文章目录
一、什么是库
库是写好的现有的,成熟的,可以复⽤的代码。现实中每个程序都要依赖很多基础的底层库,不可能每个⼈的代码都从零开始,因此库的存在意义⾮同寻常。
本质上来说库是⼀种可执⾏代码的⼆进制形式,可以被操作系统载⼊内存执⾏。库有两种:
- 静态库
.a[Linux] .lib[windows] - 动态库
.so[Linux] .dll[windows]
C:

C++:

预备⼯作,准备好历史封装的libc代码,再任意新增"库⽂件"。
cpp
// mystdio.h
#pragma once
#include<stdio.h>
#define MAX 1024
#define NONE_FLUSH (1<<0)
#define LINE_FLUSH (1<<1)
#define FULL_FLUSH (1<<2)
typedef struct IO_FILE
{
int fileno;
int flag;
char outbuffer[MAX];
int bufferlen;
int flush_method;
}MyFile;
MyFile* MyFopen(const char* path, const char* mode);
void MyFclose(MyFile*);
int MyFwrite(MyFile*, void* str, int len);
void MyFFlush(MyFile*);
// my_stdio.c
#include"mystdio.h"
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<string.h>
#include<stdlib.h>
#include<unistd.h>
static MyFile* BuyFile(int fd, int flag)
{
MyFile* f = (MyFile*)malloc(sizeof(MyFile));
if(f == NULL) return NULL;
f->bufferlen = 0;
f->fileno = fd;
f->flag = flag;
f->flush_method = LINE_FLUSH;
memset(f->outbuffer, 0, sizeof(f->outbuffer));
return f;
}
MyFile* MyFopen(const char* path, const char* mode)
{
int fd = -1;
int flag = 0;
if(strcmp(mode,"w") == 0)
{
flag = O_CREAT | O_WRONLY | O_TRUNC;
fd = open(path, flag, 0666);
}
else if(strcmp(mode,"a") == 0)
{
flag = O_CREAT | O_WRONLY | O_APPEND;
fd = open(path, flag, 0666);
}
else if(strcmp(mode,"r") == 0)
{
flag = O_RDWR;
fd = open(path, flag);
