目录
- 1.树
-
- [1.1 树的概念](#1.1 树的概念)
- [1.2 树的物理结构](#1.2 树的物理结构)
- [1.3 树的实际应用------文件系统](#1.3 树的实际应用——文件系统)
- 2.二叉树
-
- [2.1 概念及性质](#2.1 概念及性质)
- [2.2 特殊的二叉树](#2.2 特殊的二叉树)
-
- [2.2.1 满二叉树](#2.2.1 满二叉树)
-
- [2.1.1.1 概念](#2.1.1.1 概念)
- [2.1.1.2 节点数量计算](#2.1.1.2 节点数量计算)
- [2.2.2 完全二叉树](#2.2.2 完全二叉树)
-
- [2.2.2.1 概念](#2.2.2.1 概念)
- [2.2.3 题目训练](#2.2.3 题目训练)
- [2.3 二叉树的应用------堆](#2.3 二叉树的应用——堆)
-
- [2.3.1 概念](#2.3.1 概念)
- [2.3.2 代码实现------创销增删改查堆排](#2.3.2 代码实现——创销增删改查堆排)
-
- [2.3.2.1 向上调整](#2.3.2.1 向上调整)
- [2.3.2.2 向下调整](#2.3.2.2 向下调整)
- [2.3.2.3 堆排序](#2.3.2.3 堆排序)
-
- [2.3.2.3.1 向下调整堆排序](#2.3.2.3.1 向下调整堆排序)
-
- [2.3.2.3.1.1 代码实现](#2.3.2.3.1.1 代码实现)
- [2.3.2.3.1.2 时间复杂度分析](#2.3.2.3.1.2 时间复杂度分析)
- [2.3.2.3.2 向上调整堆排序](#2.3.2.3.2 向上调整堆排序)
