给上次的代码加个前端页面,然后也顺便打包成exe,这样方便一点
思路
1.前端随便找个网页模板,能传过来需要的值就行
2.后端ai推荐使用flask框架
3.把一些限制加上(主要是分隔符)
修改后端app.py
1.导入模块flask
反正需要啥就导入啥
python
# 1. 导入基础模块(和标签处理相关)
import os
import random
import re
import sys
import webbrowser
import threading
import time
# 2. 导入Flask核心组件
from flask import Flask, render_template, request, redirect, url_for, flash2.获取打包路径
打包成exe之后的,会把所有的资源以及python那些全部加进去,这时候的访问文件路径不一样的
正常来说flask框架的资源会再static(静态资源),templates(网页)文件夹里面找,但是打包之后这些被整合在一起,所以会临时解压再系统的临时目录(这样不管哪个电脑都可以使用),所以我们需要获取路径
python
# 获取打包后/未打包时的根路径
def get_base_path():
if hasattr(sys, '_MEIPASS'):
# 打包后,sys._MEIPASS 是临时资源目录
return sys._MEIPASS
# 未打包时,返回当前项目根目录
return os.path.abspath(".")sys: 是python系统模块,存放一些系统参数
_MEIPASS : PyInstaller 打包后自动生成的隐藏特殊属性,存放在sys里面,只有exe运行时才会存在,这个值就是临时解压的目录
hasattr() :判断某个对象有没有相应的属性或者方法,这里就是判断sys 里面有没有**_MEIPASS**
os.path.abspath(".") :把路径转化成绝对路径,这里的**"."**表示当前工作目录,就是没打包就直接返回工作目录,打包了就会返回临时目录
3.实例化flask
python
# 3. 初始化Flask应用(后端服务的入口)
app = Flask(__name__,
static_folder=os.path.join(get_base_path(), "static"), # 静态资源目录
template_folder=os.path.join(get_base_path(), "templates")) # 模板目录个人理解为,创建一个对象,相当于初始化一个flask框架给你用
**name :**基础实例化,一定要加的参数
static_folder、template_folder :这两个时flask框架的默认存储路径参数,不写的话就时默认static和templates,但是打包的原因,我们给他加上路径
os.path.join():拼接路径,把找到的路径拼接上static和templates,然后赋值给上面两个参数
4.修改项目的文件夹
框架其实就是规定好好了一些东西,让你去遵循,于是你就可以少些很多代码
所以flask框架的规定文件夹时这样的
一个后端(app.py),外加两个文件夹static和templates(是不是看着很熟,上面的代码就是搞这两个),其中static放的资源文件,图片,js,css那些,templates放的是网页文件
一开始我也很纳闷,一直404,因为我下载的网页我直接放根目录了...
5.设置密钥
python
# 4. 设置秘钥(用于flash消息、session等功能,随便写一个字符串即可)
app.secret_key = "tag_shuffler_key"
# 新增这行,启动时看终端输出
print("当前secret_key:", app.secret_key)这个随便设置一个就行,为了到时候用session传flash消息给前端,如果使用session的话flask框架要求得加密
6.设置分隔符的正则限制
这个是后面想到的,一般token的分隔符是逗号,因为我不小心把分割符输入了点,它竟然还是返回成功的消息......
