
🎮 HY-World 1.5: 具有实时延迟与几何一致性的交互式世界建模系统框架
📖 简介
尽管HY-World 1.0 能够生成沉浸式3D世界,但其依赖耗时的离线生成流程且缺乏实时交互能力。HY-World 1.5 通过WorldPlay填补了这一空白------这是一个支持实时交互式世界建模的流式视频扩散模型,具备长期几何一致性,解决了现有方法在速度与内存之间的权衡难题。我们的模型依托四大核心设计实现突破:
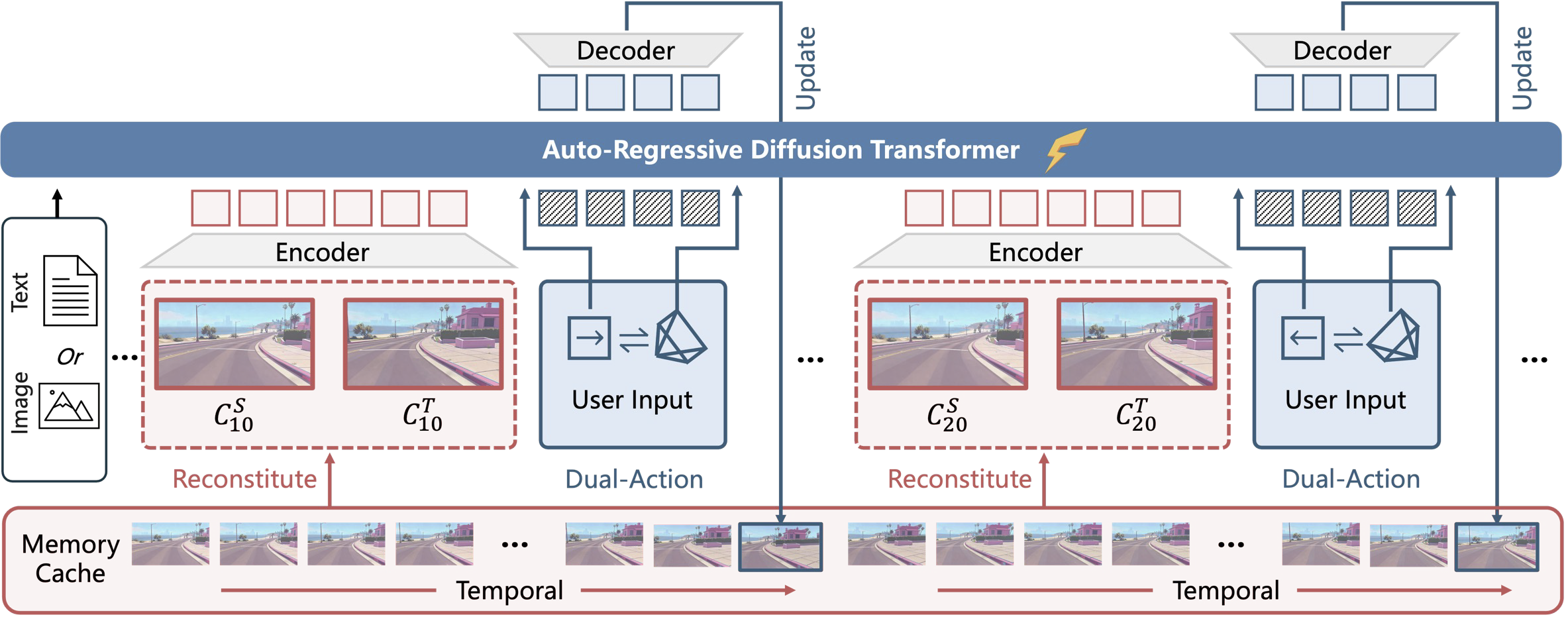
- 双重动作表征:通过键盘鼠标输入实现鲁棒的动作控制;
- 重构上下文记忆:动态重组历史帧上下文,采用时序重构技术保留几何关键帧的可访问性,有效缓解记忆衰减;
- 世界罗盘:创新的强化学习后训练框架,直接提升长时序自回归视频模型的动作跟随性与视觉质量;
- 上下文强制蒸馏:专为记忆感知模型设计的新蒸馏方法,通过对齐师生模型的记忆上下文保留远程信息处理能力,在实现实时速度的同时避免误差漂移。
综合而言,HY-World 1.5能以24FPS生成具备卓越一致性的长时序流式视频,性能优于现有技术。该模型在多样化场景中展现出强大泛化能力,支持第一人称与第三人称视角,兼容写实与风格化环境,可应用于3D重建、可触发事件及无限世界扩展等多元场景。
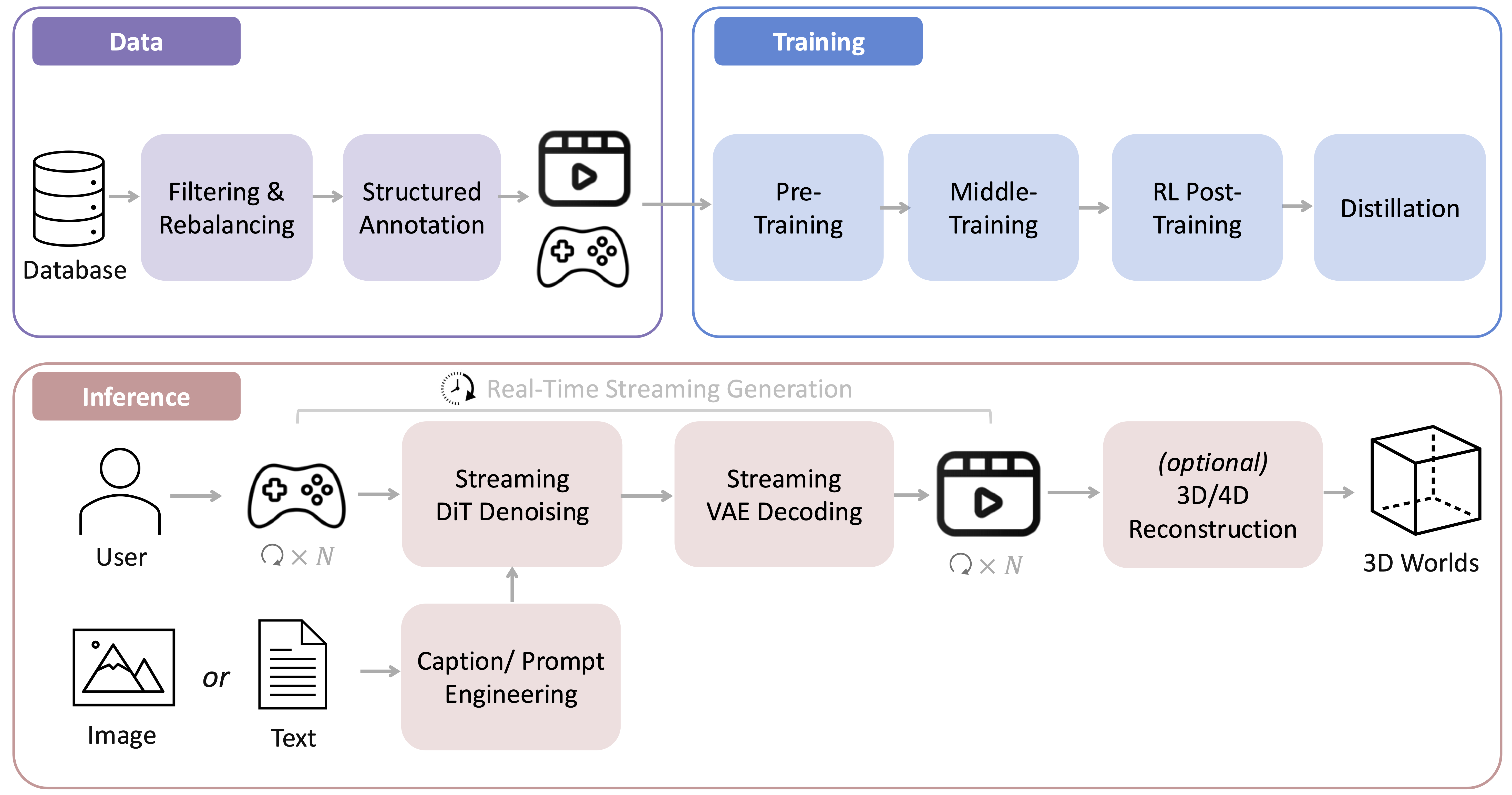
- 系统概览
HY-World 1.5开源了实时世界模型的系统化训练框架,涵盖数据、训练、推理部署全流程。技术报告详细披露了模型预训练、中期训练、强化学习后训练及记忆感知蒸馏的具体实现,并介绍了一系列降低网络传输延迟与模型推理延迟的工程技术,最终为用户提供实时流式推理体验。
-
推理流程
给定一张图像或描述世界的文本提示,我们的模型执行下一片段(16个视频帧)预测任务,根据用户动作生成未来视频。对于每个片段的生成,我们会动态重组过去片段的上下文记忆,以确保长期的时间和几何一致性。
🔑 使用示例
我们开源了双向扩散模型和自回归扩散模型的推理代码。对于提示词改写,推荐使用Gemini或通过vLLM部署的模型。当前代码库仅支持兼容vLLM API的模型。如需使用Gemini,需自行实现接口调用。具体实现可参考HunyuanVideo-1.5项目。
推荐使用generate_custom_trajectory.py脚本生成自定义相机运动轨迹。
bash
export T2V_REWRITE_BASE_URL="<your_vllm_server_base_url>"
export T2V_REWRITE_MODEL_NAME="<your_model_name>"
export I2V_REWRITE_BASE_URL="<your_vllm_server_base_url>"
export I2V_REWRITE_MODEL_NAME="<your_model_name>"
