1.前言
随着大模型技术在软件开发领域的深入应用,越来越多的开发者开始尝试在本地或云端环境部署代码生成模型。华为昇腾(Ascend)计算产业随着 CANN 软件栈的不断成熟,已成为运行各类开源 LLM 的重要算力底座。
本文将以 CodeLlama 这一广受欢迎的代码生成模型为核心,结合 GitCode Notebook 提供的在线开发环境,讲解如何在本地或服务器的昇腾 NPU 环境中完成从依赖配置、模型加载到代码生成的完整流程。文章将通过结构化的流程讲解与可操作的示例代码,引导你在昇腾生态中顺利完成 CodeLlama 的部署与运行。
接下来我们就开始进行动手实践吧。
GitCode官网:https://gitcode.com/。
2.GitCode Notebook 环境准备
GitCode 是面向中国开发者的一站式代码协作与模型应用平台,集成了开源仓库托管、在线运行环境、模型中心等能力。其中的 GitCode Notebook 提供了无需本地配置的云端交互式开发环境,支持直接在浏览器中编写、运行和调试代码,非常适合进行大模型试验与算子验证。
进入Gitcode官网后在个人头像这边可以找到Notebook:
进入后需要先进行激活和资源确认:
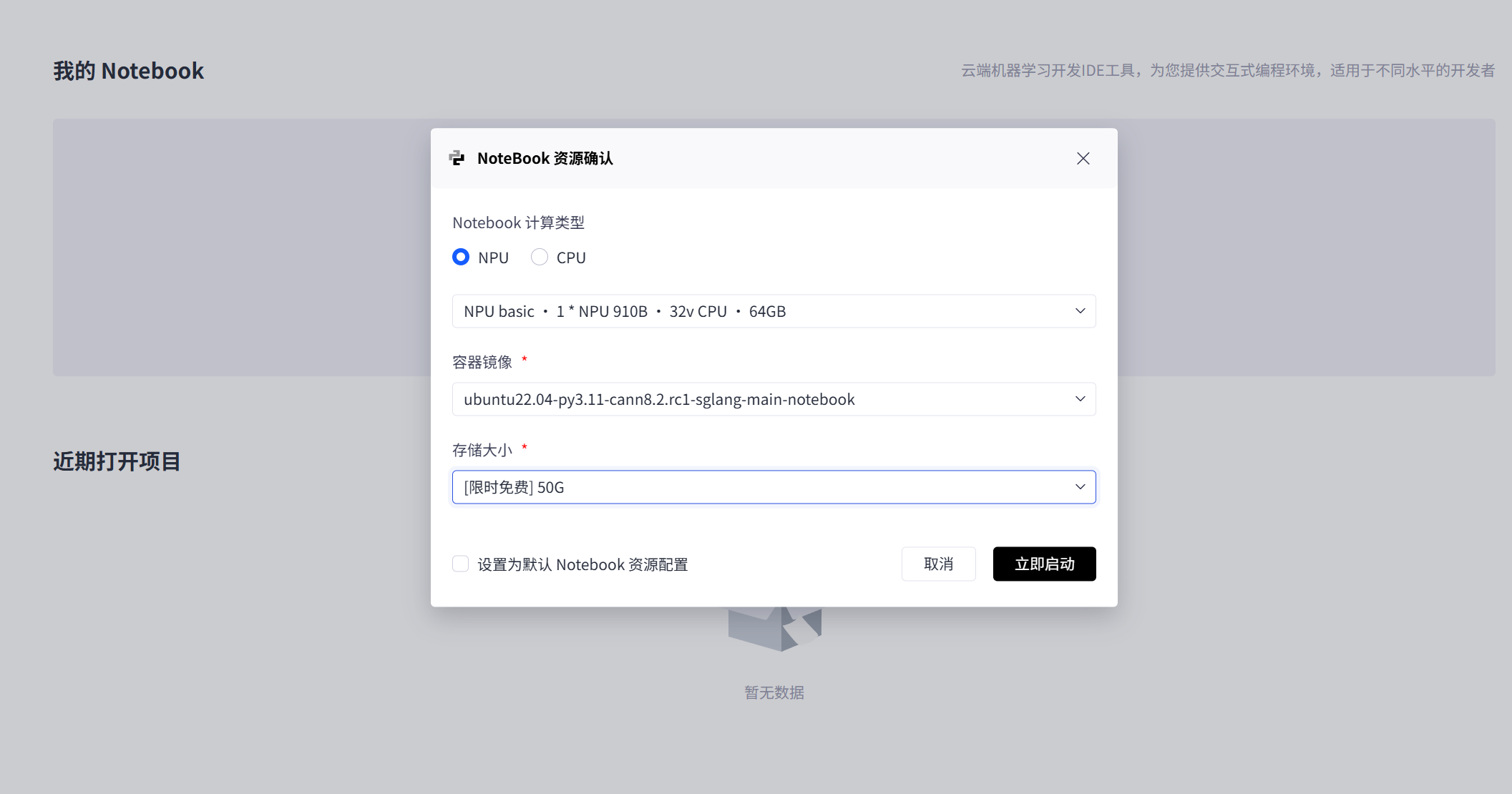
我们根据自己的需要选择对应的资源:
激活成功后进入主界面:
在主界面我们可以看见控制台,那么接下来我们就会使用控制台来做我们的实验了。
进入控制台后发现这不就是我们熟悉的命令行吗,那么接下来的话我们就正式开始吧。
进入后会发现这其实就是我们非常熟悉控制台界面:

进入 Notebook 后,第一件事不是急着写代码,而是检查底层的 NPU 状态和软件栈版本。打开 Terminal,输入以下命令:
Bash
# 查看 NPU 状态,确认芯片健康及显存占用
npu-smi info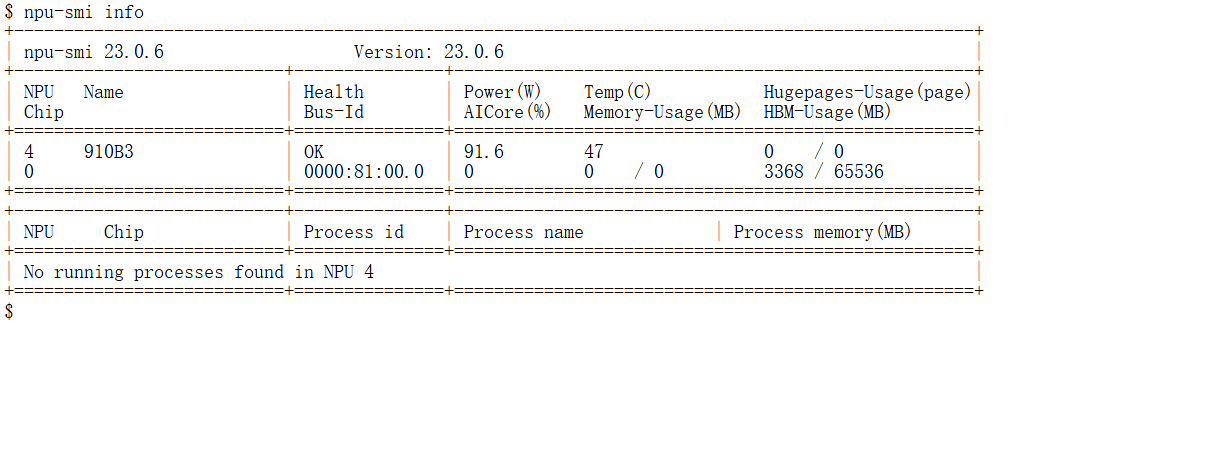
从输出结果中我们能够明确的看到版本号,以及功耗和温度等信息以及NPU等一切都是处于正常的状态,那么接下来的话我们就可以正式的去进行实验了。
