Yolov3 目标检测算法原理详解
核心改进:网络架构
得到了更高的准确性和更好的泛化能力
由于军工领域的应用,2020年Joseph Redmon宣布推出计算机视觉的研究。
网络结构
Backbone + Neck + Prediction(head)
图片来源:bilibili 炮哥带你学

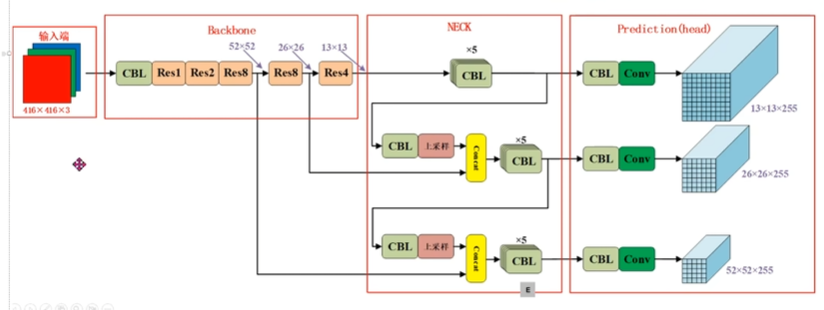
Backbone 做分类模型
Backbone后面接上Avgpooling, Linear,softmax即为分类模型。
Neck 颈部
图像金字塔FPN
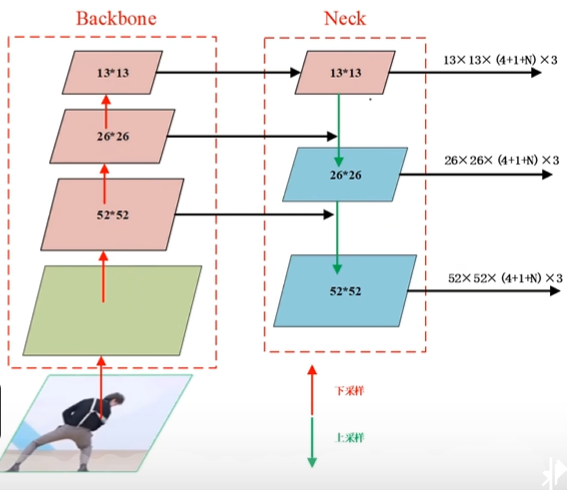
在早期的目标检测中,图像金字塔是一种常见的多尺度处理手段:将输入图像缩放成不同分辨率(如512×512、256×256等),分别送入网络进行检测,最后综合所有尺度的结果。这种方法虽然能提升多尺度检测能力,但计算量巨大,且需要多次前向推理,效率较低。
YOLOv3没有采用这种传统的图像金字塔,而是使用了特征金字塔的思想,即在不同深度的特征图上进行预测,从而在单次前向过程中覆盖多个尺度。
FPN最初由Lin等人在2017年提出,旨在高效构建多尺度的特征表示。其核心思想是:
-
自底向上的路径:骨干网络(如ResNet)自然形成不同分辨率的特征层(例如从浅层到深层,分辨率逐渐降低,语义信息逐渐增强)。
-
自顶向下的路径:通过上采样将高层语义特征图放大,然后与对应的底层特征图进行横向连接(通常是相加或拼接),使底层特征也能获得丰富的语义信息。
-
多尺度预测:在融合后的不同层级特征图上独立进行预测,每个层级负责检测特定尺度范围的目标(大、中、小)。
这种设计既保留了底层细节(利于小目标),又融合了高层语义(利于大目标),且计算开销远小于图像金字塔。
YOLOv3中的FPN实现
YOLOv3借鉴了FPN的思想,但做了简化,形成了自己的多尺度预测结构。具体来说:
- 骨干网络:YOLOv3使用Darknet-53作为特征提取器。网络在三个不同尺度的特征图上进行检测,分别对应下采样32倍、16倍和8倍的特征层:
13×13(下采样32倍):感受野最大,负责检测大目标。
26×26(下采样16倍):由13×13的特征图上采样后与Darknet-53中对应的26×26特征图拼接而成,负责检测中等目标。
52×52(下采样8倍):由26×26的特征图上采样后与对应的52×52特征图拼接而成,负责检测小目标。
融合方式:YOLOv3不是像标准FPN那样进行逐元素相加,而是采用通道拼接(concatenation)。高层特征经过上采样后,与骨干网络中相同分辨率的底层特征在通道维度上拼接,从而同时获得语义信息和细节信息。
预测头:每个尺度的特征图后接一组卷积层,最终输出边界框、目标置信度和类别概率。
这种结构使得YOLOv3在单次前向中就能获得丰富的多尺度特征,显著提升了对小目标的检测能力,同时保持了较高的推理速度。
head 检测头
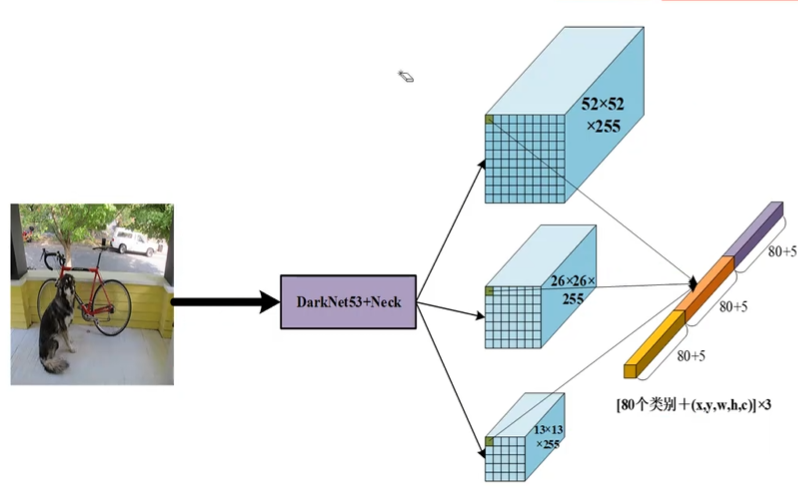
在YOLOv3中,head(检测头)是网络的最后一部分,负责将FPN生成的多尺度特征图转换为最终的检测结果,包括边界框坐标、目标置信度和类别概率。它是整个检测流程的决策输出层。
1. head的结构
YOLOv3在三个不同尺度的特征图上分别设置了一个检测头,每个头的结构基本相同,由一系列卷积层组成:
- 通常先通过几个卷积层进一步提取特征(例如在YOLOv3原文中,每个尺度的特征图后接一组卷积层,具体配置为:Conv 3×3 + Conv 1×1的组合)。
- 最后一个卷积层的滤波器数量由预测任务决定,输出张量的维度为 S × S × 3 × ( 4 + 1 + C ) S \times S \times 3 \\times (4 + 1 + C) S×S×3×(4+1+C):
- S × S S \times S S×S:特征图的空间尺寸(如13×13、26×26、52×52)。
- 3:每个网格单元预测的边界框数量(锚框个数)。