思考一下就会发现,其实是整个文件内容都没分割,读出来又放进去了,说成功也没错!但是其实就是没有打乱,所以之前的代码是有问题的
但是我又想到一个很恐怖的事情,如果我不小心输入了一个a,那么文件标签就会瞎打乱,最后导致文件直接没法用了,那就完蛋了...所以我赶紧设置了校验,感觉正则会写少很多东西
python
# 核心正则校验:仅允许常见符号
tag_separator = tag_separator.strip() # 去除首尾空格
symbol_pattern = re.compile(r'^[!@#$%^&*()_+\-=\[\]{};:\'\"\\|,.<>\/?`~]+$')
if not symbol_pattern.match(tag_separator):
return False, "分隔符仅允许输入符号(如, | ; : . 等)!禁止输入字母、数字、空值"re.compile():这个不用说了,就是把里面的字符串变成预编译正则对象,这样不用每次都去转化很方面,也提高了资源利用
**.match("字符串"):**字符串正则匹配,看是否符合设置的校验
重点是正则的设置 ,这个我为了弄明白查了好久
r'^!@#$%\^\&\*()_+\\-=\\\[\\{};:\'\"\\|,.<>\/?`~]+$'
拆分理解,首先r 代表把里面这个当成字符串,用单引号**''**把正则包裹
^ 代表位置,从头开始匹配,然后是【】里面的内容,+ 代表着至少一个,**$**代表结尾
意思就是从头到尾都要匹配,并且中间的内容至少匹配一个【】里面的内容,因为是至少一个(≥1),所以中间的字符串长度没有限制
【】里面就是匹配的符号,一大堆,就限制了输入的内容只能是符号,但是里面又很多\的转义需要注意一下
我们要的是字符,但是某些符号会又特殊意义,必须价格转义让计算机理解把它当成字符
|------|-------------------|
| - | 代表范围,例如a-z代表字幕a到z |
| \[\] | 用来代表正则的限制内容 |
| '' | 用来包裹正则表达式 |
| "" | 这个倒无所谓,加上去保险一点 |
| \ | 代表转义的意思 |
上面这些都有特殊意义,所以我们要在前面加一个\来转义成,代表本身字符串
7.参数空值判断
python
# 5.1 校验参数合法性
if not os.path.exists(root_folder):
return False, "文件夹路径不存在!"
if keep_first_n < 0:
return False, "前N个标签不能为负数!"
if not tag_separator.strip():
return False, "标签分隔符不能为空!"8.不符合规格的文件token判断
有思考到这个,如果文件中有些是逗号分隔,有些句号分隔怎么办?
直接凉拌,懒得去弄一个什么多少个文件打乱成功,多少个文件没有打乱,分别是谁谁谁....太麻烦了,而且也不可能出现token的分隔符不同的问题
所以设置了,只要出现一个文件的分隔符不同,我就直接返回错误提示信息,当然那些执行过打乱的文件就执行了,毕竟为了打乱平均,可以打乱多次
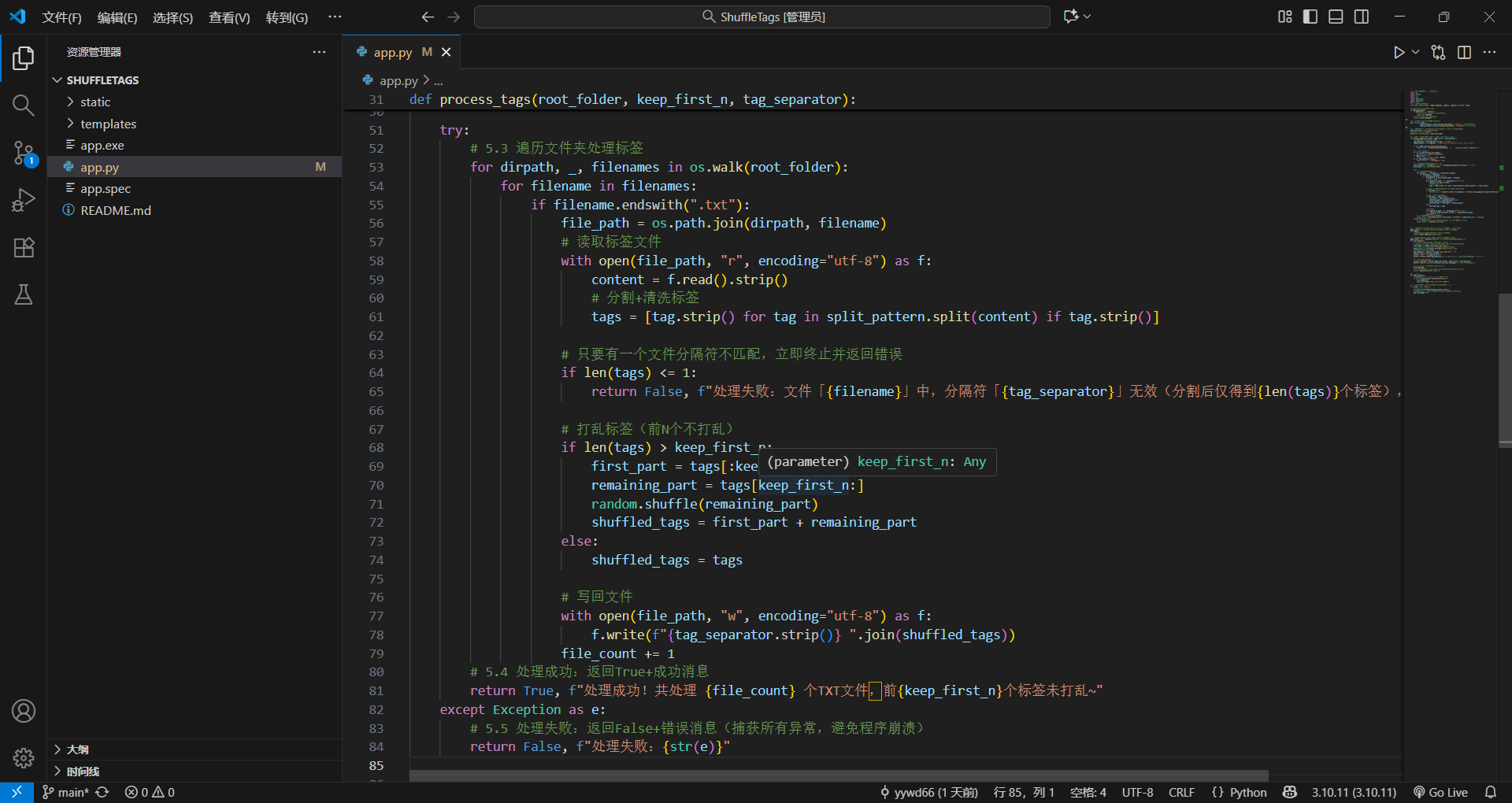
python
# 只要有一个文件分隔符不匹配,立即终止并返回错误
if len(tags) <= 1:
return False, f"处理失败:文件「{filename}」中,分隔符「{tag_separator}」无效(分割后仅得到{len(tags)}个标签),已终止所有处理!"直接在打乱的函数里面,提取了tags(文件分割的token数组)之后,做判断就行
