在当前的大模型应用生态中,如何精准地将非结构化文档(图片、PDF、复杂表格)转化为大模型可理解的结构化数据,是提升 Agent 智能程度的关键瓶颈。合合信息推出的 TextIn 通用文档解析专业版(ParseX)配合字节跳动火山引擎的 Coze 平台,提供了一套高效的解决方案。本指南将从底层逻辑到具体配置,还原整个智能体的构建过程。
第一章:智能体底座的初始化与架构搭建
构建智能体的第一步是在火山引擎 Coze 平台建立独立的运行空间。开发者需要在工作空间中选择项目开发选项,点击创建按钮进入智能体生成流程。
在弹出的界面中输入项目名称。项目名称应具备高度的辨识度,以方便在多项目并行开发中进行管理。完成创建后,系统将分配唯一的智能体 ID,作为后续 API 调用与逻辑编排的身份标识。
进入智能体编辑界面后,可以看到核心的配置区域。左侧为提示词(Prompt)与角色设定区,中间为工具与插件配置区,右侧为预览调试区。为了实现复杂的文档处理逻辑,单纯依靠提示词无法满足需求,必须引入工作流(Workflow)机制。
第二章:文档处理工作流的逻辑编排
工作流是智能体的"神经中枢",负责定义数据从输入到解析、再到模型处理的线性或非线性路径。
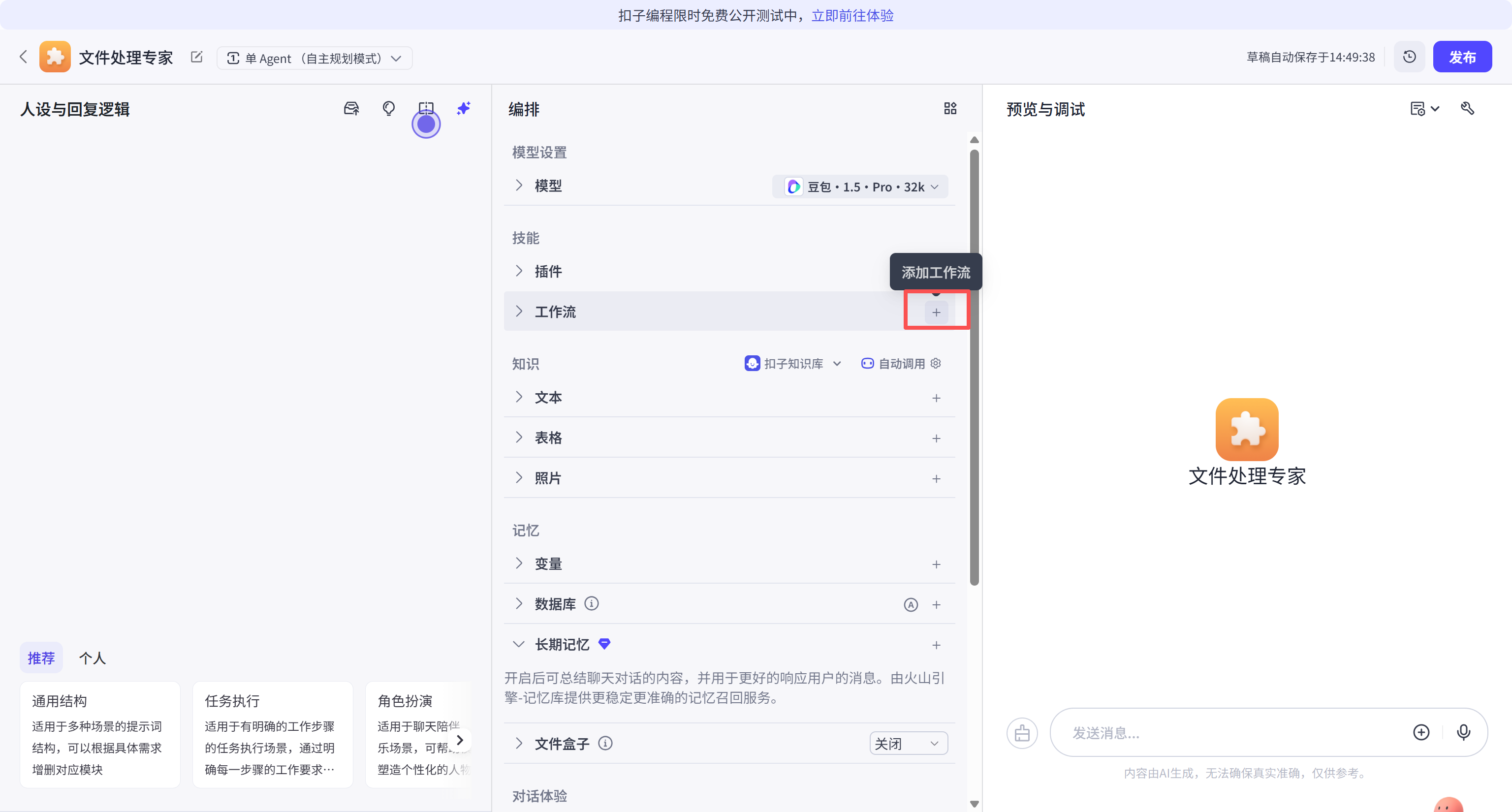
在编辑界面的右侧功能栏,点击"添加工作流"按钮。这一步骤旨在将复杂的业务逻辑从主对话流中抽离出来,实现模块化管理。
点击"创建工作流"后,系统会跳转至独立的逻辑编排画布。每一个工作流都需要一个清晰的命名和描述,以便大模型在对话过程中准确判断何时该触发该逻辑。
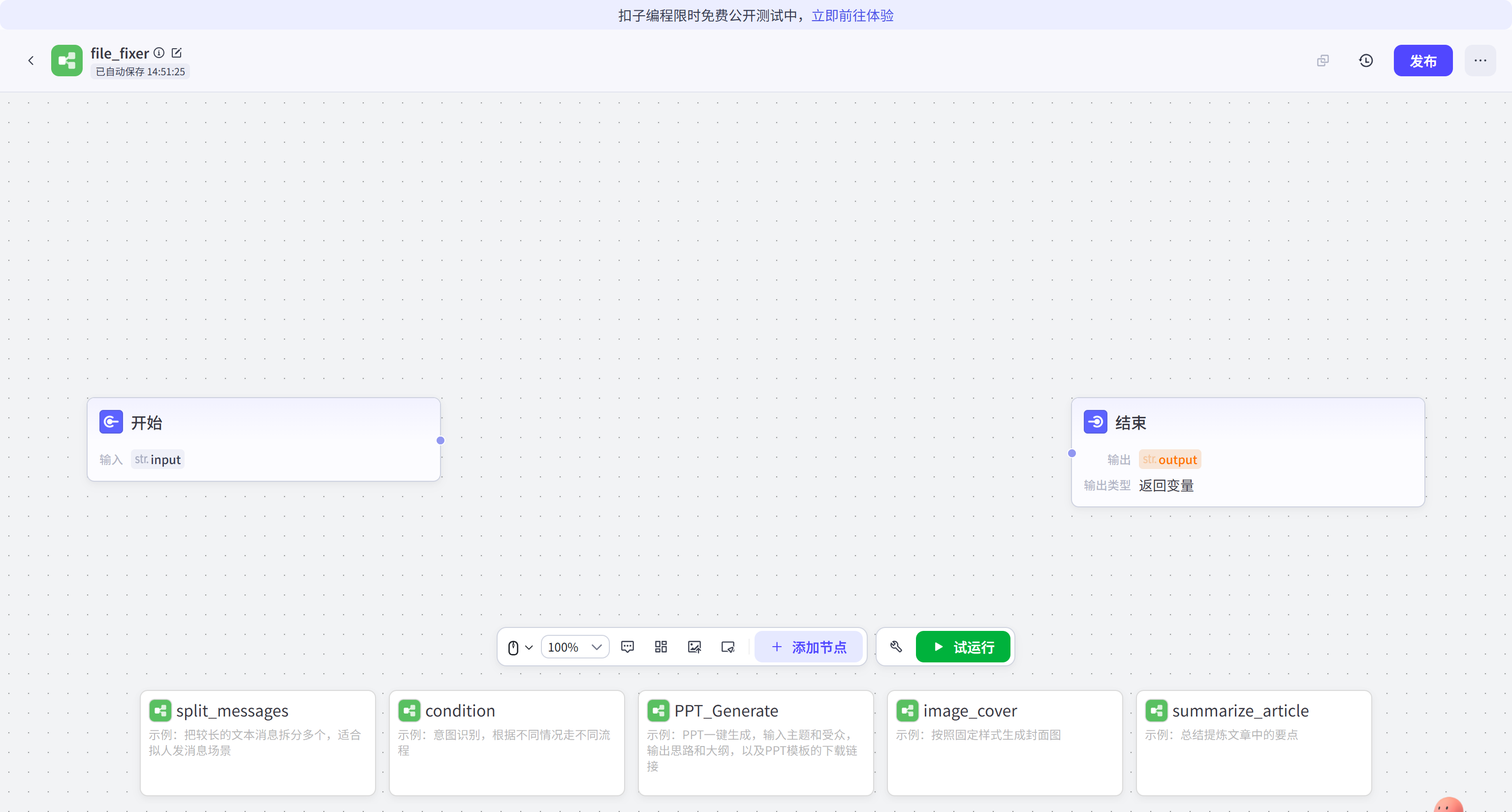
完成命名后,画布初始化。画布中默认包含"开始"节点和"结束"节点。
白板界面提供了一个可视化的编程环境。开发者可以通过拖拽节点的方式,自由组合 OCR 插件、大模型、代码块及数据库查询。
第三章:TextIn ParseX 核心插件的深度集成
