案例地址:猫眼电影票房
确定加密数据
首先找到数据包:
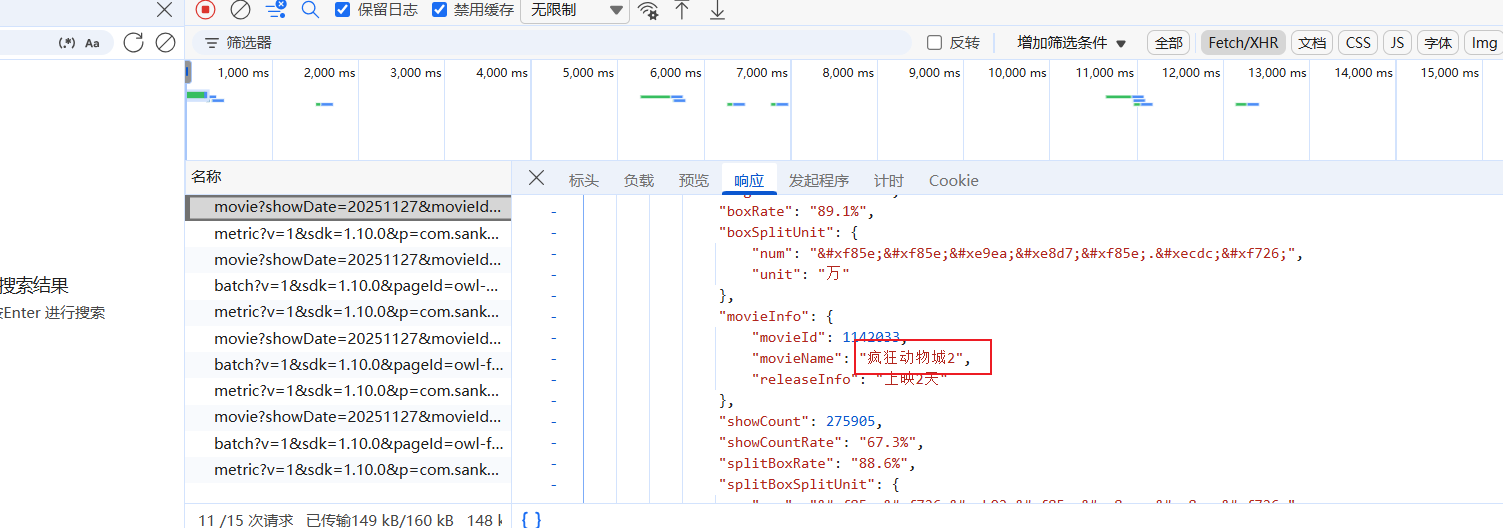
看请求头,有两个参数加密:
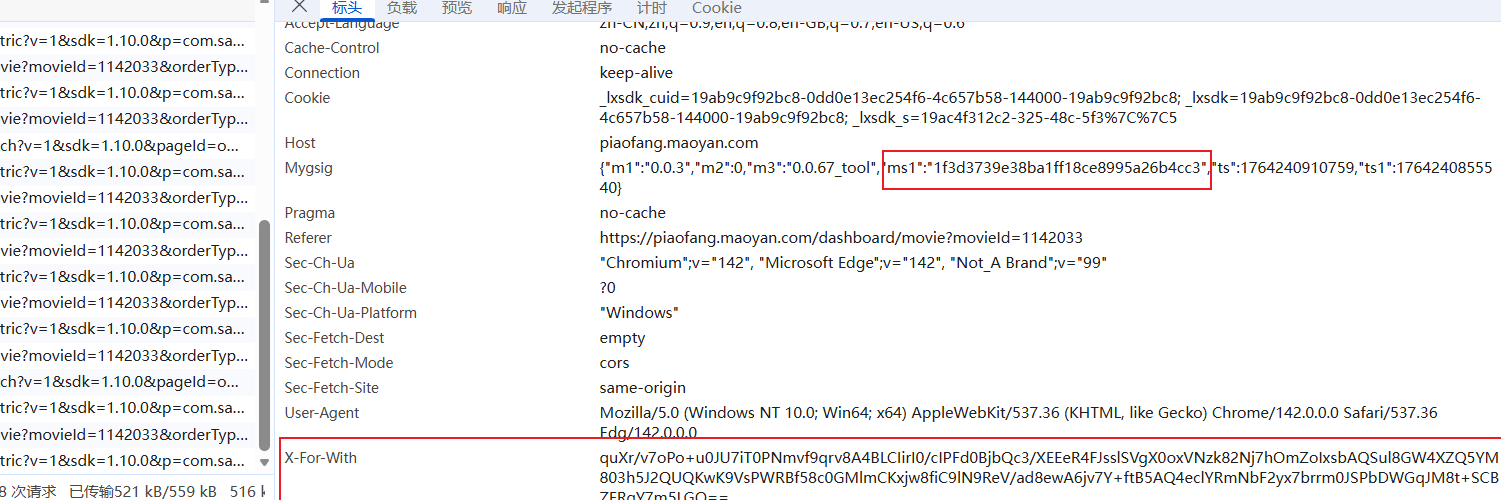
再看负载:
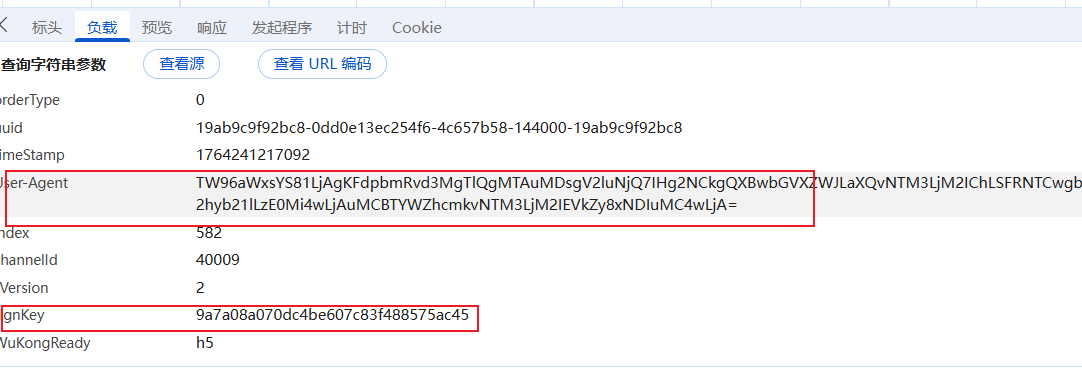
又有两个,面对这种请求参数比较多的,可以直接生成基础爬虫代码然后通过注释来判断哪些需要逆向:
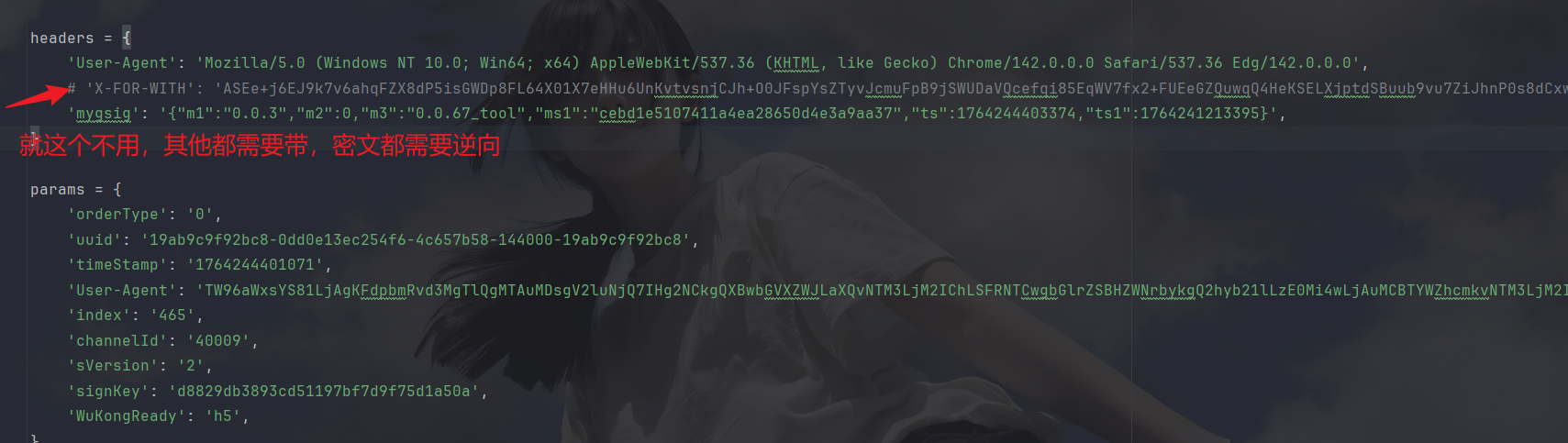
我们先逆向请求头的参数
复现请求头加密
这里有混淆,但是运气好关键字可以搜到,不过我还是带大家用xhr定位一下:
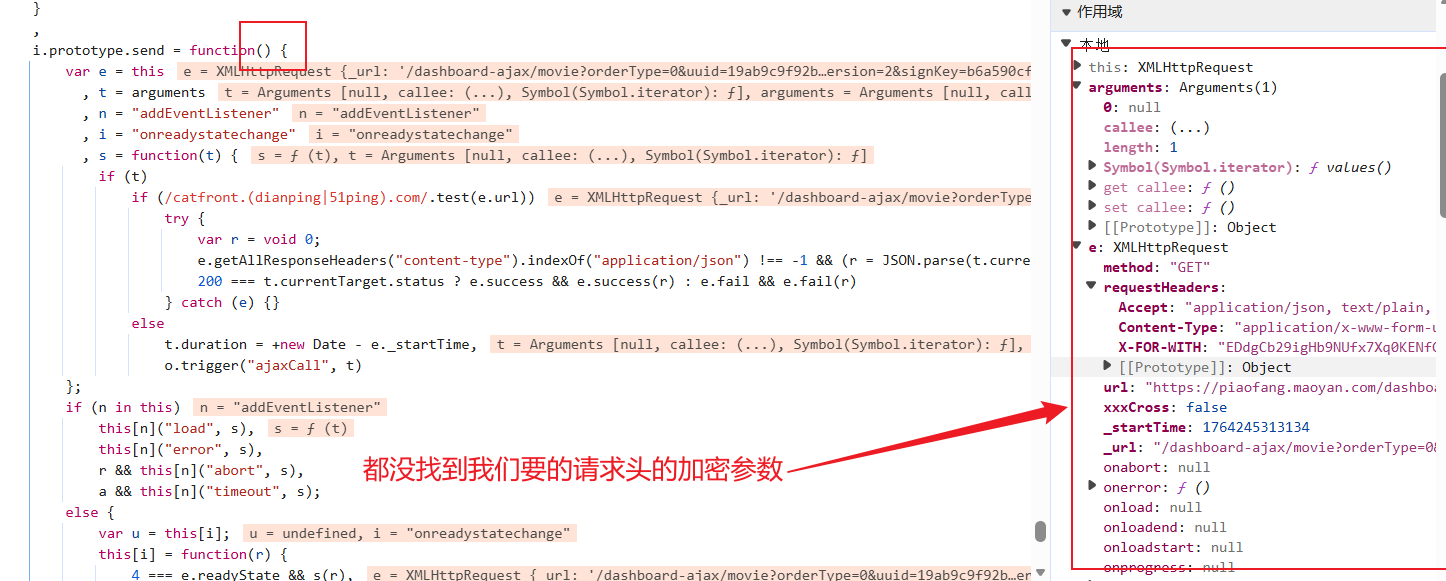
跟上一个栈:
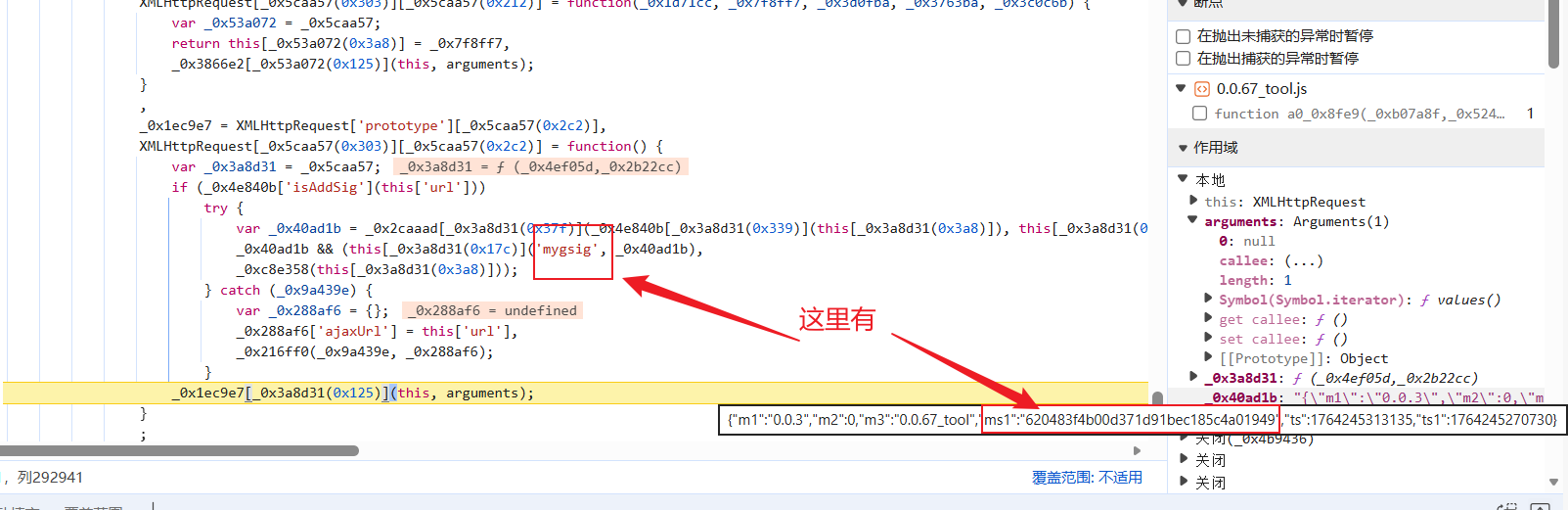
看一下这行代码是干啥的:
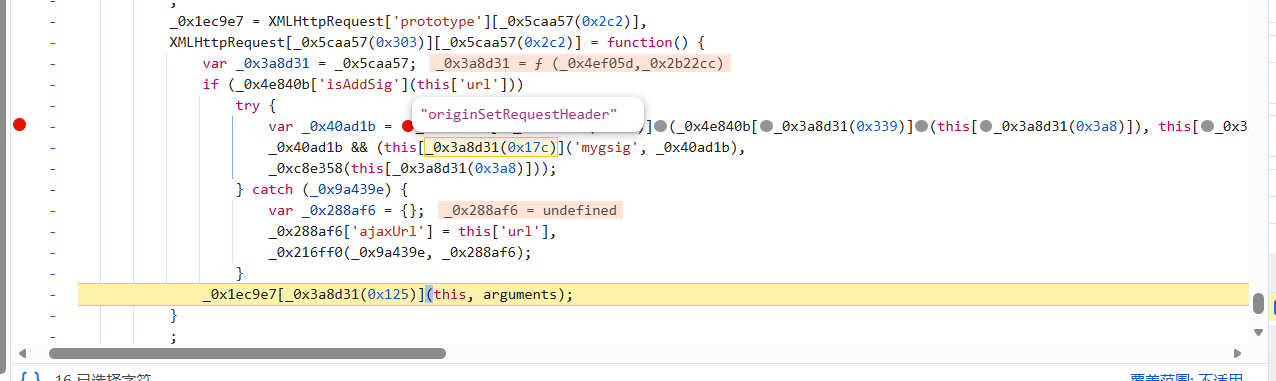
这里这个意思是设置原始的请求头,应该是将那个加密参数赋值后(因为后面有另一个入参)填进原始的请求头,那上一行应该是加密的密文,控制台输出一下:

果然如此,那就将断点打在生成密文那一行,分析一下:
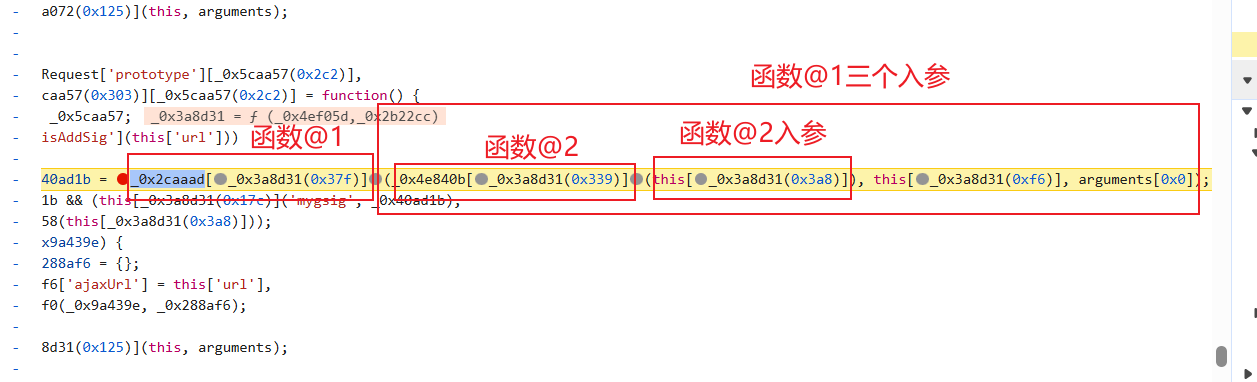
其实我们只需要ms1,其他都不变,所以入参暂时不需要太过关注,我们进函数@1中看看ms1怎么生成的,进来发现集体赋值的位置:
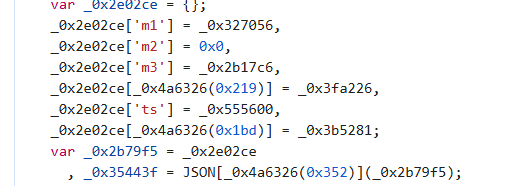
看看我们要的参数在不在:
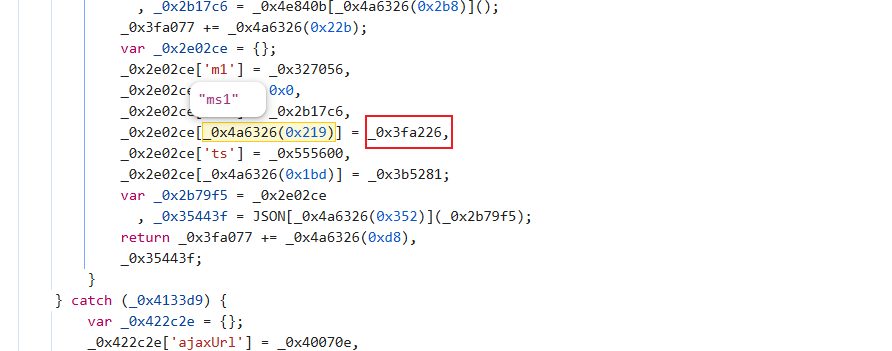
是在这里赋值的,现在看这个值在哪儿生成:
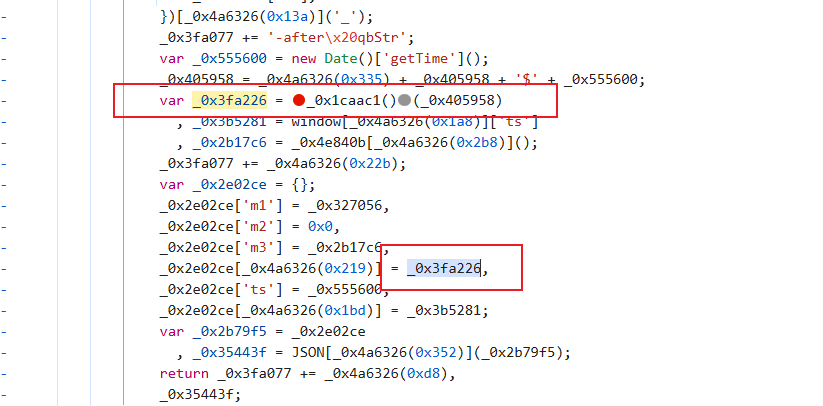
找到了,打断点运行过来:
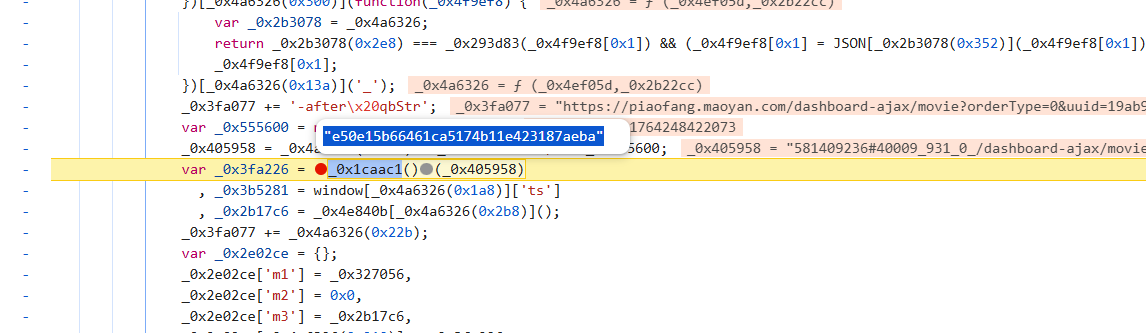
确定一下是啥加密:
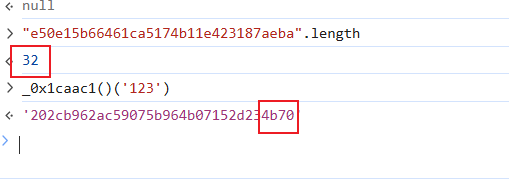
不必多言,md5且标准,直接写代码:
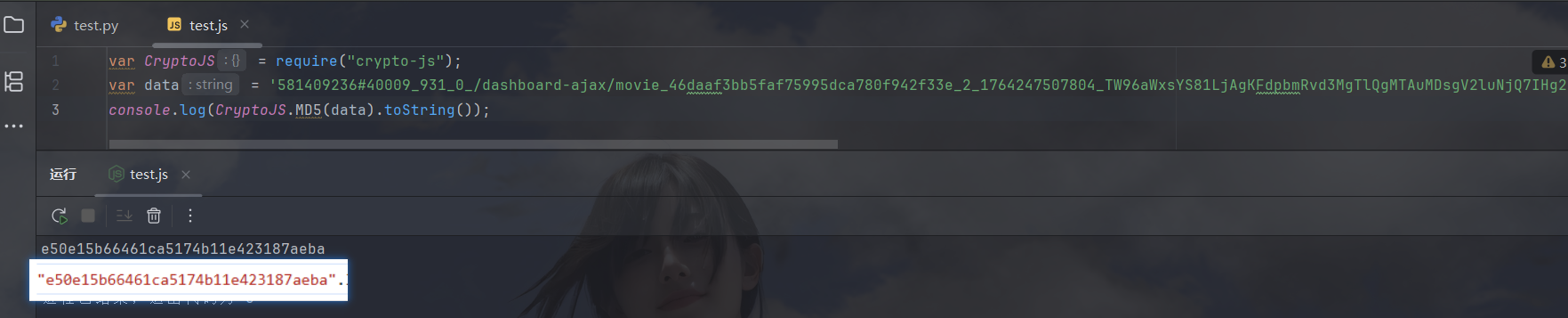
