文章目录
- 一、Transformer架构和主要思想
- 二、重要组成部分:注意力机制
-
- [2.1 注意力机制的本质](#2.1 注意力机制的本质)
- [2.2 Transfromer中的自注意力机制运算](#2.2 Transfromer中的自注意力机制运算)
- [2.3 Multi-Head Attention多头注意力机制](#2.3 Multi-Head Attention多头注意力机制)
- 三、Transformer的基本结构
-
- [3.1 Embedding层与位置编码](#3.1 Embedding层与位置编码)
- [3.2 Encoder结构](#3.2 Encoder结构)
-
- [3.2.1 残差连接](#3.2.1 残差连接)
- [3.2.2 Layer Normalization层归一化](#3.2.2 Layer Normalization层归一化)
- [3.2.3 Feed-Forward Networks前馈网络](#3.2.3 Feed-Forward Networks前馈网络)
- [3.3 Decoder结构](#3.3 Decoder结构)
-
- [3.3.1 完整Transformer与Decoder-Only结构的数据流](#3.3.1 完整Transformer与Decoder-Only结构的数据流)
- [3.3.2 Encoder-Decoder结构的Decoder](#3.3.2 Encoder-Decoder结构的Decoder)
-
- [3.3.2.1 输入与teacher forcing](#3.3.2.1 输入与teacher forcing)
- [3.3.2.2 掩码注意力机制](#3.3.2.2 掩码注意力机制)
- [3.3.2.3 普通掩码与前瞻掩码](#3.3.2.3 普通掩码与前瞻掩码)
- [3.3.2.4 编码器-解码器注意力层](#3.3.2.4 编码器-解码器注意力层)
- [3.3.3 Encoder-Decoder结构的Decoder](#3.3.3 Encoder-Decoder结构的Decoder)
一、Transformer架构和主要思想