}
else
{
// ...
}
if(fd < 0) return NULL;
return BuyFile(fd, flag);
}
void MyFclose(MyFile* file)
{
if(file->fileno < 0) return;
MyFFlush(file);
close(file->fileno);
free(file);
}
int MyFwrite(MyFile* file, void* str, int len)
{
// 1. 拷贝
memcpy(file->outbuffer + file->bufferlen, str, len);
file->bufferlen += len;
// 2. 尝试判断是否满足刷新条件!
if((file->flush_method & LINE_FLUSH) && file->outbuffer[file->bufferlen-1] =='\n')
{
MyFFlush(file);
}
return 0;
}
void MyFFlush(MyFile* file)
{
if(file->bufferlen <= 0) return;
// 把数据从用户拷贝到内核文件缓冲区中
int n = write(file->fileno, file->outbuffer, file->bufferlen);
(void)n;
fsync(file->fileno);
file->bufferlen = 0;
}
// mystring.h
#pragma once
int my_strlen(const char* s);
// mystring.c
#include"mystring.h"
int my_strlen(const char* s)
{
const char* start = s;
while(*s)
{
s++;
}
return s - start;
}二、静态库
- 静态库(.a):程序在编译链接的时候把库的代码链接到可执⾏⽂件中,程序运⾏的时候将不再需要静态库。
- ⼀个可执⾏程序可能⽤到许多的库,这些库运⾏有的是静态库,有的是动态库,⽽我们的编译默认为动态链接库,只有在该库下找不到动态.so的时候才会采⽤同名静态库。我们也可以使⽤ gcc 的
-static强转设置链接静态库。
1、静态库⽣成
Makefile:
powershell
libmyc.a:mystdio.o mystring.o
ar -rc $@ $^ # $@ 和 $^分别指代目标文件和依赖文件
mystdio.o:mystdio.c
gcc -c $< # $< 指代依赖文件
mystring.o:mystring.c
gcc -c $<
.PHONY:output
output:
mkdir -p lib/include
mkdir -p lib/mylib
cp -f *.h lib/include
cp -f *.a lib/mylib
tar czf lib.tgz lib
.PHONY:clean
clean:
rm -rf *.o libmyc.a lib lib.tgz注意:
-