PROMPT='A paved pathway leads towards a stone arch bridge spanning a calm body of water. Lush green trees and foliage line the path and the far bank of the water. A traditional-style pavilion with a tiered, reddish-brown roof sits on the far shore. The water reflects the surrounding greenery and the sky. The scene is bathed in soft, natural light, creating a tranquil and serene atmosphere. The pathway is composed of large, rectangular stones, and the bridge is constructed of light gray stone. The overall composition emphasizes the peaceful and harmonious nature of the landscape.'
IMAGE_PATH=./assets/img/test.png # Now we only provide the i2v model, so the path cannot be None
SEED=1
ASPECT_RATIO=16:9
RESOLUTION=480p # Now we only provide the 480p model
OUTPUT_PATH=./outputs/
MODEL_PATH= # Path to pretrained hunyuanvideo-1.5 model
AR_ACTION_MODEL_PATH= # Path to our HY-World 1.5 autoregressive checkpoints
BI_ACTION_MODEL_PATH= # Path to our HY-World 1.5 bidirectional checkpoints
AR_DISTILL_ACTION_MODEL_PATH= # Path to our HY-World 1.5 autoregressive distilled checkpoints
POSE_JSON_PATH=./assets/pose/test_forward_32_latents.json # Path to the customized camera trajectory
NUM_FRAMES=125
# Configuration for faster inference
# For AR inference, the maximum number recommended is 4. For bidirectional models, it can be set to 8.
N_INFERENCE_GPU=4 # Parallel inference GPU count.
# Configuration for better quality
REWRITE=false # Enable prompt rewriting. Please ensure rewrite vLLM server is deployed and configured.
