相关项目下载链接
本节内容基于ae.py文件,实现了一个Patch 级自动编码器(Patch AutoEncoder),核心功能是将图像按固定尺寸分块(Patch),通过编码 - 解码流程实现图像重。具体流程如下:
导入依赖库
python
import abc
import torch定义模型加载函数
python
def load() -> torch.nn.Module:
from pathlib import Path
model_name = "PatchAutoEncoder"
model_path = Path(__file__).parent / f"{model_name}.pth"
print(f"Loading {model_name} from {model_path}")
return torch.load(model_path, weights_only=False)定义转换通道函数,实现 "通道最后"(HWC)与 "通道第一"(CHW)格式转换
python
def hwc_to_chw(x: torch.Tensor) -> torch.Tensor:
"""
Convert an arbitrary tensor from (H, W, C) to (C, H, W) format.
This allows us to switch from transformer-style channel-last to pytorch-style channel-first
images. Works with or without the batch dimension.
"""
dims = list(range(x.dim()))
dims = dims[:-3] + [dims[-1]] + [dims[-3]] + [dims[-2]]
return x.permute(*dims)
def chw_to_hwc(x: torch.Tensor) -> torch.Tensor:
"""
The opposite of hwc_to_chw. Works with or without the batch dimension.
"""
dims = list(range(x.dim()))
dims = dims[:-3] + [dims[-2]] + [dims[-1]] + [dims[-3]]
return x.permute(*dims)Patch 分块模块
- 分块模块:接收 (B, H, W, 3) 格式的图像张量,将其按patch_size大小分块,每个 Patch 通过线性变换映射为latent_dim维的嵌入向量,输出 (B, H//patch_size, W//patch_size, latent_dim) 格式的 Patch 嵌入张量。
- 逆分块模块:接收 (B, w, h, latent_dim) 格式的 Patch 嵌入张量,将其逆转换为原始尺寸的图像张量 (B, wpatch_size, hpatch_size, 3),是PatchifyLinear的逆操作。
python
# 分块模块
class PatchifyLinear(torch.nn.Module):
"""
Takes an image tensor of the shape (B, H, W, 3) and patchifies it into
an embedding tensor of the shape (B, H//patch_size, W//patch_size, latent_dim).
It applies a linear transformation to each input patch
"""
def __init__(self, patch_size: int = 25, latent_dim: int = 128):
super().__init__()
self.patch_conv = torch.nn.Conv2d(3, latent_dim, patch_size, patch_size, bias=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = hwc_to_chw(x)
x = self.patch_conv(x)
return chw_to_hwc(x)
# 逆分块模块
class UnpatchifyLinear(torch.nn.Module):
"""
Takes an embedding tensor of the shape (B, w, h, latent_dim) and reconstructs
an image tensor of the shape (B, w * patch_size, h * patch_size, 3).
"""
def __init__(self, patch_size: int = 25, latent_dim: int = 128):
super().__init__()
self.unpatch_conv = torch.nn.ConvTranspose2d(latent_dim, 3, patch_size, patch_size, bias=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = hwc_to_chw(x)
x = self.unpatch_conv(x)
return chw_to_hwc(x)抽象基类 PatchAutoEncoderBase
定义了 Patch 自动编码器的核心抽象接口,包含encode(编码)和decode(解码)两个抽象方法。
python
class PatchAutoEncoderBase(abc.ABC):
@abc.abstractmethod
def encode(self, x: torch.Tensor) -> torch.Tensor:
"""
Encode an input image x (B, H, W, 3) into a tensor (B, h, w, bottleneck)
"""
@abc.abstractmethod
def decode(self, x: torch.Tensor) -> torch.Tensor:
"""
Decode a tensor x (B, h, w, bottleneck) into an image (B, H, W, 3)
"""核心模型 PatchAutoEncoder
python
class PatchAutoEncoder(torch.nn.Module, PatchAutoEncoderBase):
"""
Implement a PatchLevel AutoEncoder
Hint: Convolutions work well enough, no need to use a transformer unless you really want.
