
作为一名长期深耕视觉生成与强化学习领域的开发者,最近在昇腾平台上完成了DanceGRPO框架与FLUX模型的融合实践。这段经历让我对多模态生成强化学习有了更直观的认知------不仅要吃透理论原理,更要解决跨硬件迁移、性能调优等实际工程问题。下面就结合这次实战经历,从**<font style="background-color:rgba(255,246,122,0.8);">项目背景、核心原理、迁移实践到性能优化</font>**,一步步拆解整个过程中的关键细节与心得体会。
一、项目缘起:为什么选择DanceGRPO+FLUX?
团队核心需求为优化生图效果,提升细节还原度与文本对齐精度。对比主流模型后选定 FLUX,其支持 Diffusion 和 Rectified Flow 两种生成范式,灵活性高且图像细节表现佳。强化学习框架调研中,意外发现字节跳动 DanceGRPO 适配性强,专为视觉生成设计,可无缝对接 FLUX 等跨范式模型,还支持文生图、文生视频等多任务,省去自研适配成本。
项目的基础环境是基于昇腾硬件搭建的,具体依赖版本如下(实际部署时反复调试过多次,这个组合稳定性最佳):
| 驱动固件 | CANN | Python | Pytorch |
|---|---|---|---|
| 1230商发 | 8.1 620poc | 3.10 | 2.6.0 |
最开始跑通 baseline 时,性能其实并不理想:A+X-376T 机型每步要 419 秒,A+K-376T 也要 395 秒,完全达不到实际应用的要求。经过多轮优化后,现在 A+X 机型已经降到 315 秒/步,A+K 降到 352 秒/步,业界对标能达到 1.0x 和 0.8x 推理标卡水平,这个提升还是很可观的。
二、核心原理:搞懂生成范式与GRPO逻辑
在动手实践前,我花了不少时间梳理多模态生成强化学习的核心逻辑,尤其是两种生成范式和GRPO的工作原理------这是后续迁移和优化的基础,没吃透的话遇到问题根本无从下手。
(一)两种生成范式:各有千秋,逐渐融合
生成模型的生图逻辑主要分为两类,就像两种不同的绘画风格,适用场景完全不同:
1. Diffusion Model(扩散模型):慢工出细活
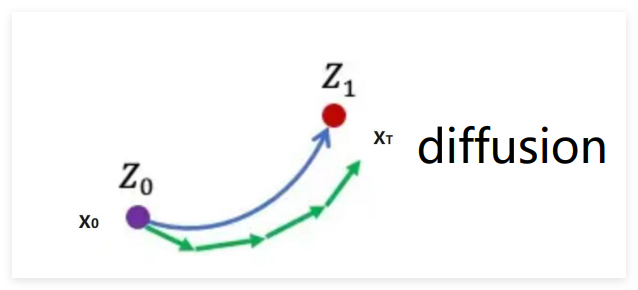
扩散模型的生成过程很有意思,有点像"慢慢打磨"的过程。它从一个纯高斯噪声开始,通过 Policy Model 一步步预测并去除噪声,最终得到清晰图像。数学上它基于 SDE(随机扩散路径),生成轨迹是弯曲的,需要多步迭代才能逼近目标。
我用生成猫的图片来理解:初始是纯噪声 X₀ 和 Z₀,参考样本是真实猫图片 Z₁,模型生成的轨迹是绿色线,目标是让生成的 XT 既接近 Z₁ 又不过度拟合。步长越小、迭代次数越多,细节越逼真,但耗时也会成倍增加,公式表达很直观:
x ( t + 1 ) = x ( t ) + h × v ( x ( t ) , t , θ x(t+1)=x(t)+h × v(x(t), t, \theta x(t+1)=x(t)+h×v(x(t),t,θ
其中 v 是去噪方向,h 是步长。这种范式适合对质量要求极高的场景,比如艺术创作,需要还原皮肤纹理、毛发细节的时候,它的优势就很明显。
2. Rectified Flow(矫正流):高效快节奏
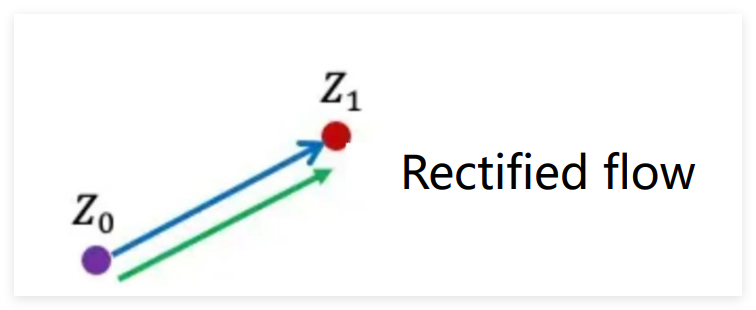
矫正流思路不同,基于ODE确定性路径将去噪轨迹矫正为直线,理论可一步生成。实际训练初始轨迹仍弯曲,需通过条件注入(如文本嵌入向量)和reflow技术拉直,减少生成轨迹交点避免"走错路"。
3. 融合趋势
现在这两种范式已经不是孤立的了,而是相互借鉴。比如 DanceGRPO 中,扩散模型会借鉴矫正流的思路加快推理速度,矫正流也会加入随机扰动增加多样性,这也是我们选择 FLUX+DanceGRPO 组合的重要原因------FLUX 同时支持两种范式,能更好地发挥这种融合优势。
(二)GRPO核心逻辑:生成-评估-优化的闭环
强化学习的核心是"通过反馈持续优化",GRPO 也不例外,主要包含三个核心模块:
- Policy Model:负责生成样本,相当于"执行者",会根据反馈更新权重;
- Reward Model:评估生成结果的好坏,输出一个标量分数,相当于"评委";