现在需要找一下此函数的入参赋值位置以及看一下它是怎么生成的:
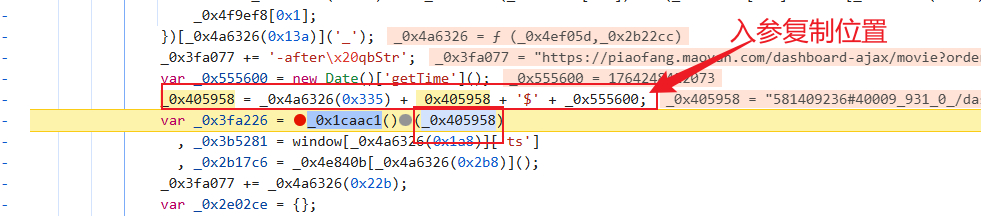
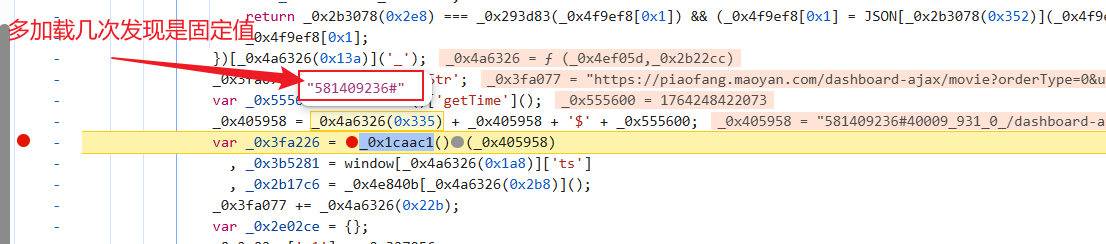
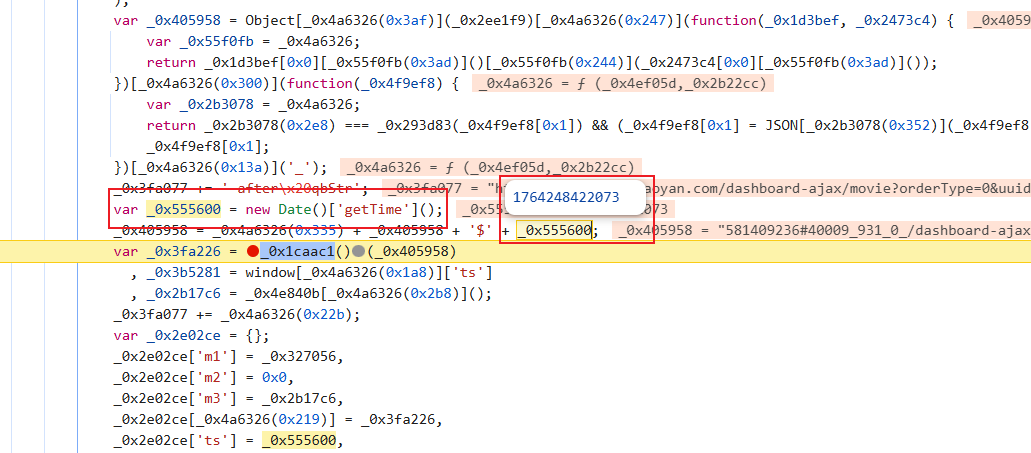
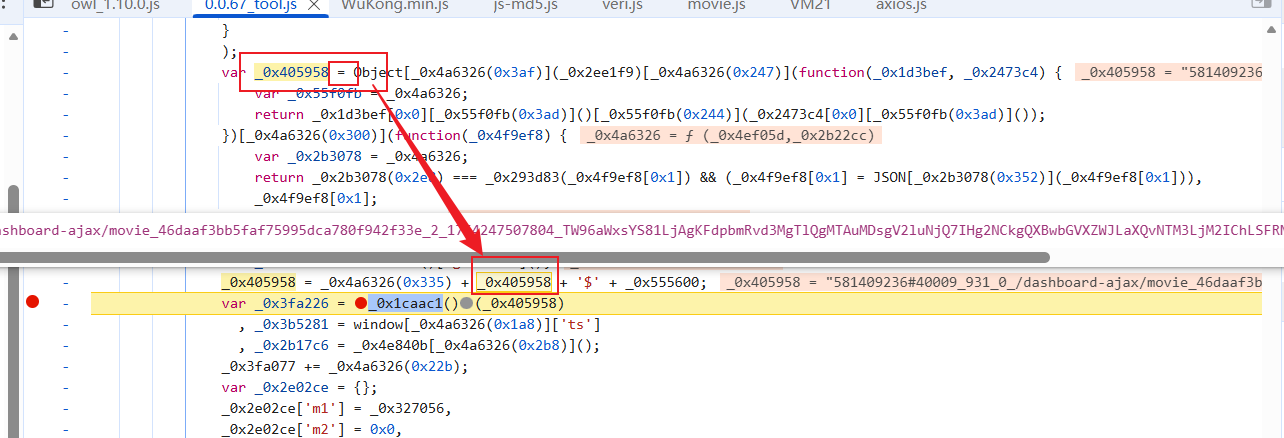
该拿拿,该写写:
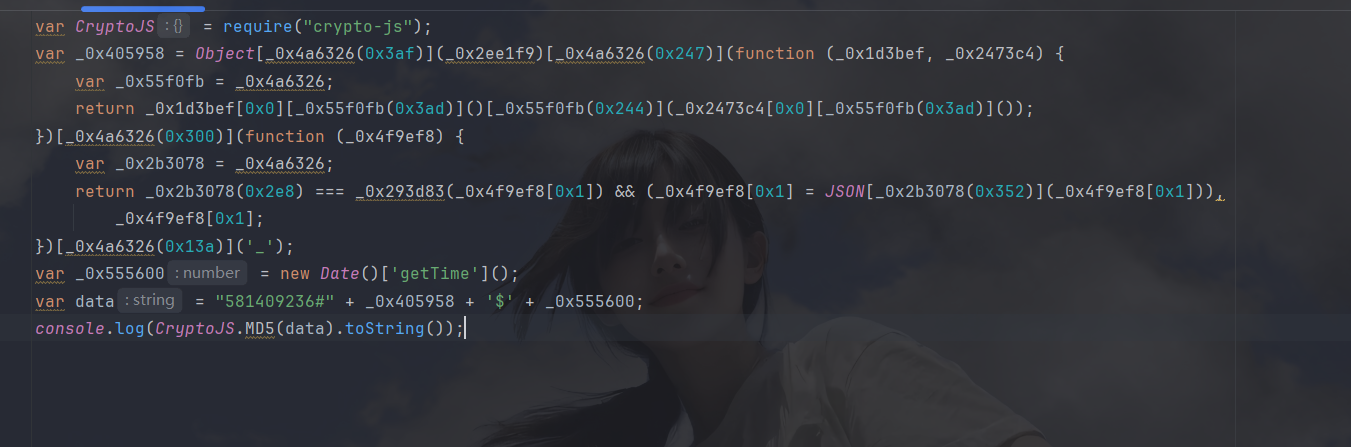
这里的混淆直接扣就行,不拿那三个函数了(大数组 解密 自执行):
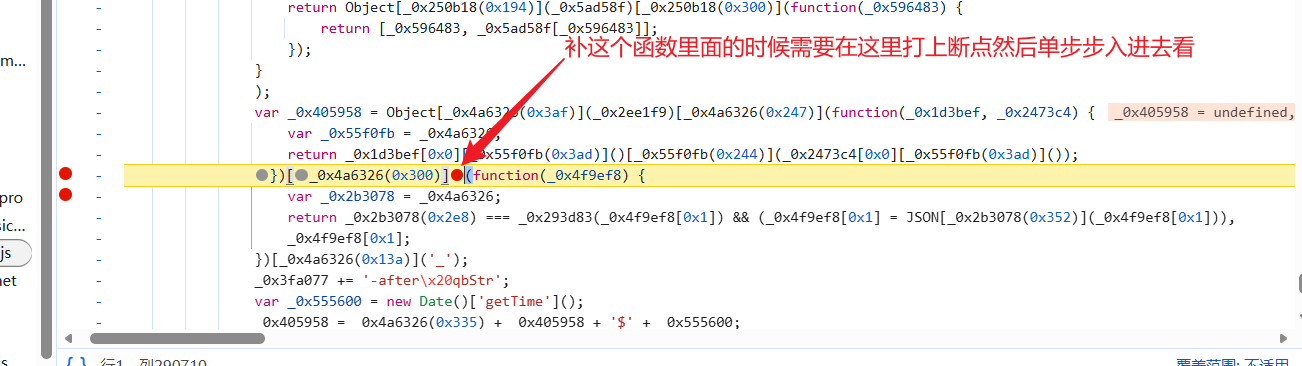
补完如下:
javascript
var CryptoJS = require("crypto-js");
var _0x2ee1f9 = {
"WuKongReady": "h5",
"signKey": "51c1a1a699e785b53666899b414f8294",
"sVersion": "2",
"channelId": "40009",
"index": "798",
"User-Agent": "TW96aWxsYS81LjAgKFdpbmRvd3MgTlQgMTAuMDsgV2luNjQ7IHg2NCkgQXBwbGVXZWJLaXQvNTM3LjM2IChLSFRNTCwgbGlrZSBHZWNrbykgQ2hyb21lLzE0Mi4wLjAuMCBTYWZhcmkvNTM3LjM2IEVkZy8xNDIuMC4wLjA=",
"timeStamp": "1764249665075",
"uuid": "19ab9c9f92bc8-0dd0e13ec254f6-4c657b58-144000-19ab9c9f92bc8",
"orderType": "0",
"path": "/dashboard-ajax/movie"
}
var _0x405958 = Object["entries"](_0x2ee1f9)["sort"](function (_0x1d3bef, _0x2473c4) {