- 4:边界框的4个坐标偏移量( t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th)。
- 1:目标置信度(objectness score),表示该框内包含目标的概率。
- (C):类别数(COCO数据集为80)。
因此,对于COCO数据集,每个尺度的输出通道数为 3 × ( 4 + 1 + 80 ) = 255 3 \times (4 + 1 + 80) = 255 3×(4+1+80)=255。最终输出是一个三维张量,包含了所有预测信息。
2. head的预测内容
每个网格单元负责预测固定数量的边界框(这里为3个),每个框的预测值包括:
- 边界框坐标 :YOLOv3采用相对偏移的预测方式。对于每个锚框,网络预测 t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th,通过以下公式转换为最终坐标:
b x = σ ( t x ) + c x , b y = σ ( t y ) + c y , b w = p w e t w , b h = p h e t h b_x = \sigma(t_x) + c_x, \quad b_y = \sigma(t_y) + c_y, \quad b_w = p_w e^{t_w}, \quad b_h = p_h e^{t_h} bx=σ(tx)+cx,by=σ(ty)+cy,bw=pwetw,bh=pheth
其中 c x , c y c_x, c_y cx,cy 是网格单元的左上角坐标, p w , p h p_w, p_h pw,ph 是锚框的宽高, σ \sigma σ 是sigmoid函数,确保中心点落在网格内。 - 目标置信度:一个sigmoid输出,表示该框包含目标的概率(即与真实框的IoU)。
- 类别概率:每个类别的得分,通过sigmoid或softmax(YOLOv3使用独立的逻辑分类器,即每个类别用sigmoid,以适应多标签情况)输出,表示该框内目标属于各类别的概率。
3. 锚框(anchor boxes)的作用
每个尺度的head对应3个预设的锚框,这些锚框通过K-means聚类在训练数据集上得到,分别适合不同大小的目标:
- 大尺度特征图(13×13):感受野大,锚框尺寸较大,负责检测大目标。
- 中尺度特征图(26×26):锚框尺寸中等,负责检测中等目标。
- 小尺度特征图(52×52):感受野小,锚框尺寸较小,负责检测小目标。
head不直接预测框的绝对尺寸,而是预测相对于这些锚框的偏移量,从而简化学习难度。
4. head与FPN的协同
FPN提供了三个不同语义层次和分辨率的特征图,每个head分别作用于其中一个特征图。这种设计实现了多尺度检测:
- 浅层特征图(52×52)细节丰富,适合小目标。
- 深层特征图(13×13)语义强,适合大目标。
- 每个head独立预测,最后将所有尺度的预测结果合并,通过非极大值抑制(NMS)得到最终输出。
5. head的改进意义
相比于YOLOv2的单一尺度检测头,YOLOv3的多头设计显著提升了模型对多尺度目标的适应能力,尤其是小目标检测。同时,每个head采用锚框机制和坐标偏移预测,保持了YOLO系列快速、简洁的特点。
正负样本
在 YOLOv3 的训练中,每个预测框(anchor 对应的预测)会被划分为三类:正例、忽略样例、负例。划分依据是预测框与 ground truth 的 IoU。
1. 正例
分配规则
- 对于每个 ground truth,在所有预测框中计算 IoU
- IoU 最大的那个预测框被分配为该 ground truth 的正例
- 一个预测框最多只负责一个 ground truth(避免重复分配)
- 不要求 IoU 必须超过阈值
参与的 loss
正例会参与三部分损失:
- 置信度 loss(objectness)
- 边框回归 loss(bbox loss)
- 分类 loss(class loss)
正例的置信度标签为 1
2. 忽略样例(Ignore)
判定条件
