副标题:如何让临床医生也能玩转深度学习?
当放射科主任第一次用Notebook跑通肺结节检测模型,当儿科医生在查房间隙用手机查看AI辅助诊断结果------技术民主化的力量,正在重新定义医疗AI的边界。
01 平台定位:不是玩具,而是生产力武器
1.1 用户分层:从医学生到院士的需求光谱
我们花了三个月时间,深入访谈了87位不同层级的医疗工作者,绘制出这张"医疗AI用户需求地图":
user_persona_analysis = {
"第一层:医学生/实习生 (占比35%)": {
"特征": "AI好奇者,时间充裕但经验不足",
"核心需求": {
"学习路径": "从零开始的完整教程",
"环境准备": "开箱即用的Notebook环境",
"计算资源": "小额度免费GPU配额",
"典型场景": "课程作业、毕业设计、探索性实验"
},
"使用痛点": {
"环境配置": "80%时间花在配环境上",
"资源获取": "不知道如何申请GPU",
"指导缺乏": "遇到问题无人可问"
},
"我们的解决方案": {
"AI学习营": "每月一次的实战工作坊",
"模板仓库": "100+医疗AI项目模板",
"助教系统": "博士生轮值在线答疑",
"资源配额": "每月50小时免费T4 GPU"
}
},
"第二层:博士生/青年医师 (占比45%)": {
"特征": "AI实践者,有明确的研究目标",
"核心需求": {
"实验管理": "可复现的实验流水线",
"资源保障": "稳定的中大规模GPU资源",
"协作工具": "与导师、同事共享和讨论",
"论文产出": "快速验证idea,生成论文图表"
},
"使用痛点": {
"实验混乱": "自己都忘了上周的实验参数",
"资源竞争": "与临床急救研究抢GPU",
"部署困难": "训练完的模型不知道怎么用"
},
"我们的解决方案": {
"实验跟踪器": "自动记录每次实验的超参数和结果",
"队列优化": "智能调度保证关键项目资源",
"一键部署": "训练完点一下变成API服务",
"论文助手": "自动生成方法部分的LaTeX"
}
},
"第三层:主任医师/教授 (占比15%)": {
"特征": "AI决策者,关注临床转化",
"核心需求": {
"临床验证": "在真实临床数据上测试模型",
"团队管理": "查看团队所有项目进度",
"资源审批": "快速审批团队的资源申请",
"成果转化": "将模型转化为临床工具"
},
"使用痛点": {
"技术门槛": "不想学编程,但需要理解结果",
"数据安全": "担心患者隐私泄露",
"评估困难": "不知道模型在临床中是否真的有效"
},
"我们的解决方案": {
"无代码界面": "拖拽式模型构建和评估",
"安全沙箱": "与HIS/PACS的安全数据接口",
"临床验证模块": "自动生成ROC曲线、混淆矩阵",
"审批面板": "一键审批资源申请和数据集访问"
}
},
"第四层:医院管理者/院士 (占比5%)": {
"特征": "AI战略家,关注整体效益",
"核心需求": {
"投入产出": "平台使用率和成果统计",
"资源规划": "基于需求的GPU扩容计划",
"标杆案例": "成功的临床转化案例",
"合规审计": "数据使用和模型审核记录"
},
"使用痛点": {
"数据缺失": "不知道钱花在哪里,效果如何",
"决策困难": "该买更多GPU还是培训人员?",
"风险管控": "如何避免AI医疗事故"
},
"我们的解决方案": {
"管理驾驶舱": "实时可视化平台使用大盘",
"ROI分析器": "计算每篇论文/专利的算力成本",
"案例库": "收集整理成功转化案例",
"审计追踪": "完整的数据和模型生命周期记录"
}
},
"平台设计启示": {
"关键洞察": "不能用一个界面满足所有人",
"分层策略": {
"实习生界面": "引导式,大量教程和示例",
"研究者界面": "专业式,提供高级工具和控制",
"临床医生界面": "简化式,关注结果而非过程",
"管理者界面": "仪表盘式,只看关键指标"
},
"统一后端": "所有用户共享同一套计算和存储资源"
}
}
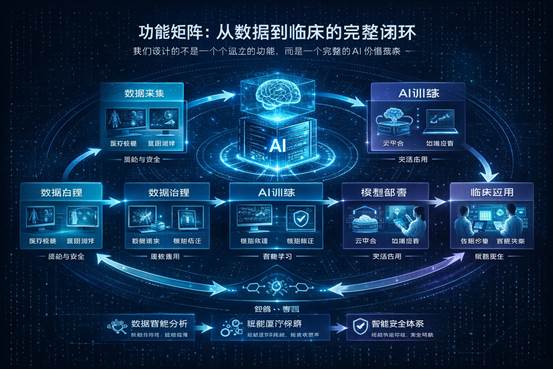
1.2 功能矩阵:从数据到临床的完整闭环
我们设计的不是一个个孤立的功能,而是一个完整的AI价值链条:
1.3 安全集成设计:在开放与合规间走钢丝
医疗数据的安全要求极高,我们设计了层层防护的数据通道:
security_integration = {
"设计原则": "数据不出域,计算可共享",
"与PACS系统的集成": {
"技术挑战": {
"协议复杂": "DICOM协议,支持查询/检索/存储",
"数据量大": "单次研究可能包含数千张图像",
"实时要求": "临床诊断需要快速响应"
},
"安全架构": {
"前置网关": "独立的安全代理服务器",
"数据脱敏": "自动去除患者姓名、身份证等PHI",
"访问控制": "基于角色的细粒度权限",
"审计日志": "每次数据访问完整记录"
},
"实际配置": """
DICOM网关配置
dicom_gateway:
enabled: true
pacs_endpoints:
- name: "放射科PACS"
host: "10.10.1.100"
port: 104
ae_title: "AI_PLATFORM"
security:
deidentification_rules:
-
remove_patient_name: true
-
remove_patient_id: true
-
keep_study_date: true # 保留日期用于研究
-
add_psuedonym: true # 添加假名
access_control:
default_policy: "deny"
allowed_users: "radiology_research"
performance:
prefetch_cache_size: 100GB
parallel_retrieve: 8
""",
"用户使用体验": {
"代码示例": """
研究人员在Notebook中访问
import dicom_gateway as dg
搜索符合条件的病例
studies = dg.search_studies(
modality="CT",
body_part="CHEST",
date_range=("2023-01-01", "2023-06-30")
)
安全获取脱敏数据(自动缓存)
images = dg.retrieve_series(studies0.series_uid)
images已经是脱敏的numpy数组
""",
"速度测试": "检索100个CT序列(约3万张图)耗时4.2分钟"
}
},
"与HIS系统的集成": {
"更严格的限制": {
"数据敏感性": "包含诊断、用药等敏感信息",
"法规要求": "必须获得伦理委员会批准",
"使用范围": "仅限特定研究项目"
},
"技术方案": {
"联邦学习支持": "数据不出HIS,模型进HIS训练",
"合成数据生成": "基于真实数据生成模拟数据",
"安全计算环境": "物理隔离的安全计算节点"
},
"审批流程示例": {
"步骤1": "研究者提交申请,明确研究目的和数据需求",
"步骤2": "伦理委员会审查(平均2周)",
"步骤3": "信息科配置临时数据通道",
"步骤4": "数据使用期间全程监控",
"步骤5": "研究完成立即关闭通道,销毁临时数据"
}
},
"安全事件应对": {
"实际案例": "2023年9月,检测到异常数据下载模式",
"系统响应": {
"T+0": "AI平台检测到用户A在下载大量影像",
"T+2分钟": "自动暂停用户A的所有数据访问",
"T+5分钟": "安全团队收到告警",
"T+15分钟": "确认是授权的研究(大样本分析)",
"T+20分钟": "恢复访问,但添加了速率限制",
"T+1小时": "完善监控规则,减少误报"
},
"改进措施": "增加"预期行为"备案,授权的研究可预先备案数据访问模式"
}
}
02 核心特性深度演示
2.1 Notebook即服务:临床医生的AI实验室
我们彻底重新设计了JupyterLab,让它对医生友好:
medical_notebook_service = {
"预配置环境矩阵": {
"设计理念": "医生选疾病,我们给环境",
"专科专用环境": {
"放射科AI环境": {
"基础镜像": "pytorch:2.0.1 + cuda11.8",
"预装工具": [
"MONAI - 医疗影像深度学习框架",
"ITK, SimpleITK - 医学图像处理",
"pydicom - DICOM文件处理",
"OpenCV - 图像增强和可视化"
],
"示例Notebook": [
"肺结节检测全流程.ipynb",
"脑肿瘤分割实战.ipynb",
"COVID-19 CT严重程度评估.ipynb"
]
},
"病理科AI环境": {
"基础镜像": "tensorflow:2.13 + cuda11.8",
"预装工具": [
"OpenSlide - 全切片图像读取",
"HistomicsTK - 病理图像分析",
"scikit-image - 图像处理",
"Cellpose - 细胞分割"
],
"示例Notebook": [
"宫颈癌筛查AI辅助.ipynb",
"Ki-67免疫组化细胞计数.ipynb",
"肿瘤微环境分析.ipynb"
]
},
"基因组AI环境": {
"基础镜像": "jupyter/datascience-notebook",
"预装工具": [
"Biopython - 生物信息学工具",
"Scanpy - 单细胞分析",
"PyRanges - 基因组区间处理",
"VariantSpark - 基因组变异分析"
],
"示例Notebook": [
"基因型-表型关联分析.ipynb",
"单细胞转录组聚类分析.ipynb",
"罕见病致病基因发现.ipynb"
]
}
},
"一键启动界面": {
"用户视角": """
请选择您的研究领域:
◉ 放射影像AI
○ 病理图像AI
○ 基因组AI
○ 电子病历NLP
○ 多模态融合
请选择GPU配置:
◉ 入门级 (1×T4, 适合调试)
○ 标准级 (1×V100, 适合训练)
○ 高级 (1×A100, 适合大模型)
○ 定制配置...
