文章目录
- [1 概要](#1 概要)
- [2 项目介绍](#2 项目介绍)
-
- [2.1 代码目录结构](#2.1 代码目录结构)
- [2.2 检测代码yolo11_ascend_video.py的实现](#2.2 检测代码yolo11_ascend_video.py的实现)
- [2.3 模型转换](#2.3 模型转换)
- [2.4 开始推理](#2.4 开始推理)
- [3 总结](#3 总结)
- [4 其余章节连接](#4 其余章节连接)
1 概要
最近博主准备了一个可以检测车辆的网络模型,准备部署到华为和香橙派联合出版的香橙派 Ai Pro上(Oriange Pi Ai Pro),此推理板使用的是Ascend3130B4的芯片。其中,博主学习CANN
的相关知识以满足模型优化的需求。
具体的学习路径如下:
- 项目介绍
- 项目优化(AIPP的使用)
- 项目再次优化(AIPP+DVPP的使用)
硬件环境:
- 香橙派AI Pro (Ubuntu) : 用于部署最终的模型
- 宿主机(Windows):用于编写代码
整体流程:
在宿主机上编写完程序后通过Mobaxterm的SSH将文件上传到香橙派上,随后进行模型转换(.ONNX->.om),最后实现运行
2 项目介绍
项目为车辆检测,所用模型为YOLO11X,最终实现效果为实时检测视频流。
2.1 代码目录结构
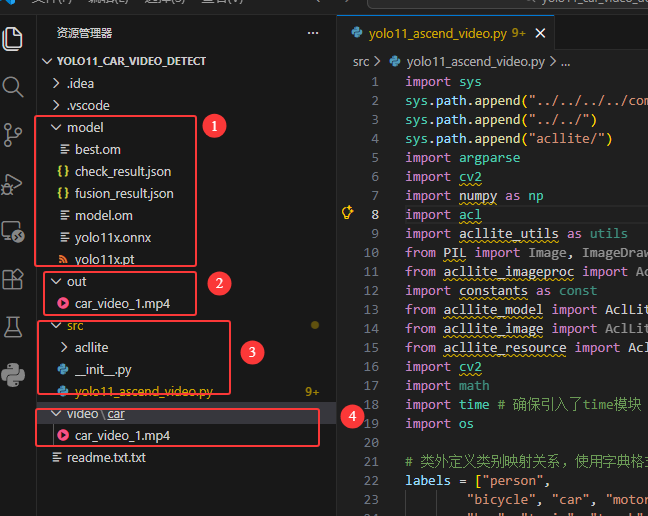
代码分为四个部分
① model:用于存放训练好的.onnx模型和转换得到的.om模型
② out:处理后的视频流
③ src:用于存放核心的检测文件,其中有一个acllite的文件夹,此文件夹为华为官方提供的API接口,可以大大简化我们开发的流程
④ video:原始视频流
2.2 检测代码yolo11_ascend_video.py的实现
c
import sys
sys.path.append("../../../../common")
sys.path.append("../../")
sys.path.append("acllite/")
import argparse
import cv2
import numpy as np
import acl
import acllite_utils as utils
from PIL import Image, ImageDraw, ImageFont
from acllite_imageproc import AclLiteImageProc
import constants as const
from acllite_model import AclLiteModel
from acllite_image import AclLiteImage
from acllite_resource import AclLiteResource
import cv2
import math
import time # 确保引入了time模块
import os
# 类外定义类别映射关系,使用字典格式
labels = ["person",
"bicycle", "car", "motorbike", "aeroplane",
"bus", "train", "truck", "boat", "traffic light",
"fire hydrant", "stop sign", "parking meter", "bench",
"bird", "cat", "dog", "horse", "sheep", "cow", "elephant",
"bear", "zebra", "giraffe", "backpack", "umbrella", "handbag",
"tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball",
"kite", "baseball bat", "baseball glove", "skateboard", "surfboard",
"tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon",
"bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog",
"pizza", "donut", "cake", "chair", "sofa", "potted plant", "bed", "dining table",
"toilet", "TV monitor", "laptop", "mouse", "remote", "keyboard", "cell phone",
"microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase",
"scissors", "teddy bear", "hair drier", "toothbrush"]
class YOLO11:
"""YOLO11 目标检测模型类,用于处理推理和可视化。"""
def __init__(self, parser_args, onnx_model = None):
"""
初始化 YOLO11 类的实例。
参数:
onnx_model: ONNX 模型的路径。
input_image: 输入图像的路径。
confidence_thres: 用于过滤检测结果的置信度阈值。
iou_thres: 非极大值抑制(NMS)的 IoU(交并比)阈值。
"""
self.onnx_model = onnx_model
self.parser_args = parser_args
self.img = None
self.img_height = 640
self.img_weight = 640
# 加载类别名称
self.classes = labels
