Few-Shot Object Detection: A Comprehensive Survey
Abstract
- 人类甚至能够从几个例子中学会识别新物体。相比之下,训练基于深度学习的目标检测器需要大量带注释的数据。为了避免获取和注释这些大量数据的需要,少样本对象检测(FSOD)旨在从目标域中新类别的少数对象实例中学习。在本次调查中,我们概述了 FSOD 的最新技术。我们根据训练计划和架构布局对方法进行分类。对于每种类型的方法,我们描述了一般实现以及提高新类别性能的概念。在适当的时候,我们会给出有关这些概念的简短要点,以突出最好的想法。最后,我们介绍常用的数据集及其评估协议,并分析报告的基准结果。因此,我们强调评估中的常见挑战,并确定 FSOD 这一新兴领域中最有前途的当前趋势。
- 少样本目标检测(FSOD) 是应对深度学习目标检测对海量标注数据依赖的新兴领域,旨在通过少量(K-shot,K 通常为 1-30)标注样本 检测新类别目标,核心分为元学习 (含双分支、单分支架构,依赖 episodic 训练和特征聚合)和迁移学习 (基于简单微调,聚焦梯度流优化与知识迁移)两大类方法,关键技术包括注意力机制、度量学习、数据增强等;常用数据集为 PASCAL VOC(20 类) 和 Microsoft COCO(80 类),评估以平均精度(AP)为核心指标;当前趋势包括技术优化(如 Transformer 融合)、跨领域扩展(半监督、弱监督),面临数据集真实性不足、领域迁移等挑战,两类方法各有优劣且可相互借鉴。
INTRODUCTION
-
在过去的十年中,对象检测通过深度学习得到了巨大的改进。然而,基于深度学习的方法通常需要大量的训练数据。因此,很难将它们应用于涉及常见对象检测数据集中不存在的新对象的现实场景。注释大量图像以进行对象检测既昂贵又烦人。在某些情况下,例如医学应用 或稀有物种的检测,甚至不可能获取大量图像。此外,与典型的基于深度学习的方法相比,人类即使在很小的时候就能够用很少的数据学习新概念。当孩子们看到新的物体时,即使他们只见过一次或几次,他们也能够识别这些物体。
-
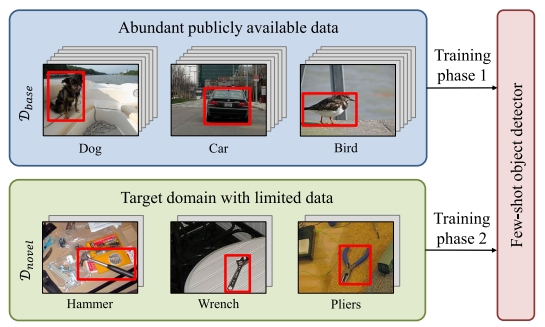
因此,该方向一个有前景的研究领域是少样本目标检测(FSOD)。 FSOD 的目标是在第一阶段对大量公开可用数据进行预训练后,仅用很少的注释实例来检测新颖的对象,如图 1 所示。因此,它减轻了在目标域中注释大量数据的负担。
-
-
图 1.总体思路:通过首先在具有丰富注释边界框的基础数据集上进行训练,可以将少样本对象检测器应用于仅具有很少注释对象实例的设置,例如机械工具。
-
-
在本次调查中,我们旨在为这一新兴研究领域的新研究人员提供最先进的 FSOD 方法概述。首先,我们定义 FSOD 问题。然后,我们对当前的方法进行分类,并强调相似性和差异性。随后,我们介绍常用的数据集并提供基准结果。最后,我们强调评估中的常见挑战,并确定有前途的研究方向以指导未来的研究。
-
深度学习目标检测(如 Faster R-CNN、YOLO)需海量标注数据,而医疗成像、稀有物种检测等场景中,数据获取 / 标注成本高甚至不可行。人类可通过 1 - 少数次示例识别新物体,FSOD 模仿该能力。先在基础数据集(D_base)预训练,再通过少量新类别样本(D_novel)适配,缓解目标域标注负担。
-
总数据集 D=Dbase∪DnovelD = D_{base} \cup D_{novel}D=Dbase∪Dnovel,基础类别 CbaseC_{base}Cbase 与新类别 CnovelC_{novel}Cnovel 无交集(Cbase∩Cnovel=∅C_{base} \cap C_{novel} = \emptysetCbase∩Cnovel=∅)。每个样本含图像 IiI_iIi 和目标标注(类别 c + 边界框 b=(x,y,w,h)b = (x,y,w,h)b=(x,y,w,h))。
-
N-way K-shot 检测:K-shot:每类新类别含 K 个标注样本(K=1 时为 one-shot,最具挑战性)。N-way:需检测 N 个新类别(N≤∣Cnovel∣N \leq |C_{novel}|N≤∣Cnovel∣)。仅用 D_novel 训练易过拟合;直接用 Dbase∪DnovelD_{base} \cup D_{novel}Dbase∪Dnovel 训练易偏向基础类别。
PROBLEM DEFINITION
-
FSOD 旨在检测仅具有很少注释实例的新颖对象。形式上,训练数据集 D=Dbase∪DnovelD = D_{base} ∪ D_{novel}D=Dbase∪Dnovel 分为两个数据集 Dbase和DnovelD_{base} 和 D_{novel}Dbase和Dnovel,其中包含基本类别 CbaseC_{base}Cbase 和 新颖类别 CnovelC_{novel}Cnovel 的非重叠集,其中 Cbase∩Cnovel=∅C_{base} ∩ C_{novel} = ∅Cbase∩Cnovel=∅。每个元组 (I_i, \\hat y_{o1} , . . . ,\\hat y_{oM}) ∈ D 由图像 Ii={o1,...,y^oM)I_i = \{o_1, . . . ,\hat y_{oM})Ii={o1,...,y^oM) 组成 包含 M 个对象 o1,....、oMo_1, . ... 、 o_Mo1,....、oM 及其相应标签 y^oi={coi,boi}\hat y_{oi} = \{c_{oi} , b_{oi}\}y^oi={coi,boi},包括类别 coic_{oi}coi 和边界框 boi={xoi,yoi,woi,hoi}b_{oi} = \{x_{oi} , y_{oi} , w_{oi} , h_{oi}\}boi={xoi,yoi,woi,hoi} ,坐标为 (xoi,yoi)(x_{oi} , y_{oi} )(xoi,yoi)、宽度 woiw_{oi}woi 和高度 hoih_{oi}hoi 。对于基本类别 CbaseC_{base}Cbase,基本数据集 DbaseD_{base}Dbase 中有丰富的训练数据。
-
相比之下,新颖数据集 DnovelD_{novel}Dnovel 仅包含 CnovelC_{novel}Cnovel 中每个小说类别的少量带注释的对象实例。对于 K-shot 对象检测任务,CnovelC_{novel}Cnovel 中的每个类别恰好有 K 个带注释的对象实例可用。因此,带注释的新颖对象实例的数量 ∣{oj∈Ii∀Ii∈Dnovel}∣=K⋅∣Cnovel∣|\{o_j ∈ I_i∀I_i ∈ D_{novel}\}| = K·|C_{novel}|∣{oj∈Ii∀Ii∈Dnovel}∣=K⋅∣Cnovel∣ 相对较小。请注意,带注释的对象实例的数量不一定对应于图像的数量,因为一张图像可能包含多个实例。 FSOD 最困难的情况是一次性对象检测,其中 K = 1。N 路对象检测表示一种检测器,旨在检测 N 个新类别中的对象实例,其中 N≤∣Cnovel∣N ≤ |C_{novel}|N≤∣Cnovel∣。因此,FSOD 通常被称为 N 路 K 样本检测。
-
由于训练数据有限 ,仅在 DnovelD_{novel}Dnovel 上训练目标检测器很快会导致过度拟合和泛化不良。然而,对高度不平衡的组合数据 D=Dnovel∪DbaseD = D_{novel} ∪ D_{base}D=Dnovel∪Dbase 进行训练通常会导致检测器严重偏向基本类别,因此无法正确检测新类别中的实例。因此,当前的研究重点是 FSOD 的新方法。通常,配备有针对分类数据进行预训练的主干的初始检测器模型 MinitM_{init}Minit 首先在 DbaseD_{base}Dbase 上进行训练,从而产生基础模型 MbaseM_{base}Mbase。大多数方法然后在数据 Dfinetune⊆DD_{finetune} ⊆ DDfinetune⊆D 上训练 MbaseM_{base}Mbase,包括新类别 CnovelC_{novel}Cnovel,产生最终模型 MfinalM_{final}Mfinal.
- Minit→Dbase→Mbase→Dfinetune→Mfinal.(1) M_{init}\rightarrow^{Dbase}\rightarrow M_{base}\rightarrow^{D_{finetune}}\rightarrow M^{final}. (1) Minit→Dbase→Mbase→Dfinetune→Mfinal.(1)
RELATED WORK ON TRAINING WITH LIMITED DATA
-
有一些相关的研究领域也专注于有限数据的训练。下面我们简单讨论一下与 FSOD 的异同。
| 研究领域 | 核心特点 | 与 FSOD 的关联 |
|---|---|---|
| 少样本分类 | 无需定位,仅分类,数据需求低 | 技术可迁移(如度量学习) |
| 半监督学习 | 少量标注 + 大量无标注数据 | 可补充新类别数据方差 |
| 增量学习 | 避免新增类别时 "灾难性遗忘" | FSOD 部分方法整合该技术 |
| 跨域检测 | 相同类别,不同域适配(如合成→真实) | 类别不变,与 FSOD 核心差异 |
| 零样本检测 | K=0,依赖语义嵌入 | 极端场景,FSOD 的延伸 |
| 弱监督检测 | 仅图像级标注,无边界框 | 降低标注成本,与 FSOD 互补 |
A. Related Concepts for Learning With Limited Data
-
少样本学习和分类:在应用于检测之前,少样本学习首先被探索用于分类任务。由于只有很少训练实例的对象不需要定位,分类显然更容易。然而,FSOD 可以采用许多想法。
-
半监督学习与少样本学习相关,因为只有少数目标类别的标记实例可用。然而,与少样本学习相反,大量额外的未标记数据通常可以帮助学习适当的表示。因此,当有额外的未标记数据可用时,应考虑使用半监督学习方法来改进少样本学习方法中的学习表示。
-
增量学习:当模型接受新数据训练时,典型的深度学习方法会遭受灾难性遗忘。相比之下,增量学习方法旨在在增量添加新类别时保留旧类别的性能。一些 FSOD 方法还结合了增量学习技术。
B. Object Detection
-
通用对象检测是对检测器所训练的类别的对象实例进行本地化和分类的联合任务。感兴趣区域 (RoI) 通过边界框的坐标进行定位,并分为一组预定义的类别。所有其他对象类别(不属于训练类别的一部分)都被视为背景,并且检测器经过训练以抑制这些其他类别的检测。虽然取得了令人印象深刻的结果,但这些方法需要每个类别大量带注释的对象实例,并且在应用于少样本情况时通常会失败。对于该领域的新研究人员,我们参考有关该主题的综合调查。
-
跨域目标检测是首先在丰富的标记数据上训练检测器,然后使该检测器适应具有有限数据的不同域的任务;一个典型的例子是合成到真实。然而,与 FSOD 不同的是,这些类别在不同的域中保持相同。
-
零样本目标检测的定义与 FSOD 类似。然而,作为极端情况,带注释的对象实例的数量为零(K = 0)。零样本检测器通常结合语义词嵌入,即语义相似的类别会导致嵌入空间中的相似特征。这适用于检测日常物体,这些物体可以很容易地标记,但当提供特定标签很困难或需要区分非常相似的物体时可能会出现问题。
-
弱监督对象检测放宽了所需的注释,使得训练数据仅包含图像级标签,即图像中某处是否存在特定对象类别。这些注释更容易获得,通常可以通过关键字搜索来获得。弱监督对象检测器面临的挑战是在训练期间没有任何定位信息的情况下检测所有对象实例。尽管减轻了注释负担,但弱监督对象检测器仍然需要大量图像,这对于检测稀有对象可能很难获得。
C. Learning Techniques for FSOD
-
除了上述相关研究领域外,下面我们还将讨论 FSOD 中广泛采用的学习技术。
-
