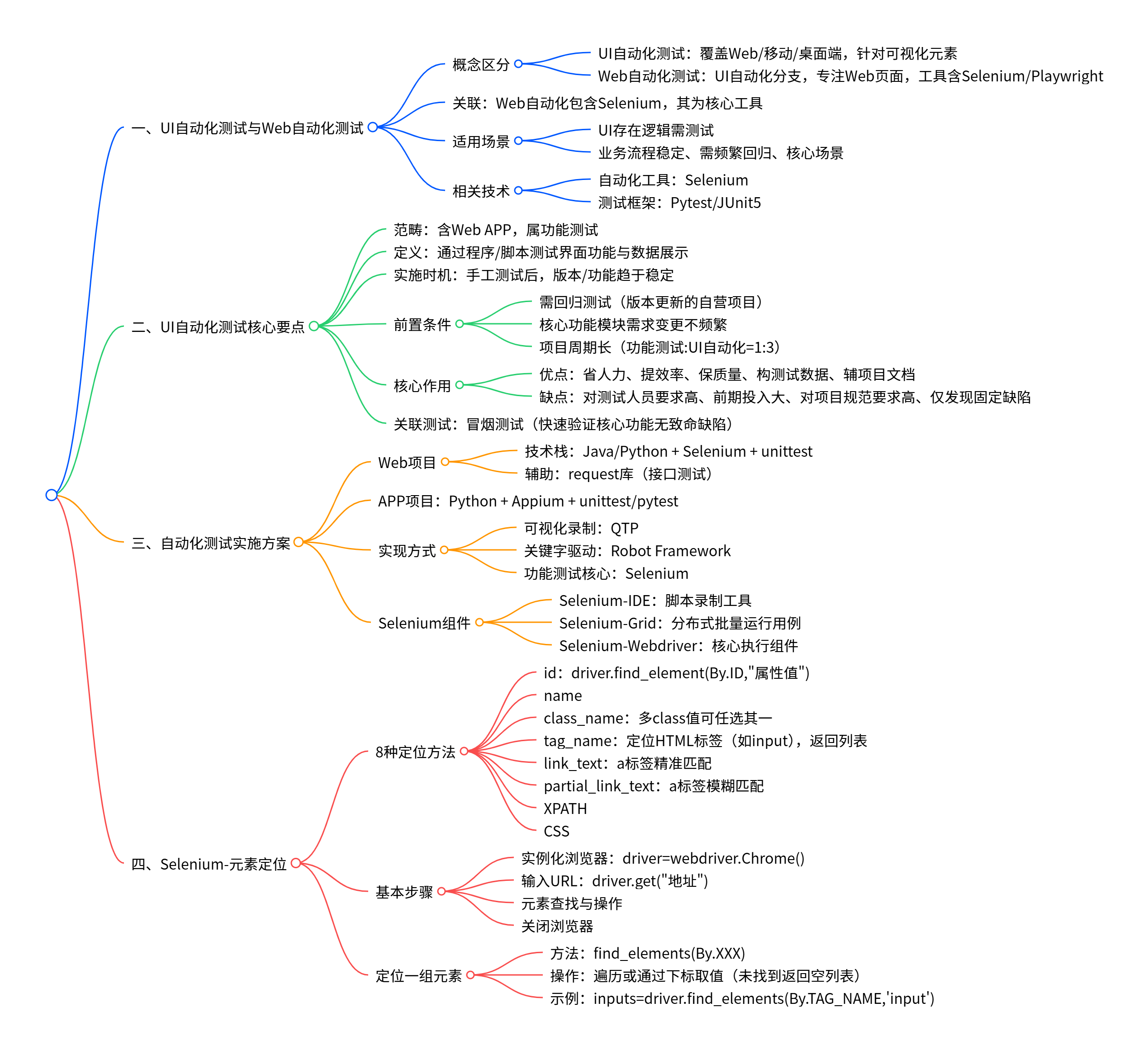
一、UI自动化测试与Web自动化测试
1.UI 自动化测试是一个大范畴,指对软件的用户界面(按钮、输入框、菜单等可视化元素)进行自动化操作与验证,覆盖Web 端、移动端(安卓 /iOS)、桌面端等所有带界面的应用。
Web 自动化测试是UI 自动化测试的一个分支,专门针对 Web 页面的界面元素做自动化测试,工具以 Selenium、Playwright 等为主
2.Web测试与Selenium
Web 自动化测试包含 Selenium,而且 Selenium 是 Web 自动化测试中最常用的工具之一
3.什么时候做UI自动化测试?(对前端的覆盖)
(1)UI 有逻辑,有逻辑就要进行测试
(2)当业务流程相对稳定、需要频繁回归、核心场景
(3)Web自动化测试相关技术:
自动化工具:Selenium
测试框架:Pytest/JUnit5
二、UI自动化测试 ---自动化测试属于功能测试
1.两部分:Web APP
2.项目中实施web和app自动化测试
3.UI自动化测试
(1)UI:user lnterface:用户界面是系统和用户之间进行交互和信息转换的媒介
(2)UI自动化测试:使用程序、脚本对系统界面体现的功能和数据信息展示等进行的测试技术
4.什么时候进行UI自动化? -提高测试效率
(1)大量的版本回归 --检测新代码是否对旧代码有影响
(2)手工回归效率低
(3)测试工程师价值得不到体现
5.实施UI自动化测试的前置条件
(1)项目需要回归测试 版本更新(公司需要自己运营的项目)
(2)项目需要实现自动化的功能模块需求变更不频繁
一般只实现核心功能模块;页面功能也展示信息变更
(3)项目周期要长
Time :功能测试:UI自动化测试=1:3
6.UI自动化测试执行时机
(1)一般情况下载手工测试完成之后,版本嚯项目功能趋于稳定
7.UI自动化测试核心作用和劣势
(1)优点:
节省人力成本:回归测试工作由脚本代替人去执行
提高回归测试效率:脚本执行测试速度更快
提高测试质量:一旦自动化脚本库完善后测试执行过程更标准和准确
构建测试数据
做为项目文档辅助
(2)缺点:
对测试人员要求高;前期投入成本大;对项目要求高(要求项目你叫规范)
自动化只能发现固定的缺陷
8.冒烟测试:冒烟测试(Smoke Test)是软件测试里的快速基础验证测试,核心目的是确认新版本的软件最核心的功能能正常运行,没有致命缺陷。
三、对Web项目做自动化
1.Java/Python + Selenium(查找元素、操作元素) + unittest
request库 --> 对接口 unittest -->框架
2.对APP实施自动化:
python + appium + unitest/pytest
3.如何做自动化?
(1)可视化代码工具录制 QTP
(2)Robot Framework 关键字驱动
(3)Selenium 主要做功能测试;自动化测试属于功能测试
4.Selenium
(1)Selenium-IDE 录制脚本工具
(2)Selenium-Grid 分布式 批量在不同平台运行用例
(3)Selenium-Webdriver
四、Selenium-元素定位
1.8中元素定位方法 元素定位:通过代码调用方法查找元素
(1)id
(2)name
(3)class_name driver.find_element(By.CLASS_NAME,"")
当class有多个值时,可以使用任意一个
(4)tag_name: HTML标签的名称,如<input> <button><div>
如 定位一组input
inputs=driver.find_elements(By.TAG_NAME,'input')