ENABLE_SR=false # Enable super resolution. When the NUM_FRAMES == 121, you can set it to true
# inference with bidirectional model
torchrun --nproc_per_node=$N_INFERENCE_GPU generate.py \
--prompt "$PROMPT" \
--image_path $IMAGE_PATH \
--resolution $RESOLUTION \
--aspect_ratio $ASPECT_RATIO \
--video_length $NUM_FRAMES \
--seed $SEED \
--rewrite $REWRITE \
--sr $ENABLE_SR --save_pre_sr_video \
--pose_json_path $POSE_JSON_PATH \
--output_path $OUTPUT_PATH \
--model_path $MODEL_PATH \
--action_ckpt $BI_ACTION_MODEL_PATH \
--few_step false \
--model_type 'bi'
# inference with autoregressive model
#torchrun --nproc_per_node=$N_INFERENCE_GPU generate.py \
# --prompt "$PROMPT" \
# --image_path $IMAGE_PATH \
# --resolution $RESOLUTION \
# --aspect_ratio $ASPECT_RATIO \
# --video_length $NUM_FRAMES \
# --seed $SEED \
# --rewrite $REWRITE \
# --sr $ENABLE_SR --save_pre_sr_video \
# --pose_json_path $POSE_JSON_PATH \
# --output_path $OUTPUT_PATH \
# --model_path $MODEL_PATH \
# --action_ckpt $AR_ACTION_MODEL_PATH \
# --few_step false \
# --model_type 'ar'
# inference with autoregressive distilled model
#torchrun --nproc_per_node=$N_INFERENCE_GPU generate.py \