本章图包含了Transformer的背景和目的、Transformer架构图、其主要组成部分Attention机制的主要思想+代码、残差连接+简要代码、Positional Encoder正余弦位置编码主要思想、teacher forcing介绍、两种Mask(Padding Mask/ Look-ahead Mask)。漏掉了Encoder-Decoder Attention。

注:Transformer囊括了两个重要的组成部分(encoder和decoder两种),encoder和decoder可以分开使用。
二、重要组成部分:注意力机制
2.1 注意力机制的本质
注意力机制通过计算样本与样本之间的相关性,从而判断每个样本在一个序列中的重要程度,并给这些样本赋予能代表其重要性的权重。
经典的注意力机制(Attention)进行的是跨序列的样本相关性计算:考虑的是序列A的样本之于序列B的重要程度。这样形式常常用于经典的序列到序列任务(Seq2Seq),比如机器翻译。在机器翻译中,会考虑到原始语言系列中的样本对于新生成的序列中有多大的影响,因此计算的是原始序列的样本之于新序列的重要程度。
2.2 Transfromer中的自注意力机制运算
Transformer中使用的是自注意力机制(Self-Attention),这是一个序列内部对样本进行相关性计算的方式,核心考虑的是序列A样本之于序列A本身的重要程度。
NLP任务中,序列数据中的每个样本会被编码成一个向量,其中文字数据被编码后的结果被成为词向量,时序数据则被编码成时序向量。计算样本与样本之间的相关性,本质就是计算向量与向量之间的相关性。向量之间的相关行可以由两个向量的点积来衡量。
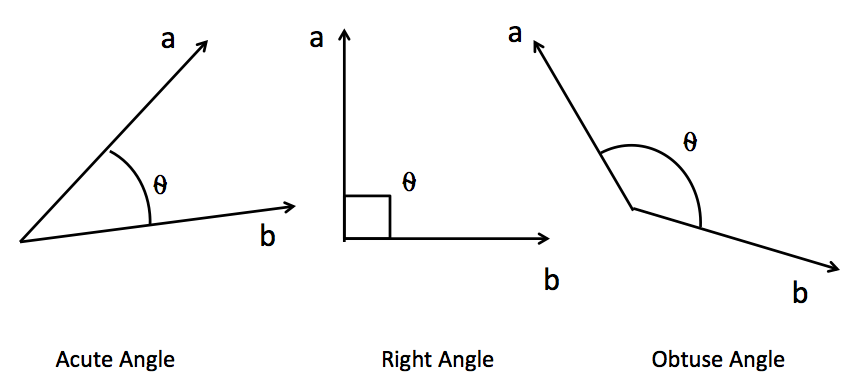
相似度计算:sim = a.b/||a||.||b|| --->余弦相似度计算。假设有两个三维向量A和B,他们的点积可以具体表示为:
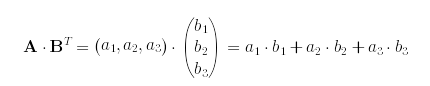
在实际计算相关性的时候,一般不会直接用原始矩阵与其转置矩阵点乘。我们希望得到语义的相关性,非为单纯数字上的相关性,因此在Transformer中,要将原本的emdding 通过可学习的参数矩阵 WQ,WK,WV投影到查询、键、值空间,使得模型能够学习在不同上下文中如何计算相关性。