(5)link_text、 定位a标签 精准匹配
driver.find_element(By.LINK_TEXT,"新闻" ).click()
(6)partial_link_text 定位a标签 模糊匹配
driver.find_element(By.PARTIAL_LINK_TEXT,"新").click()
python
# link_text 定位a标签
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
"""
定位a标签链接 精准定位 By.LINK_TEXT / 模糊匹配 By.PARTIAL_LINK_TEXT
"""
# 1.打开浏览器 --实例化浏览器
driver=webdriver.Chrome()
# 2.输入url
driver.get("https://www.baidu.com")
# 3.1定位以及操作 精准定位a吧标签
# driver.find_element(By.LINK_TEXT,"新闻" ).click()
# 3.2 模糊定位a标签
driver.find_element(By.PARTIAL_LINK_TEXT,"新").click()
# 4.关闭浏览器
sleep(5)
driver.quit()(7)XPATH
(8)CSS
(1)通过id属性定位元素
(2)driver.find_element(By.ID,"id属性值")
python
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
# 1.打开浏览器 --实例化浏览器
driver=webdriver.Chrome()
# 2.输入url
driver.get("https://www.baidu.com")
# 3.找元素以及操作
# driver.find_element(By.ID,"kw").send_keys("python")
driver.find_element(By.CLASS_NAME,"s_ipt").send_keys("oo")
sleep(2)
# driver.find_element(By.ID,"chat-submit-button").click()
# 4.关闭浏览器
sleep(5)
driver.quit()3.步骤:
(1)# 1.打开浏览器 --实例化浏览器
driver=webdriver.Chrome()
2.输入url
driver.get("http://60.204.225.104")
3.找元素以及操作
4.关闭浏览器
python
from time import sleep
from selenium import webdriver
# 1.打开浏览器 --实例化浏览器
driver=webdriver.Chrome()
# 2.输入url
driver.get("http://60.204.225.104")
# 3.找元素以及操作
# 4.关闭浏览器
driver.quit()4.如果需要获取所有的相同标签,使用查找一组元素的方法 --遍历/添加下标
(1)find_elements(By.CLASS_NAME)
(2)# 定位一组元素 查找所有的input标签 --通过下标的方式
inputs=driver.find_elements(By.TAG_NAME,'input')
inputs0.send_keys("admin")
inputs1.send_keys("admin")
python
# 定位一组元素
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
# 1.打开浏览器 --实例化浏览器
driver=webdriver.Chrome()
