项目概述
本项目是一个基于FastAPI的多模态RAG(检索增强生成)系统,集成了长期记忆功能、流式响应和向量化知识检索。系统支持文本、图像、音频(预留扩展)等多种模态输入,能够根据用户历史记忆提供个性化服务。
项目结构
bash
rag_project/
├── .env # 环境变量配置
├── config.py # 全局配置文件
├── main.py # 主程序入口
├── requirements.txt # 依赖管理
└── src/
├── __init__.py
├── init_rag.py # 核心初始化模块
└── memory_manager.py # 记忆管理模块环境准备
1. 系统要求
- Python 3.8+
- pip 包管理器
- 虚拟环境(推荐)
2. 依赖安装
bash
# 创建虚拟环境
python -m venv venv
# 激活虚拟环境
# Windows:
venv\Scripts\activate
# Linux/Mac:
source venv/bin/activate
# 安装依赖
pip install -r requirements.txt3. requirements.txt 完整内容
txt
annotated-doc==0.0.4
annotated-types==0.7.0
anyio==4.12.0
certifi==2025.11.12
charset-normalizer==3.4.4
click==8.3.1
distro==1.9.0
dnspython==2.8.0
email-validator==2.3.0
fastapi==0.127.0
fastapi-cli==0.0.16
fastapi-cloud-cli==0.7.0
fastar==0.8.0
h11==0.16.0
httpcore==1.0.9
httptools==0.7.1
httpx==0.28.1
idna==3.11
itsdangerous==2.2.0
Jinja2==3.1.6
jiter==0.12.0
jsonpatch==1.33
jsonpointer==3.0.0
langchain==1.2.0
langchain-core==1.2.4
langchain-openai==1.1.6
langgraph==1.0.5
langgraph-checkpoint==3.0.1
langgraph-prebuilt==1.0.5
langgraph-sdk==0.3.1
langsmith==0.5.0
markdown-it-py==4.0.0
MarkupSafe==3.0.3
mdurl==0.1.2
numpy==2.4.0
openai==2.14.0
orjson==3.11.5
ormsgpack==1.12.1
packaging==25.0
pydantic==2.12.5
pydantic-extra-types==2.10.6
pydantic-settings==2.12.0
pydantic_core==2.41.5
Pygments==2.19.2
python-dotenv==1.2.1
python-multipart==0.0.21
PyYAML==6.0.3
regex==2025.11.3
requests==2.32.5
requests-toolbelt==1.0.0
rich==14.2.0
rich-toolkit==0.17.1
rignore==0.7.6
sentry-sdk==2.48.0
shellingham==1.5.4
sniffio==1.3.1
starlette==0.50.0
tenacity==9.1.2
tiktoken==0.12.0
tqdm==4.67.1
typer==0.20.1
typing-inspection==0.4.2
typing_extensions==4.15.0
ujson==5.11.0
urllib3==2.6.2
uuid_utils==0.12.0
uvicorn==0.40.0
uvloop==0.22.1
watchfiles==1.1.1
websockets==15.0.1
xxhash==3.6.0
zstandard==0.25.04. 环境变量配置 (.env)
env
# API配置
OPENAI_API_URL=https://api.siliconflow.cn/v1/
OPENAI_API_KEY=sk-your-api-key-here
# 模型配置
EMBEDDING_MODEL=BAAI/bge-m3
LLM_MODEL=deepseek-ai/DeepSeek-OCR
# 应用配置
DEBUG=true
LOG_LEVEL=INFO核心组件详解
1. 配置管理(config.py)
python
import os
from typing import Optional
from dotenv import load_dotenv
load_dotenv()
class Config:
# API Url
OPENAI_API_URL: Optional[str] = os.getenv("OPENAI_API_URL")
# API Keys
OPENAI_API_KEY: Optional[str] = os.getenv("OPENAI_API_KEY")
# 模型配置
EMBEDDING_MODEL: Optional[str] = os.getenv("EMBEDDING_MODEL")