-
- [2.3.2.3.2.1 代码实现](#2.3.2.3.2.1 代码实现)
- [2.3.2.3.2.2 时间复杂度分析](#2.3.2.3.2.2 时间复杂度分析)
- [2.3.3 TOP K问题](#2.3.3 TOP K问题)
-
- [2.3.3.1 问题阐述](#2.3.3.1 问题阐述)
- [2.3.3.2 代码实现](#2.3.3.2 代码实现)
1.树
1.1 树的概念
如图所示,
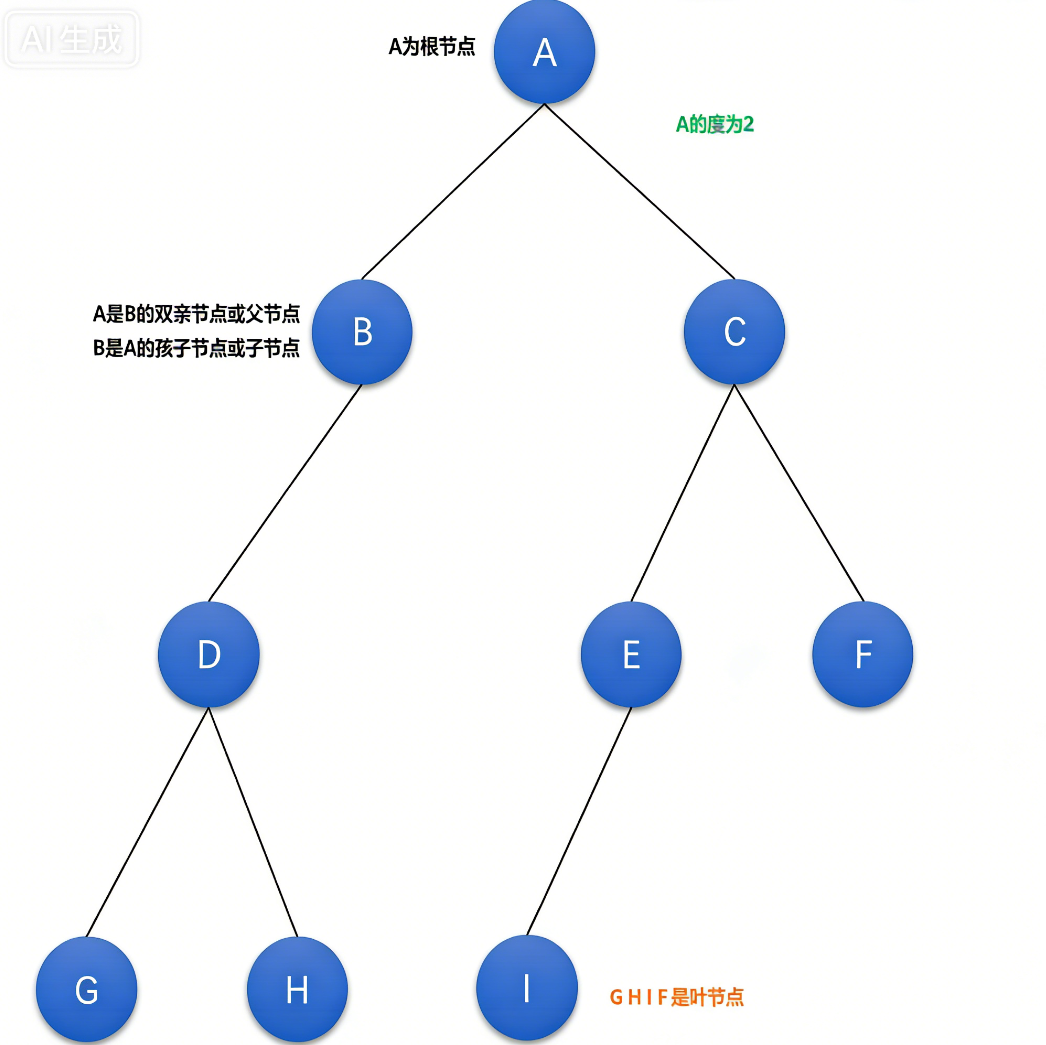
非线性 结构,其逻辑结构看起来像一颗倒挂的树,因此而得名。
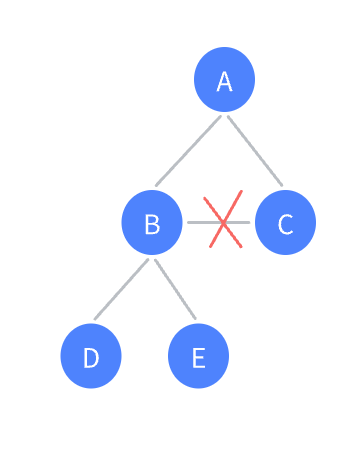
注:树形结构中,子树之间不能有交集。树是递归定义的,如果子树之间有交集,会形成死循环。
如下图,B和C如果有交集就是图。
概念
度 :一个结点含有的子树个数称为该节点的度。
树的度 :树中度最大节点的度即为该树的度
叶节点或终端节点*:度为0的节点。
以下概念借助人类亲缘关系命名,便于理解
父节点/双亲结点 *:若一节点含有子节点,则该节点称为其子节点的父节点或双亲节点。
子节点/孩子节点 *:一个节点含有的子树的根节点称为该节点的子节点/孩子节点。
兄弟节点 :具有共同父结点或双亲节点的节点//人类视角下的亲兄弟
堂兄弟节点 :位于同一高度的节点//人类视角下的堂兄弟或表兄弟,其父结点或双亲节点是堂兄弟或表兄弟
树的高度或深度*:树中节点的最大层次,最后一层节点的高度;
节点的祖先*:从根节点到该节点路径上所有节点(除该节点)都是该节点的祖先;
子孙*:位于子树中的节点都是该节点的子孙.