迁移学习是指重用在基线数据集上预训练的网络权重,以提高在有限数据的新领域上的泛化能力。与少样本学习和检测一样,这通常涉及目标领域的新类别。然而,与小样本学习不同,新类别的对象实例数量不一定很小。因此,从少量数据中学习的技术需要纳入 FSOD 的迁移学习方法中。
-
度量学习的目的是学习一种嵌入,其中具有相似内容的输入被编码为在度量方面彼此距离较小的特征,而来自不同输入的编码特征应该相距很远。为了学习具有低类内距离和高类间 ℓ 2 距离的特征,通常使用三元组损失或其扩展。由于这种学习到的特征嵌入通常可以很好地概括,因此该模型还可以应用于对训练期间未知的新类别实例进行编码,并做出基于度量的决策,而无需重新训练 。在少样本分类的背景下,这意味着在推理过程中,模型提取 DnovelD_{novel}Dnovel 的少数带注释示例以及相应测试图像的特征嵌入。然后将测试图像分配给带注释的示例的最接近特征嵌入的类别。然而,对于少样本检测,需要集成用于定位图像中实例的概念。
-
元学习方法学习如何学习以泛化新任务或新数据。对于少样本学习,这意味着这些方法学习如何学习对给定输入进行分类,即使类别在训练期间不固定。这些方法需要了解如何最有效地学习有关类别的所需知识,以便也可以通过很少的训练示例来学习新类别的类别知识。
D. Related Surveys
- 尽管还有其他关于 FSOD 的调查,但它们并没有像我们那样涵盖与 FSOD 相关的那么多出版物。作品是更广泛的调查,也解决了自监督、弱监督和/或零样本学习,并且不太关注 FSOD。作品 仅涵盖 FSOD 的早期工作,因此有些过时,因为至少缺少一些当前在常见基准上表现最佳的方法。由于工作 没有英语版本,因此只有有限的研究人员可以访问。总的来说,我们的调查与最相关,因为它还根据这些概念阐述了几个核心概念和组方法。然而,通过图4、7和9中的视觉分类法。 我们使读者能够更快地掌握哪些方法遵循相似的概念以及哪些概念似乎可以很好地相互补充。我们还通过强调评估协议和具有可比评估的分组方法的差异,为基准结果提供更好的指导。此外,我们提供了更全面的调查,涵盖的 FSOD 论文数量几乎是 的两倍。
CATEGORIZATION OF FSOD APPROACHES
-
FSOD 方法结合了新颖的想法,以便能够仅用很少的训练示例来检测对象。一般来说,基础类别 CbaseC_{base}Cbase 的丰富训练示例用于利用有限标记数据的新类别 CnovelC_{novel}Cnovel 的知识。
-
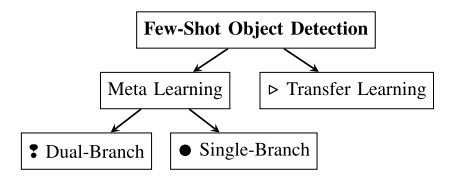
我们将 FSOD 方法分为元学习和迁移学习方法,如图 2 所示。我们进一步将元学习方法分为单分支和双分支架构。双分支架构由查询和支持网络分支构成,即网络分别处理两个输入(查询和支持图像)。单分支方法通常类似于通用检测器的架构,但在新类别训练或利用度量学习时减少了可学习参数的数量。
-
-
图 2. FSOD 方法的分类。
-
-
然而,一些双分支架构和一些迁移学习方法也融合了度量学习的思想。因此,为了避免分类不明确,我们不会像 FSOD 的早期工作那样将度量学习作为一个单独的类别。相反,我们通过训练方案和架构方面进行区分,这更好地反映了当前技术水平的不同趋势。FSOD 是一个相当年轻但新兴的研究领域,因为大多数方法仅在过去三年内发表。大多数方法使用迁移学习或双分支元学习。
-
接下来,我们首先在第五节中描述双分支元学习方法。我们从元学习的一般训练方案开始,然后是典型的实现。下面,我们描述具体方法如何偏离一般实现。在第六节中,我们重点关注单分支元学习方法。尽管没有其他人偏离的共同认识,但我们仍然对他们的主要思想进行分组。在第 VI-D 节中,我们介绍了迁移学习方法。与双分支元学习方法类似,我们首先描述一般实现,然后转向修改。只要适当,我们就会在各小节的末尾给出简短的要点,以突出关键见解。一些要点还包含引文,将概念与关于第九节中基准的具体表现良好的方法联系起来。
-
此外,我们在相应部分的末尾总结了每个训练方案的最佳表现方法。最后,在第八节中,我们在第九节中讨论常见数据集和基准结果之前,对元学习和迁移学习方法进行了比较。
DUAL-BRANCH META LEARNING
-
许多 FSOD 方法都利用元学习来学习如何泛化新类别。在本节中,我们首先在第 V-A 节中描述元学习的一般训练方案。为了实现元学习,双分支方法使用查询和支持分支,正如我们在第 V-B 节中概述的那样。之后,我们描述具体方法如何偏离一般实现。
-
元学习:学习 "如何学习",通过 episodic 训练提升新类别适配能力。
- 双分支架构(主流)核心结构:查询分支(处理待检测图像)+ 支持分支(处理少量新类别样本)。训练流程:先在 D_base 预训练→episodic 训练(模拟 N-way K-shot 场景)→微调 / 元测试。特征聚合:RPN 前聚合(如 AttentionRPN)、RPN 后聚合、注意力聚合(Transformer-based)、多尺度聚合。优化策略:加权融合多支持样本、类别关系建模(图卷积)、对比训练提升判别力。
- 单分支架构,核心结构:类似通用检测器(如 Faster R-CNN),无独立支持分支。关键技术:度量学习(距离度量、原型网络)、减少可学习参数(冻结骨干网络)、可学习学习率。代表方法:RepMet(距离度量学习)、MetaRetinaNet(系数向量微调)。
-
迁移学习: 基于基础数据集预训练模型,通过简单微调适配新类别,无需复杂 episodic 训练。
- 基础框架:两阶段训练阶段 1:在 D_base 训练基础模型(冻结骨干网络,仅训练 RoI 头)。阶段 2:用 Dbase∪DnovelD_{base} \cup D_{novel}Dbase∪Dnovel 微调,关键是余弦相似度分类(补偿特征范数差异)。
- 关键修改策略,网络结构优化:RPN/FPN 微调、多尺度特征增强。数据增强:缩放 / 平移、伪标签(补充无标注数据)。知识迁移:语义相似基础类别权重初始化、图卷积建模类别关系。梯度流控制:停止 RPN→骨干网络梯度,缩放 RoI 头→骨干网络梯度(如 DeFRCN)。避免遗忘: episodic 记忆存储基础样本、双分支分离基础 / 新类别检测。
-
核心任务是 N-way K-shot 目标检测,即检测 N 个新类别(CnovelC_{novel}Cnovel),每类仅含 K 个标注样本(K 通常为 1-30);数据集划分为基础数据集 DbaseD_{base}Dbase(含海量标注的基础类别 CbaseC_{base}Cbase)和新类别数据集 DnovelD_{novel}Dnovel(含少量标注的新类别 CnovelC_{novel}Cnovel),且 CbaseC_{base}Cbase 与 CnovelC_{novel}Cnovel 无交集,避免数据泄露;训练目标是通过 DbaseD_{base}Dbase 预训练获取通用特征,再通过 DnovelD_{novel}Dnovel 适配新类别,同时避免过拟合和基础类别偏置。
| 对比维度 | 元学习 | 迁移学习 |
|---|---|---|
| 训练方式 | 复杂 episodic 训练(模拟 N-way K-shot 场景) | 简单两阶段微调(基础预训练→新类微调) |
| 新类适配 | 快速适配,部分方法(如 SQMG)无需微调 | 必须微调新类别数据 |
| 关键技术 | 双分支特征聚合(注意力 / 多尺度)、度量学习 | 梯度流控制、知识迁移、伪标签数据增强 |
| 核心优势 | 适配灵活,适合动态新增类别 | 实现简单,当前 SOTA 性能更优 |
| 核心劣势 | 训练复杂,计算成本高 | 对新类样本方差敏感,易遗忘基础类 |
A. Training Scheme
-
对于元学习,模型分多个阶段进行训练。首先,模型 MinitM_{init}Minit 仅在基础数据集 DbaseD_{base}Dbase 上进行训练,得到 MbaseM_{base}Mbase。通常,应用情景训练方案,其中每个 E 情景模拟 N-way K-shot 设置。这称为元训练。在每个情节 e(也称为少样本任务)中,模型在随机子集 Dmetae⊂Dbase,∣Dmetae∣=K⋅ND^e_{meta} ⊂ D_{base}, |D^e_{meta}| = K·NDmetae⊂Dbase,∣Dmetae∣=K⋅N 上的 N 个类别的 K 个训练样本上进行训练。因此,模型需要学习如何根据输入来区分所呈现的类别。最后,在元微调期间,模型 MbaseM_{base}Mbase 在最终任务上进行训练,得到 MfinalM_{final}Mfinal。
-
Minit→e=1,...,EDmetae⊂Dbase→Mbase→Dfinetune→Mfinal.(2) M_{init}\rightarrow^{D^e_{meta}⊂D_{base}}{e=1,...,E}\rightarrow M^{base}\rightarrow^{D{finetune}}\rightarrow M_{final}. (2) Minit→e=1,...,EDmetae⊂Dbase→Mbase→Dfinetune→Mfinal.(2)
-
如果模型应该检测基本类别和新类别,则它会在每个类别的 K 个训练示例的平衡集 Dfinetune ⊂ D 上进行训练,无论它是基本类别还是新类别。否则,如果我们只对新颖类别感兴趣,则仅在 Dfinetune=DnovelD_{finetune} = D_{novel}Dfinetune=Dnovel 上训练模型。请注意,某些方法明确不针对新类别进行微调,而只是将 Mbase 应用于新类别,这称为元测试。在元测试期间,当呈现 N 个类别的 K 个带注释的示例时,模型只是在推理模式下预测新对象。
-
B. General Realization
-
双分支方法采用双流架构,其中一个查询分支 Q 和一个支持分支 S,如图 3 所示。查询分支 Q 的输入是模型应在其上检测对象实例的图像 IQI^QIQ,而支持分支 S 接收支持集 DS={(IiS,y^oj∣)}i=1K⋅ND^S = \{(I^S_i ,\hat y_{oj}| )\} ^{K·N}{i=1}DS={(IiS,y^oj∣)}i=1K⋅N ,其中 N 个类别中的每一个都有 K 个支持图像 IiSI^S_iIiS ,并且每个图像恰好有一个指定对象 oj 及其标签 y^oj\hat y{oj}y^oj 。
-
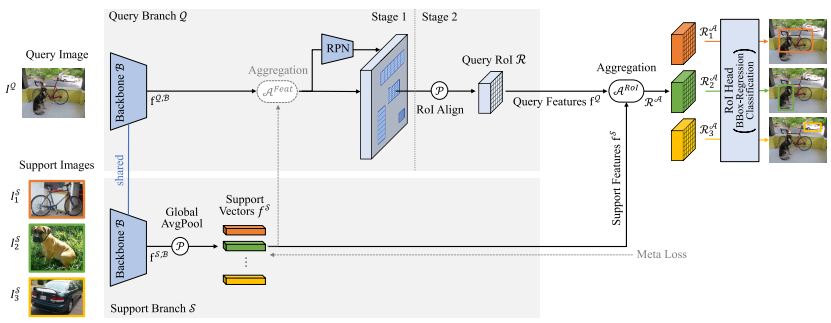
-
图 3. 基于 Faster R-CNN 的双分支元学习的总体架构。查询和支持图像通过共享主干网提供。支持特征通过全局平均来汇集并与查询特征聚合。不失一般性,我们在这里展示一次三路的情况。
-
-
有三个选项,如何呈现指定的对象。首先,所有训练样例均已通过真实边界框裁剪为指定对象,如图 3(底部)所示。其次,呈现全尺寸图像和指示对象位置的附加二进制掩模。第三,可以使用全尺寸图像,并通过RoIalignRoI_{align}RoIalign 提取具有指定对象特征的区域。对于所有三个选项,我们将呈现的图像称为支持图像 ISI^SIS 。特定类别 c 的支持图像表示为 IS,cI^{S,c}IS,c 。
-
支持分支 S 现在应该提取支持图像 ISI^SIS 的相关特征 fSf^SfS 。然后将这些支持特征 fSf^SfS 与来自查询分支 Q 的特征 fQf^QfQ 聚合,表示为 A(fQ,fS)A(f^Q, f^S )A(fQ,fS),以引导检测器从查询图像 IQI^QIQ 中的 IS,cI^{S,c}IS,c 中检测类别 c 的对象实例。
-
请注意,以下解释指的是图 3 所示的带有元学习的 FSOD 最基本且广泛使用的架构。如图 4 所示,具体方法可能在此处描述的一个或多个点上有所不同,并将在下面详细解释。
-
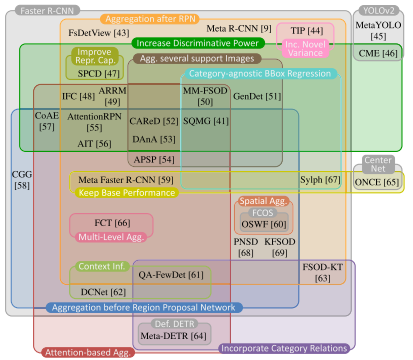
-
图 4.双分支元学习方法的分类。最好以彩色形式观看。
-
-