LLM_MODEL: Optional[str] = os.getenv("LLM_MODEL")
# RAG配置
CHUNK_SIZE: int = 1000
CHUNK_OVERLAP: int = 200
TOP_K_RESULTS: int = 4
# 向量数据库
VECTOR_STORE_PATH: str = "./vector_store"
COLLECTION_NAME: str = "knowledge_base"
# 内存存储配置
MEMORY_NAMESPACE: str = "chitchat"
MEMORY_USER_ID: str = "user_001"
@classmethod
def validate(cls):
if not cls.OPENAI_API_KEY or not cls.OPENAI_API_URL:
raise ValueError("请设置OPENAI_API_KEY, OPENAI_API_URL环境变量")
@classmethod
def get_embeddings_model(cls):
from langchain.embeddings import init_embeddings
return init_embeddings(
model=cls.EMBEDDING_MODEL,
provider="openai",
openai_api_base=cls.OPENAI_API_URL,
openai_api_key=cls.OPENAI_API_KEY
)
@classmethod
def get_llm(cls):
from langchain.chat_models import init_chat_model
return init_chat_model(
model=cls.LLM_MODEL,
model_provider="openai",
api_key=cls.OPENAI_API_KEY,
base_url=cls.OPENAI_API_URL,
)
@classmethod
def get_memory_store(cls):
"""获取内存存储实例"""
from langgraph.store.memory import InMemoryStore
# 初始化嵌入模型
embedding_model = cls.get_embeddings_model()
# 创建支持向量检索的存储
memory_store = InMemoryStore(
index={
"embed": lambda texts: embedding_model.embed_documents(texts),
"dims": 1024 # bge-m3 的维度是1024
}
)
return memory_store2. 数据模型定义(init_rag.py)
python
import json
from datetime import datetime
from typing import List, Dict, Any, AsyncGenerator
from pydantic import BaseModel, Field
from fastapi import HTTPException
from langchain_core.messages import BaseMessage
from langchain.messages import SystemMessage, HumanMessage, AIMessage
from config import Config
from .memory_manager import memory_manager # 导入内存管理器
# =============================
# 数据模型(保持不变)
# =============================
class ContentBlock(BaseModel):
"""内容块模型"""
type: str = Field(description="内容类型: text, image, audio")
content: str = Field(description="内容数据")
class MessageRequest(BaseModel):
"""请求消息模型"""
content_blocks: List[ContentBlock] = Field(default=[], description="内容块")
history: List[Dict[str, Any]] = Field(default=[], description="对话历史")
class MessageResponse(BaseModel):
"""响应消息模型"""
content: str
timestamp: str
role: str3. 系统提示工程(init_rag.py)
python
# 系统提示模板 - 可配置化设计
SYSTEM_PROMPT_TEMPLATE = """
# 角色定义
你是一个专业的多模态智能助手,具有以下能力:
1. 多模态理解:能够处理文本、图像、音频等多种输入
2. 长期记忆:可以访问用户的个性化信息和历史对话
3. RAG增强:基于知识库提供准确、可靠的回答
4. 专业领域:在技术、学习、工作等领域提供专业建议
# 用户记忆上下文
{memory_context}
# 响应准则
1. 准确性:基于事实和知识库内容回答