// var _0x55f0fb = _0x4a6326; // 这里是解密函数赋值,不管了
return "signKey"["toLowerCase"]()["localeCompare"]("WuKongReady"["toLowerCase"]());
})["map"](function (_0x4f9ef8) {
// var _0x2b3078 = _0x4a6326; // 这里是解密函数赋值,不管了
return "40009"
})["join"]('_');
var _0x555600 = new Date()['getTime']();
var data = "581409236#" + _0x405958 + '$' + _0x555600;
console.log(CryptoJS.MD5(data).toString());_0x2ee1f9这个参数中还有需要改的地方,这和我们下面复现的有关系
复现负载加密
依旧xhr定位:
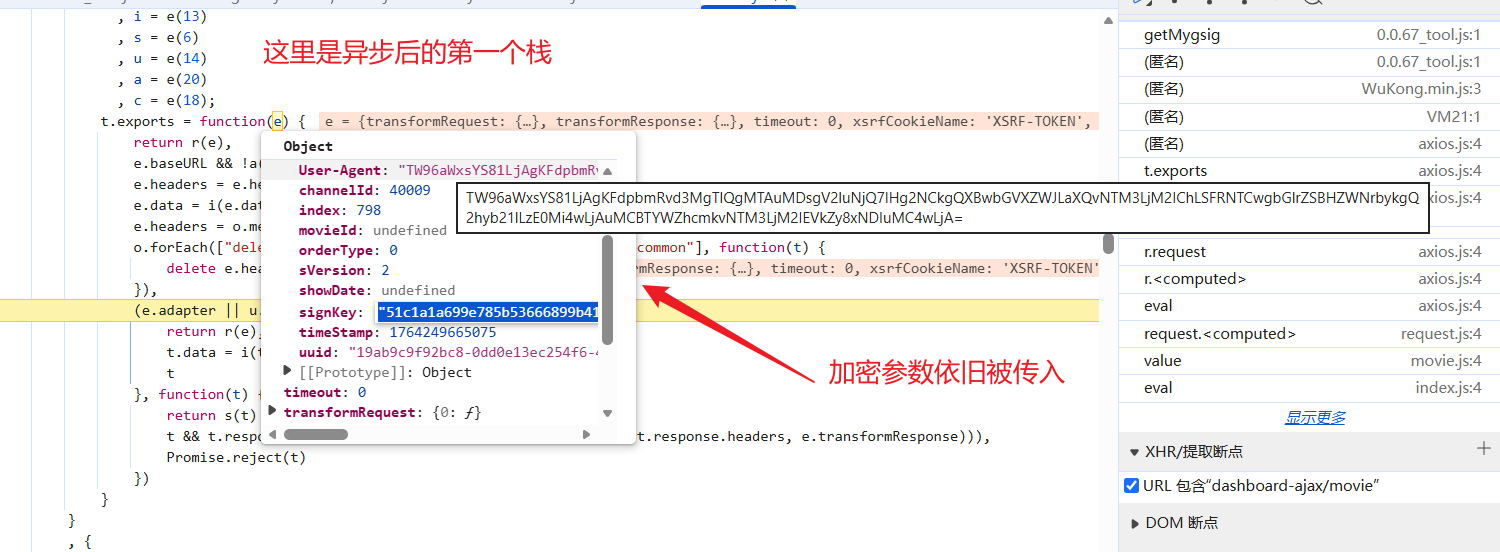
在异步前打断点进入异步前:
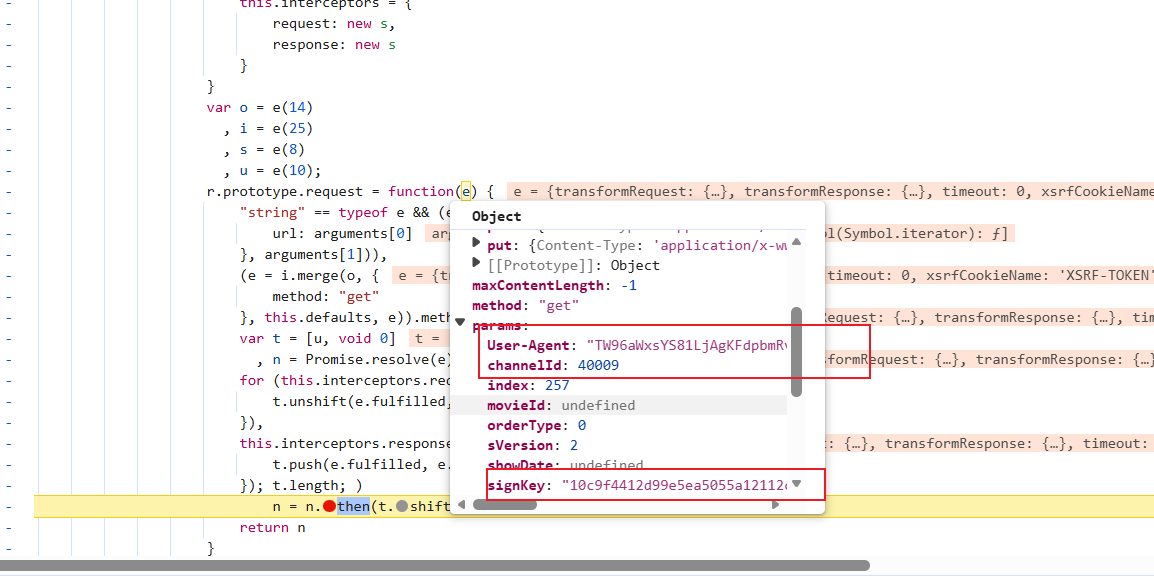
异步前依旧还有加密参数被传入,再往前跟栈:
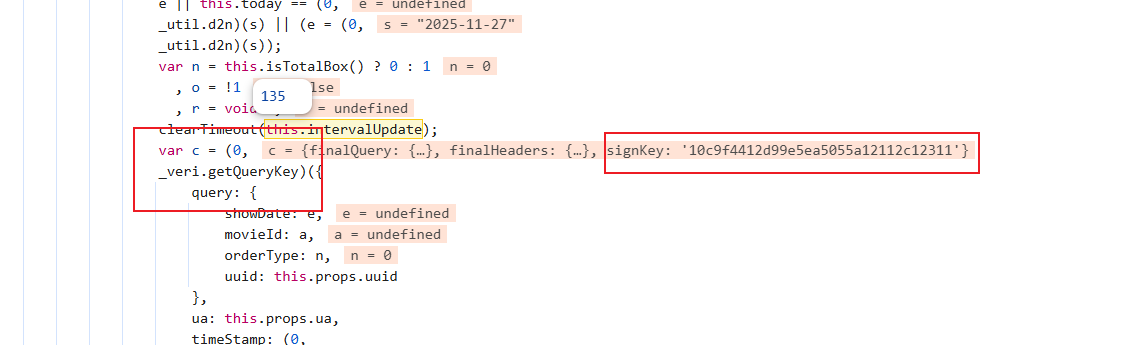
最后找到了,c赋值的位置是密文生成的位置,进函数看看:
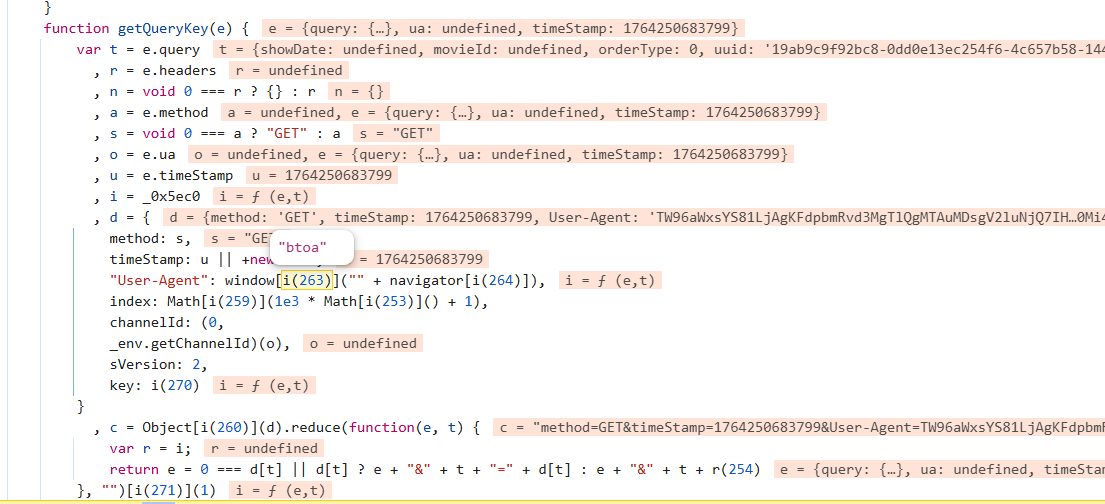
这里有user-agent怎么生成的,是base64伪加密,继续先下运行看右侧那里产生signKey密文:
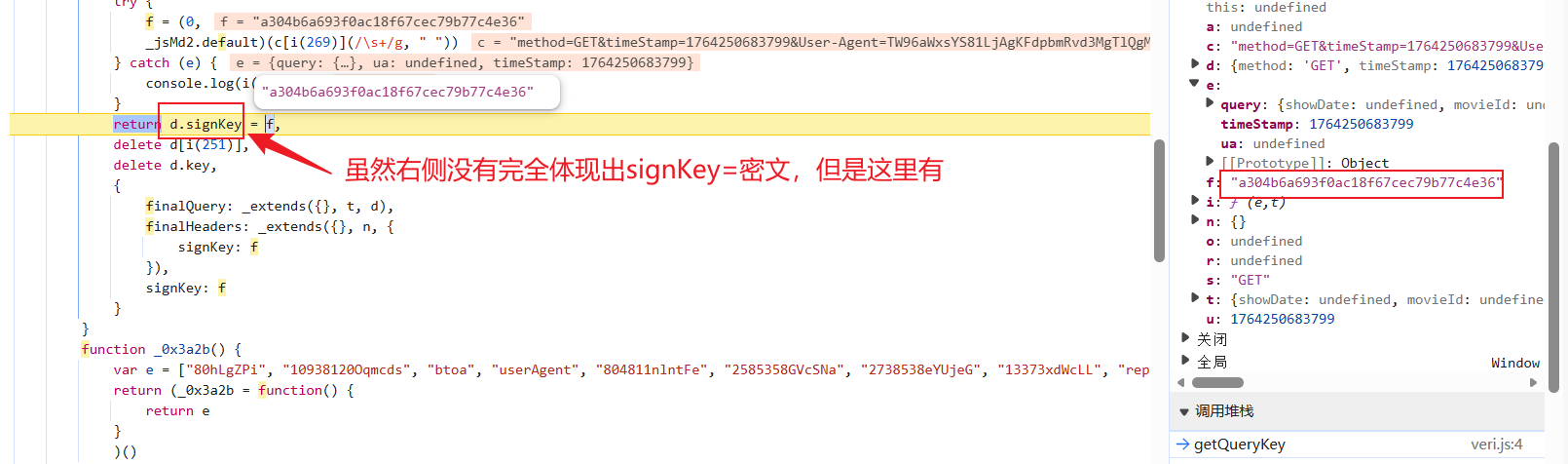
下面开始找f怎么生成的:
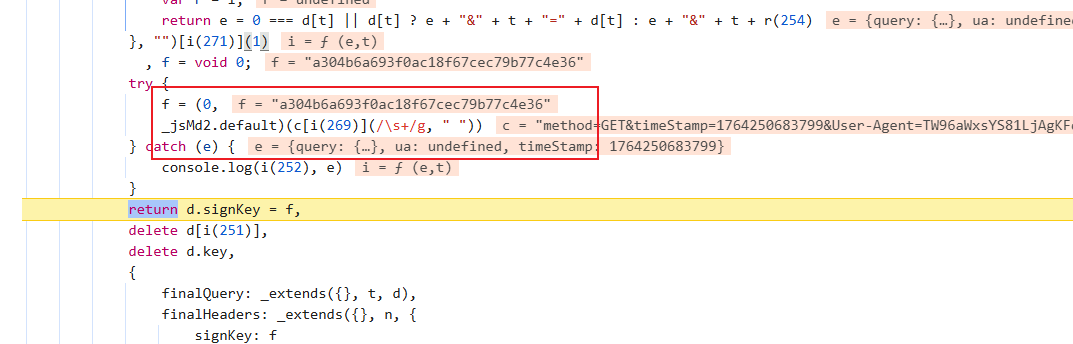
找到了,打断点然后运行过来开始分析:
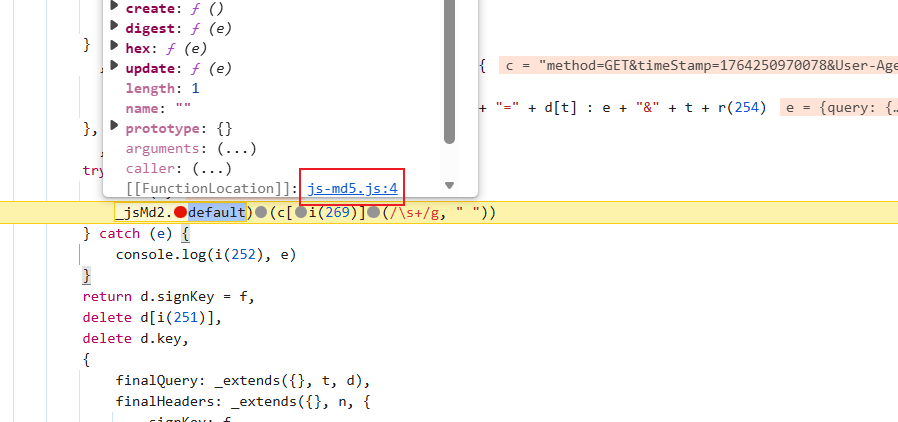
根据长度和这个名字,大概就是md5了,验证一下:
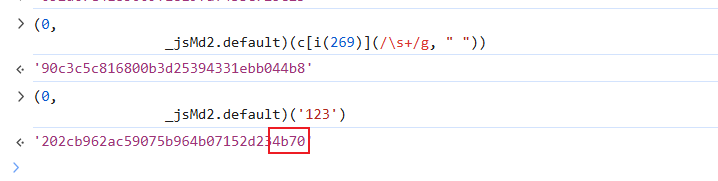
标准md5加密,再手写一下:

然后将c找到并拿下来:
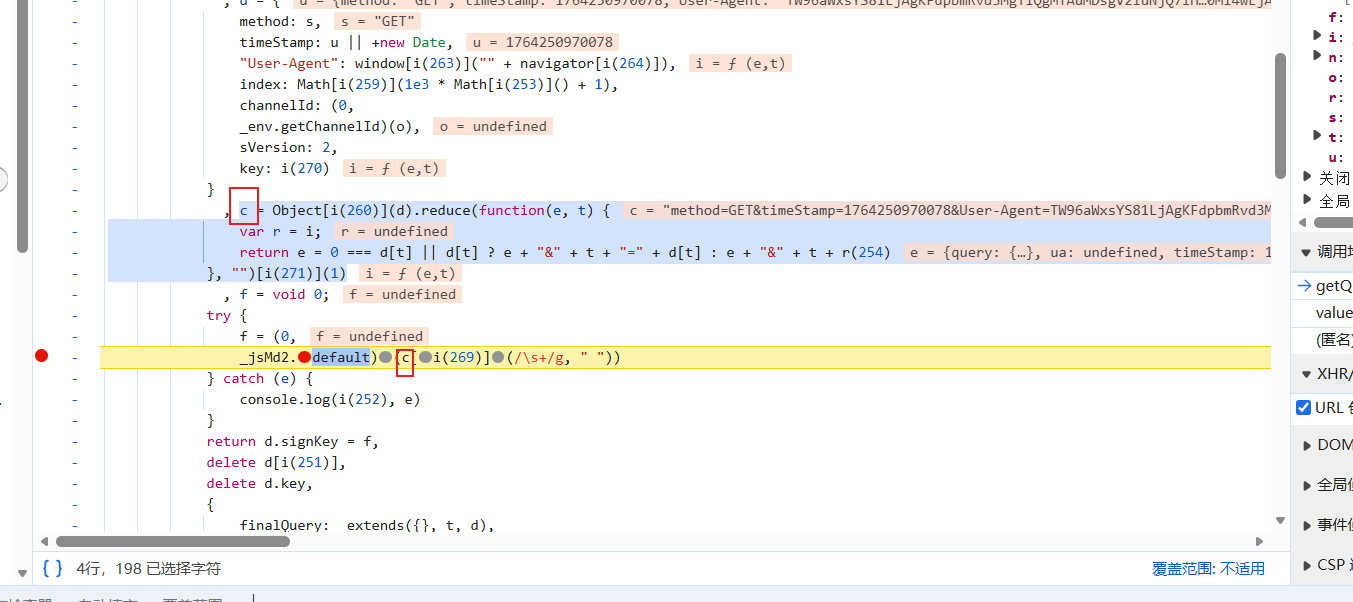
这里还有混淆i(xxx)全扣下来:
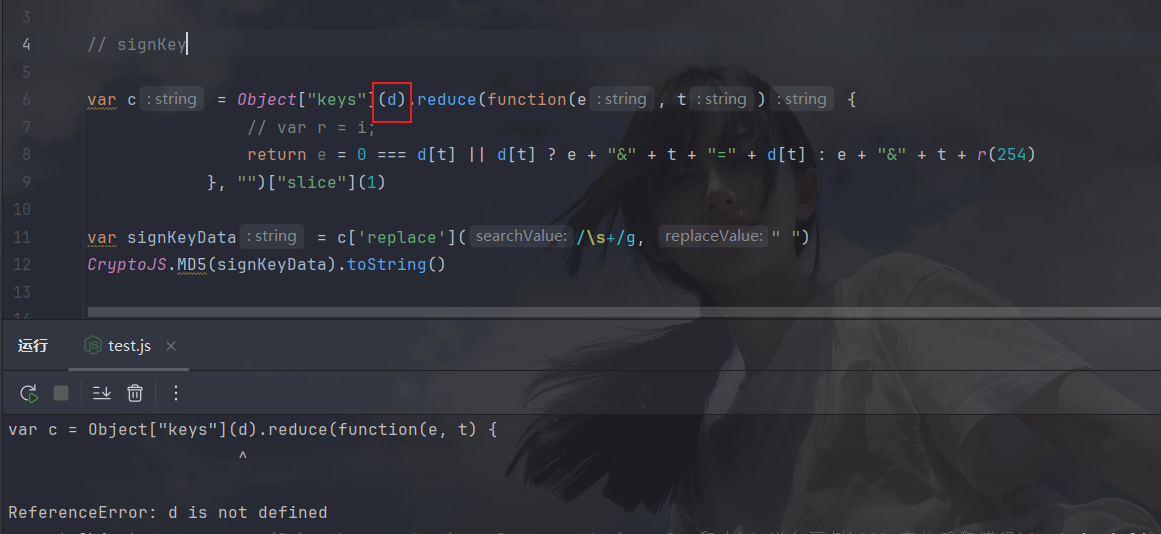
现在找d:
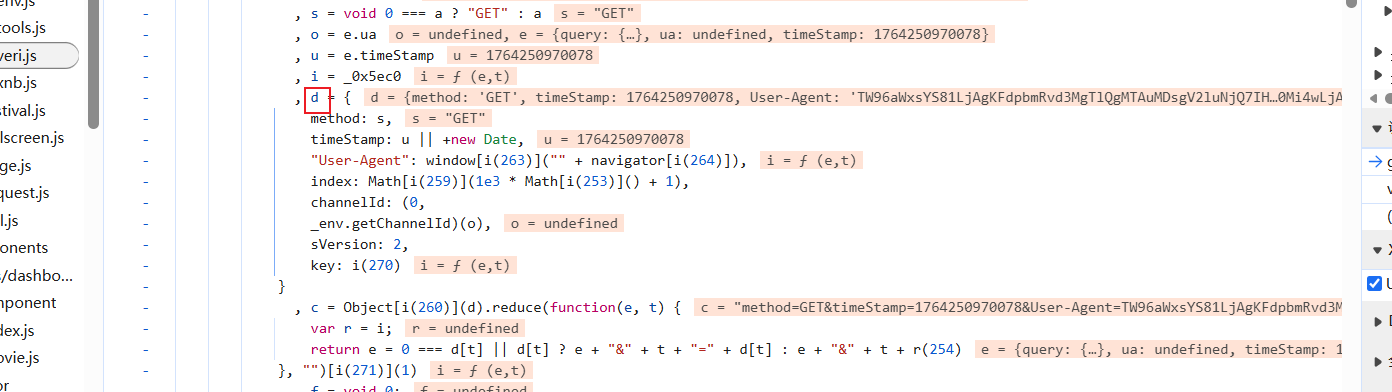
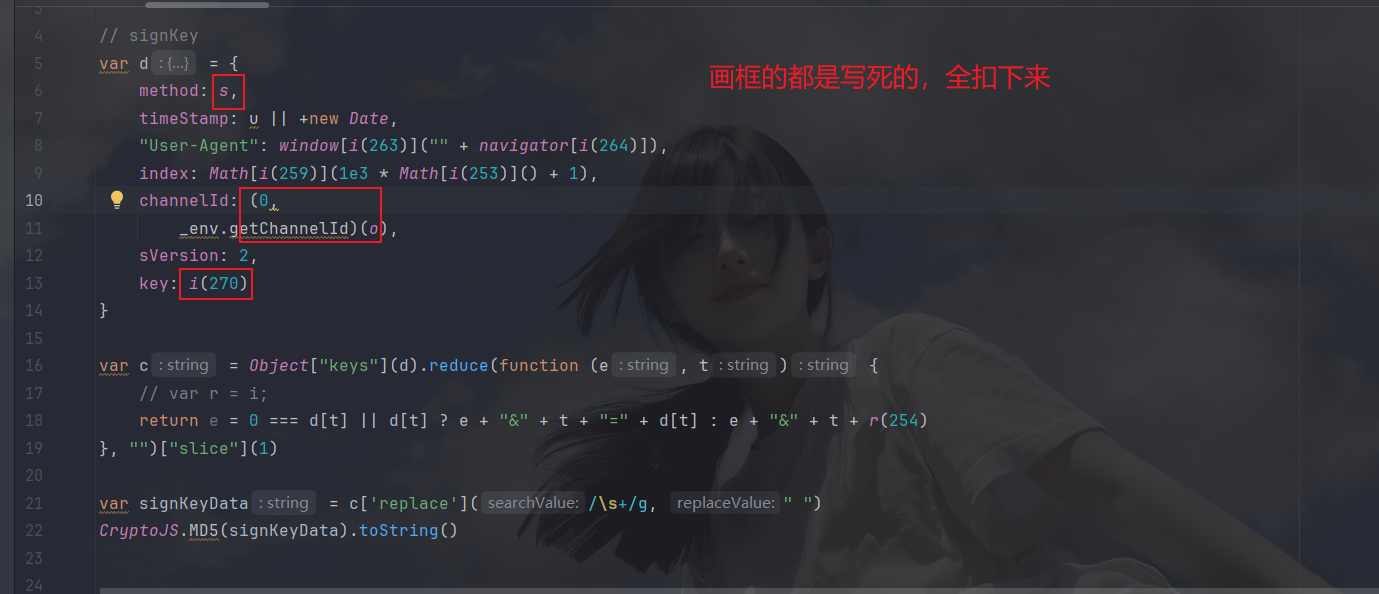
扣完后运行:
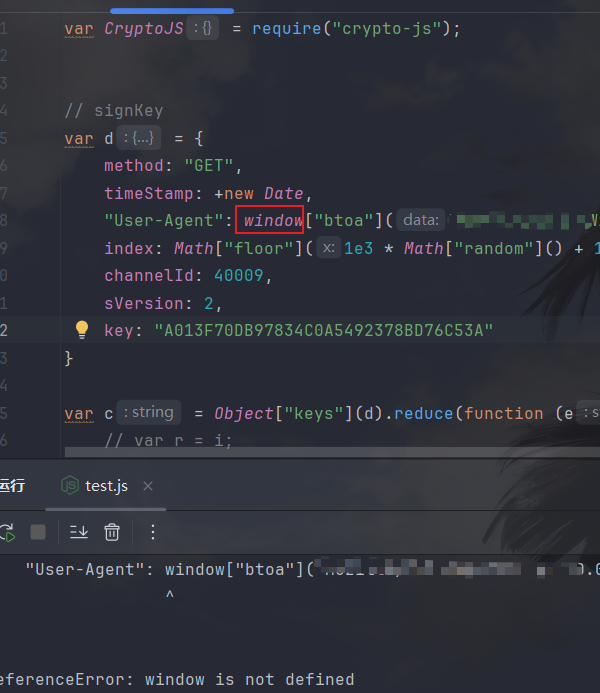
window = global;写一下,然后运行发现不报错了,打印一下:
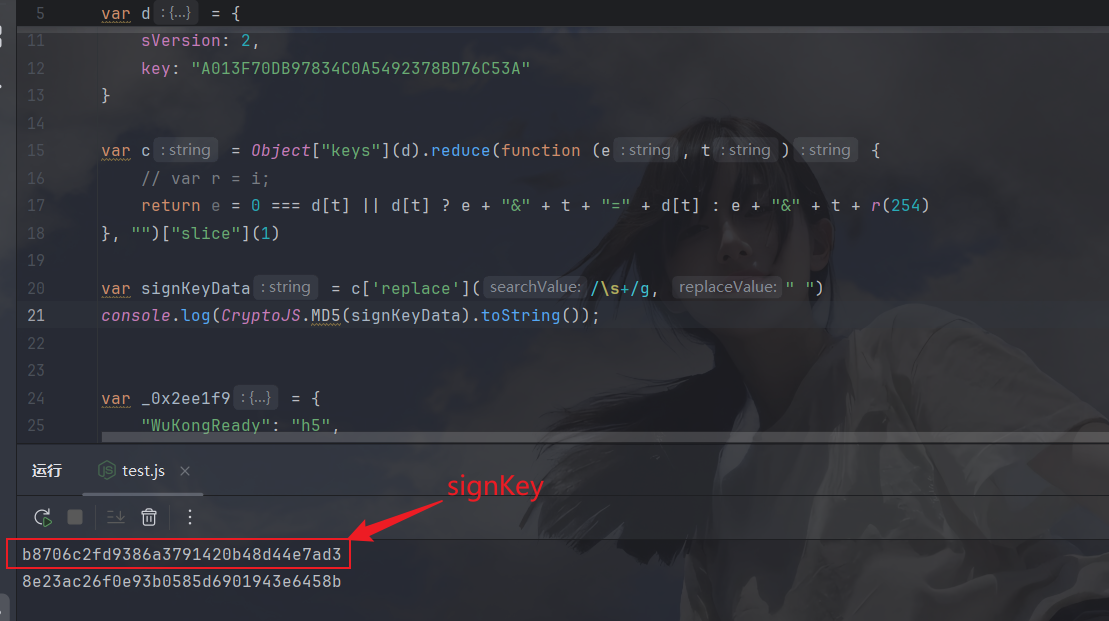
封装一下函数
封装
封装会有坑点,写博客之前自己做了一遍,出错时代码是这样的:
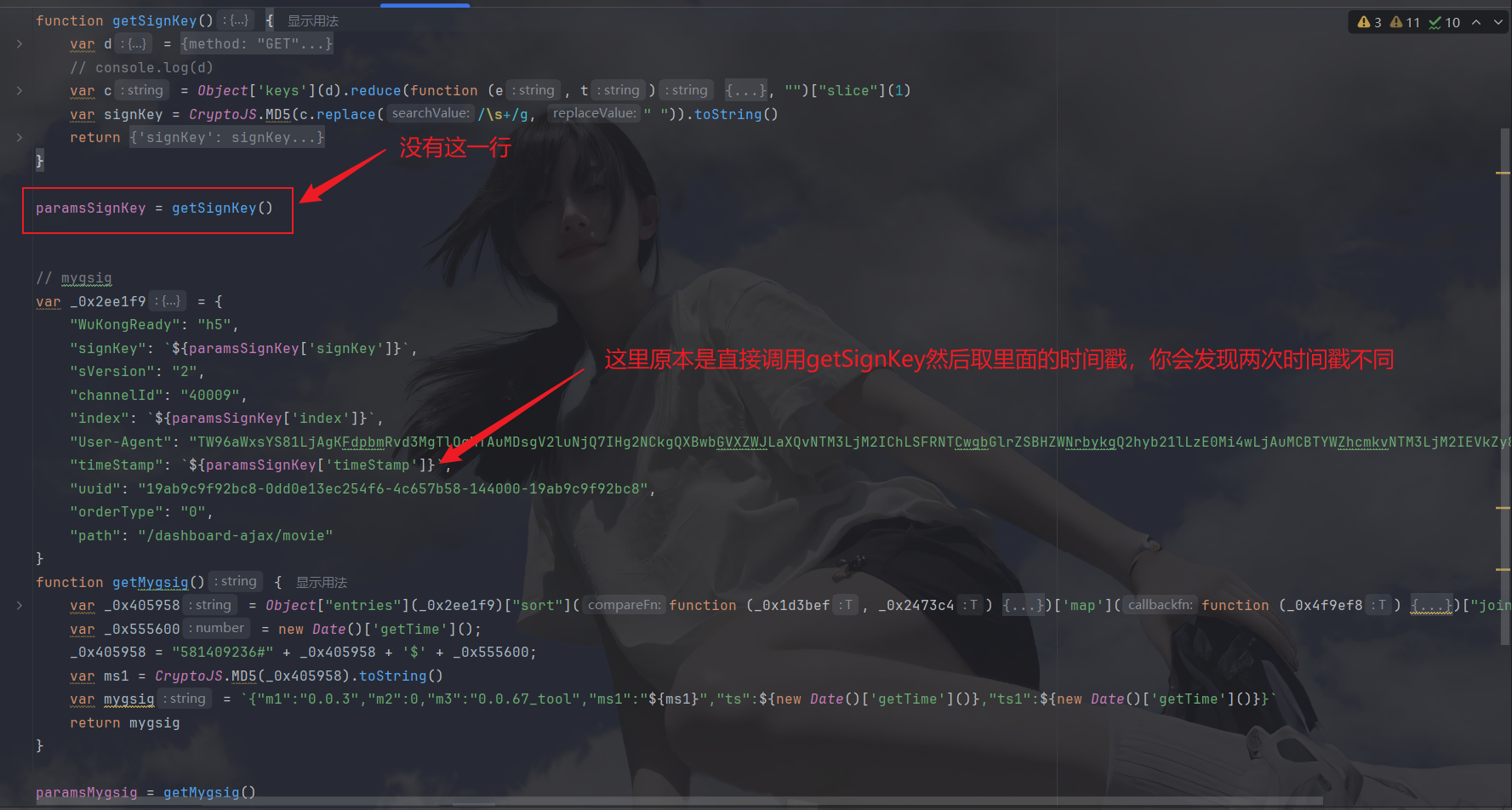
啥意思呢,就是本来getSignKey这个函数就返回了一次时间戳了,而下一个参数本应该使用第一次返回出的时间戳进行加密,我却再次调用函数取出第二次返回值中的时间戳(误以为调用后返回的时间戳就是之前的时间戳,殊不知调用时已经过了一段时间导致时间戳变化)这时时间戳不同了,后端校验失败了,所以说,**有相同的变量值需要再次使用时,要么封装在一个函数中直接取,要么就调用函数赋值给一个变量固定住返回值种变化的值(时间戳,随机数等)然后再使用,OK,有了这次教训,下面开始封装函数:
javascript
var CryptoJS = require("crypto-js");
window = global;
// signKey
var d = {
method: "GET",
timeStamp: +new Date,
"User-Agent": window["btoa"](自己的ua),
index: Math["floor"](1e3 * Math["random"]() + 1),
channelId: 40009,
sVersion: 2,
key: "A013F70DB97834C0A5492378BD76C53A"
}
var c = Object["keys"](d).reduce(function (e, t) {
// var r = i;
