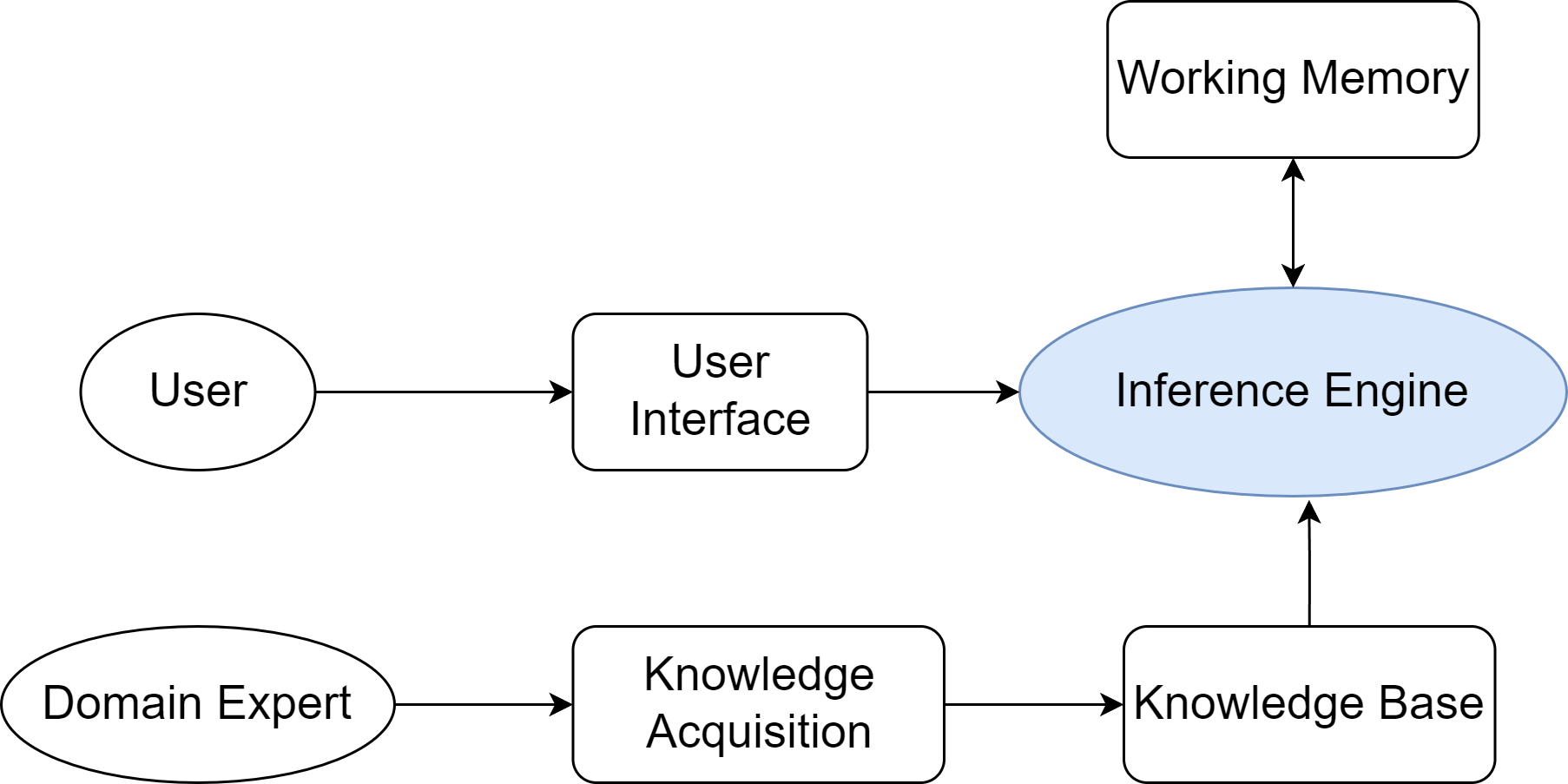
典型的专家系统通常由由知识库、推理机、用户界面等几个核心部分构成,如下图所示
-
核心组件:知识库和推理机
- 知识库(Knowledge Base)
- 专家系统的知识存储中心,用于存放领域专家的知识和经验
- 通过一系列"IF-THEN"形式的条件语句制定规则,将特定情境(IF部分,条件)与相应的结论或行动(THEN部分,结论)关联起来
- 推理机(Inference Engine) :
- 正向链(Forward Chaining):从已知事实出发,不断匹配规则的IF部分,触发THEN部分的结论,并将新结论加入事实库,直到最终推导出目标或无新规则可匹配。这是一种"数据驱动"的推理方式.
