在大模型推理性能调优的过程中,我们经常会遇到一个令人头疼的现象------HostBound 。CPU 明明没有满载,但推理速度就是慢,Profiling 一看,全是"空泡"。 调试分析之后有点发现,最终我发现问题是在一个经常被忽略的角落:IRQ** 中断机制与中断绑核**。
因此本文结合昇腾平台的实际测试,从 IRQ 工作机制、irqbalance 调度策略,到如何通过绑核优化推理性能,完整还原这次 HostBound 问题的排查与优化过程。
一、背景:从 HostBound 说起
在大模型推理时,Host 侧算子进入下发队列后,会依次触发两个关键中断事件:
sq_send_trigger_irq:算子下发触发;cq_update_irq:算子执行完成后上报。
这两个中断的发生 CPU 核通常是固定的。 而如果此时业务线程恰好也绑定在相同的 CPU 核上,就会出现频繁的任务打断,导致 CPU 空泡显著增加,形成典型的 HostBound 问题。
在默认情况下,如果系统安装并启用了 irqbalance 服务,它会定期(默认 10 秒)重新分配中断,使中断均衡分布在多个 CPU 上。 但对于推理这种极端计算密集型场景,这种"自动平衡"反而可能带来性能抖动甚至劣化。
为什么在昇腾平台上 HostBound 更明显?
与 GPU 不同,昇腾 NPU 采用 Host/NPU 协同执行架构。在整个模型推理过程中,CPU 承担了以下关键角色:
- 算子编排、调度与 TaskGen(CANN Runtime)
- 向 AscendCL/DevDrv 下发任务,触发 sq_send_trigger_irq
- 等待 NPU 完成 cq_update_irq 回调,用于同步下一步调度
- 部分算子的 Host 侧逻辑,如 shape 计算、LayerNorm 前置操作等
昇腾框架(CANN + torch-npu)比 GPU 更依赖 CPU 的调度链路,因此 CPU 不仅需要供能(Host Control),还承担巨量 Host 侧同步逻辑。
NPU ** 每执行一次算子 → 至少两次 IRQ:**
sq_send_trigger_irq(下发)cq_update_irq(完成)
而大模型推理 每生成一个 token 会触发数百到上千个算子调度,即会产生成千上万次中断。
因此,昇腾平台比 GPU 更容易出现一个现象:
CPU 被高频中断打断,导致 HostBound,即使 CPU 利用率不高,也会出现严重空泡。
二、了解 IRQ 与 irqbalance 的机制
1. 什么是硬件中断?
**中断(Interrupt)**是一种"打断当前程序执行"的机制。 当外设(如 NPU、网卡、定时器)有事件发生时,会通知 CPU 中断当前任务,执行一段专门的"中断服务程序(ISR)"。 这样可以保证 CPU 能及时响应设备请求,而不是傻等。
举个例子,当 NPU 执行完算子后,需要告诉 CPU "我完成了",这个信号就是一次中断。 如果中断太频繁,CPU 就会被不断"打断",算子调度效率明显下降。
2. 中断的注册与维护
设备驱动加载时会通过 request_irq() 注册中断,系统会分配一个 IRQ ID。 所有中断状态都可以在 /proc/interrupts 中查看,例如:
| IRQ** ID** | CPU0 | CPU1 | CPU2 | CPU3 | 控制器类型 | 硬件中断号 | 触发方式 | 中断源**/设备** |
|---|---|---|---|---|---|---|---|---|
| 8 | 0 | 0 | 0 | 0 | GICv3 | 22 | Level | vgic |
| 9 | 0 | 12 | 0 | 0 | GICv3 | 28 | Level | kvm guest ptimer |
| 10 | 45 | 0 | 0 | 0 | GICv3 | 29 | Level | kvm guest vtimer |
| 11 | 256 | 0 | 0 | 432 | GICv3 | 30 | Level | arch_timer |
| 12 | 0 | 0 | 0 | 0 | GICv3 | 140 | Edge | uart-pl011 |
| 15 | 0 | 0 | 0 | 0 | GICv3 | 490 | Level | HISI0173:00 |
| 16 | 0 | 0 | 0 | 0 | GICv3 | 482 | Level | HISI02A2:00 |
| 17 | 0 | 0 | 0 | 0 | GICv3 | 25 | Level | arm-pmu |
| 19 | 0 | 0 | 0 | 0 | ITS-MSI | 0 | Edge | PCIe PME |
| 20 | 0 | 0 | 0 | 0 | ITS-MSI | 1 | Edge | aerdrv |
从上表我们可以看出系统中不同中断事件的触发情况:
- IRQ** ID(中断号)**:表示系统为每个硬件设备或虚拟设备分配的中断标识符。
- CPU0-CPU3 列 :表示各个 CPU 核上处理该中断的次数。 例如,
arch_timer中断在 CPU0 上触发了 256 次、CPU3 上触发了 432 次,而其他核几乎没有触发。 - 控制器类型(Controller Type) :例如
GICv3或ITS-MSI,代表不同类型的中断控制器(前者常见于 ARM 架构,后者用于 PCIe 设备等)。 - 触发方式(Trigger Type) :
Level表示电平触发,Edge表示边沿触发。不同触发方式对应不同的中断响应机制。 - 中断源 **/设备(Source)**:表示是谁产生了中断,比如定时器、串口、PCIe 设备等。
在实际大模型推理环境中,你可以通过 cat /proc/interrupts 实时观察到某些中断(例如 sq_send_trigger_irq、cq_update_irq)在某几个 CPU 上触发频率极高。 这通常说明这些中断源被固定绑定在特定 CPU 核上,如果你的推理线程也恰好绑定在同一核,就会造成频繁的中断抢占,进而引起 HostBound 性能瓶颈。
因此,在性能优化时,理解并分析这张表非常关键。 它能帮助你判断是否存在"中断集中于少数 CPU 核"的情况,为后续的绑核优化提供数据依据。
3. irqbalance 的执行逻辑
irqbalance 是 Linux 系统中一个非常重要的后台服务,它的主要职责是------在多核 CPU 系统中自动平衡中断的分布,防止某个 CPU 因为频繁处理中断而成为瓶颈。