智能体识别文档能力的核心在于 TextIn 提供的 ParseX 插件。该插件具备极强的布局分析能力,能够处理多栏排版、嵌套表格及复杂公式。
点击"开始"节点右侧的加号,进入插件搜索界面。插件作为外部能力的延伸,是智能体感知外部物理世界文档的唯一通道。
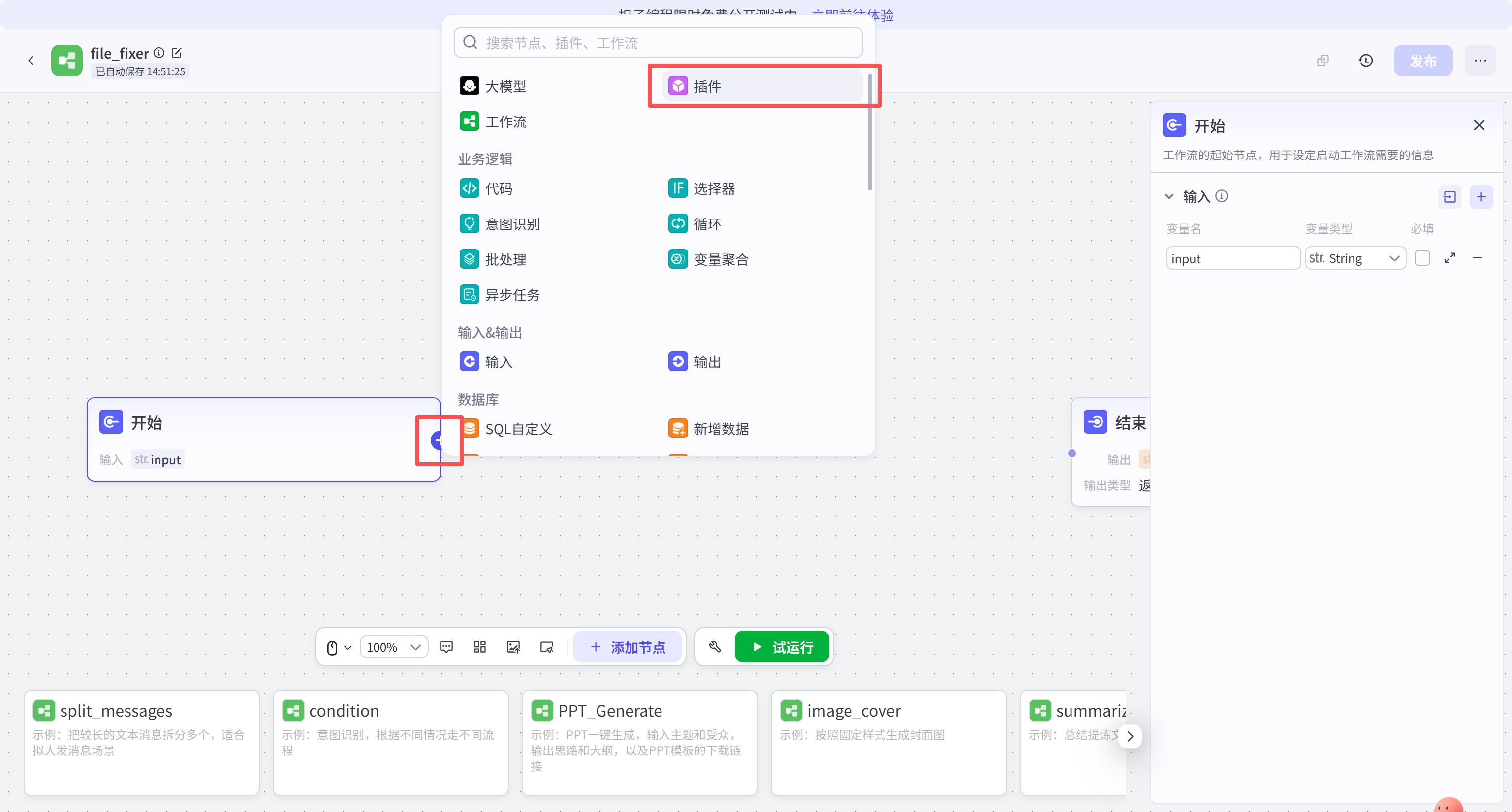
在搜索框输入"通用文档解析专业版",定位到由 TextIn 提供的 ParseX 工具。点击添加,将该能力引入当前工作流画布。
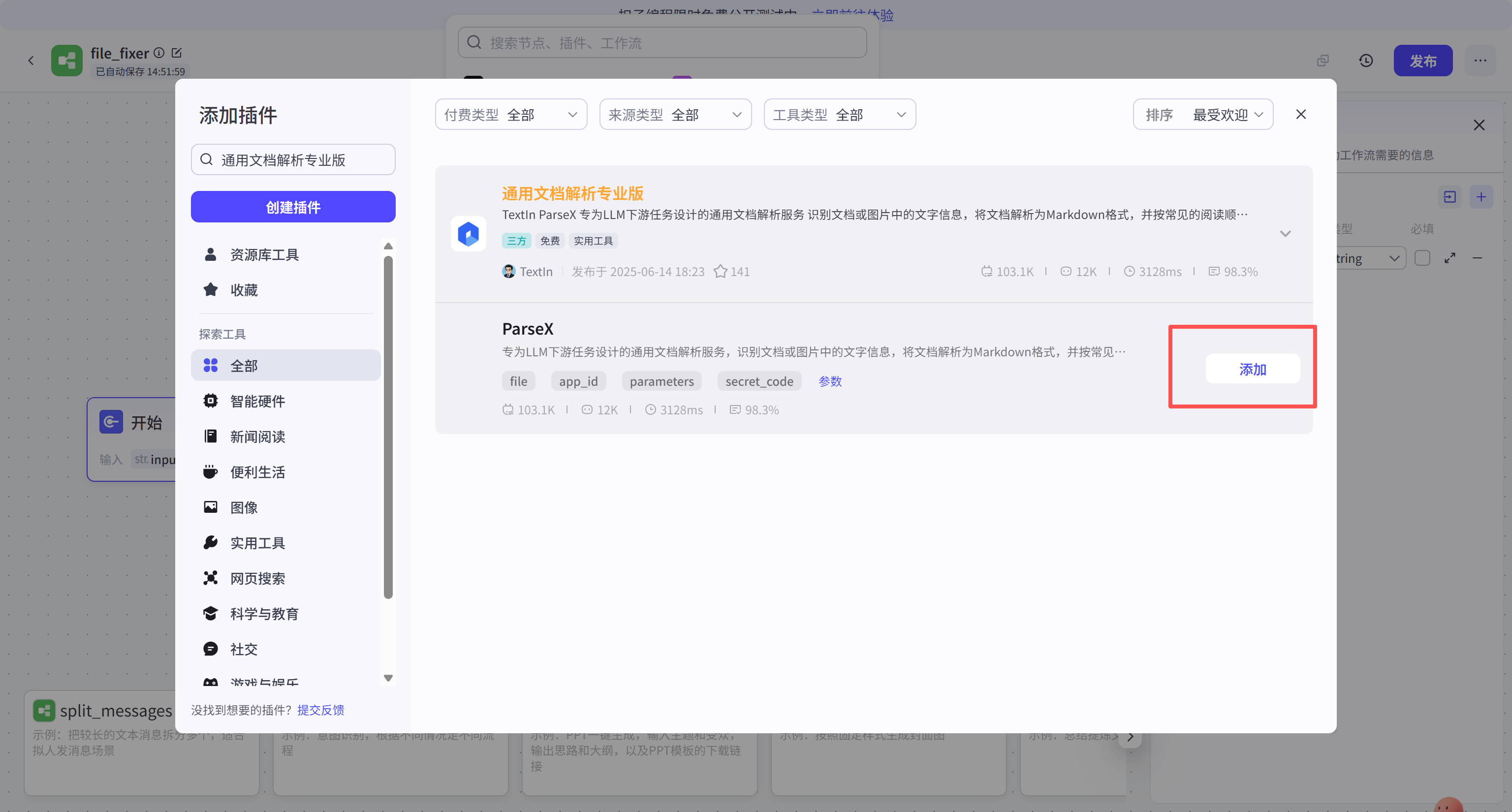
添加成功后,ParseX 节点将出现在画布中间。该节点需要配置输入参数,才能将上一环节接收的文件流传递给 TextIn 的云端解析引擎。
第四章:接口参数配置与开发者身份验证
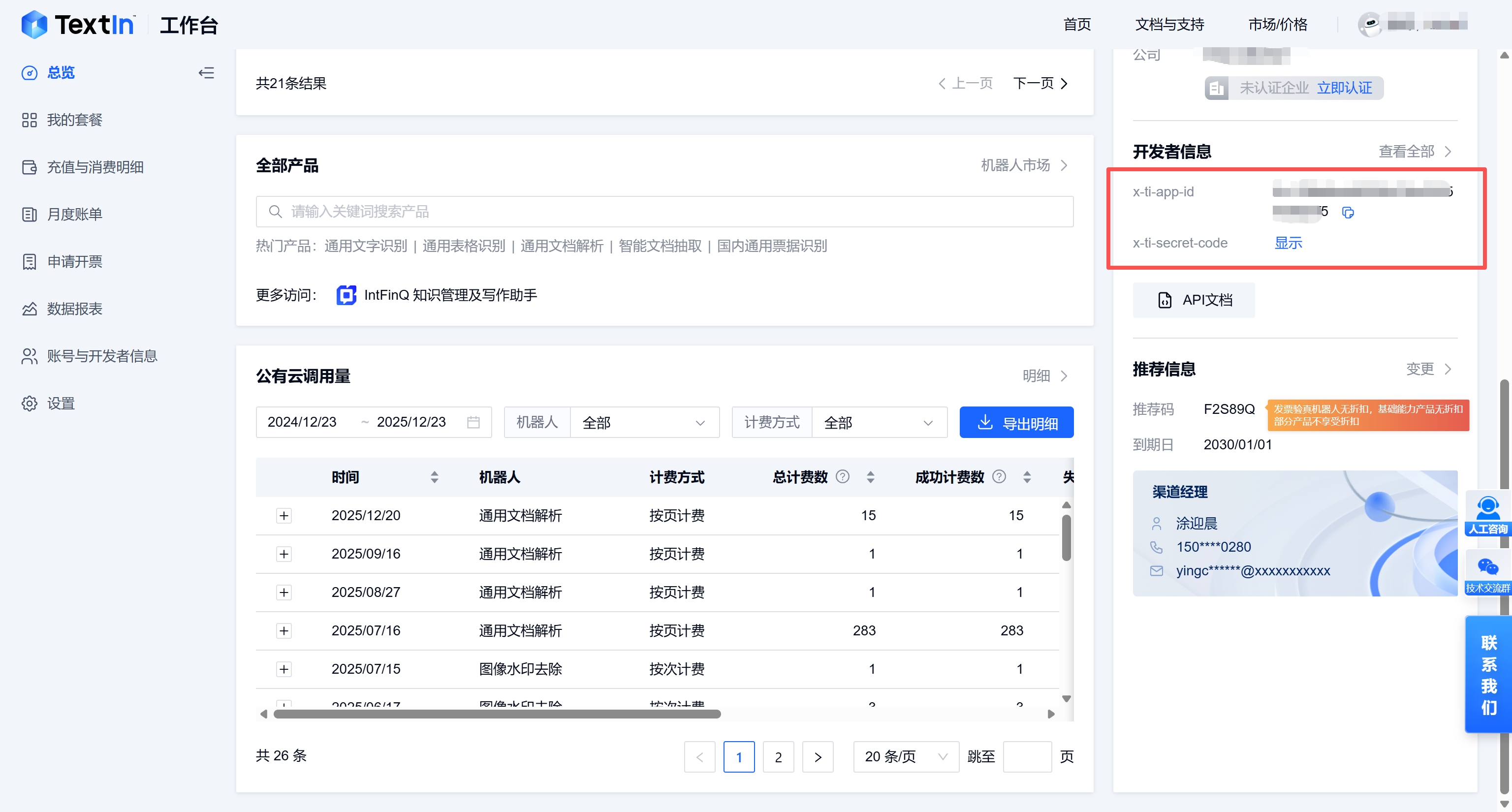
解析节点需要建立在合法的身份认证基础上。开发者必须获取 TextIn 平台的 API 密钥。