2.3 Multi-Head Attention多头注意力机制

具体代码如下:
python
import torch
from torch import nn
class Mutlithead_Attention(nn.Module):
def __init__(self, dmodel, nheads):
super().__init__()
self.dmodel = dmodel
self.nheads = nheads
self.d_k = dmodel// nheads # 使用整数除法
self.W_Q = nn.Linear(dmodel, dmodel)
self.W_K = nn.Linear(dmodel, dmodel)
self.W_V = nn.Linear(dmodel, dmodel)
self.W_O = nn.Linear(dmodel, dmodel)
def forward(self, X):
#将设X的shape为(batch_size=100, seq_len=10, dmodel = 512)
batch_size, seq_len, _ = X.shape
Q = self.W_Q(X) #(100, 10, 512)
K = self.W_K(X) #(100, 10, 512)
V = self.W_V(X) #(100, 10, 512)
Q = Q.view(batch_size, seq_len, self.nheads, self.d_k) #(100, 10, 8, 64)
K = K.view(batch_size, seq_len, self.nheads, self.d_k)#(100, 10, 8, 64)
V = V.view(batch_size, seq_len, self.nheads, self.d_k)#(100, 10, 8, 64)
#调整维度,以便让8个头同时进行计算
Q = Q.transpose(1, 2) #(100, 8, 10, 64)
K = K.transpose(1, 2) #(100, 8, 10, 64)
V = V.transpose(1, 2) #(100, 8, 10, 64)
#计算注意力权重得分