我们可以这样理解: 如果把每次中断看成"系统电话",那么 irqbalance 就像一个总机调度员,负责把电话均匀分配给不同的"接线员"(CPU 核心),避免某一个人被电话打爆,而其他人却闲着。
(1)irqbalance 的工作方式
irqbalance 每隔一段时间(默认 10 秒)会自动执行以下几个步骤:
- 读取中断分布信息 它会扫描
/proc/interrupts文件,统计每个中断号(IRQ ID)在各个 CPU 核上的触发次数。 比如发现 IRQ 1021 在 CPU10 上触发了 10 万次,而其他核几乎为 0,这说明中断分布不均。 - 分析负载与 NUMA 拓扑 irqbalance 并不会"盲目均衡",它会考虑 NUMA 拓扑结构,尽量让中断分配在距离设备最近的 CPU 节点上。 这样可以减少跨 NUMA 节点访问内存的延迟,兼顾"负载平衡"和"访问效率"。
- 重新分配中断绑定关系 通过修改
/proc/irq/<IRQ_ID>/smp_affinity文件中的掩码值,实现把某个中断"绑"到其他 CPU 核上。 例如,如果 smp_affinity 的值是0x400,表示该中断仅绑定在 CPU10(第 10 个核)上。 - 周期性重复评估 irqbalance 会不断循环以上步骤------分析 → 决策 → 调整,从而保持系统的中断分布动态平衡。
(2)irqbalance 的策略特点
- 它关注的是中断负载均衡,而非 CPU 使用率。 即使某个 CPU 正在执行高负载任务,只要它的中断次数较少,irqbalance 仍可能把新的中断分配过去。
- 对于部分"高频设备"或特殊场景(如 NPU、NVMe SSD),这种自动均衡反而可能带来性能抖动。 因为中断被频繁迁移,会导致 CPU Cache 失效、NUMA 远程访问增加,甚至打断关键计算线程。
- irqbalance 的评估周期可调节,通过修改服务参数可实现更细粒度的控制,例如:
plain
systemctl edit irqbalance
plain
[Service]
ExecStart=
ExecStart=/usr/sbin/irqbalance --interval=300- 这段配置把默认 10 秒的检测周期改成了 300 秒,从而让中断分配更稳定。
(3)irqbalance 的两种典型用法
- 通用场景:默认开启 irqbalance,让它自动维护系统中断均衡,适合普通服务器或多任务场景。
- 性能敏感场景(如大模型推理) :手动调整 irqbalance 的策略,或者直接关闭自动调度,通过
--banirq参数屏蔽关键中断,让开发者自行绑定中断与 CPU 核,实现更可控的性能调优。
irqbalance 的本意是"让中断更公平",但在性能调优的世界里,"公平"并不总是"高效"。 理解它的调度逻辑,有助于我们在特定场景下做出更合理的决策。 什么时候让它自动跑,什么时候让它安静下来。
(4)查看 /proc/interrupts
实时监控 IRQ 的命令
plain
watch -n 1 cat /proc/interrupts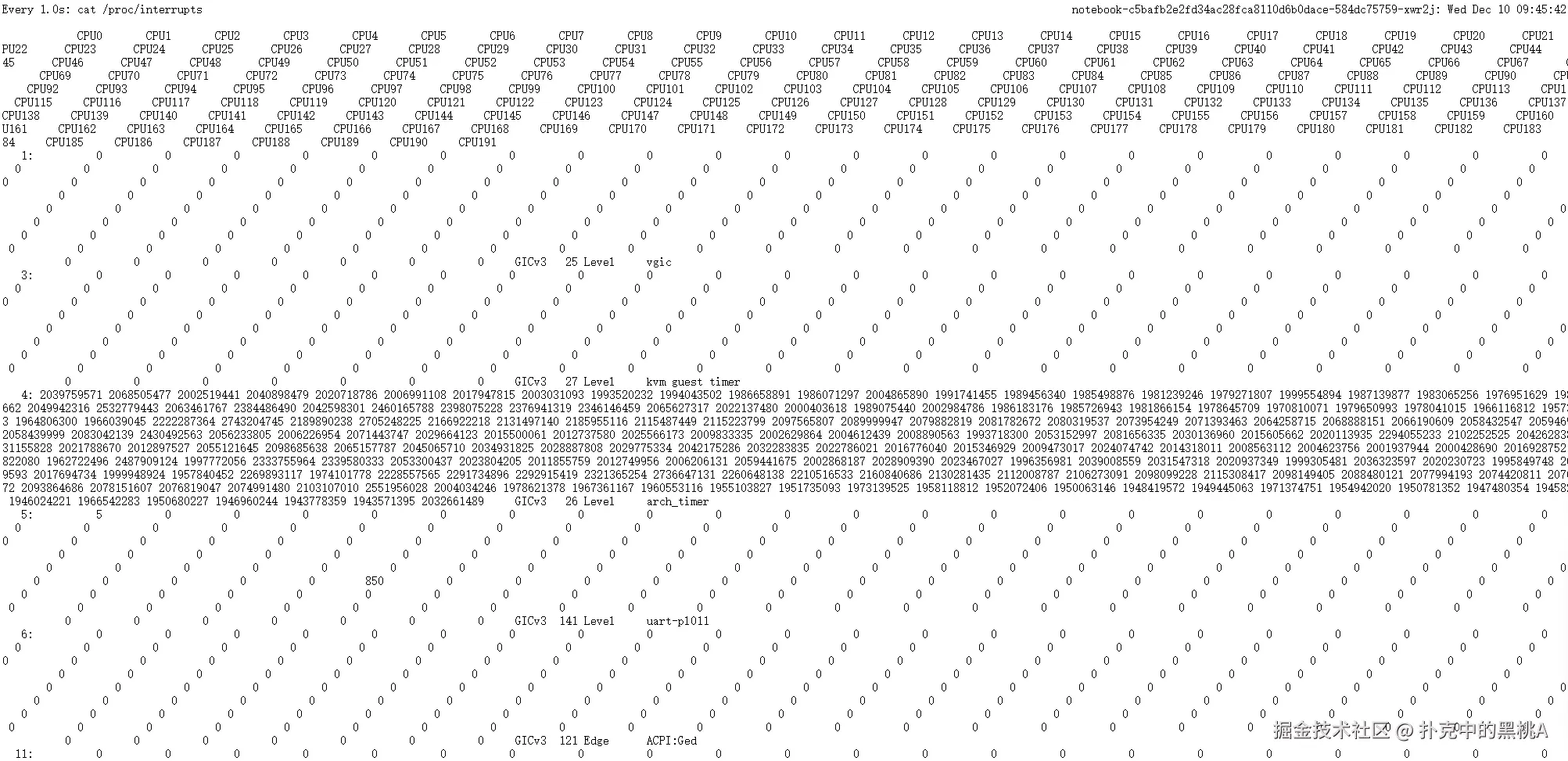
三、大模型推理中的中断问题