9.加上try catch(为了返回错误信息)
10.装饰器工厂绑定路由映射表
装饰器函数查了我两天才弄懂,就是套娃,给原函数添加额外功能,然后保持一致性(例如函数名,参数,返回值等)
说白了就是给一个函数加装功能,然后返回一个函数,有赋予给了原函数一样的函数名
装饰器工厂就是给装饰器再套娃一层,给装饰器加装功能,这时候就可以传入一些自己要的参数去做设置了(带参数),例如判断哪些东西自己需要,然后定制你自己需求的功能(这时候就可以破坏一些一致性了)
python
# 6. 前端页面路由(用户访问http://127.0.0.1:5000时执行这个函数)
@app.route('/') # 装饰器:给index函数绑定"访问根路径"的功能
def index():
# 渲染templates文件夹下的index.html(前端页面)
return render_template("index.html")index():我们自定以的函数
**render_template("index.html") :**这个就是flask的渲染函数,找到并且渲染html,返回给服务器
重点在这里**@app.route('/')**
**@ :**python的语法糖,让代码更加简洁,逻辑性清晰
@app.route('/') :这个就是flask的装饰器工厂了,这里的作用就是把index绑定给路由映射表,传入的参数就是路径/,绑定的函数时index
这个语法糖的写法,相当于 index = app.route('/')(index)
因为不需要加函数功能,只是做绑定,所以装饰器函数内部是返回原函数,所以index函数还是原函数,没有被改变加装了啥功能
**路由映射表 :**这个是flask框架里的东东,相当于map,键值对数组,里面的键就是路径,值就是函数,意思就是转到哪个路径,就执行什么函数
这里就是跳转到根目录/,就执行index
python
# 7. 处理表单提交的路由(前端点击"提交"后,请求这个路径)
@app.route('/run', methods=['POST']) # 只允许POST请求(表单提交常用)
def run_process():
# 7.1 接收前端表单提交的参数(name属性对应)
# request.form.get("参数名"):从POST表单中取参数,没有则返回None
root_folder = request.form.get("root_folder")
# 取参数并转换为整数,默认值1(避免用户没填导致报错)
keep_first_n = int(request.form.get("keep_first_n", 1))
# 取分隔符参数,默认值逗号
tag_separator = request.form.get("tag_separator", ",")
print(f"文件夹路径:{root_folder}")
print(f"前N个标签:{keep_first_n}")
print(f"分隔符:{repr(tag_separator)}") # repr能显示空格/特殊字符,比如逗号是',',空格是' '
# 7.2 调用核心函数处理标签
success, message = process_tags(root_folder, keep_first_n, tag_separator)
print(f"处理结果:success={success},message={message}") # 新增:打印处理结果
# 7.3 用flash传递消息(给前端显示结果)
flash(message)
