kubernetes弹性伸缩
水平自动伸缩 HPA
介绍
HPA(Horizontal Pod Autoscaler,Pod 水平自动伸缩)是 Kubernetes 原生的弹性伸缩组件,核心作用是基于监控指标动态调整 Deployment/ReplicaSet/ReplicationController 的 Pod 副本数,实现 "负载高时扩容、负载低时缩容",最终优化资源利用率、保障服务稳定性。
其核心特性:
- 适配对象:仅支持可扩缩的控制器(Deployment/ReplicaSet/ReplicationController),不支持 DaemonSet(每个节点固定 1 个 Pod,无法扩缩)、StatefulSet(需额外配置适配,原生支持有限);
- 扩缩逻辑:由 HPA 控制器周期性(默认 15 秒)检查指标,对比 "当前指标值" 与 "目标指标值",计算合理的副本数并执行调整;
- 指标支持:从基础的 CPU / 内存,到自定义业务指标,覆盖绝大多数生产场景。
核心监控指标
Resource Metrics(资源指标,最基础)
- 核心指标:CPU 利用率、内存使用率(基于容器申请的
resources.requests计算,而非节点实际资源); - 计算逻辑:例如 CPU 利用率 = Pod 实际使用 CPU / Pod 申请的 CPU 限额(如申请 1 核,实际用 0.8 核,则利用率 80%);
- 适用场景:通用服务的基础弹性(如 Web 服务、API 服务的常规负载波动)。
Pod Metrics(Pod 级指标)
- 核心指标:Pod 网络吞吐量(入 / 出站流量)、网络连接数、磁盘 I/O 等;
- 依赖条件:需部署 metrics-server 或 Prometheus 等监控组件采集 Pod 级指标;
- 适用场景:网络密集型服务(如网关、文件传输服务),根据流量动态扩缩。
Object Metrics(对象级指标)
- 核心指标:针对特定 Kubernetes 对象的聚合指标(如 Ingress 的每秒请求数(RPS)、Service 的连接数);
- 计算逻辑:基于对象的总指标分摊到每个 Pod,触发扩缩(如 Ingress 总 RPS 1000,当前 5 个 Pod,目标每 Pod 承担 200 RPS,若总 RPS 涨到 2000,则扩容到 10 个 Pod);
- 适用场景:入口层服务(如 Ingress 后端的 Web 集群),按访问量弹性调整。
Custom Metrics(自定义指标,业务化)
- 核心指标:业务自定义监控指标(如接口响应时间(P95/P99)、订单提交成功率、队列堆积数);
- 实现方式:通过 Prometheus + Custom Metrics API 或 Kubernetes 自定义指标适配器(如 kube-metrics-adapter)暴露指标;
- 适用场景:需基于业务健康度扩缩的场景(如秒杀场景下响应时间超过 500ms 时扩容,队列堆积超过 1000 条时扩容)。
工作流程
- 部署监控组件(如 metrics-server 采集资源指标,Prometheus 采集自定义指标),确保指标能被 Kubernetes API 访问;
- 创建 HPA 资源,配置目标控制器(如 Deployment)、目标指标(如 CPU 利用率 70%)、扩缩容上下限(如最小 2 个 Pod,最大 10 个 Pod);
- HPA 控制器定期(默认 15 秒)从监控组件获取指标,计算当前平均指标值;
- 对比当前值与目标值:
- 若当前值 > 目标值(如 CPU 利用率 90% > 目标 70%),则计算需扩容的副本数(如从 2 个扩到 3 个);
- 若当前值 < 目标值(如 CPU 利用率 30% < 目标 70%),则计算需缩容的副本数(如从 3 个缩到 2 个);
- HPA 调用 Kubernetes API,修改目标控制器的
replicas字段,触发 Pod 扩缩容。
核心配置
- 扩缩容上下限(minReplicas/maxReplicas):
- 必须配置,避免无限制扩缩(如
minReplicas: 2保证基础可用性,maxReplicas: 10控制资源开销);
- 必须配置,避免无限制扩缩(如
- 指标阈值:
- 资源指标建议:CPU 利用率 70%-80%(预留缓冲),内存利用率 80%-90%(避免 OOM);
- 自定义指标建议:结合业务峰值(如响应时间 P95 < 500ms,队列堆积 < 500 条);
- 扩缩容冷却时间(默认无,生产建议配置):
- 扩容冷却(
scaleUpStabilizationWindowSeconds):避免短时间内频繁扩容(如配置 300 秒,扩容后 5 分钟内不再次扩容); - 缩容冷却(
scaleDownStabilizationWindowSeconds):避免负载短暂下降导致误缩容(如配置 600 秒,缩容后 10 分钟内不再次缩容);
- 扩容冷却(
- 指标容忍度(
tolerance):允许指标小幅波动(如 CPU 利用率 70%±5% 内不触发扩缩,减少抖动)。