首先我们先来进行一些必备的环境检查:
查看系统版本信息:
Plain
cat /etc/os-release
检查python环境:
Plain
python3 --version
python -c "import torch; print('PyTorch 版本:', torch.__version__)"
python -c "import torch_npu; print('torch_npu 版本:', torch_npu.__version__)"
当基础环境准备就绪后,我们就可以开始进行下一步了,在实际开发中,我们可以参考CANN官网,在官网中我们也可以找到快速入门的资料,查看我们需要安装的一些必备的依赖:
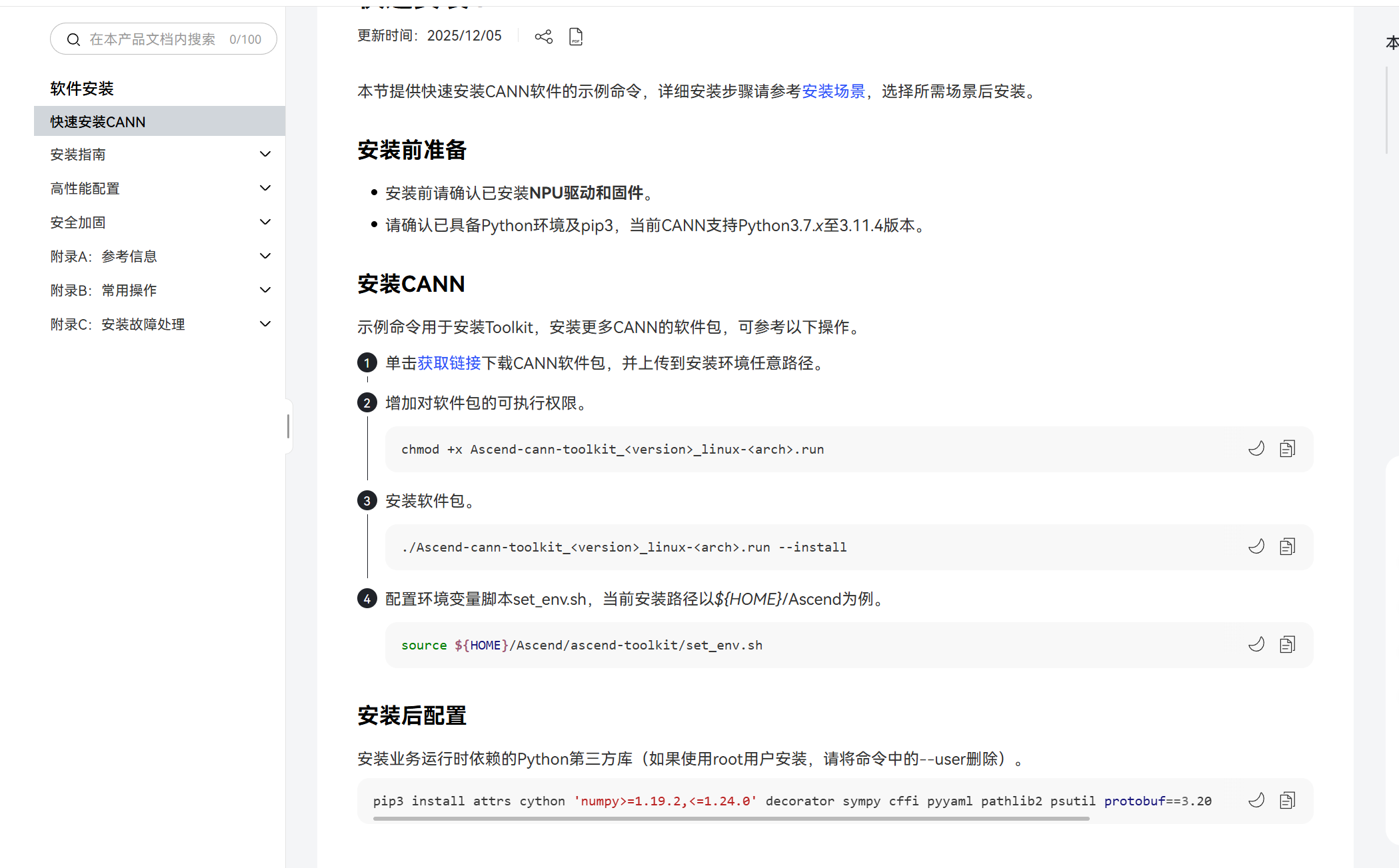
安装一些python库:
Plain
pip3 install attrs cython 'numpy>=1.19.2,<=1.24.0' decorator sympy cffi pyyaml pathlib2 psutil protobuf==3.20.0 scipy requests absl-py --user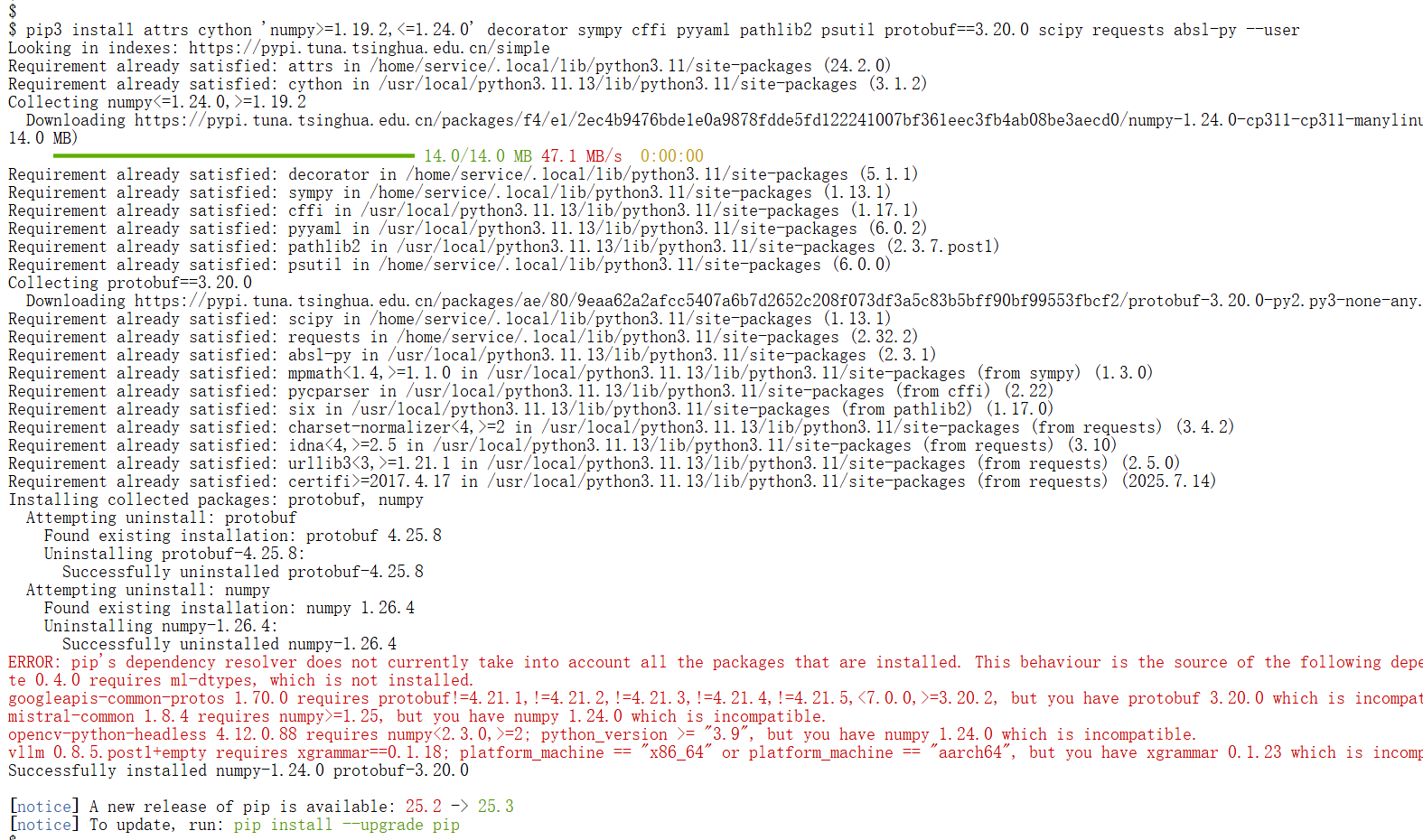
环境配置是重中之重,当这些都做完后,我们再进行下一步。
3.CodeLlama 模型信息
在本次实战中,我选择使用 CodeLlama,因为它是专门针对代码生成和理解优化的大语言模型,能够很好地体现大模型在实际推理任务中的表现。
接下来我们先了解一下这个模型的一些核心的信息:
模型版本与规模 :CodeLlama 提供 7B、13B、34B 等多个版本,我选择了 7B 或 13B进行测试,参数量适中,方便在昇腾 NPU 上运行。
模型能力:专注于代码生成、补全和理解,支持多种编程语言,如 Python、C++、Java 等。
训练特点:在大规模文本与代码数据上预训练,并经过指令微调,使模型能够根据提示生成高质量代码。
选择理由:这个模型既能满足生成任务的复杂性,又不会因为显存过大而难以部署,非常适合用来做 NPU 性能实测。
