
目录
[一、进程等待:父进程的 "责任与担当"](#一、进程等待:父进程的 “责任与担当”)
[1.1 进程等待必要性:不做 "甩手掌柜",规避系统风险](#1.1 进程等待必要性:不做 “甩手掌柜”,规避系统风险)
[1.1.1 僵尸进程的 "危害演示"](#1.1.1 僵尸进程的 “危害演示”)
[1.1.2 进程等待的三大核心作用](#1.1.2 进程等待的三大核心作用)
[1.2 进程等待的方法:wait 与 waitpid 的 "双雄记"](#1.2 进程等待的方法:wait 与 waitpid 的 “双雄记”)
[1.2.1 wait 函数:简单直接的 "阻塞等待"](#1.2.1 wait 函数:简单直接的 “阻塞等待”)
[实战:wait 函数基本用法(wait_basic.c)](#实战:wait 函数基本用法(wait_basic.c))
[1.2.2 waitpid 函数:功能强大的 "灵活等待"](#1.2.2 waitpid 函数:功能强大的 “灵活等待”)
[实战 1:指定子进程的阻塞等待(waitpid_specify.c)](#实战 1:指定子进程的阻塞等待(waitpid_specify.c))
[实战 2:非阻塞等待(waitpid_nonblock.c)](#实战 2:非阻塞等待(waitpid_nonblock.c))
[1.3 解析子进程退出状态:status 参数的 "位图密码"](#1.3 解析子进程退出状态:status 参数的 “位图密码”)
[1.4 阻塞等待与非阻塞等待的适用场景](#1.4 阻塞等待与非阻塞等待的适用场景)
[二、进程程序替换:子进程的 "改头换面"](#二、进程程序替换:子进程的 “改头换面”)
[2.1 程序替换原理:"换核不换壳"](#2.1 程序替换原理:“换核不换壳”)
[生动类比:进程程序替换就像 "演员换剧本"](#生动类比:进程程序替换就像 “演员换剧本”)
[2.2 exec 函数族:程序替换的 "六大金刚"](#2.2 exec 函数族:程序替换的 “六大金刚”)
[2.2.1 函数原型与头文件](#2.2.1 函数原型与头文件)
[2.2.2 函数命名规律:轻松记准六大函数](#2.2.2 函数命名规律:轻松记准六大函数)
[2.2.3 函数返回值说明](#2.2.3 函数返回值说明)
[2.2.4 六大函数用法实战](#2.2.4 六大函数用法实战)
[1. execl 函数:列表形式 + 完整路径](#1. execl 函数:列表形式 + 完整路径)
[2. execlp 函数:列表形式 + PATH 查找](#2. execlp 函数:列表形式 + PATH 查找)
[3. execle 函数:列表形式 + 自定义环境变量](#3. execle 函数:列表形式 + 自定义环境变量)
[4. execv 函数:数组形式 + 完整路径](#4. execv 函数:数组形式 + 完整路径)
[5. execvp 函数:数组形式 + PATH 查找](#5. execvp 函数:数组形式 + PATH 查找)
[6. execve 函数:数组形式 + 自定义环境变量(系统调用)](#6. execve 函数:数组形式 + 自定义环境变量(系统调用))
[2.2.5 程序替换失败的常见原因](#2.2.5 程序替换失败的常见原因)
[2.3 程序替换与 fork 的经典组合:shell 的核心工作原理](#2.3 程序替换与 fork 的经典组合:shell 的核心工作原理)
[实战:实现一个简易 shell(mini_shell.c)](#实战:实现一个简易 shell(mini_shell.c))
前言
在 Linux 进程的生命周期中,创建(fork)与终止(exit/_exit)只是 "开场" 和 "落幕",而进程等待与程序替换则是连接两者的核心 "剧情"。试想:子进程完成任务后悄然离场,父进程若视而不见,会引发怎样的系统隐患?子进程继承父进程代码后,如何 "改头换面" 执行全新程序?这两个问题,正是进程等待与程序替换要解决的核心命题。
本文将承接进程创建与终止的基础,深入拆解进程等待的必要性与实现方法,详解程序替换的底层原理与函数用法带你打通 Linux 进程控制的 "任督二脉",真正理解进程从 "分身" 到 "协作"、从 "继承" 到 "重生" 的完整逻辑。下面就让我们正式开始吧!