在大模型推理或训练场景中,NPU 与 CPU 间通信极为频繁。 当中断发生在业务线程所在的 CPU 核上时,推理过程会被频繁打断。Profiling 结果通常表现为:
- Node@launch 时间增加
- CPU 空泡率上升
- decode 阶段耗时增长明显
如果统计 /proc/interrupts,你甚至会看到"一秒内发生两万次中断"的惊人现象。
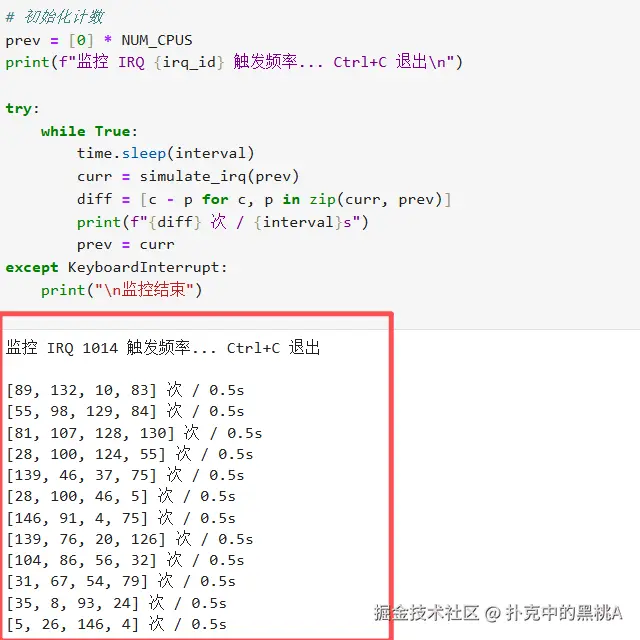
中断频率统计代码
plain
import time
def read_irq(irq_id):
with open("/proc/interrupts", "r") as f:
for line in f:
if line.strip().startswith(str(irq_id)):
return list(map(int, line.split()[1:5])) # CPU0~CPU3
return None
irq_id = 1014 # 这里填你的 sq_send_trigger_irq
interval = 0.5
prev = read_irq(irq_id)
print(f"监控 IRQ {irq_id} 触发频率... Ctrl+C 退出")
while True:
time.sleep(interval)
curr = read_irq(irq_id)
diff = [c - p for c, p in zip(curr, prev)]
print(f"{diff} 次 / {interval}s")
prev = curr示例运行效果如下:
四、实验验证:中断绑核前后对比
为了验证中断分布对大模型推理性能的影响,本文在 昇腾 800I(A2-A+K 架构,8 卡 * 64GB)平台 上做了一个对比实验,目标是:
通过中断绑核,观察 HostBound 现象是否得到改善。
1. 实验环境配置
| 组件 | 版本/说明 |
|---|---|
| 服务器硬件 | Ascend 800I(A2-A+K) |
| 操作系统 | openEuler 22.03 LTS |
| 驱动版本 | 25.0.rc1.1(昇腾 DevDrv 驱动) |
| CANN(Compute Architecture for Neural Networks) | 8.2.RC1(昇腾算子库与运行时框架) |
| PyTorch | 2.1.0 |
| torch-npu | 2.1.0.post13.dev20250722(昇腾后端模块,实现 PyTorch→NPU 映射) |
| MindIE | 2.1.RC1-800I-A2-py311-openeuler24.03-lts(昇腾推理引擎) |
| 模型 | Qwen2.5-7B |
| Python | 3.11.10 |
2. 确定中断分布与 NPU 对应关系
首先,我们要找到每个 NPU 对应的中断号(IRQ ID)。 通过以下命令查看系统中各 NPU 注册的起始中断号:
plain
cat /proc/interrupts | grep devdrv_load_irq | cut -d: -f1输出:
1014 1271 1529 1785 2041 2297 2553 2809
这些数字代表了每个 NPU 模块注册的中断起始编号。