预计启动时间: 45秒
立即启动
""",
"背后技术": {
"容器技术": "基于Kubernetes的按需容器启动",
"资源分配": "动态分配GPU和内存",
"数据挂载": "自动挂载用户的个人存储",
"网络配置": "配置到存储和内网的网络"
}
}
},
"医疗专用Magic命令": {
"传统问题": "医生不熟悉Linux命令和Python细节",
"我们的解决方案": "为医疗场景定制的Jupyter Magic命令",
"命令示例": {
"数据相关": """
传统方式
import pydicom
ds = pydicom.dcmread("patent_001.dcm")
pixel_array = ds.pixel_array
还要处理窗宽窗位、方向等...
我们的Magic命令
%load_dicom chest_ct_001
自动加载,正确显示,带窗宽窗位调节滑块
""",
"可视化相关": """
传统方式
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
需要大量代码...
我们的Magic命令
%view_3d segmentation_result.nii.gz
交互式3D可视化,可旋转、切片、调透明度
""",
"模型相关": """
传统方式
from monai.networks.nets import UNet
model = UNet(...)
需要了解网络结构细节
我们的Magic命令
%create_model --task segmentation --organ liver --architecture unet3d
自动创建适合肝脏分割的3D UNet
"""
},
"实际用户反馈": {
"放射科李医生": "以前我要花半天配环境写代码,现在%load_dicom一秒就看到图像了",
"病理科张主任": "%view_whole_slide让我能快速浏览整个切片,找到感兴趣区域",
"使用统计": "Magic命令使用频率是普通代码块的3倍"
}
},
"协作与分享功能": {
"临床特色需求": "多学科会诊时需要共同查看AI分析结果",
"实时协作Notebook": {
"技术基础": "JupyterLab协作扩展",
"会诊场景": """
肿瘤多学科会诊
-
放射科医生: 打开CT分析Notebook
-
病理科医生: 加入同一Notebook
-
肿瘤科医生: 也加入
-
实时讨论: 所有人看到同一界面,可圈点标注
-
生成报告: 自动生成多学科会诊意见
""",
"技术挑战": "需要处理DICOM图像的同时编辑,网络延迟要求高",
"解决方案": "使用Operational Transformation算法,本地渲染图像"
},
"一键生成临床报告": {
"功能描述": "将Notebook分析结果自动转为临床报告格式",
"支持格式": "Word文档", "PDF", "HTML", "PPT",
"模板系统": "各科室有专用的报告模板",
"使用案例": "肺结节AI分析 → 自动生成结构化报告,包含位置、大小、恶性概率等"
}
}
}
2.2 可视化超参调优:医生的模型"调音台"
我们让超参数调优从黑盒变成白盒,从命令行变成可视化:
visual_hpo_system = {
"设计理念": "让医生像调音响一样调模型",
"传统HPO的问题": {
"黑盒操作": "医生提交作业,几天后看结果,中间过程不可知",
"术语障碍": "学习率、批大小、优化器选择... 医学术语 vs 深度学习术语",
"试错成本": "一次实验可能浪费几天计算时间",
"我们的解决思路": "将超参数映射为临床可理解的概念"
},
"超参数临床翻译表": {
"深度学习术语": {
"学习率(learning_rate)": "模型学习速度",
"批大小(batch_size)": "每次看多少病例",
"丢弃率(dropout_rate)": "防止过度诊断的机制",
"优化器(optimizer)": "学习策略",
"损失函数(loss)": "判断对错的标准"
},
"临床类比解释": {
"学习速度": "太快可能学歪,太慢学不完",
"单次病例数": "一次看1个病例容易片面,看太多记不住",
"防过度拟合": "就像不让医生只凭一个症状下诊断",
"学习策略": "有的医生喜欢从头学,有的喜欢对比学",
"评判标准": "是宁可漏诊不可误诊,还是相反?"