return e = 0 === d[t] || d[t] ? e + "&" + t + "=" + d[t] : e + "&" + t + r(254)
}, "")["slice"](1)
var signKeyData = c['replace'](/\s+/g, " ")
function getParams() {
var signKey = CryptoJS.MD5(signKeyData).toString(),
_0x2ee1f9 = {
"WuKongReady": "h5",
"signKey": signKey,
"sVersion": "2",
"channelId": "40009",
"index": d['index'],
"User-Agent": d['User-Agent'],
"timeStamp": d['timeStamp'],
"uuid": "19ab9c9f92bc8-0dd0e13ec254f6-4c657b58-144000-19ab9c9f92bc8",
"orderType": "0",
"path": "/dashboard-ajax/movie"
}
var _0x405958 = Object["entries"](_0x2ee1f9)["sort"](function (_0x1d3bef, _0x2473c4) {
// var _0x55f0fb = _0x4a6326; // 这里是解密函数赋值,不管了
return "signKey"["toLowerCase"]()["localeCompare"]("WuKongReady"["toLowerCase"]());
})["map"](function (_0x4f9ef8) {
// var _0x2b3078 = _0x4a6326; // 这里是解密函数赋值,不管了
return "40009"
})["join"]('_');
var _0x555600 = new Date()['getTime']();
var mygsigData = "581409236#" + _0x405958 + '$' + _0x555600;