许多方法都建立在具有 ResNet 主干的 Faster R-CNN 之上。通常,使用 Siamese 主干,即查询分支 Q 和支持分支 S 共享它们的权重。查询分支 Q 的主干特征 fQ,Bf^{Q,B}fQ,B 由区域提议网络 (RPN) 和 RoI 对齐进一步处理,产生查询 RoIs R。在支持分支 S 中,来自主干 fS,Bf^{S,B}fS,B 的支持特征通过全局平均进行池化,从而产生每个类别的代表性支持向量 fSf^SfS 。在 K > 1 的情况下,对于每个类别 c,计算其支持向量的平均值,从而得到每个类别一个支持向量 fS,cf^{S,c}fS,c 。这些支持向量编码特定于类别的信息,然后用于指导 RoI 头识别这些类别的对象。因此,在最简单的情况下,查询 RoIs R 和支持向量 fSf^SfS 被聚合(如图 3 中的 ARoI 所示),通过通道乘法 Amult,如方程(3)所示。
-
聚合后,对于 N 个类别中的每个类别,都有单独的 RoIs RA,c 。它们的特征专门用于识别相应类别 c 的对象。然后,将这些特定于类别的 RoI RA,c 输入到共享 RoI 头中,以进行边界框回归和二元分类。由于聚合的 RoI RA,cR^{A,c}RA,c 已经包含类别特定信息,因此多类别分类可以由仅输出 RoI RA,cR^{A,c}RA,c 是否包含特定类别 c 的对象的信息的二元分类代替。为了仅对每个 RoI R 强制执行一个类别,可以在之后应用一个 softmax 层。
-
请注意,所有类别的 RoI 头共享相同的权重。因此,RoI head 必须跨类别泛化。通过这种机制,理论上可以检测新类别的对象,而无需对新类别进行微调,而只需进行元测试。这使得元学习方法对于现实世界的应用特别有用,因为不需要进一步的训练。在推理过程中,可以为所有 N 个类别计算一次 DnovelD_{novel}Dnovel 的少数图像的支持特征 fSf^SfS ,从而不再需要支持分支 S 。
C. Variants for Aggregation
-
特定的双分支元学习方法的最大不同之处在于查询 fQf^QfQ 和支持特征 fSf^SfS 之间的聚合的实现方式。
-
RPN之前的聚合:通常,查询RoI R 的特征与支持向量f S 聚合。然而,这要求 RPN 为每个相关对象输出至少一个 RoI。否则,即使是最好的聚合方法也无法帮助识别所需的对象 。然而,RPN 仅在基本类别上进行训练。如果小说类别 CnovelC_{novel}Cnovel 与基本类别 CbaseC_{base}Cbase 有很大不同,则 RPN 可能无法输出合适的 RoIs 来识别 CnovelC_{novel}Cnovel 的对象。因此,Fan等人设计了一种所谓的 Attention RPN,它在RPN之前有效地聚合查询和支持特征。我们在图 3 中用 AFeatA^{Feat}AFeat 表示。具体来说,支持特征 fSf^SfS 首先被平均池化,然后通过深度互相关与查询特征 fQf^QfQ 聚合。然后,将 RPN 应用于增强的特征,产生与支持图像 I S,c 的呈现类别 c 更相关的区域建议,从而提高召回率。
-
张等人(PNSD)基于该方法构建,但用二阶池化和功率归一化代替平均池化。这些二阶表示更像是一个特征检测器来捕获共现,而不是像平均池中那样充当计数器。这有助于减轻由于对象外观不同(例如颜色、视角和纹理)而产生的有害特征变化。
-
由于二阶池化仅限于线性相关性,在后续工作中,Zhang 等人(KFSOD)利用核化协方差矩阵和再现捕获非线性模式的核希尔伯特空间核。这些内核可以分解空间顺序,同时保留有关每个区域的丰富统计数据。由于这种平移不变性,可以更轻松地匹配物理位置、方向或视点不同的相似对象。此外,许多其他人也采用了 AttentionRPN 的思想,如图 4 所示。然而,有些人使用不同的聚合操作,我们将在下面讨论。
-
要点:当使用 Faster R-CNN 作为检测器时,RPN 之前的聚合会带来更好的区域建议,从而减少漏检。
-
聚合操作:在最简单的情况下,支持向量 fSf^SfS 和查询特征 fQf^QfQ 按通道相乘
-
Amult(fQ,fS)=fQ⊙fS,(3) A_{mult}(f_Q, f_S) = f_Q ⊙ f_S, (3) Amult(fQ,fS)=fQ⊙fS,(3)
-
其中 ⊙ 表示哈达玛积。
-
-
此外,现有技术还探索了不同的聚合操作。在 AttentionRPN 和 GenDet 中,支持特征与查询特征进行卷积/相关。 Li 等人 (OSWF) 使用 fQf^QfQ 和 fSf^SfS 的每个元素之间的余弦相似度,类似于等式 (3) 中的 Amult,但具有附加的比例因子。
-
Michaelis 等人 (CGG) 和 (OSIS) 计算了每个位置的 ℓ 1 距离,并将所得的相似特征与查询特征连接起来。 Xiao 和 Marlet (FsDetView) 通过将 Amult 中的通道乘法与减法和查询功能本身相结合,使用了更复杂的聚合操作.
-
A(fQ,fS)=fQ⊙fS,fQ−fS,fQ(4) A (f^Q, f^S) = f\^Q ⊙ f\^S , f\^Q − f\^S , f\^Q (4) A(fQ,fS)=fQ⊙fS,fQ−fS,fQ(4)
-
其中 ·,· 表示通道级联。Meta Faster R-CNN 建立在这种聚合的基础上
-
A=ϕMult(fQ⊙fS),ϕSub(fQ−fS),ϕCat\[fQ,fS],(5) A = \\phi_{Mult} (f\^Q ⊙ f\^S) , \\phi_{Sub} (f\^Q − f\^S) , \\phi_{Cat} \[f\^Q, f\^S], (5) A=ϕMult(fQ⊙fS),ϕSub(fQ−fS),ϕCat\[fQ,fS],(5)
-
其中 ϕMult、ϕSub和ϕCat\phi_{Mult}、\phi_{Sub} 和 \phi_{Cat}ϕMult、ϕSub和ϕCat 分别表示具有三个卷积层和修正线性单元 (ReLU) 层的小型卷积网络。
-
-
张等人(SQMG)决定通过动态卷积支持特征 fSf^SfS 来增强查询特征 fQf^QfQ 。 fSf^SfS 被输入内核生成器以生成卷积的权重。然后,生成的权重与 fQf^QfQ 进行卷积。
-
要点:支持特征 fSf^SfS 和查询特征 fQf^QfQ 的简单通道乘法无法充分利用它们包含的信息。
-
保留空间信息进行聚合:与通过平均池聚合支持特征相反,其他人(见图 4)建议利用空间信息。对于对象检测任务,通过边界框来定位对象。然而,并非该边界框的每个部分都被该对象占据,因此,不包含有关相应类别的相关信息。然而,通过平均池化,这些不相关的特征被聚合到支持向量中。此外,通过全局平均池化,空间信息完全丢失,如图5(a)所示。
-
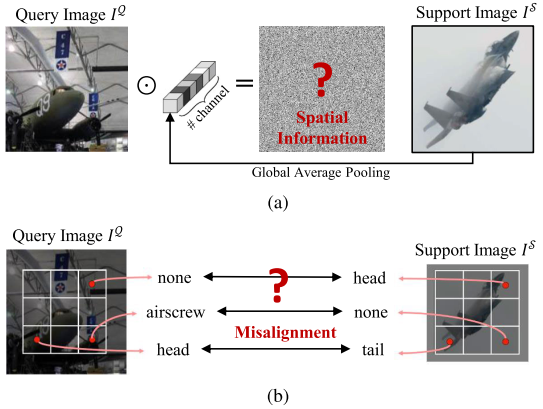
-
图 5. 常见聚合问题。 (a) 由于全局平均池化导致空间信息丢失。 (b) 由于基于卷积的聚合而导致的空间错位。
-
-
因此,Li等人(OSWF)首先将支持特征池化到与查询RoI R相同的空间维度。然后,这些池化特征被连接到查询 RoI R。最后,使用 1 × 1 卷积来比较结构感知的局部特征。
-
然而,Chen 等人认为,查询特征 fQf^QfQ 和支持特征 fSf^SfS 的卷积不太合适,因为查询图像 IQI^QIQ 和支持图像 ISI^SIS 中的对象通常不以相同的方式对齐,如图 5(b)所示。因此,他们设计了一种基于注意力的聚合,如下所述。
-
要点:为了整合支持图像 ISI^SIS 的有价值的空间信息,不应简单地对其特征进行平均以进行聚合。
-
基于注意力的聚合:最近,注意力机制可以显着提高许多视觉任务的性能。因此,支持和查询功能的聚合也受益于合并注意力机制也就不足为奇了。这些注意力机制的范围从传统的非局部注意力到Transformer 中的多头注意力。我们将在下面讨论所有这些内容。
-
Chen等人(DAnA)旨在合并查询图像IQ和支持图像IS之间的空间相关性,但也认为这些图像通常不对齐(见图5(b))。因此,双重意识注意力首先在支持特征f S 上突出显示各自类别的相关语义特征并抑制背景信息。然后,将空间相关性与基于注意力的聚合相结合。 Meta Faster R-CNN 也解决了这种空间错位问题。使用两个注意力模块,支持和 RoI 特征首先在空间上对齐,然后突出显示前景区域。
-
Wang等人(IFC)首先在平均和最大池化查询特征之上使用自注意力模块来分别挖掘局部语义和详细纹理信息。随后,利用基于可学习软阈值算子的新特征聚合机制,可以缩小冗余信息,同时增强新类别和基本类别的特征敏感性和稳定性。
-
Huang等人(ARRM)旨在通过设计一个由不同特征的多个卷积和矩阵乘法组成的基于注意力的亲和关系推理模块来实现支持和查询特征的更好交互。通过附加的全局平均池分支,还集成了支持功能的全局语义上下文。使用这种基于注意力的模块进行聚合,可以减少错误分类。
-
Hsieh等人(CoAE)提出了一种共同关注方法,以使查询特征 fQf^QfQ 关注支持特征 fSf^SfS ,反之亦然。因此,利用两个相互非局部操作,它们接收来自 fQf^QfQ 和 fSf^SfS 的输入。这有助于 RPN 计算能够更好地从支持图像 IS,cI^{S,c}IS,c 中定位类别 c 的对象的区域建议。此外,Hsieh等人提出了一种后续的挤压和共激励方法------扩展 SENet 的挤压和激励方法------以突出相关的特征通道来检测相关提案并最终检测目标对象。 Hu 等人 (DCNet) 使用了类似的共同注意力。
-
通过 AIT,Chen 等人 将 CoAE 的想法进一步推进了一些。不使用单个非局部块,而是利用多头共同注意力在 RPN 之前聚合查询和支持特征。令 V、K 和 Q 为基于 Transformer 的注意力的值、键和查询 。与CoAE中的co-attention类似,查询特征源于另一个分支
-
FQ=attn(VQ,KQ,QS),FS=attn(VS,KS,QQ),(6) F^Q = attn(V^Q, K^Q, Q^S) , F^S = attn(V^S , K^S , Q^Q), (6) FQ=attn(VQ,KQ,QS),FS=attn(VS,KS,QQ),(6)
-
其中上标 Q 和 S 表示特征是否来自查询分支或支持分支。得到的特征 FQ 对查询图像 IQ 和支持图像 IS 的相关视觉特征进行编码,这有助于 RPN 预测与 IS 相关的 RoIs。根据 Chen 等人 的说法,与 CoAE 中的非局部注意力块 相比,这提高了准确性。在 RPN 之后,AIT 使用基于 Transformer 的编码器-解码器架构来转换 RoIs R 以强调与给定支持图像 IS 相对应的视觉特征。
-
-
Meta-DETR 和 APSP 中也使用了等式 (6) 中与 FS 类似的聚合。然而,Meta-DETR 和 APSP 首先增强了查询或支持功能,我们将在下面描述。
-
要点:支持图像 IS 的空间信息及其与查询图像 IQ 的关系最好通过基于变压器的注意力机制来整合 。
-
多级聚合:到目前为止,支持和查询特征仅在主干中进行特征提取后才聚合。然而,Han 等人 (FCT) 认为查询和支持分支之间的多级特征交互可以更好地对齐特征。因此,他们提出了一种基于改进的金字塔视觉 Transformer PVTv2的新型完全交叉 Transformer。 FCT 模型由主干中查询和支持之间的三个交互阶段以及检测头中的一个附加交互阶段组成。最后,类似于 Attention RPN 的成对匹配输出最终检测结果。
-
要点:低、中、高级功能的聚合可以提高性能。
-
多个支持图像的聚合:在一般方法中,为了融合类别 c 的所有支持图像,计算它们的特征的平均值
-
{IS,c}i=1K:fS,c=1K∑i=1KfiS,c.(7) \{I^{S,c}\}^K_{i=1} : f^{S,c} = \frac1 K\sum^K_{i=1} f^{S,c}_i . (7) {IS,c}i=1K:fS,c=K1i=1∑KfiS,c.(7)