# 7.4 跳回首页(url_for("index"):找到index函数对应的路由,即/)
return redirect(url_for('index')) 一样的绑定,只不过这次是绑定**/run**路径,并且一定得是post提交才行
这时候就会触发绑定函数run_process()
这个就是接受网页提交的表单数据,然后打乱标签(上面我们定义的函数)
需要注意的是这个
success, message = process_tags(root_folder, keep_first_n, tag_separator)
这个是一个元组,我们看这个process_tags返回的其实就是两个值,直接使用元组赋值就行(我是理解成同时赋予两个值)
**flash(message) :**这个也是flask的函数,把字符串传回前端的session
return redirect(url_for('index')) :redirect 重定向,url_for是找到index视图函数的路径(前面已经绑定了/),所以重定向跳转到/,然后跳转/又会执行index函数,index函数又会渲染网页....感觉又在套娃
11.避免启动多页面
这个问题是因为,我设置了flask的debug=True(开发模式)的时候,会自动启动两个首页页面,原理如下

说白了就是开发者模型双进程,主进程来监控代码,重载进程用来运行服务,我设置了自动启用页面,所以他会开启两个页面
python
#打开浏览器
def open_browser():
# 关键判断:只让主进程打开浏览器,重载进程跳过
if not os.environ.get('WERKZEUG_RUN_MAIN'):
time.sleep(0.5)
webbrowser.open("http://127.0.0.1:5000/")这里就直接判断,根据上面的资料os.environ.get('WERKZEUG_RUN_MAIN')返回值可以确定是哪个进程,一个true,一个false
直接判断,只有在主进程才执行webbrowser.open("http://127.0.0.1:5000/")打开网页
time.sleep(0.5) :延时0.5秒,给服务器启动点时间,再打开网页,防止服务器还没启动就打开网页,这样网页时会404
12.启动flask服务器
python
# 8. 启动Flask服务器(只有直接运行这个文件时才执行)
if __name__ == "__main__":
# 启动线程打开浏览器
threading.Thread(target=open_browser).start()
# debug=True:开发模式,改代码后自动重启,报错时显示详细信息
app.run(debug=True) **if name == "main":**判断是不是直接启动该文件,避免在导入该文件时启动
**name :**python的内置变量,存储了文件的启动方式
如果是运行文件,name 的值是**main ,**如果是导入模块,那他的值是模块的名字
threading.Thread(target=open_browser).start():使用异步线程启动网页,不阻塞 Flask 服务器的启动流程
说白了就是不跟你抢资源,你启动你的服务器(一个线程),我创建一个子线程来启动我的网页
app.run(debug=True) :这个就是最重要的启动服务器,只不过设置了degub模式,这样在修改代码不用重启服务器,会方便很多
当然,如果打包成exe的话,记得把debug设置成false,不然会有问题
太长了,有空下一篇继续,讲前端的代码