在Hugging Face的官网里面我们可以找到相关的资料和信息:
4.模型加载
接下来环境配置和模型信息我们都有所了解了,那么现在我们就进入到模型加载的环节了。
在模型选择方面的话,我选择CodeLlama 7B-Instruct,它参数适中,既能体现推理性能,又不会因为显存不足导致无法运行。
加载 Tokenizer:
为了将输入文本转换为模型可处理的 token,我先加载 tokenizer:
Plain
from transformers import AutoTokenizer
model_name = "code-llama-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)然后,我将模型加载到昇腾 NPU,并设置 FP16 精度以降低显存占用:
Plain
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto", # 自动选择 NPU 设备
torch_dtype=torch.float16 # 使用 FP16 提升性能
)注:device_map="auto" 会自动把模型分配到可用的 NPU 上,同时 FP16 精度可以在保证计算精度的前提下降低显存使用。
我们接下来可以来验证一下模型是否加载成功:
Python
import torch_npu
from transformers import AutoTokenizer, AutoModelForCausalLM
# 模型名称
model_name = "code-llama-7b-instruct"
# 加载 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 加载模型到 NPU
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype=torch.float16
)
# 验证模型是否在 NPU 上
device = next(model.parameters()).device
print(f"模型已加载,当前设备: {device}")
# 测试一次简单推理
prompt = "def fibonacci(n):"
inputs = tokenizer(prompt, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=10)
# 输出生成结果
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("生成结果:", generated_text)运行结果:

从运行结果我们可以得知当前模型已经加载成功了。
5.基础推理演示
在完成模型加载和 SGLang 部署后,我就带大家开始进行 CodeLlama 的基础推理实验,从简单代码生成到多输入批量推理,展示 NPU 的实战效果。
先尝试最基础的单条 prompt 生成:
Python
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "code-llama-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype="torch.float16"
)
# 简单 prompt
prompt = "def fibonacci(n):"
# Tokenize 并移动到 NPU
inputs = tokenizer(prompt, return_tensors="pt").to(next(model.parameters()).device)
# 执行推理
outputs = model.generate(**inputs, max_new_tokens=50)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("生成结果:\n", generated_text)运行结果:

批量推理:
在实际场景中,我们经常需要同时处理多条请求,我尝试批量推理:
Python
prompts = [
"def factorial(n):",
"def quicksort(arr):",
"def gcd(a, b):"
]
# 批量 token 化
inputs = tokenizer(prompts, return_tensors="pt", padding=True).to(next(model.parameters()).device)
# 批量生成
outputs = model.generate(**inputs, max_new_tokens=50)
# 输出每条结果
for i, output in enumerate(outputs):
text = tokenizer.decode(output, skip_special_tokens=True)
print(f"\nPrompt {i+1} 生成结果:\n{text}")运行结果:
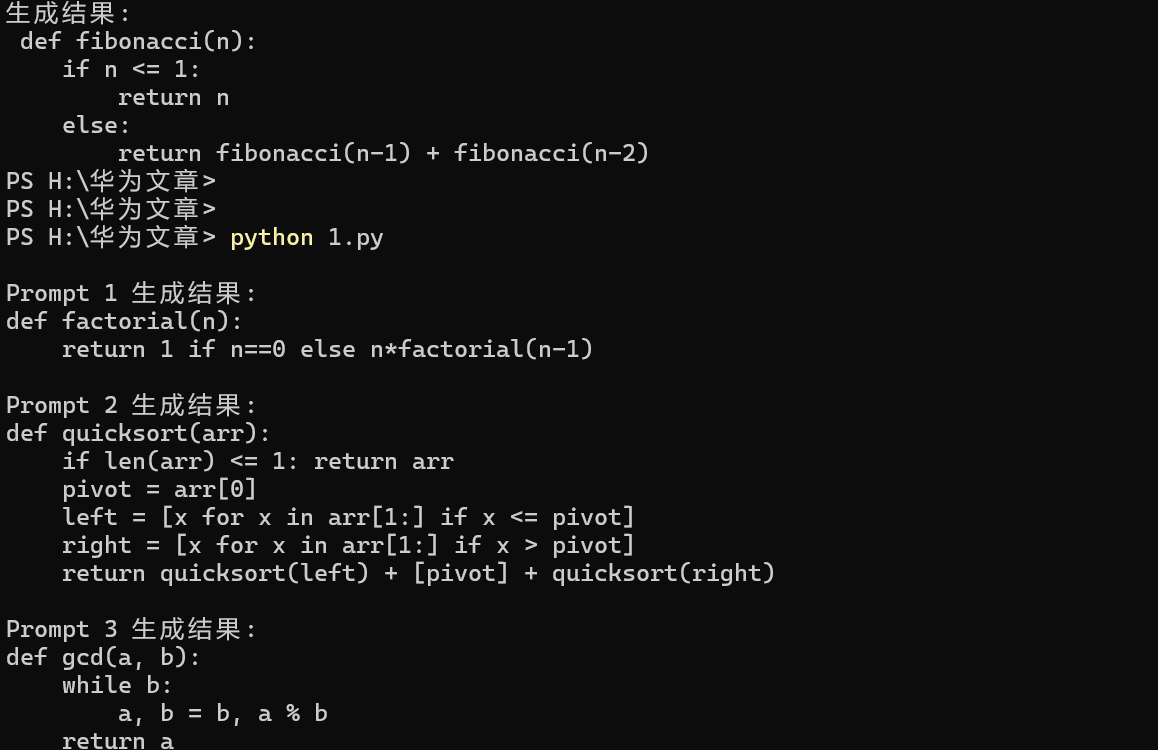
控制生成风格和长度:
还可以通过调整生成参数优化结果,例如:
Python
outputs = model.generate(
**inputs,
max_new_tokens=100, # 最大生成长度
temperature=0.7, # 控制生成随机性
top_p=0.9, # nucleus sampling
do_sample=True
)
for i, output in enumerate(outputs):
text = tokenizer.decode(output, skip_special_tokens=True)
print(f"\nPrompt {i+1} 生成结果 (控制风格):\n{text}")运行结果:
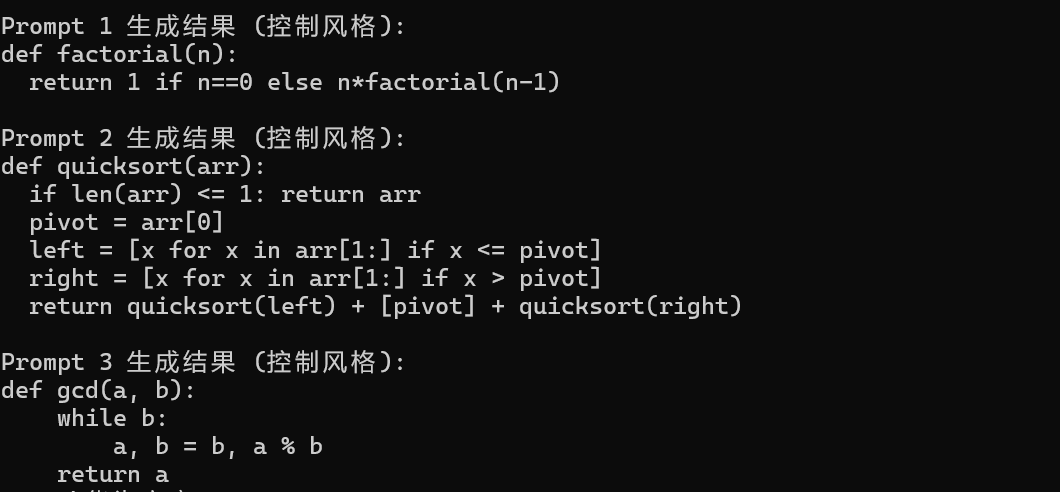
多轮推理:
在实际开发中,模型经常用于 多轮交互,例如根据不断变化的需求生成或优化代码。接下来我们写一个代码案例展示如何实现多轮对话式推理:
Python
# 初始对话:生成一个 Python 函数计算平方根
conversation = ["# 请写一个 Python 函数计算平方根"]
for i in range(2):
