
在 Java 应用中,PDF 解析(PDF parsing in Java)通常用于从 PDF 文件中提取可用信息,而不仅仅是将其渲染出来进行展示。常见的应用场景包括文档索引、自动化报表处理、发票分析以及数据采集与导入流程等。
与 JSON、XML 等结构化数据格式不同,PDF 的设计目标是保证视觉呈现效果的一致性。文本、表格、图像等内容在 PDF 中并不是以逻辑结构存储的,而是以带有坐标信息的绘制指令形式存在。因此,在 Java 中进行 PDF 解析,核心在于理解 PDF 内部的内容表示方式,以及 Java PDF 库是如何通过 API 将这些内容暴露出来的。
本文将基于Spire.PDF for Java,从实际开发角度出发,介绍在 Java 项目中常见的 PDF 解析操作。文章不会将 PDF 解析视为一个单一的线性流程,而是按功能划分,分别讲解文本、表格、图像和元数据的提取方式,便于在真实项目中按需组合使用。
从实现角度理解 Java 中的 PDF 解析
从实践层面来看,Java 中的 PDF 解析并不是一个单一操作,而是一组针对同一 PDF 文档执行的不同数据提取任务,具体取决于应用需要获取哪类信息。
在实际系统中,PDF 解析通常用于获取以下内容:
- 纯文本内容,用于搜索、索引或文本分析
- 结构化数据(如表格),用于后续处理或存储
- 嵌入资源(如图片),用于归档或下游处理
- 文档元数据,用于分类、审计或版本管理
PDF 解析之所以复杂,根本原因在于 PDF 的内容存储方式。与结构化文档不同,PDF 并不会显式保存段落、行或表格等逻辑结构,而是主要由以下内容组成:
- 页面级内容流
- 通过坐标定位的文本片段
- 用于构成视觉结构的图形元素(图片、线条、间距、边框等)
因此,Java 中的 PDF 解析本质上是基于页面布局信息还原内容语义的过程。这也是为什么在实际项目中,往往需要借助专业的 PDF 解析库:它既能暴露底层页面内容,又提供了文本提取、表格识别等高级功能,从而减少手写解析逻辑的复杂度。
Java 中实用的 PDF 解析思路
在生产环境中,PDF 解析更适合被设计为一组可独立调用的解析操作,而不是固定顺序的流水线。这种设计方式有助于隔离错误,也能让应用只执行真正需要的解析逻辑。
本文使用Spire.PDF for Java作为示例库。它提供了文本提取、表格解析、图像导出和元数据访问等 API,适用于后端服务、批量任务以及文档自动化系统。
安装 Spire.PDF for Java
你可以从慧都网 Spire.PDF for Java 下载页面 下载并手动引入依赖。如果项目使用 Maven,也可以通过以下配置进行安装:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.11.11</version>
</dependency>完成安装后,即可直接使用 Java 代码加载和解析 PDF 文件,无需依赖外部工具。
在 Java 中加载并验证 PDF 文档
在执行任何解析操作之前,首先需要加载并验证 PDF 文档。建议将这一步作为独立操作,用于确认文档是否可以被后续解析逻辑安全处理。
import com.spire.pdf.PdfDocument;
public class loadPDF {
public static void main(String[] args) {
// 创建 PdfDocument 实例
PdfDocument pdf = new PdfDocument();
// 加载 PDF 文件
pdf.loadFromFile("sample.pdf");
// 获取页面总数
int pageCount = pdf.getPages().getCount();
System.out.println("总页数: " + pageCount);
}
}控制台输出示例
从实现角度来看,只要能够成功加载文档并访问页面集合,就已经验证了多个关键条件:
- 文件格式受支持
- 文档结构可以正常解析
- 页面树存在且可访问
在生产系统中,这一步通常作为入口校验使用,无法加载或页面结构异常的 PDF 可以直接被拦截,避免影响后续流程,有助于在批处理或自动化场景中避免错误级联。
使用 Java 解析 PDF 页面中的文本
文本解析 是 Java 中最常见的 PDF 处理需求之一,其核心目标是从 PDF 页面中提取并重组可读文本内容。使用 Spire.PDF for Java 解析 PDF 文本时,文本解析不应简单理解为一次性 API 调用,而应通过 PdfTextExtractor 配合可配置的 PdfTextExtractOptions 来实现,以获得更稳定、可控的解析结果。
将文本解析设计为独立的处理步骤,可以在文档索引、内容分析、全文搜索或数据迁移等场景中灵活复用。
Java 中文本解析的实现流程
在典型的 Java 实现中,PDF 文本解析通常由以下几个清晰的步骤构成,每一步都能在代码中直接体现:
- 将 PDF 文件加载为 PdfDocument 实例
- 通过 PdfTextExtractOptions 配置文本解析行为
- 针对每一页创建对应的 PdfTextExtractor
- 按页面提取文本并汇总解析结果
这种基于页面的解析方式与 PDF 的底层结构高度一致,也为多页文档的处理提供了更好的控制能力。
示例:使用 Java 提取 PDF 页面中的文本
import com.spire.pdf.PdfDocument;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
public class extractPdfText {
public static void main(String[] args) {
// 创建并加载 PDF 文档
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample1.pdf");
// 使用 StringBuilder 高效累积解析结果
StringBuilder extractedText = new StringBuilder();
// 配置文本解析选项
PdfTextExtractOptions options = new PdfTextExtractOptions();
// 启用简化解析模式,提高文本可读性
options.setSimpleExtraction(true);
// 遍历 PDF 中的每一页
for (int i = 0; i < pdf.getPages().getCount(); i++) {
// 为当前页面创建文本解析器
PdfTextExtractor extractor =
new PdfTextExtractor(pdf.getPages().get(i));
// 按配置选项解析当前页面文本
String pageText = extractor.extract(options);
// 追加到结果缓冲区
extractedText.append(pageText).append("\n");
}
// 此时 extractedText 已包含完整文本内容,
// 可用于存储、索引或后续处理
System.out.println(extractedText.toString());
}
}控制台输出示例
关键类与配置说明
-
PdfTextExtractor 以页面为解析单位,对文本内容进行提取和重组,提供比全局提取更精细的控制能力。
-
PdfTextExtractOptions 用于控制文本解析行为。启用 setSimpleExtraction(true) 可在多数场景下生成更干净、更易读的文本结果,减少因布局干扰导致的断行或错序问题。
-
按页解析策略 将解析范围限定在单页,有助于处理大体量 PDF 文档,也更容易在出现异常时定位和隔离问题页面。
技术要点与实现注意事项
- PDF 中的文本并不是以段落或行结构存储的,而是由带有位置信息的字符(glyph)组合而成,因此文本解析本质上是一个基于坐标的重组过程
- 文本提取行为可以通过 PdfTextExtractOptions 进行调整,以在布局还原精度和文本可读性之间取得平衡
- 采用页面级文本提取能够显著提升容错性和灵活性,尤其适合多页或结构不完全一致的 PDF 文件
- 提取后的文本在进入搜索、分析或数据处理系统之前,通常仍需要进行额外的规范化处理,例如清理多余空白、合并断行、统一编码等
这种基于页面的文本解析方式非常适合布局相对稳定、以文字内容为主的文档,如报告、合同和说明文档;也是在 Java 中使用 Spire.PDF for Java解析 PDF 页面文本的推荐实践。
使用 Java 解析 PDF 页面中的表格
表格解析属于较为高级的 PDF 解析操作,其目标是在 PDF 页面中识别出表格结构,并将其还原为具有行和列关系的结构化数据。与纯文本解析相比,表格解析更强调单元格之间的语义关系,常用于发票、财务报表、业务统计报表等场景。
在 Java 中进行 PDF 解析时,表格解析可以将视觉上对齐的数据转换为程序可直接处理的结构化内容,便于存储、分析或导出。
Java 中表格解析的实现思路
表格解析的核心不再是简单的文本提取,而是基于页面布局和对齐关系进行结构推断:
- 将 PDF 文档加载为 PdfDocument
- 创建并绑定 PdfTableExtractor
- 从指定页面解析表格结构
- 根据解析结果还原行和列
- 对单元格数据进行校验和规范化
与文本解析不同,表格解析是通过元素的视觉对齐和布局一致性来推断结构的,从而实现对原本"散落在页面上的文本"的行列级访问。
示例:使用 Java 从 PDF 页面中解析表格
下面的示例展示了如何使用 PdfTableExtractor 从 PDF 页面中解析表格,并将其转换为按行列组织的数据结构,便于后续处理或导出。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
public class extractPdfTable {
public static void main(String[] args) {
// 载入 PDF 文档
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample1.pdf");
// 创建 PdfTableExtractor 对象
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
// 从第一页解析表格(页索引从 0 开始)
PdfTable[] tables = extractor.extractTable(0);
// 遍历表格
if (tables != null) {
for (PdfTable table : tables) {
// 获取表格的行数和列数
int rowCount = table.getRowCount();
int columnCount = table.getColumnCount();
System.out.println("Rows: " + rowCount +
", Columns: " + columnCount);
StringBuilder tableData = new StringBuilder();
for (int i = 0; i < rowCount; i++) {
for (int j = 0; j < columnCount; j++) {
// 获取单元格数据
tableData.append(table.getText(i, j));
if (j < columnCount - 1) {
tableData.append("\t");
}
}
if (i < rowCount - 1) {
tableData.append("\n");
}
}
System.out.println(tableData.toString());
}
}
}
}控制台输出示例
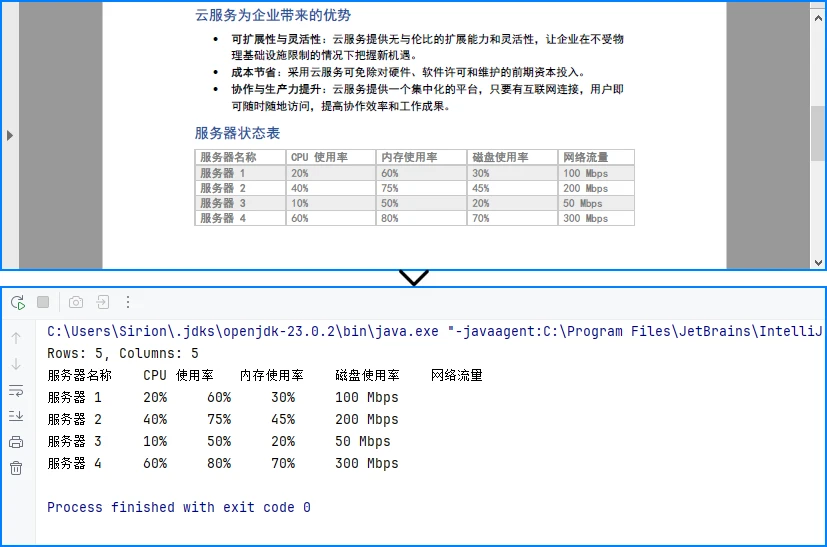
实现细节说明
-
PdfTableExtractor: 通过分析页面级内容,根据文本对齐和布局特征识别表格区域。
-
结构还原: 行和列是通过文本元素的相对位置推断得出的,可通过行列索引访问单元格内容。
-
按页解析: 每页单独解析,有助于应对不同页面布局不一致的问题。
表格解析的实际注意事项
- 表格边界来源于视觉布局,而非显式定义
- 表头行可能需要额外识别或处理逻辑
- 单元格内容在存储或导出前通常需要规范化
- 布局复杂或不规则的表格可能影响解析精度
尽管存在一定限制,表格解析依然是 Java PDF 解析中极具价值的能力之一,特别适合从结构化业务文档中自动提取数据。
使用 Java 解析 PDF 页面中的图像
图像解析是一种专门用于提取 PDF 页面中嵌入图像资源的解析能力。与文本或表格解析不同,图像解析并不依赖内容流或布局推断,而是直接分析页面资源,识别其中的图像对象。
在 Java PDF 处理系统中,图像解析常用于视觉内容归档、文档组成审计,或将图像数据传递给下游处理流程。
Java 中图像解析的工作方式
从实现角度来看,图像解析主要基于页面级资源:
- 将 PDF 文档加载为 PdfDocument
- 初始化 PdfImageHelper 工具类
- 遍历页面并获取图像资源信息
- 提取并导出每个嵌入的图像对象
由于图像作为独立资源存储,这一解析过程不依赖文本顺序、布局重建或表格识别逻辑。
示例:使用 Java 从 PDF 页面中解析图像
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfImageHelper;
import com.spire.pdf.utilities.PdfImageInfo;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class extractPdfImages {
public static void main(String[] args) throws IOException {
// 载入 PDF 文档
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample1.pdf");
// 创建 PdfImageHelper 对象
PdfImageHelper imageHelper = new PdfImageHelper();
// 遍历每一页
for (int i = 0; i < pdf.getPages().getCount(); i++) {
// 获取当前页的图片信息
PdfImageInfo[] imageInfos =
imageHelper.getImagesInfo(pdf.getPages().get(i));
if (imageInfos != null) {
for (int j = 0; j < imageInfos.length; j++) {
// 获取指定图片
BufferedImage image = imageInfos[j].getImage();
// 保存图片为 PNG 文件
File output = new File(
"output/images/page_" + i + "_image_" + j + ".png"
);
ImageIO.write(image, "PNG", output);
}
}
}
}
}提取结果示例
图像解析的关键说明
-
PdfImageHelper / PdfImageInfo: 用于分析页面资源并以 BufferedImage 形式访问嵌入图像。
-
按页处理: 即使多页文档中存在重复或复用图像,也能准确提取。
-
与布局无关: 图像解析不依赖文本流或表格结构,适用于所有视觉资源。
图像解析的实际注意事项
- 提取的图像可能包含装饰性或背景元素
- 不同 PDF 的图像分辨率、色彩空间和格式可能不同
- 大型 PDF 文档可能包含大量图像,需要合理管理内存和存储
- 图像解析通常与文本、表格和元数据解析结合使用,共同构成完整的 PDF 解析流程
使用 Java 解析 PDF 元数据
元数据解析是 PDF 解析中的基础能力之一,主要用于读取独立于页面内容之外的文档级信息。与文本或表格解析不同,元数据解析不依赖页面布局,因此在绝大多数 PDF 文件中都具有较高的稳定性。
在 Java PDF 处理系统中,元数据通常作为前置分析步骤,用于文档分类、流程路由或索引决策。