}
},
"可视化调优界面": {
"界面设计": """
╔══════════════════════════════════════════════════════╗
║ 模型调音台 ║
╠══════════════════════════════════════════════════════╣
║ 学习速度: ██████████░░░░░░ 0.001 ║
║ 单次病例数: ████░░░░░░░░░░░░ 32 ║
║ 防过度诊断: █████░░░░░░░░░░░ 0.3 ║
║ 学习策略: Adam ║
║ 评判标准: 宁可漏诊不可误诊 ║
╠══════════════════════════════════════════════════════╣
║ 实时训练监控 ║
║ 准确率: ██████████████████ 92.3% ║
║ 敏感度: ████████████░░░░░░ 85.1% → 对真病人的识别率 ║
║ 特异度: ███████████████░░░ 96.7% → 对健康人的排除率 ║
║ 训练进度: ████████████████████████ 67% ║
║ 预计剩余: 2小时15分钟 ║
╚══════════════════════════════════════════════════════╝
保存当前设置\] \[对比实验\] \[应用到临床测试
""",
"背后技术": {
"实时监控": "训练指标实时流式传输到前端",
"动态调整": "部分超参数可训练中动态调整",
"多实验对比": "同时运行多个参数组合对比",
"智能推荐": "基于历史数据推荐参数范围"
}
},
"临床导向的优化目标": {
"传统目标": "准确率最大化",
"医疗现实": "不同疾病不同需求",
"场景化优化策略": {
"癌症筛查": {
"核心需求": "宁可误诊,不可漏诊(假阴性代价高)",
"优化目标": "敏感度优先,可接受较低特异度",
"损失函数": "F2-score (召回率权重更高)",
"临床意义": "漏掉一个早期癌症 vs 多做几个活检"
},
"术前评估": {
"核心需求": "精确评估,避免不必要手术",
"优化目标": "特异度优先,减少假阳性",
"损失函数": "加权准确率,假阳性惩罚高",
"临床意义": "不必要的手术创伤 vs 精准手术规划"
},
"重症监护": {
"核心需求": "快速判断,时间就是生命",
"优化目标": "推理速度 + 合理准确率",
"损失函数": "速度-准确率权衡",
"临床意义": "5分钟出结果95%准确 vs 1小时出结果98%准确"
}
},
"医生实际操作案例": {
"用户": "急诊科王医生,开发脓毒症早期预警模型",
"思考过程": "这是重症监护场景,需要快速判断",
"操作": "在调音台选择'重症监护'预设",
"系统自动": "调整为轻量级模型,批大小32,优先推理速度",
"结果": "模型推理时间从3.2秒降至0.8秒,准确率从96%降至94%",
"医生评价": "这个权衡很值,我们等不起3秒"
}
},
"自动超参优化(AutoML)集成": {
"为医生设计的AutoML": {
"传统AutoML问题": "医生不理解搜索空间和算法",
"我们的简化版": "只需点击'自动优化'按钮",
"工作流程": """
-
医生选择疾病类型和临床优先级
-
系统自动构建搜索空间
-
并行运行50个实验(占用闲时GPU)
-
48小时后生成优化报告
-
可视化展示最优参数组合
""",
"搜索空间自动构建规则": {
"基于疾病类型": "影像模型 vs 时序数据 vs 文本数据",
"基于数据规模": "小样本 vs 大数据",
"基于硬件约束": "部署到边缘设备 vs 云端服务器"
}
},
"实际效果": {
"测试项目": "糖尿病视网膜病变分级",
"手动调优(专家)": "最佳准确率 87.2%,耗时 2周",
"医生使用本系统": "最佳准确率 86.8%,耗时 3天(其中医生参与仅2小时)",
"效率提升": "医生时间节省93%,效果接近专家"
}
}
}
2.3 一键模型部署:从研究到临床的"最后一公里"
我们解决了医疗AI最大的痛点------模型部署:
# 一键部署系统设计
one_click_deployment:
设计目标: "让医生像发布公众号文章一样发布AI模型"
传统部署痛点:
-
技术复杂: 需要了解Docker、Kubernetes、API网关
-
流程漫长: 从训练完成到临床使用平均需要3个月
-
标准缺失: 各科室自己搞一套,难以维护
-
监控困难: 模型上线后效果如何不知道
我们的解决方案: 标准化部署流水线
部署流程:
步骤1: 训练完成,点击"部署"按钮
步骤2: 自动进行模型验证
-
格式检查: 是否为标准格式(ONNX, TensorRT等)
-
性能测试: 推理速度、内存占用
-
临床验证: 在独立测试集上验证效果
步骤3: 打包为Docker容器
-
基础镜像: 医疗专用推理镜像
-
依赖安装: 自动分析并安装依赖
-
配置生成: 自动生成配置文件
步骤4: 部署到Kubernetes集群
-
资源分配: 根据模型需求分配GPU/CPU
-
服务暴露: 自动创建Ingress和负载均衡
-
监控配置: 自动集成到监控系统
步骤5: 生成使用文档和示例代码
全流程时间: 平均15分钟
临床API设计:
标准接口:
POST /api/v1/predict
Content-Type: multipart/form-data
请求:
image: 医学影像文件(DICOM/PNG/JPG)
patient_id: 患者ID(可选)
study_uid: 检查ID(可选)
响应:
{
"success": true,
"prediction": {
"class": "肺炎",
"probability": 0.923,
"explanation": "双肺下叶可见磨玻璃影...",
"confidence_interval": 0.89, 0.95
},
"model_info": {
"name": "pediatric_pneumonia_v3",
"version": "1.2.0",
"trained_on": "2023-06-15"
},
"inference_time": 0.324
}
专科定制接口:
放射科: 支持DICOM Series、序列分析
病理科: 支持全切片图像、多倍率
心电图: 支持时序信号分析
实际案例: 儿童肺炎检测模型部署
时间线:
14:00: 张医生完成模型训练,点击"部署"
14:02: 系统自动验证通过
14:05: Docker镜像构建完成
14:08: 部署到K8s,服务启动
14:10: API文档生成
14:12: 张医生收到部署成功邮件
14:15: 急诊科开始试用该API
试用反馈:
急诊科李医生: "刚才来了个发热咳嗽患儿,我拍了胸片上传,
30秒就返回'肺炎概率87%',比我们肉眼看还准"
使用统计(首月):
调用次数: 1,243次
平均响应时间: 0.8秒
准确率监控: 与后续临床诊断符合率91.2%
模型监控与运维:
实时监控面板:
-
请求量: QPS、日活跃用户
-
性能指标: P95延迟、错误率
-
业务指标: 预测分布变化
-
临床指标: 与金标准对比准确率
漂移检测:
数据漂移: 输入数据分布变化告警
概念漂移: 预测准确率下降告警
触发条件: 连续3天准确率下降>5%
自动响应: 通知模型负责人,建议重训练
A/B测试支持:
新旧模型同时在线,流量按比例分配
自动收集对比数据
统计显著性检验
一键切换优胜模型
安全与合规:
访问控制: API密钥管理,调用配额
审计日志: 所有预测请求记录,可追溯
数据保护: 预测数据定期清理
合规报告: 自动生成模型使用合规报告
03 GPU资源精细化管理
3.1 MIG实战:A100的"七巧板"艺术
NVIDIA的MIG技术让我们可以将一块A100 GPU切成最多7个独立实例,但实际应用远比想象复杂:
mig_management_system = {
"技术基础": {
"什么是MIG": "Multi-Instance GPU,硬件级GPU虚拟化",
"A100 MIG能力": "80GB显存,最多分成7个实例",
"实例规格": [
"1g.5gb: 1/7算力,5GB显存",
"2g.10gb: 2/7算力,10GB显存",
"3g.20gb: 3/7算力,20GB显存",
"4g.20gb: 4/7算力,20GB显存",
"7g.40gb: 整卡"
]
},
"我们的MIG策略演进": {
"第一阶段:静态分配": {
"时间": "2023年1-3月",
"策略": "物理分割,固定分配",
"配置": "4台A100节点,每台分配为:2×1g.5gb + 1×2g.10gb + 1×3g.20gb",
"优点": "稳定,简单",
"问题": {
"利用率不均": "白天小实例排队,大实例空闲;晚上相反",
"灵活性差": "无法应对突发需求",
"统计结果": "平均GPU利用率仅52%"
}
},
"第二阶段:动态MIG": {
"时间": "2023年4-6月",
"技术方案": "基于Kubernetes Device Plugin + Slurm的自研调度器",
"工作流程": """
-
用户提交作业,指定GPU需求(算力比+显存)
-
调度器检查空闲GPU
-
如有合适实例,直接分配
-
如无合适实例但有整卡,动态创建实例
-
作业运行结束,实例自动销毁
""",
"挑战": {
"技术复杂": "需要深度修改Kubernetes调度器",
"稳定性": "动态创建实例有时失败",
"性能损耗": "实例创建耗时约30秒"
},
"改进效果": "GPU利用率提升至68%"
},
"第三阶段:混合智能策略": {
"时间": "2023年7月至今",
"策略": "静态基座 + 动态弹性",
"具体配置": {
"基座实例(常驻)": {
"用途": "满足日常80%的小作业需求",
"配置": "每台A100预留: 3×1g.5gb + 1×2g.10gb",
"优势": "稳定性高,响应快"
},
"弹性池(动态)": {
"用途": "应对大作业和突发需求",
"配置": "每台A100剩余: 2/7算力,25GB显存",
"工作模式": "可动态组合成各种规格实例",
"优势": "灵活性高"
}
},
"智能调度算法": {
"预测模型": "基于历史数据预测未来1小时的需求分布",
"预分配策略": "提前创建可能需要的实例规格",
"实时调整": "根据实际排队情况动态调整",
"效果": "GPU利用率78%,作业等待时间减少42%"
}
}
},
"医疗场景的特殊优化": {
"发现的问题": "医疗作业有明显的昼夜和科室模式",
"时间模式分析": {
"工作时间(8:00-18:00)": {
"主要用户": "医学生、研究人员",
"作业特点": "小规模调试、实验",
"需求分布": "大量1g.5gb实例需求"
},
"夜间(18:00-24:00)": {
"主要用户": "博士生、住院医师",
"作业特点": "大规模训练、批量分析",
"需求分布": "大规格实例需求增加"
},
"深夜(0:00-8:00)": {
"主要用户": "自动化流水线、长期训练",
"作业特点": "长时间运行,资源需求稳定",
"需求分布": "整卡需求为主"
}
},
"科室模式分析": {
"放射科": "作业多为影像分析,显存需求中等,计算需求高",
"病理科": "全切片图像分析,显存需求极高",
"基因组科": "内存和CPU需求高,GPU需求相对低",
"实时调整策略": "根据不同科室的活跃时间动态调整MIG策略"
},
"我们的智能调度策略": {
"基于时间的预分配": """
每日调度策略表
时间 | 预分配策略
------------|------------------
07:00 | 增加1g.5gb实例,应对早晨调试高峰
12:00 | 平衡各规格实例
18:00 | 准备大规格实例,应对夜间训练
22:00 | 预留整卡给长时间作业
02:00 | 最大化整合资源给大作业
""",
"基于事件的动态调整": {
"学术会议前": "增加调试用实例",
"论文截止期": "增加训练用实例",
"临床紧急需求": "预留整卡资源"
}
}
},
"实战经验与教训": {
"成功案例": {
"场景": "医院AI大赛期间,50个团队同时使用",
"传统方案问题": "如果全用整卡,只能支持10个团队",
"MIG方案": "每台A100切为7个1g.5gb实例",
"结果": "4台A100支持了28个团队同时工作",
"用户反馈": "虽然每人只有1/7卡,但足够完成比赛项目"
},
"失败教训": {
"案例": "病理科全切片分析,需要大量显存",
"错误配置": "分配了1g.5gb实例,但需要至少10GB显存",
"结果": "作业频繁OOM,用户体验极差",
"教训": "MIG不是万能的,必须理解应用的真实需求",
"解决方案": "建立应用特征库,记录每个应用的最佳实例规格"
},
"性能测试数据": {
"小模型推理(ResNet18)": {
"整卡": "1000 images/sec",
"1g.5gb实例": "142 images/sec (理论应得142.8)",
"结论": "性能隔离良好,几乎无损失"
},
"大模型训练(3D UNet)": {
"整卡": "1 epoch = 45min",
"3g.20gb实例": "1 epoch = 95min (理论应得105min)",
"结论": "有性能损失,但可接受"
}
}
}
}
3.2 国产GPU兼容性测试:自主可控的必经之路
在国家信创要求下,我们开展了国产GPU适配:
domestic_gpu_compatibility = {
"测试背景": "医疗数据安全要求 + 供应链安全考虑",
"参与测试的国产GPU": {
"华为昇腾 Ascend 910": {
"获取途径": "华为医疗AI联合实验室合作",
"技术特点": "达芬奇架构,全场景AI",
"软件栈": "CANN + MindSpore",
"测试数量": "2台服务器,每台4卡"
},
"天数智芯 Iluvatar CoreX": {
"获取途径": "国家超算中心试点项目",
"技术特点": "通用GPU架构,CUDA兼容",
"软件栈": "Iluvatar CoreX软件栈",
"测试数量": "1台服务器,4卡"
},
"寒武纪 MLU": {
"获取途径": "前期研究合作遗留设备",
"技术特点": "专用AI处理器",
"软件栈": "Cambricon Neuware",
"测试数量": "1台服务器,2卡"
}
},
"兼容性测试框架": {