-
然而,并非所有支持图像都为相应类别提供相同数量的信息,如图 6 所示。如果简单地对支持特征 fiS,cf^{S,c}_ifiS,c 进行平均,则不寻常的对象视图、对象部分、甚至其他类别对象的遮挡都会削弱辨别能力。
-

-
图 6. 同一类别的多个支持图像的不同信息量。图片来自 GenDet 。
-
-
因此,GenDet 提出了加权平均。每个支持图像 IiS,cI^{S,c}_iIiS,c 的权重 wi 通过单次检测器和均值检测器之间的相似度计算并在训练期间学习
- {IiS,c}i=1K:fS,c=1K∑i=1Kwi⋅fiS,c.(8) \{I^{S,c}i\}^K{i=1} : f^{S,c} =\frac 1 K\sum^K_{i=1} w_i · f^{S,c}_i . (8) {IiS,c}i=1K:fS,c=K1i=1∑Kwi⋅fiS,c.(8)
-
Quan 等人 (CAReD) 也采用了类似的方法。然而,权重 wi 是由支持特征 fiS,cf^{S,c}_ifiS,c 与同一类别 c 的所有其他支持特征 {fjS,c}j=1K\{ f^{S,c}j \}^K{j=1}{fjS,c}j=1K 之间的相关性的 softmax 确定的。由于采用了 softmax,权重因子之和已经为 1,并且因子 (1/k) 被省略。
-
DAnA 、SQMG 以及 APSP 结合了查询 fQf^QfQ 的相似性和不同的支持特征 fSf^SfS 。在DAnA 中,K个不同图像 {IiS,c}i=1K\{I^{S,c}i \} ^K{i=1}{IiS,c}i=1K 的支持特征f S,c i 首先基于查询和支持之间的相关性与查询特征f Q 独立聚合。由于每个支持图像 I S,c i 的重要性已经被纳入,因此可以简单地对所得的 K 个聚合特征进行平均
- nIS,cioKi=1:AfQ,fS,c=1KKXi=1AfQ,fS,ci.(9) n I S,c i oK i=1 : A f Q, f S,c = 1 K K X i=1 A f Q, f S,c i . (9) nIS,cioKi=1:AfQ,fS,c=1KKXi=1AfQ,fS,ci.(9)
-
在SQMG 中,使用注意机制根据多个支持图像 IiS,cI^{S,c}_iIiS,c 的支持特征 fiS,cf^{S,c}_ifiS,c 与查询特征 fQ 的相似度对它们进行加权。首先,使用关系网络计算相似度。然后,使用相似度分数上的 softmax 计算支持特征 fiS,cf^{S,c}_ifiS,c 的权重值 wi 。最终的支持特征是通过等式(8)中的加权和来实现的。
-
Lee 等人 (APSP) 首先使用多头注意力通过合并同一类别 c 的所有其他支持向量来细化每个单独的支持向量 fiS,cf^{S,c}_ifiS,c 。之后,不是计算单个支持向量,而是在第二个多头注意力中利用所有 K 个支持向量 {fiS,c}i=1K\{ f^{S,c}i \}^K{i=1}{fiS,c}i=1K 来与查询特征聚合。因此,并非不同支持图像的所有方差都需要合并到单个支持向量中,从而产生更鲁棒的特征。
-
要点:由于并非所有支持图像都提供相同数量的信息,因此应合并它们各自的相关性,如图 6 所示。
D. Incorporate Relations Between Categories
-
Han 等人 (QA-FewDet) 强调了许多双分支元学习方法作为一种单类别检测器而不对多类别关系进行建模的问题。然而,特别是对于类似于基本类别的新类别,这些关系可以帮助正确分类对象(例如,摩托车与自行车比飞机更相似)。
-
因此,与仅使用视觉特征相比,Kim 等人(FSOD-KT)还结合了语言特征。在聚合之前,支持向量 fS 通过知识传输模块馈送,该模块利用不同类别之间的语义相关性。该知识转移模块是由图卷积网络实现的。该图卷积网络的输入是一个图,其中每个节点代表一个类别,边上的值代表语言类别名称之间的相似性。然而,这仅适用于所有类别都具有预定义且不同的类别名称并且可能难以转移到例如医学成像的情况。
-
Han 等人 (QA-FewDet) 也利用了图卷积,但不依赖于语言类别名称。相反,他们构建了一个异构图,该图增强了具有多类别关系的支持向量 fS ,以便更好地建模它们的关系并合并来自相似类别的特征。此外,它们的异构图还调整了支持和查询功能。由于一个类别c的支持特征 fS,cf^{S,c}fS,c 仅从少数支持图像中提取,因此查询实际上属于同一类别c的RoIs Rc可能存在巨大差异。因此,异构图还包含RoI之间的成对边,以相互适应 fS,cf^{S,c}fS,c 和Rc的特征并减少它们的差异。
-
尽管没有使用图卷积,Zhang等人(Meta-DETR)也通过转换不同类别的支持特征来合并不同类别之间的关系。作者引入了一个相关性聚合模块,该模块能够同时聚合多个支持类别以捕获它们的类间相关性。这有助于减少错误分类并增强对新类别的泛化。首先,利用注意模块将查询特征 fQ 同时与多个支持特征 fS 进行匹配。之后,任务编码有助于区分这些支持类别。
-
要点:结合不同类别之间的关系有助于更好地表示和分类数据稀疏的小说类别 CnovelC_{novel}Cnovel。
E. Increase Discriminative Power
-
聚合后,对于每个RoI R,存在N个类别特定的RoI RA,c ,它们被独立分类。如果不同类别的支持特征 fSf^SfS 太相似,这种独立的分类可能会导致歧义。因此,一些方法使用额外的元损失来强制支持特征 fSf^SfS 尽可能多样化。最常见的是,对支持特征 fSf^SfS 进行分类,并应用简单的交叉熵损失。这鼓励支持向量落入相应对象所属的类别。更先进的方法利用度量学习技术来提高判别能力,如下所述。
-
GenDet 和 Meta-DETR 使用基于余弦相似性的损失来获得更具辨别力的支持向量。首先,对支持向量 fSf^SfS 进行归一化。然后,对于每对支持向量 ( fiS,c,fjS,cf^{S,c}_i , f^{S,c}_jfiS,c,fjS,c ),计算余弦相似度,从而得到相似度矩阵 A∈RN×NA ∈ \R^{N×N}A∈RN×N ,其中 N 是不同类别的数量。通过 ℓ 1 损失,相似度矩阵 A 被限制为接近单位矩阵 IN∈RN×NIN ∈ \R^{N×N}IN∈RN×N 。直观地说,这会导致不同支持向量之间的相似性最小化,并最大化每个支持向量的判别能力,即不同支持向量之间的高裕度。
-
Wang等人(IFC)、Kobayashi(SPCD)和Huang等人(ARRM)也使用了余弦损失,但在ARRM中,添加了额外的边距以进一步增加区分度并减少错误分类。
-
MM-FSOD 使用皮尔逊距离来聚合 fSf^SfS 和 fQf^QfQ 。与余弦相似度相比,皮尔逊距离首先用所有维度的均值对每个维度进行归一化,从而导致内部类方差更小。因此,不需要设计专门的距离损失函数,可以利用简单的交叉熵损失。
-
Li等人(CME)提出了一种最小-最大-边缘的对抗性训练程序:除了增加边缘的损失之外,新类别的特征受到干扰,以降低其支持向量的判别力,从而减少边缘。准确地说,通过将梯度反向传播到输入支持图像,以对抗方式擦除最具辨别力的像素。通过这种方法,CME 能够准确检测更多物体,同时误报率更少。
-
对于元学习方法,检测器应该检测查询图像 IQ 中与支持图像 IS,cI^{S,c}IS,c 中的对象属于同一类别 c 的对象。由于这个问题的定义,元学习方法倾向于将前景与背景分开,而不是区分不同的类别,正如Zhang等人(SQMG)所指出的。这通常会导致误报,即预测的边界框,即使查询图像 I Q 不包含所考虑类别 c 的任何实例。然而,同样重要的是检测器能够区分不同的类别并识别哪些对象类别不存在于查询图像中。
-
因此,在AttentionRPN 中,提出了多关系检测器以及双向对比训练策略。多关系检测器结合了支持特征 fSf^SfS 和查询 RoIs R 之间的全局、局部和基于补丁的关系,以测量它们的相似性。所有三个匹配模块的输出相加得出最终匹配分数。许多其他采用或建立在这种多关系检测器的基础上。另外提出的双向对比训练策略的实现如下。除了正支持图像 IS,cI^{S,c}IS,c 之外,还使用来自查询图像 I Q 中不存在的对象类别 n∈C{c}n ∈ C\{c\}n∈C{c} 的负支持图像 I S,n 。这种双向对比训练策略由 DAnA 和 CAReD 改编。张等人(SQMG)用自适应边缘扩展了对比损失,以便以适当的距离分隔不同的类别。自适应边距通过词嵌入合并类别的语义相似性。
-
张等人(SQMG)强调的第二个问题是许多背景提案与少数前景提案的极度不平衡,这阻碍了距离度量学习。为了解决前景-背景不平衡的问题,作者使用了焦点损失,它降低了简单背景提案的权重,并专注于硬底片。
-
CoAE 使用额外的基于边际的损失来提高 RPN 中 RoI 的排名。那些与支持图像 IS 中的对象具有高相似度的 RoI 应该位于排名的顶部,因为只有前 128 个 RoI 将被进一步处理。因此,作者设计了一个基于边缘的指标来预测所有 RoI 的相似性。 Chen 等人 (AIT) 采用了这种 margin-based 的排名损失。
-
在典型的情景训练中,每个情景中仅呈现 N 个类别。根据 Liu 等人 (GenDet) 的说法,这可能导致提取的特征的区分能力较低,因为仅区分了采样的类别。因此,他们的方法 GenDet 在训练期间使用了一个额外的参考检测器,其中所有基本类别 CbaseC_{base}Cbase 都需要区分。特定基本类别的索引在所有剧集中保持不变。通过额外的损失,两个检测器都被限制输出相似的结果。这引导主干网络提取更具辨别力的特征
-
要点:为了增加判别力并区分多个类别,应采用度量学习的思想,例如相似性度量以及对比训练。
F. Improve Representation Capability
- Kobayashi (SPCD) 强调,在基础训练期间,所有其他非基础类别都被视为负数。这导致识别新类别的表达能力不足。因此,他们引入了一个额外的自我监督模块。通过选择性搜索,提取与基本类别不同的矩形区域,并教导网络以自我监督的方式在应用强数据增强之前和之后检测相同的区域。
G. Proposal-Free Detectors
-
大多数方法都建立在两级检测器 Faster R-CNN 之上 。然而,这些方法需要处理可能不准确的区域提议,以及是否在 RPN 之前或之后聚合支持特征 fSf^SfS 和查询特征 fQf^QfQ 的决定。当使用无提议检测器时, fSf^SfS 和 fQf^QfQ 可以在特征提取之后、分类和边界框回归之前简单地聚合。
-
一些方法利用简单的一级检测器,例如 MetaYOLO 中的 YOLOv2 和 CME 或 DAnA 中的 RetinaNet 。其他的则建立在无锚检测器之上,例如 ONCE 中的 CenterNet 或 Li 等人 (OSWF) 中的 FCOS 和 GenDet 。基于 Transformer 的探测器 Deformable DETR 用于 Meta-DETR 。 Meta-DETR 聚合在共享主干之后支持特征 fSf^SfS 和查询特征 fQf^QfQ 。随后,与类别无关的 Transformer 架构预测对象。
-
要点:虽然大多数方法都建立在 Faster R-CNN 之上,但无提议检测器更容易实现。特别是基于 Transformer 的架构,例如 MetaDETR ,已经超越了其他方法。
H. Keep the Performance on Base Categories
-
为了更好地检测基本类别并防止灾难性遗忘,Han 等人(Meta Faster R-CNN)在原始 Faster R-CNN 架构之后使用了一个附加分支。由于 Meta Faster R-CNN 已经在 RPN 之前聚合了查询特征 fQf^QfQ 和支持特征 fSf^SfS ,因此这两个分支之间仅共享主干网的权重。在对基本类别 CbaseC_{base}Cbase 进行元训练后,固定主干的权重,并训练基本类别分支的 RPN 和 RoI 头。最后,另一个分支分别通过元微调或元测试进行调整或简单地应用于新类别(有关术语定义,请参阅第 V-A 节)。由于第一个分支保持固定,基本类别 CbaseC_{base}Cbase 的性能不会因元微调而下降。