一、进程等待:父进程的 "责任与担当"
1.1 进程等待必要性:不做 "甩手掌柜",规避系统风险
当子进程执行完任务终止后,内核并不会立即释放其所有资源(如 PCB、退出状态等),而是将其标记为**"僵尸进程(Zombie)"**,等待父进程 "认领"。如果父进程对此不管不顾,僵尸进程就会一直占用系统资源,久而久之导致内存泄漏;更严重的是,僵尸进程无法被 kill -9 强制删除,如同 "幽灵" 般难以清除。
除此之外,父进程还需要通过等待机制获取子进程的执行结果:子进程是正常完成任务,还是中途异常终止?执行结果是否符合预期?这些信息都需要通过进程等待来回收。
1.1.1 僵尸进程的 "危害演示"
为了让大家直观感受僵尸进程,我们通过代码模拟一个父进程不等待子进程的场景(zombie_demo.c):
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
pid_t pid = fork();
if (pid == -1)
{
perror("fork failed");
exit(1);
}
else if (pid == 0)
{
// 子进程执行完立即退出
printf("子进程(PID:%d)执行完毕,退出\n", getpid());
exit(0);
}
else
{
// 父进程无限循环,不等待子进程
printf("父进程(PID:%d)不等待子进程,持续运行...\n", getpid());
while (1)
{
sleep(1);
}
}
return 0;
}编译执行:
bash
gcc zombie_demo.c -o zombie_demo
./zombie_demo此时打开另一个终端,使用 ps命令查看僵尸进程:
ps aux | grep defunct执行结果如下:
root 45200 0.0 0.0 0 0 pts/0 Z+ 16:20 0:00 [zombie_demo] <defunct>其中**
1.1.2 进程等待的三大核心作用
- 回收子进程资源:清除僵尸进程,释放其占用的 PCB、PID 等系统资源,避免内存泄漏;
- 获取子进程退出状态:得知子进程是正常退出(返回退出码)还是异常终止(被信号杀死);
- 实现父子进程同步:父进程可以通过等待控制执行节奏,确保子进程完成任务后再继续运行。
1.2 进程等待的方法:wait 与 waitpid 的 "双雄记"
Linux 提供了 wait和 waitpid两个核心函数来实现进程等待,前者是简单的阻塞等待,后者功能更强大,支持指定等待对象、非阻塞等待等高级特性。
1.2.1 wait 函数:简单直接的 "阻塞等待"
wait 函数是进程等待的基础接口,其头文件和函数原型如下:
cpp
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);函数参数与返回值
- 参数 status:输出型参数,用于存储子进程的退出状态。若不关心子进程退出状态,可设为 NULL;
- 返回值:成功返回被等待子进程的 PID;失败返回 - 1(如没有子进程可等待)。
核心特性:阻塞等待
当父进程调用 wait后,会立即进入阻塞状态,暂停执行,直到有子进程终止。此时内核会唤醒父进程,让其回收子进程资源并获取退出状态。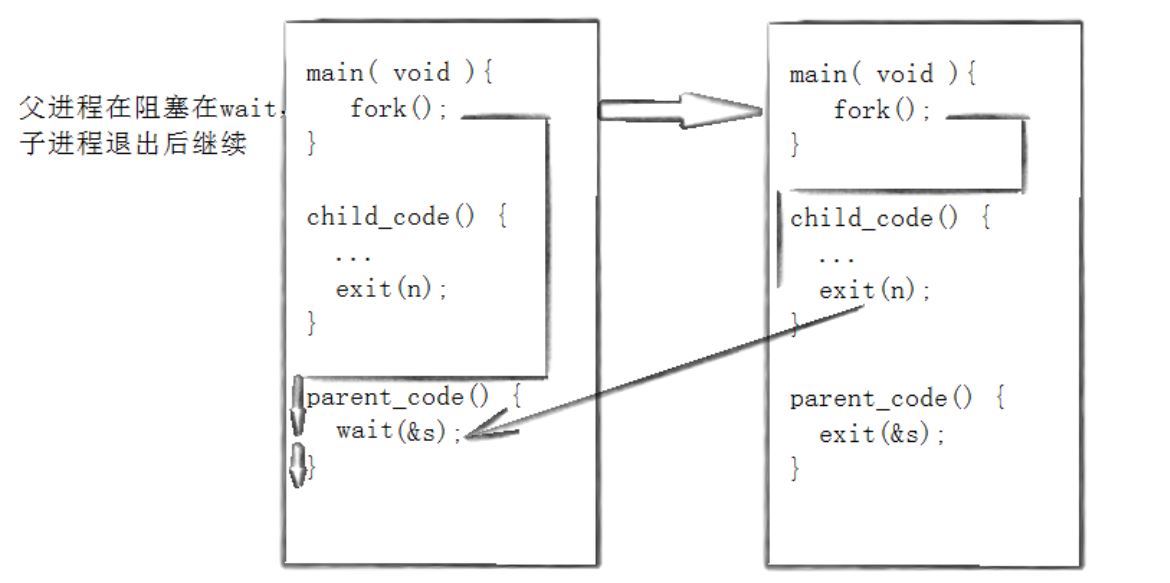
实战:wait 函数基本用法(wait_basic.c)
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
int main(void)
{
pid_t pid = fork();
if (pid == -1)
{
perror("fork failed");
exit(1);
}
else if (pid == 0)
{
// 子进程模拟执行任务(睡眠3秒)
printf("子进程(PID:%d)开始执行任务...\n", getpid());
sleep(3);
printf("子进程执行完毕,退出码:10\n");
exit(10); // 正常退出,退出码10
}
else
{
int status;
pid_t ret = wait(&status); // 阻塞等待子进程退出
if (ret == -1)
{
perror("wait failed");
exit(1);
}
printf("父进程(PID:%d)等待成功,回收子进程PID:%d\n", getpid(), ret);
}
return 0;
}编译执行:
bash
gcc wait_basic.c -o wait_basic
./wait_basic执行结果:
子进程(PID:45205)开始执行任务...
子进程执行完毕,退出码:10
父进程(PID:45204)等待成功,回收子进程PID:45205从结果可以看到,父进程调用 wait后阻塞,直到子进程执行完 3 秒任务并退出,才继续执行后续代码,成功回收子进程资源。
1.2.2 waitpid 函数:功能强大的 "灵活等待"
waitpid函数是 wait函数的增强版,支持指定等待的子进程、设置等待方式(阻塞 / 非阻塞),其函数原型如下:
cpp
pid_t waitpid(pid_t pid, int *status, int options);函数参数详解
pid 参数:指定等待的子进程 PID,支持三种取值:
- pid = -1:等待任意一个子进程(与 wait 功能等效);
- pid > 0:等待 PID 等于该值的特定子进程;
- pid = 0:等待与父进程同属一个进程组的所有子进程。
status 参数:与 wait 函数的 status 参数一致,用于存储子进程退出状态,为输出型参数。
options 参数:设置等待方式,常用取值:
0:默认值,阻塞等待(与 wait 行为一致);WNOHANG:非阻塞等待。若指定的子进程未退出,waitpid 立即返回 0,不阻塞父进程;若子进程已退出,返回子进程 PID;若出错,返回 - 1。
返回值说明
- 成功回收子进程:返回被回收子进程的 PID;
- 非阻塞等待时子进程未退出:返回 0;
- 出错(如无指定子进程):返回 - 1,errno 会被设置为对应错误码。
实战 1:指定子进程的阻塞等待(waitpid_specify.c)
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
int main(void)
{
// 创建两个子进程
pid_t pid1 = fork();
pid_t pid2 = fork();
if (pid1 == -1 || pid2 == -1)
{
perror("fork failed");
exit(1);
}
else if (pid1 == 0)
{
// 第一个子进程(PID:pid1),睡眠2秒后退出
printf("子进程1(PID:%d)执行任务,睡眠2秒...\n", getpid());
sleep(2);
exit(2);
}
else if (pid2 == 0)
{
// 第二个子进程(PID:pid2),睡眠4秒后退出
printf("子进程2(PID:%d)执行任务,睡眠4秒...\n", getpid());
sleep(4);
exit(4);
}
else
{
int status1, status2;
// 先等待子进程1(指定PID为pid1)
pid_t ret1 = waitpid(pid1, &status1, 0);
printf("父进程回收子进程1,PID:%d,退出码:%d\n", ret1, WEXITSTATUS(status1));
// 再等待子进程2(指定PID为pid2)
pid_t ret2 = waitpid(pid2, &status2, 0);
printf("父进程回收子进程2,PID:%d,退出码:%d\n", ret2, WEXITSTATUS(status2));
}
return 0;
}编译执行:
bash
gcc waitpid_specify.c -o waitpid_specify
./waitpid_specify执行结果:
子进程1(PID:45210)执行任务,睡眠2秒...
子进程2(PID:45211)执行任务,睡眠4秒...
父进程回收子进程1,PID:45210,退出码:2
父进程回收子进程2,PID:45211,退出码:4可以看到,父进程按照指定的 PID 顺序等待子进程,先回收睡眠 2 秒的子进程 1,再回收睡眠 4 秒的子进程 2,实现了精准的子进程回收。
实战 2:非阻塞等待(waitpid_nonblock.c)
非阻塞等待的核心优势是:父进程在等待子进程的同时,可以执行其他任务,提高 CPU 利用率。例如,父进程在等待子进程处理任务时,可同时处理日志、响应其他请求等。
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
// 父进程在等待期间执行的临时任务
void do_other_task()
{
static int count = 0;
printf("父进程执行临时任务,已执行%d次\n", ++count);
sleep(1); // 模拟任务耗时
}
int main(void)
{
pid_t pid = fork();
if (pid == -1)
{
perror("fork failed");
exit(1);
}
else if (pid == 0)
{
// 子进程模拟耗时任务(睡眠5秒)
printf("子进程(PID:%d)开始执行耗时任务,预计5秒...\n", getpid());
sleep(5);
printf("子进程执行完毕,退出码:5\n");
exit(5);
}
else
{
int status;
pid_t ret;
// 非阻塞等待:循环检查子进程是否退出
while (1)
{
ret = waitpid(pid, &status, WNOHANG); // 非阻塞模式
if (ret == 0)
{
// 子进程未退出,父进程执行其他任务
do_other_task();
continue;
}
else if (ret == pid)
{
// 子进程已退出,回收成功
printf("父进程回收子进程PID:%d,退出码:%d\n", ret, WEXITSTATUS(status));
break;
}
else
{
// 等待出错
perror("waitpid failed");
exit(1);
}
}
}
return 0;
}编译执行:
bash
gcc waitpid_nonblock.c -o waitpid_nonblock
./waitpid_nonblock执行结果:
子进程(PID:45215)开始执行耗时任务,预计5秒...