# 为每个类别生成一个颜色调色板
self.color_palette = np.random.uniform(0, 255, size=(len(self.classes), 3))
def preprocess(self, img_data = None):
"""
对输入图像进行预处理,以便进行推理。
返回:
image_data: 经过预处理的图像数据,准备进行推理。
"""
if img_data is None:
print("error img datas, please check again")
#获取输入图像数据
self.img = img_data
# 获取输入图像的高度和宽度
self.img_height, self.img_width = img_data.shape[1], img_data.shape[0]
# 将图像颜色空间从 BGR 转换为 RGB
img = cv2.cvtColor(self.img, cv2.COLOR_BGR2RGB)
# 保持宽高比,进行 letterbox 填充, 使用模型要求的输入尺寸
img, self.ratio, (self.dw, self.dh) = self.letterbox(img, new_shape=(self.input_width, self.input_height))
# 通过除以 255.0 来归一化图像数据
image_data = np.array(img) / 255.0
# 将图像的通道维度移到第一维
image_data = np.transpose(image_data, (2, 0, 1)) # 通道优先
# 扩展图像数据的维度,以匹配模型输入的形状
image_data = np.expand_dims(image_data, axis=0).astype(np.float32)
# 返回预处理后的图像数据
return image_data
def letterbox(self, img, new_shape=(640, 640), color=(114, 114, 114), auto=False, scaleFill=False, scaleup=True):
"""
将图像进行 letterbox 填充,保持纵横比不变,并缩放到指定尺寸。
"""
shape = img.shape[:2] # 当前图像的宽高
# print(f"Original image shape: {shape}") # 注释掉以减少刷屏
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# 计算缩放比例
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1]) # 选择宽高中最小的缩放比
if not scaleup: # 仅缩小,不放大
r = min(r, 1.0)
# 缩放后的未填充尺寸
new_unpad = (int(round(shape[1] * r)), int(round(shape[0] * r)))
# 计算需要的填充
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # 计算填充的尺寸
dw /= 2 # padding 均分
dh /= 2
# 缩放图像
if shape[::-1] != new_unpad: # 如果当前图像尺寸不等于 new_unpad,则缩放
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
# 为图像添加边框以达到目标尺寸
top, bottom = int(round(dh)), int(round(dh))
left, right = int(round(dw)), int(round(dw))
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color)
# print(f"Final letterboxed image shape: {img.shape}") # 注释掉以减少刷屏
return img, (r, r), (dw, dh)
def postprocess(self, input_image, output):
"""
对模型输出进行后处理,以提取边界框、分数和类别 ID。
"""
outputs = np.transpose(np.squeeze(output[0]))##此处的outputs就一个维度
# print("outputs shape:",outputs.shape) ##outputs: (21504, 6) # 注释掉以减少刷屏
rows = outputs.shape[0]
boxes, scores, class_ids = [], [], []##分别是框,置信度,类别
# 计算缩放比例和填充,根据比例将检测框画回原图像
ratio = self.img_width / self.input_width, self.img_height / self.input_height
for i in range(rows): ##遍历所有的检测框
classes_scores = outputs[i][4:]#后几列是置信度大小
#print("classes_scores:",classes_scores)
max_score = np.amax(classes_scores)
if max_score >= self.parser_args.conf_thres:
class_id = np.argmax(classes_scores)#找到对应列索引
x, y, w, h = outputs[i][0], outputs[i][1], outputs[i][2], outputs[i][3]