- Reference Model:提供基准输出,通过 KL 散度控制 Policy Model 不过度偏移,相当于"校准器"。
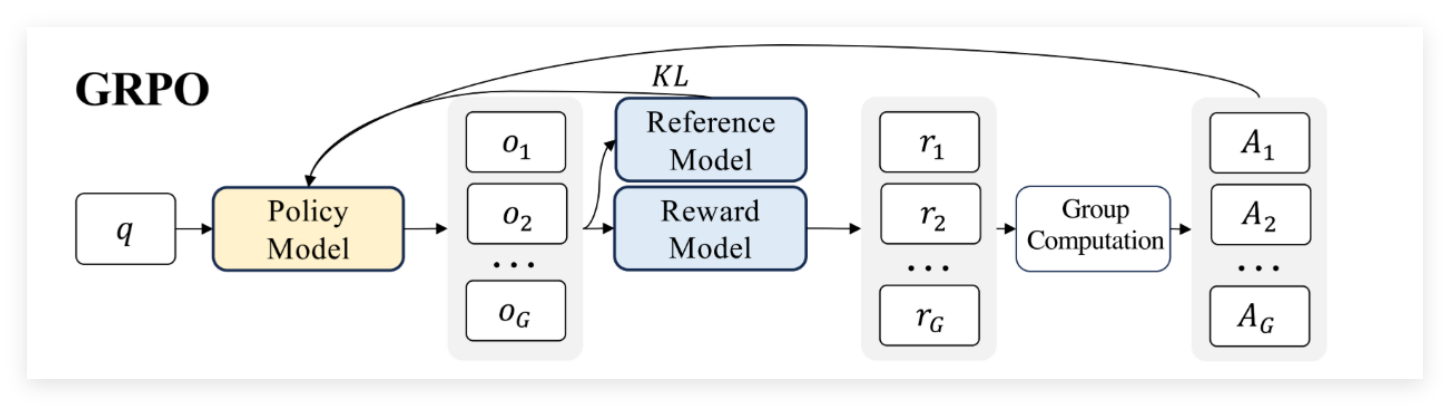
GRPO核心流程分三步:Policy Model生成N组样本,Reference Model提供基准并计算KL散度,Reward Model打分后,Policy Model依据分数更新梯度。
而DanceGRPO针对视觉生成优化,去掉Reference Model,仅保留CLIP约束防止局部突变,实测效果差异极小,还简化了框架结构。CLIP约束核心代码简洁、逻辑清晰:
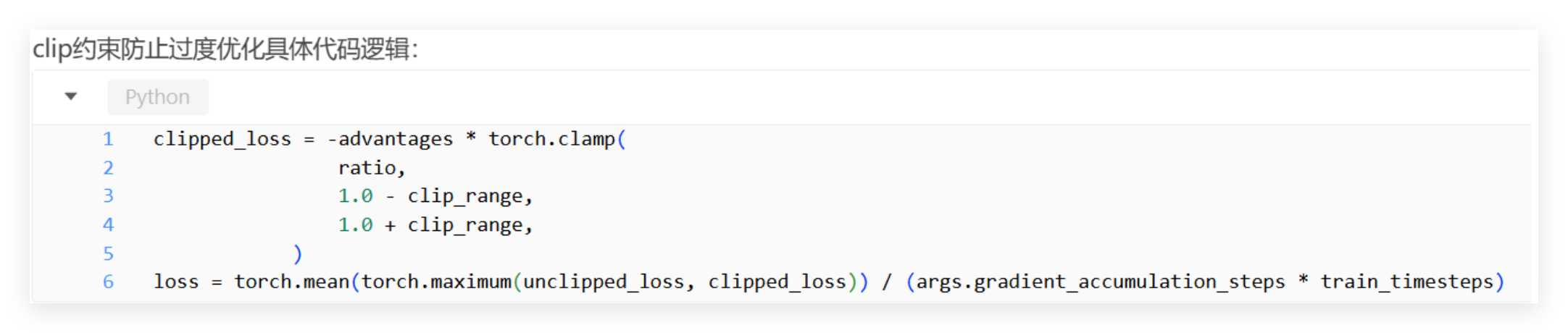
通过 clamp 函数限制比率的范围,避免某一步更新幅度过大,导致生成效果突变。
三、迁移实践:从GPU到昇腾NPU的踩坑之路
把 FLUX 模型迁移到昇腾 NPU 并适配 DanceGRPO 框架,是整个项目中最耗时的环节------硬件差异、依赖兼容、精度对齐,每个环节都有不少坑要踩。
(一)环境搭建与代码修改
首先是基础环境准备,迁移到 NPU 后,依赖版本需要调整,最终确定的稳定组合:
| CANN | Torch | Transformers | Python |
|---|---|---|---|
| 8.2.RC1.B080 | 2.6.0 | 4.53.0 | 3.10 |
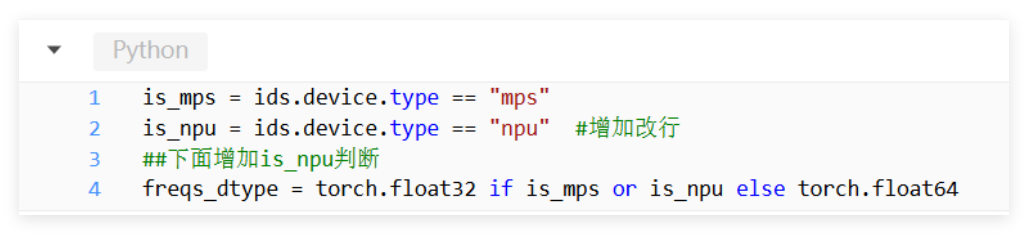
然后是代码层面的修改,最关键的是解决 NPU 不支持 complex128 计算的问题。在 diffusers 库的 <embeddings.py> 文件第 1250 行,需要增加 NPU 设备判断,把数据类型改为 float32:
另外还有两个小技巧:一是仓库没有懒加载,没用的依赖库可以跳过安装,能节省不少时间;二是未调用的接口可以注释掉,比如 flashattn 接口,我们的模型源于 diffusers,根本用不到,注释后能避免不必要的兼容问题。
(二)精度对齐:确保NPU与GPU效果一致