父进程执行临时任务,已执行1次
父进程执行临时任务,已执行2次
父进程执行临时任务,已执行3次
父进程执行临时任务,已执行4次
父进程执行临时任务,已执行5次
子进程执行完毕,退出码:5
父进程回收子进程PID:45215,退出码:5从结果可以看到,父进程在等待子进程的 5 秒内,并未阻塞,而是循环执行临时任务,直到子进程退出后才停止,充分利用了 CPU 资源。
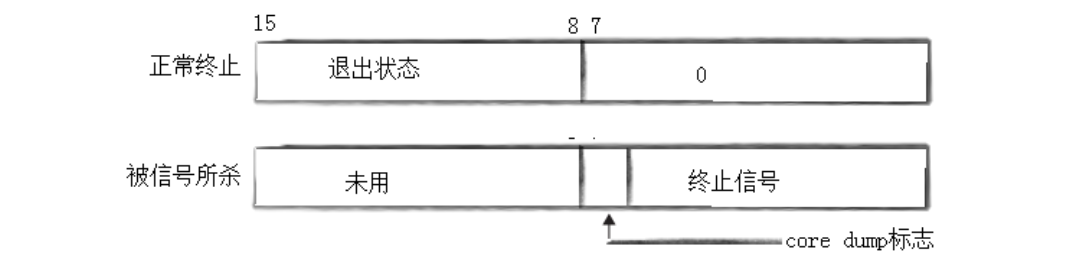
1.3 解析子进程退出状态:status 参数的 "位图密码"
wait 和 waitpid 的 status 参数并非普通整数,而是一个 16 位的位图(低 16 位有效),用于存储子进程的退出状态信息,其结构如下:
| 位范围(低 16 位) | 含义 | 说明 |
|---|---|---|
| 0-6 位 | 终止信号编号 | 若子进程被信号杀死,该字段存储信号编号;若正常退出,该字段为 0 |
| 7 位 | core dump 标志 | 若为 1,表示子进程终止时产生了 core 文件(用于调试) |
| 8-15 位 | 退出码 | 子进程正常退出时,该字段存储退出码(如 exit (n) 中的 n) |
为了方便解析 status 参数,Linux 提供了一组宏定义,无需手动操作位图:
WIFEXITED(status):判断子进程是否正常退出。若为真,说明子进程通过 return、exit 或_exit 退出;WEXITSTATUS(status):若 WIFEXITED 为真,提取子进程的退出码;WIFSIGNALED(status):判断子进程是否被信号杀死。若为真,说明子进程因收到致命信号而终止;WTERMSIG(status):若 WIFSIGNALED 为真,提取终止子进程的信号编号;WCOREDUMP(status):判断子进程终止时是否产生了 core 文件。
实战:解析子进程退出状态(status_parse.c)
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <signal.h>
int main(void)
{
pid_t pid = fork();
if (pid == -1)
{
perror("fork failed");
exit(1);
}
else if (pid == 0)
{
// 子进程模拟两种退出场景:注释掉其中一种进行测试
// 场景1:正常退出,退出码3
// printf("子进程正常退出,退出码:3\n");
// exit(3);
// 场景2:触发除零错误,被SIGFPE信号(编号8)杀死
printf("子进程触发除零错误,即将被信号终止...\n");
int a = 10 / 0;
exit(0); // 不会执行
}
else
{
int status;
pid_t ret = waitpid(pid, &status, 0);
if (ret == -1)
{
perror("waitpid failed");
exit(1);
}
// 解析退出状态
if (WIFEXITED(status))
{
// 正常退出
printf("子进程(PID:%d)正常退出,退出码:%d\n", ret, WEXITSTATUS(status));
}
else if (WIFSIGNALED(status))
{
// 被信号杀死
printf("子进程(PID:%d)被信号终止,信号编号:%d,信号名称:%s\n",
ret, WTERMSIG(status), strsignal(WTERMSIG(status)));
// 检查是否产生core文件
if (WCOREDUMP(status))
{
printf("子进程终止时产生了core文件\n");
}
}
}
return 0;
}编译执行(测试场景 2):
bash
gcc status_parse.c -o status_parse
./status_parse执行结果:
子进程触发除零错误,即将被信号终止...
