目录

🎬 攻城狮7号 :个人主页
🔥 个人专栏 :《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 Meta开源SAM Audio
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
剪过视频的朋友都知道,最让人头疼的往往不是画面,而是声音。
画面拍废了还能靠滤镜救,但如果录音里混进了嘈杂的汽车鸣笛、邻居的装修声,或者是背景音乐盖过了人声,那这段素材基本就废了。传统的解决方法是找专业的音频工程师,对着复杂的波形图和频谱仪,一点点地去"修"。
但现在,Meta说:不需要那么麻烦了。
就在最近,Meta开源了一款名为 SAM Audio 的新模型。简单来说,它就是音频界的"Photoshop魔棒工具"。你不需要懂什么是频率、什么是分贝,只需要告诉AI"我要吉他声"或者在视频里点一下那把吉他,它就能把你要的声音完美地"抠"出来。

一、打破"耳听为虚":不仅能听,还能"看"
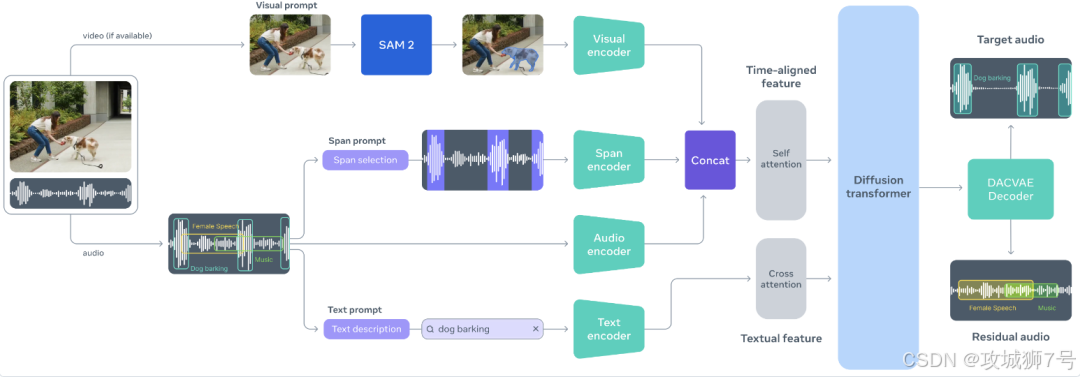
SAM Audio最大的突破,在于它彻底改变了我们和声音交互的方式。以前处理音频,我们只能靠"听"和看波形;而SAM Audio引入了多模态提示(Multimodal Prompting),让我们能用更直观的逻辑来指挥AI。

它支持三种"指挥"方式,甚至可以组合使用:
(1)像聊天一样修音(文本提示)
这是最基础的用法。你不需要在音轨上找那段噪音在哪,直接输入文字:"狗叫声"、"掌声"或者"背景里的风声"。AI会理解你的意思,然后在整段音频里把符合描述的声音全部提取出来,或者直接消除掉。
(2)指哪打哪(视觉提示)
这是最让人惊艳的功能。假设你有一段乐队演出的视频,你想单独听听鼓手的演奏。在以前,这几乎是不可能的任务,因为各种乐器的声音都混在一起。
但在SAM Audio里,你只需要在视频画面中,用鼠标点击一下那个鼓手。模型会结合视觉画面和音频信息,瞬间理解:"哦,你是要画面里这个人发出的声音",然后通过像素与声波的对齐技术,精准锁定并分离出鼓声。这就是真正的"所见即所听"。
(3)时间画框(时间跨度提示)
有些声音很难描述,画面里也找不到对应物体(比如画外音里的某种怪声)。这时,你可以直接在时间轴上画一个框,告诉AI:"就处理第10秒到第15秒这段时间里的这个声音"。这就好比在PS里用选框工具圈定了一个样本,AI学会后,能把整段音频里类似的怪声都找出来。
二、背后的功臣:给AI装上耳朵和眼睛
为什么SAM Audio能做到这一点?这得益于它背后的核心引擎------PE-AV(Perception Encoder Audiovisual)。
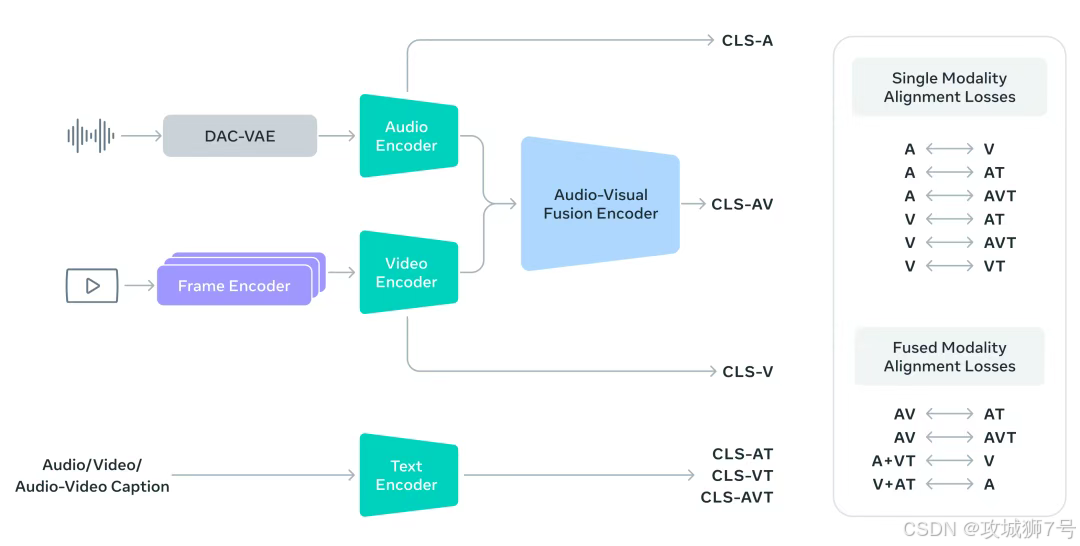

