为什么QList是数组
结论:在 Qt5 / Qt6 中,QList 不是链表,而是一个披着 list 名字的顺序容器。
一、QList 的历史背景
1. 名字的误导性
QList 这个名字,本身就极具欺骗性。
- C++ 世界里:
list≈ 链表 - Qt 世界里:
QList≠ 链表(至少现在不是)
很多认知混乱,并不是程序员不行,而是 API 命名留下的历史债务。
2. Qt4 时代的 QList
在 Qt4 时代:
- QList 对小对象做内嵌存储
- 对大对象存指针
- 行为介于数组和链表之间
当时它确实不像 QVector 那么"纯粹",也导致了大量口口相传的"经验结论"。
3. Qt5 / Qt6 的转折
为了性能和可预测性:
- Qt5 起,QList 内部实现改为连续存储
- 行为与 QVector 高度一致
- 但 API 名字和接口被完整保留
于是诞生了今天这个局面:
实现已经变了,但大家的印象没更新。
二、QList 的真实本质
1. 内存模型
在 Qt5 / Qt6 中:
- 元素存储在连续内存中
- 支持随机访问
operator[] - 迭代器是
RandomAccessIterator
这三点中,只要成立一条,就已经可以否定"链表实现"。
2. 一个简单的自证方法
QList list;
list << 1 << 2 << 3 << 4;
for (int i = 0; i < list.size(); ++i)
{
qDebug() << &listi;
}
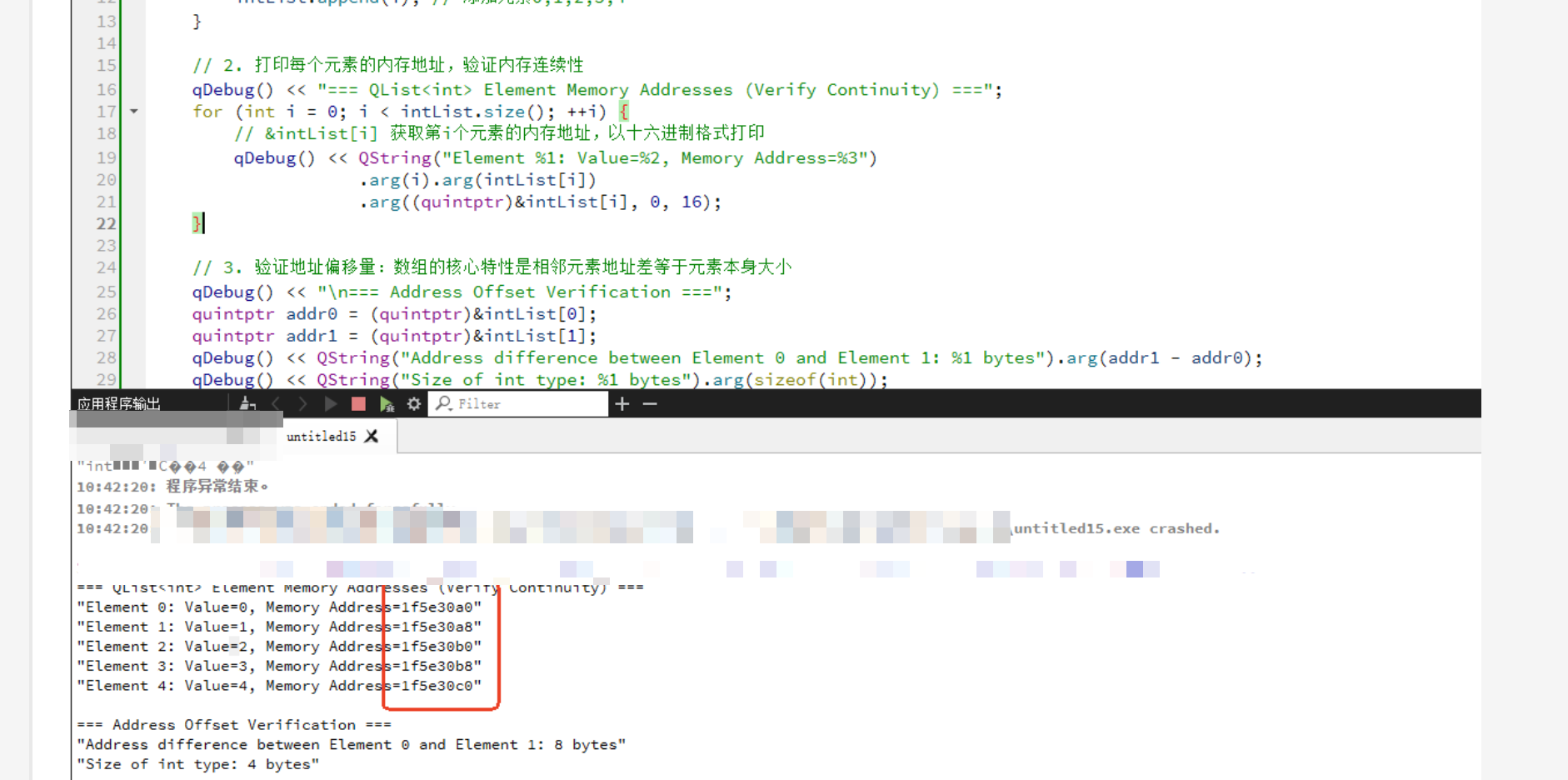
如果它是链表,地址不可能连续。
三、QList 的核心特性
1. 随机访问
int v = listi; // O(1)
这是 QList 与真正链表在语义上的决定性分水岭。
2. 隐式共享(Copy-On-Write)
QList a = b; // O(1)
a0 = newValue; // 触发 detach
特点:
- 拷贝"看起来"很便宜
- 写入时才发生真实拷贝
这是 Qt 框架层面非常重要的设计哲学,但不是免费午餐。
3. 插入 / 删除复杂度
list.insert(pos, value);
list.removeAt(pos);
- 时间复杂度:O(n)
- 会移动内存
- 并不比 QVector 更擅长中间插入
因此:
用 QList 解决"频繁中间插入"的问题,是一个误判。
四、QList 的常见误用场景
1. 当成链表使用
QList<Node*> nodes;
// 期望中间插入很快
这是历史经验误导下最常见的错误。
2. 多线程下无锁读写
// 一个线程遍历
for (auto& v : list) {}
// 另一个线程 append
list.append(x);
隐式共享 不等于线程安全。
这是 Qt 项目里非常隐蔽、但后果严重的坑。
五、QList vs QVector
1. 行为对比
- 连续内存:两者都是
- 随机访问:两者都是
- 中间插入:两者都是 O(n)
2. 关键差异
- QVector:语义清晰、无历史歧义
- QList:API 兼容性强、历史包袱重
3. 工程选择原则
新代码默认 QVector,QList 只为兼容存在。
六、什么时候还可以接受 QList
不是绝对不能用,而是使用场景极少。
- 维护老 Qt 项目
- 被动接收 Qt API 返回的 QList
- 项目中已经大量使用 QList,且无性能/并发问题
七、结论
- QList 不是链表(Qt5 / Qt6)
- 不要用链表思维使用 QList
- 隐式共享在多线程下必须显式加锁
- QList 不适合并发队列
- 新代码优先 QVector