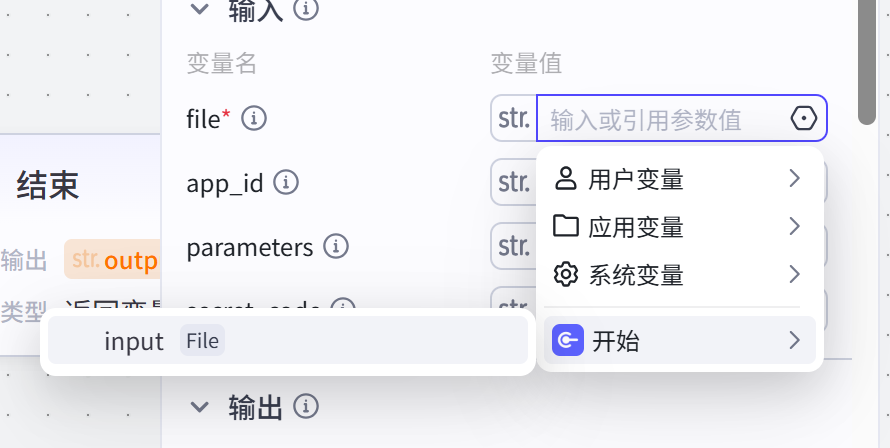
在配置 ParseX 节点前,先对"开始"节点进行初始化。设置输入变量名为 input,类型选择 File(文件流)。这是整个工作流的能量来源。
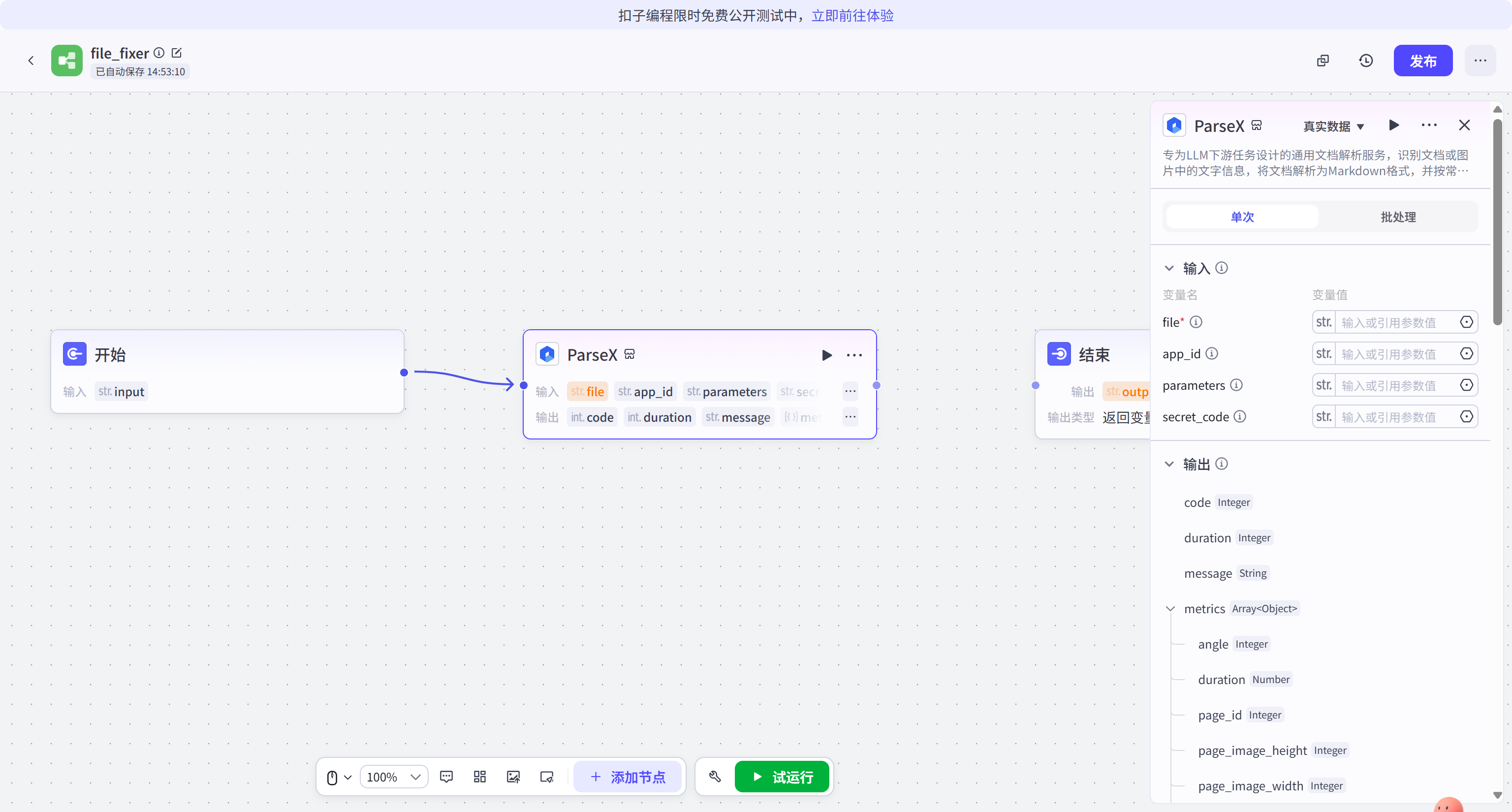
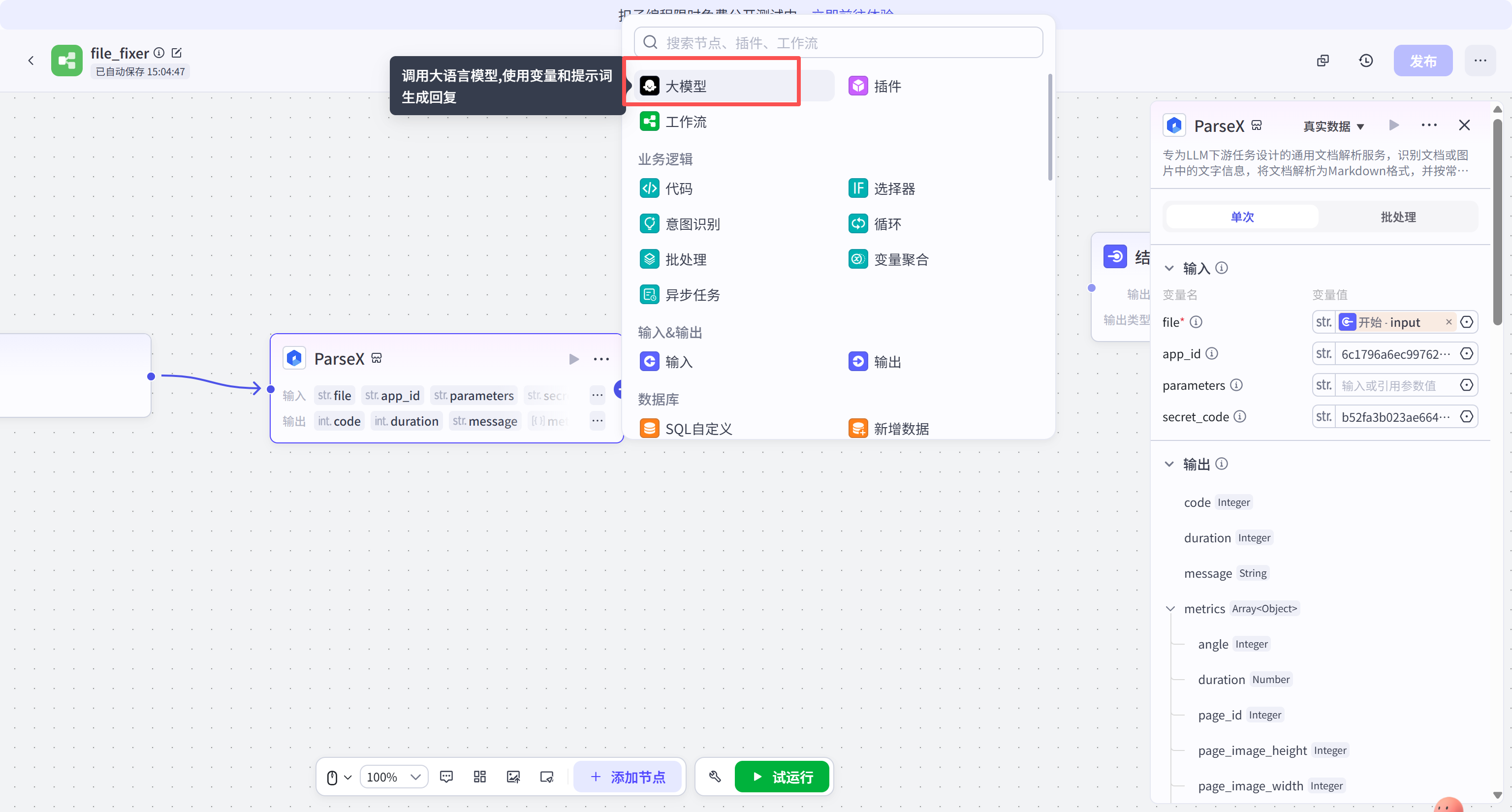
进入 ParseX 节点的详细设置界面。此时需要填充关键的四个参数:file、app_id、secret_code 以及 parameters。
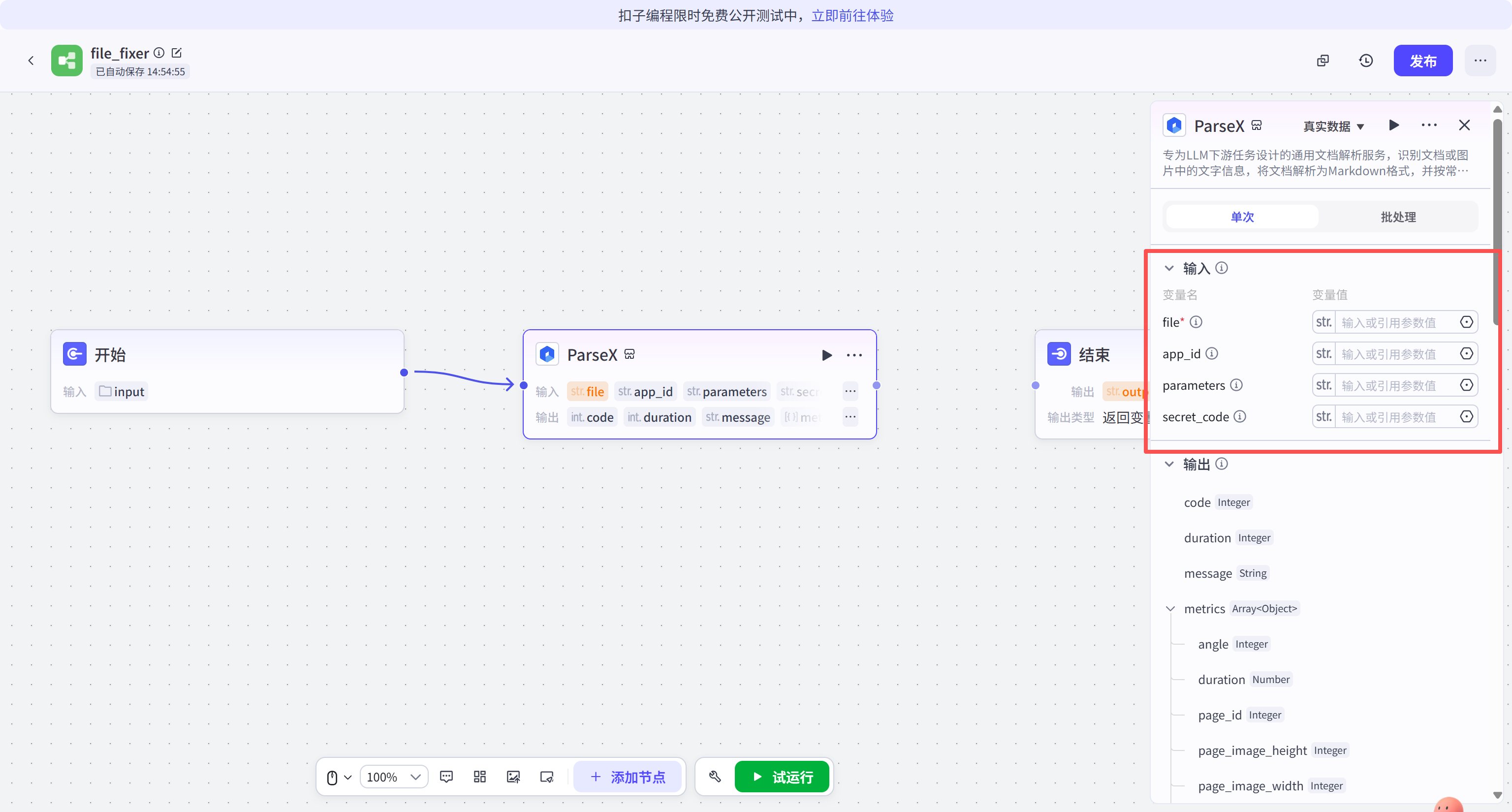
file 参数通过引用方式关联到"开始"节点的 input 变量。
app_id 与 secret_code 需要登录 TextIn 官网控制台获取。这两串字符代表了开发者的调用权限与计费额度,必须妥善保管,防止泄露。