-
对于增量学习方法 ONCE 和 Sylph ,已学习类别的权重也保持固定。 Sylph 没有使用基于 softmax 的分类器,而是使用几个独立的基于 sigmoid 的二元分类器(每个类别一个),这样类别就不会相互影响。对于每个新类别 c,支持分支 S 顶部的超网络为其分类器生成权重。因此,不需要元微调。
I. Increase the Variance of Novel Categories
- TIP 使用高斯噪声或剪切等数据增强技术扩展了新类别的少数训练示例。然而,天真地添加数据增强会损害检测性能。因此,Li和Li (TIP)使用了额外的变换引导一致性损失,由ℓ 2范数实现,它限制原始图像 IiSI^S_iIiS 和变换图像 IjS=φ(IiS)I^S_j = φ(I^S_i )IjS=φ(IiS) 生成的支持向量 fSf^SfS 和 fjSf^S_jfjS 彼此接近。即使对于不同的支持图像,这也会产生更相似和更具代表性的支持向量,从而提高新类别的检测性能。此外,在训练期间,查询分支 Q 还接收变换后的图像和原始图像。变换后的查询图像 IQ 的特征被输入到 RPN 中来预测 RoIs。然后通过 RoI Align 从原始未转换查询图像的特征中裁剪这些 RoI。这迫使检测器预测一致的 RoIs,而与查询图像所使用的变换无关。
J. Incorporate Context Information
-
通常,通过应用 RoI 池或 RoI 对齐,区域提案被池化为特定的平方大小,例如 7 × 7。然而,这可能会导致训练过程中的信息丢失,这可以通过丰富的训练数据来弥补。由于只有几个可用的训练示例,这种信息丢失可能会导致误导性的检测。因此,**DCNet 使用三种不同的分辨率并执行并行池化。类似于 PSPNet 中用于语义分割的金字塔池化模块,这有助于提取上下文信息,其中较大的分辨率有助于关注局部细节,而较小的分辨率有助于捕获整体信息。**与金字塔池化模块相反,分支与基于注意力的求和融合。
-
Han 等人 (QA-FewDet) 发现查询 RoIs R 可能有噪声并且可能不包含完整的对象。因此,他们构建了一个使用图卷积层的异构图。提案节点之间的成对边结合了不同 RoI 的局部和全局上下文,以改进分类和边界框回归。
K. Category-Agnostic Bounding Box Regression
- 尽管二元分类和边界框回归的参数对于所有类别都是共享的,但大多数方法都独立地为每个特定于类别的 RoI 计算它们。相比之下,GenDet 、MM-FSOD 、SQMG 和 Sylph 共享不同类别之间的边界框计算。这遵循这样的直觉:尽管不同类别的视觉外观有所不同,但边界框值的回归具有共同的特征。此外,它还节省了计算开销。
最佳表现双分支元学习方法总结
-
下面,我们总结了在 FSOD 基准数据集上表现最佳的选定双分支元学习方法(参见第 IX 节),以突出其关键概念。
-
Meta-DETR 是第一个建立在基于变压器的检测器 DETR 之上的方法。在不依赖准确的区域建议的情况下,Meta-DETR 规避了将这些建议适应新类别的挑战。此外,在其基于注意力的聚合模块中,纳入了不同类别之间的相关性,从而减少了错误分类。通过基于余弦相似度的额外损失,学习到的特征更具辨别力,从而增强泛化能力。
-
FCT 也使用了 Transformer,但 Faster R-CNN 的 ResNet 主干不是 DETR,而是简单地被改进的 Pyramid Vision Transformer PVTv2 所取代。然而,支持和查询功能在多个级别上聚合,以更好地对齐功能。此外,多关系检测器计算支持特征和查询特征之间的相似性以输出最终检测。
-
IFC 并不是建立在 Transformer 之上,而是利用交互式自注意力模块来捕获稀缺新颖类别的区分特征。此外,还引入了一种新颖的特征聚合机制,旨在减少冗余信息,同时增强新类别和基本类别的特征敏感性和稳定性。最后,正交余弦损失增强了前景的可区分性。
-
SQMG 是少数不需要微调的方法之一。在SQMG中,支持和查询功能都通过相互指导得到增强。首先,这有助于生成更多具有类别意识的区域提案。其次,还纳入了多个支持图像的个体相关性。此外,SQMG 注重通过不同的训练技术进行正确分类。为了减轻相似类别的混乱,采用了具有自适应边缘的双向对比训练策略。为了解决许多背景提案与少数前景提案之间的不平衡,引入了额外的焦点损失。最后,边界框回归在不同类别之间共享,以便专注于分类。
双分支元学习方法的结论
- 双分支元学习方法在 FSOD 中非常常见。它们能够快速适应新类别,甚至可以无需微调而只需简单的前向传递(即元测试)即可应用于新类别。这对于现实世界的应用程序特别有用。然而,它们需要复杂的情景培训计划,如第 V-A 节所述。尽管如此,通过利用基于注意力的聚合并结合度量学习技术,双分支元学习方法可以实现最先进的结果,正如我们将在第九节中讨论的那样。
SINGLE-BRANCH META LEARNING
- FSOD 的单分支架构遵循另一种方法。由于没有查询和支持分支,因此总体架构类似于 Faster R-CNN 等通用对象检测器的架构。然而,没有任何一种方法是其他人所偏离的。尽管如此,所有方法都使用章节 V-A 中描述的情景训练,这对于元学习来说是典型的。在图 7 中,我们展示了单分支元学习方法的分类,我们将在下面进一步描述。
-
-
图 7.单分支元学习方法的分类。最好以彩色形式观看。
-
A. Metric Learning
-
与双分支元学习类似,度量学习在单分支方法中起着关键作用。
-
FSOD 的最早方法之一------RepMet ------将 FSOD 任务定义为距离度量学习问题。对于定位,RepMet 仅使用 Faster R-CNN 中的 RoIs R。这些 RoI 的嵌入特征向量 f + 与每个类别的多个学习代表进行比较,以确定 RoI 的类别。为了学习足够的特征嵌入,使用了额外的嵌入损失,它强制嵌入向量到正确类别的最接近代表的距离和到错误类别的最接近代表的距离之间的最小余量。
-
RepMet 使用类别的正区域提案,但丢弃其负提案。然而,为了学习嵌入空间,否定(尤其是强否定)建议是必不可少的。因此,NP-RepMet 还学习负嵌入特征向量 f − 和每个类别的负代表向量。代表的嵌入空间是通过利用三元组损失来学习的。
-
PNPDet 使用余弦相似度进行对象类别的距离度量学习,以更好地推广到新类别。余弦相似度计算输入图像的特征与每个类别的学习原型的相似度.
-
要点:度量学习有助于创建更具区分性的特征,以便更好地区分不同类别。
B. Reduce Learnable Parameters
-
由于新类别的训练示例很少可能不足以训练深度神经网络,因此一些方法减少了可学习参数的数量以进行少样本微调。
-
在基础数据集上训练 MetaDet 后,类别不可知的权重(即 Faster R-CNN 的主干和 RPN)被冻结,并应用情景训练方案来学习如何首先预测基本类别 CbaseC_{base}Cbase 的类别特定权重,然后预测新类别 CnovelC_{novel}Cnovel 的类别特定权重。为了进行推理,可以分离元模型,并且检测器看起来像标准的 Faster R-CNN。
-
Li 等人 (MetaRetinaNet) 在 DbaseD_{base}Dbase 上训练后冻结所有骨干层,并学习初始化为 1 的系数向量 v,从而减少了可学习参数的数量。这些可学习系数向量 v 与卷积权重 w 相乘,得到修改后的卷积运算:fout=fin⊗(w⊙v)⊕bf_{out} = f_{in} ⊗ (w ⊙ v) ⊕ bfout=fin⊗(w⊙v)⊕b。
-
张等人(PNPDet)在 DnovelD_{novel}Dnovel 上训练后冻结了整个网络。对于少样本微调,引入了第二个小子网络来学习对新颖类别 CnovelC_{novel}Cnovel 进行分类。这种新颖类别和基本类别的分离可以防止基本类别的性能下降。
-
要点:在数据稀缺的 DnovelD_{novel}Dnovel 上进行训练时,应减少可学习参数的数量。
C. Learnable Learning Rate
- Fu 等人设计了他们的元单次检测器(SSD),使得模型的参数可以快速调整(只需更新一个参数)以适应新类别 CnovelC_{novel}Cnovel 。来自原始 SSD 检测器 的所有参数都获得额外的可学习学习率。在元学习过程中,这些学习率是由元学习器从当前任务的分布中单独学习的,不会导致过拟合或欠拟合。
D. Balanced Loss Function
- Li等人强调,对于元训练,在每个episode中,对不同类别的不同训练示例进行采样,并且它们获得不同的性能。这种性能不平衡会影响稳定性,并使模型难以适应新的类别。因此,在他们的 MetaRetinaNet 中,引入了平衡损失,这限制了检测器在不同场景中实现相似的性能。
单分支元学习方法的结论
- FSOD 中对单分支元学习方法的探索要少得多。因此,更先进的双分支方法或迁移学习方法能够超越此处介绍的方法。
TRANSFER LEARNING
-
元学习方法依赖于复杂的情景训练。相比之下,迁移学习方法在单分支架构上利用相当简单的两阶段方法,最常见的是 Faster R-CNN ,如 Wang 等人 (TFA) 首次提出的,如图 8 所示。
-
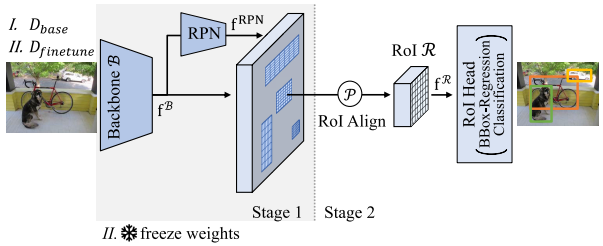
-
图 8. 迁移学习的实现。
-
-
在第一阶段,检测器在基本类别 CbaseC_{base}Cbase 上进行训练。之后,除了负责边界框回归和分类的 RoI head 之外,所有检测器权重都被冻结。在第二阶段,通过微调基本类别 CbaseC_{base}Cbase 和新类别 CnovelC_{novel}Cnovel 的最后一层来执行迁移学习。为了进行微调,训练集由基本类别数据 DbaseD_{base}Dbase 和新颖类别数据 DnovelD_{novel}Dnovel 的平衡子集组成,每个基本类别和新颖类别都有 K 个样本。 Faster R-CNN 的唯一修改是使用余弦相似度进行分类,这对于补偿基本类别 CbaseC_{base}Cbase 和新类别 CnovelC_{novel}Cnovel 的特征规范差异至关重要,如102中的分析所示。 Wang等人表明,这种简单的方法足以充分学习新颖的类别 CnovelC_{novel}Cnovel ,并且优于早期更复杂的元学习方法。
-
基于这个简单的方法,人们提出了许多修改方案。图 9 显示了按所采用的架构及其修改进行分类的所有迁移学习方法。下面,我们将描述所有建议的修改,并按所示类别分组。
-
-
图 9. 按检测器架构和修改类型分类的迁移学习方法。最好以彩色形式观看。
-
A. Modifications of the RPN
-
对于非常少的样本设置,其中新颖类别 CnovelC_{novel}Cnovel 的实例 K 数量非常低,RPN 被认为是错误的关键来源 。例如,如果检测器必须学习从单个示例中检测类别,则检测器只能通过提出与对象的真实情况相匹配的多个 RoI 来对类别的变化进行建模,这类似于随机裁剪增强。如果 RPN 错过了其中一个 RoI,那么这一新颖类别的性能可能会显着下降。因此,Zhang等人(CoRPN)修改了RPN,用M个二元分类器替换RPN中的单个二元前景分类器。目标是至少有一个分类器将相关 RoI 识别为前景。 Vu 等人 (FORD + BL) 在 RPN 之前添加了一个多孔空间金字塔池 (ASPP) 上下文模块,以增加其感受野。这有助于将相关的 RoI 识别为前景。
-