- 反向链(Backward Chaining):从一个假设的目标(比如"病人是否患有肺炎")出发,寻找能够推导出该目标的规则,然后将该规则的IF部分作为新的子目标,如此递归下去,直到所有子目标都能被已知事实所证明。这是一种"目标驱动"的推理方式
- 典型案例:MYCIN,由斯坦福大学于20世纪70年代开发
- 知识库(Knowledge Base)
-
-
SHRDLU
由**特里·威诺格拉德(Terry Winograd)**于1968-1970年开发,在"广度"上实现了革命性的突破,它首次将多个独立的人工智能模块(如语言解析、规划、记忆)集成在一个统一的系统中,并使它们协同工作
- 自然语言理解:能够解析结构复杂且含有歧义的英语句子
- 规划与行动:在理解指令后,能够自主规划出一系列必要的动作来完成任务
- 记忆与问答:拥有关于其所处环境和自身行为的记忆
-
符号主义面临的挑战
- 常识知识与知识获取瓶颈
- 知识获取瓶颈(Knowledge Acquisition Bottleneck):专家系统的知识需要由人类专家和知识工程师通过繁琐的访谈、提炼和编码过程来构建。这个过程成本高昂、耗时漫长,且难以规模化
- 常识问题(Common-sense Problem):人类行为依赖于庞大的常识背景(例如,"水是湿的"、"绳子可以拉不能推"),但符号系统除非被明确编码,否则对此一无所知
- 框架问题与系统脆弱性
- 框架问题(Frame Problem):在一个动态世界中,每个动作显式地声明所有不变的状态,在计算上是不可行的,而人类却能毫不费力地忽略不相关的变化
- 系统脆弱性(Brittleness):符号系统完全依赖预设规则,一旦遇到规则之外的任何微小变化或新情况,系统便可能完全失灵,无法像人类一样灵活变通
- 常识知识与知识获取瓶颈
二、基于规则的优化
-
ELIZA的设计思想
ELIZA是由麻省理工学院的计算机科学家**约瑟夫·魏泽鲍姆(Joseph Weizenbaum)**于1966年发布的一个计算机程序,是早期自然语言处理领域的著名尝试之一。
通过一系列的预设规则进行内容处,例如,当用户说"我为我的男朋友感到难过"时,ELIZA可能会识别出关键词"我为......感到难过",并应用规则生成回应:"你为什么会为你的男朋友感到难过?"
-
模式匹配和文本替换
算法流程基于模式匹配(Pattern Matching)与文本替换(Text Substitution)
- **关键词识别与排序:**对每个关键词设置一个优先级,程序自动选择优先级最高的
- **分解规则:**根据关键词,程序使用通配符(*)来分解规则捕获语句内容
- **重组规则:**从重组规则中选择一条来回应关联分解后的规则内容
- **代词转换:**代词转换(如
I→you,my→your),以维持对话的连贯性
-
核心逻辑
定义一堆预设规则,以匹配输入内容,系统看似智能的表现,完全依赖于设计者预先编码的规则。
-
存在缺陷
- 缺乏语义理解 :系统不理解词义。例如,面对"I am not happy"的输入,它仍会机械地匹配
I am (.*)规则并生成语义不通的回应,因为它无法理解否定词"not"的作用 - 无上下文记忆 :系统是无状态的(Stateless),每次回应仅基于当前单句输入,无法进行连贯的多轮对话
- 规则的扩展性问题:尝试增加更多规则会导致规则库的规模爆炸式增长,规则间的冲突与优先级管理将变得极其复杂,最终导致系统难以维护
- 缺乏语义理解 :系统不理解词义。例如,面对"I am not happy"的输入,它仍会机械地匹配
三、马文·明斯基(Marvin Minsky)心智社会
-
对单体智能模型的反思
- "理解"是什么? 当我们说我们理解一个故事时,这是一种单一的能力吗?还是说,它其实是视觉化能力、逻辑推理能力、情感共鸣能力、社会关系常识等数十种不同心智过程协同工作的结果?
- "常识"是什么? 常识是一个包含了数百万条逻辑规则的庞大知识库吗(如Cyc项目的尝试)?还是说,它是一种分布式的、由无数具体经验和简单规则片段交织而成的网络?
- 智能体应该如何构建? 我们是否应该继续追求一个完美的、统一的逻辑系统,还是应该承认,智能本身就是"不完美"的、由许多功能各异、甚至会彼此冲突的简单部分组成的大杂烩?
