Redis 故障检测进化论:从 Sentinel 到 Cluster 的机制演变
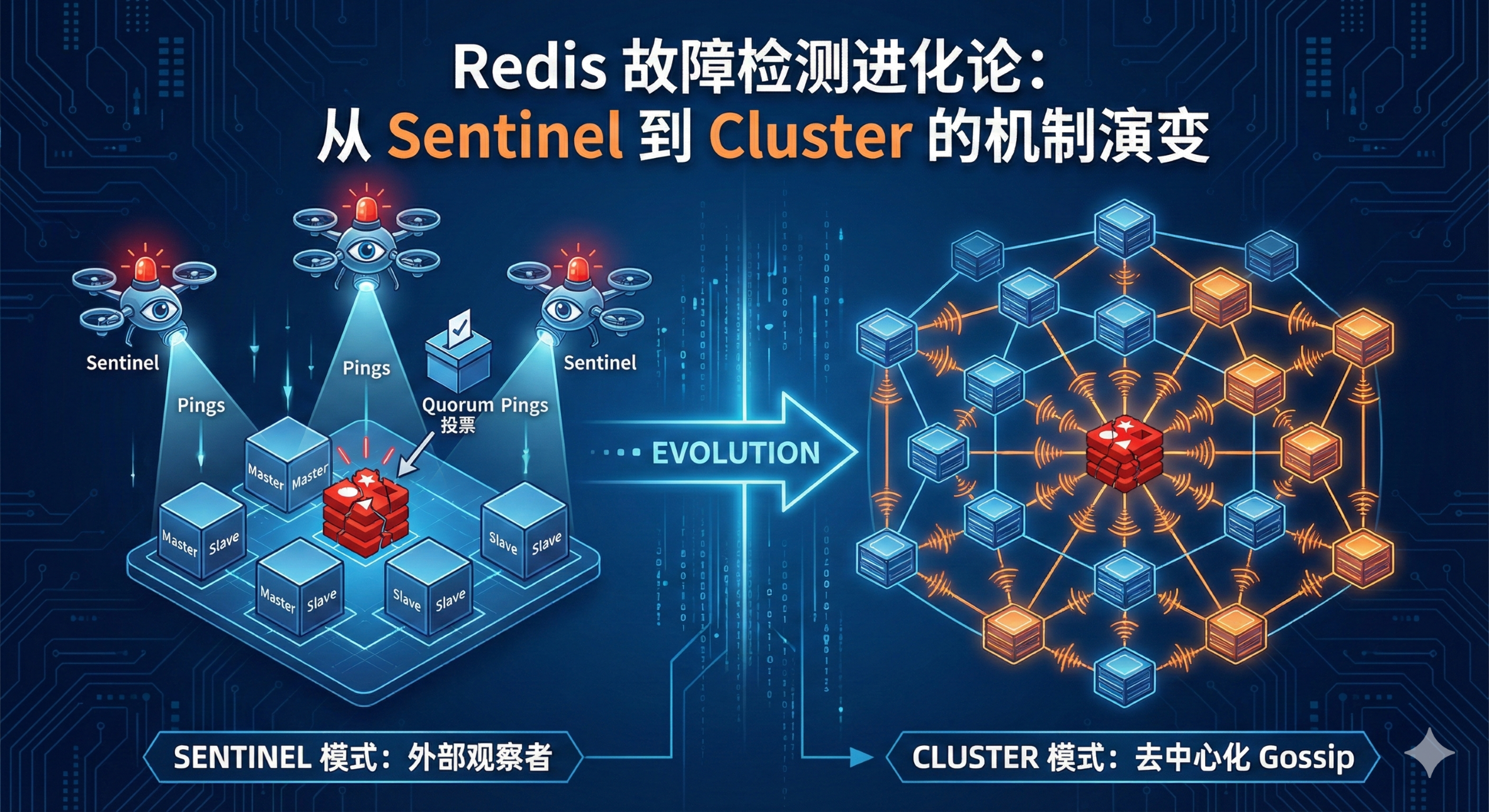
在 Redis 的架构演进中,高可用(High Availability)始终是核心议题。很多同学在从主从+哨兵(Sentinel)模式迁移到 Redis Cluster 模式时,往往会产生一个惯性思维:认为 Cluster 的故障检测机制只是把 Sentinel 的功能集成到了数据节点里。
虽然两者底层都依赖 PING/PONG 的心跳机制,但在分布式一致性的达成逻辑上,它们代表了两种截然不同的架构哲学。今天我们就深入到底层,聊聊这两者在故障判定上的本质区别。
核心差异:监控视角的转变
首先要明确一个概念,故障检测不仅仅是"发现节点挂了",更重要的是"让集群对节点挂了达成共识"。
1. Sentinel:外部观察者模式(Sidecar 视角)
Sentinel 就像是挂在 Redis 集群旁边的"纠察队"。它是一个独立的进程,不存储数据,只负责监控。
虽然 Sentinel 本身也是一个小集群(为了避免单点故障),但对于 Redis 数据节点来说,监控流量是自上而下的。
- 机制:Sentinel 每秒向 Master 和 Slave 发送 PING。
- SDOWN(主观下线) :如果单个 Sentinel 在
down-after-milliseconds时间内没收到回复,它自己会在小本本上记一笔:这个 Redis 挂了。 - ODOWN(客观下线) :这才是关键。发现主观下线的 Sentinel 会通过
SENTINEL is-master-down-by-addr命令询问其他 Sentinel:"你们看这个 Master 挂了吗?"只有当达到 Quorum(法定人数)数量的 Sentinel 都认为它挂了,SDOWN 才会升级为 ODOWN,进而触发故障转移。
本质 :这是一种类中心化的监控(虽然 Sentinel 是分布式的,但相对于 Data Node,它们是外部的仲裁中心)。
2. Cluster:去中心化的 Gossip 协议(Peer-to-Peer 视角)
Redis Cluster 去掉了外部的 Sentinel,将故障检测的能力下沉到了每一个数据分片(Node)中。这里没有"纠察队",每个节点既是数据存储者,也是集群状态的维护者。
- 机制:Cluster 节点之间通过 Gossip 协议互通有无。每个节点维护一份集群视图,并通过 TCP 连接(通常是端口号+10000)不断交换信息。
- PFAIL(拟似下线):类似于 Sentinel 的 SDOWN。节点 A 给节点 B 发 PING,超时未回,A 就在本地把 B 标记为 PFAIL。
- FAIL(确诊下线) :类似于 Sentinel 的 ODOWN。但是,这里没有显式的"投票请求"。节点 A 会通过 Gossip 消息把"B 疑似挂了"这个信息传播出去。
- 当节点 A 收集到集群中半数以上持有 Slot 的 Master 节点都将 B 标记为 PFAIL 或 FAIL 时,A 就会把 B 的状态强行升级为 FAIL。