# 2.输入url
driver.get("http://60.204.225.104")
# 3.找元素以及操作
# 定位一组元素 查找所有的input标签
inputs=driver.find_elements(By.TAG_NAME,'input')
inputs[0].send_keys("admin")
inputs[1].send_keys("admin")
# for x in inputs:
# print(inputs)
# 4.关闭浏览器
sleep(5)
driver.quit()(3)返回列表形式,如果没有找到符合要求的标签,会返回空列表
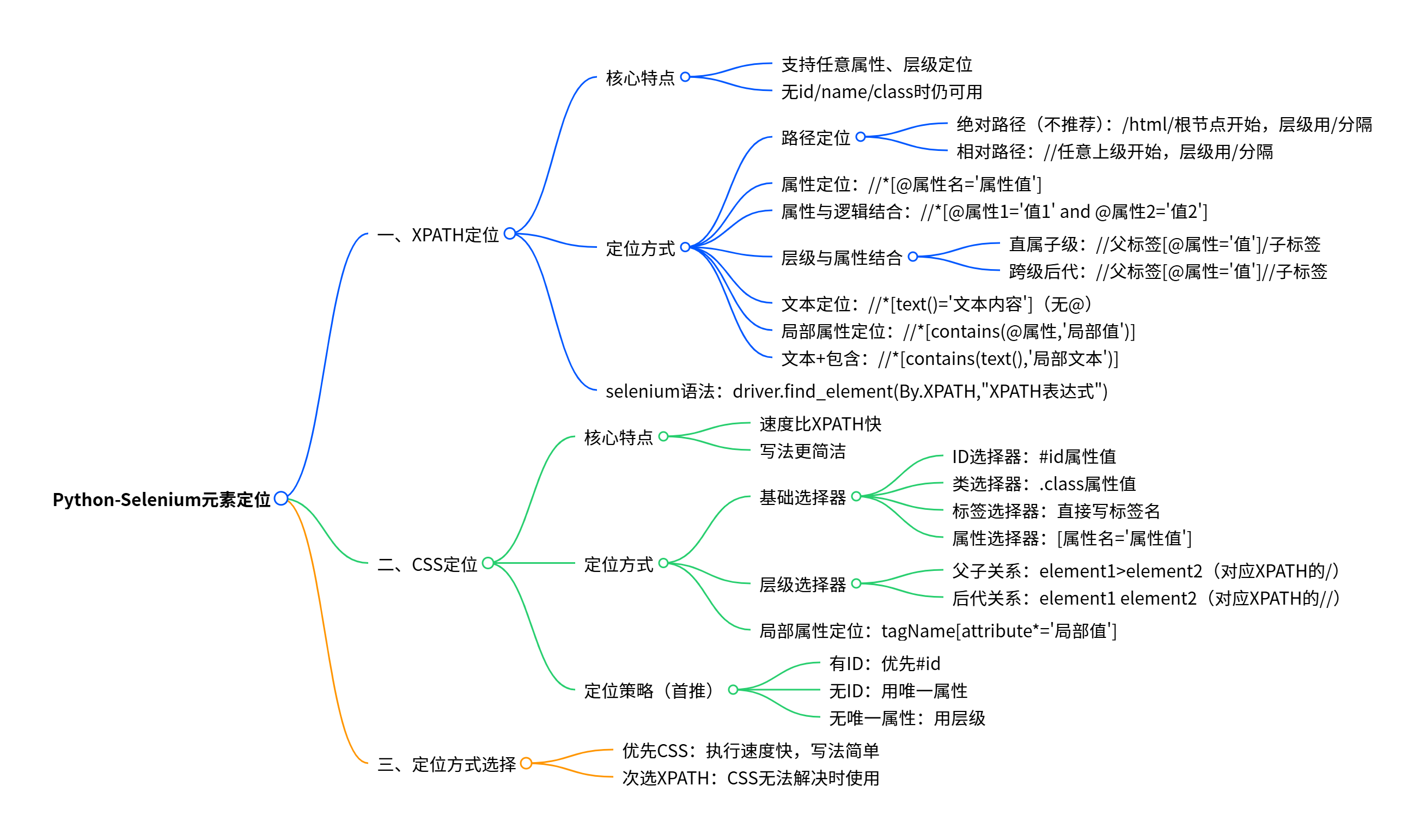
五、Python-Selenium元素定位 -XPATH
1.元素定位:
(1)定位元素时,可以使用元素自身的信息,如id name class tag_name 文本 ---所有属性都可以用来定位
(2)元素的层级关系
2.XPATH
(1)XPATH: XML Path
(2)如果标签没有(id name class)这三个属性,也不是a标签,无法定位,只能使用tag_name定位,比较麻烦(因为得到的是一组,需要下标/遍历)
(3)XPATH和CSS查找元素方便 --支持任意属性、层级定位查找元素
3.Selenium根据XPath定位:
(1)driver.find_element(By.XPATH,"XPATH表达式"
(2)路径定位
(3)属性定位
//*@属性名='属性值'
(4)属性和逻辑结合 (多个属性)
//*@属性名='属性值' and @属性名='属性值'
(5)层级与属性结合
//父标签/子标签 必须为直属子级
//父标签@属性名='属性值'//子标签 父与后代之间可以跨越元素
4.Xpath定位-路径定位
(1)绝对路径不推荐:
从最外层元素到指定元素之间所有经过的元素层级的路径。
表达式写法:绝对路径以/html根节点开始,使用/来分隔元素层级。
/html/body/div/fieldset/p1/input
p1:表示第一个,而不是下标
python
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
# 1.打开浏览器 --实例化浏览器
driver=webdriver.Chrome()
# 2.输入url
driver.get("http://60.204.225.104")
# 3.XPATH --绝对路径[不推荐] 定位元素
driver.find_element(By.XPATH,"/html/body/div/div/form/div[1]/div/div/input").send_keys("admin")
driver.find_element(By.XPATH,"/html/body/div/div/form/div[2]/div/div/input").send_keys("admin")
driver.find_element(By.XPATH,"/html/body/div/div/form/div[3]/div/div/input").send_keys("2")
# 4.关闭浏览器
sleep(5)
driver.quit()(2)相对路径:
从目标定位元素的任意层级的上级元素开始到目标元素所经过的层级的路径
表达式写法:以//开始,后续每个层级都使用/来分隔。
/html/body/div/fieldset/p1/input
5.Xpath定位-属性定位
(1)利用元素的任意属性来进行定位
//input@type='submit' @属性名="属性值"
//*@value='提交'
python