生产实践注意事项
- 依赖监控组件:必须部署 metrics-server(资源指标)或 Prometheus + 自定义指标适配器(Pod / 对象 / 自定义指标),否则 HPA 无法获取数据,会处于 "Unknown" 状态;
- Pod 必须配置
resources.requests:资源指标(CPU / 内存)的计算基于requests,未配置则 HPA 无法计算利用率; - 避免频繁扩缩(抖动):通过冷却时间、容忍度配置,减少短时间内负载波动导致的 "扩缩 - 缩扩" 循环;
- 有状态服务适配:StatefulSet 支持 HPA,但需注意存储(如 PVC 动态供应)、网络(如固定域名)是否能适配副本数变化,建议仅在无状态服务优先使用 HPA;
- 结合其他弹性策略:HPA 是 "水平扩缩"(增加 Pod 数量),可搭配 "垂直扩缩"(VPA,调整 Pod 资源限额),但生产中建议优先 HPA(更稳定,不中断服务)。
metircs-server
metrics-server 是 Kubernetes 官方提供的轻量级核心监控组件 ,并非全量监控系统,核心职责是采集集群资源指标并提供统一查询接口,是 HPA(水平自动伸缩)、kubectl top 命令的依赖基础,支撑集群原生弹性伸缩和基础资源监控能力。
核心功能
-
采集集群资源指标
专门采集节点(Node)和 Pod 的核心资源使用数据,仅聚焦于CPU 利用率 / 用量、内存利用率 / 用量(基于 Pod/Node 的resources.requests/limits计算),不采集网络、磁盘等非核心指标,也不采集业务自定义指标。
-
提供标准化 Metrics API 接口
通过 Kubernetes Aggregated API(聚合层 API)暴露metrics.k8s.io接口,供 HPA 控制器、kubectl top命令、其他运维工具调用,实现指标统一查询。
-
轻量高效的指标缓存
指标数据仅在内存中短期缓存(默认保留几分钟),不做持久化存储,无需依赖外部存储(如 Prometheus 的 TSDB),资源占用极低(仅需少量 CPU 和内存),适合集群基础监控场景。
核心依赖关系 :metrics-server 是 HPA 实现资源指标伸缩的必备组件 ,无 metrics-server 则 HPA 无法获取 CPU / 内存指标,会处于 Unknown 状态;
bash
#验证有没有安装metrics-server
#已经安装过了
[root@master session]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-658d97c59c-tk2pk 1/1 Running 19 (2d18h ago) 17d
calico-node-7c5d5 1/1 Running 0 91m
calico-node-bx9tp 1/1 Running 0 91m
calico-node-m5kkc 1/1 Running 0 92m
coredns-66f779496c-26pcb 1/1 Running 19 (2d18h ago) 17d
coredns-66f779496c-wpc57 1/1 Running 19 (2d18h ago) 17d
etcd-master 1/1 Running 19 (2d18h ago) 17d
kube-apiserver-master 1/1 Running 33 (108m ago) 17d
kube-controller-manager-master 1/1 Running 24 (108m ago) 17d
kube-proxy-cd8gk 1/1 Running 19 (2d18h ago) 17d
kube-proxy-q8prd 1/1 Running 19 (2d18h ago) 17d
kube-proxy-xtfxw 1/1 Running 19 (2d18h ago) 17d
kube-scheduler-master 1/1 Running 19 (2d18h ago) 17d
metrics-server-57999c5cf7-bxjn7 1/1 Running 21 (2d18h ago) 16d
#可以使用top命令查看nodes节点状态
[root@master session]# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master 260m 6% 1616Mi 44%
node1 130m 3% 1007Mi 27%
node2 120m 3% 966Mi 26% HPA案例实战
创建nginx的应用及服务
bash
[root@master ~]# mkdir hpa
[root@master ~]# cd hpa/
[root@master hpa]#
[root@master hpa]#
[root@master hpa]# rz -E
rz waiting to receive.