2. 个性化:考虑用户的个人偏好和历史信息
3. 友好性:保持专业且友好的语气
4. 完整性:提供全面且有价值的回答
5. 安全性:不生成有害、偏见或不当内容
# 格式要求
- 使用清晰的结构(如列表、段落)
- 重要信息可以适当强调
- 复杂概念提供简单解释
- 代码示例要规范可运行
"""4. 记忆管理(memory_manager.py)
python
import json
from typing import List, Dict, Any, Optional
from datetime import datetime
from dataclasses import dataclass
from langgraph.store.memory import InMemoryStore
from config import Config
@dataclass
class MemoryItem:
"""记忆项数据结构"""
key: str
content: str
metadata: Dict[str, Any]
timestamp: str
class MemoryManager:
"""内存管理器类"""
def __init__(self):
self.memory_store = Config.get_memory_store()
self.namespace = Config.MEMORY_NAMESPACE
self.user_id = Config.MEMORY_USER_ID
def add_memory(self, key: str, content: str, metadata: Optional[Dict[str, Any]] = None):
"""
添加记忆
Args:
key: 记忆键名
content: 记忆内容
metadata: 附加元数据
"""
if metadata is None:
metadata = {}
memory_data = {
"内容": content,
"timestamp": datetime.now().isoformat(),
**metadata
}
self.memory_store.put(
(self.namespace, self.user_id),
key,
memory_data
)
def search_memories(self, query: str, limit: int = 2) -> List[MemoryItem]:
"""
语义搜索记忆
Args:
query: 搜索查询
limit: 返回结果数量
Returns:
List[MemoryItem]: 搜索到的记忆项列表
"""
search_results = self.memory_store.search(
(self.namespace, self.user_id),
query=query,
limit=limit
)
memories = []
for item in search_results:
memory_item = MemoryItem(
key=item.key,
content=item.value.get("内容", ""),
metadata={k: v for k, v in item.value.items() if k != "内容"},
timestamp=item.value.get("timestamp", "")
)
memories.append(memory_item)
return memories
def get_all_memories(self) -> List[MemoryItem]:
"""
获取所有记忆
Returns:
List[MemoryItem]: 所有记忆项列表
"""
# 注意:InMemoryStore 没有直接获取所有的方法
# 这里需要通过搜索空查询来获取(或者使用其他方法)
return self.search_memories("", limit=100)
def clear_memories(self):
"""
清空用户的所有记忆
"""
# 注意:InMemoryStore 可能没有直接的clear方法
# 实际使用时需要根据存储的实现进行调整
pass
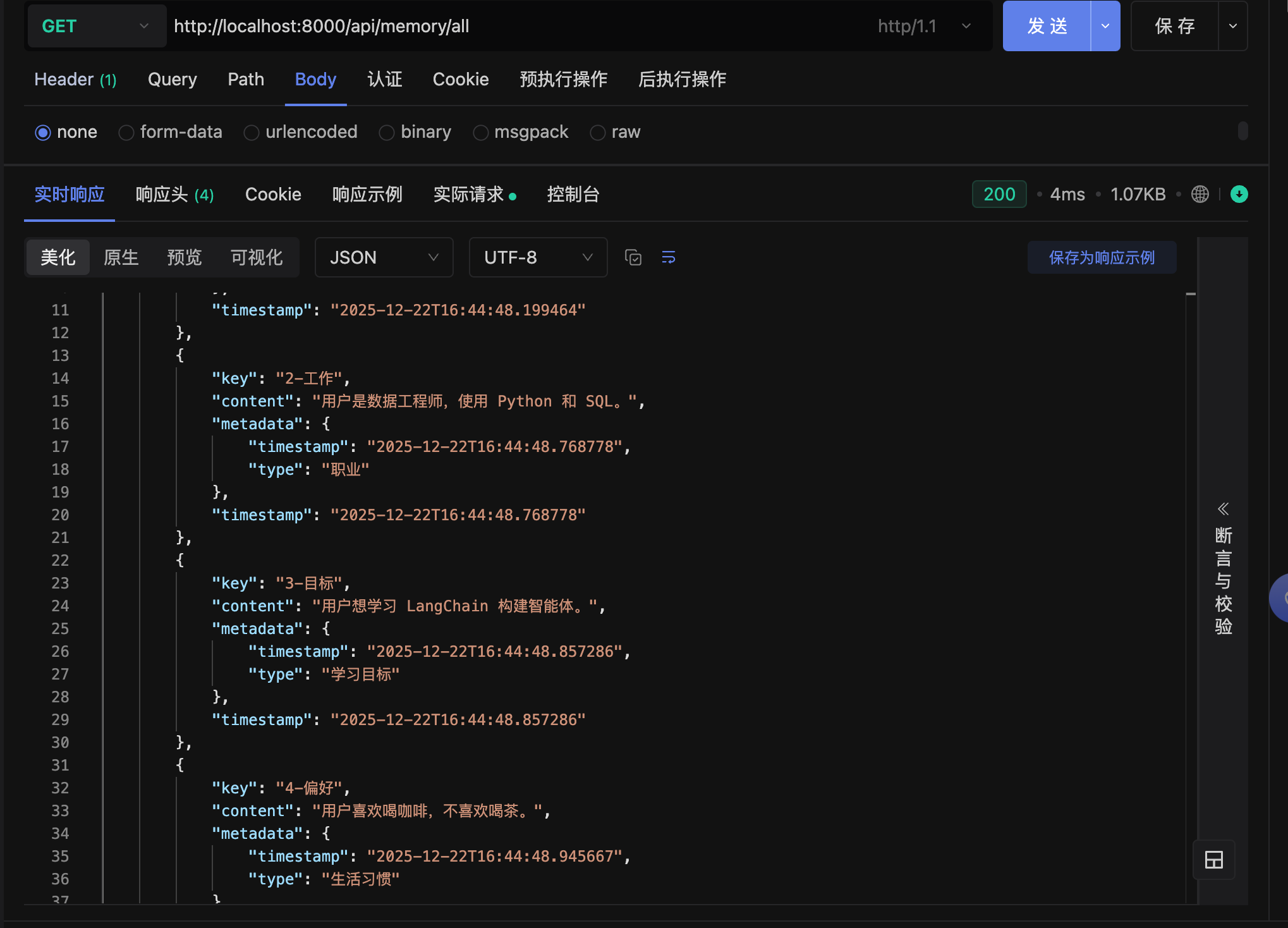
def initialize_sample_memories(self):
"""
初始化示例记忆(用于测试)
"""
sample_memories = [
("1-爱好", "用户喜欢编程和爬山。", {"type": "兴趣"}),
("2-工作", "用户是数据工程师,使用 Python 和 SQL。", {"type": "职业"}),
("3-目标", "用户想学习 LangChain 构建智能体。", {"type": "学习目标"}),
("4-偏好", "用户喜欢喝咖啡,不喜欢喝茶。", {"type": "生活习惯"}),
("5-项目", "用户正在开发一个RAG聊天机器人项目。", {"type": "当前项目"})
]
for key, content, metadata in sample_memories:
self.add_memory(key, content, metadata)
# 创建全局内存管理器实例
memory_manager = MemoryManager()