parameters 栏目用于控制解析的精细度。例如,通过填入 JSON 格式的参数 {"get_image":"both", "image_output_type":"default"},可以指示引擎在解析文本的同时,提取文档中的图片及表格截图,并以 Base64 或 URL 形式返回。这对于需要处理带图文档的场景至关重要。
第五章:火山引擎豆包模型的语义理解
当 ParseX 完成非结构化到结构化的转换后,数据将以 Markdown 格式返回。此时需要大模型对其进行语义总结或信息提取。
在 ParseX 节点后增加一个 LLM(大语言模型)节点。这个节点相当于智能体的大脑,负责理解解析出的文本。
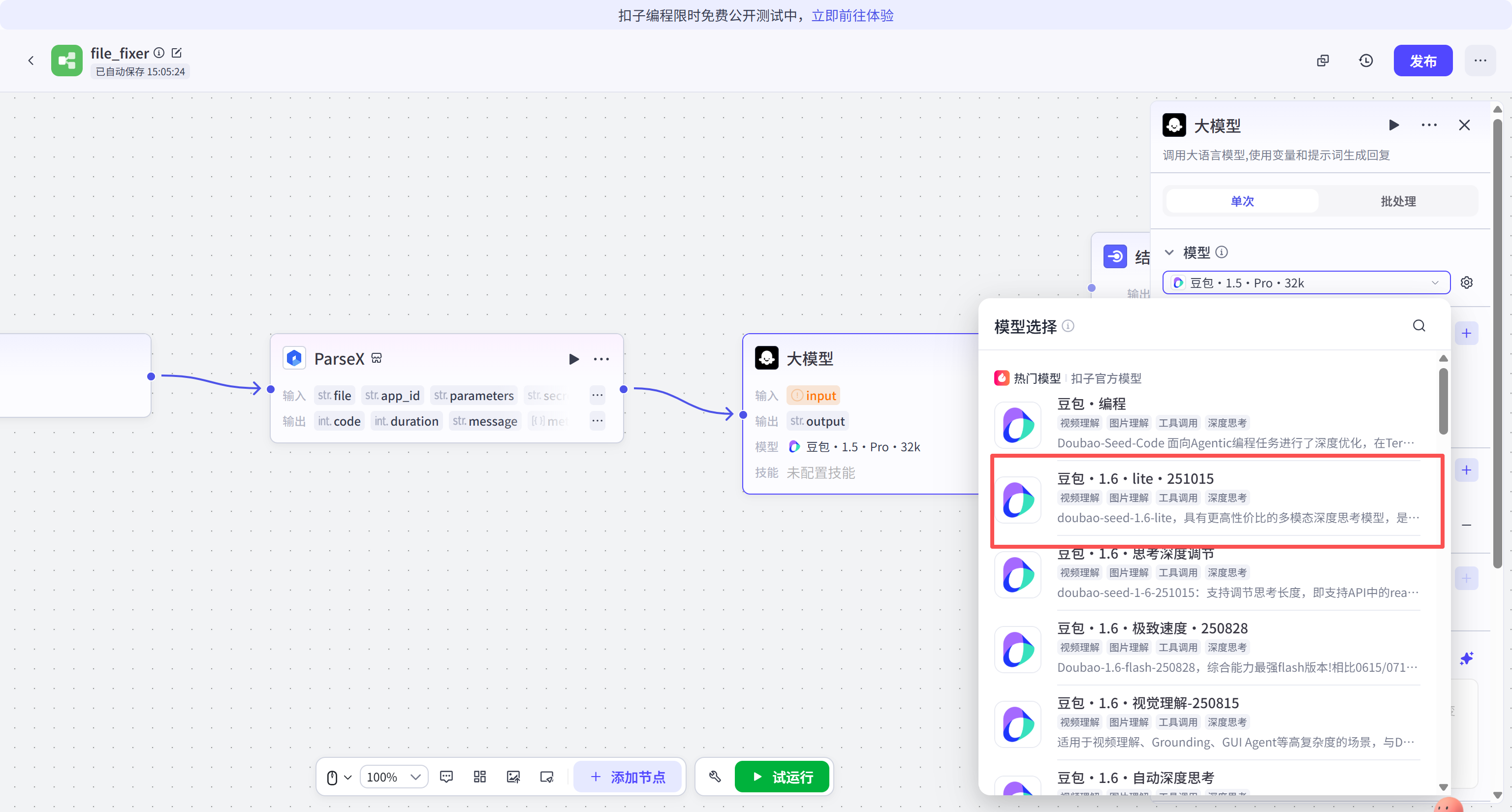
模型选择火山引擎自研的"豆包 1.6 lite"。该模型在保持高效响应的同时,具备出色的上下文理解能力,尤其擅长处理长文本摘要任务。
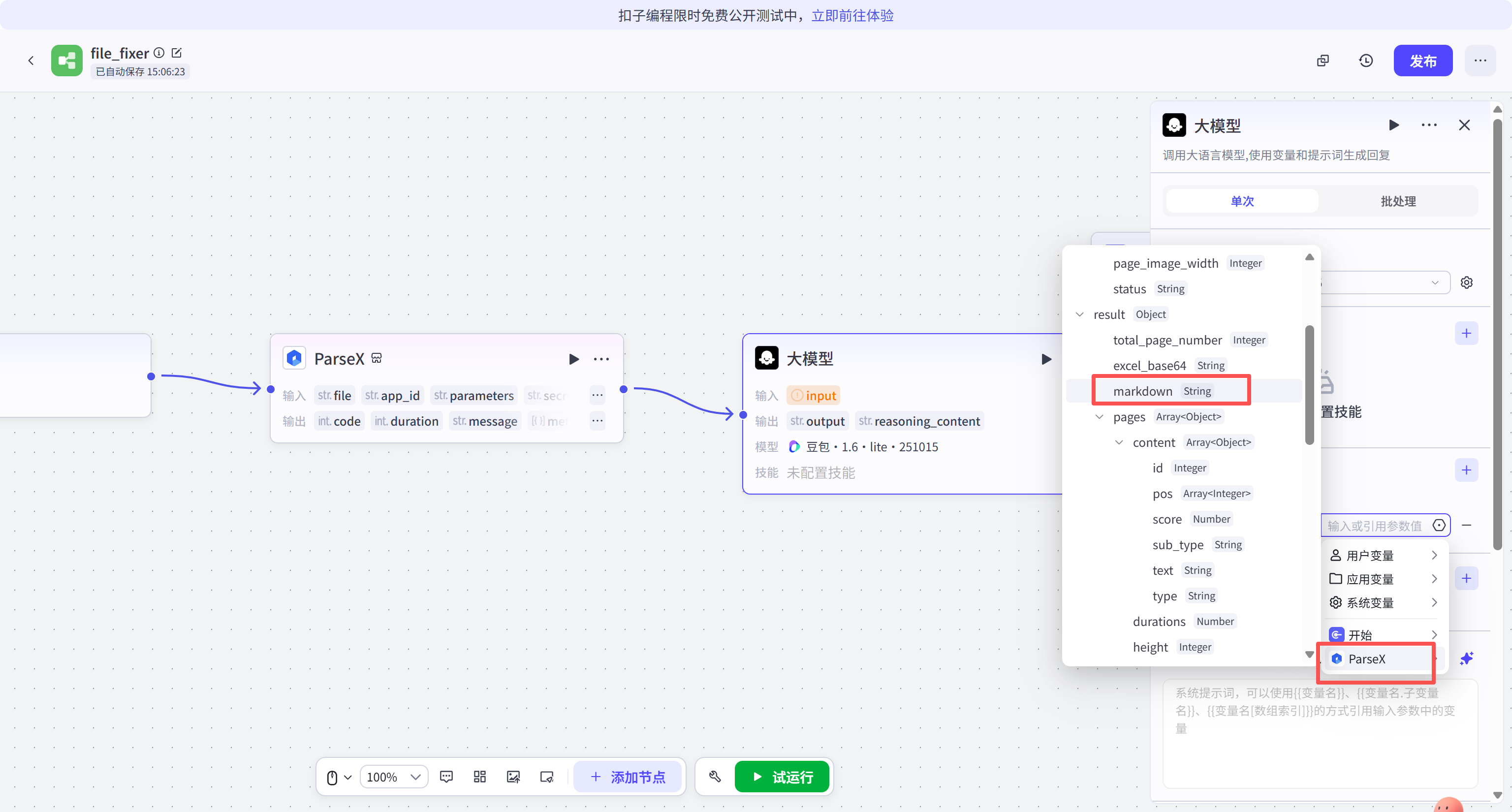