你可以把PE-AV想象成一个超级翻译官,它负责把视频画面里的像素信息,翻译成AI能听懂的音频特征。它基于Meta之前发布的Perception Encoder模型,通过在海量视频数据上进行训练,学会了"什么东西会发出什么声音"。
比如,它看到画面里有人嘴巴在动,就知道这时候应该有人声;看到琴弦震动,就知道应该有吉他声。这种像素级与声波级的深度对齐,才让"点击画面分离声音"这种科幻般的操作成为了现实。
为了验证效果,Meta还顺手发布了一个专门的评测裁判------SAM Audio Judge。这个裁判不依赖参考答案,而是像人类听众一样,从感知层面去评价分离出来的声音干不干净、自不自然。
三、从剪辑工具到未来入口
Meta费这么大劲搞这个,仅仅是为了方便大家剪Vlog吗?显然不是。SAM Audio的野心,藏在Meta对未来的布局里。
(1)拯救废片的"后悔药"
对于短视频创作者来说,SAM Audio意味着废片率的大幅降低。只要画面还在,声音的瑕疵就可以通过AI修复。那种因为"风噪太大"或"背景太吵"而不得不放弃素材的时代,将一去不复返。这将极大地降低内容创作的门槛,让普通人也能做出专业级的音频效果。
(2)AR眼镜的"听觉增强"
这才是Meta真正的杀手锏。试想一下,当你戴着Meta的Ray-Ban智能眼镜走进一个嘈杂的派对。
现在的眼镜只能录音,录下来是一片嘈杂。但未来的眼镜搭载了SAM Audio技术后,它能根据你眼睛看哪里,就增强哪里的声音。
你看向朋友,眼镜就自动提取朋友的说话声,同时屏蔽掉周围的音乐和酒杯碰撞声。这种"定向听觉"体验,才是下一代计算平台(AR/VR)该有的样子。
(3)无障碍领域的福音
Meta还宣布与助听器厂商合作。对于听力障碍人士来说,世界往往充满了无法分辨的噪音。如果有AI能帮他们分离出重要的对话声、警报声,过滤掉无意义的背景噪嘴,那将极大地改善他们的生活质量。
四、开源的勇气与挑战
与OpenAI的"闭源保护"策略不同,Meta依然坚持将SAM Audio及其代码完全开源。
这意味着全球的开发者都可以免费下载、使用甚至改进这个模型。对于行业来说,这无疑是一件好事,它会加速音频AI技术的普及。但同时,这也带来了隐忧。
**"窃听"风险:**既然AI能从嘈杂环境里精准提取某人的说话声,那是不是意味着,以前那些因为环境太吵而听不清的私密对话,现在很容易被别有用心的人"还原"出来?
Meta对此的回应比较模糊,更多是强调"技术中立"。但在AI技术狂飙突进的今天,如何防止这种强大的工具被滥用,依然是一个悬而未决的伦理难题。
结语
不管怎么说,SAM Audio的出现,标志着音频处理终于迎来了它的"Photoshop时刻"。
**它把一项原本属于专业工程师的高门槛技能,拉低到了普通人的指尖。**从SAM分割图像,到SAM 2分割视频,再到如今的SAM Audio分割声音,Meta正在一步步拼凑出那个"万物皆可AI"的未来拼图。
而对于我们普通用户来说,只需要静静等待,也许下一次更新剪辑软件时,这个神奇的"魔棒"就已经静静地躺在工具栏里了。
项目官网:https://ai.meta.com/samaudio/
Github仓库:https://github.com/facebookresearch/sam-audio