//加*是比较重要的概念,剩下的概念了解就够用啦~
1.2 树的物理结构
因为一个节点的子树数量是不确定的,所以用顺序结构很难实现;
左孩子右兄弟表示法:树的定义本就递归来的,延续这个思想,每个节点有两个指针,一个指针指向自己的第一棵子树,第二个指针指向自己的兄弟,依次类推;
代码如下所示,
c
typedef struct TreeNode {
struct TreeNode* child;
struct TreeNode* pnextbrother;
int data;
}TreeNode;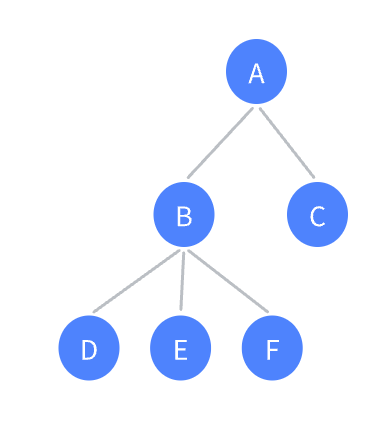
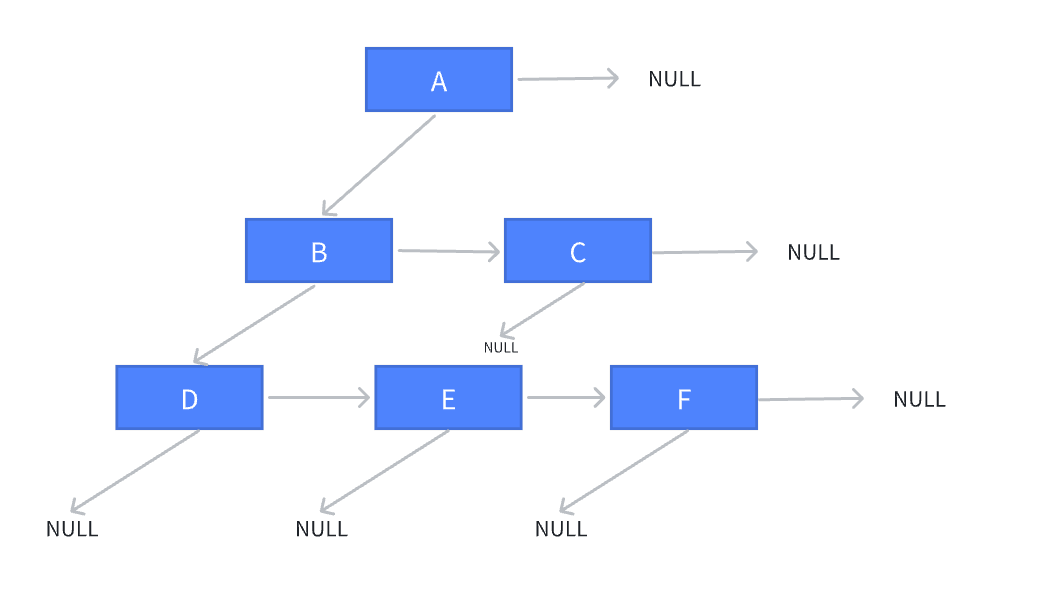
上图逻辑结构表示的树的物理结构示意图如下图所示
1.3 树的实际应用------文件系统
比如下图为WindowsC盘下的一个文件Program Files对应的结构,打开Program Files对应的就是找到Program Files对应节点的第一个孩子,之后遍历该孩子的兄弟节点,若要在该文件内部新建一个文件,就是在最后一个遍历到的兄弟节点后插入一个节点;
每个节点对应一个目录或者是文件,目录不为空,就由目录文件和文件组成,若为空,则为叶结点。


2.二叉树
2.1 概念及性质
度最大为2的树,树及树中任一结点的度可为0, 1, 2(进行了计划生育的树).