# --prompt "$PROMPT" \
# --image_path $IMAGE_PATH \
# --resolution $RESOLUTION \
# --aspect_ratio $ASPECT_RATIO \
# --video_length $NUM_FRAMES \
# --seed $SEED \
# --rewrite $REWRITE \
# --sr $ENABLE_SR --save_pre_sr_video \
# --pose_json_path $POSE_JSON_PATH \
# --output_path $OUTPUT_PATH \
# --model_path $MODEL_PATH \
# --action_ckpt $AR_DISTILL_ACTION_MODEL_PATH \
# --few_step true \
# --num_inference_steps 4 \
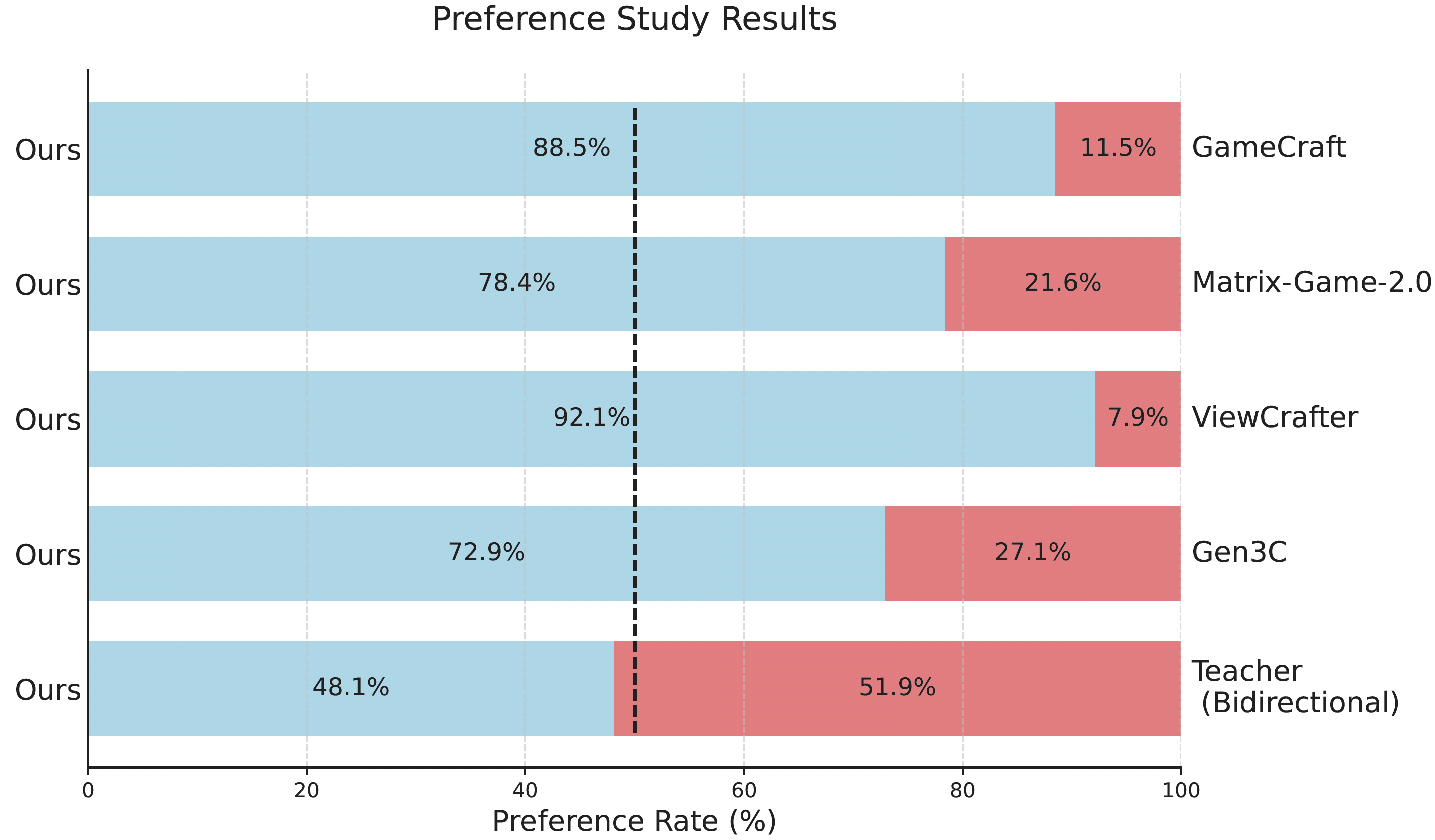
# --model_type 'ar'📊 评估结果
HY-World 1.5 在多项量化指标上超越现有方法,包括不同视频时长的重建指标和人工评估结果。
| Model | Real-time | Short-term | Long-term | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR ⬆ | SSIM ⬆ | LPIPS ⬇ | R d i s t R_{dist} Rdist ⬇ | T d i s t T_{dist} Tdist ⬇ | PSNR ⬆ | SSIM ⬆ | LPIPS ⬇ | R d i s t R_{dist} Rdist ⬇ | T d i s t T_{dist} Tdist ⬇ | ||
| CameraCtrl | ❌ | 17.93 | 0.569 | 0.298 | 0.037 | 0.341 | 10.09 | 0.241 | 0.549 | 0.733 | 1.117 |
| SEVA | ❌ | 19.84 | 0.598 | 0.313 | 0.047 | 0.223 | 10.51 | 0.301 | 0.517 | 0.721 | 1.893 |
| ViewCrafter | ❌ | 19.91 | 0.617 | 0.327 | 0.029 | 0.543 | 9.32 | 0.271 | 0.661 | 1.573 | 3.051 |
| Gen3C | ❌ | 21.68 | 0.635 | 0.278 | 0.024 | 0.477 | 15.37 | 0.431 | 0.483 | 0.357 | 0.979 |
| VMem | ❌ | 19.97 | 0.587 | 0.316 | 0.048 | 0.219 | 12.77 | 0.335 | 0.542 | 0.748 | 1.547 |
| Matrix-Game-2.0 | ✅ | 17.26 | 0.505 | 0.383 | 0.287 | 0.843 | 9.57 | 0.205 | 0.631 | 2.125 | 2.742 |
| GameCraft | ❌ | 21.05 | 0.639 | 0.341 | 0.151 | 0.617 | 10.09 | 0.287 | 0.614 | 2.497 | 3.291 |