在模型提示词配置中,将 result 参数关联为 ParseX 返回的结构化内容。通过设定系统提示词,要求模型对提取出的 Markdown 文本进行分类、脱敏或关键指标提取。
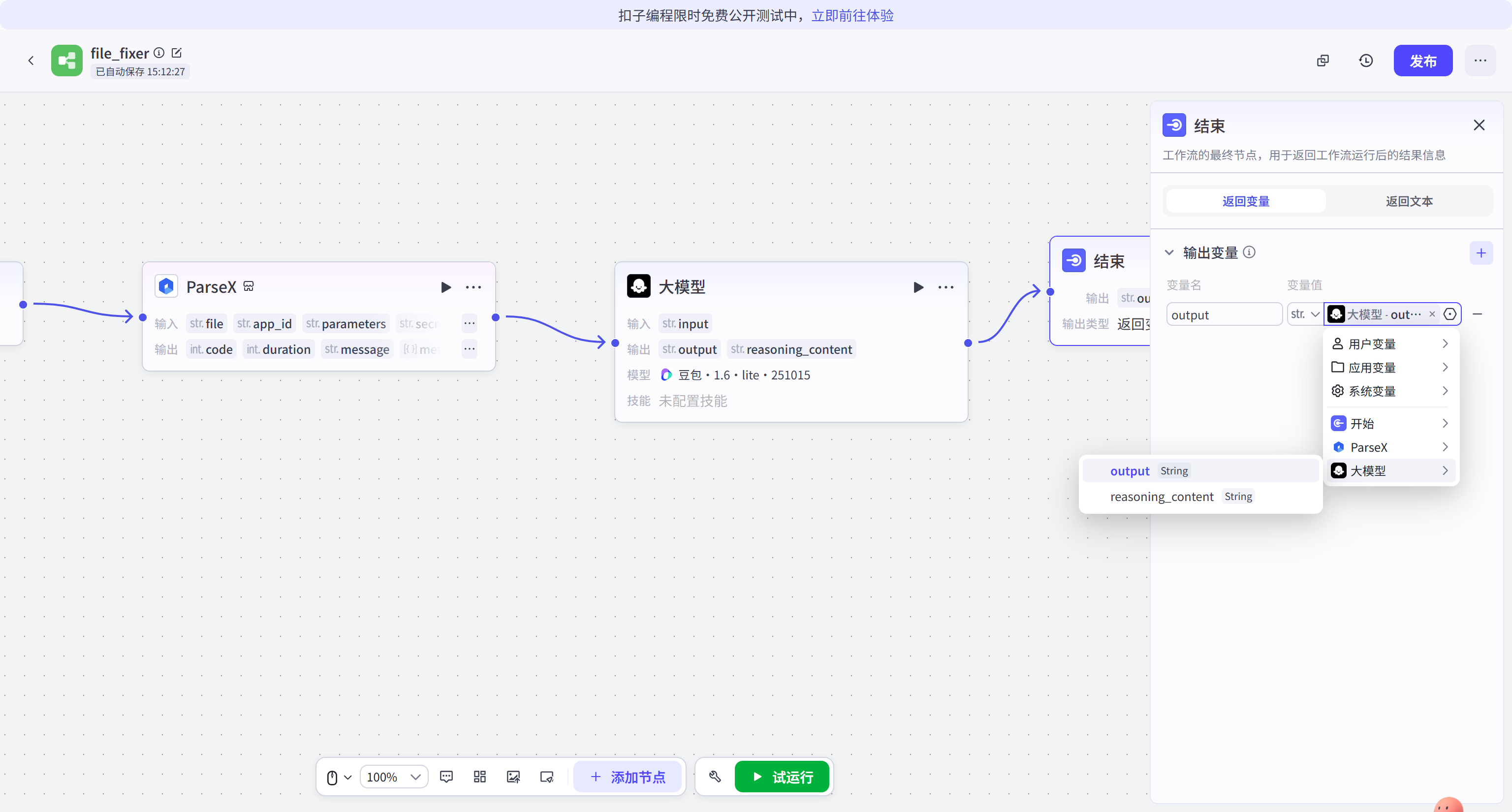
工作流的最后环节是"结束"节点。在此节点设置输出参数,确保大模型的分析结果能够正常回传至对话界面,展示给最终使用者。
第六章:系统调试与工业级应用实战
完成全链路编排后,必须进入压力测试与真实场景验证阶段。
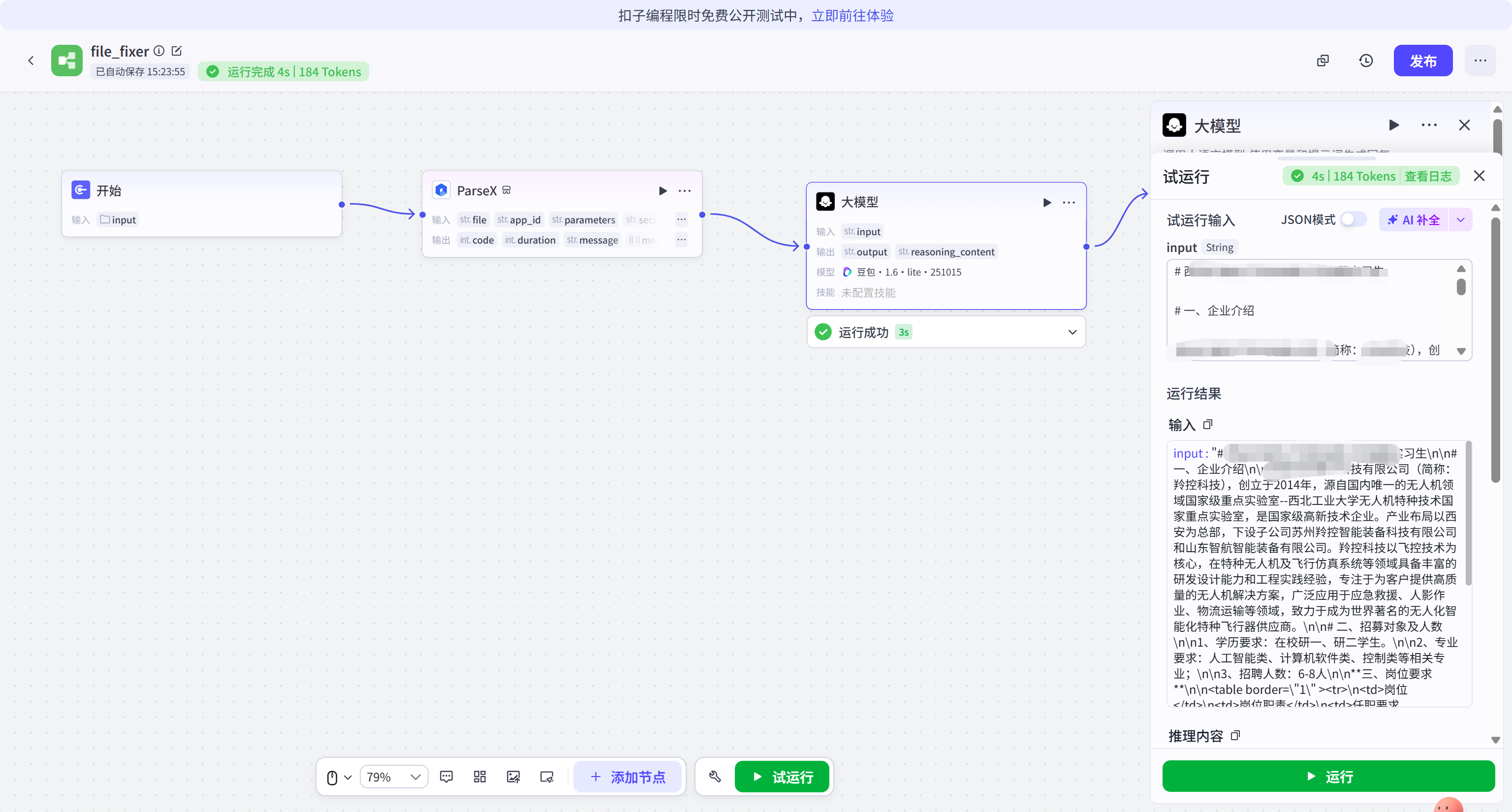
通过上传一份真实的面试需求文档进行测试。可以看到,系统成功触发工作流,ParseX 瞬间完成了对文档结构的拆解,豆包模型随后给出了精准的总结。调用链路显示绿色,标志着逻辑通路完全闭环。
在开发者控制台后台,可以实时观测数据包的交换细节。ParseX 返回的 JSON 数据流中包含了每一行文字的坐标、每一个单元格的逻辑关系。这种透明的调试信息有助于优化解析参数。