度为0的节点个数总是比度为2的节点多一个,也即N2=N0+1(高度为1的完全二叉树N0=1,N2=0,每增加一个度为1的节点,N1+=1,N0、N2保持不变;每增加一个度为2的节点就会增加一个度为0的节点,减少一个度为1的节点)。
2.2 特殊的二叉树
2.2.1 满二叉树
2.1.1.1 概念
深度为h的二叉树,前(h-1)层节点的度均为2,最后一层的节点均为叶节点。
2.1.1.2 节点数量计算
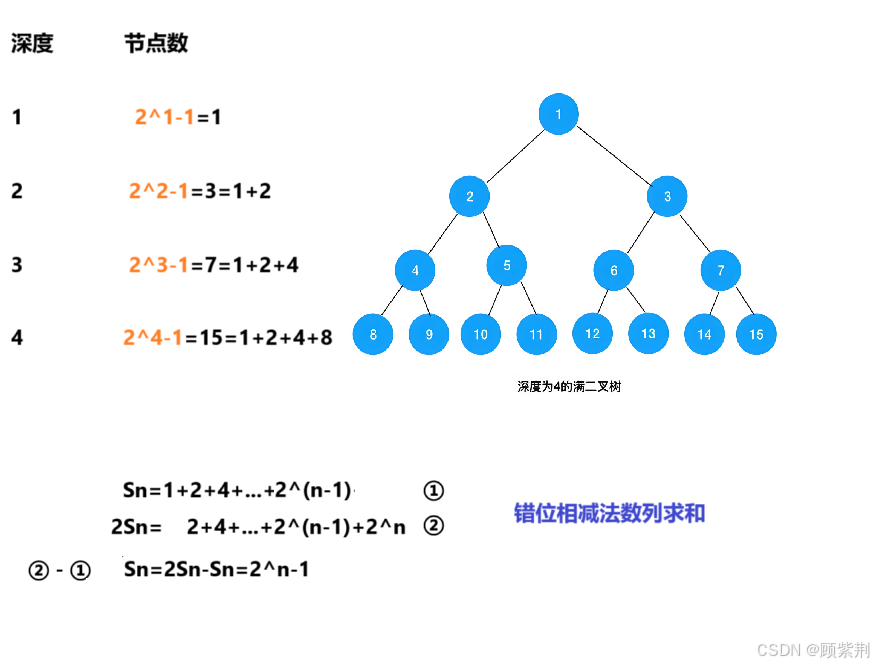
高度为h的满二叉树的节点数量
方法一:等比数列求和
Sh=2^0 +2^1 +2^2+...+ 2^(h-1)= 2^h-1 //第i层共有2^(i-1)个节点
方法二:错位相减法,推导如下图
2.2.2 完全二叉树
2.2.2.1 概念
前(h-1)层为满二叉树,最后一层从左至右节点必须是连续的;
满二叉树可以看作特殊的完全二叉树;
高度为h的完全二叉树节点数量范围推导如下图,
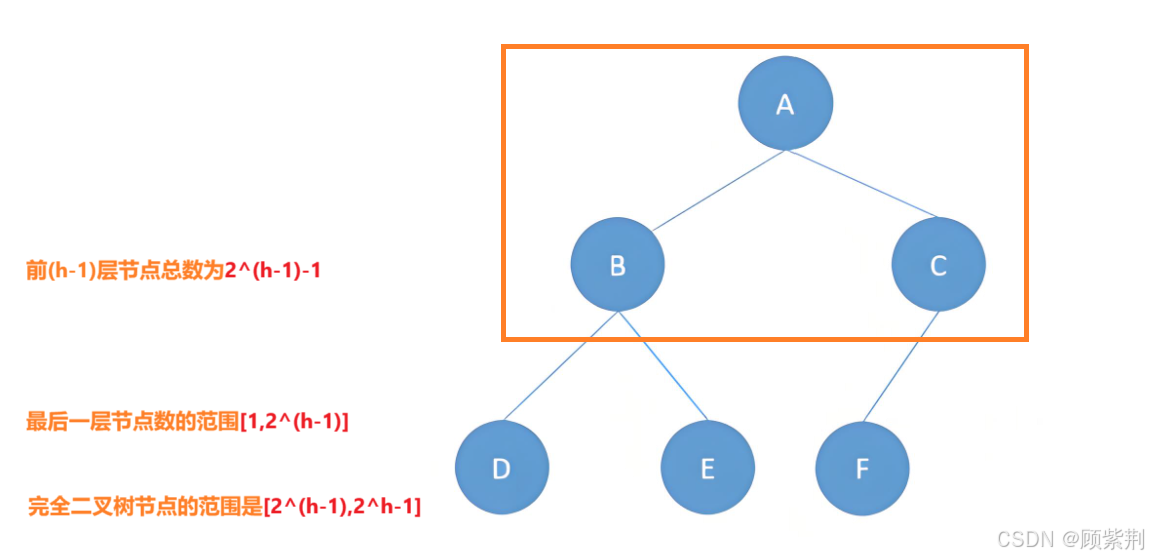
通过观察我们可以得到:度为1的节点个数为0/1,也即N1=0/1.
数组存储二叉树适用于完全二叉树,因为要利用随机访问特性,父结点和孩子节点的位置关系,父节点i,左孩子下标2i+1,右孩子下标2i+2;已知孩子下标i,父节点下标为⌊ (i-1)/2⌋,即(i-1)/2.