ar是gnu归档⼯具,rc表⽰replace and create -
t:列出静态库中的⽂件
-
v:详细信息
示例:

2、静态库使⽤
usercode.c:
powershell
#include"mystdio.h"
#include<string.h>
#include<unistd.h>
int main()
{
MyFile* filep = MyFopen("./log.txt","a");
if(!filep)
{
printf("fopen error!\n");
return 1;
}
int cnt = 10;
while(cnt--)
{
char* msg = (char*)"hello myfile!";
MyFwrite(filep, msg, strlen(msg));
MyFFlush(filep);
printf("buffer: %s\n", filep->outbuffer);
sleep(1);
}
MyFclose(filep);
return 0;
}场景1:头⽂件和库⽂件安装到系统路径下
powershell
gcc usercode.c -o usercode -lmyc场景2:头⽂件和库⽂件和我们⾃⼰的源⽂件在同⼀个路径下
powershell
gcc usercode.c -o usercode -L. -lmyc场景3:头⽂件和库⽂件有⾃⼰的独⽴路径
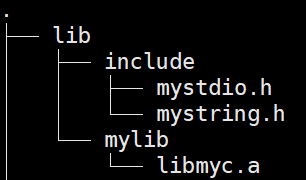
powershell
gcc usercode.c -o usercode -I lib/include -L lib/mylib -lmyc-I:指定头⽂件搜索路径-L:指定库路径-l:指定库名
注意:
- 测试⽬标⽂件⽣成后,静态库删掉,程序照样可以运⾏。
- 库⽂件名称和引⼊库的名称:去掉前缀
lib,去掉后缀.so,.a,如:libc.so,c就是这个动态库的名称。
三、动态库
-
动态库(.so):程序在运⾏的时候才去链接动态库的代码,多个程序共享使⽤库的代码。
-
⼀个与动态库链接的可执⾏⽂件仅仅包含它⽤到的函数⼊⼝地址的⼀个表,⽽不是外部函数所在⽬标⽂件的整个机器码。
-
在可执⾏⽂件开始运⾏以前,外部函数的机器码由操作系统从磁盘上的该动态库中复制到内存中,这个过程称为动态链接(dynamic linking)。
-
动态库可以在多个程序间共享,所以动态链接使得可执⾏⽂件更⼩,节省了磁盘空间。操作系统采⽤虚拟内存机制允许物理内存中的⼀份动态库被要⽤到该库的所有进程共⽤,节省了内存和磁盘空间。
1、动态库⽣成
Makefile:
powershell
libmyc.so:mystdio.o mystring.o
gcc -shared -o $@ $^
mystdio.o:mystdio.c
gcc -fPIC -c $<
mystring.o:mystring.c
gcc -fPIC -c $<
.PHONY:output
output:
mkdir -p lib/include
mkdir -p lib/mylib
cp -f *.h lib/include
cp -f *.so lib/mylib