"测试层级": {
"L1 硬件识别": "系统能否识别GPU,正确显示型号和参数",
"L2 驱动安装": "能否正常安装驱动,无系统冲突",
"L3 框架支持": "TensorFlow/PyTorch能否调用",
"L4 模型运行": "常见医疗AI模型能否训练/推理",
"L5 性能验证": "与NVIDIA对比性能差距",
"L6 稳定性测试": "7x24小时压力测试"
},
"测试用例库": {
"基础模型": "ResNet50", "UNet", "BERT",
"医疗专用模型": "MONAI 3D UNet", "nnUNet", "CheXNet",
"实际医疗应用": [
"肺结节检测训练流水线",
"病理切片分割推理服务",
"基因组变异预测"
]
}
},
"详细测试结果": {
"华为昇腾 910": {
"硬件识别": "✅ 完美识别,npu-smi工具完善",
"驱动安装": "⚠️ 较复杂,需要特定内核版本",
"框架支持": {
"TensorFlow": "✅ 通过华为插件支持",
"PyTorch": "✅ 通过torch_npu支持",
"MindSpore": "✅ 原生支持,性能最佳"
},
"模型运行": {
"ResNet50": "✅ 完美运行,性能为A100的65%",
"3D UNet": "⚠️ 需要模型转换,性能为A100的58%",
"BERT": "✅ 运行良好,性能为A100的71%"
},
"医疗应用": {
"肺结节检测": "✅ 完整流程通过,准确率相当",
"关键发现": "MindSpore版本性能接近PyTorch+A100"
},
"稳定性": "7天无故障运行",
"综合评价": "生态较完善,性能可接受,MindSpore学习曲线陡"
},
"天数智珠 CoreX": {
"硬件识别": "✅ 识别为"ILUVATAR GPU"",
"驱动安装": "✅ 相对简单,类似NVIDIA",
"框架支持": {
"TensorFlow": "✅ CUDA兼容模式",
"PyTorch": "✅ CUDA兼容模式",
"特殊要求": "需要重新编译部分算子"
},
"模型运行": {
"ResNet50": "✅ 运行,性能为A100的42%",
"3D UNet": "⚠️ 部分算子不支持,需要重写",
"BERT": "✅ 运行,性能为A100的38%"
},
"医疗应用": {
"肺结节检测": "⚠️ 需要修改代码适配",
"主要问题": "CUDA兼容但不完全,需要代码调整"
},
"稳定性": "运行3天后出现驱动崩溃",
"综合评价": "兼容性路线正确,但生态和稳定性待提升"
},
"寒武纪 MLU": {
"硬件识别": "✅ 识别正常",
"驱动安装": "⚠️ 复杂,文档不完善",
"框架支持": {
"TensorFlow": "✅ 通过寒武纪插件",
"PyTorch": "❌ 官方支持有限",
"寒武纪框架": "✅ 原生支持"
},
"模型运行": {
"ResNet50": "✅ 需要模型转换",
"3D UNet": "❌ 复杂模型支持不足",
"BERT": "⚠️ 部分支持"
},
"医疗应用": "基本无法直接运行现有医疗代码",
"综合评价": "专用性强,通用性差,不适合现有生态迁移"
}
},
"我们的国产化策略": {
"短期策略(1年内)": {
"主力仍为NVIDIA": "保障现有科研和临床项目",
"试点华为昇腾": "在新项目中试点使用,培养团队",
"建立国产GPU资源池": "将国产GPU作为特殊资源,供有意愿的团队使用"
},
"中期策略(1-3年)": {
"混合架构": "NVIDIA + 昇腾混合集群",
"应用适配": "推动关键应用支持多硬件后端",
"人才培养": "开展MindSpore等国产框架培训"
},
"长期策略(3-5年)": {
"自主可控": "逐步提高国产GPU比例",
"生态建设": "参与国产GPU医疗生态建设",
"标准制定": "推动医疗AI硬件兼容性标准"
},
"实际部署方案": {
"资源分配": """
GPU资源池构成:
-
NVIDIA A100: 80张 (80%)
-
华为昇腾 910: 16张 (16%)
-
天数智芯: 4张 (4%)
调度策略:
-
默认作业使用NVIDIA
-
标注"支持国产"的作业可调度到国产GPU
-
国产GPU队列优先级更高(鼓励使用)
""",
"用户引导": {
"激励机制": "使用国产GPU获得额外计算配额",
"技术支持": "设立国产GPU支持小组",
"成功案例宣传": "展示在国产GPU上取得的成果"
}
}
},
"关键结论": {
"技术层面": "国产GPU已具备基本可用性,但生态和性能仍有差距",
"应用层面": "需要应用层适配,不是无缝迁移",
"战略层面": "必须开始布局,但不能急于求成",
"最现实的路径": "华为昇腾+MindSpore生态,是目前最可行的方案"