| Ours (w/o Context Forcing) | ❌ | 21.27 | 0.669 | 0.261 | 0.033 | 0.157 | 16.27 | 0.425 | 0.495 | 0.611 | 0.991 |
| Ours (full) | ✅ | 21.92 | 0.702 | 0.247 | 0.031 | 0.121 | 18.94 | 0.585 | 0.371 | 0.332 | 0.797 |
🎬 更多示例
https://github.com/user-attachments/assets/6aac8ad7-3c64-4342-887f-53b7100452ed
https://github.com/user-attachments/assets/531bf0ad-1fca-4d76-bb65-84701368926d
https://github.com/user-attachments/assets/f165f409-5a74-4e19-a32c-fc98d92259e1
📚 引用
bibtex
@article{hyworld2025,
title={HY-World 1.5: A Systematic Framework for Interactive World Modeling with Real-Time Latency and Geometric Consistency},
author={Team HunyuanWorld},
journal={arXiv preprint},
year={2025}
}
@article{worldplay2025,
title={WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Model},
author={Wenqiang Sun and Haiyu Zhang and Haoyuan Wang and Junta Wu and Zehan Wang and Zhenwei Wang and Yunhong Wang and Jun Zhang and Tengfei Wang and Chunchao Guo},
year={2025},
journal={arXiv preprint}
}
@inproceedings{wang2025compass,
title={WorldCompass: Reinforcement Learning for Long-Horizon World Models},
author={Zehan Wang and Tengfei Wang and Haiyu Zhang and Wenqiang Sun and Junta Wu and Haoyuan Wang and Zhenwei Wang and Hengshuang Zhao and Chunchao Guo and Zhou Zhao},
journal = {arXiv preprint},
year = 2025
}🙏 致谢
我们要感谢 HunyuanWorld、HunyuanWorld-Mirror、HunyuanVideo 和 FastVideo 的杰出贡献。