子进程(PID:45220)被信号终止,信号编号:8,信号名称:Floating point exception
子进程终止时产生了core文件若测试场景 1(正常退出),执行结果如下:
子进程正常退出,退出码:3
子进程(PID:45221)正常退出,退出码:3通过这些宏定义,我们可以轻松解析子进程的退出状态,判断其是正常完成任务还是异常终止,为后续处理提供依据。
1.4 阻塞等待与非阻塞等待的适用场景
- 阻塞等待:适用于父进程无需执行其他任务,仅需等待子进程完成的场景(如简单的命令执行、单一任务处理)。优点是逻辑简单,无需循环检查;缺点是父进程会暂停执行,CPU 利用率较低。
- 非阻塞等待:适用于父进程需要并发处理多个任务的场景(如服务器同时处理多个客户端请求、后台程序同时执行多个子任务)。优点是父进程可充分利用 CPU 资源,执行其他任务;缺点是需要循环检查子进程状态,逻辑稍复杂。
二、进程程序替换:子进程的 "改头换面"
通过 fork创建的子进程,会继承父进程的代码段、数据段、堆和栈,本质上执行的是与父进程相同的程序(只是可能执行不同的代码分支)。但在实际开发中,我们常常需要子进程执行一个全新的程序(如 shell 中执行 ls、ps 命令),这就需要通过进程程序替换来实现。
2.1 程序替换原理:"换核不换壳"
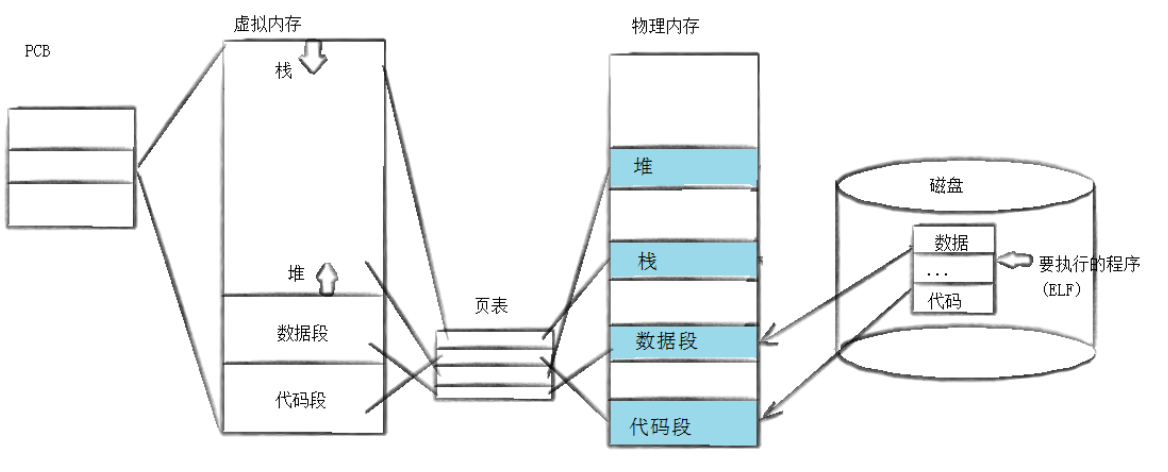
进程程序替换的核心原理是:用磁盘上的一个全新程序(代码和数据),覆盖当前进程的用户空间代码段、数据段、堆和栈,然后从新程序的启动例程开始执行。
需要注意的是:
- 程序替换不会创建新进程,进程的 PID、PCB 等内核数据结构保持不变,只是进程的用户空间内容被完全替换;
- 若替换成功,新程序会从 main 函数开始执行,原进程的代码段、数据段等被彻底覆盖,替换函数之后的代码不会执行;
- 若替换失败,函数会返回 - 1,原进程的代码和数据保持不变。
程序替换的底层流程
- 父进程 fork创建子进程,子进程继承父进程的用户空间内容;
- 子进程调用 exec系列函数,请求替换程序;
- 内核根据 exec函数指定的路径或文件名,找到磁盘上的可执行文件(ELF 格式);
- 内核加载可执行文件的代码段、数据段到子进程的用户空间,覆盖原有的内容;
- 内核设置子进程的程序计数器(PC),指向新程序的启动地址(通常是 main 函数的入口);
- 子进程开始执行新程序,原有的代码和数据不再被访问。
生动类比:进程程序替换就像 "演员换剧本"
一个进程就像一个演员,fork创建子进程相当于 "克隆" 了一个演员,两者初始时拿到的是相同的剧本(父进程的代码);而程序替换相当于给克隆的演员换了一本全新的剧本(新程序的代码),演员会按照新剧本从头开始表演,原来的剧本就被丢弃了,但演员本身(进程 PID、身份)没有变化。
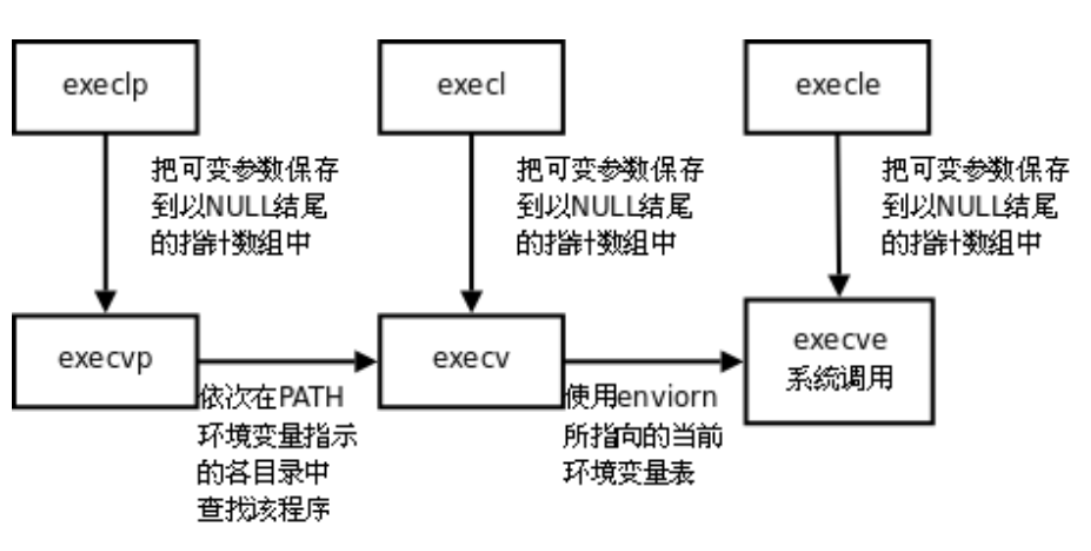
2.2 exec 函数族:程序替换的 "六大金刚"
Linux 提供了 6 个以 exec 开头的函数(统称 exec 函数族),用于实现进程程序替换。它们的核心功能一致,只是参数格式和使用场景略有不同。
2.2.1 函数原型与头文件
cpp
#include <unistd.h>
// 1. execl:参数列表形式,需指定程序完整路径
int execl(const char *path, const char *arg, ...);
// 2. execlp:参数列表形式,支持通过PATH环境变量查找程序
int execlp(const char *file, const char *arg, ...);
// 3. execle:参数列表形式,支持自定义环境变量
int execle(const char *path, const char *arg, ..., char *const envp[]);
// 4. execv:参数数组形式,需指定程序完整路径
int execv(const char *path, char *const argv[]);
// 5. execvp:参数数组形式,支持通过PATH环境变量查找程序
int execvp(const char *file, char *const argv[]);
// 6. execve:参数数组形式,支持自定义环境变量(系统调用,其他函数的底层实现)
int execve(const char *path, char *const argv[], char *const envp[]);2.2.2 函数命名规律:轻松记准六大函数
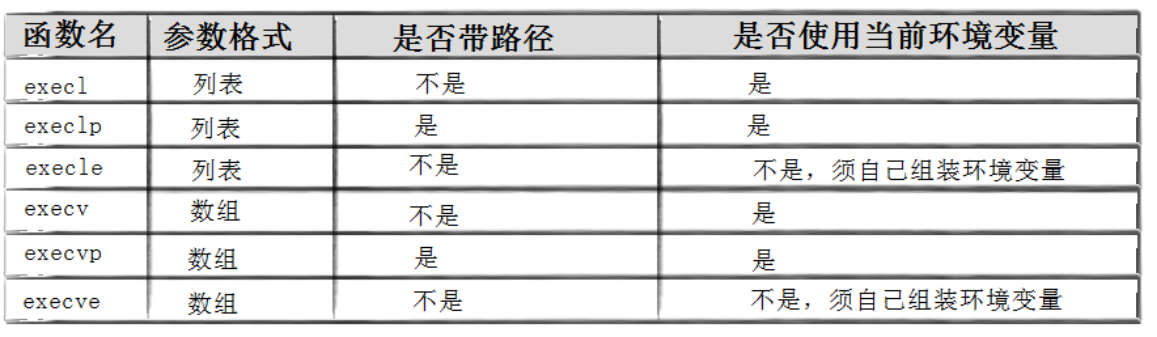
exec 函数族的命名有明确规律,掌握后可快速区分用法:
- l(list):参数采用 "列表形式",需逐个指定命令参数,最后以 NULL 结尾(标记参数结束);
- v(vector):参数采用 "数组形式",将所有命令参数存入一个字符串数组,数组最后一个元素必须是 NULL;
- p(path):支持通过系统的 PATH 环境变量查找程序,无需指定完整路径(如 execlp ("ls", "ls", "-l", NULL) 可直接找到 ls 命令);