tar czf lib.tgz lib
.PHONY:clean
clean:
rm -rf *.o libmyc.so lib lib.tgz注意:
shared:表⽰⽣成共享库格式fPIC:产⽣位置⽆关码(position independent code)
2、动态库使⽤
场景1:头⽂件和库⽂件安装到系统路径下
powershell
gcc usercode.c -o usercode -lmyc场景2:头⽂件和库⽂件和我们⾃⼰的源⽂件在同⼀个路径下
powershell
gcc usercode.c -o usercode -L. -lmyc场景3:头⽂件和库⽂件有⾃⼰的独⽴路径
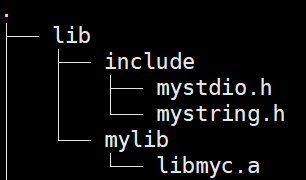
powershell
gcc usercode.c -o usercode -I lib/include -L lib/mylib -lmyc3、库运⾏搜索路径
1)问题
当我们将库拷贝到一个用户下,解压缩后:

运行程序时系统提示找不到库!
此时查看可执⾏程序的库依赖:ldd usercode

我们可以看到,libmyc.so没有显示对应的搜索路径,这说明当前系统的动态库搜索路径里没有包含这个库所在的目录。
2)解决⽅案
1. 拷⻉ .so ⽂件到系统共享库路径下
powershell
sudo cp lib/mylib/libmyc.so /lib64

2. 向系统共享库路径下建⽴同名软链接
powershell
sudo ln -s /home/zsy/code/linux/test_12_16/zsy/lib/mylib/libmyc.so /lib64/libmyc.so

3. 导入环境变量: LD_LIBRARY_PATH
powershell
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/home/zsy/code/linux/test_12_16/zsy/lib/mylib
但是存在一个问题,就是该环境变量无法保存,所以每次重新启动,该环境变量就会清空。
要想让环境变量永久生效,就要将其写入环境变量的配置文件~/.bashrc中。
步骤 1:编辑配置文件
powershell
vim ~/.bashrc步骤 2:添加环境变量配置
powershell
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/home/zsy/code/linux/test_12_16/zsy/lib/mylib步骤 3:让配置立即生效
powershell
source ~/.bashrc4. ldconfig⽅案:配置/etc/ld.so.conf.d/
步骤1:在这个目录下新建一个文件
powershell
sudo touch /etc/ld.so.conf.d/zsy.conf步骤2:写入动态库的目录路径
powershell
/home/zsy/code/linux/test_12_16/zsy/lib/mylib/步骤3:刷新缓存
powershell