- 随后,A 会向全网广播"B 已经 FAIL"的消息,迫使所有节点接受这一事实。
本质 :这是纯粹的去中心化。没有上帝视角,只有节点间的口口相传和共识达成。
深度剖析:为什么 Cluster 要用 Gossip?
既然 Sentinel 的机制很成熟,Cluster 为什么要改用复杂的 Gossip?
这就涉及到了"中心化 vs 去中心化"的问题。
1. 元数据管理的瓶颈
在 Sentinel 模式下,客户端通常需要通过 Sentinel 获取 Master 地址,或者连接 VIP。而在 Cluster 模式下,规模可能达到上千个节点。如果依然依赖一组外部 Sentinel 来管理上千个节点的状态,Sentinel 本身会成为网络流量和判断逻辑的瓶颈。
2. 消息风暴的抑制
Cluster 的 Gossip 协议设计得非常巧妙。节点不是每一轮都 Ping 所有人(那是 O(N2)O(N^2)O(N2) 的复杂度,网络会炸)。
Redis Cluster 的做法是:每个节点每秒随机选几个节点发送 Ping,但会优先选择那些"很久没通信"的节点。这在保证故障能在有限时间内被检测到的同时,严格控制了网络带宽的消耗。
3. 故障判定的差异点总结
为了更清晰地对比,我整理了以下核心差异表:
| 特性 | Sentinel 模式 | Redis Cluster 模式 |
|---|---|---|
| 监控主体 | 独立的 Sentinel 进程 | 持有 Slot 的 Master 节点 |
| 通信流向 | 外部 -> 内部 (Sentinel -> Redis) | 内部互联 (Mesh 网络) |
| 状态术语 | SDOWN -> ODOWN | PFAIL -> FAIL |
| 共识机制 | Quorum 投票 (Raft 变种) | Gossip 传播 + 过半 Master 确认 |
| 适用场景 | 小规模、逻辑简单的主从架构 | 大规模分片、水平扩展场景 |
避坑指南:Cluster 故障检测的误区
在实际生产环境中,Cluster 的这种机制也带来了一些需要注意的问题:
- Gossip 端口阻塞 :很多运维同学在配置防火墙时,只开了 Redis 的服务端口(如 6379),忘了开集群总线端口(16379)。这会导致节点间无法握手,集群永远处于
fail状态。 - 收敛时间:由于 Gossip 具有传染性,它不如 Sentinel 的集中投票来得快。在极大规模集群中,故障信息的传播和确认是需要时间的(虽然通常也是毫秒级),这中间可能存在短暂的数据路由错误。
- 网络分区:在出现脑裂(Network Partition)时,Cluster 必须要有半数以上 Master 在同一分区才能继续工作,且能完成故障判定。如果分割得比较碎,整个集群可能会进入不可用状态。
总结
回到最初的问题:它们的机制一样吗?
微观上一样:都依赖 Ping/Pong 超时来做存活探测。
宏观上完全不同:Sentinel 是代议制民主(选出代表 Sentinel 投票),而 Cluster 是全民公投(Master 节点直接参与状态确认)。
理解了这一点,在做 Redis 架构选型和故障排查时,就能更准确地判断系统的行为模式了。