确认无误后,点击右上角的"发布"按钮。发布操作将工作流封装成一个生产环境可用的 API 服务,并将其正式挂载到智能体身上。
第七章:多模态输出与跨场景落地
该智能体的价值不仅在于读取文件,更在于它能处理复杂的视觉信息。
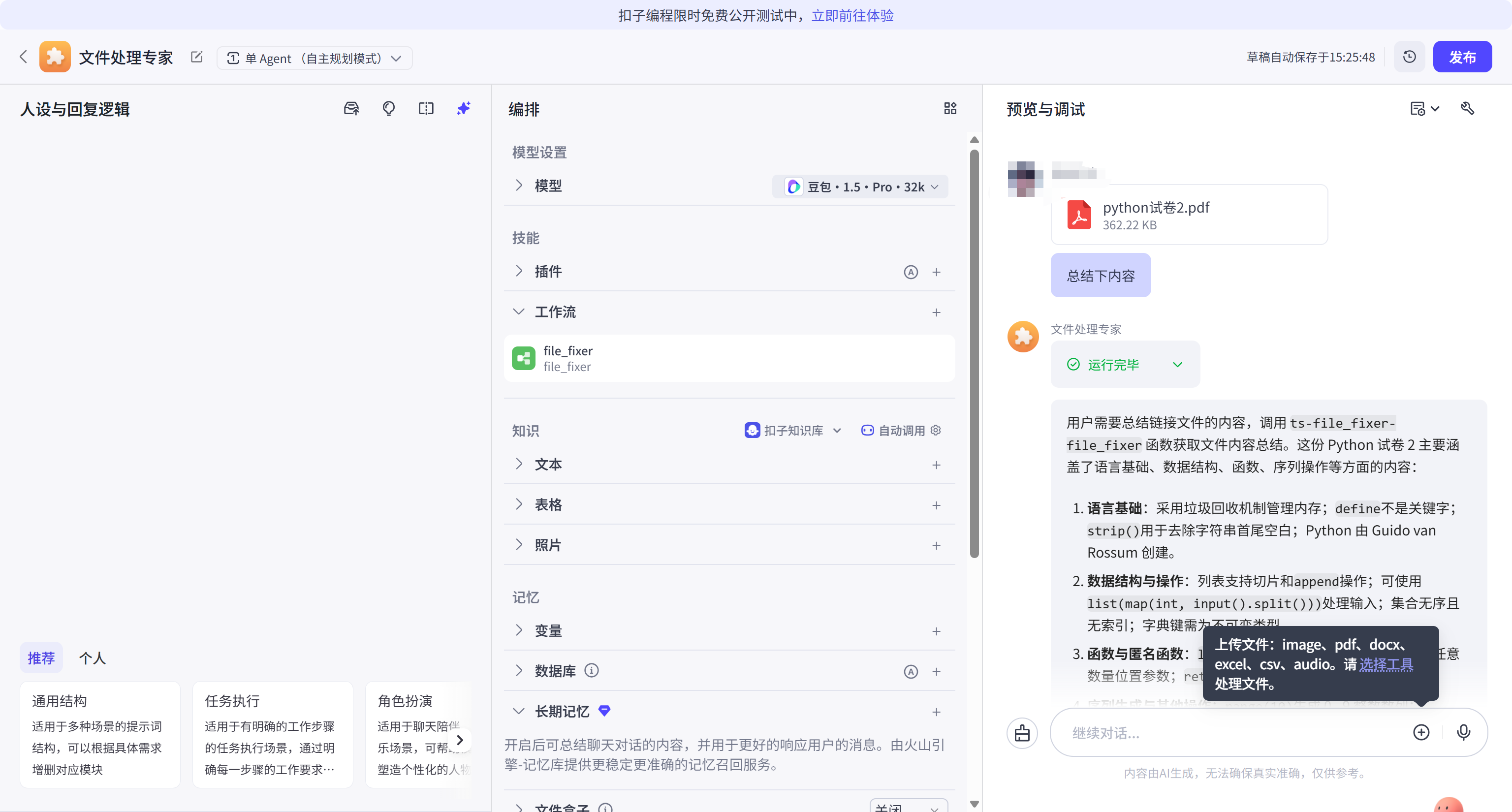
在对话界面测试上传 PDF 文件。智能体迅速反馈了文档的核心大纲。相比传统的 RAG(检索增强生成),基于 ParseX 的方案能够识别表格内的嵌套逻辑,避免了数据错位的现象。
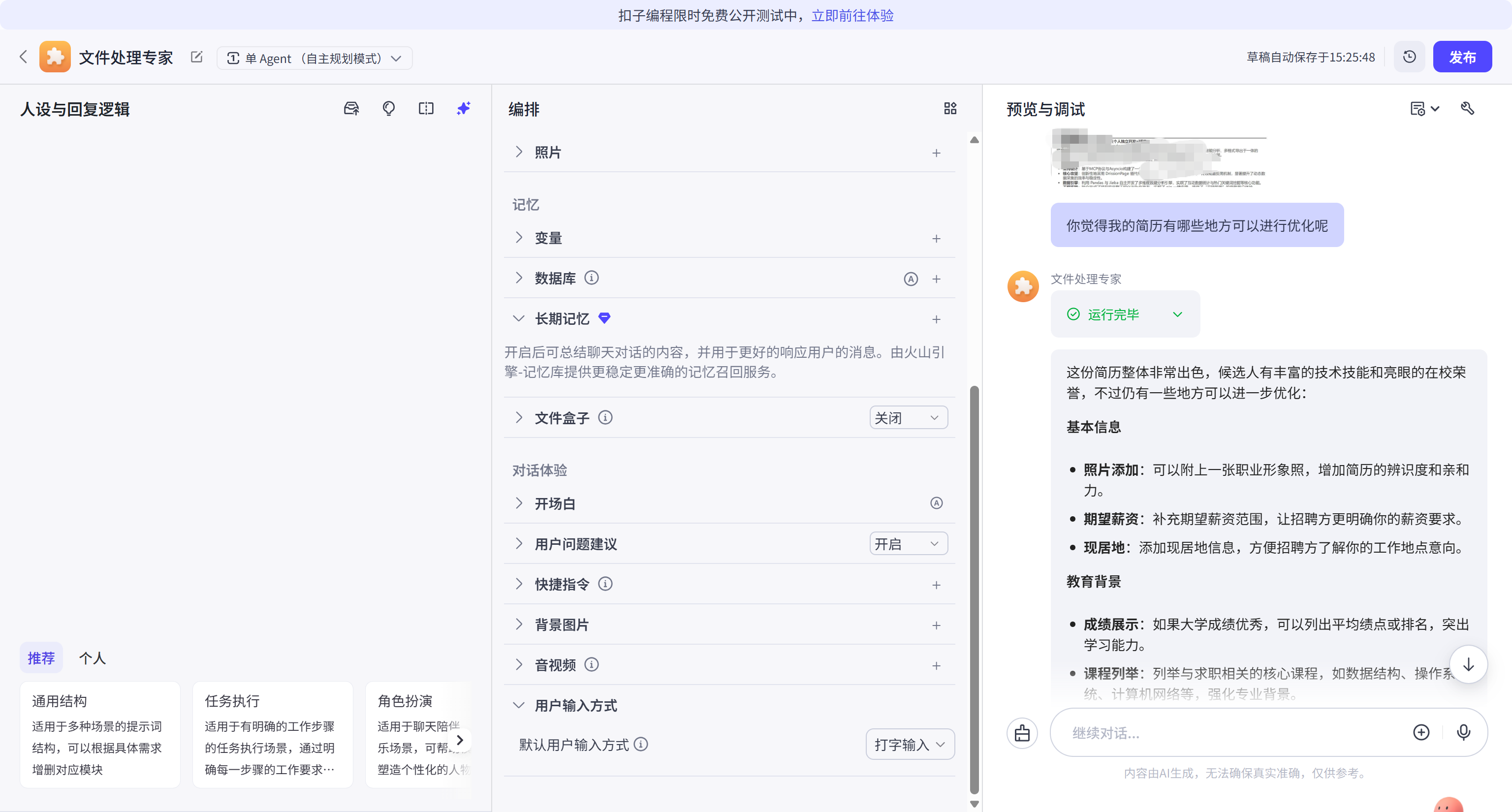
更进一步,当用户上传一张带有复杂排版的图片时,智能体能够将图片内容转化为标准的 Markdown 语法并导出。这意味着该智能体已经突破了"纯文本"的限制,具备了将物理世界纸质资料快速数字化的能力。
核心知识点深度挖掘
-
ParseX 的 Markdown 还原逻辑 :
传统的 OCR 只是将文字堆砌,而 ParseX 通过深度学习模型,能够识别标题层级(H1-H6)、列表、加粗粗体以及表格跨行跨列。大模型天然对 Markdown 敏感,这种格式极大降低了大模型的推理幻觉。
-
API 参数微调的必要性 :
在
parameters中,get_image决定了是否进行 OCR 转图。在处理带有印章、签名或流程图的文档时,开启此项能让大模型通过视觉 API 辅助验证文档的真实性与合规性。 -
工作流的异步处理优势 :
Coze 的工作流支持异步调用。对于几十页的长文档,通过工作流编排,可以将文档切片解析后再汇总,有效规避了大模型上下文长度的限制。
-
火山引擎生态联动 :
豆包模型与 TextIn 插件的结合,本质上是"视觉感知"与"逻辑认知"的融合。TextIn 负责"看清"世界,豆包负责"读懂"含义。
通过上述步骤,开发者可以在极短的时间内构建出一套企业级的文档处理 Agent。这种智能体不仅能胜任 HR 的简历筛选、财务的进销存票据录入,还能在法律合同审查等高精尖领域发挥巨大的技术杠杆作用。