scores = torch.matmul(Q, K.transpose(-1, -2)) / (self.d_k ** 0.5)
#权重的shape为(100, 8, 10, 10)
#计算得分
atten_weight = torch.softmax(scores, dim=-1) #(100, 8, 10, 10)
#多头输出
head_outs = torch.matmul(atten_weight, V)
#(100, 8, 10, 10) @ (100, 8, 10, 64)------>(100, 8, 10, 64)
#多头拼接
head_outs = head_outs.transpose(1, 2) #(100, 10, 8, 64)
concat_outputs = head_outs.reshape(batch_size, seq_len, self.dmodel)
#全连接投影
outputs = self.W_O(concat_outputs)
return outputs
X = torch.randn((100, 10, 512))
#print(X.shape)
#torch.Size([100, 10, 512])
model = Mutlithead_Attention(dmodel=512, nheads=8)
predict_y = model.forward(X)
#print(predict_y.shape)
#torch.Size([100, 10, 512])三、Transformer的基本结构
3.1 Embedding层与位置编码
当信息在进入Transformer架构之前,首先要对信息进行Embedding和Positional Encoding 两种编码。转换成Embedding是因为需要将序列样本转换成计算机可以读取的结构。Embedding层将离散的词汇或符号转换为连续的高维向量,使得模型能够处理和学习这些向量的语义关系 。通过嵌入表示,输入的序列可以更好地捕捉到词与词之间的相似性和关系。此外,在输入到编码器和解码器之前,通常还会添加位置编码(Positional Encoding) ,因为Transformer没有内置的序列顺序信息,也就是说Attention机制本身会带来位置信息的丧失。