二叉树对应空的节点在数组中只能空着,否则没办法随机访问,因此如果数组存储的不是完全二叉树,空间大大浪费
下图所示二叉树的存储结构如下表所示


2.2.3 题目训练
-
某二叉树共有 399 个结点,其中有 199 个度为 2 的结点,则该二叉树的叶子结点数为()
A 不存在这样的二叉树
B 200
C 198
D 199
-
在具有 2n 个结点的完全二叉树中,叶子结点个数为()
A n
B n+1
C n-1
D n/2
-
一棵完全二叉树的节点数位为531个,那么这棵树的高度为()
A 11
B 10
C 8
D 12
-
一个具有767个节点的完全二叉树,其叶子节点个数为()
A 383
B 384
C 385
D 386
解析:
1.直接套公式,N0=N2+1=199+1=200,B
2.N0=N2+1,2n=N0+N1+N2=2N0-1+N1,则N1=1,N0=n,A
3.高度为h的完全二叉树节点数量范围:2\^(h-1), 2\^h-1, 2^9=512<531< 2^10-1=1023,B
4.N0=N2+1,N=N0+N1+N2=N1+2N0-1=767,则N1=0,N0=384,B
2.3 二叉树的应用------堆
2.3.1 概念
大根堆:父节点的值>=孩子节点的值
小根堆:父节点的值<=孩子节点的值
物理存储结构为数组,利用随机访问的特性
之前学习顺序表、链表等数据结构,只是单独存储数据,而堆、栈、队列等不仅存储数据,还有一定的实际应用意义,删、插入之后要保持原有性质,而且删还要删的有意义,书本上的知识最终还是要为实际应用服务的。
2.3.2 代码实现------创销增删改查堆排
Heap.h
c
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <stdbool.h>
typedef int HPDataType;
typedef struct Heap {
HPDataType* a;
int size;
int capacity;
}HP;
void Swap(HPDataType* a, HPDataType* b);
void HeapInit(HP* php);//创
void HeapDestroy(HP* php);//销
void HeapPush(HP* php, HPDataType x);//增
void HeapPop(HP* php);//删
HPDataType HeapTop(HP* php);//查
bool HeapEmpty(HP* php);//判空
void AdjustUp(HPDataType* a, int child);//向上调整
void AdjustDown(HPDataType* a, int n, int parent);//向下调整
void HeapSort(HPDataType* a, int n);//堆排序,排正序,建大堆Heap.c
c
#include "Heap.h"
void Swap(HPDataType* a, HPDataType* b) {
HPDataType tmp = *a;
*a = *b;
*b = tmp;
}
//初始化
void HeapInit(HP* php) {
assert(php);
php->a = (HPDataType*)malloc(sizeof(HPDataType) * 4);
if (php->a == NULL) {
perror("malloc fail");
return;
}
php->a = php->a;
php->size = 0;
php->capacity = 4;
}2.3.2.1 向上调整
c
void AdjustUp(HPDataType* a, int child) {
int parent = (child - 1) / 2;
while (child > 0) {//过程的魅力,这个地方直接用child>0作为判断条件而不是parent>=0,因为如果parent=0,进入循环,child=0,parent=0(i/2是向零截断),再次进入循环,虽然不会进入if直接break,但是没必要,这个效果就像下图
//不推荐把所有的条件都写进while,条件一旦多起来复杂起来,害怕控制不住
if (a[child] > a[parent]) {//除了child,前面都是堆
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
break;
}
}来自过来人的忠告,发现有问题但是使用已久特别是标注"如果你看到这个代码有问题,千万不要动",这时候千万不要动它,天下英雄如过江之卿,你会的前辈一般都会,前辈的提醒还是要听的~

c
void HeapPush(HP* php, HPDataType x) {//插入
assert(php);
if (php->size == php->capacity) {//插入先判是否满,删除先判是否空
HPDataType* tmp = (HPDataType*)realloc(php->a, sizeof(HPDataType) * php->capacity * 2);
if (tmp == NULL) {
perror("realloc fail");
return;
}
php->a = tmp;
php->capacity *= 2;
}
php->a[php->size++] = x;
AdjustUp(php->a, php->size - 1);
}
bool HeapEmpty(HP* php) {
assert(php);
return php->size == 0;
}2.3.2.2 向下调整
c
void AdjustDown(HPDataType* a, int n, int parent) {
assert(a);
int child = 2 * parent + 1;//在找链表公共节点有类似的处理方法,逻辑是如果是左孩子大是一种处理逻辑,如果是右孩子大是另一种处理逻辑,直接假设是左孩子大,之后进行判断,如果是右孩子大,child调整为右孩子.