# 初始化示例记忆(在应用启动时执行)
memory_manager.initialize_sample_memories()5. 流式响应实现(init_rag.py)
python
# =============================
# 模型初始化
# =============================
def get_chat_model():
"""获取聊天模型实例"""
try:
return Config.get_llm()
except Exception as e:
raise HTTPException(status_code=500, detail=f"模型初始化失败: {str(e)}")
# =============================
# 记忆增强功能
# =============================
def get_memory_context(user_query: str) -> str:
"""
根据用户查询获取相关记忆上下文
Args:
user_query: 用户查询文本
Returns:
str: 格式化后的记忆上下文
"""
# 搜索相关记忆
relevant_memories = memory_manager.search_memories(
query=user_query,
limit=3 # 返回最相关的3条记忆
)
if not relevant_memories:
return "暂无相关用户记忆。"
# 格式化记忆上下文
memory_context = "以下是从用户长期记忆中检索到的相关信息:\n"
for i, memory in enumerate(relevant_memories, 1):
memory_context += f"{i}. {memory.content} (来源: {memory.key})\n"
return memory_context
def update_user_memory(user_query: str, assistant_response: str):
"""
根据对话内容更新用户记忆
Args:
user_query: 用户查询
assistant_response: 助手回复
"""
# 这里可以根据需要实现记忆更新逻辑
# 例如:从对话中提取关键信息并存储
# 示例:如果用户提到个人信息,可以提取并存储
personal_info_keywords = ["我是", "我住在", "我今年", "我喜欢", "我不喜欢", "我的工作是"]
for keyword in personal_info_keywords:
if keyword in user_query:
# 提取相关信息(简化示例)
content = f"用户提到:{user_query}"
memory_key = f"conversation-{datetime.now().strftime('%Y%m%d-%H%M%S')}"
memory_manager.add_memory(
key=memory_key,
content=content,
metadata={
"type": "对话记忆",
"query": user_query[:50],
"timestamp": datetime.now().isoformat()
}
)
break
# =============================
# 消息处理
# =============================
def create_multimodal_message(request: MessageRequest) -> HumanMessage:
"""
创建多模态消息
当前仅支持文本内容,后续可扩展支持图像/音频
"""
# 提取文本内容
text_content = next(
(block.content for block in request.content_blocks if block.type == "text"),
""
)
return HumanMessage(content=text_content)
def convert_history_to_messages(history: List[Dict[str, Any]], user_query: str = "") -> List[BaseMessage]:
"""
将历史记录转换为 LangChain 消息格式
支持多模态内容(当前仅实现文本处理)
Args:
history: 对话历史
user_query: 当前用户查询(用于记忆检索)
Returns:
List[BaseMessage]: LangChain消息列表
"""
# 获取记忆上下文
memory_context = get_memory_context(user_query)
# 创建系统提示(包含记忆上下文)
system_message = SystemMessage(
content=SYSTEM_PROMPT.format(memory_context=memory_context)
)
messages = [system_message]
# 添加历史消息
for msg in history:
if msg["role"] == "user":
# 处理用户消息
text_content = next(
(block.get("content", "") for block in msg.get("content_blocks", []) if block.get("type") == "text"),