迁移的核心要求是"效果不打折",所以精度对齐是重中之重。我们总结了一套四阶段对齐流程,从随机性固定到端到端验证,一步步确保 NPU 和 GPU 的输出一致。
1. 随机性固定
生成模型的随机性很强,想要对比效果,必须先固定所有随机因素。我们用了两种方式:一是精细对比,把 GPU 生成的随机变量保存下来,NPU 直接加载;二是固定 seed 后用 CPU 生成张量,避免设备差异导致的随机序列不同。涉及的随机类型和代码如下:
| 随机类型 | 作用 | 涉及代码 |
|---|---|---|
| 全局随机性 | 固定 python seed、开启确定性计算 | from msprobe.pytorch import seed_all; seed_all(mode=True) |
| 通信随机性 | 开启 HCCL 通信确定性 | export HCCL_DETERMINISTIC=TRUE |
| 数据随机性 | 关闭 shuffle,固定训练数据顺序 | sampler = DistributedSampler(train_dataset, rank=rank, num_replicas=world_size, shuffle=False, seed=args.sampler_seed) |
| 固定 noise | 统一噪声生成 | input_latents = torch.randn((1, IN_CHANNELS, latent_h, latent_w), dtype=torch.bfloat16, device="cpu").to(device) |
2. 分阶段对齐
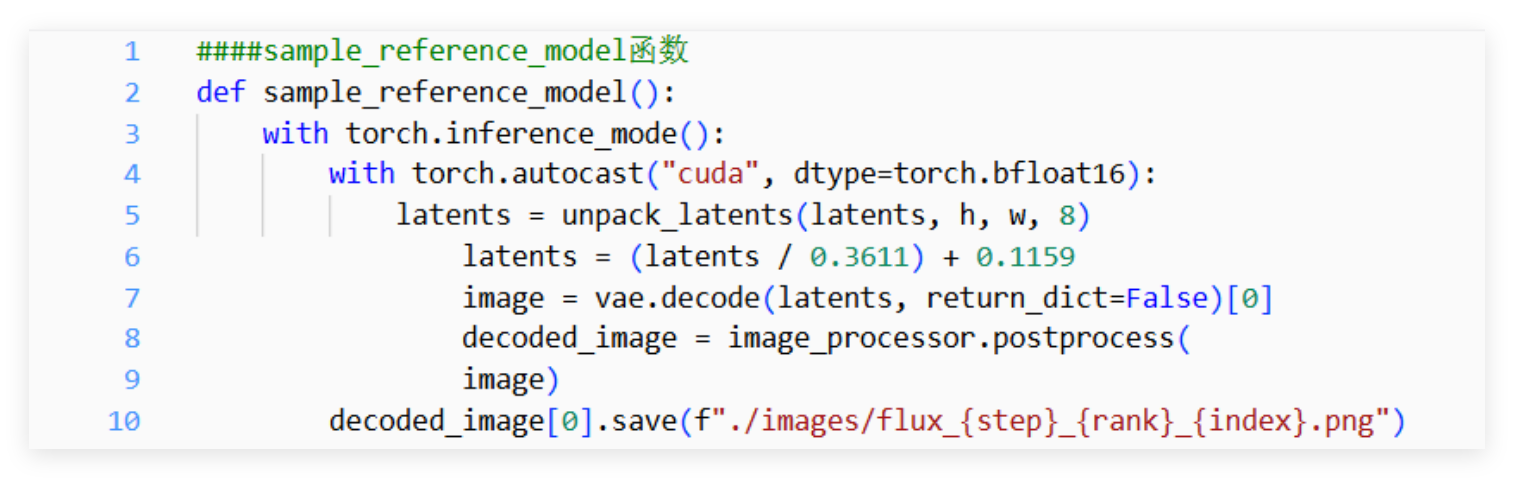
- 推理阶段:同一个 prompt 生成 12 张图片(默认参数 num_generations=12),分别保存 NPU 和 GPU 的输出,直观对比视觉效果。我们写了个函数专门保存图片,方便后续对比:
- Reward 阶段:单独抽取 CLIP 奖励模型,模拟 1000 张图片的评分过程,NPU 和 GPU 的绝对误差只有 0.015%,均值误差 0.000154,精度完全达标。