Java 中元数据解析的实现方式
元数据解析是文档级操作,其实现步骤通常如下:
- 将 PDF 加载为 PdfDocument
- 访问文档信息字典
- 读取可用的元数据字段
- 将解析结果用于分类、路由或索引逻辑
由于元数据不依赖渲染内容,这一解析过程开销小、速度快,且结果较为一致。
示例:使用 Java 解析 PDF 文档元数据
import com.spire.pdf.PdfDocument;
public class parsePdfMetadata {
public static void main(String[] args) {
// 载入 PDF 文档
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample1.pdf");
// 获取 PDF 文档元数据信息
String title = pdf.getDocumentInformation().getTitle();
String author = pdf.getDocumentInformation().getAuthor();
String subject = pdf.getDocumentInformation().getSubject();
String keywords = pdf.getDocumentInformation().getKeywords();
String creator = pdf.getDocumentInformation().getCreator();
String producer = pdf.getDocumentInformation().getProducer();
String creationDate = pdf.getDocumentInformation()
.getCreationDate().toString();
String modificationDate = pdf.getDocumentInformation()
.getModificationDate().toString();
System.out.println(
"Title: " + title +
"\nAuthor: " + author +
"\nSubject: " + subject +
"\nKeywords: " + keywords +
"\nCreator: " + creator +
"\nProducer: " + producer +
"\nCreation Date: " + creationDate +
"\nModification Date: " + modificationDate
);
}
}控制台输出示例
元数据解析的要点说明
-
文档信息字典: 元数据存储在 PDF 的独立结构中,与页面渲染内容无关。
-
字段完整性: 并非所有 PDF 都包含完整元数据,使用前应进行空值校验。
-
解析成本低: 不需要遍历页面,适合作为初始解析步骤。
元数据解析的常见用途
- 文档分类与标签管理
- 搜索索引与筛选
- 工作流路由与权限控制
- 版本管理与审计记录
由于不受布局和内容流影响,元数据解析在复杂 PDF 中通常比文本或表格解析更加稳定。
Java PDF 解析的实现注意事项
在实际项目中,往往需要在同一处理流程中组合多种 PDF 解析能力。
组合使用多种解析操作
常见的实现模式包括:
- 提取文本用于索引,同时解析表格用于结构化存储
- 利用元数据决定文档进入哪条处理流程
- 在定时任务或批处理作业中异步执行解析操作
将文本、表格、图像和元数据解析视为相互独立但可组合的模块,有助于系统的扩展性、可测试性和长期维护。
实际限制与约束
即便使用成熟的 Java PDF 解析库,仍存在一些不可避免的限制:
- 扫描版 PDF 在解析前,需要先进行 OCR 处理
- 布局高度复杂或不一致的文档会降低解析精度
- 自定义字体或编码方式可能影响文本还原效果
充分理解这些限制,有助于在生产环境中制定合理的解析策略,并降低异常处理复杂度。
总结
在 Java 中进行 PDF 解析时,将其视为一组目标明确、彼此独立的提取操作,往往比线性流程更高效、更可靠。通过分别处理文本、表格和元数据,Java 应用可以稳定地将 PDF 文档转换为可用数据。
借助Spire.PDF for Java 这样的专业库,开发者可以构建可维护、可扩展,并能满足真实业务需求的 PDF 处理解决方案。
Java PDF 解析常见问题解答
Q1:如何在 Java 中解析 PDF 页面中的文本?
A:可以使用 Spire.PDF for Java 提供的 PdfTextExtractor 与 PdfTextExtractOptions,按页面提取文本,适用于索引、分析或内容迁移场景。
Q2:如何在 Java 中提取 PDF 表格?
A:通过 PdfTableExtractor 识别表格区域并还原行列结构,解析结果可进一步处理或导出为结构化数据。
Q3:Java 可以解析 PDF 中的图片吗?
A:可以。使用 PdfImageHelper 和 PdfImageInfo 可提取页面中的嵌入图像,也可将整页 PDF 转换为图片。
Q4:如何在 Java 中读取 PDF 元数据?
A:通过 PdfDocumentInformation 获取标题、作者、创建时间等字段,该操作速度快且不依赖页面内容。
Q5:Java PDF 解析是否存在限制?
A:复杂布局、扫描版 PDF 和自定义字体都会影响解析效果。扫描文档需要先进行 OCR 处理。