""
)
messages.append(HumanMessage(content=text_content))
elif msg["role"] == "assistant":
# 处理助手消息
messages.append(AIMessage(content=msg.get("content", "")))
return messages
# =============================
# 流式响应生成(增强版)
# =============================
async def generate_streaming_response(messages: List[BaseMessage], user_query: str = "") -> AsyncGenerator[str, None]:
"""
生成流式响应
处理模型调用和响应流式传输,并更新用户记忆
Args:
messages: LangChain消息列表
user_query: 用户查询(用于记忆更新)
Yields:
str: SSE格式的数据流
"""
try:
model = get_chat_model()
full_response = ""
# 流式生成响应
async for chunk in model.astream(messages):
if hasattr(chunk, 'content') and chunk.content:
content = chunk.content
full_response += content
# 流式传输内容块
data = {
"type": "content_delta",
"content": content,
"timestamp": datetime.now().isoformat()
}
yield f"data: {json.dumps(data, ensure_ascii=False)}\n\n"
# 更新用户记忆(如果查询非空)
if user_query:
try:
update_user_memory(user_query, full_response)
except Exception as mem_error:
# 记忆更新失败不影响主流程
print(f"记忆更新失败: {mem_error}")
# 发送完成信号
final_data = {
"type": "message_complete",
"full_content": full_response,
"timestamp": datetime.now().isoformat(),
}
yield f"data: {json.dumps(final_data, ensure_ascii=False)}\n\n"
except Exception as e:
error_data = {
"type": "error",
"error": str(e),
"timestamp": datetime.now().isoformat()
}
yield f"data: {json.dumps(error_data, ensure_ascii=False)}\n\n"6. API路由实现(main.py)
python
import uvicorn
from fastapi import FastAPI, HTTPException
from fastapi.responses import StreamingResponse
from fastapi.middleware.cors import CORSMiddleware
from src.init_rag import MessageRequest, convert_history_to_messages, create_multimodal_message, generate_streaming_response
from src.memory_manager import memory_manager # 导入内存管理器
# =============================
# FastAPI 应用
# =============================
app = FastAPI(
title="RAG 服务API",
description="LangChain v1 RAG智能体(带长期记忆)",
version="1.0.0"
)
# =============================
# 跨域配置
# =============================
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# =============================
# 路由处理
# =============================
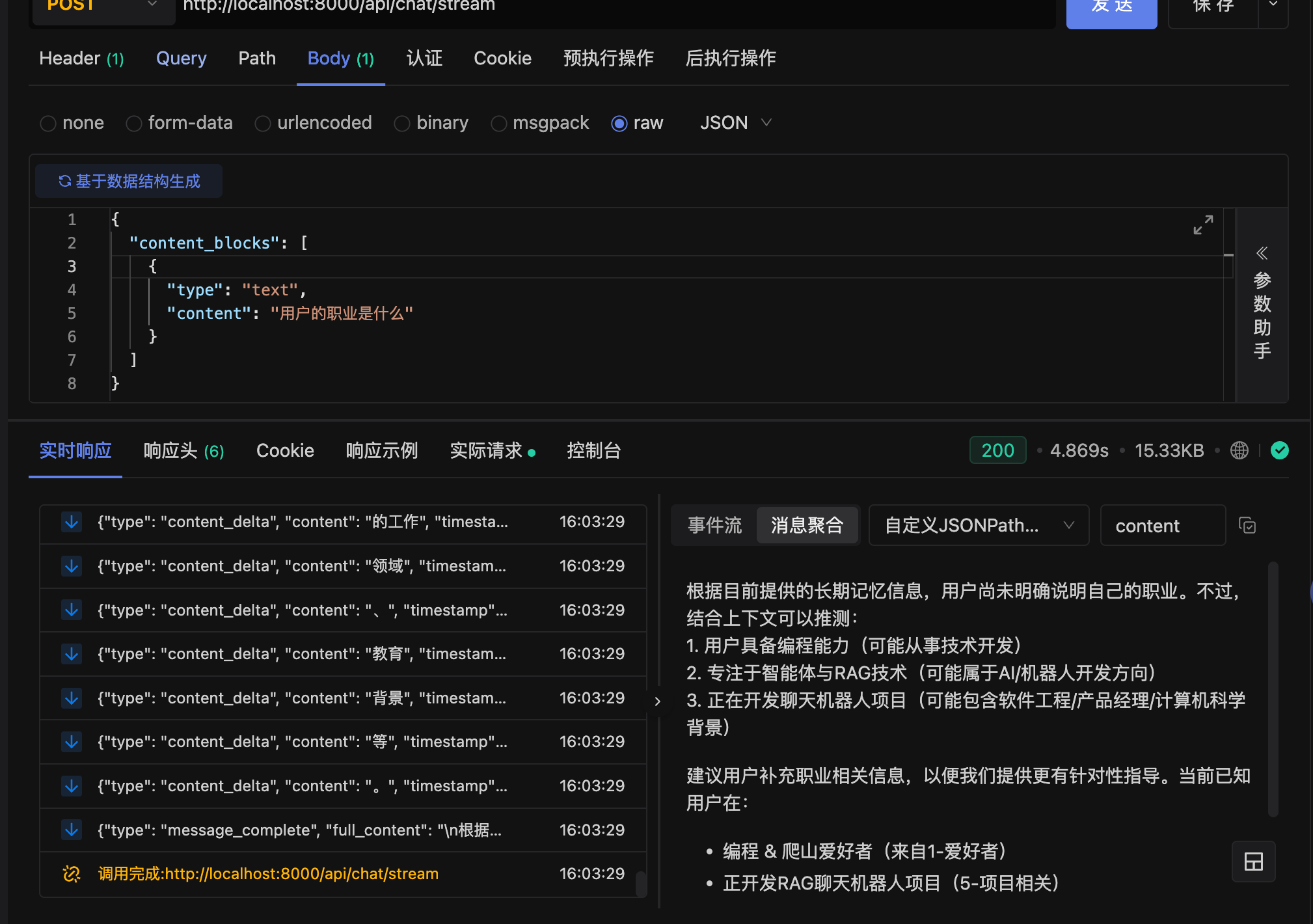
@app.post("/api/chat/stream")
async def chat_stream(request: MessageRequest):
"""
流式聊天接口
处理多模态输入并返回流式响应(带长期记忆)
"""
try:
# 提取用户当前查询文本
current_query = next(
(block.content for block in request.content_blocks if block.type == "text"),