在排除正例之后:
- 如果某预测框与任意一个 ground truth 的 IoU
- 大于 ignore 阈值(通常为 0.5)
则该预测框被标记为忽略样例。
特点
- 不参与任何 loss 计算
- 不作为正例
- 不作为负例
作用
忽略样例用于:
- 防止把质量尚可的预测框当成负样本惩罚
- 缓解正负样本极度不平衡
- 稳定训练过程
3. 负例
判定条件
在排除正例之后:
- 如果某预测框与所有 ground truth 的 IoU
- 都小于 ignore 阈值
则该预测框为负例。
参与的 loss
负例只参与:
- 置信度 loss(objectness)
不会参与:
- 边框 loss
- 分类 loss
负例的置信度标签为 0
判定流程总结
对于每个预测框:
- 是否是某个 GT 的最大 IoU?
- 是 → 正例
- 否 → 是否与任一 GT 的 IoU > ignore_thresh?
- 是 → 忽略样例
- 否 → 负例
常见易错点
- 正例不要求 IoU > 0.5
- 忽略样例不产生任何 loss
- 负例只计算置信度 loss
- 一个预测框只能匹配一个 GT
- YOLOv3 是 anchor-based 且多尺度独立分配
损失函数
YOLOv3 损失函数详解
YOLOv3 的整体损失由三部分组成:
- 位置损失(bbox regression)
- 置信度损失(objectness)
- 分类损失(classification)
只对"负责该目标的预测框"(正样本)计算完整损失,对负样本只计算置信度损失。
总体损失形式
Loss = λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i , j o b j ⋅ L b o x + ∑ i = 0 S 2 ∑ j = 0 B 1 i , j o b j ⋅ L c l s + o b j + λ n o o b j ∑ i = 0 S 2 ∑ j = 0 B 1 i , j n o o b j ⋅ L n o o b j \text{Loss} = \lambda_{coord}\sum_{i=0}^{S^2}\sum_{j=0}^{B} \mathbf{1}{i,j}^{obj}\cdot L{box} + \sum_{i=0}^{S^2}\sum_{j=0}^{B} \mathbf{1}{i,j}^{obj}\cdot L{cls+obj} + \lambda_{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^{B} \mathbf{1}{i,j}^{noobj}\cdot L{noobj} Loss=λcoordi=0∑S2j=0∑B1i,jobj⋅Lbox+i=0∑S2j=0∑B1i,jobj⋅Lcls+obj+λnoobji=0∑S2j=0∑B1i,jnoobj⋅Lnoobj
其中:
- S 2 S^2 S2:网格数
- B B B:每个网格的 anchor 数
- 1 o b j \mathbf{1}^{obj} 1obj:正样本指示
- 1 n o o b j \mathbf{1}^{noobj} 1noobj:负样本指示
位置损失(Bounding Box Loss)
仅对正样本计算。
坐标回归项
L b o x = ( b x − b \^ x ) 2 + ( b y − b \^ y ) 2 + ( b w − b \^ w ) 2 + ( b h − b \^ h ) 2 ⋅ ( 2 − w i h i ) L_{box} = \left(b_x-\\hat b_x)\^2 + (b_y-\\hat b_y)\^2 + (b_w-\\hat b_w)\^2 + (b_h-\\hat b_h)\^2\\right \cdot (2 - w_i h_i) Lbox=(bx−b\^x)2+(by−b\^y)2+(bw−b\^w)2+(bh−b\^h)2⋅(2−wihi)
变量含义