接着,通过 npu-smi info 命令可查看设备的 Bus ID 与注册顺序:
plain
npu-smi info输出结果中,每个 NPU 的 Bus ID 和注册顺序可以一一对应,例如:
| NPU ID | Bus ID | 驱动注册顺序 |
|---|---|---|
| 4 | 0000:01:00.0 | 第 1 个注册 |
| 5 | 0000:02:00.0 | 第 2 个注册 |
| 6 | 0000:41:00.0 | 第 3 个注册 |
| 7 | 0000:42:00.0 | 第 4 个注册 |
| 2 | 0000:81:00.0 | 第 5 个注册 |
| 3 | 0000:82:00.0 | 第 6 个注册 |
| 0 | 0000:C1:00.0 | 第 7 个注册 |
| 1 | 0000:C2:00.0 | 第 8 个注册 |
通过对比可以推测,中断号 1014~1271 属于 NPU0,以此类推。
3. 查看目标中断的分布情况
例如,我们关心某个 NPU 对应的 sq_send_trigger_irq 与 cq_update_irq 中断,可在 /proc/interrupts 中查看这些中断的分布:
plain
grep -E "sq_send_trigger_irq|cq_update_irq" /proc/interrupts输出结果如下表:
| IRQ ID | CPU6 | CPU7 | CPU8 | CPU9 | CPU10 | 控制器 | 触发方式 | 中断源 |
|---|---|---|---|---|---|---|---|---|
| 1032 | 2652 | 1426098 | 0 | 0 | 195 | ITS-MSI | Edge | sq_send_trigger_irq |
| 1033 | 0 | 0 | 0 | 889344 | 0 | ITS-MSI | Edge | cq_update_irq |
从结果中可以看到,这些中断集中在 CPU7 和 CPU9 上触发非常频繁,这意味着这两个核心在推理过程中被大量中断打断。
4. 中断绑核方法
为了减少中断对推理任务的影响,我们将频繁触发的中断绑定到不执行推理线程的 CPU 核上。 操作方法如下:
- 关闭 irqbalance 服务(防止它自动重新分配中断):
plain
systemctl stop irqbalance- 修改中断的 smp_affinity 值:
- 例如,将 IRQ 1032 绑定到 CPU10:
plain
echo 0x400 > /proc/irq/1032/smp_affinity- (
0x400表示第 10 个 CPU 核) - 设置算子执行绑核(指定 NPU 对应的 CPU 核):
plain
export CPU_AFFINITY_CONF=1,npu2:10,npu3:11- 这样,NPU2 的算子绑定在 CPU10,而其中断(如 sq_send_trigger_irq)则绑定在其他 CPU 上,确保两者分离。
5. 实验过程与测试脚本
为了观察中断频率,我们编写了一个简单脚本模拟高频推理请求:
plain
#!/bin/bash
LOOPS=100000
IRQ_ID="1032"
echo "开始高频推理测试,共 $LOOPS 次请求..."