""
)
# 转换消息历史(传入当前查询用于记忆检索)
messages = convert_history_to_messages(request.history, current_query)
print(messages)
# 创建当前用户消息
current_message = create_multimodal_message(request)
messages.append(current_message)
# 返回流式响应(传入用户查询用于记忆更新)
return StreamingResponse(
generate_streaming_response(messages, current_query),
media_type="text/plain",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Content-Type": "text/event-stream",
}
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/api/memory/search")
async def search_memories(query: str = "", limit: int = 5):
"""
搜索用户记忆
Args:
query: 搜索查询
limit: 返回结果数量
"""
try:
memories = memory_manager.search_memories(query, limit)
# 转换为JSON可序列化格式
memory_list = []
for memory in memories:
memory_list.append({
"key": memory.key,
"content": memory.content,
"metadata": memory.metadata,
"timestamp": memory.timestamp
})
return {
"query": query,
"limit": limit,
"memories": memory_list
}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/api/memory/all")
async def get_all_memories():
"""
获取所有用户记忆
"""
try:
memories = memory_manager.get_all_memories()
# 转换为JSON可序列化格式
memory_list = []
for memory in memories:
memory_list.append({
"key": memory.key,
"content": memory.content,
"metadata": memory.metadata,
"timestamp": memory.timestamp
})
return {
"total": len(memory_list),
"memories": memory_list
}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/api/memory/add")
async def add_memory(key: str, content: str):
"""
添加新的用户记忆
Args:
key: 记忆键名
content: 记忆内容
"""
try:
memory_manager.add_memory(key, content)
return {
"status": "success",
"message": f"记忆 '{key}' 已添加",
"key": key,
"content": content
}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
# =============================
# 主程序入口
# =============================
if __name__ == "__main__":
# 初始化示例记忆
memory_manager.initialize_sample_memories()
print("示例记忆已初始化")
uvicorn.run(
app,
host="localhost",
port=8000
)部署与运行
1. 开发模式运行
bash
# 直接运行
python main.py
# 或使用uvicorn
uvicorn main:app --reload --host 0.0.0.0 --port 80002. 生产环境配置
python
# gunicorn配置 (gunicorn_config.py)
workers = 4
worker_class = "uvicorn.workers.UvicornWorker"
bind = "0.0.0.0:8000"
timeout = 120
keepalive = 5
# 启动命令
# gunicorn -c gunicorn_config.py main:app3. Docker部署
dockerfile
# Dockerfile
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]API使用示例
1. 流式聊天
2. 记忆搜索