sudo ldconfig
四、使⽤外部库
我们现在没接触过太多的库,唯⼀接触过的就是C、C++标准库,这⾥我们可以推荐⼀个好玩的图形库:ncurses
安装ncurses库:sudo yum install -y ncurses-devel
系统中其实有很多库,它们通常由⼀组互相关联的⽤来完成某项常⻅⼯作的函数构成。⽐如⽤来处理屏幕显⽰情况的函数(ncurses库)
cpp
// win.c
#include<stdio.h>
#include<string.h>
#include<ncurses.h>
#include<unistd.h>
#define PROGRESS_BAR_WIDTH 30
#define BORDER_PADDING 2
#define WINDOW_WIDTH (PROGRESS_BAR_WIDTH + 2 * BORDER_PADDING + 2) // 加边框的宽度
#define WINDOW_HEIGHT 5
#define PROGRESS_INCREMENT 3
#define DELAY 300000 // 微秒(300毫秒)
int main()
{
initscr();
start_color();
init_pair(1, COLOR_GREEN, COLOR_BLACK); // 已完成部分:绿色前景,黑色背景
init_pair(2, COLOR_RED, COLOR_BLACK); // 剩余部分(虽然用红色可能不太合适,但为演示目的):红色背景
cbreak();
noecho();
curs_set(FALSE);
int max_y, max_x;
getmaxyx(stdscr, max_y, max_x);
int start_y = (max_y - WINDOW_HEIGHT) / 2;
int start_x = (max_x - WINDOW_WIDTH) / 2;
WINDOW* win = newwin(WINDOW_HEIGHT, WINDOW_WIDTH, start_y, start_x);
box(win, 0, 0); // 加边框
wrefresh(win);
int progress = 0;
int max_progress = PROGRESS_BAR_WIDTH;
while (progress <= max_progress)
{
werase(win); // 清除窗口内容
// 计算已完成的进度和剩余的进度
int completed = progress;
int remaining = max_progress - progress;
// 显示进度条
int bar_x = BORDER_PADDING + 1; // 进度条在窗口中的x坐标
int bar_y = 1; // 进度条在窗口中的y坐标(居中)
// 已完成部分
attron(COLOR_PAIR(1));
for (int i = 0; i < completed; i++) {
mvwprintw(win, bar_y, bar_x + i, "#");
}
attroff(COLOR_PAIR(1));
// 剩余部分(用背景色填充)
attron(A_BOLD | COLOR_PAIR(2)); // 加粗并设置背景色为红色(仅用于演示)
for (int i = completed; i < max_progress; i++)
{
mvwprintw(win, bar_y, bar_x + i, " ");
}
attroff(A_BOLD | COLOR_PAIR(2));
// 显示百分比
char percent_str[10];
snprintf(percent_str, sizeof(percent_str), "%d%%", (progress * 100) / max_progress);
int percent_x = (WINDOW_WIDTH - strlen(percent_str)) / 2; // 居中显示
mvwprintw(win, WINDOW_HEIGHT - 1, percent_x, percent_str);
wrefresh(win); // 刷新窗口以显示更新
// 增加进度
progress += PROGRESS_INCREMENT;
// 延迟一段时间
usleep(DELAY);
}
// 清理并退出ncurses模式
delwin(win);
endwin();
return 0;
}编译链接:
powershell
gcc win.c -o win -std=c99 -lncurses运行结果:

五、⽬标⽂件
编译和链接这两个步骤,在Windows下被我们的IDE封装的很完美,我们⼀般都是⼀键构建⾮常⽅便,但⼀旦遇到错误的时候呢,尤其是链接相关的错误,很多⼈就束⼿⽆策了。在Linux下,我们学过如何通过gcc编译器来完成这⼀系列操作。
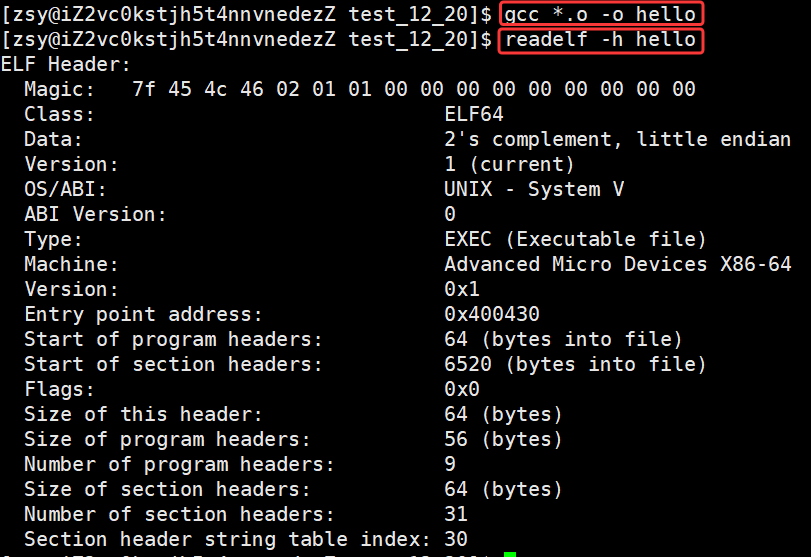
接下来我们深⼊探讨⼀下编译和链接的整个过程,来更好的理解动静态库的使⽤原理。
先来回顾下什么是编译呢?编译的过程其实就是将我们程序的源代码翻译成CPU能够直接运⾏的机器代码。
⽐如:在⼀个源⽂件 hello.c ⾥便简单输出"hello world!",并且调⽤⼀个run函数,⽽这个函数被定义在另⼀个原⽂件 code.c 中。这⾥我们就可以调⽤ gcc -c 来分别编译这两个原⽂件。
cpp
// hello.c
#include<stdio.h>
void run();
int main()
{
printf("hello world!\n");
run();
return 0;
}
// code.c
#include<stdio.h>
void run()
{
printf("running...\n");
}编译两个源⽂件
powershell
gcc -c hello.c
gcc -c code.c
可以看到,在编译之后会⽣成两个扩展名为 .o 的⽂件,它们被称作⽬标⽂件。要注意的是如果我们修改了⼀个原⽂件,那么只需要单独编译它这⼀个,⽽不需要浪费时间重新编译整个⼯程。⽬标⽂件是⼀个⼆进制的⽂件,⽂件的格式是 ELF ,是对⼆进制代码的⼀种封装。
file命令用于辨识⽂件类型

六、ELF⽂件
要理解编译链接的细节,我们不得不了解⼀下ELF⽂件。以下四种⽂件其实都是ELF⽂件:
-
可重定位⽂件(Relocatable File) :即 xxx.o ⽂件。包含适合于与其他⽬标⽂件链接来创建可执⾏⽂件或者共享⽬标⽂件的代码和数据。
-
可执⾏⽂件(Executable File) :即可执⾏程序。
-
共享⽬标⽂件(Shared Object File) :即 xxx.so⽂件。
-
内核转储文件(core dumps) :存放当前进程的执⾏上下⽂,⽤于dump信号触发。
⼀个ELF⽂件由以下四部分组成:
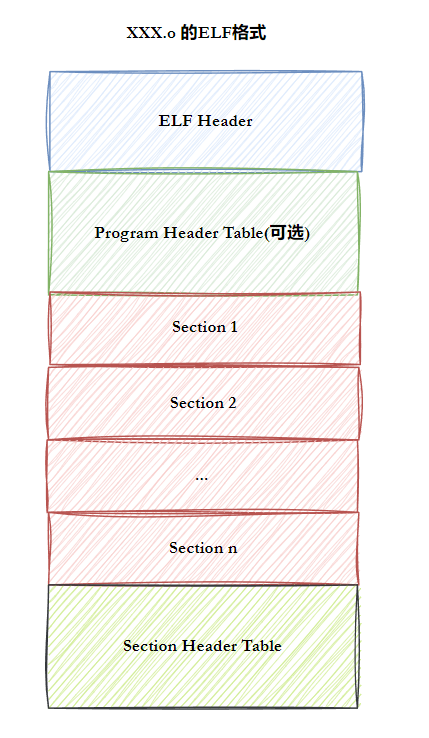
-
ELF头(ELF header) :描述⽂件的主要特性。其位于⽂件的开始位置,它的主要⽬的是定位⽂件的其他部分。
-
程序头表(Program header table) :列举了所有有效的段(segments)和他们的属性。表⾥记着每个段的开始的位置和位移(offset)、⻓度,毕竟这些段,都是紧密的放在⼆进制⽂件中,需要段表的描述信息,才能把他们每个段分割开。
-
节头表(Section header table) :包含对节(sections)的描述。
-
节(Section ):ELF⽂件中的基本组成单位,包含了特定类型的数据。ELF⽂件的各种信息和数据都存储在不同的节中,如代码节存储了可执⾏代码,数据节存储了全局变量和静态数据等。
最常⻅的节:
- 代码节(.text):⽤于保存机器指令,是程序的主要执⾏部分。
- 数据节(.data):保存已初始化的全局变量和局部静态变量。
七、ELF从形成到加载
1、ELF形成可执⾏
-
步骤1:将多份
C/C++源代码,翻译成为⽬标.o⽂件 -
步骤2:将多份
.o⽂件section进⾏合并
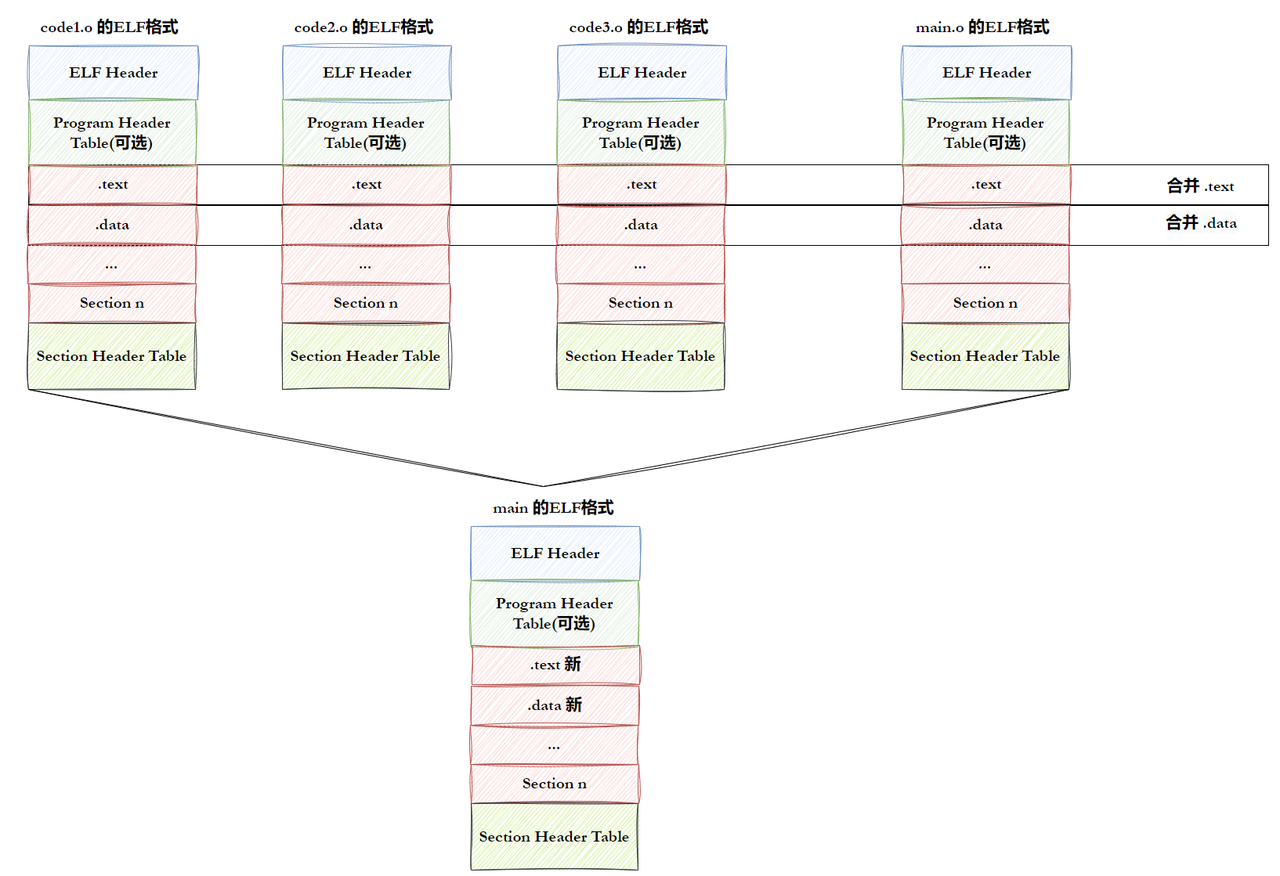
注意:
实际合并是在链接时进⾏的,但是并不是这么简单的合并,也会涉及对库合并。
2、ELF可执⾏⽂件加载
-
⼀个ELF会有多种不同的Section,在加载到内存的时候,也会进⾏Section合并,形成segment。
-
合并原则:相同属性,⽐如:可读,可写,可执⾏,需要加载时申请空间等
-
这样,即便是不同的Section,在加载到内存中,也可能会以segment的形式,加载到⼀起
-
很显然,这个合并⼯作也已经在形成ELF的时候,合并⽅式就已经确定了,具体合并原则被记录在了ELF的程序头表中
查看可执⾏程序的section:
powershell
readelf -S /usr/bin/ls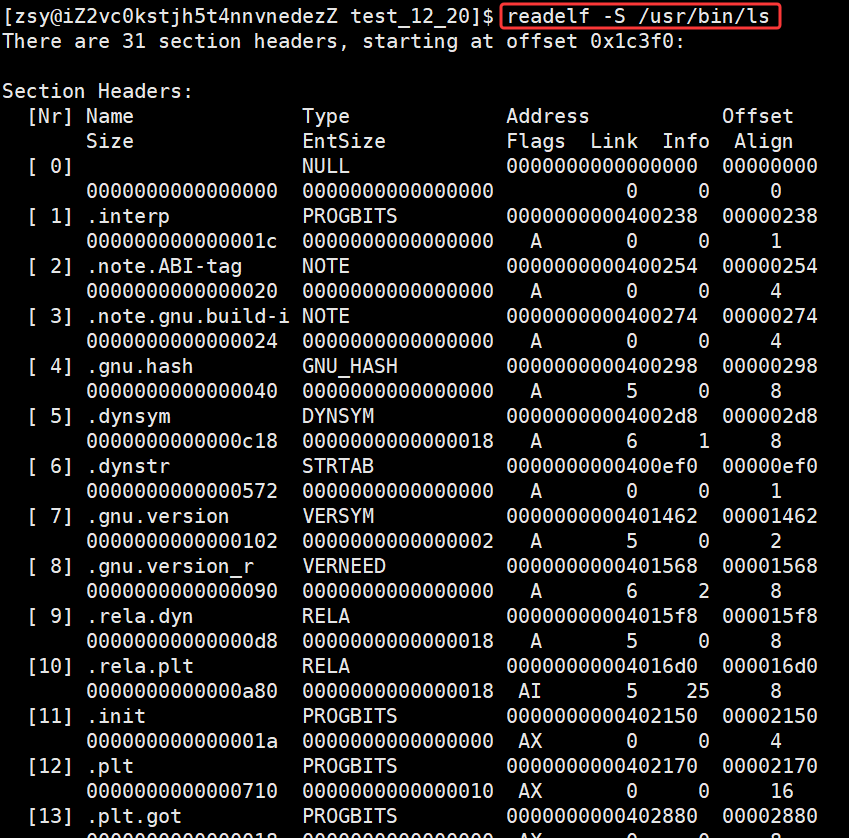
查看section合并的segment:
powershell
readelf -l /usr/bin/ls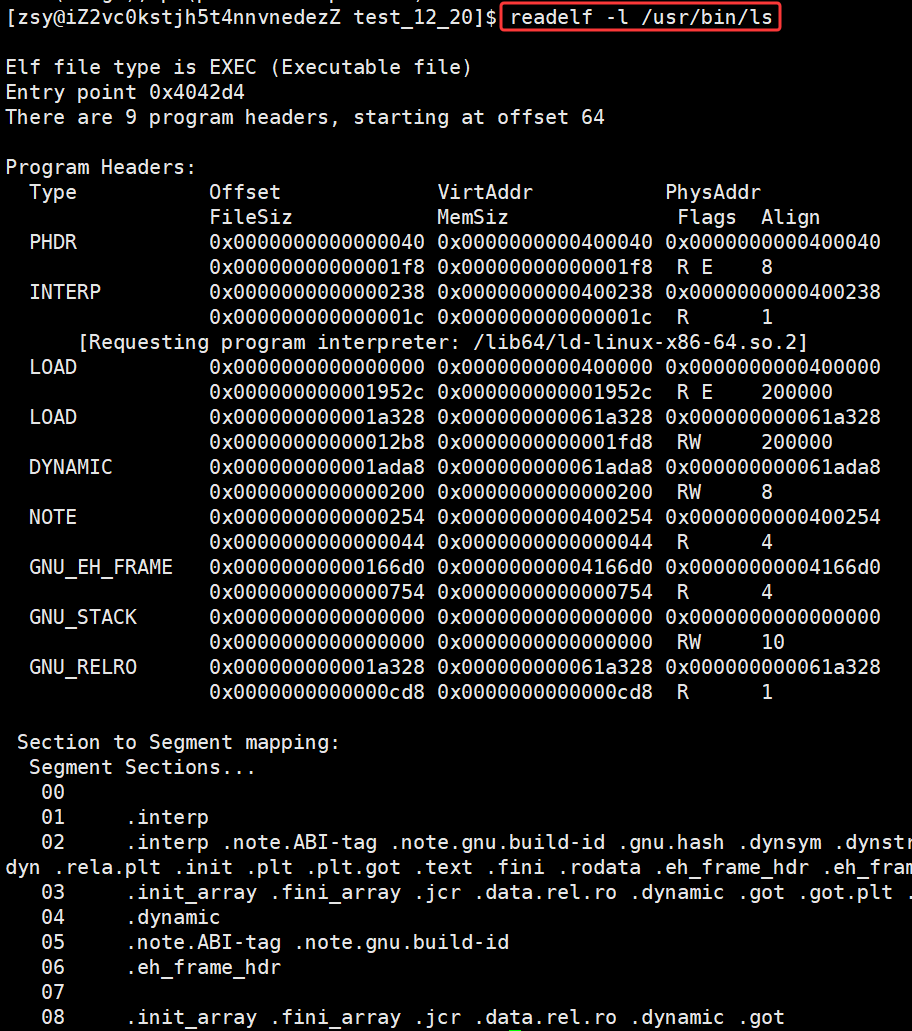 为什么要将section合并成为segment ?
为什么要将section合并成为segment ?
- Section合并的主要原因是为了减少⻚⾯碎⽚,提⾼内存使⽤效率。如果不进⾏合并,假设⻚⾯⼤⼩为4096字节(内存块基本⼤⼩,加载,管理的基本单位),如果.text部分为4097字节,.init部分为512字节,那么它们将占⽤3个⻚⾯,⽽合并后,它们只需2个⻚⾯。
- 此外,操作系统在加载程序时,会将具有相同属性的section合并成⼀个⼤的segment,这样就可以实现不同的访问权限,从⽽优化内存管理和权限访问控制。
那么 程序头表 和 节头表 ⼜有什么⽤呢,其实 ELF ⽂件提供 2 个不同的视图/视⻆来让我们理解这两个部分:
-
链接视图(Linking view) - 对应节头表(Section header table)
- ⽂件结构的粒度更细,将⽂件按功能模块的差异进⾏划分,静态链接分析的时候⼀般关注的是链接视图,能够理解 ELF ⽂件中包含的各个部分的信息。
- 为了空间布局上的效率,将来在链接⽬标⽂件时,链接器会把很多节(section)合并,规整成可执⾏的段(segment)、可读写的段、只读段等。合并了后,空间利⽤率就⾼了,否则,很⼩的很⼩的⼀段,未来物理内存⻚浪费太⼤(物理内存⻚分配⼀般都是整数倍⼀块给你,⽐如4k),所以,链接器趁着链接就把⼩块们都合并了。
-
执⾏视图(execution view) - 对应程序头表(Program header table)
- 告诉操作系统,如何加载可执⾏⽂件,完成进程内存的初始化。⼀个可执⾏程序的格式中,⼀定有程序头表。
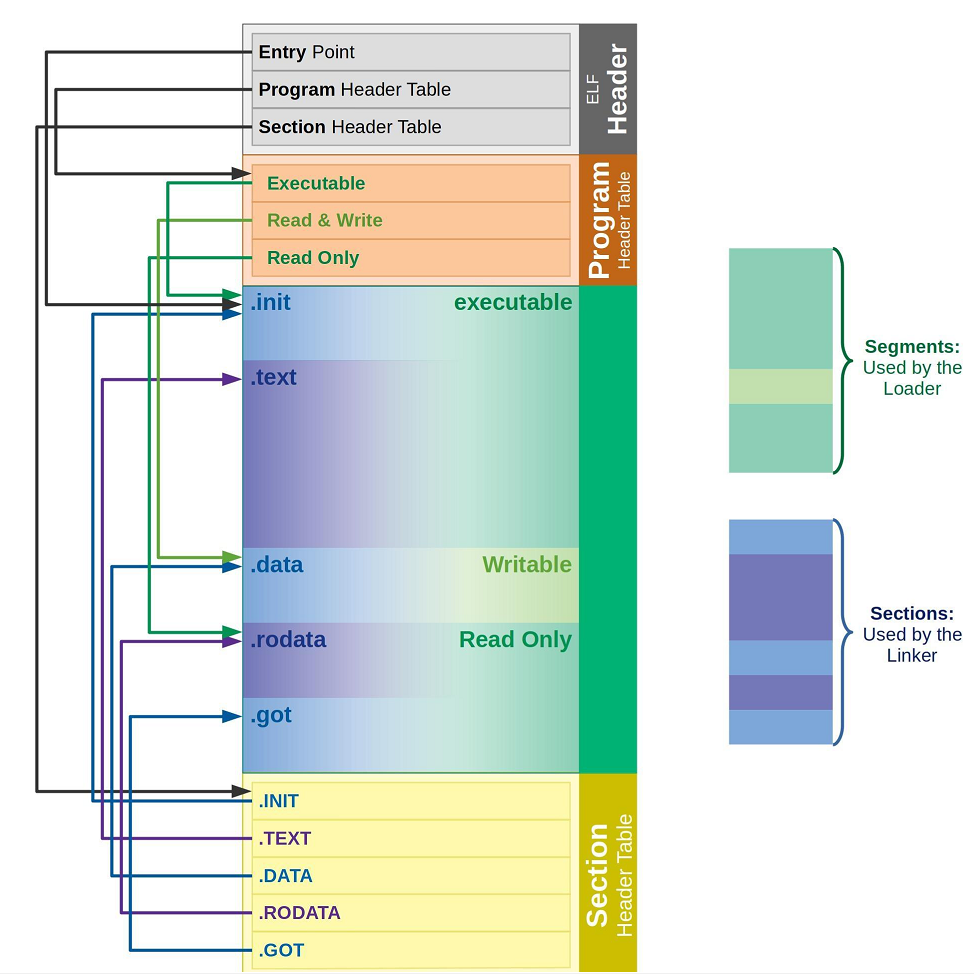
从链接视图来看:
命令 readelf -S hello.o 可以帮助查看ELF⽂件的节头表 。
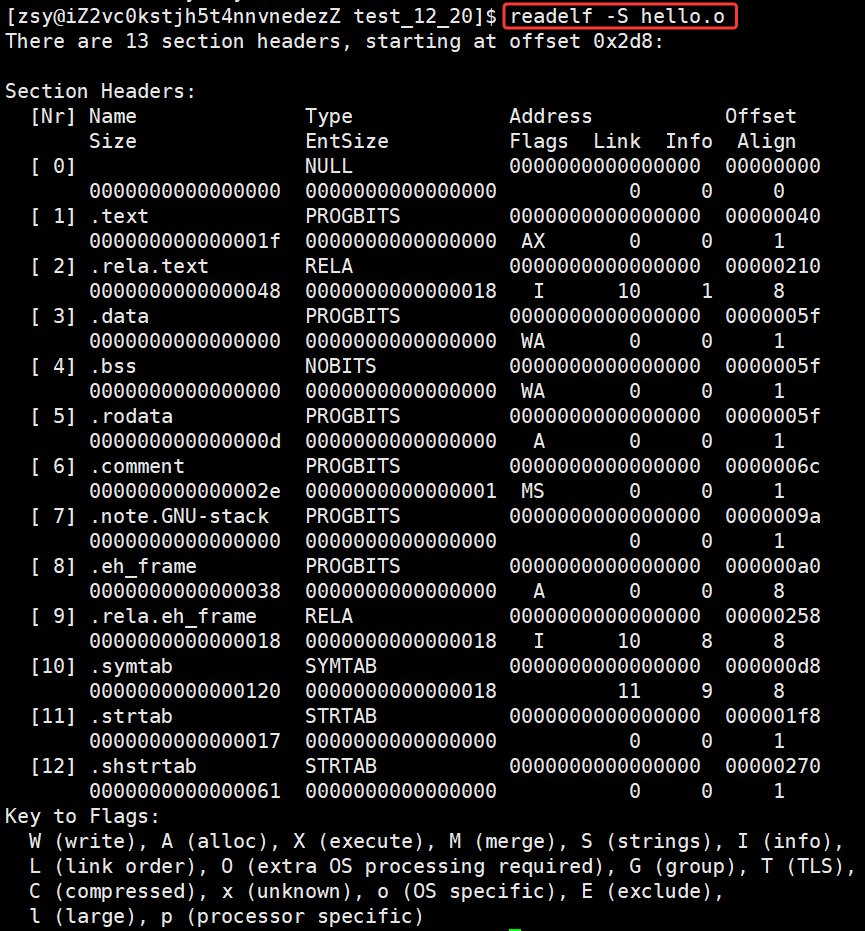
-
.text节 :保存了程序代码指令的代码节。
-
.data节 :保存了初始化的全局变量和局部静态变量等数据。
-
.rodata节 :保存了只读的数据,如⼀⾏C语⾔代码中的字符串。由于.rodata节是只读的,所以只能存在于⼀个可执⾏⽂件的只读段中。因此,只能是在text段(不是data段)中找到
.rodata节。 -
.BSS节 :为未初始化的全局变量和局部静态变量预留位置。
-
.symtab节:Symbol Table 符号表,就是源码中函数名、变量名和代码的对应关系。
-
.got.plt节 (全局偏移表-过程链接表):
.got节保存了全局偏移表。.got节和.plt节⼀起提供了对导⼊的共享库函数的访问⼊⼝,由动态链接器在运⾏时进⾏修改。使⽤readelf命令查看.so⽂件可以看到该节。
从执⾏视图来看:
- 告诉操作系统哪些模块可以被加载进内存。
- 加载进内存之后哪些分段是可读可写,哪些分段是只读,哪些分段是可执⾏的。
我们可以在ELF头 中找到⽂件的基本信息,以及可以看到ELF头 是如何定位程序头表 和节头表的。
例如我们查看下hello.o这个可重定位⽂件的节头表:
powershell
readelf -h hello.o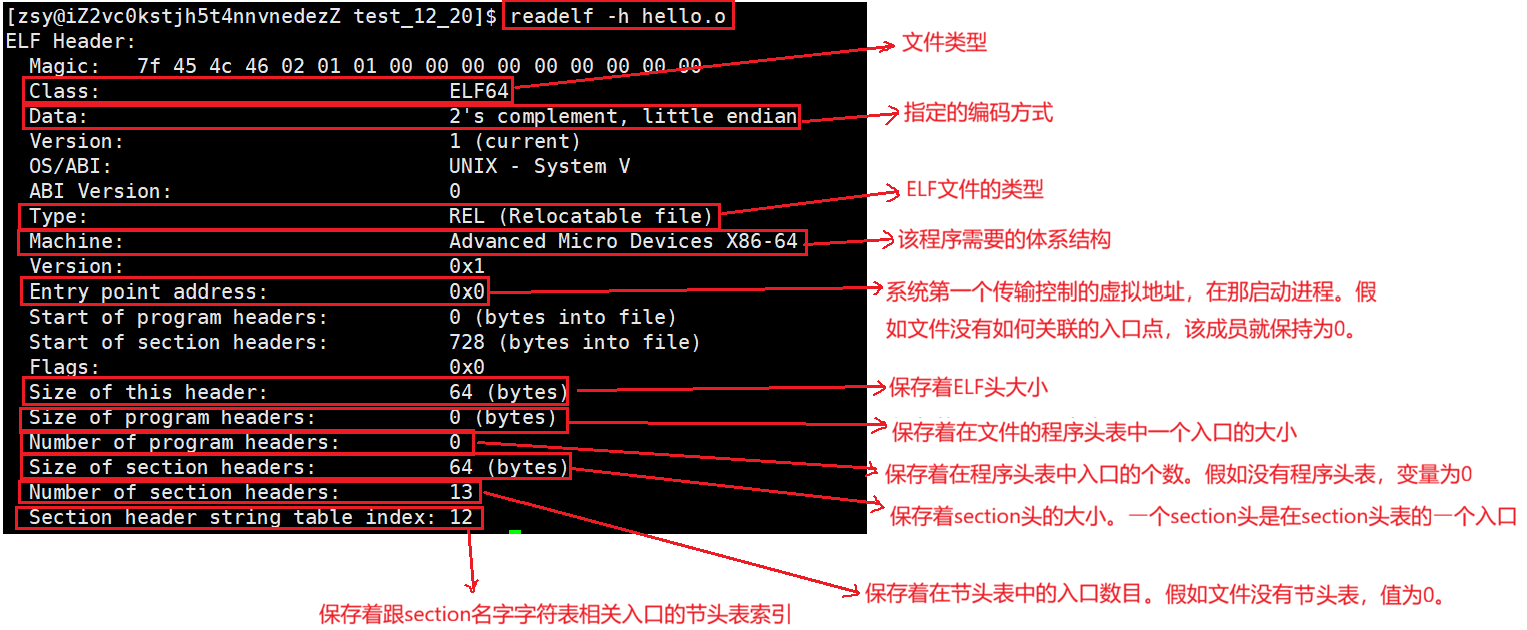
查看可执⾏程序hello的节头表:
powershell
readelf -h hello