while (child < n) {
if (child + 1 < n && a[child + 1] > a[child])//注意我们要用到child+1,就要先判断i+1是否越界;
child++;
if (a[child] > a[parent]) {
Swap(&a[parent], &a[child]);
parent = child;
child = parent * 2 + 1;//左右子树是堆,向下调整
}
else
break;
}
}
//删除
void HeapPop(HP* php) {
assert(php);
assert(!HeapEmpty(php));
Swap(&php->a[0], &php->a[--php->size]);
AdjustDown(php->a, php->size, 0);
}我们在删除元素的时候并没有采取将剩下的n-1个元素往前挪,因为这样时间复杂度是O(N),破坏了堆的性质,本来a1和a2是兄弟节点,往前挪,a1成了a2的父节点,正如那句话,a2想和a1做兄弟,结果a1想当a2的爹

儿子不是儿子,爹不是爹,兄弟不是兄弟~
但是a1和a2的大小关系是未知的,以此类推,剩下节点原有父子关系被打乱,父子关系代表元素大小关系,大小关系不确定,所以要重新建堆,代价太大。
给我们的启示,在解决问题时,要想方设法运用已有优势,尽量不要破坏已有优势,那样问题变复杂,更不好解决,条条大路通罗马,多思考,多分析,选对方向也很重要
c
HPDataType HeapTop(HP* php) {//获取堆顶元素
assert(php);
return php->a[0];
}
void HeapDestroy(HP* php) {//销毁
assert(php);
free(php->a);
php->a = NULL;
php->size = php->capacity=0;
}2.3.2.3 堆排序
我们在排正序的时候建的是大根堆,为什么不是小根堆?
因为如果建小根堆,最小的元素在a0位置,因为a0不能动了呀,那剩下的元素要看成一个小根堆找a中次小的元素,这样要重新建堆,时间复杂度是O(NlogN),效率低下,你要这样做还不如直接遍历求最值,复杂度是O(N);
而如果建大根堆,将堆顶元素和最后一个元素交换,将前n-1个元素看作大根堆,将a0向下浮,依次类推,每次向下调整的时间复杂度是O(logN). 关键是我把堆顶元素拿了,我才能找新的堆顶------次大元素,而上面的方法拿不了,除非再开一个数组,空间复杂度O(N),没必要,有更好的方法,为什么要在一棵树上吊死呢? 关键在于,把a0和an-1互换之后,不影响除a[0]之外其他元素依然保持堆的性质,这是关键;而上面的方法破坏了堆的性质,建堆不易,且行且珍惜。