# 1.打开浏览器 --实例化浏览器
driver=webdriver.Chrome()
# 2.输入url
driver.get("http://60.204.225.104")
# 3.XPATH --属性
driver.find_element(By.XPATH,"//input[@placeholder='账号']").send_keys("admin")
driver.find_element(By.XPATH,"//input[@placeholder='密码']").send_keys("admin")
driver.find_element(By.XPATH,"//input[@placeholder='验证码']").send_keys("2")
# 4.关闭浏览器
sleep(5)
driver.quit()6.Xpath定位--属性与逻辑结合
(1)利用元素的多个属性定位(当单个属性无法定位时)
//input@value='提交'and @dass='banana'
7.Xpath定位--属性与层级结合
python
# 1.打开浏览器 --实例化浏览器
driver=webdriver.Chrome()
# 2.输入url
driver.get("https://www.baidu.com/")
# 3.XPATH --属性、层级、逻辑
# 3.1定位百度 新闻链接 并跳转
# driver.find_element(By.XPATH,"//div[@id='s-top-left']/a[@target='_blank'][1]").click()
# 3.2 包含contains 和文本text()
driver.find_element(By.XPATH,"//a[contains( text(),'新闻')]").click()
# 4.关闭浏览器
sleep(5)
driver.quit()(1)先定位到其父级元素,然后再找到该元素
//div@id='test1'/input@value='提交'
(2)当利用多个属性信息(属性与逻辑结合)时找不到元素时使用
(3)利用元素的文本定位元素
//*text()="仓库管理系统" --text非属性(没有@)
(4)利用局部属性值定位元素
//inputcontains(@placeholder,'密码')
(5)包含和文本综合使用
//acontains( text(),"新闻")
python
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
# 1.打开浏览器 --实例化浏览器
driver=webdriver.Chrome()
# 2.输入url
driver.get("http://60.204.225.104")
# 3.XPATH --向表单中输入账号 密码 和验证码 并点击登录,进入商城内部页面
# XPath 属性定位 输入用户名 ;属性与逻辑定位密码;层级与属性定位验证码 包含定位登录按钮并点击
driver.find_element(By.XPATH,"//div[1]/div[1]/div/input").send_keys("admin")
sleep(2)
# driver.find_element(By.XPATH,"//input[@type='password']").send_keys("123456")
driver.find_element(By.XPATH,"//*[@type='password' and @placeholder='密码']").send_keys("123456")
sleep(2)