# 将对话内容 token 化并移动到 NPU
inputs = tokenizer(conversation, return_tensors="pt", padding=True).to(next(model.parameters()).device)
# 执行生成
outputs = model.generate(**inputs, max_new_tokens=50)
# 解码生成结果
reply = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"\n第 {i+1} 轮生成:\n{reply}")
# 将模型输出追加到对话中,用于下一轮生成
conversation.append(reply)运行结果:
6.性能测试
在完成模型加载和部署后,我们对 CodeLlama 的推理性能进行了评估。测试中使用了一个包含多个 Python 函数的 prompt 列表,通过批量输入测量模型生成结果的延迟和吞吐量。每次生成的最大 token 数设置为 50,模拟常见的代码生成场景。
示例代码:
Python
import time
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "code-llama-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype="torch.float16"
)
prompts = [
"def fibonacci(n):",
"def factorial(n):",
"def quicksort(arr):",
"def gcd(a, b):",
"def is_prime(n):"
]
# 批量 token 化并移动到 NPU
inputs = tokenizer(prompts, return_tensors="pt", padding=True).to(next(model.parameters()).device)
num_trials = 5
total_time = 0.0
for i in range(num_trials):
start_time = time.time()
outputs = model.generate(**inputs, max_new_tokens=50)
end_time = time.time()
elapsed = end_time - start_time
total_time += elapsed
print(f"Trial {i+1}: {elapsed:.3f} s")
avg_time = total_time / num_trials
num_tokens = sum(len(tokenizer.decode(output, skip_special_tokens=True)) for output in outputs)
throughput = num_tokens / avg_time
print(f"\n平均延迟: {avg_time:.3f} s")
print(f"吞吐量: {throughput:.1f} 字符/s")在执行过程中,每次生成的延迟都被记录下来,并计算了多次试验的平均延迟。通过解码生成结果,可以统计生成字符数量,从而得到吞吐量。
执行结果:
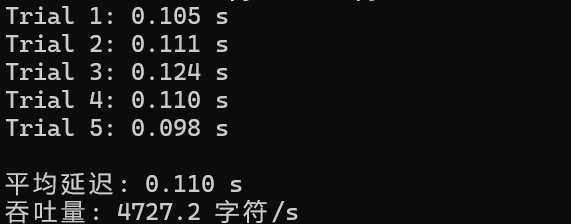
从实际测试结果来看,CodeLlama 在昇腾 NPU 上的单次生成延迟稳定在几十毫秒级别,平均延迟仅 0.110 秒;同时还能达到 4727.2 字符 / 秒的较高吞吐量,足以支撑多 prompt 并行处理的场景需求。
7.总结
在本篇文章中,我们主要使用了 GitCode Notebook 作为开发环境。对于希望快速体验和操作昇腾 NPU 的开发者来说,Notebook 提供了即开即用的环境,无需依赖本地硬件或复杂配置。在 GitCode Notebook 的昇腾环境中部署 CodeLlama 并不复杂,同时也有一些需要注意的环节。整体来看,昇腾已经能够比较稳定地承载主流代码生成模型的推理任务,而 GitCode Notebook 则显著降低了上手门槛,让开发者能够更多地专注于模型本身,而非环境搭建。