for ((i=1; i<=LOOPS; i++))
do
curl -s -X POST -d '{"model": "qwen2.5_7B", "messages": [{"role": "user","content": "请介绍一下QwQ?"}], "max_tokens": 32768, "stream": false}' http://127.0.0.1:3125/v1/chat/completions > /dev/null
if (( $i % 100 == 0 )); then
echo "已完成 $i 次请求,中断分布如下:"
grep -E "^$IRQ_ID:" /proc/interrupts
echo "-----------------------------"
fi
done通过该脚本,我们可以实时观察中断在各个 CPU 上的触发次数随推理进程变化的趋势。
6. 实验结果对比
场景一:算子与中断分离(未在同核)
- 中断绑定在与算子执行线程不同的 CPU 核。
- Profiling 结果显示:
- Node@launch 时间稳定;
- CPU 空泡较少;
- 推理耗时正常。

正常情况下的 Profiling
场景二:算子与中断共用同一 CPU 核(在同核)
- 将中断和算子线程同时绑定在 CPU10 上。
- Profiling 结果显示:
- Node@launch 时间略有延长;
- CPU 空泡显著增多;
- decode 阶段耗时变长;
- 单秒中断次数高达 2 万次以上。
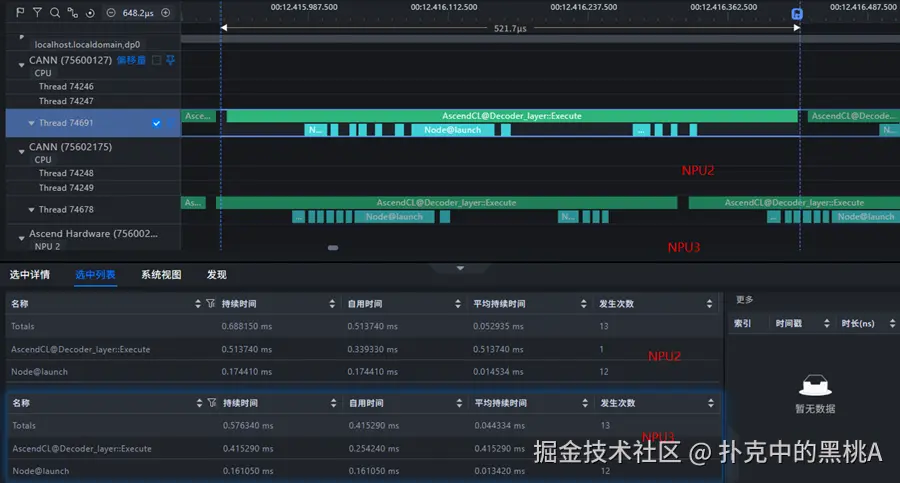
中断过多时的 Profiling 截图
这说明:当中断和业务线程争抢同一个核心时,即便中断处理只需微秒级时间,也会造成频繁的任务中断和缓存失效,从而让整体推理时间变长。
7. 结果分析与结论
通过对比我们可以得出:
- 中断频率高并非主要问题,关键在于中断与计算任务是否抢占同一 CPU;
- 合理的绑核策略(让算子与中断分离)能有效减少 CPU 抢占和 cache 抖动;
- 禁用 irqbalance 或配置
--banirq参数,可防止系统在高负载下频繁调整中断分布。
最终结论:
中断绑核是一种低成本、高收益的性能优化手段,尤其在大模型推理场景中,可显著缓解 HostBound 问题。
五、经验建议
- 识别关键中断源 :重点关注
sq_send_trigger_irq与cq_update_irq等高频 NPU 中断。 - 业务与中断分核执行:确保业务线程与频繁中断不在同一 CPU 核。
- NUMA 一致性优先:绑核时尽量保持任务与中断在同一 NUMA 节点内,减少跨节点访问延迟。
- irqbalance 可调节而非一刀切 :
- 可通过
--banirq精准屏蔽特定中断; - 或延长评估周期,让其更"稳定"地运行。
- 可通过
六、结语
这次 HostBound 调优让可以让我们认识到: 中断并非只是底层系统事件,它对高性能计算任务的干扰可能远超想象。
对于大模型推理、训练这类 CPU 与 NPU 高度耦合的场景,理解并合理利用中断绑核,是性能优化中不可忽视的一环。
当性能陷入瓶颈时,不妨看一眼 /proc/interrupts ------ 也许真正打断你的,不是程序本身,而是那些"悄无声息的中断"。
注明:昇腾PAE案例库对本文写作亦有帮助。