他们发现,解冻 RPN 最后一层(用于分类对象是前景还是背景)的权重足以改进第二阶段的 RPN。 Sun等人(FSCE)、Kaul等人(LVC)和Wang等人(CIR)得出了相同的结论,因此所有RPN权重都被解冻。此外,FSCE 和 CIR 将通过非极大值抑制 (NMS) 的提案数量增加了一倍,以获得更多针对新类别的提案。 FSCE 通过仅采样 RoI 头中用于损失计算的提案数量的一半来补偿这一点,因为他们观察到在第二个训练阶段,丢弃的一半仅包含背景。
-
要点:为了减少漏检的数量,在 DnovelD_{novel}Dnovel 上进行微调时应调整 RPN 权重,并且可以增加通过 NMS 的提案数量。
B. Modifications of the Feature Pyramid Network
-
接下来解冻 RPN,Sun 等人 (FSCE) 表明,与冻结其权重相比,在第二阶段对特征金字塔网络 (FPN) 进行微调可以提高性能。他们认为,如果不进行任何微调,基本类别中的概念就无法转移到新类别。
-
Wu等人(MPSR)观察到,FPN的尺度并不能补偿新类别的少数样本的尺度的稀疏性。因此,在细化分支中,应用特定的数据增强来解决这个问题(参见第 VII-C 节)。 Wang等人(CIR)设计了一个上下文模块来扩大FPN的感受野,这也解决了不同尺度的问题,特别是改善了小物体的检测。
-
要点:此外,FPN 权重应该在微调期间进行调整 。
C. Increase the Variance of Novel Categories
-
如果新类别 CnovelC_{novel}Cnovel 的训练实例是有限的,那么关于这些类别的数据的方差也是有限的。因此,一些方法试图增加新类别数据的方差。
-
在 MPSR 的细化分支中,每个对象都被方形窗口裁剪并调整为各种比例。这增加了对象大小的差异。这种增强也被用于 FSOD-UP 和 CME 。Xu等人(FSSP)采用了类似的方法,其中在辅助分支中,对象在缩放和平移方面得到增强,如图10所示。
-

-
图 10. FSSP 中有关规模和翻译的新类别的增强。
-
-
张和王(Halluc.)引入了一个幻觉网络,该网络学习为新类别 CnovelC_{novel}Cnovel 生成额外的训练示例。为了实现这一点,通过利用来自基本类别 CbaseC_{base}Cbase 的共享类内特征变化来增强新类别样本的 RoI head f R 中的特征。
-
Kaul 等人 (LVC) 在他们的实验中表明,数据增强,即颜色抖动、随机裁剪、马赛克和每个 ROI 提取特征的丢失,显着提高了性能。 Sun 等人 (FSCE) 描述了几种随机图像裁剪的增强与 RPN 中的多个 RoI 建议之间的相似性。因此,如第 VII-A 节所述,增加每个新类别实例的建议 RoIs 数量也会增加新类别的方差,因为它类似于随机裁剪增强。增加新类别的方差主要有利于极端少样本场景,每个新类别的样本 K 很少。
-
如果包含新类别的其他未标记数据可用,则可以应用半监督学习技术来增加新类别的样本数量。 Liu等人(N-PME)对微调后的基础数据集DbaseD_{base}Dbase进行伪标记,以便在 DbaseD_{base}Dbase 中找到CnovelC_{novel}Cnovel的额外样本。然后,通过包含伪标记为 CnovelC_{novel}Cnovel 中的类别之一的样本,将新样本用于额外的微调阶段,并进行更多样本。由于附加样本的边界框相当不精确,因此在回归损失中省略了它们。
-
Kaul等人(LVC)进一步改进了这一尝试,首先验证搜索到的新颖样本确实属于CnovelC_{novel}Cnovel,然后纠正不准确的边界框。为了进行验证,他们应用了视觉 Transformer(ViT),该变换器通过无标签的自蒸馏(DINO)以自监督的方式进行训练,以获得可用于 k 最近邻分类器的特征,以与新类别的 K 个样本进行比较。
-
如果新颖的样本能够被验证,则将其纳入DnovelD_{novel}Dnovel;否则,在接下来对扩展数据进行额外微调时,这些区域将被忽略。已验证样本的边界框以 Cascade R-CNN 的方式进行校正。使用高质量的扩展数据,可以对探测器进行端到端微调,而无需冻结探测器的任何组件。虽然这似乎显着提高了性能,但应该指出的是,对于 FSOD 基准数据集 Microsoft COCO 和 PASCAL VOC,在 DbaseD_{base}Dbase 图像中搜索新物体就足够了,但对于现实世界的小样本应用,例如医疗应用或稀有物种检测,需要额外的(未标记的)数据,这可能会出现问题。
-
要点:增加来自新类别的训练示例的方差(例如,通过数据增强或伪标记附加数据)可以提高检测精度,特别是当训练示例 K 的数量非常小时。
D. Transfer Knowledge Between Base and Novel Categories
-
在LSTD 中,使用相似基类别的软分配,新类别的分量权重由基类别权重初始化,以传递基础知识。Chen 等人 (AttFDNet) 使用来自基础对象检测器的参数和印记初始化方法初始化了新型对象检测器的参数。此外,Li 等人(CGDP + FSCN)使用印记进行初始化。
-
通过学习和利用新类别和基本类别之间的视觉和语义语言相似性,在第二个训练阶段,Khandelwal 等人 (UnitT) 将边界框回归和分类的权重从基本类别转移到新类别。 Zhu等人(SRRFSD)通过从大型文本语料库中学习的语义词嵌入来表示每个类别概念。对象的图像表示被投影到这个嵌入空间中,以从视觉信息和语义关系中学习 CnovelC_{novel}Cnovel。 Cao等人(FADI)也纳入了类别的语义含义:在DbaseD_{base}Dbase上训练后,他们通过WordNet测量基本类别和新颖类别的语义相似性。
-
作者认为,在第二个微调阶段,将新类别与多个基本类别相关联会导致新类别的类内结构分散。因此,每个新颖类别恰好与具有最高相似性的一个基本类别相关联。然后,为每个新类别分配一个相关基本类别的伪标签。然后,整个网络被冻结(除了 RoI Head 中的第二个全连接层),并对网络进行训练,使其学会将新类别的特征分布与相关的基本类别对齐。这导致新颖类别的类内差异较小,但不可避免地会导致 CbaseC_{base}Cbase 和 CnovelC_{novel}Cnovel 之间的混淆。因此,在随后的判别步骤中,CbaseC_{base}Cbase 和 CnovelC_{novel}Cnovel 的分类分支被解开以学习良好的判别。在(KR-FSOD)中,基于词嵌入的语义知识图用于描述场景和对象之间的关系。这有助于改善新颖类别和相关类别之间的知识传播。
-
要点:为了初始化每个新类别的组件权重,应该转移语义上最相似的基本类别的知识。
E. Keep the Performance on Base Categories
-
许多方法在 CnovelC_{novel}Cnovel 上训练时都会遭受灾难性遗忘。尽管在微调阶段模型也可以在CbaseC_{base}Cbase上进行训练,但与微调前相比,性能仍然有所下降。因此,Fan等人(Retentive R-CNN)提出分别为CbaseC_{base}Cbase和CnovelC_{novel}Cnovel的RoI提案和分类复制RPN和分类头。在CnovelC_{novel}Cnovel头的微调过程中,使用余弦分类器来平衡CbaseC_{base}Cbase和CnovelC_{novel}Cnovel特征规范的变化。 CbaseC_{base}Cbase 冻结的 RPN 和 RoI 头应保持基本类别的表现。Feng等人(BPMCH)在微调阶段主要通过固定主干Bbase和这些类别的分类头来对抗基本类别CbaseC_{base}Cbase的灾难性遗忘,并使用额外的主干Bnovel作为新类别CnovelC_{novel}Cnovel的特征提取器。
-
在MemFRCN 中,除了RoI头中基于softmax的分类器之外,每个类别ci的代表性特征向量 fiR,cf^{R,c}ifiR,c 都被学习并存储,以在微调阶段修改RoI头后记住基本类别 CbaseC{base}Cbase 。在推理过程中,提取的特征 fRf^RfR 可以通过余弦相似度与这些类别代表进行比较。这类似于双分支元学习中的支持向量。
-
Guirguis等人(CFA)建立在持续学习方法GEM和A-GEM的基础上,观察到当先前任务的损失梯度向量与当前任务的梯度更新之间的角度为钝角时,就会发生灾难性遗忘。因此,CFA 将 K 个基本类别的样本存储在情景存储器中,类似于 AGEM,以便能够在 DbaseD_{base}Dbase 上计算梯度。在微调阶段,情景记忆是静态的,这意味着不会添加更多样本。然后按如下方式进行微调。基本类别梯度 gbase 是在从情节记忆中提取的小批量上计算的,新颖类别梯度 gnovel 是在来自 DnovelD_{novel}Dnovel 的小批量上计算的。
-
如果 gbase 和 gnovel 之间的角度是锐角,则 gnovel 将按原样反向传播。否则,导出一个新的梯度更新规则,该规则对基本梯度 gbase 和新梯度 gnovel 进行平均。它还自适应地重新加权它们,以防新颖的梯度槽指向可能导致遗忘的方向。
-
要点:为了防止灾难性遗忘并保持基本类别的性能,必须考虑新类别和基本类别的梯度之间的角度。
F. Modify the Training Objective
-
更新训练目标的修改损失可以引导检测器关注前景区域或特定方面,可以提高多个分支的一致性,并且还可以帮助改善对象分类的特征的内类和类间方差。此外,限制检测器中的梯度流或稍微修改训练方案可以改善检测器不同组件的训练。
-
附加损失项:Chen 等人 (LSTD) 在损失函数中使用了附加的背景抑制和转移知识正则化项,以帮助检测器聚焦于目标对象并合并源域知识。 Li 等人 (CGDP + FSCN) 认为基础数据集 DbaseD_{base}Dbase 中新类别 CnovelC_{novel}Cnovel 的未标记实例是有问题的。他们引入了一个额外的半监督损失项来利用这些未标记的实例。
-
Chen等人(AttFDNet)提出了两个损失项来最大化同一类别实例之间的余弦相似度并解决数据集中未标记实例的问题。 Cao等人(FADI)引入了额外的集合专用边际损失来扩大类间可分离性。与之前的边际损失(例如 ArcFace )相比,他们对不同的边际使用缩放因子,其中 CnovelC_{novel}Cnovel 的缩放因子高于 DbaseD_{base}Dbase,因为新颖的类别更具挑战性。 Liu等人(N-PME)通过评估附加数据上新类别的正确和错误伪标签的不确定性分数,使用边际损失来利用容易出错的伪标签。
-
辅助分支的损失:与元学习方法 TIP 类似,Wu 等人 (FSOD-UP) 使用一致性损失来强制两个分支的特征相似。他们在这些特征之间应用 KL 散度损失。 CIR 的上下文模块由辅助分类分支以监督方式进行训练,该分支预测二进制前景-背景分割图。MPSR 的两个分支通过共享权重以及两个分支对损失函数的贡献来松散耦合。 CME 建立在 MPSR 之上,但引入了额外的对抗性训练,如我们在第 V-E 节中所述。此外,Xu 等人(FSSP)引入了一个辅助分支。它包括用于数据增强的检测网络的完整复制。修改后的分类损失结合了原始分支和该辅助分支中的决策,该辅助分支仅处理一个对象,并删除了大部分背景。
-
Sun等人(FSCE)在RoI头中引入了一个新分支。除了标准的 RoI head 之外,他们还应用单个完全连接的层作为对比分支,以便能够测量学习的对象提议表示之间的相似性分数。在对比分支上,他们使用对比提案编码损失进行训练,从而能够增加同一类别表示的余弦相似度,并减少不同类别提案的相似度 。 Lu 等人(DMNet)遵循了类似的方法。他们使用辅助分类分支,通过欧几里德距离将提取的特征与每个类别的代表进行比较。特征嵌入和类别代表是通过基于三元组损失的度量学习来学习的。
-