- 端到端对齐:加载相同预训练权重,固定所有随机性,同时监控图片效果、loss 值、reward 分数和下游任务效果。这里踩过一个坑:替换 rope 融合算子后,loss 和 reward 都正常,但生成的图片出现了"花图",所以必须全程关注视觉效果,不能只看量化指标。
四、性能优化:从419s到315s的迭代过程
性能优化是项目落地的关键,我们从算子、通信、调度三个维度入手,一步步压榨硬件性能。整个优化过程是循序渐进的,每个优化点都经过了多次测试验证,以下是几个关键优化手段:
(一)算子优化:解决核心性能瓶颈
算子是性能的基础,我们重点优化了三个关键算子:
1. repeat_interleave 算子
FLUX 模型的 ROPE 位置编码会用到这个算子,它在首轴重复的效率很高,但非首轴重复时需要前后调用 Transpose,耗时极高。我们的优化思路是调整轴顺序,先转置到首轴再重复,最后再转置回来:

这个简单的修改效果立竿见影:A+X 机型从 419s/步降到 335s/步,A+K 从 395s/步降到 365s/步,单算子优化带来了近 20% 的性能提升。
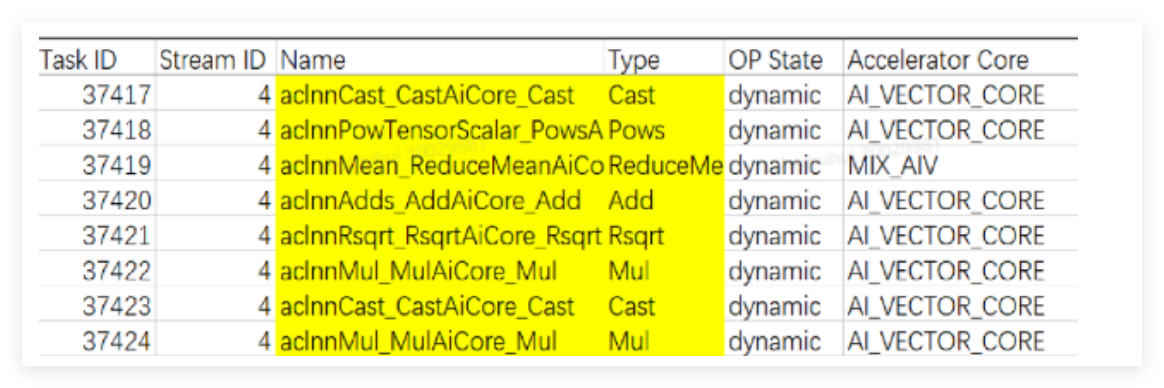
2. RMSNorm 融合算子
原始的 RMSNorm 由多个小算子组合而成,调度开销大。
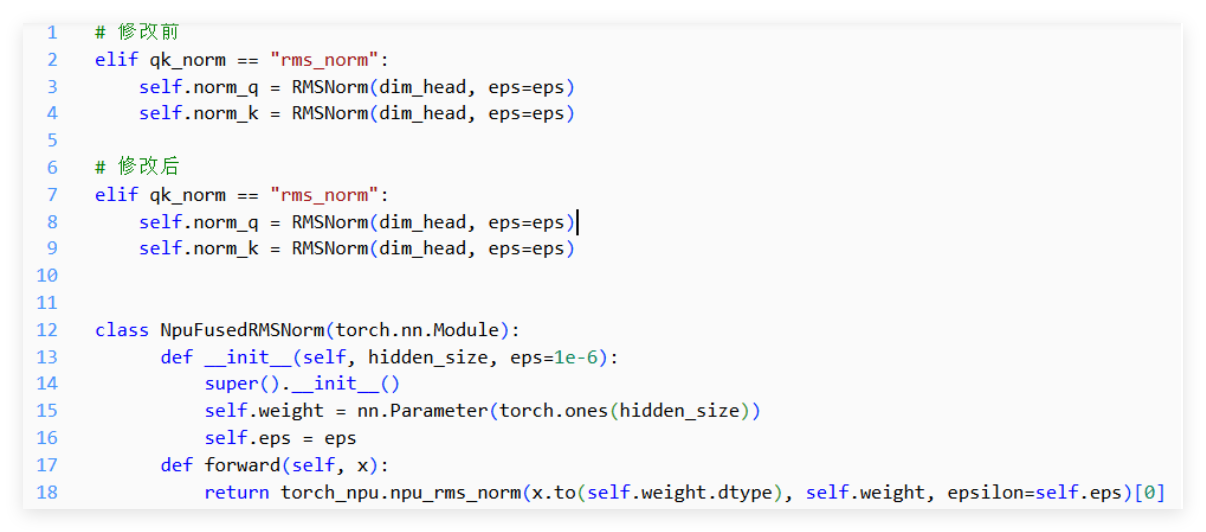
我们自定义了 NPU 融合算子,直接调用 torch_npu.npu_rms_norm,把多个小算子合并成一个,减少调度次数:
3. Cast 消除
性能分析发现,Cast 算子占总计算耗时的 34%,主要来自两部分:一是 FSDP 通信与计算的精度转换(无法消除),二是 Attention 前后的类型转换(可以优化)。旧版本 FLUX 代码中,npu_fusion_attention 不支持 fp32 计算,需要先转换类型,最新版本已经支持,我们直接去掉了转换逻辑:
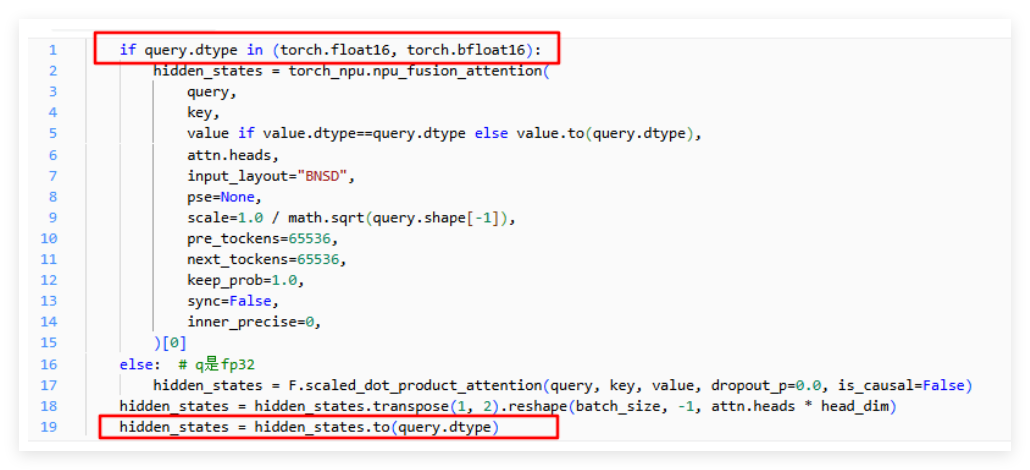