下面堆排,直接将a看作完全二叉树,调整为堆,没有将a放到堆里面进行堆排,因为堆要开辟空间,空间复杂度是O(N),而且我将数据放到堆里,再拷回来,时间复杂度是O(N),我这样做一样的效果,省时省空间,何乐而不为呢?
2.3.2.3.1 向下调整堆排序
2.3.2.3.1.1 代码实现
c
//向下调整建堆
void HeapSort1(HPDataType* a, int n) {
int i;
for(i=(n-1-1)/2;i>=0;i--) {
AdjustDown(a, n, i);//排正序建的是大堆
}
i = n - 1;
while (i > 0) {
Swap(&a[0], &a[i]);
AdjustDown(a, i--, 0);
}
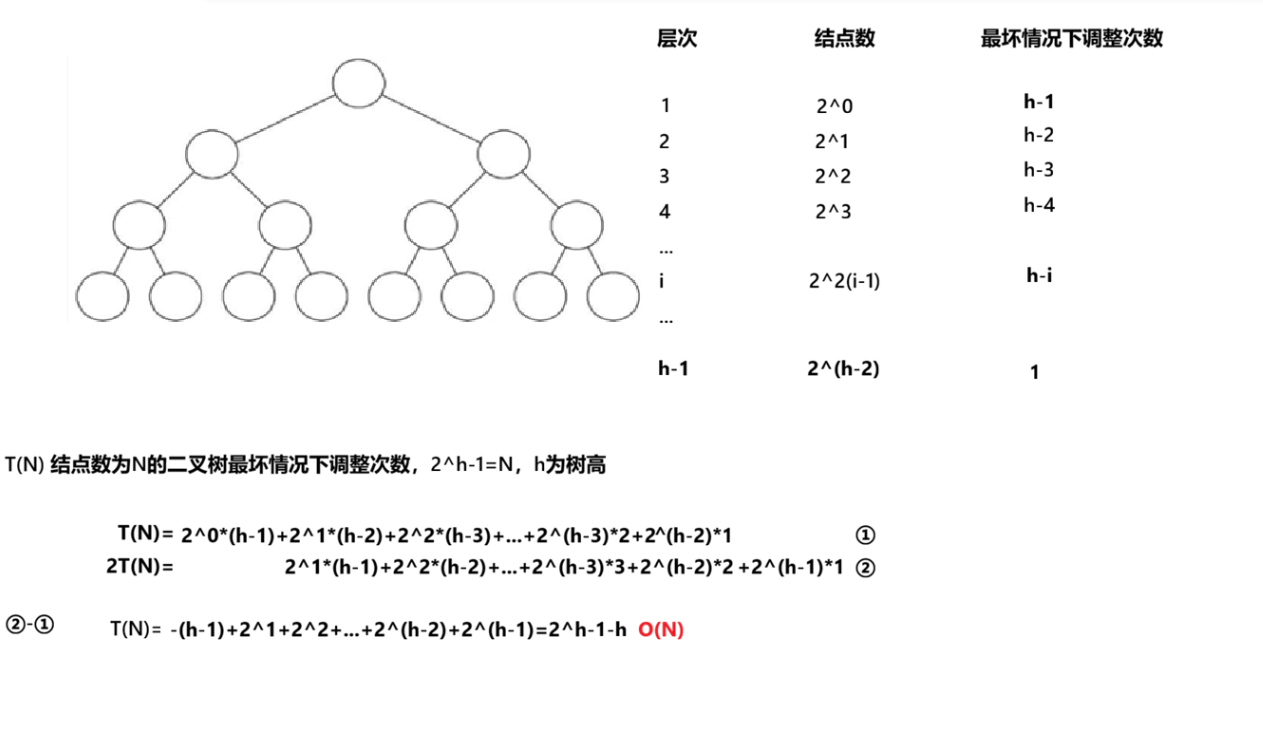
}2.3.2.3.1.2 时间复杂度分析
2.3.2.3.2 向上调整堆排序
2.3.2.3.2.1 代码实现
c
//向上调整建堆
void HeapSort2(HPDataType* a, int n) {
int i;
for (i = 1; i < n; i++)
AdjustUp(a, i);//将a[0]~a[i-1]看作堆,将a[i]向上调整,模拟插入建堆
i = n - 1;
while (i > 0) {
Swap(&a[0], &a[i]);
AdjustDown(a, i--, 0);
}//和HeapPop的处理雷同,这个不删除元素
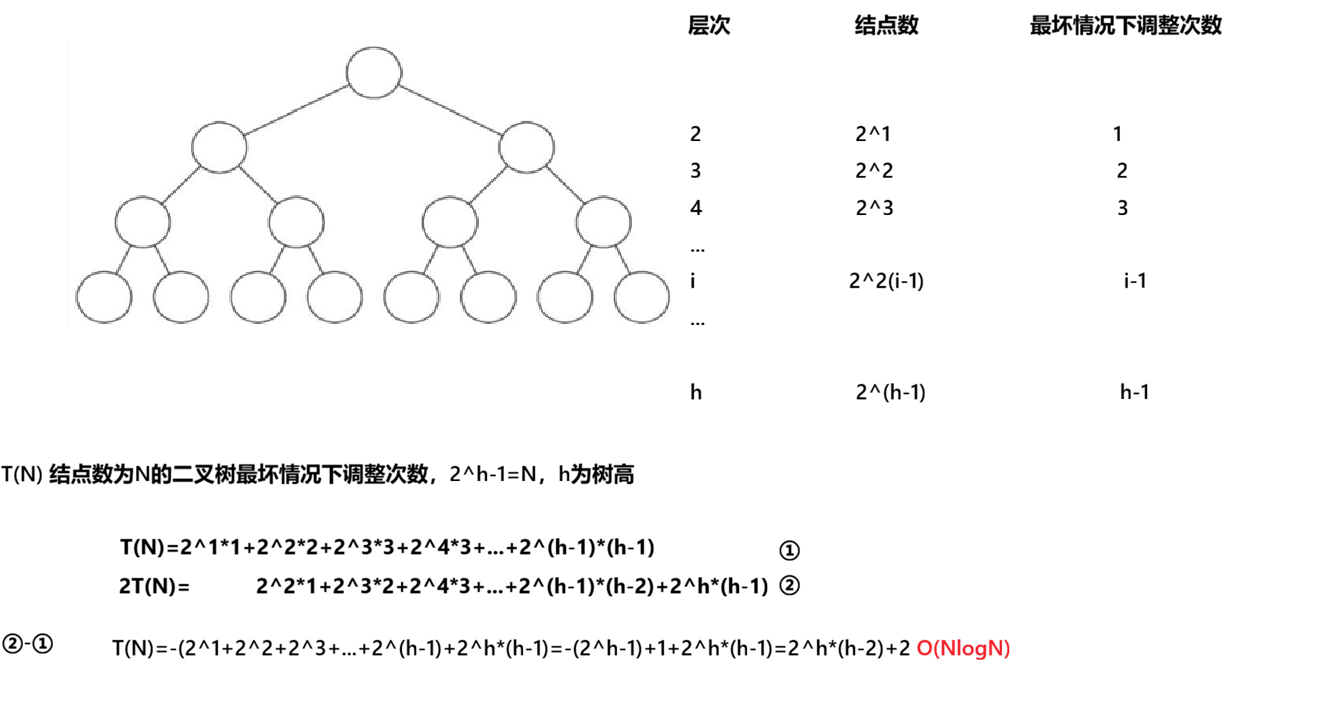
}2.3.2.3.2.2 时间复杂度分析
向上调整时间复杂度:
2.3.3 TOP K问题
2.3.3.1 问题阐述
2022年408真题

解决办法一:将这N个数建立一个大根堆,读堆顶元素,POP堆顶元素,进行K次,这样一方面堆事顺序存储,如果N很大,内存放不下,比如n=100亿=10^10,100亿个整数大概是40亿GB,这时候要放磁盘,调堆要用指针,不现实;
解决办法二:将N个数据的前K个建小根堆,TOP K问题和堆排序好像和我们惯性思维不一样,TOP K求最大的十个数,建立的是小根堆,遍历剩下的元素,如果剩下的元素小于等于堆顶元素,肯定不是最大的十个数,遍历下一个;如果剩下的元素大于堆顶元素,topk0=val,并且让堆顶元素"往下坠",循环往复遍历剩下的n-k个元素,最后得到的是最大的十个数;
那如果是大根堆行不行呢,我们假设最大的数出现在前k个,那剩下的n-k个就进不了堆,不知道刚开始的k个数是不是最大的十个数,所以不行嘞~
2.3.3.2 代码实现
建立人工测试数据集