var mygsig = CryptoJS.MD5(mygsigData).toString()
return {
'mygsig': mygsig,
'signKey': signKey,
'timeStamp':_0x2ee1f9['timeStamp'],
'index': d['index'],
}
}
console.log(getParams());py调用发现得不到结果,其实我们扣代码时还会有坑:
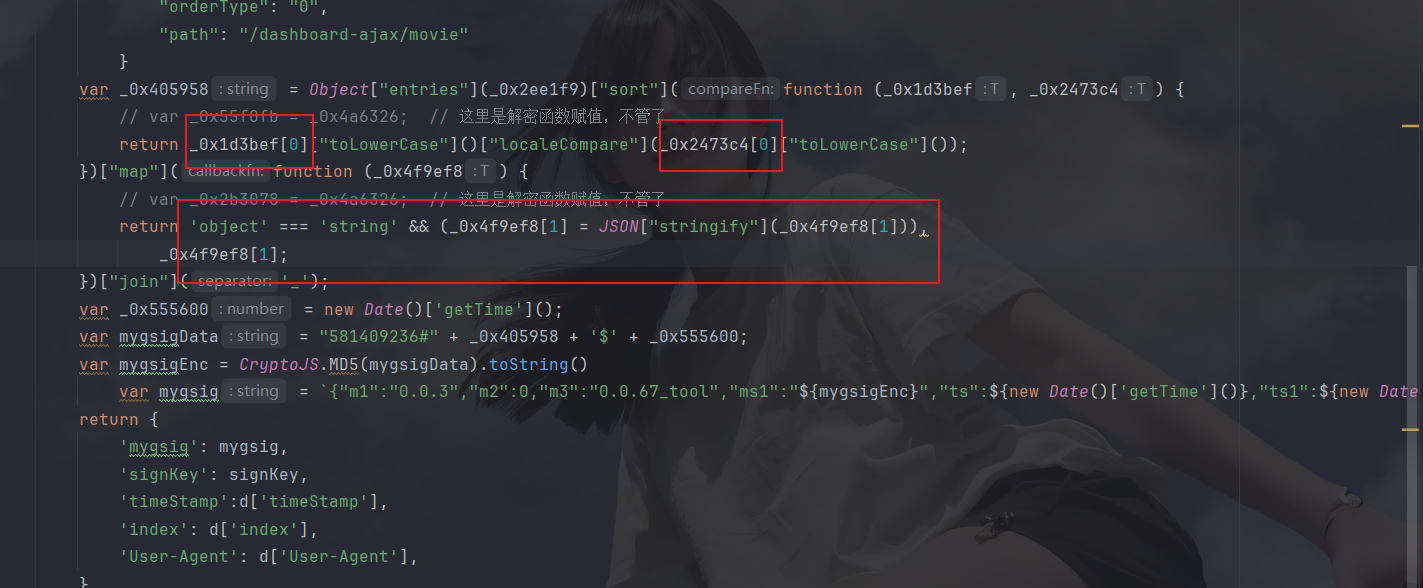
这里都不能写死,因为它取了每一个键,所以有索引那些都是会根据键的不同而改变,不能写死,改回来之后,调用:
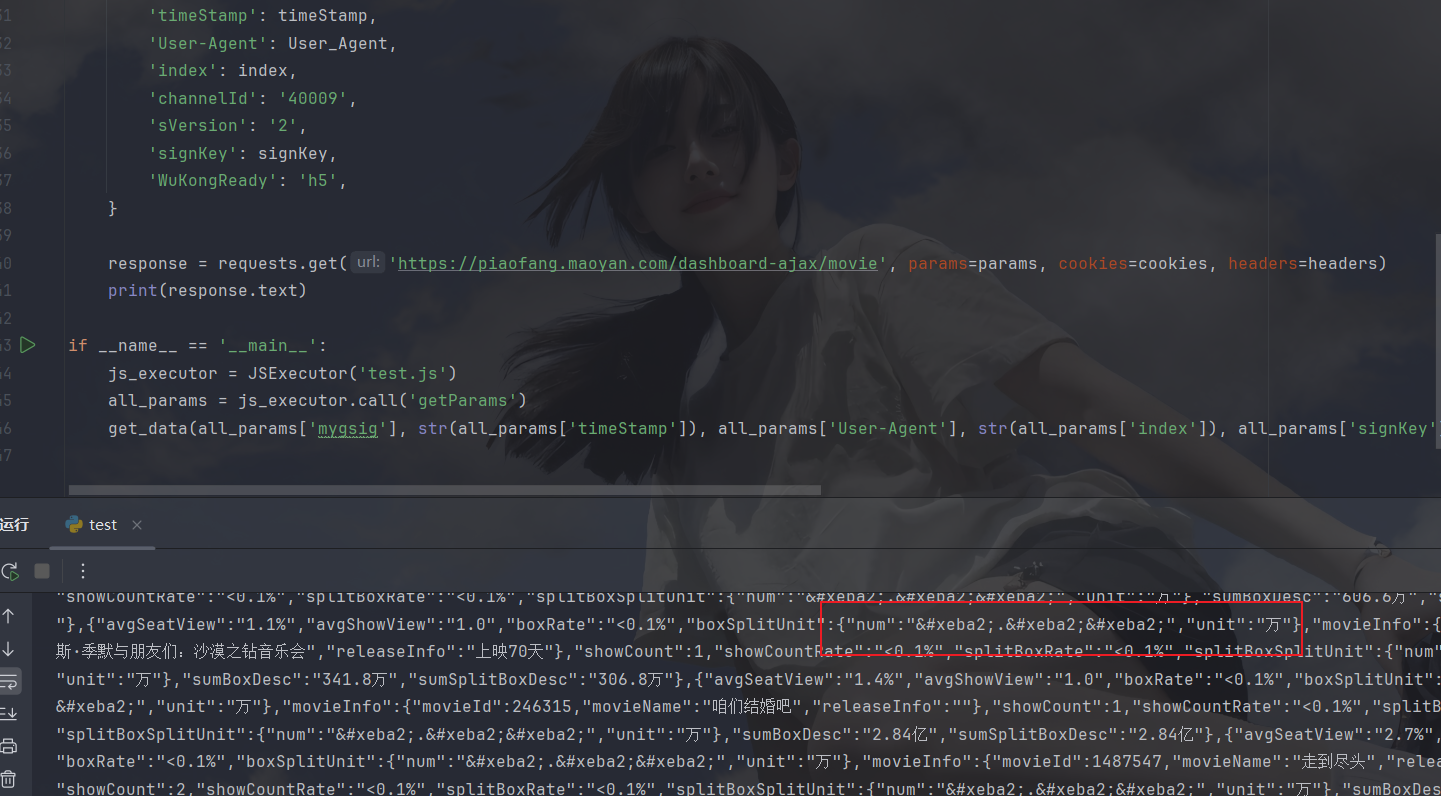
ok出结果了,这里发现有好多数据都是乱七八糟的'乱码',下面就是重点了,字体文件保存,解析,绘图和识别
字体处理
字体处理首先需要先找到字体文件才行啊,观察后发现字体文件就藏在返回值中:

先通过字典结合re正则提取出来关键字符串,然后拼接https://来得到字体文件:

然后保存字体文件并转换为xml文件:
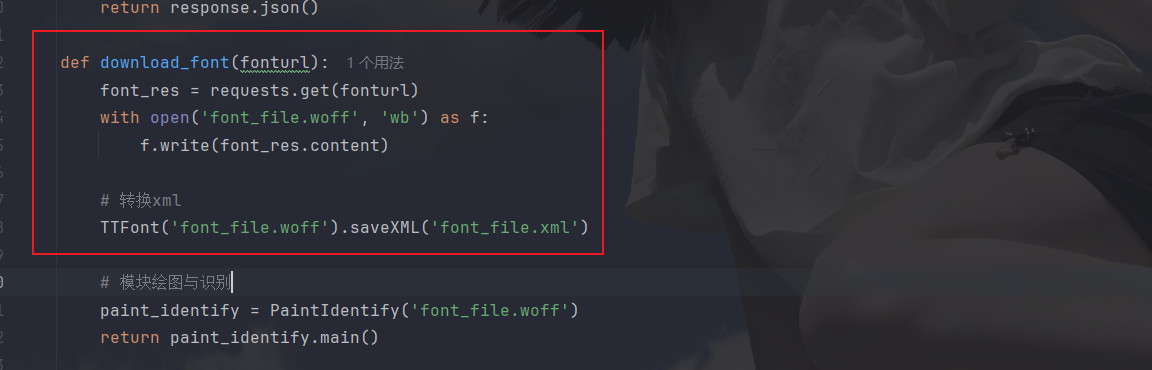
下面开始写class来绘图和识别:
javascript
import ddddocr
from lxml import etree
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
class PaintIdentify:
def __init__(self, font_file_path):
self.font_file_path = font_file_path
def identify(self, font_name):
ocr = ddddocr.DdddOcr()
with open(f'图片/{font_name}.png', 'rb') as f:
image = f.read()
res = ocr.classification(image)
return res
def paint(self, eve_font_lst, font_name):
# 创建画布
plt.figure(figsize=(10, 10))