# 将框调整到原始图像尺寸,考虑缩放和填充
x -= self.dw # 移除填充
y -= self.dh
x /= self.ratio[0] # 缩放回原图
y /= self.ratio[1]
w /= self.ratio[0]
h /= self.ratio[1]
left = int(x - w / 2)
top = int(y - h / 2)
width = int(w)
height = int(h)
boxes.append([left, top, width, height])
scores.append(max_score)
class_ids.append(class_id)#添加进列表中方便后续画图调用
indices = cv2.dnn.NMSBoxes(boxes, scores, self.parser_args.conf_thres, self.parser_args.iou_thres)
for i in indices:
box = boxes[i]
score = scores[i]
class_id = class_ids[i]
self.draw_detections(input_image, box, score, class_id)
return input_image
def draw_detections(self, img, box, score, class_id):
"""
在输入图像上绘制检测到的边界框和标签。
"""
# 提取边界框的坐标
x1, y1, w, h = box
# 获取类别对应的颜色
color = self.color_palette[class_id]
# 在图像上绘制边界框
cv2.rectangle(img, (int(x1), int(y1)), (int(x1 + w), int(y1 + h)), color, 2)
# 创建包含类别名和分数的标签文本
label = f"{self.classes[class_id]}: {score:.2f}"
# 计算标签文本的尺寸
(label_width, label_height), _ = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)
# 计算标签文本的位置
label_x = x1
label_y = y1 - 10 if y1 - 10 > label_height else y1 + 10
# 绘制填充的矩形作为标签文本的背景
cv2.rectangle(img, (label_x, label_y - label_height), (label_x + label_width, label_y + label_height), color, cv2.FILLED)
# 在图像上绘制标签文本
cv2.putText(img, label, (label_x, label_y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1, cv2.LINE_AA)
def main(self):
# 打印模型的输入尺寸
print("YOLO11 🚀 目标检测 ONNXRuntime")
print("模型名称:", self.onnx_model)
#ACL resource initialization
acl_resource = AclLiteResource()
acl_resource.init()
#load model
model = AclLiteModel(self.parser_args.model_path)
dims, ret = acl.mdl.get_input_dims(model._model_desc, 0)
_, _, height, width = tuple(dims["dims"])
# 获取模型的输入形状
#model_inputs = session.get_inputs()
self.input_width = width
self.input_height = height
print(f"模型输入尺寸:宽度 = {self.input_width}, 高度 = {self.input_height}")
# open video
video_path = self.parser_args.video_path
if not os.path.exists(video_path):
print("please input correct video path\r")
return
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
Width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
Height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
if not os.path.exists(self.parser_args.output_dir):
os.mkdir(self.parser_args.output_dir)
output_Video = os.path.basename(video_path)
output_Video = os.path.join(self.parser_args.output_dir, output_Video)
fourcc = cv2.VideoWriter_fourcc(*'mp4v') # DIVX, XVID, MJPG, X264, WMV1, WMV2
outVideo = cv2.VideoWriter(output_Video, fourcc, fps, (Width, Height))
# Read until video is completed
frame_count = 0
print("开始推理...")