# driver.find_element(By.XPATH,"//div[@class='el-form-item__content']//input[@placeholder='验证码']").send_keys("2")
driver.find_element(By.XPATH,"//*[@placeholder='验证码']").send_keys("2")
sleep(2)
# .//表示从当前节点 也可以//button[.//span[contains(text(),'登')]]
# driver.find_element(By.XPATH,"//button//span[contains(text(),'登')]").click()
driver.find_element(By.XPATH,"//*[contains(text(),'登')]").click()
# 4.关闭浏览器
sleep(5)
driver.quit()六、Python-Selenium元素定位 -CSS
1.相比XPATH 速度更快,写法更简单
2.CSS
(1)一种语言,用来秒速HTML元素的显示样式
(2)选择器:一种表达式,可以找到HTML中的标签元素
3.CSS定位:selenium利用选择器定位元素的定位方式
4.策略:
(1)ID选择器 --利用元素ID属性来选择 #id属性值
(2)类选择器--利用元素class属性来选择 .class属性值
(3)标签选择器 --标签名 标签名
(4)属性选择器 --利用元素任何属性来选择 属性名='属性值'
(5)层级选择器
python
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
# 1.打开浏览器 --实例化浏览器
driver=webdriver.Chrome()
# 2.输入url
driver.get("http://60.204.225.104")
# 3. CSS --向表单中输入账号 密码 和验证码 并点击登录,进入商城内部页面
driver.find_element(By.CSS_SELECTOR, ".el-form-item__content input[placeholder='账号']").send_keys("admin")
sleep(2)
driver.find_element(By.CSS_SELECTOR, ".el-form-item__content input[placeholder='密码']").send_keys("123456")
sleep(2)
driver.find_element(By.CSS_SELECTOR, ".el-form-item__content input[placeholder='验证码']").send_keys("2")
sleep(2)
driver.find_element(By.XPATH,"//*[contains(text(),'登')]").click()
# 4.关闭浏览器
sleep(5)
driver.quit()5.CSS定位--层级选择器
(1)父子关系:根据元素的父子关系来选择元素
element1>element2 xpath:/ element:可以是CSS的任意选择器(id class ...)
pid='p1'>input
(2)后代关系:根据元素的上级元素来选择元素
element1 element2
pid='p1' input xpath://
(3)利用局部属性值定位元素
tagNameattribute\*='局部属性值'
placehplder\*='号'
6.总结:
(1)首推css定位,原因执行速度快。
a如果有ID属性,使用#id
b没有id属性,使用其他有的属性(能代表唯一的属性)
c如果属性都带不了唯一,使用层级
(2)如果css解决不了,使用xpath。
七、总结