for shape in eve_font_lst:
x, y = zip(*[(int(point[0]), int(point[1])) for point in shape])
# print(x, y)
plt.plot(x, y, marker='o')
plt.fill(x, y, alpha=0.3)
plt.xticks([])
plt.yticks([]) # 隐藏刻度标签
# 设置绘图属性
plt.axis('equal') # 坐标轴比例一致
plt.grid(True)
# 保存图片
plt.savefig('图片/' + f'{font_name}' + '.png')
def font_parser(self, x_y):
if x_y.xpath('./contour'):
# 每个字总的lst,在此函数外还有一个循环
eve_font_lst = []
# print(x_y)
font_name = x_y.xpath('./@name')
print(font_name)
# 拿每个字的坐标
font_contour = x_y.xpath('./contour') # 此时还是内存地址,需要循环取出
for contour in font_contour:
x_y_lst = [(x, y) for x, y in zip(contour.xpath('./pt/@x'), contour.xpath('./pt/@y'))]
x_y_lst.append(x_y_lst[0])
eve_font_lst.append(x_y_lst)
# print(eve_font_lst)
# 画图
self.paint(eve_font_lst, font_name)
# 识别
res = self.identify(font_name)
return font_name[0], res
return None
def main(self):
charactor_name_dic = {}
# 读取xml文件
with open('font_file.xml', 'r', encoding='utf-8') as f:
xml_code = f.read().encode('utf-8')
