前篇文章提到,为了评估actor结合s所做的action是否为好的动作(有利于reward积累)而引入了优势函数A,在不同情况下优势函数的定义不同。优势函数可以由人为来进行设定,然后评估action的好坏,但如果每一笔数据都需要人类来评定分数,效率显然太低,所以需要引入critic(评估)模型,来进行对action的评价。critic模型的一种主要形式是价值函数V(s)。
下面的图片直接用总得分G和优势函数相等,而G的得分需要完成所有的a之后才能累计得出,在这种情况下训练critic就需要做完全部的动作aciton;另一种情况,critic模型要做的是在看到第一个action a1之后,就能推断出之后所有的action所累积的分数是多少,也即推断出总得分A,A实际上是G的一个估计量。
训练critic的方式有两种
一、蒙特卡洛算法
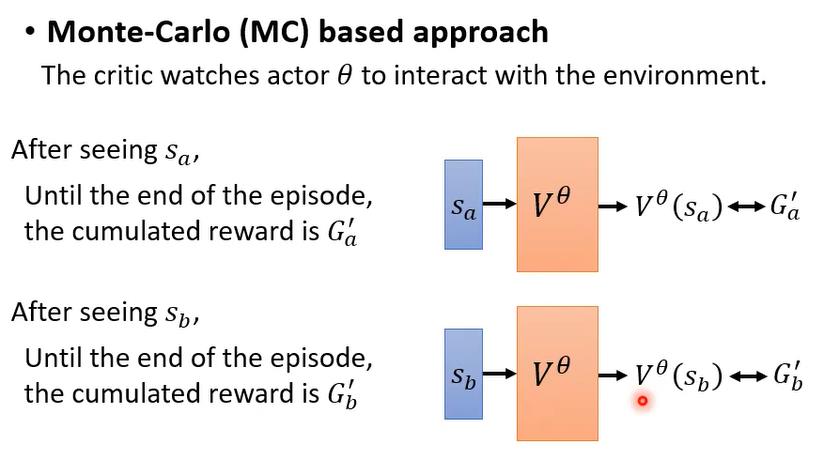
actor执行一个action,将后续所有action的reward累计,得到G。以(s,G)对作为数据集来训练critic,如果是on-policy的方法来训练,那么只有当actor执行完一组action后才能得到一组训练critic的数据。
二、时序差分算法
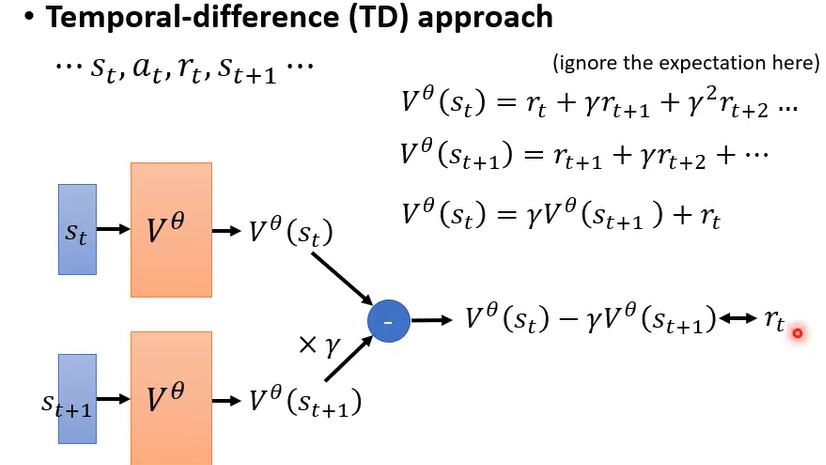
如果critic只能在actor执行完所有的action后才能得到数据G用于训练,效率是十分低下的,我们希望actor在做完当前action之后就可以得到critic的训练数据。actor在s1下进行a1得到r1,并且产生了新的s2;而V(s1)近似于G1,V(s2)近似于G2;由于actor并没有进行完所有的action,所以G1和G2的具体值都是不知道的,但我们知道G1和G2之间是有关系的,G1=nG2+r1,所以G1-nG2=r1,所以V(s1)-nV(s2)应该近似于r1。我们可以用(s1,a1,r1,s2)来训练critic。
下面给出一个例子来分别通过两种方法进行V的预测。

设定,进行八轮训练。得到的V(Sb)的平均值是3/4,试计算V(Sa)的值。
如果使用蒙特卡洛思想,那么V(Sa)的值应该等于G(Sa),即在环境Sa下采取动作后,后续所有reward的累计,即0+0=0。此时我们希望critic的输出V(Sa)是0。
如果使用时序查分思想,那么V(Sa)的值不仅取决于G(Sa),还取决于G(Sb),G(Sa)-G(Sb)应该等于r=0,所以V(Sa)的值也应该是0。
现在我们得到了用于评估状态价值函数的critic模型,接下来要将其运用在actor的训练中。
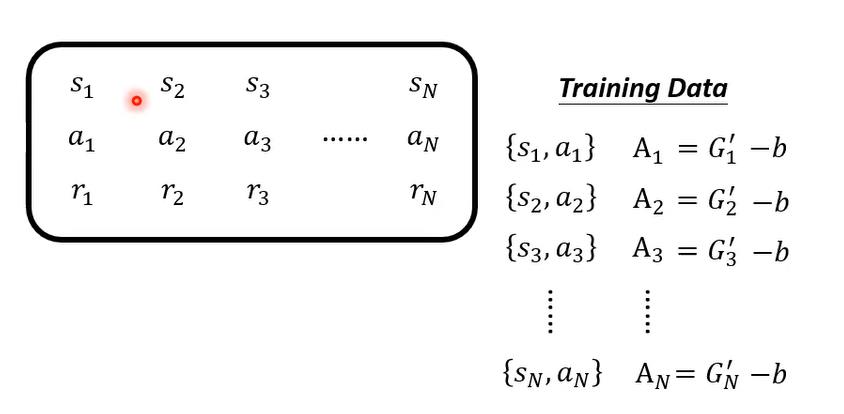
给定环境s1,actor做出动作a1,得到回报r1,产生新的环境s2,然后继续进行a2......循环此过程,最后累积的汇报为G1',而用于评估该动作a的优势函数A定义为G1'-b;b为偏置,b的值就是我们通过critic模型在评估环境s1以后得到的价值函数V(s1)。可以看出,V(s1)代表的是在s1状态下,执行一系列动作以后得到的reward的累计的平均值;而G1'表示的是在状态s1采取动作a1之后再执行一系列动作以后得到的reward的累计值,G1'的值是有随机性的,因为actor在执行a1后的动作并不一定是固定的,所以用G1'-V(s1)实际上是用动作的平均优势值对单个动作的优势值进行了标准化,从而衡量单个动作的好坏。