- ( b x , b y , b w , b h ) (b_x,b_y,b_w,b_h) (bx,by,bw,bh):真实框
- ( b ^ x , b ^ y , b ^ w , b ^ h ) (\hat b_x,\hat b_y,\hat b_w,\hat b_h) (b^x,b^y,b^w,b^h):预测框
- w i h i w_i h_i wihi:真实框面积(归一化后)
小目标权重的作用
( 2 − w i h i ) (2 - w_i h_i) (2−wihi) 是一个尺度权重:
- 框越小 → 权重越大
- 框越大 → 权重越小
目的:
- 防止大框主导训练
- 提升小目标检测效果
- 平衡不同尺度目标的梯度
正样本置信度与分类损失
只对正样本计算。
L c l s + o b j = − log ( p c ) + ∑ k = 1 n B C E ( c ^ k , c k ) L_{cls+obj} = -\log(p_c) + \sum_{k=1}^{n} BCE(\hat c_k, c_k) Lcls+obj=−log(pc)+k=1∑nBCE(c^k,ck)
置信度损失(objectness)
− log ( p c ) -\log(p_c) −log(pc)
含义:
- p c p_c pc:预测该框有目标的概率
- 正样本标签为 1
- 使用二元交叉熵形式
YOLOv3 中 objectness 标签为 0/1,而不是 IoU。
分类损失(classification)
∑ k = 1 n B C E ( c ^ k , c k ) \sum_{k=1}^{n} BCE(\hat c_k, c_k) k=1∑nBCE(c^k,ck)
YOLOv3 的重要变化:
- 使用 sigmoid + BCE
- 不再使用 softmax
优点:
- 支持多标签
- 类别独立建模
- 训练更稳定
负样本置信度损失
只对负样本计算。
L n o o b j = − log ( 1 − p c ) L_{noobj} = -\log(1 - p_c) Lnoobj=−log(1−pc)
完整形式:
λ n o o b j ∑ i = 0 S 2 ∑ j = 0 B 1 i , j n o o b j ⋅ − log ( 1 − p c ) \lambda_{noobj} \sum_{i=0}^{S^2}\sum_{j=0}^{B} \mathbf{1}_{i,j}^{noobj}\cdot -\\log(1-p_c) λnoobji=0∑S2j=0∑B1i,jnoobj⋅−log(1−pc)
特点
负样本:
- 不参与 bbox 回归
- 不参与分类
- 只训练 objectness
为什么要有 λ n o o b j \lambda_{noobj} λnoobj
因为负样本数量远大于正样本,如果不降权:
- 训练会被背景主导
- 模型倾向于预测全是背景
通常:
λ n o o b j < 1 \lambda_{noobj} < 1 λnoobj<1
三类样本与损失对应关系
| 样本类型 | bbox loss | obj loss | cls loss |
|---|---|---|---|
| 正样本 | 计算 | 计算 | 计算 |
| 忽略样本 | 不计算 | 不计算 | 不计算 |
| 负样本 | 不计算 | 计算 | 不计算 |
工程实现流程(重要)
实际训练通常按如下顺序:
- 匹配正样本 anchor
- 标记 ignore anchor
- 构建 obj / noobj mask
- 分别计算三部分 loss
- 加权求和得到总 loss
优缺点总结
优点
-
多尺度检测:在三个不同的尺度上检测,提高模型对于不同大小物体的识别能力
-
在类别预测方面,YOLOV3使用BCE
-
多个anchorbox
-
更大更深的模型 (主干+neck+head)最重要的优势
-
新的损失函数,更加注重目标的定位和分类
缺点
-
小目标检测仍然有局限性
-
高置信度的错误检测:Yolov3可能会生成一些高置信度的错误检测,尤其是在目标密集或者重叠的场景中。