锋哥原创的Transformer 大语言模型(LLM)基石视频教程:
https://www.bilibili.com/video/BV1X92pBqEhV
课程介绍

本课程主要讲解Transformer简介,Transformer架构介绍,Transformer架构详解,包括输入层,位置编码,多头注意力机制,前馈神经网络,编码器层,解码器层,输出层,以及Transformer Pytorch2内置实现,Transformer基于PyTorch2手写实现等知识。
Transformer 大语言模型(LLM)基石 - 输出层(Output Layer)详解以及算法实现
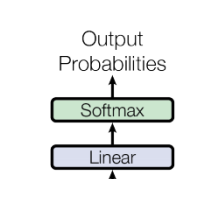
解码器的最终输出会传递给输出层,通常是一个全连接层,它将解码器的输出映射到目标词汇表的维度,生成每个时间步的预测词汇。
-
功能:生成序列的预测输出,例如在翻译任务中,输出为目标语言的词汇。
-
结构:这个层的输出维度为batch_size, seq_len, vocab_size,表示每个词的位置的输出分布。
在输出层的最后,通常会使用Softmax函数来将模型的输出转换为概率分布,然后选择概率最高的词作为模型的预测输出。
-
功能:根据输出分布生成最终的预测结果。
-
结构:Softmax将每个位置的输出转换为一个概率分布,并选择概率最高的词作为最终的输出。
代码实现:
# 输出层
class OutputLayer(nn.Module):
def __init__(self, d_model, vocab_size):
super().__init__()
self.d_model = d_model # 词嵌入维度大小
self.vocab_size = vocab_size # 词表大小
self.linear = nn.Linear(d_model, vocab_size) # 线性层
def forward(self, x):
"""
前向传播
对输入x通过线性层变换后,应用log_softmax函数处理,最后返回处理结果。具体来说:
self.linear(x) - 将输入x通过线性变换
F.log_softmax() - 对线性变换结果应用对数softmax操作
dim=-1 - 指定在最后一个维度上进行softmax计算
:param x: 输入张量 [batch_size, seq_len, d_model]
:return: 输出张量 [batch_size, seq_len, vocab_size]
"""
return F.log_softmax(self.linear(x), dim=-1) # 对输出张量进行softmax
# 测试输出层
def test_output_layer():
decoder_result = test_decoder()
# 实例化输出层对象
output_layer = OutputLayer(d_model=512, vocab_size=2000)
output_result = output_layer(decoder_result)
print('output_result.shape:', output_result.shape)
if __name__ == '__main__':
# test_encoder()
# test_decoder()
test_output_layer()运行输出:
