索引器
表的列索引
列索引是最常见的索引形式,一般通过[]来实现。通过[列名]可以从DataFrame中取出相应的列,返回值为Series
python
df = pd.read_csv('data/learn_pandas.csv', usecols = ['School', 'Grade', 'Name', 'Gender', 'Weight', 'Transfer'])
print(df['Name'].head())
#0 Gaopeng Yang
#1 Changqiang You
#2 Mei Sun
#3 Xiaojuan Sun
#4 Gaojuan You
#Name: Name, dtype: object如果要取出多个列,则可以通过[列名组成的列表],其返回值为一个DataFrame,例如从表中取出性别和姓名两列
python
print(df[['Gender','Name']].head())
# Gender Name
#0 Female Gaopeng Yang
#1 Male Changqiang You
#2 Male Mei Sun
#3 Female Xiaojuan Sun
#4 Male Gaojuan You此外,若要取出单列,且列名中不包含空格,则可以用.列名取出,这和[列名]是等价的
python
print(df.Name.head())
#0 Gaopeng Yang
#1 Changqiang You
#2 Mei Sun
#3 Xiaojuan Sun
#4 Gaojuan You
Name: Name, dtype: object序列的行索引
以字符串为索引的Series
如果取出单个索引的对应元素,则可以使用[item],若Series只有单个值对应,则返回这个标量值,如果有多个值对应,则返回一个Series
python
s = pd.Series([1, 2, 3, 4, 5, 6], index=['a', 'b', 'a', 'a', 'a', 'c'])
print(s)
#a 1
#b 2
#a 3
#a 4
#a 5
#c 6
#dtype: int64
print(s['a'])
#a 1
#a 3
#a 4
#a 5
#dtype: int64
print(s['b'])
#2如果取出多个索引的对应元素,则可以使用[items的列表]
python
print(s[['c','b']])
#c 6
#b 2
#dtype: int64如果想要取出某两个索引之间的元素,并且这两个索引是在整个索引中唯一出现,则可以使用切片,,同时需要注意这里的切片会包含两个端点
python
print(s['c':'b':-2])
#c 6
#a 4
#b 2
#dtype: int64以整数为索引的Series
在使用数据的读入函数时,如果不特别指定所对应的列作为索引,那么会生成从0开始的整数索引作为默认索引。当然,任意一组符合长度要求的整数都可以作为索引。
和字符串一样,如果使用[int]或[int_list],则可以取出对应索引元素的值
python
s = pd.Series(['a', 'b', 'c', 'd', 'e', 'f'], index=[1, 3, 1, 2, 5, 4])
print(s[1])
#1 a
#1 c
#dtype: object
print(s[[2,3]])
#2 d
#3 b
#dtype: object如果使用整数切片,则会取出对应索引位置 的值,注意这里的整数切片同Python中的切片一样不包含右端点
python
print(s[1:-1:2])
#3 b
#2 d
#dtype: objectloc索引器
对于表而言,有两种索引器,一种是基于元素 的loc索引器,另一种是基于位置 的iloc索引器。
loc索引器的一般形式是loc[*, *],其中第一个*代表行的选择,第二个*代表列的选择,如果省略第二个位置写作loc[*],这个*是指行的筛选。其中,*的位置一共有五类合法对象,分别是:单个元素、元素列表、元素切片、布尔列表以及函数。
*为单个元素,直接取出相应的行或列,如果该元素在索引中重复则结果为DataFrame,否则为Series
python
df = pd.read_csv('data/learn_pandas.csv')
df_demo =df.set_index('Name') #设置Name列作为索引
print(df_demo.loc['Qiang Sun']) #多个名字一样
# School Grade ... Test_Date Time_Record
#Name ...
#Qiang Sun Tsinghua University Junior ... 2019/12/11 0:05:08
#Qiang Sun Tsinghua University Sophomore ... 2019/12/30 0:04:37
#Qiang Sun Shanghai Jiao Tong University Junior ... 2019/9/7 0:04:31
#[3 rows x 9 columns]
print(df_demo.loc['Quan Zhao']) #唯一值
#School Shanghai Jiao Tong University
#Grade Junior
#Gender Female
#Height 160.6
#Weight 53.0
#Transfer N
#Test_Number 2
#Test_Date 2019/10/4
#Time_Record 0:03:45
#Name: Quan Zhao, dtype: object
print(df_demo.loc['Qiang Sun','School']) #同时选择行和列 返回Series
#Name
#Qiang Sun Tsinghua University
#Qiang Sun Tsinghua University
#Qiang Sun Shanghai Jiao Tong University
#Name: School, dtype: object
print(df_demo.loc['Quan Zhao','School']) #返回单个元素
#Shanghai Jiao Tong University*为元素列表,取出列表中所有元素值对应的行或列
python
print(df_demo.loc[['Qiang Sun','Quan Zhao'], ['School','Gender']])
# School Gender
#Name
#Qiang Sun Tsinghua University Female
#Qiang Sun Tsinghua University Female
#Qiang Sun Shanghai Jiao Tong University Female
#Quan Zhao Shanghai Jiao Tong University Female*为切片,之前的Series使用字符串索引时提到,如果是唯一值的起点和终点字符,那么就可以使用切片,并且包含两个端点,如果不唯一则报错:
python
print(df_demo.loc['Gaojuan You':'Gaoqiang Qian', 'School':'Gender'])
# School Grade Gender
#Name
#Gaojuan You Fudan University Sophomore Male
#Xiaoli Qian Tsinghua University Freshman Female
#Qiang Chu Shanghai Jiao Tong University Freshman Female
#Gaoqiang Qian Tsinghua University Junior Female需要注意的是,如果DataFrame使用整数索引,其使用整数切片的时候和上面字符串索引的要求一致,都是元素切片,包含端点且起点、终点不允许有重复值。
python
df_loc_slice_demo = df_demo.copy()
df_loc_slice_demo.index = range(df_demo.shape[0],0,-1)
print(df_loc_slice_demo.loc[5:3])
# School Grade ... Test_Date Time_Record
#5 Fudan University Junior ... 2019/10/17 0:04:31
#4 Tsinghua University Senior ... 2019/9/22 0:04:03
#3 Shanghai Jiao Tong University Senior ... 2020/1/5 0:04:48
#
#[3 rows x 9 columns]
df_loc_slice_demo.loc[3:5] # 没有返回,说明不是整数位置切片
#Empty DataFrame
#Columns: [School, Grade, Gender, Height, Weight, Transfer, Test_Number, Test_Date, Time_Record]
#Index: []*为布尔列表,根据条件来筛选行是极其常见的,此处传入loc的布尔列表与DataFrame长度相同,且列表为True的位置所对应的行会被选中,False则会被剔除。
python
print(df_demo.loc[df_demo.Weight>70].head())
# School Grade ... Test_Date Time_Record
#Name ...
#Mei Sun Shanghai Jiao Tong University Senior ... 2019/9/12 0:05:22
#Gaojuan You Fudan University Sophomore ... 2019/11/6 0:05:22
#Xiaopeng Zhou Shanghai Jiao Tong University Freshman ... 2019/9/29 0:05:16
#Xiaofeng Sun Tsinghua University Senior ... 2019/11/4 0:03:32
#Qiang Zheng Shanghai Jiao Tong University Senior ... 2019/12/5 0:04:59
#
#[5 rows x 9 columns]前面所提到的传入元素列表,也可以通过isin方法返回的布尔列表等价写出
python
#选出所有大一和大四的同学信息
print(df_demo.loc[df_demo.Grade.isin(['Freshman', 'Senior'])].head())
# School Grade ... Test_Date Time_Record
#Name ...
#Gaopeng Yang Shanghai Jiao Tong University Freshman ... 2019/10/5 0:04:34
#Changqiang You Peking University Freshman ... 2019/9/4 0:04:20
#Mei Sun Shanghai Jiao Tong University Senior ... 2019/9/12 0:05:22
#Xiaoli Qian Tsinghua University Freshman ... 2019/10/31 0:03:47
#Qiang Chu Shanghai Jiao Tong University Freshman ... 2019/12/12 0:03:53
#
#[5 rows x 9 columns]对于复合条件而言,可以用|(或), &(且), ~(取反)的组合来实现
python
#选出复旦大学中体重超过70kg的大四学生,或者北大男生中体重超过80kg的非大四的学生
condition_1_1 = df_demo.School == 'Fudan University'
condition_1_2 = df_demo.Grade == 'Senior'
condition_1_3 = df_demo.Weight > 70
condition_1 = condition_1_1 & condition_1_2 & condition_1_3
condition_2_1 = df_demo.School == 'Peking University'
condition_2_2 = df_demo.Grade == 'Senior'
condition_2_3 = df_demo.Weight > 80
condition_2 = condition_2_1 & (~condition_2_2) & condition_2_3
print(df_demo.loc[condition_1 | condition_2])
# School Grade ... Test_Date Time_Record
#Name ...
#Qiang Han Peking University Freshman ... 2020/1/7 0:03:58
#Chengpeng Zhou Fudan University Senior ... 2019/9/5 0:03:38
#Changpeng Zhao Peking University Freshman ... 2019/10/24 0:04:08
#Chengpeng Qian Fudan University Senior ... 2019/12/19 0:05:18
#
#[4 rows x 9 columns]*为函数,必须以前面的四种合法形式之一为返回值,并且函数的输入值为DataFrame本身。
python
def condition(x):
condition_1_1 = x.School == 'Fudan University'
condition_1_2 = x.Grade == 'Senior'
condition_1_3 = x.Weight > 70
condition_1 = condition_1_1 & condition_1_2 & condition_1_3
condition_2_1 = x.School == 'Peking University'
condition_2_2 = x.Grade == 'Senior'
condition_2_3 = x.Weight > 80
condition_2 = condition_2_1 & (~condition_2_2) & condition_2_3
result = condition_1 | condition_2
return result
print(df_demo.loc[condition])
# School Grade ... Test_Date Time_Record
#Name ...
#Qiang Han Peking University Freshman ... 2020/1/7 0:03:58
#Chengpeng Zhou Fudan University Senior ... 2019/9/5 0:03:38
#Changpeng Zhao Peking University Freshman ... 2019/10/24 0:04:08
#Chengpeng Qian Fudan University Senior ... 2019/12/19 0:05:18
#
#[4 rows x 9 columns]支持使用lambda表达式,其返回值也同样必须是先前提到的四种形式之一
python
print(df_demo.loc[lambda x:'Quan Zhao', lambda x:'Gender'])
#Female由于函数无法返回如start: end: step的切片形式,故返回切片时要用slice对象进行包装
python
print(df_demo.loc[lambda x: slice('Gaojuan You', 'Gaoqiang Qian')])
# School Grade ... Test_Date Time_Record
#Name ...
#Gaojuan You Fudan University Sophomore ... 2019/11/6 0:05:22
#Xiaoli Qian Tsinghua University Freshman ... 2019/10/31 0:03:47
#Qiang Chu Shanghai Jiao Tong University Freshman ... 2019/12/12 0:03:53
#Gaoqiang Qian Tsinghua University Junior ... 2019/9/3 0:03:45
#
#[4 rows x 9 columns]在对表或者序列赋值时,应当在使用一层索引器后直接进行赋值操作,这样做是由于进行多次索引后赋值是赋在临时返回的copy副本上的,而没有真正修改元素从而报出SettingWithCopyWarning警告。
iloc索引器
iloc的使用与loc完全类似,只不过是针对位置进行筛选,在相应的*位置处一共也有五类合法对象,分别是:整数、整数列表、整数切片、布尔列表以及函数,函数的返回值必须是前面的四类合法对象中的一个,其输入同样也为DataFrame本身。
python
print(df_demo.iloc[1,1]) #第二行第二列
#Freshman
print(df_demo.iloc[[0,1],[0,1]]) #前两行前两列
# School Grade
#Name
#Gaopeng Yang Shanghai Jiao Tong University Freshman
#Changqiang You Peking University Freshman
print(df_demo.iloc[1: 4, 2:4]) # 切片不包含结束端点
# Gender Height
#Name
#Changqiang You Male 166.5
#Mei Sun Male 188.9
#Xiaojuan Sun Female NaN
print(df_demo.iloc[lambda x: slice(1, 4)]) # 传入切片为返回值的函数
# School Grade ... Test_Date Time_Record
#Name ...
#Changqiang You Peking University Freshman ... 2019/9/4 0:04:20
#Mei Sun Shanghai Jiao Tong University Senior ... 2019/9/12 0:05:22
#Xiaojuan Sun Fudan University Sophomore ... 2020/1/3 0:04:08
#
#[3 rows x 9 columns]在使用布尔列表的时候要特别注意,不能传入Series而必须传入序列的values,否则会报错。因此,在使用布尔筛选的时候还是应当优先考虑loc的方式。
python
print(df_demo.iloc[(df_demo.Weight>80).values].head())
# School ... Time_Record
#Name ...
#Mei Sun Shanghai Jiao Tong University ... 0:05:22
#Qiang Zheng Shanghai Jiao Tong University ... 0:04:59
#Qiang Han Peking University ... 0:03:58
#Chengpeng Zhou Fudan University ... 0:03:38
#Feng Han Shanghai Jiao Tong University ... 0:05:10
#
#[5 rows x 9 columns]
print(df_demo.School.iloc[1])
#Peking University
print(df_demo.School.iloc[1:5:2])
#Name
#Changqiang You Peking University
#Xiaojuan Sun Fudan University
#Name: School, dtype: objectquery方法
在pandas中,支持把字符串形式的查询表达式传入query方法来查询数据,其表达式的执行结果必须返回布尔列表。在进行复杂索引时,由于这种检索方式无需像普通方法一样重复使用DataFrame的名字来引用列名,一般而言会使代码长度在不降低可读性的前提下有所减少。
python
print(df.query('((School == "Fudan University")&'
' (Grade == "Senior")&'
' (Weight > 70))|'
'((School == "Peking University")&'
' (Grade != "Senior")&'
' (Weight > 80))'))
# School Grade ... Test_Date Time_Record
#38 Peking University Freshman ... 2020/1/7 0:03:58
#66 Fudan University Senior ... 2019/9/5 0:03:38
#99 Peking University Freshman ... 2019/10/24 0:04:08
#131 Fudan University Senior ... 2019/12/19 0:05:18
#
#[4 rows x 10 columns]在query表达式中,帮用户注册了所有来自DataFrame的列名,所有属于该Series的方法都可以被调用,和正常的函数调用并没有区别。
对于含有空格的列名,需要使用col name的方式进行引用。同时,在query中还注册了若干英语的字面用法,帮助提高可读性,例如:or, and, or, is in, not in。
python
print(df.query('(Grade not in ["Freshman", "Sophomore"]) and (Gender == "Male")').head())
# School Grade ... Test_Date Time_Record
#2 Shanghai Jiao Tong University Senior ... 2019/9/12 0:05:22
#16 Tsinghua University Junior ... 2019/9/11 0:04:51
#17 Tsinghua University Junior ... 2019/11/2 0:04:53
#18 Tsinghua University Senior ... 2019/11/4 0:03:32
#21 Shanghai Jiao Tong University Senior ... 2020/1/2 0:04:54
#
#[5 rows x 10 columns]此外,在字符串中出现与列表的比较时,==和!=分别表示元素出现在列表和没有出现在列表,等价于is in和not in。
对于query中的字符串,如果要引用外部变量,只需在变量名前加@符号。
python
low, high =70, 80
print(df.query('Weight.between(@low, @high)').head())
# School Grade ... Test_Date Time_Record
#1 Peking University Freshman ... 2019/9/4 0:04:20
#4 Fudan University Sophomore ... 2019/11/6 0:05:22
#10 Shanghai Jiao Tong University Freshman ... 2019/9/29 0:05:16
#18 Tsinghua University Senior ... 2019/11/4 0:03:32
#35 Peking University Freshman ... 2019/10/8 0:03:32
#
#[5 rows x 10 columns]随机抽样
如果把DataFrame的每一行看作一个样本,或把每一列看作一个特征,再把整个DataFrame看作总体,想要对样本或特征进行随机抽样就可以用sample函数。有时在拿到大型数据集后,想要对统计特征进行计算来了解数据的大致分布,但是这很费时间。同时,由于许多统计特征在等概率不放回的简单随机抽样条件下,是总体统计特征的无偏估计,比如样本均值和总体均值,那么就可以先从整张表中抽出一部分来做近似估计。
sample函数中的主要参数为n, axis, frac, replace, weights,前三个分别是指抽样数量、抽样的方向(0为行、1为列)和抽样比例(0.3则为从总体中抽出30%的样本)。
replace和weights分别是指是否放回和每个样本的抽样相对概率,当replace = True则表示有放回抽样。例如,对下面构造的df_sample以value值的相对大小为抽样概率进行有放回抽样,抽样数量为3。
python
df_sample = pd.DataFrame({'id': list('abcde'), 'value': [1, 2, 3, 4, 90]})
print(df_sample)
# id value
#0 a 1
#1 b 2
#2 c 3
#3 d 4
#4 e 90
print(df_sample.sample(3,replace=True,weights=df_sample.value))
# id value
#4 e 90
#4 e 90
#4 e 90多级索引
Pandas 的 MultiIndex(多级索引)是 Pandas 中一种强大的数据结构,允许在 DataFrame 或 Series 的索引上使用多个级别。它可以将数据按照多个维度分层组织,从而方便对复杂数据进行切片、聚合和重塑操作。
数学上,可以将一个具有多级索引的 DataFrame 看作一个映射:
f : K1 × K2× ⋯ × K n → V
其中Ki 表示第 i 级索引的取值集合,而 V表示存储的数据值。通过多级索引,我们可以将数据分为多个层次,例如按"国家"和"城市"两个维度对销售数据进行组织。
多级索引及其表结构
创建多级索引表
python
import pandas as pd
import numpy as np
df = pd.read_csv('data/learn_pandas.csv')
np.random.seed(0)
multi_index = pd.MultiIndex.from_product([list('ABCD'), df.Gender.unique()], names=('School', 'Gender'))
multi_column = pd.MultiIndex.from_product([['Height', 'Weight'], df.Grade.unique()], names=('Indicator', 'Grade'))
df_multi = pd.DataFrame(np.c_[(np.random.randn(8,4)*5 + 163).tolist(), (np.random.randn(8,4)*5 + 65).tolist()],
index = multi_index, columns = multi_column).round(1)
print(df_multi)
#Indicator Height Weight
#Grade Freshman Senior Sophomore Junior Freshman Senior Sophomore Junior
#School Gender
#A Female 171.8 165.0 167.9 174.2 60.6 55.1 63.3 65.8
# Male 172.3 158.1 167.8 162.2 71.2 71.0 63.1 63.5
#B Female 162.5 165.1 163.7 170.3 59.8 57.9 56.5 74.8
# Male 166.8 163.6 165.2 164.7 62.5 62.8 58.7 68.9
#C Female 170.5 162.0 164.6 158.7 56.9 63.9 60.5 66.9
# Male 150.2 166.3 167.3 159.3 62.4 59.1 64.9 67.1
#D Female 174.3 155.7 163.2 162.1 65.3 66.5 61.8 63.2
# Male 170.7 170.3 163.8 164.9 61.6 63.2 60.9 56.4与单层索引类似,MultiIndex也具有名字属性,图中的School和Gender分别对应了表的第一层和第二层行索引的名字,Indicator和Grade分别对应了第一层和第二层列索引的名字。
索引的名字和值属性分别可以通过names和values获得
python
print(df_multi.index.names)
#['School', 'Gender']
print(df_multi.columns.names)
#['Indicator', 'Grade']
print(df_multi.index.values)
#[('A', 'Female') ('A', 'Male') ('B', 'Female') ('B', 'Male')
# ('C', 'Female') ('C', 'Male') ('D', 'Female') ('D', 'Male')]
print(df_multi.columns.values)
#[('Height', 'Freshman') ('Height', 'Senior') ('Height', 'Sophomore')
# ('Height', 'Junior') ('Weight', 'Freshman') ('Weight', 'Senior')
# ('Weight', 'Sophomore') ('Weight', 'Junior')]如果想要得到某一层的索引,则需要通过get_level_values获得:
python
print(df_multi.index.get_level_values(0))
#Index(['A', 'A', 'B', 'B', 'C', 'C', 'D', 'D'], dtype='object', name='School')多级索引中的loc索引器
将学校和年级设为索引,此时的行为多级索引,列为单级索引,由于默认状态的列索引不含名字,因此对应于刚刚图中Indicator和Grade的索引名位置是空缺的。
python
df_multi = df.set_index(['School', 'Grade'])
print(df_multi.head())
# Name ... Time_Record
#School Grade ...
#Shanghai Jiao Tong University Freshman Gaopeng Yang ... 0:04:34
#Peking University Freshman Changqiang You ... 0:04:20
#Shanghai Jiao Tong University Senior Mei Sun ... 0:05:22
#Fudan University Sophomore Xiaojuan Sun ... 0:04:08
# Sophomore Gaojuan You ... 0:05:22
#
#[5 rows x 8 columns]由于多级索引中的单个元素以元组为单位,因此 loc 和 iloc 方法完全可以照搬,只需把标量的位置替换成对应的元组。
当传入元组列表或单个元组或返回前二者的函数时,需要先进行索引排序以避免性能警告:
python
df_sorted = df_multi.sort_index()
print(df_sorted.loc[('Fudan University', 'Junior')].head())
# Name Gender ... Test_Date Time_Record
#School Grade ...
#Fudan University Junior Yanli You Female ... 2019/9/23 0:03:34
# Junior Chunqiang Chu Male ... 2019/10/16 0:03:58
# Junior Changfeng Lv Male ... 2019/9/11 0:04:35
# Junior Yanjuan Lv Female ... 2019/9/3 0:03:39
# Junior Gaoqiang Zhou Female ... 2019/11/4 0:04:34
#
#[5 rows x 8 columns]
print(df_sorted.loc[[('Fudan University', 'Senior'), ('Shanghai Jiao Tong University', 'Freshman')]].head())
# Name Gender ... Test_Date Time_Record
#School Grade ...
#Fudan University Senior Chengpeng Zheng Female ... 2019/11/1 0:03:39
# Senior Feng Zhou Female ... 2019/11/18 0:04:59
# Senior Gaomei Lv Female ... 2019/10/16 0:03:44
# Senior Chunli Lv Female ... 2019/11/12 0:03:53
# Senior Chengpeng Zhou Male ... 2019/9/5 0:03:38
#
#[5 rows x 8 columns]
print(df_sorted.loc[df_sorted.Weight > 70].head()) # 布尔列表也是可用的
# Name Gender ... Test_Date Time_Record
#School Grade ...
#Fudan University Freshman Feng Wang Male ... 2019/9/26 0:03:31
# Junior Chunqiang Chu Male ... 2019/10/16 0:03:58
# Junior Changfeng Lv Male ... 2019/9/11 0:04:35
# Senior Chengpeng Zhou Male ... 2019/9/5 0:03:38
# Senior Chengpeng Qian Male ... 2019/12/19 0:05:18
#
#[5 rows x 8 columns]
print(df_sorted.loc[lambda x:('Fudan University','Junior')].head())
# Name Gender ... Test_Date Time_Record
#School Grade ...
#Fudan University Junior Yanli You Female ... 2019/9/23 0:03:34
# Junior Chunqiang Chu Male ... 2019/10/16 0:03:58
# Junior Changfeng Lv Male ... 2019/9/11 0:04:35
# Junior Yanjuan Lv Female ... 2019/9/3 0:03:39
# Junior Gaoqiang Zhou Female ... 2019/11/4 0:04:34
#
#[5 rows x 8 columns]当使用切片时需要注意,在单级索引中只要切片端点元素是唯一的,那么就可以进行切片,但在多级索引中,无论元组在索引中是否重复出现,都必须经过排序才能使用切片,否则报错:
python
df_sorted = df_multi.sort_index()
print(df_sorted.loc[('Fudan University', 'Senior'):].head())
# Name Gender ... Test_Date Time_Record
#School Grade ...
#Fudan University Senior Chengpeng Zheng Female ... 2019/11/1 0:03:39
# Senior Feng Zhou Female ... 2019/11/18 0:04:59
# Senior Gaomei Lv Female ... 2019/10/16 0:03:44
# Senior Chunli Lv Female ... 2019/11/12 0:03:53
# Senior Chengpeng Zhou Male ... 2019/9/5 0:03:38
#
#[5 rows x 8 columns]
df_unique = df.drop_duplicates(subset=['School','Grade']).set_index(['School', 'Grade'])
print(df_unique.head())
# Name ... Time_Record
#School Grade ...
#Shanghai Jiao Tong University Freshman Gaopeng Yang ... 0:04:34
#Peking University Freshman Changqiang You ... 0:04:20
#Shanghai Jiao Tong University Senior Mei Sun ... 0:05:22
#Fudan University Sophomore Xiaojuan Sun ... 0:04:08
#Tsinghua University Freshman Xiaoli Qian ... 0:03:47
#
#[5 rows x 8 columns]
print(df_unique.sort_index().loc[('Fudan University', 'Senior'):].head())
# Name Gender ... Test_Date Time_Record
#School Grade ...
#Fudan University Senior Chengpeng Zheng Female ... 2019/11/1 0:03:39
# Sophomore Xiaojuan Sun Female ... 2020/1/3 0:04:08
#Peking University Freshman Changqiang You Male ... 2019/9/4 0:04:20
# Junior Juan Xu Female ... 2019/10/5 0:04:05
# Senior Changli Lv Female ... 2019/11/13 0:04:54
#
#[5 rows x 8 columns]此外,在多级索引中的元组有一种特殊的用法,可以对多层的元素进行交叉组合后索引,但同时需要指定loc的列,全选则用:表示。其中,每一层需要选中的元素用列表存放,传入loc的形式为[(level_0_list, level_1_list), cols]。
python
res = df_multi.loc[(['Peking University', 'Fudan University'], ['Sophomore', 'Junior']), :]
print(res.head())
# Name Gender ... Test_Date Time_Record
#School Grade ...
#Peking University Sophomore Changmei Xu Female ... 2020/1/3 0:04:28
# Sophomore Xiaopeng Qin Male ... 2019/12/23 0:05:29
# Sophomore Mei Xu Female ... 2019/11/5 0:04:29
# Sophomore Xiaoli Zhou Female ... 2019/10/28 0:05:24
# Sophomore Peng Han Female ... 2019/9/19 0:03:32
#
#[5 rows x 8 columns]
print(res.shape)
#(33, 8)IndexSlice对象
即使在索引不重复的时候,也只能对元组整体进行切片,而不能对每层进行切片,也不允许将切片和布尔列表混合使用,引入IndexSlice对象就能解决这个问题。Slice对象一共有两种形式,第一种为loc[idx[*,*]]型,第二种为loc[idx[*,*],idx[*,*]]型。
python
import pandas as pd
import numpy as np
df = pd.read_csv('data/learn_pandas.csv')
np.random.seed(0)
L1,L2 = ['A','B','C'],['a','b','c']
mul_index1 = pd.MultiIndex.from_product([L1,L2],names=('Upper', 'Lower'))
L3,L4 = ['D','E','F'],['d','e','f']
mul_index2 = pd.MultiIndex.from_product([L3,L4],names=('Big', 'Small'))
df_ex = pd.DataFrame(np.random.randint(-9,10,(9,9)), index=mul_index1, columns=mul_index2)
print(df_ex)
#Big D E F
#Small d e f d e f d e f
#Upper Lower
#A a 3 6 -9 -6 -6 -2 0 9 -5
# b -3 3 -8 -3 -2 5 8 -4 4
# c -1 0 7 -4 6 6 -9 9 -6
#B a 8 5 -2 -9 -8 0 -9 1 -6
# b 2 9 -7 -9 -9 -5 -4 -3 -1
# c 8 6 -5 0 1 -8 -8 -2 0
C a -6 -3 2 5 9 -9 5 -6 3
b 1 2 -5 -3 -5 6 -6 3 -5
c -1 5 6 -6 6 4 7 8 -4
idx = pd.IndexSlice
print(df_ex.loc['C':,('D','F'):])
Big D E F
Small d e f d e f d e f
Upper Lower
C a -6 -3 2 5 9 -9 5 -6 3
b 1 2 -5 -3 -5 6 -6 3 -5
c -1 5 6 -6 6 4 7 8 -4
print(df_ex.loc[idx[:'A', lambda x:x.sum()>0]]) # 列和大于0loc[idx[*,*],idx[*,*]]型
这种情况能够分层进行切片,前一个idx指代的是行索引,后一个是列索引。
python
print(df_ex.loc[idx[:'A', 'b':], idx['E':, 'e':]])
#Big E F
#Small e f e f
#Upper Lower
#A b -2 5 -4 4
# c 6 6 9 -6
#注意:不支持使用函数多级索引的构造
自己构造多级索引,常用的有from_tuples, from_arrays, from_product三种方法,它们都是pd.MultiIndex对象下的函数。
from_tuples指根据传入由元组组成的列表进行构造
python
my_tupls = [('a','cat'),('a','dog'),('b','cat'),('b','dog')]
print(pd.MultiIndex.from_tuples(my_tupls,names=['First','Second']))
#MultiIndex([('a', 'cat'),
# ('a', 'dog'),
# ('b', 'cat'),
# ('b', 'dog')],
# names=['First', 'Second'])from_arrays指根据传入列表中,对应层的列表进行构造
python
my_array = [list('aabb'), ['cat', 'dog']*2]
print(pd.MultiIndex.from_arrays(my_array, names=['First','Second']))
#MultiIndex([('a', 'cat'),
# ('a', 'dog'),
# ('b', 'cat'),
# ('b', 'dog')],
# names=['First', 'Second'])from_product指根据给定多个列表的笛卡尔积进行构造
python
my_list1 = ['a','b']
my_list2 = ['cat','dog']
print(pd.MultiIndex.from_product([my_list1, my_list2], names=['First','Second']))
#MultiIndex([('a', 'cat'),
# ('a', 'dog'),
# ('b', 'cat'),
# ('b', 'dog')],
# names=['First', 'Second'])索引的常用方法
创建3级索引例子
python
import numpy as np
import pandas as pd
np.random.seed(0)
L1,L2,L3 = ['A','B'],['a','b'],['alpha','beta']
mul_index1 = pd.MultiIndex.from_product([L1,L2,L3], names=('Upper', 'Lower','Extra'))
L4,L5,L6 = ['C','D'],['c','d'],['cat','dog']
mul_index2 = pd.MultiIndex.from_product([L4,L5,L6], names=('Big', 'Small', 'Other'))
df_ex = pd.DataFrame(np.random.randint(-9,10,(8,8)), index=mul_index1, columns=mul_index2)
print(df_ex)
#Big C D
#Small c d c d
#Other cat dog cat dog cat dog cat dog
#Upper Lower Extra
#A a alpha 3 6 -9 -6 -6 -2 0 9