Hint: See PatchifyLinear and UnpatchifyLinear for how to use convolutions with the input and
output dimensions given.
Hint: You can get away with 3 layers or less.
Hint: Many architectures work here (even a just PatchifyLinear / UnpatchifyLinear).
However, later parts of the assignment require both non-linearities (i.e. GeLU) and
interactions (i.e. convolutions) between patches.
"""
# 将输入图像编码为低维度的瓶颈特征(bottleneck),输出 (B, h, w, bottleneck) 格式的张量。
class PatchEncoder(torch.nn.Module):
"""
(Optionally) Use this class to implement an encoder.
It can make later parts of the homework easier (reusable components).
"""
def __init__(self, patch_size: int, latent_dim: int, bottleneck: int):
super().__init__()
self.patchify = PatchifyLinear(patch_size, latent_dim)
self.conv1 = torch.nn.Conv2d(latent_dim, latent_dim, kernel_size=3, padding=1)
self.conv2 = torch.nn.Conv2d(latent_dim, bottleneck, kernel_size=1)
self.activation = torch.nn.GELU()
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.patchify(x)
x = hwc_to_chw(x)
x = self.activation(self.conv1(x))
x = self.conv2(x)
return chw_to_hwc(x)
# 将瓶颈特征解码为原始尺寸的图像,实现decode(encode(x)) ≈ x的重建目标。
class PatchDecoder(torch.nn.Module):
def __init__(self, patch_size: int, latent_dim: int, bottleneck: int):
super().__init__()
self.conv1 = torch.nn.Conv2d(bottleneck, latent_dim, kernel_size=1)
self.conv2 = torch.nn.Conv2d(latent_dim, latent_dim, kernel_size=3, padding=1)
self.unpatchify = UnpatchifyLinear(patch_size, latent_dim)
self.activation = torch.nn.GELU()
self.output_act = torch.nn.Tanh()
self.output_scale = 0.5
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = hwc_to_chw(x)
x = self.activation(self.conv1(x))
x = self.activation(self.conv2(x))
x = chw_to_hwc(x)
x = self.unpatchify(x)
return self.output_act(x) * self.output_scale
# 初始化编码器和解码器,实现完整的前向传播流程,返回重建图像和损失字典。
def __init__(self, patch_size: int = 25, latent_dim: int = 128, bottleneck: int = 128):
super().__init__()
self.patch_size = patch_size
self.encoder = self.PatchEncoder(patch_size, latent_dim, bottleneck)
self.decoder = self.PatchDecoder(patch_size, latent_dim, bottleneck)
def forward(self, x: torch.Tensor) -> tuple[torch.Tensor, dict[str, torch.Tensor]]:
"""
Return the reconstructed image and a dictionary of additional loss terms you would like to
minimize (or even just visualize).
You can return an empty dictionary if you don't have any additional terms.
"""
z = self.encode(x)
x_recon = self.decode(z)
recon_loss = torch.nn.functional.mse_loss(x_recon, x)
return x_recon, {"recon_loss": recon_loss}
def encode(self, x: torch.Tensor) -> torch.Tensor:
return self.encoder(x)
def decode(self, x: torch.Tensor) -> torch.Tensor:
return self.decoder(x)下面进行模型训练:
python
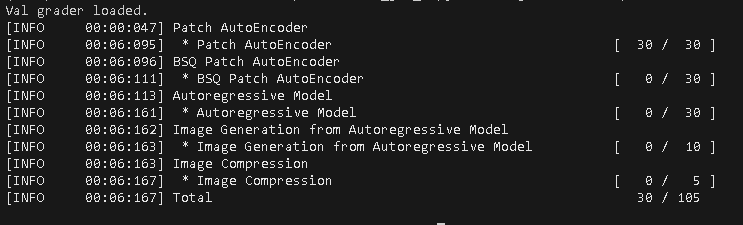
python -m homework.train PatchAutoEncoder模型训练过程如图所示

将代码打包为压缩文件
python
python bundle.py homework 20251223.zip进行评分自测:
python
python -m grader 20251223.zip最终测试得分如下: