本文来源:k学长的深度学习宝库,点击查看源码&详细教程。深度学习,从入门到进阶,你想要的,都在这里。包含学习专栏、视频课程、论文源码、实战项目、云盘资源等。

1、Monodepth 的背景和动机
1.1、背景
在计算机视觉里,"深度"(Depth)指的是场景中物体距离相机的远近。 想象你用手机拍一张街景照片:虽然照片是二维的,但我们人类能直观感受到哪些车更近、哪些建筑更远。这是因为我们的大脑利用了各种视觉线索,比如 大小对比(远处车看起来更小)、遮挡关系(近处的东西挡住远处)、阴影和光照等。
对于机器来说,理解深度也非常重要,特别是在以下场景中:
自动驾驶:汽车要知道行人、车辆与自己的距离;
机器人:机械臂需要估计物体深度来完成抓取;
AR/VR:虚拟物体需要准确插入现实世界场景中;
1.2、传统做法的挑战
历史上,获取深度的方法主要有两类:
硬件测量:比如用激光雷达(LiDAR)直接打点测距。 缺点是昂贵、笨重,并且在复杂场景下精度有限。
多视角方法:比如用双目相机(像人眼)或者多张不同角度的照片,通过几何计算得到深度。
用一个通俗的比喻来解释"双目相机/多视角几何计算得到深度"的过程
为什么需要两只眼睛?
想象一下你用一只眼睛看世界,东西是"平"的,很难判断远近。打开两只眼睛,你就能感受到深度。这是因为左右眼看到的画面略有差别(比如近处的物体在左眼画面里偏左,在右眼画面里偏右)。
核心原理:视差
这种左右画面的差别叫 "视差"。 举个例子:
把手指放在眼前,然后左右眼轮流闭眼。你会发现手指相对背景位置"跳来跳去"。
跳动的大小就是视差。越近的物体跳得越厉害,越远的物体几乎不跳。
所以,物体的距离可以通过视差来推算。
几何计算的过程(通俗版)
用相机来说就是:
已知:两台相机的相对位置("基线长度",就像两只眼睛之间的距离)。
拍摄:得到两张略有差别的照片。
找点:在两张照片里,找到同一个物体上的点(比如同一只小猫的鼻子)。
测视差:看这个点在左图和右图里的水平位置差了多少。
套公式:根据三角形几何关系,用公式算出深度(距离相机多远)。
但这需要 多台相机 或者 视频序列,而且必须校准严格。
在深度学习兴起后,有人尝试直接训练神经网络,从单张图像里预测深度。但这类方法通常需要 大量真实的深度标注数据(图像+精确的深度值),而这些数据获取起来极为困难。 比如要训练一个自动驾驶模型,需要为成千上万张街景图片提供精确的像素级深度信息,这在现实中几乎不可行。
1.3、Monodepth 的动机
作者提出了一个新想法:
能不能只用普通的双目相机拍摄的左右图像,而不需要昂贵的激光雷达深度标注,就让模型学会预测单张图像的深度?
关键点在于:
从左图生成右图(或者反过来)其实本质上就是"图像重建"问题;
如果模型能成功做到这一点,说明它学会了图像里"远近关系"的规律,也就是深度。
当说"从左图生成右图(或反过来)是图像重建"时,意思是:
如果模型只看了一张眼睛的图(比如左眼),就能把另一只眼睛应该看到的图(右眼)画出来。
这等于它在脑子里"重建"了场景的三维结构。
为什么这说明模型学会了深度?
因为要把左眼图变成右眼图,它必须知道:
哪些物体离得近(要偏移很多)
哪些物体离得远(偏移很少)
这正是 远近关系/深度 的规律。 所以,如果模型能做到双目图的互相生成,就说明它已经"看懂了深度"。
👉 用更简单的比喻:
就像你闭上一只眼睛,如果你能凭经验想象另一只眼睛看到的画面,说明你其实已经理解了物体在空间里的远近位置。
因此,Monodepth 的核心动机就是: 👉 把深度预测转化为图像重建问题,用双目图像训练,让模型学会单目深度估计,而无需真实深度标注。
1.4、打个形象的比喻
你可以把 Monodepth 想象成一个 "学画" 的过程:
老师给它看一张左眼拍的照片(左图),要求它凭想象画出右眼应该看到的画面(右图)。
如果它画得像模像样,说明它理解了哪些东西近、哪些远。
久而久之,它学会了在只看一张图时,也能脑补出场景的三维结构。
这就是 Monodepth 想要解决的核心问题: 让机器像人一样,从单眼图像里"看出"立体感。
1.5、Monodepth 的核心思想
Monodepth 的关键点就是: 利用双目相机的左右图像,把"深度估计"转化为"图像重建"问题。
具体来说:
输入:一张左图像(或者右图像);
预测:模型输出这张图的每个像素的"视差图"(disparity map);
视差可以理解为"两个眼睛看到的同一个点的水平偏移量";
视差和深度成反比:物体越近,偏移越大;物体越远,偏移越小。
重建:通过预测的视差,把左图"挪动"一下,生成右图;或者反过来。
监督:拿生成的图像和真实的右图(相机拍的)比较,差异越小,说明模型越好。
👉 总结一下:模型通过图像重建的准确性,来间接学习深度信息,而完全不需要激光雷达的深度标注。
2、Monodepth 的最大创新点
1、如果要用一句话概括:
Monodepth 最大的创新点,就是把"单目深度估计"转化为一个"无监督的图像重建问题",并引入左右一致性约束来提升几何精度。
左右一致性约束是啥?
单靠上面的"图像重建"可能会有歧义:
某些纹理少或重复的地方(比如白墙、天空),网络可能随便预测一个深度,也能凑合把图像对齐。
这样得到的深度会很不稳定。
所以作者引入了一个额外的约束:
既然我能从 左图预测深度(得到左→右的视差),
也能从 右图预测深度(得到右→左的视差),
那么这两个视差应该是互相一致的。
举个例子:
假设左图里某个像素通过预测视差,落在右图的某个位置。
那么从右图预测的视差,再"跳回"左图时,应该能回到原来的位置。
如果跳不回去,就说明预测的深度不合理。
这就是 左右一致性约束(Left-Right Consistency Constraint)。
2、三种策略
你站在马路边,用 左眼 和 右眼 各拍了一张照片。现在你的任务是: 👉 只给 AI 一张照片(比如左眼图),让它学会"补出另一只眼睛看到的画面"。
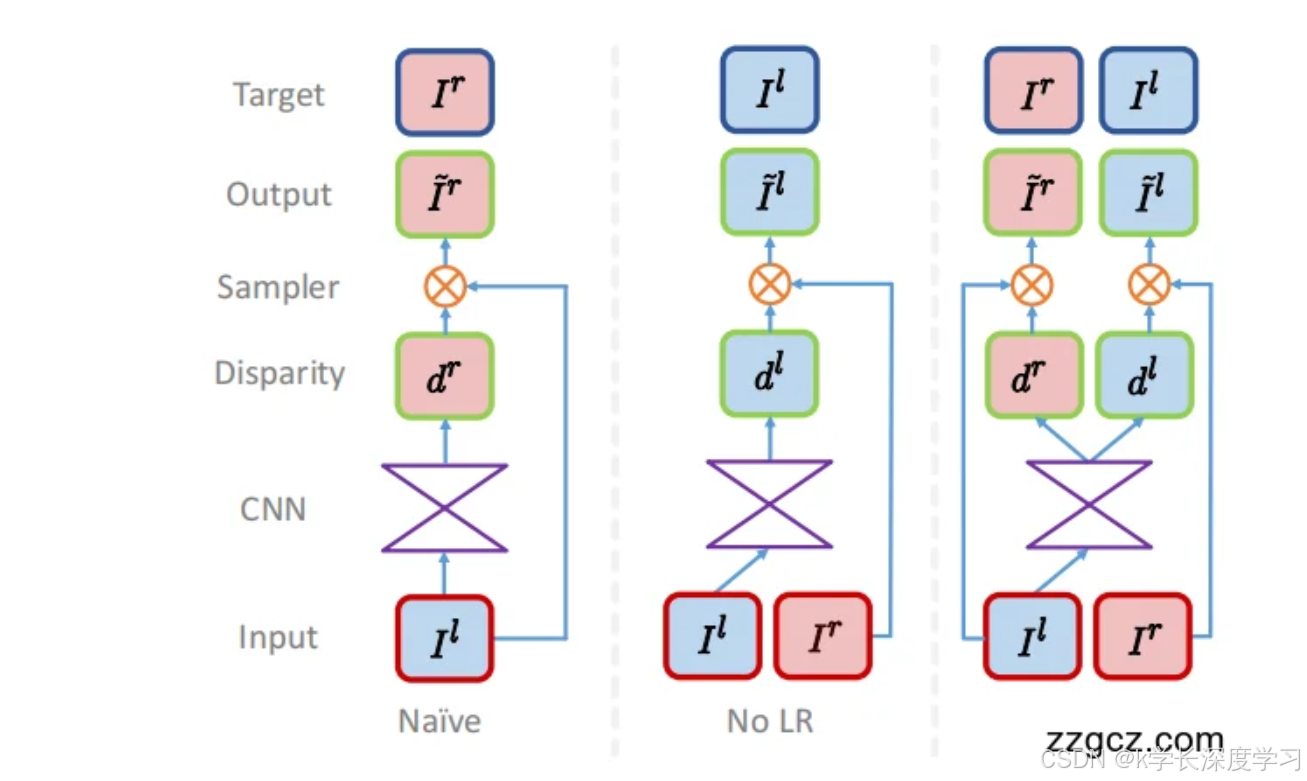
这个过程中就有三种策略(对应图里的三列):
image.png
图中共同元素先认一下
Input:底部红/蓝框,分别是左图 Il与右图 Ir(双目相机拍的一对校正图像)。
CNN:紫色"沙漏",输入图像经编码器-解码器得到视差图(绿色框 d)。视差越大表示物体越近。
Sampler:橙色带 ⊗ 的模块,是双线性采样器(来自 STN),用"视差"去从源图采样来生成目标图,形成可微的反向映射(backward warping)。
Output / Target:输出是重建的图 I~,与真实的目标图 I 做外观匹配损失(像素 L1 + SSIM);还会加视差平滑损失与(如果有)左右一致性损失
Naïve(天真的方法)
做法:AI 看左眼照片,直接尝试画出右眼的样子。
问题:它画出来的右眼图看上去还行,但其实它心里想的是"右眼坐标系",跟左眼输入没完全对齐。
形象比喻:就像一个学生照着别人的画来临摹,但没对准纸,画偏了,位置坐标全乱了。
后果:AI 在训练时好像表现不错,但一旦只给它一只眼(左图)去预测深度,就会乱套,没法直接用。
No LR(没有左右一致性)
做法:这次换个角度,AI 不再直接画右眼,而是用左眼图去推测深度,再从右眼图里"拼"出左眼。
优点:这样学到的结果至少和左眼输入对齐了(坐标对上了)。
问题:但 AI 有时候会"投机取巧"------比如马路边有个柱子,右眼其实看不到后面的墙,它还是硬生生把纹理"抹上去",导致画面出现拉花或鬼影。
形象比喻:学生画画时不会的地方就"瞎补",结果边界模糊、图像歪掉。
Ours(论文的方法)
做法:论文的方法最聪明:
AI 只看左眼照片,但它一次性要画出两份深度------既要能合成右眼画面,也要能合成回左眼画面。
左右两份预测还要互相对照,必须匹配上,否则会被惩罚。
优点:这样一来,AI 不光要让画看起来像,还要保证左右两张画在空间上对得上。
形象比喻:就像画立体画的学生,老师要求:
"你得同时画出左眼和右眼的透视图";
"而且这两张画必须对得上号"。 这样学生就不能再瞎蒙,而是必须真正理解物体的远近关系。
总结一句话
Naïve:图像坐标对不上,预测不能用。
No LR:坐标对上了,但容易瞎补出错。
Ours:双眼互相监督,既对齐又一致,学到真正的立体几何。
3、Monodepth 的网络结构与损失函数设计
- 编码器(左边绿色方块) → 相当于眼睛的大脑前端
输入:一张单目照片(左眼图像或者右眼图像)。
功能:就像人类大脑的"初级视觉皮层",把照片里的各种边缘、颜色、纹理等特征提取出来。
输出:一个大"特征图",大小是 H × W × D。
H、W → 图像的高和宽(但可能被缩小过)。
D → 特征维度,表示每个像素位置上提取了多少"特征描述"(比如 64 种特征)。
👉 通俗理解:编码器把一张照片,变成了"包含很多隐藏信息的特征版照片"。 - 解码器(中间紫色方块们) → 相当于大脑在猜"物体有多远"
功能:接收编码器提取的特征,再一步步"还原"空间细节。
输出:预测的 视差图(disparity map)。
紫色方块就是解码器预测的结果:
dˡ:左图的视差
dʳ:右图的视差
👉 通俗理解:解码器就像是在看照片后,尝试给每个像素点一个"远近标签"(近的视差大,远的视差小)。
👉 为什么要同时预测左和右?
因为这样才能互相对照,保证预测合理(这就是"左右一致性约束"的基础)。 - 重建与监督(右边彩色部分) → 相当于自我检查:我预测的远近对不对?
橙色方块:采样 / 重建模块。
原理:把预测的视差当作"桥",去另一张图像里找对应像素,并"重建"出目标图。
工具:这里用的是 双线性采样器(Sampler, 来自 STN),它能平滑地采样,并且过程是"可微"的(这样误差能反传回去训练)。
彩色部分的输出:
生成的"重建图" Ĩ(网络预测出来的)。
与真实图 I 对比,计算损失(误差),包括:
外观匹配损失 (L1 + SSIM) → 看图像重建得像不像。
视差平滑损失 → 让深度预测不要乱跳。
左右一致性损失 → 保证 dˡ 和 dʳ 的预测对得上。
👉 通俗理解:
网络先猜"物体远近",再用这个猜测去"拼出另一只眼睛的画面"。
如果拼得像,就说明猜得对;如果拼得不像,网络就要调整自己。
4、外观匹配损失 Cap
图的左上角标注了三种关键损失函数,每种损失对应一种直觉约束:
直觉:合成的图要和真实图"看起来一样"。
image.png
实现方式:用像素差 (L1) + 结构相似度指标 (SSIM)。
L1 损失(像素差)
含义:就是 逐像素对比两张图的亮度差异。
公式上:L1 = |I_real − I_recon|
举例:
如果真实图某个像素亮度是 100,重建图预测出来是 90,那误差就是 10。
这种误差会被累积起来,形成整体的 L1 损失。
👉 直观理解:L1 就像"对位对表",看每个像素值差多少。它要求重建图和原图在颜色上尽量接近。
SSIM(结构相似度指标, Structural Similarity Index)
含义:不是单纯看像素差,而是从更高层次的结构、对比度、纹理来比较两张图。
范围:0 ~ 1,越接近 1 说明越相似。
优势:
有些地方亮度稍有偏差,但整体的边缘、形状还在,这时候 L1 可能给出很大惩罚,而 SSIM 能"容忍"这种小偏差。
它更关注"这两张图的结构是不是一致"。
👉 直观理解:SSIM 更像人眼在判断两张图片是不是"看起来一样",而不是死板逐像素比较。
为什么要 L1 + SSIM 一起用?
L1:保证像素级别的准确。
SSIM:保证整体结构和感知效果。
两者结合,既严格要求像素相近,又能确保图像结构不跑偏。
👉 就像老师批改作业:
L1 是逐字对答案(扣字面分)。
SSIM 是看整体意思对不对(结构合理分)。
两者结合才能全面反映"像不像"。
5、视差平滑损失 Cds
如果你看一张真实的深度图,大部分区域(比如墙面、地面、天空)都是 连续、平滑 的,不会出现"一个像素远、下一个像素突然很近"的跳跃。
所以 Monodepth 在训练时加了个 平滑约束:希望预测的视差图在相邻像素之间变化要小。
👉 就像画地形图:
正常情况 → 像山坡,缓慢变化。
特殊情况 → 碰到"悬崖"(物体边界),可以突然变化。
image.png
为什么要乘上 e−∣∂I∣?
直接要求"所有地方都平滑"会出问题:物体边界本来就该突变,但你硬要拉平,会导致边缘模糊。
所以用图像梯度作为"参考":
图像没边界 → 强约束(要平滑)。
图像有边界 → 弱约束(允许突变)。
👉 就像"山坡 vs 悬崖":
草地上要平滑过渡。
悬崖边缘允许突然掉下去。
视差平滑损失就是: 惩罚相邻像素视差差异,但在图像边缘处放宽要求。 这样网络预测出来的深度图既平滑,又能在物体边界处保持清晰。
6、 左右一致性损失 Clr
👉 左右一致性损失,就是让网络"自己和自己对话",保证左右预测的结果能对上。
image.png
- 直觉出发
人眼看东西:左眼和右眼看到的画面虽然有差异,但它们对同一个物体的远近判断是一致的。
如果左眼说"这只猫离我 2 米",右眼却说"离我 5 米",显然就不合理。
👉 所以 Monodepth 强调:左视差图和右视差图要一致,否则深度预测就不符合几何规律。 - 公式怎么做?
假设:
左图预测的视差是 d^l,右图预测的视差是 d^rr。
从左图某个像素 (i,j)出发,加上视差 di,jl,能定位到右图的一个像素位置。
那么:
在这个对应位置上,右图的预测视差 dr 应该能"跳回"到左图的原位置。
如果跳不回来,就说明两边预测不一致,要惩罚。
7、流程串联(结合图)
按照图片流程串起来,就是:
输入左图 → 编码器提取特征。
解码器预测视差 dl和 dr。
用预测的视差,把左图合成右图 (I~r),用右图合成左图 (I~l)。
计算三类损失:
Cap:合成图和真实图是否像;
Cds:视差图是否平滑自然;
Clr:左右预测是否一致。
反向传播,更新网络参数。
最终,网络就学会了:从单张图像中预测合理的深度(视差),而且不需要激光雷达的标注数据。
4、Monodepth 的主要缺陷(来自原论文结论与讨论)
遮挡边界伪影
只靠光度重建训练,遮挡处两眼看不到同一像素,容易出"拉花/虚影"。作者明确把"显式遮挡推理"列为改进方向。
有些地方左眼能看到,右眼看不到(比如电线杆后面的背景),模型硬要"补",结果会出鬼影。
比喻:就像你画一幅画,桌子后面的部分没看到,你硬想当然地画上去,画歪了。
镜面/透明体失真
- 光度一致性假设
Monodepth 的核心训练思路是:
假设场景里的表面都是 朗伯面(Lambertian surface),即表面看起来颜色一致,不随角度变化。
所以从左眼和右眼看过去,同一个点的颜色、亮度应该是一样的。
这样才成立 光度一致性损失:用视差把右图采样过来,和左图像素比对,看差不差。
- 问题:非朗伯面(镜面 / 透明体)
但现实世界里很多表面不是朗伯的:
玻璃:透过它看到的是背后的景物,而不是玻璃本身。左眼和右眼透过去的角度不同 → 背景的折射不同 → 两边像素颜色对不上。
水面:会有反射、折射,左右眼看到的波纹、倒影可能完全不同。
镜子 / 光亮金属:你看到的是"另一边的景象",而且反射角度敏感,左右眼差别很大。
👉 在这些情况下:光度一致性假设被破坏了。
Monodepth 论文里提到:
对于这种情况,简单的像素差 (L1) 或 SSIM 已经不够用了。
作者建议用 更复杂、更鲁棒的相似性度量,比如:
多尺度特征相似性(不是直接比像素,而是比高层特征)。
或者结合语义信息(知道"这里是玻璃",就别太依赖光度损失)。
有些后续工作还会用 Mask,把这些区域权重降低。
域/标定差异敏感
不同数据集(相机内参、基线、分辨率)跨域时数值表现会掉,需要在目标域微调。
如果训练数据和测试数据的相机参数(比如焦距、分辨率)不同,效果会掉。
5、后续的哪些模型是如何基于此进行改进
Monodepth → Monodepth2(Godard et al., 2019)
主要改进:
自监督从双目扩展到视频序列:不仅用左右眼,还用前后帧做监督,进一步摆脱双目数据的限制。
更精细的重建损失:引入多尺度、多区域的损失设计,更鲁棒。
自动遮挡处理:在光度一致性里,遮挡会带来噪声,Monodepth2 提出了遮挡感知的损失。
👉 通俗理解:从"必须有双目"升级到"单目视频也能训练"。
Stereo/Mono + Self-Supervised 方向
很多工作发现:利用时序信息(视频)能进一步提高稳定性。
SfMLearner (Zhou et al., 2017):预测相机位姿 + 深度,同时训练,开创了"单目视频自监督"的思路。
Later works (比如 MegaDepth, DDVO):改进了位姿估计和优化方法,让网络更稳。
👉 通俗理解:网络一边学"物体多远",一边学"自己往哪走"。
改进损失函数
Monodepth 的核心损失是:光度一致性 + 视差平滑 + 左右一致性。
后来很多研究改进了这部分:
遮挡感知 (Occlusion-aware loss):解决物体遮挡导致的重建失败。
更鲁棒的相似性度量:替代 L1+SSIM,比如用特征空间的相似性。
边界感知平滑:让深度在边缘更锐利。
👉 通俗理解:让网络少被"玻璃、反射、遮挡"骗。
融合语义与深度
一些工作引入 语义分割(比如知道哪里是车、哪里是天空),帮助深度估计。
代表:Semantic Monodepth (Klingner et al., 2020)。
👉 通俗理解:知道"这是一辆车"后,深度预测会更合理。
更强的网络结构
使用 更强的编码器(ResNet, EfficientNet, Transformer),替代原始的简单 CNN。
PackNet-SfM (Guizilini et al., 2020):通过特殊卷积结构保留更多几何信息。
最近有 Transformer-based 方法(比如 DPT, AdaBins),利用全局建模获得更平滑深度。
👉 通俗理解:从"小模型"升级到"大模型 + Transformer",预测更精准。
6、模型结果
用了哪个数据集?
作者主要在 KITTI 数据集上做实验。
使用的是 KITTI Stereo benchmark 的子集(也叫 KITTI raw dataset 的子集)。
具体来说:
训练:使用 Eigen 等人定义的训练划分(常见的 split),大约 23k 左右训练图像。
测试:在 KITTI 官方的 Eigen split 测试集(697 张图)上评测。
同时,他们还在 KITTI 官方的 online stereo benchmark 上提交了结果,与其他方法比较。
论文里主要用了以下标准深度估计指标:
Abs Rel:平均相对误差
Sq Rel:平方相对误差
RMSE:均方根误差
RMSE log:log 空间的 RMSE
δ < 1.25, δ < 1.25², δ < 1.25³:预测值和真值在一定容差内的比例
本文来源:k学长的深度学习宝库,点击查看源码&详细教程。深度学习,从入门到进阶,你想要的,都在这里。包含学习专栏、视频课程、论文源码、实战项目、云盘资源等。