- e(env):支持自定义环境变量,需传入一个环境变量数组(如 {"PATH=/bin", "TERM=console", NULL}),不使用系统默认环境变量。
2.2.3 函数返回值说明
- 若程序替换成功:函数不会返回(新程序直接开始执行,覆盖原进程代码);
- 若程序替换失败:返回 - 1(此时需检查错误原因,如程序路径错误、权限不足等)。
2.2.4 六大函数用法实战
为了让大家清晰掌握每个函数的用法,我来为大家分别演示 6 个 exec 函数的使用。
1. execl 函数:列表形式 + 完整路径
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
pid_t pid = fork();
if (pid == -1)
{
perror("fork failed");
exit(1);
}
else if (pid == 0)
{
printf("子进程(PID:%d)使用execl执行ls -l\n", getpid());
// 参数1:程序完整路径(通过which ls可查询)
// 参数2~n:命令参数,第一个参数是命令名,最后以NULL结尾
execl("/bin/ls", "ls", "-l", NULL);
// 若execl返回,说明替换失败
perror("execl failed");
exit(1);
}
else
{
wait(NULL); // 父进程等待子进程完成
printf("父进程:子进程执行完毕\n");
}
return 0;
}编译执行:
cpp
gcc exec_execl.c -o exec_execl
./exec_execl执行结果:
子进程(PID:45225)使用execl执行ls -l
总用量 40
-rwxr-xr-x 1 root root 8800 6月 10 17:30 exec_execl
-rw-r--r-- 1 root root 542 6月 10 17:29 exec_execl.c
...(其他文件列表)
父进程:子进程执行完毕2. execlp 函数:列表形式 + PATH 查找
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
pid_t pid = fork();
if (pid == -1)
{
perror("fork failed");
exit(1);
}
else if (pid == 0)
{
printf("子进程(PID:%d)使用execlp执行ls -l\n", getpid());
// 参数1:程序名(无需完整路径,通过PATH环境变量查找)
execlp("ls", "ls", "-l", NULL);
perror("execlp failed");
exit(1);
}
else
{
wait(NULL);
printf("父进程:子进程执行完毕\n");
}
return 0;
}编译执行:
bash
gcc exec_execlp.c -o exec_execlp
./exec_execlp执行结果与 execl 一致,区别在于 execlp 无需指定 ls 的完整路径,内核会自动在 PATH 环境变量包含的目录(如 /bin、/usr/bin)中查找。
3. execle 函数:列表形式 + 自定义环境变量
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
pid_t pid = fork();
if (pid == -1)
{
perror("fork failed");
exit(1);
}
else if (pid == 0)
{
printf("子进程(PID:%d)使用execle执行ls -l(自定义环境变量)\n", getpid());
// 自定义环境变量数组,最后以NULL结尾
char *const envp[] = {"PATH=/bin", "TERM=console", NULL};
// 最后一个参数传入自定义环境变量数组
execle("/bin/ls", "ls", "-l", NULL, envp);
perror("execle failed");
exit(1);
}
else
{
wait(NULL);
printf("父进程:子进程执行完毕\n");
}
return 0;
}编译执行:
bash
gcc exec_execle.c -o exec_execle
./exec_execleexecle会使用自定义的环境变量执行程序,若自定义的 PATH中不包含 ls 的路径,会替换失败。
4. execv 函数:数组形式 + 完整路径
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
pid_t pid = fork();
if (pid == -1)
{
perror("fork failed");
exit(1);
}
else if (pid == 0)
{
printf("子进程(PID:%d)使用execv执行ls -l\n", getpid());