这个修改让 A+K 机型的性能从 352s/步降到 348s/步,虽然提升幅度不大,但积少成多。
(二)通信优化:提升数据传输效率
分布式训练中,通信开销往往是瓶颈。我们通过调整 HCCL_BUFFSIZE 参数来增大通信带宽------这个参数代表 NPU 间共享数据的缓存区大小,默认是 200M。我们在训练脚本中添加了:
plain
export HCCL_BUFFSIZE=800调整后,A+K 机型的性能从 365s/步降到 352s/步,通信效率明显提升。不过这里要注意,缓存区大小不能盲目增大,如果集群中通信域较多,可能会影响模型数据存放,需要根据实际情况调整。
(三)调度优化:让硬件资源不闲置
调度优化的核心是"让计算和通信、IO 并行起来",避免硬件闲置。我们做了两个关键优化:
1. 开启 FSDP 前反向预取
FSDP 中,AllGather 和 ReduceScatter 默认是串行执行的,会阻塞梯度计算。开启前向预取后,能在当前前向计算前发出下一个 AllGather 操作;开启反向预取后,能在当前 ReduceScatter 前发出下一个 AllGather 操作,实现通信与计算重叠。在 fsdp_kwargs 中添加相关参数:
plain
from torch.distributed.fsdp import BackwardPrefetch
fsdp_kwargs = {
"auto_wrap_policy": auto_wrap_policy,
"sharding_strategy": sharding_strategy,
"mixed_precision": mixed_precision,
"device_id": device_id,
"forward_prefetch": True,
"backward_prefetch": BackwardPrefetch.BACKWARD_PREFETCH,
}这个优化让 A+X 机型从 335s/步降到 325s/步,而且前向预取的收益更明显------因为模型大部分时间都在做前向计算。
2. 异步保存与增大 batch size