3.2 Encoder结构
Encoder编码器可以单独使用。在许多情况下,我们可以单独使用Encoder的输出执行各种任务,而不需要Decoder解码器部分,下面是经典场景:
(1)序列到序列任务的编码器:在一些序列到序列任务中,只需要对输入序列进行编码,而不需要生成输出序列。例如,文本摘要、问答系统中,只需将输入文本编码为一个语义表示,而无需生成摘要或答案。
(2)预训练模型的基础部分:许多预训练模型,如BERT(Bidirectional Encoder Representations from Transformers)等,基于 Transformer Encoder 架构。在这些模型中,Encoder 的输出可以被用作下游任务的输入,从而提供丰富的语义信息。
除此之外,Encoder还应用于许多任务,比如:
(1)情感分析:旨在确定文本的情感倾向,如正面、负面或中性。在这类任务中,只需要输入文本编码作为一个语义表示即可预测文本的情感倾向,而不需要生成任何文本输出。
(2)文本分类:例如垃圾邮件过滤、新闻分类等。在这种任务中,我们使用Enocder将输入文本编码作为一个语义表示,然后通过该表示进行分类预测。
(3)命名实体识别:要求文本识别和分类名命名实体,如人名、地名、组织名等。在这类任务中,我们可以使用Encoder将文本编码成一个语义表示,然后通过该表示来对命名实体进行识别。
(4)关系抽取:旨在从文本中提取实体之间的关系。例如:从病历中抽取药物与疾病之间的关系。
(5)文本生成的预训练:在预训练语言模型中,我们可以使用Encoder将文本编码成一个语义表示,然后利用这个语义来预测下一个词或生成文本序列。这在生成式任务中非常有用,如对话生成、摘要生成。
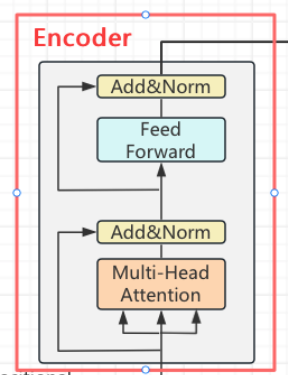
3.2.1 残差连接
"Add"表示"加和",在Encoder中,这里的加和指的是X和F(X)的加和。

3.2.2 Layer Normalization层归一化