// 命令参数数组,最后以NULL结尾
char *const argv[] = {"ls", "-l", NULL};
// 参数1:程序完整路径,参数2:参数数组
execv("/bin/ls", argv);
perror("execv failed");
exit(1);
}
else
{
wait(NULL);
printf("父进程:子进程执行完毕\n");
}
return 0;
}编译执行:
bash
gcc exec_execv.c -o exec_execv
./exec_execvexecv与 execl的区别在于参数传递方式:execl 逐个传入参数,execv 将参数存入数组传入,适用于参数数量较多的场景。
5. execvp 函数:数组形式 + PATH 查找
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
pid_t pid = fork();
if (pid == -1)
{
perror("fork failed");
exit(1);
}
else if (pid == 0)
{
printf("子进程(PID:%d)使用execvp执行ls -l\n", getpid());
char *const argv[] = {"ls", "-l", NULL};
// 参数1:程序名(通过PATH查找),参数2:参数数组
execvp("ls", argv);
perror("execvp failed");
exit(1);
}
else
{
wait(NULL);
printf("父进程:子进程执行完毕\n");
}
return 0;
}编译执行:
bash
gcc exec_execvp.c -o exec_execvp
./exec_execvpexecvp是 shell 执行命令的核心函数,shell 通过 fork创建子进程后,调用 execvp执行用户输入的命令(如 ls、pwd 等),无需用户指定程序路径。
6. execve 函数:数组形式 + 自定义环境变量(系统调用)
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
pid_t pid = fork();
if (pid == -1)
{
perror("fork failed");
exit(1);
}
else if (pid == 0)
{
printf("子进程(PID:%d)使用execve执行ls -l(自定义环境变量)\n", getpid());
char *const argv[] = {"ls", "-l", NULL};
char *const envp[] = {"PATH=/bin", "TERM=console", NULL};
// 系统调用,其他exec函数的底层实现
execve("/bin/ls", argv, envp);
perror("execve failed");
exit(1);
}
else
{
wait(NULL);
printf("父进程:子进程执行完毕\n");
}
return 0;
}编译执行:
bash
gcc exec_execve.c -o exec_execve
./exec_execveexecve是唯一的系统调用,其他 5 个 exec 函数都是基于 execve 的封装,提供更便捷的参数传递方式。
2.2.5 程序替换失败的常见原因
- 程序路径错误:如 execl ("/bin/lss", "lss", "-l", NULL),lss 命令不存在;
- 权限不足:程序文件没有执行权限(可通过 chmod +x 文件名添加执行权限);
- 参数格式错误:如参数列表未以 NULL 结尾,或参数数组最后一个元素不是 NULL;
- 自定义环境变量缺失:如 execle/execve 的环境变量数组中未包含程序所需的 PATH。
2.3 程序替换与 fork 的经典组合:shell 的核心工作原理
进程创建(fork) 、进程等待(wait/waitpid) 与**程序替换(exec)**的组合,是 Linux shell(如 bash)的核心工作原理。shell 的工作流程如下:
- 读取用户输入的命令(如 ls -l);
- fork 创建子进程;
- 子进程调用 exec 函数族替换程序,执行用户输入的命令;
- 父进程(shell)调用 wait/waitpid 等待子进程执行完毕;
- 子进程执行完毕后,shell 打印提示符,等待用户输入下一条命令。
实战:实现一个简易 shell(mini_shell.c)
基于上述原理,我们可以实现一个支持基本命令执行的简易 shell,来加深对 fork+exec+wait 组合的理解:
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <string.h>
#include <ctype.h>
#define MAX_CMD_LEN 1024 // 命令最大长度
#define MAX_ARG_NUM 64 // 最大参数个数
// 去除字符串前后空格