-
协作的智能
在明斯基的理论框架中,智能体指的是一个极其简单的、专门化的心智过程,它自身是"无心"的
-
多智能系统的理论启发
心智社会理论最深远的影响,在于它为**分布式人工智能(Distributed Artificial Intelligence, DAI)以及后来的多智能体系统(Multi-Agent System, MAS)**提供了重要的概念基础
- 去中心化控制(Decentralized Control):理论的核心在于不存在中央控制器。这一思想被MAS领域完全继承,如何设计没有中心节点的协调机制和任务分配策略,成为了MAS的核心研究课题之一
- 涌现式计算(Emergent Computation):复杂问题的解决方案可以从简单的局部交互规则中自发产生。这启发了MAS中大量基于涌现思想的算法,如蚁群算法、粒子群优化等,用于解决复杂的优化和搜索问题
- 智能体的社会性(Agent Sociality):明斯基的理论强调了智能体之间的交互(激活、抑制)。MAS领域将其进一步扩展,系统地研究智能体之间的通信语言(如ACL)、交互协议(如契约网)、协商策略、信任模型乃至组织结构,从而构建起真正的计算社会
四、学习范式的演进与现代智能体
-
联结主义
- 知识的分布式表示:知识并非以明确的符号或规则形式存储在某个知识库中,而是以连接权重的形式,分布式地存储在大量简单的处理单元(即人工神经元)的连接之间。整个网络的连接模式本身就构成了知识
- 简单的处理单元:每个神经元只执行非常简单的计算,如接收来自其他神经元的加权输入,通过一个激活函数进行处理,然后将结果输出给下一个神经元
- 通过学习调整权重:系统的智能并非来自于设计者预先编写的复杂程序,而是来自于"学习"过程。系统通过接触大量样本,根据某种学习算法(如反向传播算法)自动、迭代地调整神经元之间的连接权重,从而使得整个网络的输出逐渐接近期望的目标
-
强化学习的智能体
联结主义主要解决了感知问题(例如,"这张图片里有什么?"),但智能体更核心的任务是进行决策(例如,"在这种情况下,我应该做什么?")。**强化学习(Reinforcement Learning, RL)**正是专注于解决序贯决策问题的学习范式。它并非直接从标注好的静态数据集中学习,而是通过智能体与环境的直接交互,在"试错"中学习如何最大化其长期收益。
强化学习的框架可以用几个核心要素来描述:
- 智能体(Agent):学习者和决策者。在AlphaGo的例子中,就是其决策程序。
- 环境(Environment):智能体外部的一切,是智能体与之交互的对象。对AlphaGo而言,就是围棋的规则和对手。
- 状态(State, S):对环境在某一时刻的特定描述,是智能体做出决策的依据。例如,棋盘上所有棋子的当前位置。
- 行动(Action, A):智能体根据当前状态所能采取的操作。例如,在棋盘的某个合法位置上落下一子。
- 奖励(Reward, R):环境在智能体执行一个行动后,反馈给智能体的一个标量信号,用于评价该行动在特定状态下的好坏。例如,在一局棋结束后,胜利获得+1的奖励,失败获得-1的奖励。