推理阶段生成图片后,同步保存会导致 NPU 闲置。我们用线程池实现异步保存,让 NPU 在保存图片的同时继续执行 Reward 计算:
plain
from concurrent.futures import ThreadPoolExecutor
image_save_executor = ThreadPoolExecutor(max_workers=8)
def async_save_image(image, path):
image_save_executor.submit(torchvision.utils.save_image, image, path)
# 替换同步保存
async_save_image(decoded_image[0], f"./images/flux_{rank}_{index}.png")这个修改让 A+X 机型节约了 3 秒左右。另外,我们还把推理阶段的 batch size 从 1 增大到 4------昇腾硬件适合大 kernel 计算,增大 batch size 能更好地利用硬件并行能力,最终让 A+X 机型的性能从 325s/步降到 315s/步,达到了预期目标。
五、实战心得与未来方向
本次 DanceGRPO+FLUX 昇腾落地,深刻体会 "理论指导实践,实践反哺理解",从认知模糊到攻克问题、实现精度与性能双达标,挑战与收获并存
总结几个关键心得:
- 原理要吃透:两种生成范式的差异、GRPO 的闭环逻辑,是后续迁移和优化的基础,遇到问题时能快速定位根源;
- 迁移有方法:精度对齐要分阶段进行,先固定随机性,再分阶段验证,最后端到端测试,避免盲目调试;
- 优化讲策略:性能优化要从瓶颈入手,先解决算子和通信的核心问题,再通过调度优化挖掘潜力,不能盲目尝试;
- 细节定成败:比如 NPU 不支持 complex128、Cast 算子的隐藏开销,这些细节往往会影响最终效果,需要耐心排查。
视觉生成技术还在快速发展,DanceGRPO 这类统一框架的出现,让跨范式、跨任务的模型优化变得更加高效。相信随着硬件算力的提升和算法的迭代,视觉生成会在更多行业场景中落地生根,创造更大的价值。
注明:昇腾PAE案例库对本文写作亦有帮助。