# beta -5 -3 3 -8 -3 -2 5 8
# b alpha -4 4 -1 0 7 -4 6 6
# beta -9 9 -6 8 5 -2 -9 -8
#B a alpha 0 -9 1 -6 2 9 -7 -9
# beta -9 -5 -4 -3 -1 8 6 -5
# b alpha 0 1 -8 -8 -2 0 -6 -3
# beta 2 5 9 -9 5 -6 3 1索引层的交换和删除
索引层的交换由swaplevel和reorder_levels完成,前者只能交换两个层,而后者可以交换任意层,两者都可以指定交换的是轴是哪一个,即行索引或列索引:
python
print(df_ex.swaplevel(0,2,axis=1).head()) # 列索引的第一层和第三层交换
#Other cat dog cat dog cat dog cat dog
#Small c c d d c c d d
#Big C C C C D D D D
#Upper Lower Extra
#A a alpha 3 6 -9 -6 -6 -2 0 9
# beta -5 -3 3 -8 -3 -2 5 8
# b alpha -4 4 -1 0 7 -4 6 6
# beta -9 9 -6 8 5 -2 -9 -8
#B a alpha 0 -9 1 -6 2 9 -7 -9
print(df_ex.reorder_levels([2,0,1],axis=0).head()) # 列表数字指代原来索引中的层
#Big C D
#Small c d c d
#Other cat dog cat dog cat dog cat dog
#Extra Upper Lower
#alpha A a 3 6 -9 -6 -6 -2 0 9
#beta A a -5 -3 3 -8 -3 -2 5 8
#alpha A b -4 4 -1 0 7 -4 6 6
#beta A b -9 9 -6 8 5 -2 -9 -8
#alpha B a 0 -9 1 -6 2 9 -7 -9若想要删除某一层的索引,可以使用droplevel方法
python
print(df_ex.droplevel(1,axis=1))
#Big C D
#Other cat dog cat dog cat dog cat dog
#Upper Lower Extra
#A a alpha 3 6 -9 -6 -6 -2 0 9
# beta -5 -3 3 -8 -3 -2 5 8
# b alpha -4 4 -1 0 7 -4 6 6
# beta -9 9 -6 8 5 -2 -9 -8
#B a alpha 0 -9 1 -6 2 9 -7 -9
# beta -9 -5 -4 -3 -1 8 6 -5
# b alpha 0 1 -8 -8 -2 0 -6 -3
# beta 2 5 9 -9 5 -6 3 1
print(df_ex.droplevel([0,1],axis=0))
#Big C D
#Small c d c d
#Other cat dog cat dog cat dog cat dog
#Extra
#alpha 3 6 -9 -6 -6 -2 0 9
#beta -5 -3 3 -8 -3 -2 5 8
#alpha -4 4 -1 0 7 -4 6 6
#beta -9 9 -6 8 5 -2 -9 -8
#alpha 0 -9 1 -6 2 9 -7 -9
#beta -9 -5 -4 -3 -1 8 6 -5
#alpha 0 1 -8 -8 -2 0 -6 -3
#beta 2 5 9 -9 5 -6 3 1索引属性的修改
通过rename_axis可以对索引层的名字进行修改,常用的修改方式是传入字典的映射
python
print(df_ex.rename_axis(index={'Upper':'Changed_row'}, columns={'Other':'Changed_Col'}).head())
#Big C D
#Small c d c d
#Changed_Col cat dog cat dog cat dog cat dog
#Changed_row Lower Extra
#A a alpha 3 6 -9 -6 -6 -2 0 9
# beta -5 -3 3 -8 -3 -2 5 8
# b alpha -4 4 -1 0 7 -4 6 6
# beta -9 9 -6 8 5 -2 -9 -8
#B a alpha 0 -9 1 -6 2 9 -7 -9通过rename可以对索引的值进行修改,如果是多级索引需要指定修改的层号level
python
print(df_ex.rename(columns={'cat':'not_cat'}, level=2).head())
#Big C D
#Small c d c d
#Other not_cat dog not_cat dog not_cat dog not_cat dog
#Upper Lower Extra
#A a alpha 3 6 -9 -6 -6 -2 0 9
# beta -5 -3 3 -8 -3 -2 5 8
# b alpha -4 4 -1 0 7 -4 6 6
# beta -9 9 -6 8 5 -2 -9 -8
#B a alpha 0 -9 1 -6 2 9 -7 -9传入参数也可以是函数,其输入值就是索引元素
python
print(df_ex.rename(index=lambda x:str.upper(x), level=2).head())
#Big C D
#Small c d c d
#Other cat dog cat dog cat dog cat dog
#Upper Lower Extra
#A a ALPHA 3 6 -9 -6 -6 -2 0 9
# BETA -5 -3 3 -8 -3 -2 5 8
# b ALPHA -4 4 -1 0 7 -4 6 6
# BETA -9 9 -6 8 5 -2 -9 -8
#B a ALPHA 0 -9 1 -6 2 9 -7 -9整个索引的元素替换,可以利用迭代器实现
python
new_values = iter(list('abcdefgh'))
print(df_ex.rename(index=lambda x:next(new_values), level=2))
#Big C D
#Small c d c d
#Other cat dog cat dog cat dog cat dog
#Upper Lower Extra
#A a a 3 6 -9 -6 -6 -2 0 9
# b -5 -3 3 -8 -3 -2 5 8
# b c -4 4 -1 0 7 -4 6 6
# d -9 9 -6 8 5 -2 -9 -8
#B a e 0 -9 1 -6 2 9 -7 -9