while (cap.isOpened()):
# [修改1] 记录开始时间
t_start = time.time()
ret, frame = cap.read()
if ret == True:
# 预处理图像数据,确保使用模型要求的尺寸 (1024*1024)
img_data = self.preprocess(img_data = frame)
# 使用预处理后的图像数据运行推理
# outputs = session.run(None, {model_inputs[0].name: img_data})
outputs = model.execute([img_data, ])
# 对输出进行后处理以获取输出图像
result_return = self.postprocess(self.img, outputs) # 输出图像
outVideo.write(result_return)
# [修改2] 记录结束时间并计算 FPS
t_end = time.time()
time_cost = t_end - t_start
if time_cost > 0:
current_fps = 1 / time_cost
else:
current_fps = 0.0
# [修改3] 格式化输出,清除之前的多余换行,使其显示更紧凑
print(f"Frame: {frame_count} | Time: {time_cost:.4f}s | FPS: {current_fps:.2f}")
frame_count += 1
# Break the loop
else:
break
cap.release()
outVideo.release()
print("Execute end")
if __name__ == "__main__":
# 创建参数解析器以处理命令行参数
parser = argparse.ArgumentParser()
parser.add_argument("--model", type=str, default=r"", help="输入你的onnx模型路径。")
parser.add_argument("--model-path", type=str, default=r"../model/model.om", help="输入你的om模型路径。")
parser.add_argument("--video-path", type=str, default=r"../video/car/car_video_1.mp4", help="输入图像的路径。")
parser.add_argument("--conf-thres", type=float, default=0.5, help="置信度阈值")
parser.add_argument("--iou-thres", type=float, default=0.45, help="NMS IoU 阈值")
parser.add_argument("--output-dir", type=str, default="../out/", help="处理结果保存文件夹")
args = parser.parse_args()
# 使用指定的参数创建 YOLO11 类的实例
detection = YOLO11(args, args.model)
# 执行目标检测并获取输出图像
output_image = detection.main()2.3 模型转换
进行模型转换需要执行如下命令:
- 进入到model目录
- 执行如下命令:
c
atc --model=yolo11x.onnx --framework=5 --output=yolo11x --soc_version=Ascend310B4 --input_format=NCHW其中
1.进入到model目录
2.执行如下命令:
atc --model=yolo11x.onnx --framework=5 --output=yolo11x --soc_version=Ascend310B4 --input_format=NCHW
(1)--model 是模型结构
{
0:Caffe
1:MindSpore框架*.air格式的模型文件或TorchAir通过export导出的标准*.air格式文件
3:TensorFlow
5:ONNX
}
(2)--framework 是模型权重
(3)output=yolov3 代表输出yolov3.om
(4)--soc_version=Ascend310B4 所用到的芯片是升腾310B4
eg:--insert_op_conf=aipp_nv12.cfg
(5)--insert_op_conf=aipp_nv12.cfg 代表的是用到的aipp
(6)--input_format=NCHW 这个将输入图片转化为想要的尺寸
模型转换成功如下:

2.4 开始推理
进入src文件夹执行如下命令:
c
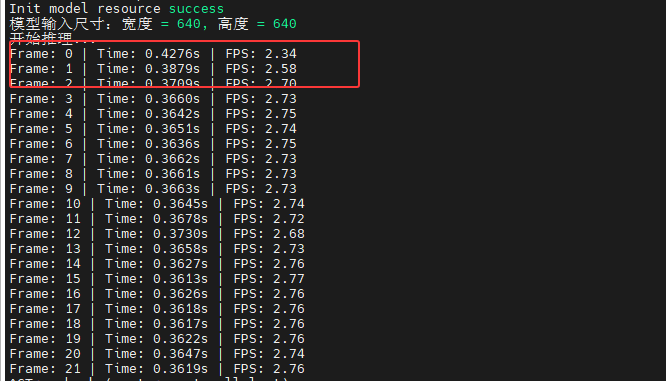
python yolo11_ascend_video.py --model-path ../model/yolo11x.om推理结果及帧数如下所示:
3 总结
本章节介绍了将要部署到香橙派AI Pro的车辆检测工程文件,但是可以看到检测帧数还是比较低,接下来将会使用AIPP和DVPP进行进一步的优化。