c
void CreateNData(int n) {//生成n个0~n的随机数,计算机做这种重复的事最擅长了
int x;
srand(time(0));
const char* file = "data.txt";
FILE* fin = fopen(file, "w");
if (fin == NULL) {
perror("fopen error");
return;
}
for (int i = 0; i < n; i++) {
x = rand() % n;
fprintf(fin, "%d\n", x);//一个整型写一行
}
fclose(fin);
}注:fprintf写文件,能看,能打开;读写有两种情况,二进制和文本,fwrite以4B为单位写内存,把这4B按二进制写入文件,人类视角直接读文件是乱码,但能通过函数读,写文件;fputs写的是字符串;fprintf是文件系列最好用接口之一,fscanf, printf, scanf都比较好用,prinf写到显示台.
c
//求最大的十个数,建小堆
void PrintTopK(const char* file, int k) {
int i, val, ret, * topk = (int*)malloc(sizeof(int) * k);
assert(topk);
FILE* fout = fopen(file, "r");
if (fout == NULL) {
perror("fopen error");
return;
}
for (i = 0; i < k; i++) {
fscanf(fout, "%d", &topk[i]);
}
for (i = (k - 1 - 1) / 2; i >= 0; i--)
AdjustDown(topk, k, i);//建小堆
ret = fscanf(fout, "%d", &val);
while (ret != EOF) {
if (val > topk[0]) {
topk[0] = val;
AdjustDown(topk, k, 0);
}
ret = fscanf(fout, "%d", &val);//fscanf, scanf读数据,默认换行、空格是分割符
}
for (i = 0; i < k; i++)
printf("%d ", topk[i]);
printf("\n");
free(topk);
fclose(fout);
}最后,大家写代码遇到问题要调试鸭,调试本身不会告诉你问题,但可以帮助你发现问题;我们对于代码运行结果有一个预期,监视窗口会出一个结果,如果跟预期符不符合,观察结果、查代码,从而提高效率、能力,一定要学会调试,多画图,多练习~