在Transformer结构中,Layer Normalization(层归一化)是一个至关重要的部分。与Batch Normalization(批归一化)不同,Layer Normalization不是对一个批次中的样本进行归一化,而是独立对每个样本中的所有特征进行归一化(也就是对同一个单词、同一个时间点的词向量的所有维度进行归一化)。具体来说,对于每个样本,Layer Normalization会在特定层的所有激活上计算均值和方差,然后用这些统计量归一化该样本的激活值。这样可以将每一次迭代的数据调整为相同分布,消除极端值,提升训练稳定性。
3.2.3 Feed-Forward Networks前馈网络
自注意力机制大多数时候是一个线性结构:加权求和是一个线性操作,即便我们是经过丰富的权重变化、由丰富的Q、K、V等矩阵点积的结果,还有softmax函数,但是自注意力机制依然是一个线性的过程。因此,在加入前馈神经网络之前,transformer本身不带有传统意义上的非线性结构。Transformer模型中的前馈网络在自注意力层之后对每个位置的表示独立地应用相同的变换,这样可以进一步提高网络的表示能力。

3.3 Decoder结构
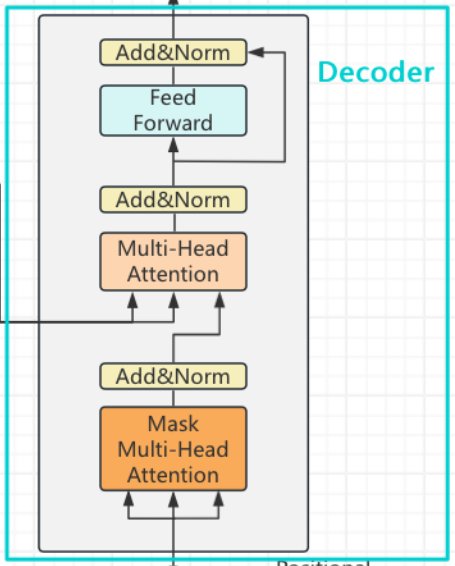
3.3.1 完整Transformer与Decoder-Only结构的数据流
1. 使用完整Transformer结构的任务
(1)机器翻译:将源语言句子翻译成目标语言的句子。例如将英文翻译成中文。
(2)文本摘要:将长文本总结成简短的摘要,例如:将新闻文章总结为间断的新闻标题。
(3)图像字幕生成:为给定的图像生成描述性文字。
(4)文本到语音:将文本转换为语音信号,比如将输入文本转换成自然的语音输出。
(5)问答系统:根据上下文回答用户的问题,或者给定一段文本,回答其中提到的具体问题。
2. 只用Decoder结构的任务
适用于需要从部分输入生成完整序列的任务:
(1)大语言模型:预测给定文本序列中的下一个词或字符,例如GPT系统模型用于生成连续的文本段落。(但并不是所有的大语言模型都是Decoder-only结构)
(2)文本生成:根据部分输入生成完整的文本,比如根据开头的一句话生成一篇文章或故事,根据部分诗歌生成完整的诗歌。
(3)代码补全:根据部分输入代码生成完整的代码段。
(4)对话生成:根据对话历史生成下一句回复。
(5)问答系统:根据上下文回答用户的问题,或者给定一段文本,回答其中提到的具体问题。