# 解析xml
tree = etree.XML(xml_code)
TTGlyph = tree.xpath('//glyf/TTGlyph')[1:-1]
for every_x_y in TTGlyph:
key, value = self.font_parser(every_x_y)
charactor_name_dic[key] = value
return charactor_name_dic
if __name__ == '__main__':
paint_identify = PaintIdentify('font_file.xml')
print(paint_identify.main())上面代码思路很简单:其实就是通过lxml来解析xml文件然后取出x y坐标和映射名,然后通过matplotlib画图,再通过ddddocr来识别然后返回映射名与识别内容形成的字典,写完此模块后,py主文件调用:
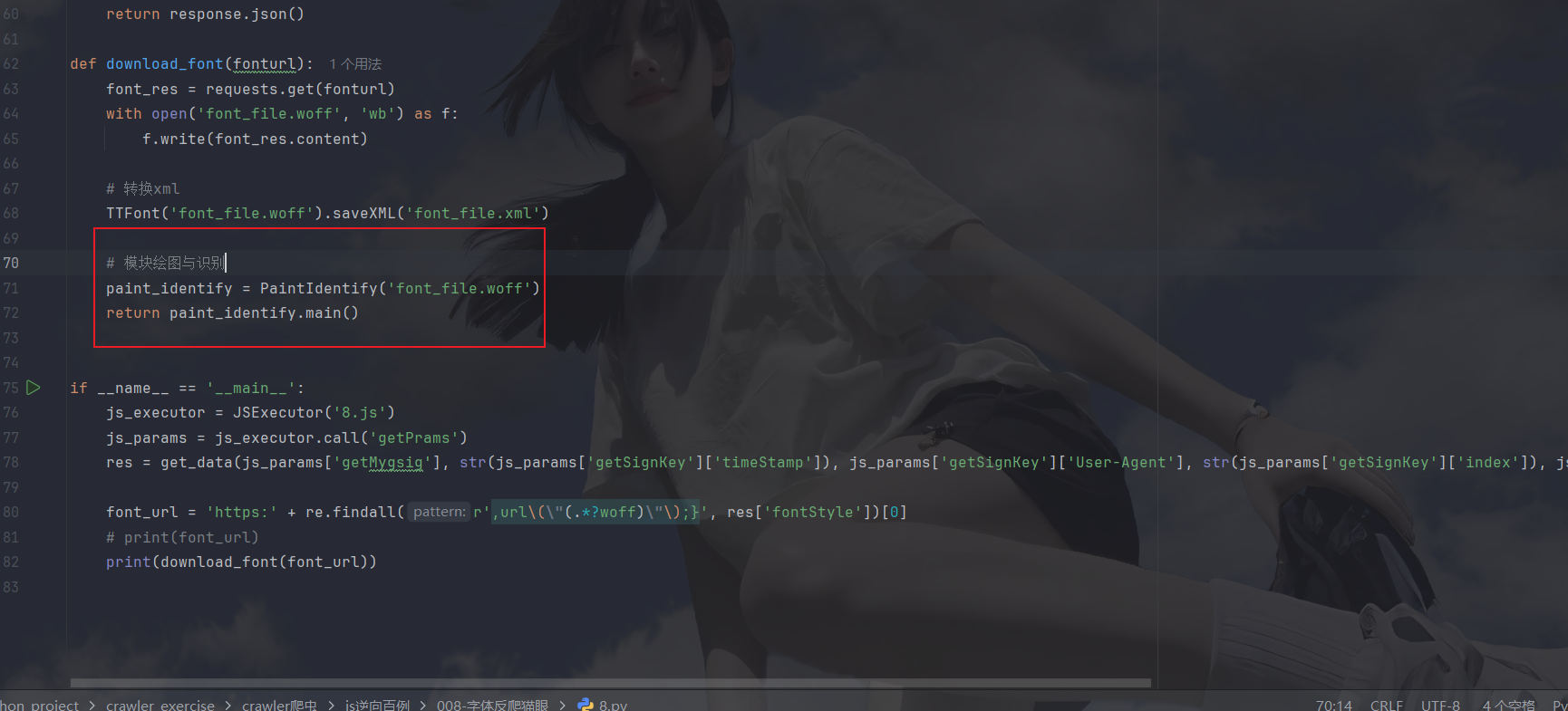
看一下结果:
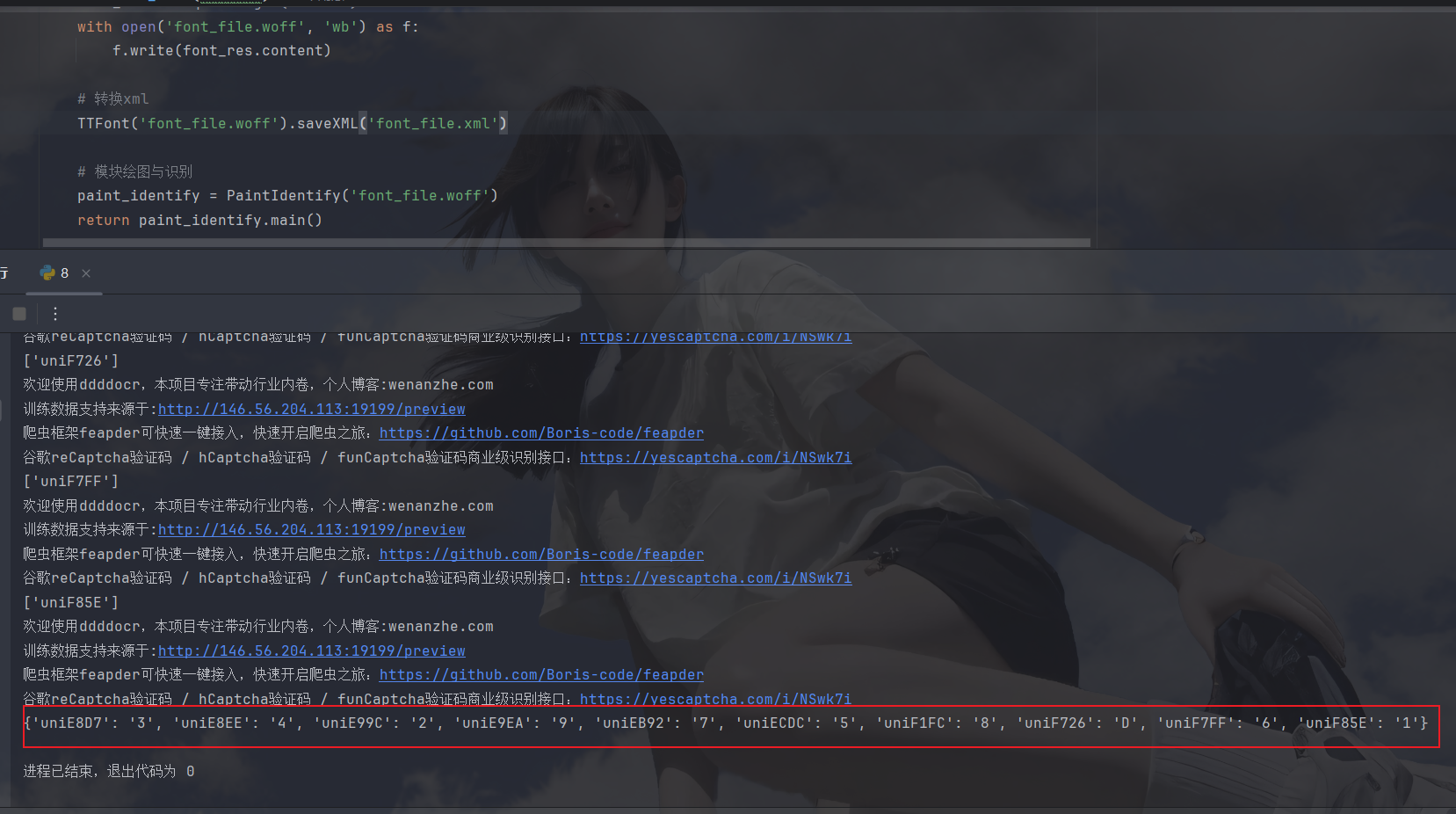
可以检查一下有没有空数据或者识别错误的,然后看看网页中数据是啥样,通过映射来替换爬取网页的数据,那么我们需要先解析爬虫返回的数据并提取出想要的信息才能对比:
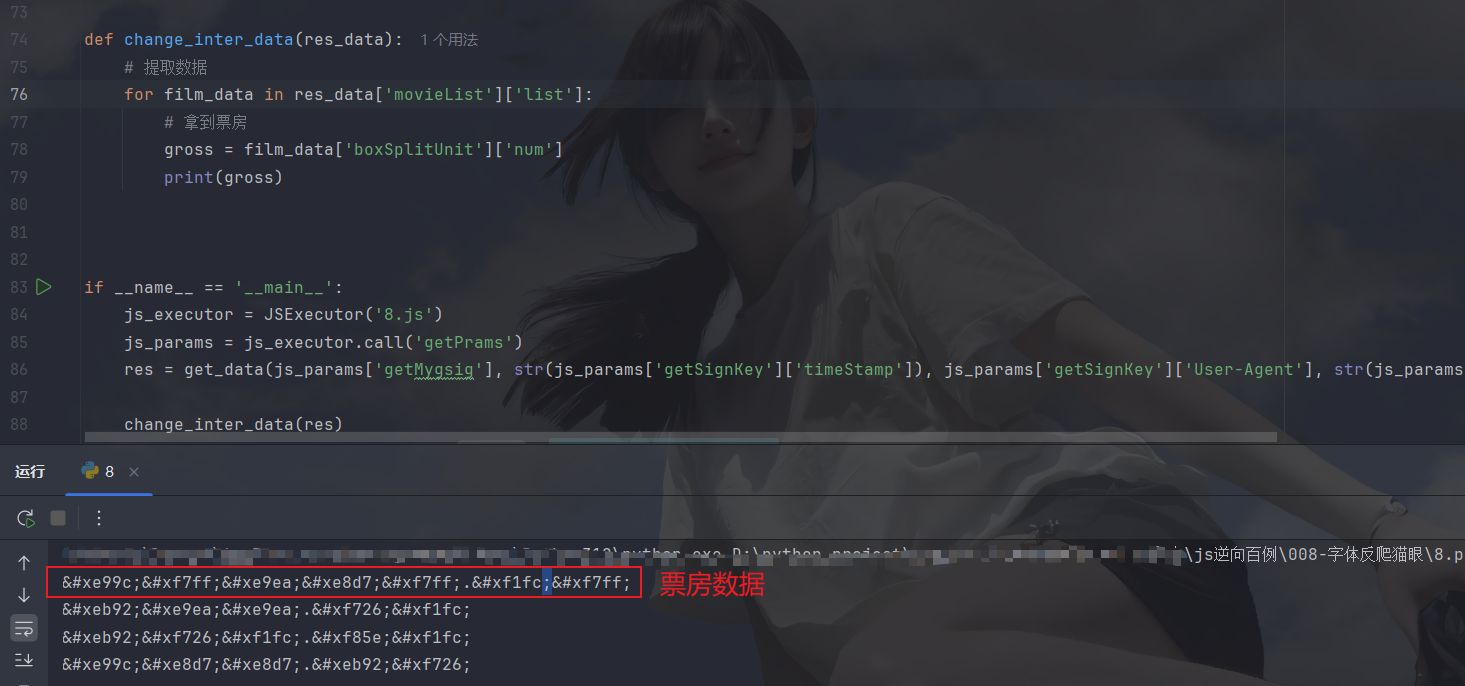
下面对比一下,看看怎么替换:

咱们在爬到的数据上做修改吧,就是将前面&#x去掉然后转成大写即可,但是里面有些**.**开头,咱们需要分情况讨论:
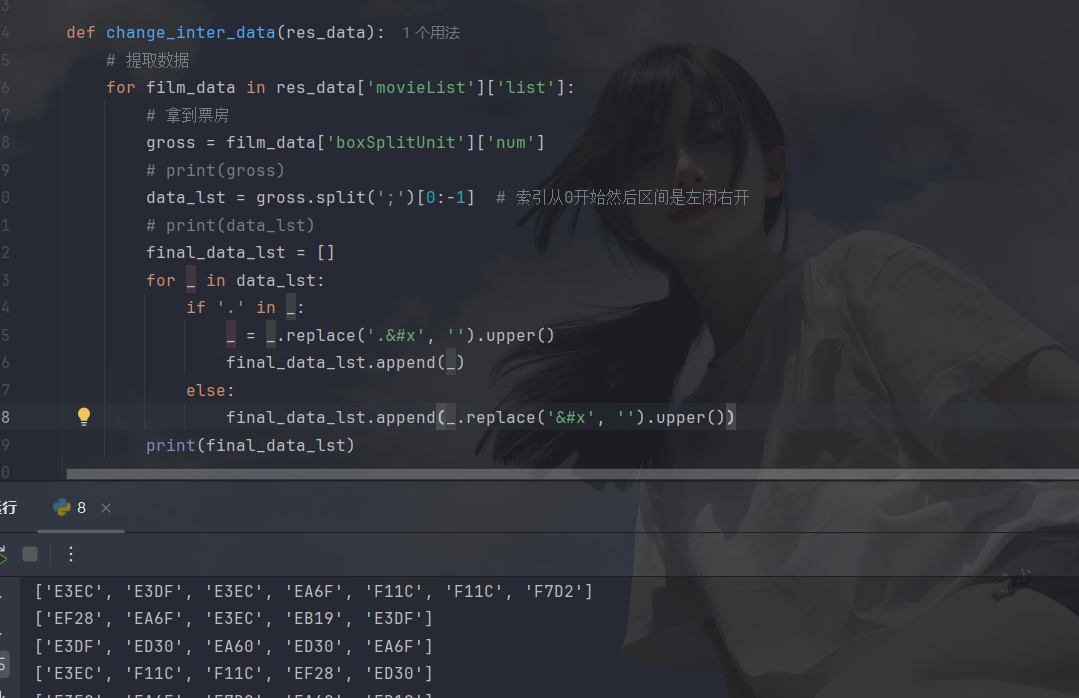
这样就差不多了,咱再把uni拼接上,再将要替换的字典传进change_inter_data函数中,然后再开始替换:
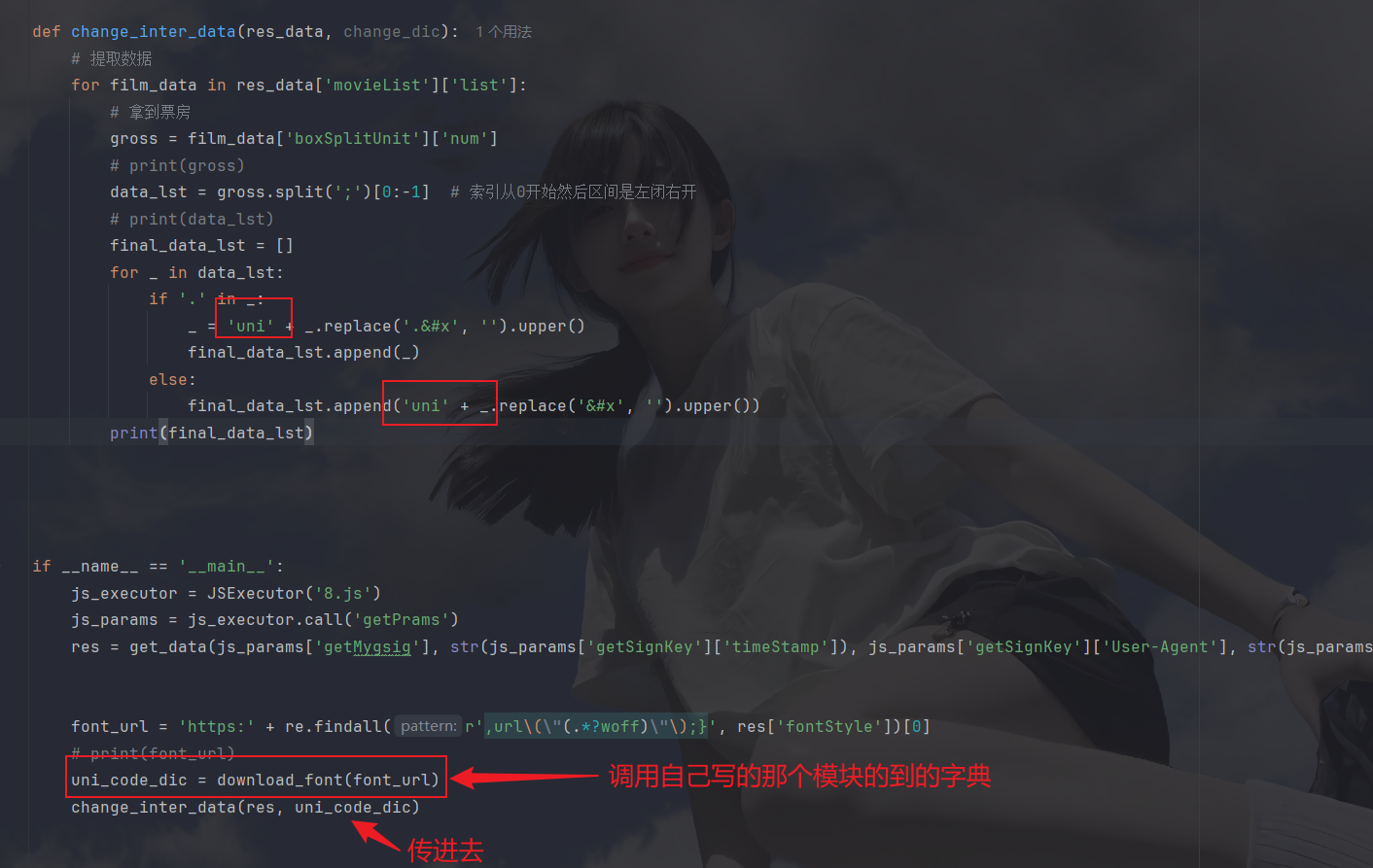
开始遍历替换,然后拼接列表中的字符串:
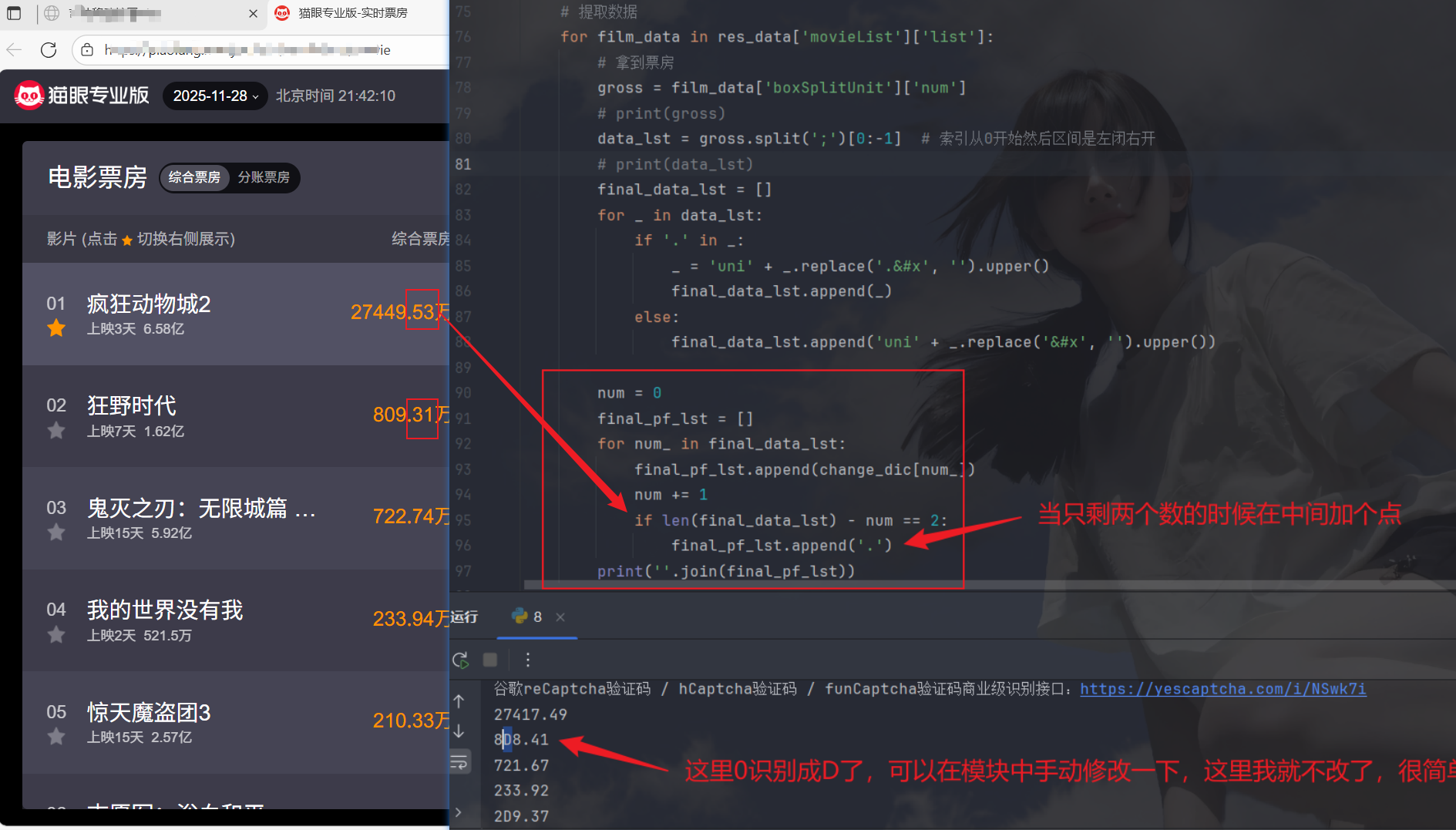
ok拿下✌
小结
本文可能比较难,不过学会了就不难了哈哈哈,如果文章有什么问题请及时提出,一起交流,加油加油