# f -9 -5 -4 -3 -1 8 6 -5
# b g 0 1 -8 -8 -2 0 -6 -3
# h 2 5 9 -9 5 -6 3 1函数map,它是定义在Index上的方法,与前面rename方法中层的函数式用法是类似的,只不过它传入的不是层的标量值,而是直接传入索引的元组,这为用户进行跨层的修改提供了遍历。
python
df_temp = df_ex.copy()
new_idx = df_temp.index.map(lambda x: (x[0], x[1], str.upper(x[2])))
df_temp.index = new_idx
print(df_temp.head())
#Big C D
#Small c d c d
#Other cat dog cat dog cat dog cat dog
#Upper Lower Extra
#A a ALPHA 3 6 -9 -6 -6 -2 0 9
# BETA -5 -3 3 -8 -3 -2 5 8
# b ALPHA -4 4 -1 0 7 -4 6 6
# BETA -9 9 -6 8 5 -2 -9 -8
#B a ALPHA 0 -9 1 -6 2 9 -7 -9索引的设置和重置
python
df_new = pd.DataFrame({'A':list('aacd'), 'B':list('PQRT'), 'C':[1,2,3,4]})
print(df_new)
# A B C
#0 a P 1
#1 a Q 2
#2 c R 3
#3 d T 4
#索引的设置可以使用`set_index`完成,这里的主要参数是`append`,表示是否来保留原来的索引,直接把新设定的添加到原索引的内层
print(df_new.set_index('A'))
# B C
#A
#a P 1
#a Q 2
#c R 3
#d T 4
print(df_new.set_index('A', append=True))
# B C
# A
#0 a P 1
#1 a Q 2
#2 c R 3
#3 d T 4
#可以同时指定多个列作为索引
print(df_new.set_index(['A', 'B']))
# C
#A B
#a P 1
# Q 2
#c R 3
#d T 4
#如果想要添加索引的列没有出现在其中,那么可以直接在参数中传入相应的Series
my_index = pd.Series(list('WXYZ'), name='D')
df_new = df_new.set_index(['A', my_index])
print(df_new)
# B C
#A D
#a W P 1
# X Q 2
#c Y R 3
#d Z T 4
#reset_index是set_index的逆函数,其主要参数是drop,表示是否要把去掉的索引层丢弃,而不是添加到列中
print(df_new.reset_index(['D']))
# D B C
#A
#a W P 1
#a X Q 2
#c Y R 3
#d Z T 4
print(df_new.reset_index(['D'], drop=True))
# B C
#A
#a P 1
#a Q 2
#c R 3
#d T 4
#如果重置了所有的索引,那么`pandas`会直接重新生成一个默认索引
print(df_new.reset_index())
# A D B C
#0 a W P 1
#1 a X Q 2
#2 c Y R 3
#3 d Z T 4索引的变形
对索引做一些扩充或者剔除,更具体地要求是给定一个新的索引,把原表中相应的索引对应元素填充到新索引构成的表中
python
df_reindex = pd.DataFrame({"Weight":[60,70,80], "Height":[176,180,179]}, index=['1001','1003','1002'])
print(df_reindex)
# Weight Height
#1001 60 176
#1003 70 180
#1002 80 179
print(df_reindex.reindex(index=['1001','1002','1003','1004'], columns=['Weight','Gender']))
# Weight Gender
#1001 60.0 NaN
#1002 80.0 NaN
#1003 70.0 NaN
#1004 NaN NaN这种需求常出现在时间序列索引的时间点填充以及ID编号的扩充。另外,需要注意的是原来表中的数据和新表中会根据索引自动对齐,例如原先的1002号位置在1003号之后,而新表中相反,那么reindex中会根据元素对齐,与位置无关。
还有一个与reindex功能类似的函数是reindex_like,其功能是仿照传入的表索引来进行被调用表索引的变形。
python
df_reindex = pd.DataFrame({"Weight":[60,70,80], "Height":[176,180,179]}, index=['1001','1003','1002'])
df_existed = pd.DataFrame(index=['1001','1002','1003','1004'], columns=['Weight','Gender'])
print(df_reindex.reindex_like(df_existed))
# Weight Gender
#1001 60.0 NaN
#1002 80.0 NaN
#1003 70.0 NaN
#1004 NaN NaN索引运算
集合的运算法则
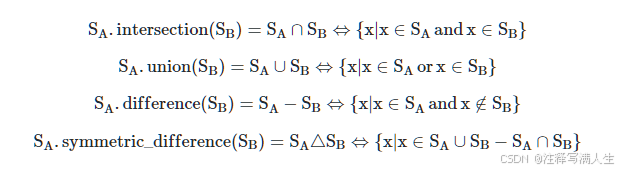
一般的索引运算
由于集合的元素是互异的,但是索引中可能有相同的元素,先用unique去重后再进行运算。
python
df_set_1 = pd.DataFrame([[0,1],[1,2],[3,4]], index = pd.Index(['a','b','a'],name='id1'))
df_set_2 = pd.DataFrame([[4,5],[2,6],[7,1]], index = pd.Index(['b','b','c'],name='id2'))
id1, id2 = df_set_1.index.unique(), df_set_2.index.unique()
print(id1.intersection(id2)) #Index(['b'], dtype='object')
print(id1.union(id2)) #Index(['a', 'b', 'c'], dtype='object')
print(id1.difference(id2)) #Index(['a'], dtype='object')
print(id1.symmetric_difference(id2)) #Index(['a', 'c'], dtype='object')若两张表需要做集合运算的列并没有被设置索引,一种办法是先转成索引,运算后再恢复,另一种方法是利用isin函数,例如在重置索引的第一张表中选出id列交集的所在行