在2025年QCon AI NYC大会上,OpenAI的Will Hang和Wenjie Zi共同呈现了一场关于企业级AI智能体优化的深度分享。他们重点介绍了Agent RFT(强化微调)这一创新方法,这是一种专门为工具使用型AI智能体设计的强化学习微调技术,旨在显著提升智能体在多步骤任务中的表现。
在2025年QCon AI NYC大会上,OpenAI的Will Hang和Wenjie Zi共同呈现了一场关于企业级AI智能体优化的深度分享。
他们重点介绍了Agent RFT(强化微调)这一创新方法,这是一种专门为工具使用型AI智能体设计的强化学习微调技术,旨在显著提升智能体在多步骤任务中的表现。
从提示优化到模型微调的渐进路径
Hang在演讲中强调了一个实用的改进路径:在修改模型权重之前,应该先从提示词和任务优化入手。

他列举了多个实际案例,包括简化需求描述、添加防护机制以防止工具误用、改进工具描述、优化工具输出质量等,这些措施能让AI智能体做出更好的下游决策。
虽然这些优化方法往往能带来高杠杆效应,但在需要跨工具交互进行一致多步骤推理的任务上,效果可能会遇到瓶颈。这时,就需要考虑更深层次的模型微调方案。
微调方法的选择:从监督学习到强化学习
Hang将微调选项描述为一个连续谱系:
• 监督微调(Supervised Fine-Tuning):当输入到输出存在可预测映射关系,且目标是模仿一致的风格或结构时,这种方法非常有效。
• 偏好优化(Preference Optimization):通过配对比较来调整输出,使其更接近偏好响应。OpenAI的Direct Preference Optimization指南将其描述为通过比较模型输出进行微调的方法,目前主要限于文本输入和输出。
• 强化微调(Reinforcement Fine-Tuning):更适合需要模型在较长轨迹中发现策略,而非简单复制单一演示完成模式的任务。
警惕奖励破解!解决评分器中的任何边缘情况。连续奖励比二元奖励效果更好。------ Will Hang, OpenAI
Agent RFT:为工具使用型智能体量身定制
Agent RFT是强化微调技术在工具使用型AI智能体上的专门适配。
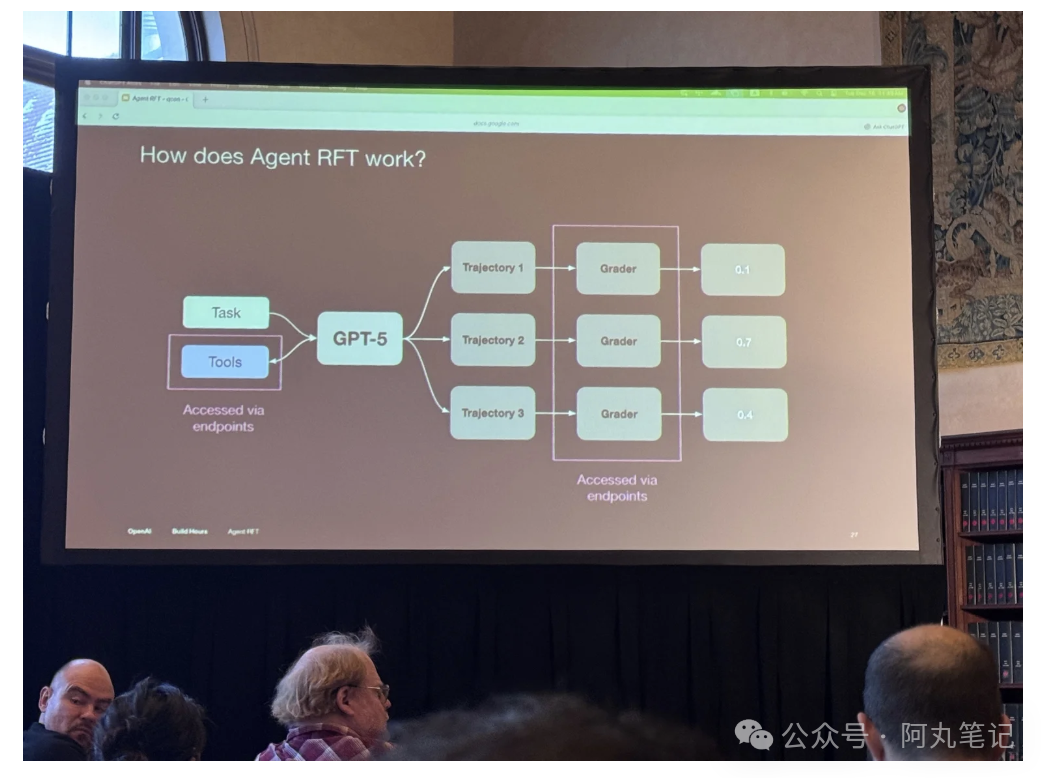
在训练过程中,模型会探索不同的策略,并从评分器(grader)获得学习信号。OpenAI的文档将这一循环描述为:采样候选响应、使用自定义评分器进行评分、基于这些分数更新模型。
Hang特别强调了跨完整轨迹的信用分配,这意味着包括工具选择和工具调用结构在内的早期决策,都可以基于下游结果得到强化或抑制。
他将AI智能体定义为一个能够通过工具与外部世界交互的系统,而不仅仅是响应用户提示。
工具生态与评分器设计
Hang描述了多种工具使用场景,包括编程智能体的终端工具、客户支持场景中的内部业务系统、文档搜索或检索端点等。
他特别强调,工具输出会流回同一个上下文窗口,因此工具调用、工具输出、推理标记和最终响应共同构成了一个单一的多步骤轨迹。
在这一工作流中,评分器成为核心组件。演讲中介绍了多种评分风格,包括简单匹配器、基于模型的判断器、基于代码的评分器、端点评分器,以及组合多种评分器来共同优化准确性和延迟。
超越准确性的运营属性优化
除了答案准确性,Agent RFT还关注那些仅靠准确率无法捕捉的运营属性。
Hang描述了使用Agent RFT来减少不必要的工具调用、强制执行工具调用预算、减少超长轨迹的长尾分布,这些都能有效降低不可预测的延迟并改善用户体验。
幻灯片展示了训练轨迹,显示推理标记和工具调用在训练过程中逐渐减少,这与智能体能够学会使用更少的步骤达到相似或更好任务结果的观点一致。
实际应用案例:金融领域的智能文档检索
Wenjie Zi在演讲的后半部分分享了具体用例和平台设置细节,包括一个面向金融领域的示例。
在这个场景中,模型必须在受限的工具调用预算下,从大型文档语料库中定位相关内容。智能体使用搜索、列表和文件读取工具(通过端点暴露),然后由评分器对最终答案进行评分。
Zi特别强调了即使对于数值答案,也使用基于模型的评分器,以减少因表面格式差异、单位或微小变化导致的假阴性结果。这种方法能够更准确地评估答案的正确性。
跨领域的应用价值
Zi还描述了在智能编程和其他领域的更广泛示例,重点关注具有多种工具、隔离执行环境和奖励设计的环境,这些设计需要平衡正确性、流程和效率。
报告的结果强调了改进的规划能力、减少的长轨迹尾部,在某些情况下还出现了向并行工具调用的转变,以减少顺序轮次。
对于希望深入了解的开发者,可以查阅OpenAI的强化微调和模型优化文档。
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量