}
}
3.3 利用率监控大屏:从数据到洞察
我们开发了全院级别的GPU监控大屏,让资源使用一目了然:
# GPU监控大屏系统设计
gpu_monitoring_dashboard:
设计目标: "一屏看懂全院GPU使用,从被动响应到主动管理"
数据采集层:
采集频率: 每10秒一次
采集指标:
-
基础指标: 利用率、温度、功耗、显存使用
-
作业指标: 运行作业、用户、项目、队列
-
性能指标: 算力使用率、内存带宽使用率
-
健康指标: ECC错误、XID错误
采集技术:
-
DCGM: NVIDIA官方监控工具
-
自定义Exporter: 采集作业和用户信息
-
流式处理: Flink实时处理监控数据
数据存储层:
实时数据: Prometheus (保留7天)
历史数据: TimescaleDB (保留2年)
作业日志: Elasticsearch (全文检索)
展示层设计:
第一屏: 全院GPU概览
-
总GPU数量: 100张
-
当前利用率: 78%
-
今日总使用时长: 2,340 GPU小时
-
各科室使用分布: 放射科32%, 病理科28%, 基因组科25%, 其他15%
-
实时热点图: 显示每张GPU的实时利用率
第二屏: 异常检测与告警
-
闲置GPU告警: 连续30分钟利用率<5%
-
过载GPU告警: 连续10分钟利用率>95%
-
健康告警: ECC错误激增、温度过高
-
异常作业检测: 长时间运行但无输出的作业
第三屏: 科室级分析
-
各科室GPU使用效率对比
-
科室内部资源分配公平性
-
科室典型作业模式分析
-
资源需求预测
第四屏: 项目级洞察
-
重点项目资源使用跟踪
-
项目ROI分析: 资源投入 vs 论文产出
-
协作网络分析: 哪些团队经常共享资源
智能分析功能:
闲置资源预测:
基于历史模式预测未来闲置时段
示例输出: "今晚22:00-06:00预计有15张GPU闲置"
资源分配优化建议:
识别分配不合理的作业
示例建议: "作业A只需要8GB显存,当前占用24GB,建议调整"
成本分摊与计费:
按项目统计GPU使用量
生成资源使用账单
支持预算管理和预警
实际应用案例:
案例1: 发现隐形闲置
时间: 2023年8月某周二下午
监控发现: 有8张GPU显示正在使用,但算力利用率为0%
深入分析: 用户用GPU跑CPU任务,只为了挂机占位
采取措施: 制定规则,连续10分钟GPU算力<1%则警告并可能回收
效果: 释放了15%的隐形闲置资源
案例2: 预测资源需求
时间: 2023年国家自然基金申请季前
历史数据分析: 每年3月GPU需求增长40%
预测建议: "建议3月预留额外20张GPU资源"
实际执行: 提前调度,减少排队
效果: 申请季用户满意度提升35%
案例3: 异常检测
时间: 2023年10月12日凌晨
系统告警: 节点gpu07温度持续上升,已达88°C
值班人员: 收到微信告警,远程检查
发现问题: 机房空调局部故障
及时处理: 迁移作业,维修空调
避免损失: 防止了GPU因过热损坏(单张价值8万元)
用户反馈:
信息科主任: "以前靠用户投诉才知道资源紧张,现在能主动发现和解决"
科研处处长: "这个数据帮助我们做采购决策,知道该买什么类型的GPU"
一线研究员: "能看到排队情况,能合理规划作业提交时间"
关键指标改进:
平均GPU利用率: 从52%提升至78%
作业平均等待时间: 从4.2小时降至1.8小时
用户资源投诉: 减少67%
硬件故障提前发现率: 从30%提升至85%
写在最后:平台的价值在于赋能
回顾AI平台这一年的建设与运营,我们最大的收获不是技术指标的提升,而是医疗工作者与AI关系的变化:
从恐惧到好奇:放射科老主任从"这玩意儿靠谱吗?"到"小王,帮我看看这个模型怎么调参"
从旁观到参与:临床医生从等待IT部门提供AI工具,到自己动手训练适合本科室的专用模型
从孤岛到生态:各科室的AI应用从分散建设到在统一平台上共享、协作、演进
从科研到临床:AI模型从论文里的数字,变成实际辅助诊断的工具
我们平台上最受欢迎的功能,不是最高深的AutoML,而是那个让医生30秒启动Notebook的按钮 。最成功的案例,不是准确率最高的模型,而是急诊科医生真正用起来的肺炎辅助诊断。
技术最终要服务于人,服务于医疗。当儿科医生在查房间隙用手机查看AI分析结果时,当罕见病患儿因为快速基因分析获得正确诊断时,我们才真正感受到了这个平台的价值。
下一期,我们将深入《运维篇:当科研平台遇上7x24小时医院运营》,揭秘如何从"救火队员"转变为"自动驾驶"的运维体系,以及那个让我们连续72小时没合眼的"存储雪崩"事件是如何彻底改变我们运维哲学的。
讨论话题:在你们的AI平台建设中,最大的挑战是什么?是技术选型、用户培训、还是资源管理?有没有特别成功的医生参与案例?欢迎分享你的故事!
技术关键词:医疗AI平台,Jupyter医疗定制,可视化HPO,一键模型部署,MIG管理,国产GPU适配,GPU监控大屏,临床AI转化