void trim_space(char *str)
{
if (str == NULL) return;
char *start = str;
char *end = str + strlen(str) - 1;
// 去除开头空格
while (isspace(*start)) start++;
// 去除结尾空格
while (end > start && isspace(*end)) end--;
// 截断字符串
*(end + 1) = '\0';
// 移动字符串到开头
memmove(str, start, end - start + 2);
}
// 解析命令行,将命令拆分为参数数组
void parse_cmd(char *cmd, char *argv[])
{
if (cmd == NULL || argv == NULL) return;
trim_space(cmd); // 去除空格
char *token = strtok(cmd, " "); // 以空格为分隔符拆分命令
int i = 0;
while (token != NULL && i < MAX_ARG_NUM - 1)
{
argv[i++] = token;
token = strtok(NULL, " ");
}
argv[i] = NULL; // 参数数组最后以NULL结尾
}
int main(void)
{
char cmd[MAX_CMD_LEN];
char *argv[MAX_ARG_NUM];
pid_t pid;
int status;
printf("===== 简易Shell(输入exit退出)=====\n");
while (1)
{
// 打印提示符
printf("[mini_shell]$ ");
fflush(stdout); // 刷新缓冲区,确保提示符立即显示
// 读取用户输入的命令
if (fgets(cmd, MAX_CMD_LEN, stdin) == NULL)
{
perror("fgets failed");
continue;
}
// 去除fgets读取的换行符
cmd[strcspn(cmd, "\n")] = '\0';
// 处理exit命令,退出shell
if (strcmp(cmd, "exit") == 0)
{
printf("mini_shell退出\n");
exit(0);
}
// 解析命令为参数数组
parse_cmd(cmd, argv);
if (argv[0] == NULL)
{
continue; // 空命令,重新等待输入
}
// fork创建子进程
pid = fork();
if (pid == -1)
{
perror("fork failed");
continue;
}
else if (pid == 0)
{
// 子进程执行程序替换
execvp(argv[0], argv);
// 若execvp返回,说明替换失败
perror("execvp failed");
exit(1);
}
else
{
// 父进程等待子进程执行完毕
waitpid(pid, &status, 0);
}
}
return 0;
}编译执行:
bash
gcc mini_shell.c -o mini_shell
./mini_shell执行结果:
===== 简易Shell(输入exit退出)=====
[mini_shell]$ ls -l
总用量 48
-rwxr-xr-x 1 root root 8800 6月 10 18:00 exec_execl
-rw-r--r-- 1 root root 542 6月 10 17:29 exec_execl.c
...(其他文件列表)
[mini_shell]$ pwd
/root/linux_process
[mini_shell]$ whoami
root
[mini_shell]$ exit
mini_shell退出这个简易 shell 完美复刻了 bash 的核心工作流程:读取命令→fork 子进程→exec 替换程序→wait 等待子进程,支持 ls、pwd、whoami 等常见命令,输入 exit 即可退出。
总结
至此,我们已经完整掌握了 Linux 进程创建、终止、等待与程序替换的核心知识,其完整生命周期可以总结为:
- 进程创建:父进程通过 fork 函数 "分身",创建子进程,父子进程共享代码段,数据段采用写时拷贝技术;
- 程序替换:子进程通过 exec 函数族 "改头换面",执行全新程序,覆盖原有的用户空间内容;
- 进程终止:子进程完成任务后,通过 return、exit 或信号终止,释放用户空间资源,进入僵尸状态;
- 进程等待:父进程通过 wait/waitpid 函数 "认领" 子进程,回收其内核资源,获取退出状态。
这四大环节环环相扣,构成了 Linux 进程控制的核心逻辑,也是 shell、服务器等核心应用的底层支撑。掌握这些知识,不仅能帮助我们编写更高效、健壮的 Linux 程序,还能让我们深入理解操作系统的资源管理与调度机制。
如果在学习过程中遇到问题,或者想深入了解相关的进阶知识点,欢迎在评论区留言讨论!