修改梯度流:Qiao 等人 (DeFRCN) 另外希望在两个训练阶段更新主干,但他们认为训练中的矛盾是有问题的。 RPN 和 ROI head 的目标是相反的,因为 RPN 试图学习与类别无关的区域建议,而 ROI head 试图区分类别。他们的大量实验表明,阻止梯度从 RPN 流向骨干网并将梯度从 ROI 头部缩放到骨干网是关键。在第一阶段 DbaseD_{base}Dbase 训练期间,他们将 ROI 头部的梯度缩放 0.75,以便主干网络学习的内容比检测器其余部分少一点。第二阶段在 DbaseD_{base}Dbase ∪ DnovelD_{novel}Dnovel 上训练时,证明有必要将梯度缩放 0.01,这是冻结主干的方向。停止 RPN 的梯度并缩放 ROI 头的梯度显着提高了性能,尤其是在第二阶段。作者观察到,当使用足够的数据进行训练时,这种梯度缩放也有利于 Faster R-CNN 作为通用目标检测器。
-
Guirguis 等人 (CFA) 导出了一种新的梯度更新规则,该规则考虑了 DbaseD_{base}Dbase 样本和 DnovelD_{novel}Dnovel 样本的梯度之间的角度,以便在微调阶段对抗基本类别 CbaseC_{base}Cbase 的灾难性遗忘,如第 VII-E 节中所述。虽然该梯度更新规则主要旨在保留基本类别 CbaseC_{base}Cbase 的性能,但它也对新类别 CnovelC_{novel}Cnovel 的性能产生积极影响。
-
修改后的训练方案:受 infants 开始从单个观察中学习的启发,在(FORD + BL)中,表明不是立即用 K 个样本进行微调,而是可以通过首先对每个类别的单个样本进行微调,然后再对所有 K 个样本进行微调来提高性能。 Wu等人(TD-Sampler)为微调阶段引入了一种批量采样策略,该策略能够使用DbaseD_{base}Dbase的所有样本,而不是每个基本类别CbaseC_{base}Cbase的K个样本,并在每个训练批次中使用更多新类别CnovelC_{novel}Cnovel的样本。这是通过选择包含大量新类别样本的批次来实现的,并且根据估计的训练难度(TD)判断,不太可能显着改变检测器激活模式。
-
结论:应该根据优化的梯度流和类间可分离性来修改损失。在辅助分支中,对比损失可以帮助提高特征的判别能力,就像在两分支元学习中一样。
G. Use Attention
- 注意力块有助于增强功能。从这个意义上说,Wu 等人 (FSOD-UP) 在学习原型(参见第 VII-H 节)和 RPN 输出之间使用了软注意力来增强额外分支中的特征。 Yang等人(CoTrans)使用锚框与其上下文字段之间的亲和力作为关系注意力,将上下文集成到锚框的表示中。 Xu等人(FSSP)首先通过自注意力模块处理图像,然后通过单级检测器处理注意力丰富的输入。因此,检测器可以聚焦于输入图像的重要部分。 Chen 等人(AttFDNet)结合了自上而下和自下而上的注意力。自上而下的注意力是在简化的非局部块和挤压和激励块中以监督方式学习的。自下而上的注意力是通过显着性预测模型(基于布尔图的显着性(BMS)或显着性注意模型(SAM))计算的。
H. Modify Architecture
-
基于 Faster R-CNN 的架构:大多数迁移学习方法都基于 Faster R-CNN 检测器,如图 8 所示。基准结果证实了这种两阶段检测器对于迁移学习方法的优越性。只有少数方法偏离了这种架构。
-
Li等人(CGDP + FSCN)观察到,Faster R-CNN中新类别的性能下降主要是由误报分类(即类别混淆)引起的。因此,他们在一个额外的可辨别性增强分支中细化了分类,该分支是用错误分类的假阳性样本进行训练的。它直接处理待分类对象的裁剪图像。然后,将分类结果与原始 Faster R-CNN 分支的分类结果融合。 Qiao 等人 (DeFRCN) 也观察到新类别的许多低分类分数。
-
与Li等人类似,他们得出的结论是,分类的平移不变特征和定位的平移协变特征的相反要求是有问题的。为了解决这个问题,他们提出了一个原型校准块,它执行分数细化以消除高分误报分类。
-
Wu 等人 (MPSR) 在训练期间使用辅助细化分支进行数据增强,但在推理期间被排除。 SVD 建立在 MPSR 的基础上。通过奇异值分解(SVD),他们将主干特征 fBf^BfB 分解为特征向量,其相关性由相应的奇异值量化。与最大奇异值相对应的特征向量被合并用于定位,因为它们能够抑制某些变化。相反,与较小奇异值相对应的特征向量被合并用于类别区分,因为它们编码类别相关信息。通过利用字典学习进一步细化该辨别空间以促进分类。
-
Wu等人(FSOD-UP)采用了反映类别信息的原型的少样本学习思想。与双分支元学习中的特定类别原型相反,它们根据处理骨干特征的额外分支中的所有类别学习通用原型。这些通用原型在不同的视觉变化下保持不变,从而增强了主干的原始特征。在处理 RPN 中的原始特征和增强特征后,在辅助分支中对 RPN 特征重复此处理,以计算 ROI 头部的输入。
-
合并一级检测器:LSDT 是最早的 FSOD 方法之一,它结合了遵循 SSD 方法的边界框回归和用于对象分类的 Faster R-CNN 概念。Yang 等人 (CoTrans) 使用 SSD 作为单级检测器。他们认为,该架构中的多尺度空间感受野提供了丰富的上下文,这对于知识转移非常重要。 Chen等人(AttFDNet)也使用了SSD检测器,但添加了两个注意分支,以帮助检测器专注于图像的重要部分,以及六个预测头,用于预测不同尺度对象的边界框和类别。Lu等人(DMNet)提出了一种单级检测器,遵循SSD和YOLO的设计原则,但使用两个解耦分支进行定位和分类。有人认为,这种解耦有利于适应,仅举几个例子。
-
Xu 等人 (FSSP) 展示了如何在中描述的普通设置中使快速单级检测器(即 YOLOv3 )与较慢的两级检测器 Faster R-CNN 竞争。这只有通过付出大量努力才能实现,即合并自注意力模块、使用包含检测网络的完整复制的附加辅助分支、增强辅助分支的输入数据并应用附加损失。然而,由于这些修改,Xu 等人的快速一级检测器在极低样本场景中的表现尤其优于 TFA 。
-
要点:在基于 Faster R-CNN 的检测器中,分数细化有助于减少误报分类 。单级检测器可以从辅助分支中获益,以实现数据增强。
表现最佳的迁移学习方法总结
-
在下文中,我们总结了选定的迁移学习方法,这些方法具有关于上述类别的不同概念,这些方法在 FSOD 基准数据集上表现最佳(参见第 IX 节)。
-
在DeFRCN中,发现RPN中的类不可知定位任务和ROI头的类区分任务是相反的。因此,停止从 RPN 到主干的梯度流并将梯度从 ROI 头缩放到主干是关键。然后,可以在两个训练阶段训练检测器的所有组件,包括主干网络,这显着提高了性能,尤其是在微调阶段。此外,原型校准块在 ROI 头部中执行分数细化,以消除高分误报分类,这是分类的平移不变特征和定位的平移协变特征相反要求的结果。
-
CFA 可以应用于 DeFRCN 之上,以解决微调过程中基本类别的灾难性遗忘,这种情况发生在基本类别梯度和新类别梯度之间的角度为钝角时。因此,CFA 将 K 个基本类别的样本存储在情景存储器中,以便在微调期间在 DbaseD_{base}Dbase 上计算梯度。如果基础类别梯度和新类别梯度之间的角度是钝角,则对两个梯度进行平均并自适应地重新加权;否则,新颖的类别梯度可以反向传播,而不会出现灾难性遗忘的风险。这种梯度更新规则也有利于新类别的性能。
-
在微调之前,FADI 通过 WordNet 测量它们的语义相似性,将每个新颖类别与一个基本类别相关联。然后,训练网络将新类别的特征分布与相关的基本类别对齐。这导致小说类别的类内差异较小,但不可避免地会导致 CbaseC_{base}Cbase 和 CnovelC_{novel}Cnovel 之间的混淆。因此,在随后的判别步骤中,CbaseC_{base}Cbase 和 CnovelC_{novel}Cnovel 的分类分支被解开以学习良好的判别。此外,还采用了集合专用边际损失来扩大类间可分离性。
-
如果可以获得包含新类别的其他未标记数据,则可以应用半监督学习技术。在 FSOD 基准数据集上,DbaseD_{base}Dbase 可用于此目的。 LVC 使用在第二训练阶段在 DnovelD_{novel}Dnovel 上微调的检测器对这些数据进行伪标记。首先,利用ViT的特征以最近邻方式与DnovelD_{novel}Dnovel的样本进行比较,验证搜索到的小说样本是否属于CnovelC_{novel}Cnovel。然后,类似于Cascade R-CNN,对验证样本的不准确边界框进行校正。使用新类别的高质量扩展数据,检测器的所有组件都可以在额外的微调阶段进行训练。
关于迁移学习方法的结论
- 迁移学习方法的训练流程要简单得多,因为它们不需要像元学习那样复杂的情景训练。通过结合特定技术,能够尽可能多地微调检测器的组件(例如,修改训练目标或在基础类别和新类别之间转移知识),迁移学习方法能够达到最先进的性能。
COMPARISON BETWEEN META LEARNING AND TRANSFER LEARNING
- 在详细阐述了元学习和迁移学习的不同方法之后,我们现在想要进行比较。由于单分支元学习在最近的工作中探索较少,并且在性能方面也落后,因此我们在比较中放弃它。在表1中,我们根据几个重要方面比较了双分支元学习和迁移学习。两者似乎对未来的工作都有希望,并且都可以通过纳入其他训练计划的想法而受益。
-
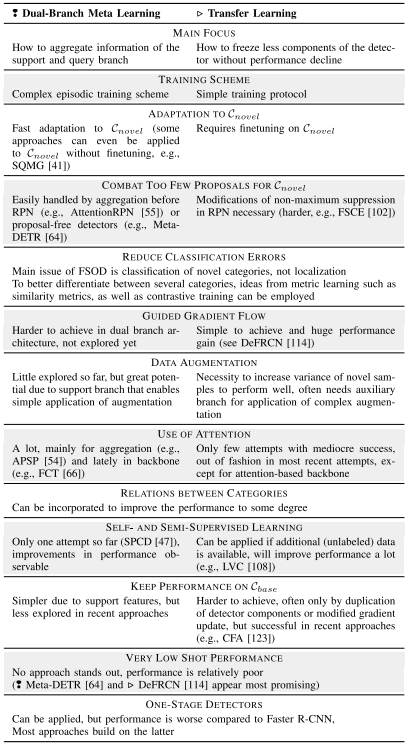
-
表 I 双分支元学习和迁移学习之间的比较
-
DATASETS, EVALUATION PROTOCOLS, AND BENCHMARK RESULTS
-
对少样本目标检测器的评估需要定制的数据集来区分基本类别和新类别。因此,大多数方法使用常见对象检测数据集 PASCAL VOC 和 Microsoft COCO 的特定分割。只有极少数情况下,才会应用其他数据集,例如 FSOD、ImageNet-LOC 或 LVIS。一般来说,少样本目标检测器以 K-shot-N-way 方式进行评估,即 DnovelD_{novel}Dnovel 由 N 个新颖类别的 K 个标记示例组成。
-
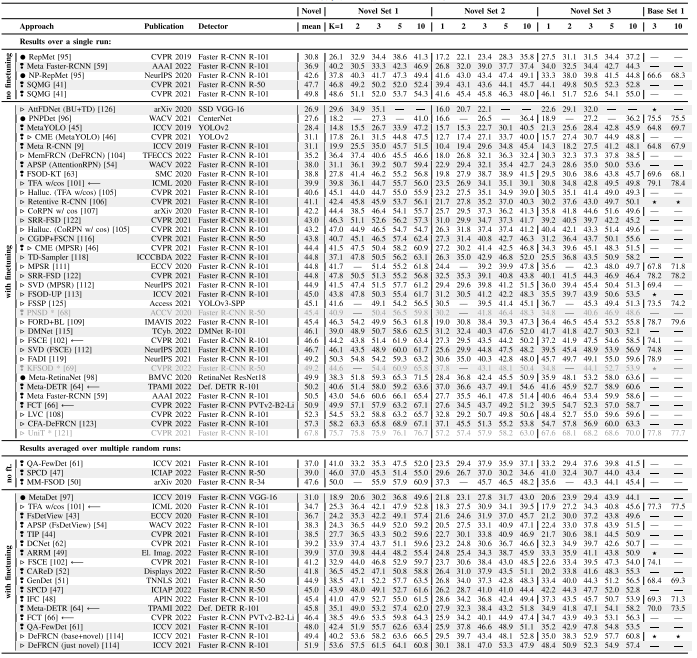
-
表 II AP50 公布的所有三组和不同样本数 K 的帕斯卡 VOC 基准结果。我们按照所有新颖组和镜头的平均值对方法进行排序。 ---:没有纸质报告结果。 ⋆:仅报告不同镜头或组数的结果,因此,此处不包含这些结果。 *:偏离评估协议,妨碍公平比较,如第 IX-C 节所述。 ❢:双分支元学习。 •:单分支元学习。 ▷:迁移学习
A. PASCAL VOC Dataset
-
PASCAL VOC 数据集 包含 20 个类别的注释。通常,使用VOC 07 + 12个训练集的组合进行训练,使用VOC 07测试集进行测试。为了评估少样本目标检测器,最常使用三个类别分割,每个类别有 15 个基本类别和 5 个新类别 (N = 5)。
- 集合 1:CnovelC_{novel}Cnovel = {鸟、公共汽车、牛、摩托车、沙发}。
- 集合2:CnovelC_{novel}Cnovel={飞机、瓶子、牛、马、沙发}。
- 集合3:CnovelC_{novel}Cnovel = {船,猫,摩托车,羊,沙发}。
-
新类别的样本数量 K 设置为 1、2、3、5 和 10。作为评估指标,使用并集交集 (IoU) 阈值 0.5 处的平均精度 (AP50)。不幸的是,特定的 K-shot 对象实例不是固定的,这导致不同方法中使用不同的实例。正如 Wang 等人所述,训练样本中的这种高方差使得很难对方法进行相互比较,因为与基于不同实例的差异相比,基于方法的性能差异可能微不足道。因此,Wang 等人 提出了一种修订后的评估协议,其中结果是使用训练样本的不同随机样本进行 30 次运行的平均值。
-