-
基于大规模训数据的预训练
强化学习赋予了智能体从交互中学习决策策略的能力,但这通常需要海量的、针对特定任务的交互数据,导致智能体在学习之初缺乏先验知识,需要从零开始构建对任务的理解
- 预训练阶段:首先在一个包含互联网级别海量文本数据的通用语料库上,通过**自监督学习(Self-supervised Learning)**的方式训练一个超大规模的神经网络模型。这个阶段的目标不是完成任何特定任务,而是学习语言本身内在的规律、语法结构、事实知识以及上下文逻辑
- 微调阶段:完成预训练后,这个模型就已经学习到了和数据集有关的丰富知识。之后,针对特定的下游任务,只需使用少量该任务的标注数据对模型进行微调,即可让模型适应对应任务
-
基于大预言模型的智能体
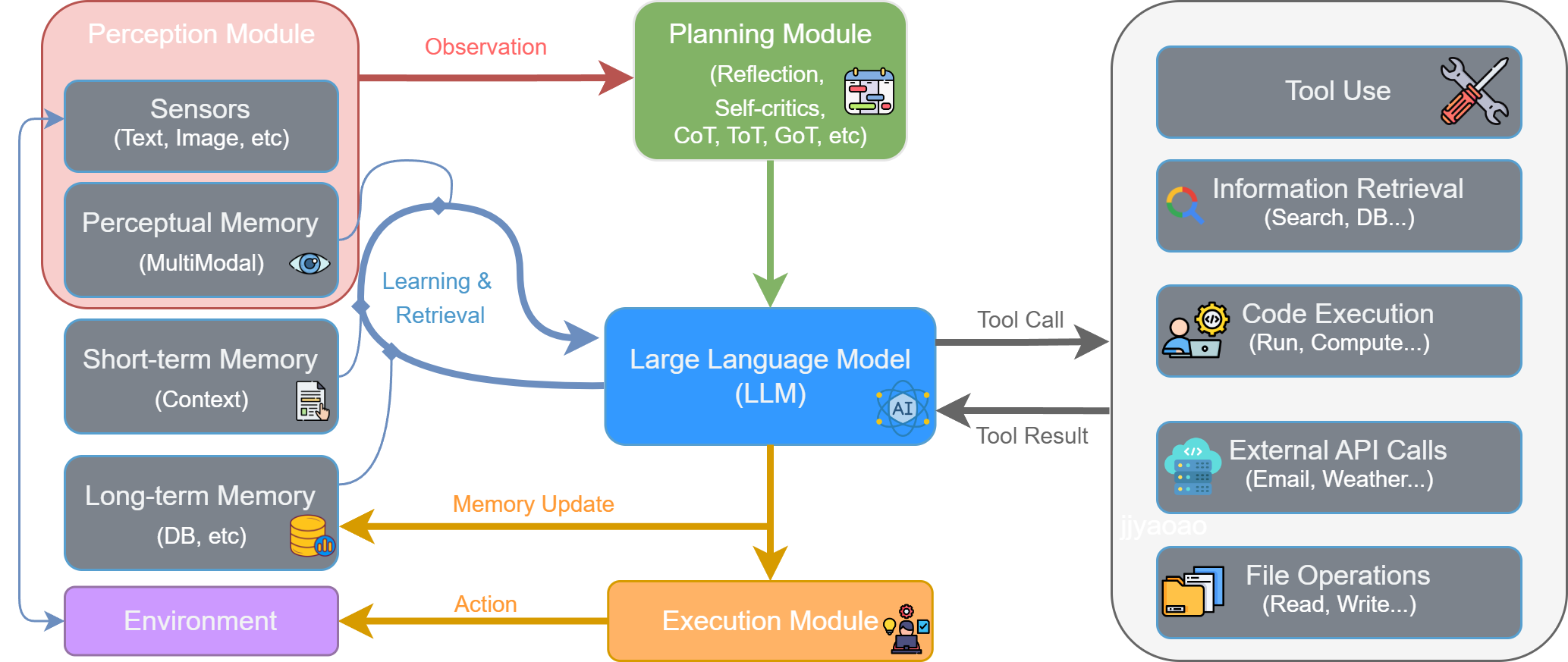
随着大型语言模型技术的飞速发展,以LLM为核心的智能体已成为人工智能领域的新范式。它不仅能够理解和生成人类语言,更重要的是,能够通过与环境的交互,自主地感知、规划、决策和执行任务
-
感知 (Perception) :流程始于感知模块 (Perception Module) 。它通过传感器从外部环境 (Environment) 接收原始输入,形成观察 (Observation)。这些观察信息(如用户指令、API返回的数据或环境状态的变化)是智能体决策的起点,处理后将被传递给思考阶段。
-
思考 (Thought) :智能体的认知核心,对应图中的规划模块 (Planning Module) 和大型语言模型 (LLM) 的协同工作。
-
规划与分解 :规划模块接收观察信息,进行高级策略制定。它通过反思 (Reflection) 和自我批判 (Self-criticism) 等机制,将宏观目标分解为更具体、可执行的步骤。
-
推理与决策 :作为中枢的LLM 接收来自规划模块的指令,并与记忆模块 (Memory) 交互以整合历史信息。LLM进行深度推理,最终决策出下一步要执行的具体操作,这通常表现为一个工具调用 (Tool Call)。
-
-
行动 (Action) :决策完成后,便进入行动阶段,由执行模块 (Execution Module) 负责。LLM生成的工具调用指令被发送到执行模块。该模块解析指令,从工具箱 (Tool Use) 中选择并调用合适的工具(如代码执行器、搜索引擎、API等)来与环境交互或执行任务。这个与环境的实际交互就是智能体的行动 (Action)。
-
观察 (Observation) 与循环 :行动会改变环境的状态,并产生结果。
-
工具执行后会返回一个工具结果 (Tool Result) 给LLM,这构成了对行动效果的直接反馈。同时,智能体的行动改变了环境,从而产生了一个全新的环境状态。
-
"工具结果"和"新的环境状态"共同构成了一轮全新的观察 (Observation) 。这个新的观察会被感知模块再次捕获,同时LLM会根据行动结果更新记忆 (Memory Update),从而启动下一轮"感知-思考-行动"的循环。
-
-