3.3.2 Encoder-Decoder结构的Decoder
3.3.2.1 输入与teacher forcing
Decoder的输入是滞后1个单位的标签矩阵(shifted right outputs),我们要将真实标签输入给模型,并且让真实标签指导模型的学习与预测,这种让模型通过正确的标签来学习的流程在Transformer中被称之为是teacher forcing强制教学机制。具体概念如图所示
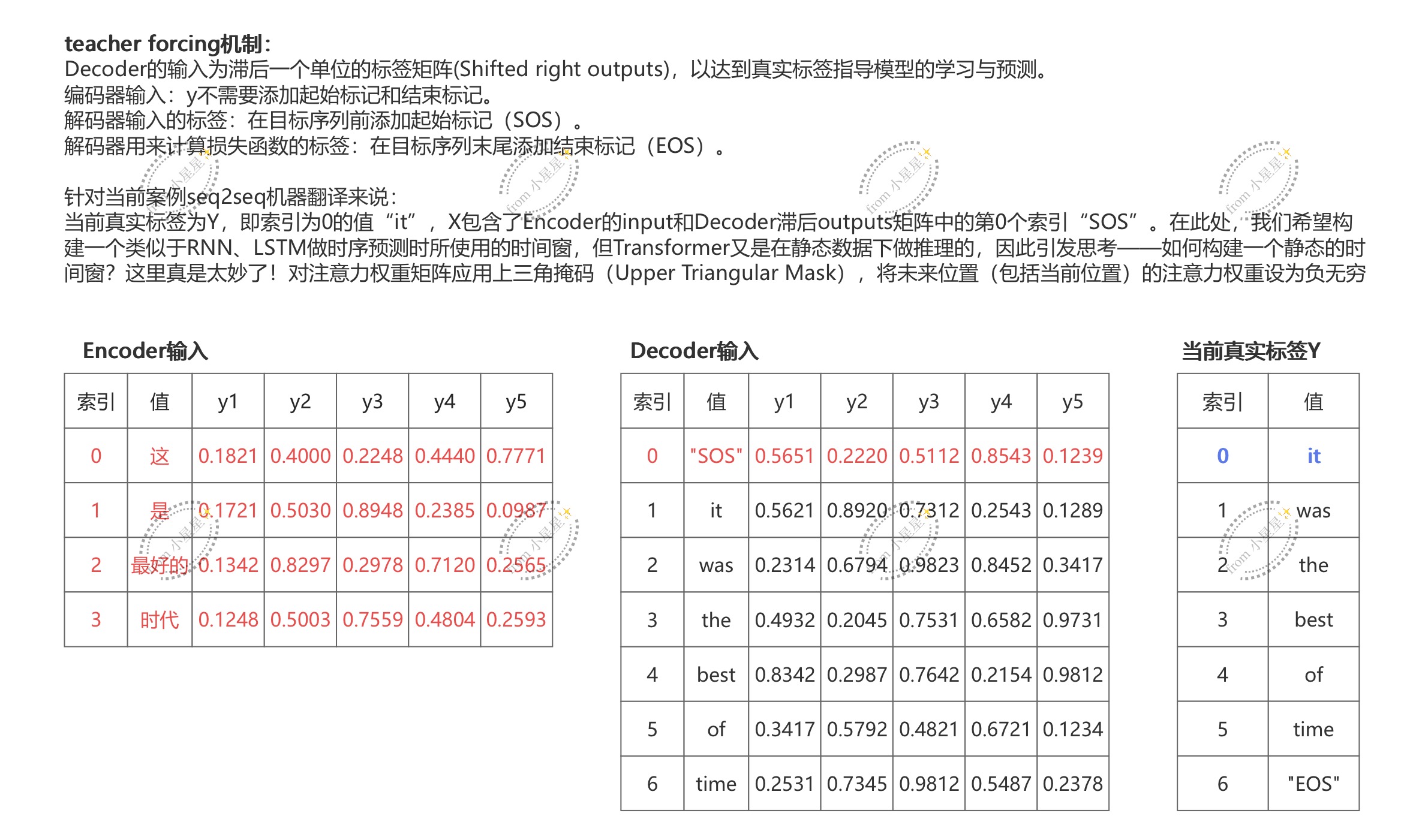
红色的部分是当前Decoder的输入,蓝色部分是当前真实标签。
3.3.2.2 掩码注意力机制

3.3.2.3 普通掩码与前瞻掩码
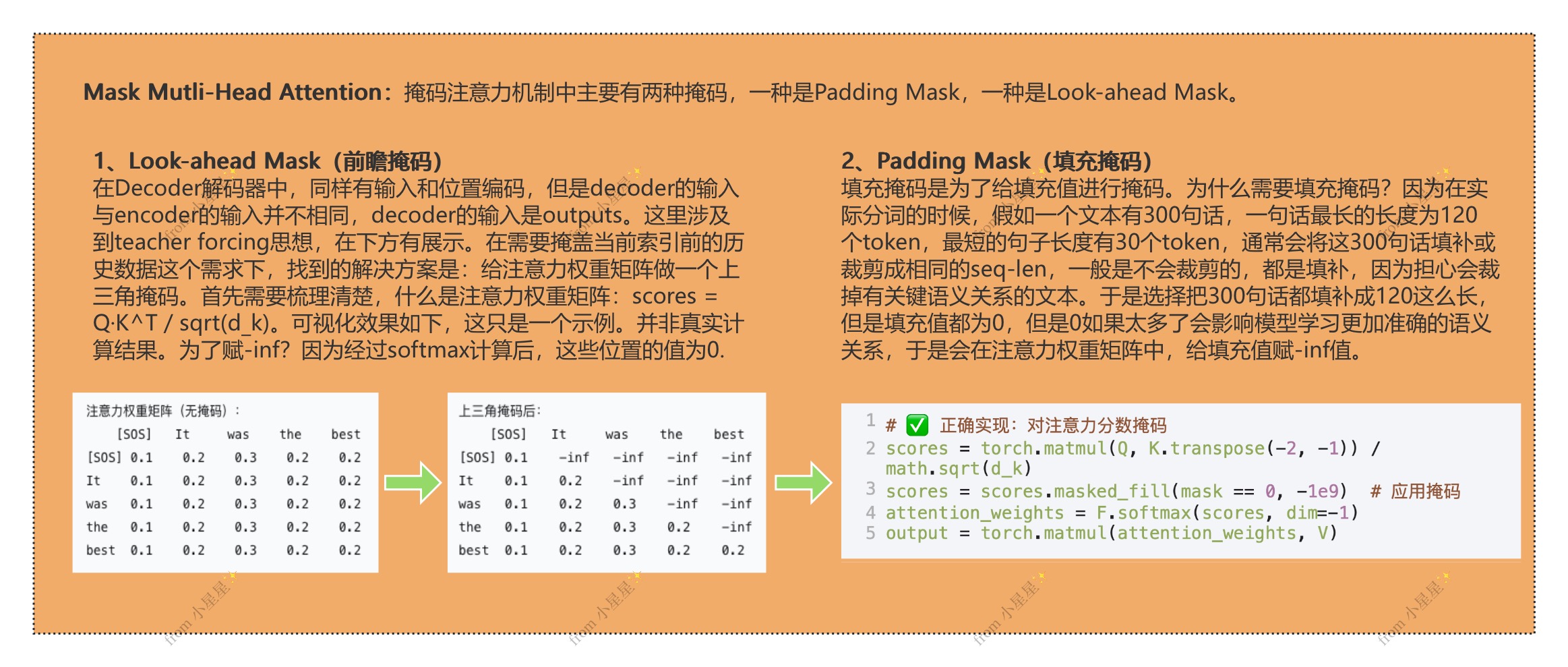
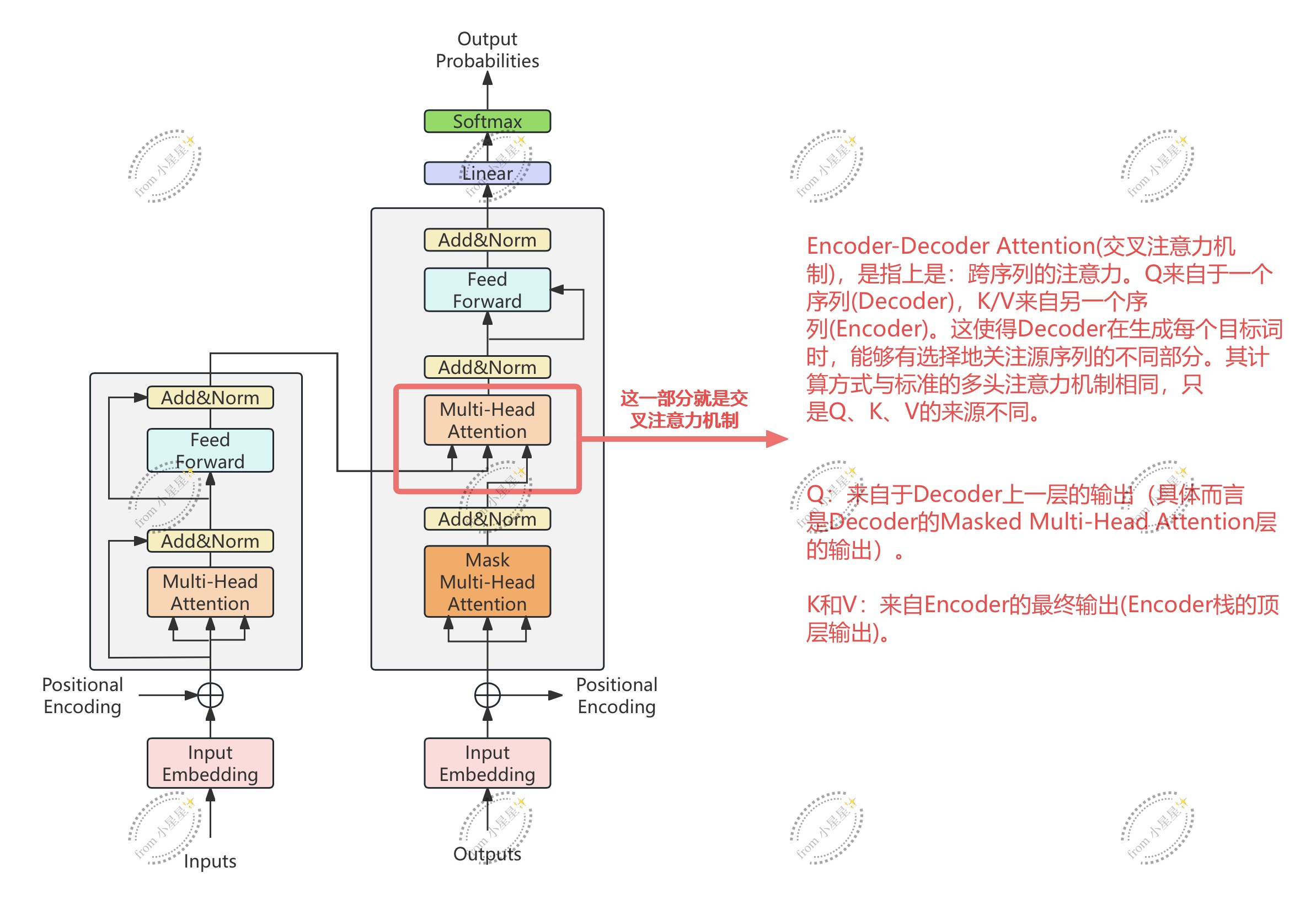
3.3.2.4 编码器-解码器注意力层
3.3.3 Encoder-Decoder结构的Decoder
如图所示,与原本的Decoder结构相比,Decoder-only状态下的Decoder不再存在编码器-解码器注意力层,整个结构会变得更像编码器Encoder,但依然保留着Teacher forcing和掩码机制。由于没有了编码器-解码器注意力层,因此原本依赖于编码器-解码器注意力层完成的整套训练和运算流程也都不再有效了,相对的,在Decoder-only结构中的Decoder大部分时候都采用"自回归"的训练流程------自回归流程在时间序列预测中是一种常用的方法,它逐步生成未来的值,每一步的预测依赖于前一步的实际值或预测值。
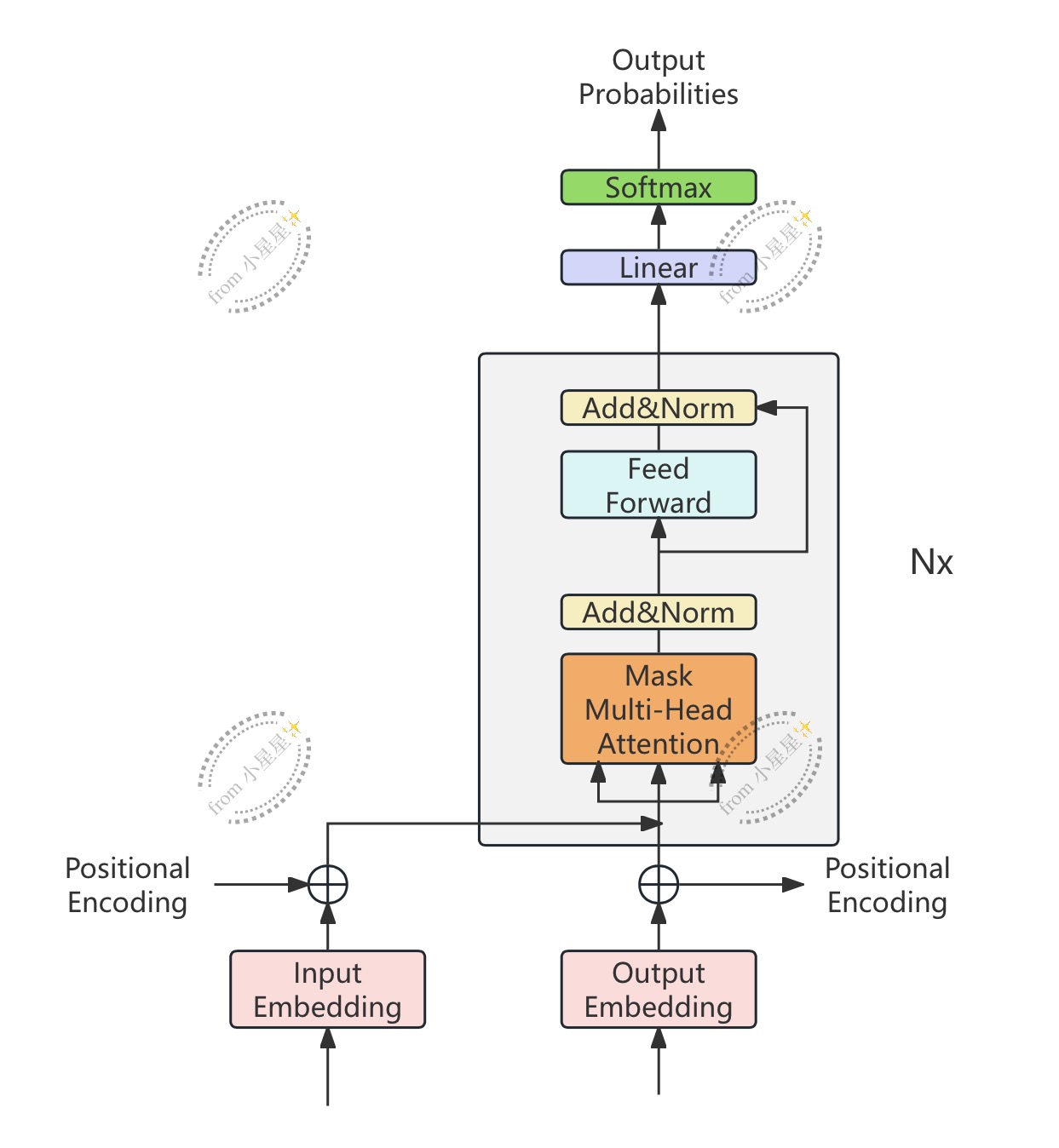
生成式任务带有一定的"自监督"属性,我们训练用的数据、和要预测的数据都来自于同一段序列,因此标签数据在下一个时间步就会成为我们的特征数据,故而我们也不会特地再去区分特征和标签、而是会区分"输入"与"输出"。不过,从架构图上来看,除了要预测的序列本身之外,我们依然也可以给Decoder输入更多额外的信息(图上的inputs部分)。大部分时候,我们可以使用这条数据流线路向Decoder传递一些相应的"条件"与"背景知识",可以帮助我们更好地进行信息的生成和填补。