此外,他们还报告基本类别的性能,因为忽略基本类别的性能可能会隐藏潜在的性能下降,因此不适合评估模型的整体性能。目前,关注这一主题的方法还报告了广义 FSOD (G-FSOD) 性能的结果,它指的是新颖类别和基本类别的平均值。
-
在表 II 中,我们列出了 PASCAL VOC 数据集所描述方法的基准结果。我们根据 Wang 等人 提出的结果是针对单次运行给出的结果还是对多次运行的平均值来划分表格。为两种评估协议提供结果的方法都标有"←−",作为比较的锚点。两种评估协议之间的性能差距不可忽略,并且表明平均结果更可靠 。此外,我们还指出是否需要对 DnovelD_{novel}Dnovel 进行微调,或者是否通过简单的元测试即可获得结果。每种方法的前面都有一个小符号。一般来说,迁移学习和双分支元学习方法都可以取得相似的结果。第 V 节的双分支元学习和第 VI-D 节的迁移学习的末尾总结了最佳表现方法的主要特征。
-
尽管 PASCAL VOC 数据集非常常用,但根据 Michaelis 等人的说法,它太简单了。通过双分支元学习方法和信息量不大的全黑支持图像,他们仍然能够定位新物体并达到 33.2 的 mAP50。然而,我们要强调的是,一般来说,对象不仅需要定位,还需要分类,即检测器还需要确定图像中存在哪个类别。
B. Microsoft COCO Dataset
-
与 PASCAL VOC 相比,Microsoft COCO 数据集更具挑战性,包含 80 个类别的注释,其中包括 20 个 VOC 类别。对于 FSOD,最常见的是,20 个 VOC 类别被用作新类别,而其余 60 个类别则作为基本类别。通常,拍摄次数K设置为10和30。然而,有些方法侧重于极低的样本范围,每个类别仅使用 1-3 个样本。
-
为了进行评估,使用标准 COCO 指标。主要指标是 AP50:95:IoU 阈值范围为 0.5, 0.95 的 10 个平均精度值的平均值。此外,还报告了 AP50,它对应于 Pascal VOC 指标。AP75 更严格,因为只有当检测与真实物体的 IoU 大于 0.75 时才算为正检测。
-
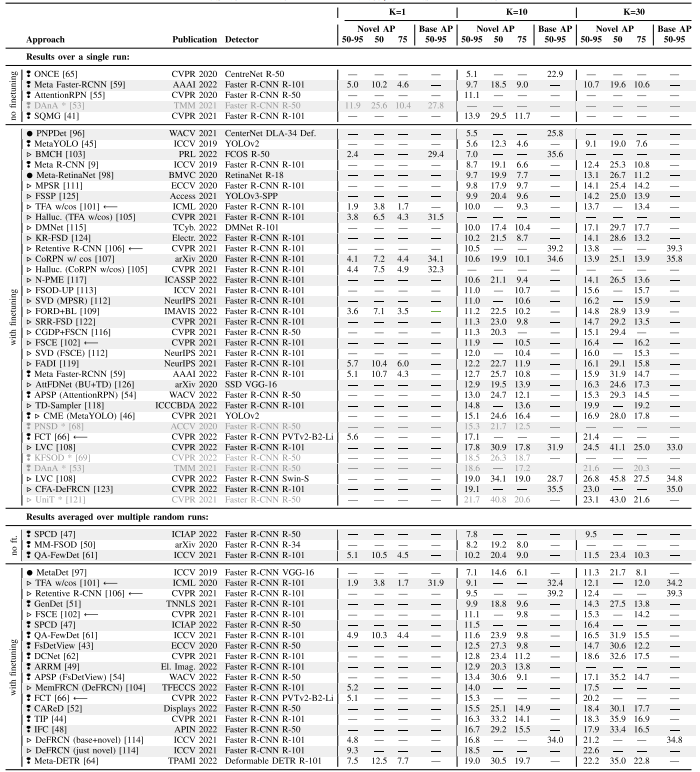
-
表 III MICROSOFT COCO 数据集的基准结果(按 10 次测试的 NOVEL AP50:95 排序)。 ---:没有纸质报告结果。*:偏离评估协议,妨碍公平比较,如第 IX-C 节所述。 ❢:双分支元学习。•:单分支元学习。 ▷:转移学习
-
-
我们在表 III 中列出了 K = 1、K = 10 和 K = 30 的已发布基准结果。与 PASCAL VOC 类似,Microsoft COCO 上的少样本检测器的评估也受到方法之间 K-shot 实例不同的影响。因此,我们再次根据是否使用 Wang 等人提出的修订后的评估协议来拆分表格,其中结果是使用不同随机样本进行十次运行的平均值。
C. Deviating Evaluation Protocols
-
一般来说,对象检测是对象实例定位和分类的联合任务。然而,一些小样本方法偏离了这个设置并创建了一个更简单的任务。例如,一些明确关注一次性场景的方法(CoAE 、AIT 、OSWF 和 CGG )假设每个查询图像 I Q 至少具有来自支持图像 IS,cI^{S,c}IS,c 的对象类别 c 的一个实例。隐含地,这消除了分类任务,只需要本地化。这同样适用于 DAnA 的单向训练和评估设置,其中检测器只需要估计当前查询图像 IQI^QIQ 是否包含对象及其位置,但消除了正确分类的难度。因此,为了报告可比较的结果,我们强烈建议始终使用 N 路设置进行评估。
-
相比之下,PNSD 和 KFSOD 通过利用在 COCO 上预训练的 ResNet 简化了对新类别的泛化,使得新类别不再是真正的新类别。
D. Problems of Common Evaluation Protocols
-
不同样本的高方差:正如 Wang 等人所指出的,对新类别使用不同样本可能会导致性能的高方差,因此使比较变得困难。因此,我们强烈建议始终报告多次随机运行结果的平均值。
-
ImageNet 预训练和新颖类别的选择:大多数方法都使用 ImageNet 预训练的主干网。虽然这对于通用对象检测很常见,但它对 FSOD 具有负面影响:新颖的类别不再真正新颖,因为模型可能已经看到过该类别的图像。然而,完全省略 ImageNet 预训练会导致性能更差,即使对于基本类别也是如此。为了缓解这个问题,有两种选择。
-
首先,与新类别相对应的 ImageNet 类别可以从 ImageNet 预训练中排除,如 CoAE 、SRR-FSD 和 AIT 中所做的那样。CoAE 和 AIT 甚至从 ImageNet 中删除了所有与 COCO 相关的类别,这导致 275 个类别被删除。然而,正如 Zhu 等人 (SRRFSD) 所说,删除所有与 COCO 相关的类别是不现实的,因为这些类别在自然世界中非常常见,删除 275 个类别可能会影响通过预训练学习到的表征能力。因此,Zhu等人仅删除了PASCAL VOC的新类别对应的类别,导致平均删除了50个类别。然而,这需要对每组不同的新颖类别进行额外的预训练。
-
防止预见新类别的第二种选择是使用包含 ImageNet 中未出现的新类别的数据集。这样的数据集也会更加真实。使用猫等类别作为新类别是荒谬的,因为有大量带注释的数据。因此,更现实的方法是选择确实罕见的新颖类别。例如,LVIS 数据集提供了一个自然的长尾,其中包含频繁和不频繁的类别。对于稀有类别,最多有 10 个可用的训练实例。因此,它们可以作为新颖的类别。然而,Huang等人指出,训练集中的一些稀有类别根本没有出现在验证集中,这阻碍了性能评估,需要进一步细化平衡分割和评估集。
CURRENT TRENDS
A. Improvement of Techniques
- 目前,双分支元学习方法通过使用注意力来聚合两个分支的特征而得到了很大的改进。通过在 RPN 之前聚合或使用无提案 Transformer 作为检测器 ,有效解决了新类别缺失提案的问题。目前,迁移学习方法通过引导梯度流能够训练尽可能多的检测器组件而得到了很大改进。在这两种方法中,当前的趋势是通过修改损失函数来使用度量学习概念,以实现更好的类别分离。作为第八节比较的一部分,强调了更多趋势。
B. Extension to Related Research Areas
- 除了改进 FSOD 技术的这些趋势之外,将 FSOD 概念扩展到进一步的研究领域,例如弱监督设置 、自监督学习 或少样本实例分割 ,也是当前的趋势。
C. Open Challenges
- 许多方法侧重于改进元学习或迁移学习,但往往忽略了两种方法之间的概念是可以互换的,如表一所示,这为未来的工作留下了改进的潜力。由于主要使用的 FSOD 基准 PASCAL VOC 和 Microsoft COCO 不包含代表稀有物体的现实新颖类别,因此我们希望鼓励未来的研究对 LVIS 或 FSOD 等更现实的数据集进行额外评估,正如中已经完成的那样。此外,提供了用于创建定制FSOD数据集的框架。当在现实环境中使用 FSOD 时,包括非常罕见的类别,很可能会发生域转移。因此,跨域检测的概念应该在未来的工作中进一步探索。
CONCLUSION
-
在本次调查中,我们全面概述了 FSOD 的最新技术。我们根据训练方案和架构布局将这些方法分为单分支元学习和双分支元学习和迁移学习。元学习方法使用情景训练来改进后续学习,每个新类别只需要很少的对象实例。双分支元学习方法利用一个单独的支持分支接收指定对象的图像,以学习如何表示对象的类别以及在查询图像中关注的位置。迁移学习方法通过简单地对新类别进行微调,使用更简化的训练方案。
-
在介绍主要概念后,我们详细阐述了具体方法与一般实现的不同之处,并给出了简短的要点,以突出表现良好的方法的关键见解。基于对最广泛使用的数据集 PASCAL VOC 和 Microsoft COCO 的基准测试结果的分析,我们确定了性能最佳的双分支元学习和迁移学习方法的当前趋势。这两个概念中哪一个更具代表性仍然是一个悬而未决的问题。
-
基于 YOLO(单阶段检测器)提升小样本目标检测能力(3-8 shot / 类,多类别),核心是 "数据方差扩充 + 模型特征增强 + 小样本适配训练",需结合 FSOD 的迁移学习、度量学习、数据增强等关键技术,同时保留 YOLO 的实时性优势。整体遵循 "基础预训练→小样本微调→性能优化" 的流程,重点解决小样本下的过拟合、特征泛化不足、多类别混淆三大问题。
数据层:扩充小样本方差,挖掘跨类别知识
-
小样本检测的核心瓶颈是数据多样性不足 ,需通过 "物理增强 + 虚拟扩充 + 知识迁移" 三重方式提升数据价值,对应文档中 "增加新类别方差""跨类别知识迁移" 技术。每类保留 3-8 个高质量标注样本(优先选择姿态 / 尺度 / 背景多样的样本,避免遮挡严重、模糊的样本),确保边界框标注精准(减少定位误差对小样本训练的影响)。划分基础数据集(DbaseD_{base}Dbase,含大量已标注类别)和新类别数据集(DnovelD_{novel}Dnovel,3-8 shot / 类),确保两类无交集(Cbase∩Cnovel=∅C_{base} \cap C_{novel} = \emptysetCbase∩Cnovel=∅)。
-
针对新类别样本,采用 "尺度 + 平移 + 形变 + 噪声" 组合增强。增强后需保持边界框同步更新,且避免过度增强导致目标特征失真(如极端尺度缩放)。
-
伪标签生成 ,步骤 1:用预训练好的 YOLO 模型(仅基础类别CbaseC_{base}Cbase)对未标注数据(或DbaseD_{base}Dbase中可能含新类别特征的图像)进行推理,筛选置信度≥0.7 的预测框作为伪标签。步骤 2:用新类别样本(3-8 shot)微调模型后,再次对伪标签数据推理,验证伪标签准确性(可通过 ViT 特征相似度匹配新类别样本)。步骤 3:将验证通过的伪标签样本加入DnovelD_{novel}Dnovel,扩充至每类 10-15 个样本(平衡方差与标注质量)。
-
冻结与微调策略 ,冻结 YOLO 骨干网络(如 Darknet-53、CSPDarknet)的前 80% 层(保留基础类别学到的通用特征),仅微调后 20% 层 + 检测头(减少小样本下的过拟合)。可在骨干网络添加自注意力模块,增强新类别特征的全局关联性(小样本下局部特征易缺失)。
-
特征融合优化 :YOLO 的 FPN 层添加跨尺度注意力融合,重点增强小目标的特征(小样本下小目标更难检测):对新类别样本集中的小目标,在 FPN 的 P3/P4 层添加注意力权重,提升小目标特征响应。
-
分类头:余弦相似度替代 Softmax ,有的YOLO版本 默认的 Softmax 分类对小样本特征分布敏感(易偏向基础类别),改为余弦相似度分类:将类别嵌入向量与预测特征向量做归一化后的点积,补偿基础 / 新类别特征范数差异。将检测头的全连接层输出改为 "特征向量"(如 256 维),预训练基础类别嵌入向量,新类别嵌入向量由 3-8 shot 样本的特征平均得到。
-
损失函数:添加对比损失 + Focal Loss ,对比损失(Metric Learning 核心):拉近同类别特征距离,拉远异类别(尤其是相似类别),公式参考:Lcontrast=−1N∑i=1Nlogecos(fi,ci)/τ∑j≠iecos(fi,cj)/τL_{contrast} = -\frac{1}{N} \sum_{i=1}^N \log \frac{e^{\cos(f_i, c_i)/\tau}}{\sum_{j \neq i} e^{\cos(f_i, c_j)/\tau}}Lcontrast=−N1∑i=1Nlog∑j=iecos(fi,cj)/τecos(fi,ci)/τ其中fif_ifi是预测特征,cic_ici是类别嵌入,τ\tauτ是温度系数(取 0.1-0.3)。Focal Loss:处理小样本下 "前景(新类别)- 背景" 极度不平衡 ,下调易分背景样本的权重,聚焦难分前景。