[root@master hpa]# cat nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: c1
image: nginx:1.26-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
#资源限制
resources:
requests:
cpu: 200m
memory: 100Mi
---
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
selector:
app: nginx
[root@master hpa]# kubectl apply -f nginx.yaml
deployment.apps/nginx created
service/nginx-svc created
[root@master hpa]# kubectl get pods,svc
NAME READY STATUS RESTARTS AGE
pod/nginx-7d7db64798-72xhw 1/1 Running 0 15s
pod/nginx-7d7db64798-rkg6h 1/1 Running 0 15s
pod/nginx-nodeport-7f87fb64cc-gmk2k 1/1 Running 2 (2d21h ago) 3d22h
pod/nginx-nodeport-7f87fb64cc-ps2q6 1/1 Running 2 (2d21h ago) 3d22h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 17d
service/nginx NodePort 10.109.182.190 <none> 80:30578/TCP 17d
service/nginx-nodeport-svc NodePort 10.97.212.112 <none> 80:31111/TCP 3d22h
service/nginx-svc NodePort 10.103.163.68 <none> 80:32013/TCP 15s
创建HPA对象
这是一个 HorizontalPodAutoscaler(HPA)对象的配置,它将控制Deployment "nginx"的副本数量。当 CPU使用率超过50%时,HPA将自 动增加 Pod 的副本数量,最高不超过10个。
bash
[root@master hpa]# cat nginx-hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
spec:
minReplicas: 1
maxReplicas: 10
#关联控制器
scaleTargetRef:
kind: Deployment
name: nginx
apiVersion: apps/v1
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
[root@master hpa]# kubectl get hpa
No resources found in default namespace.
[root@master hpa]# kubectl apply -f nginx-hpa.yaml
horizontalpodautoscaler.autoscaling/nginx-hpa created
[root@master hpa]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-hpa Deployment/nginx <unknown>/50% 1 10 0 5s
[root@master hpa]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-7d7db64798-72xhw 1/1 Running 0 60s
nginx-7d7db64798-rkg6h 1/1 Running 0 60s执行压测
bash
#安装必备工具
[root@master hpa]# yum install -y httpd-tools
#开始压测
#刚输完
[root@master hpa]# ab -c 1000 -n 1000000 http://192.168.100.72:32013/
This is ApacheBench, Version 2.3 <$Revision: 1430300 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 192.168.100.72 (be patient)
#一会后
[root@master hpa]# ab -c 1000 -n 1000000 http://192.168.100.72:32013/
This is ApacheBench, Version 2.3 <$Revision: 1430300 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 192.168.100.72 (be patient)
Completed 100000 requests
Completed 200000 requests
Completed 300000 requests
Completed 400000 requests
Completed 500000 requests
#看变化
Every 2.0s: kubectl get pods Mon Dec 1 11:24:34 2025
NAME READY STATUS RESTARTS AGE
nginx-7d7db64798-cpffh 1/1 Running 0 12m
nginx-7d7db64798-r98qp 1/1 Running 0 12m
#一会后
Every 2.0s: kubectl get pods Mon Dec 1 13:43:56 2025
NAME READY STATUS RESTARTS AGE
nginx-7d7db64798-4v678 1/1 Running 0 13s
nginx-7d7db64798-72xhw 1/1 Running 0 8m57s
nginx-7d7db64798-mlm8t 1/1 Running 0 13s
#再一会后
Every 2.0s: kubectl get pods Mon Dec 1 13:45:33 2025
NAME READY STATUS RESTARTS AGE
nginx-7d7db64798-4v678 1/1 Running 0 110s
nginx-7d7db64798-72xhw 1/1 Running 0 10m
nginx-7d7db64798-mlm8t 1/1 Running 0 110s
nginx-7d7db64798-msqm9 1/1 Running 0 4s案例:通过Prometheus及HPA实现kubernetes应用水平 自动伸缩
metircs-server部署环境
bash
#前置安装过了,验证
[root@master ~]# kubectl top pods -n kube-system
NAME CPU(cores) MEMORY(bytes)
calico-kube-controllers-658d97c59c-tk2pk 4m 72Mi
calico-node-7c5d5 41m 214Mi
calico-node-bx9tp 64m 207Mi
calico-node-m5kkc 58m 205Mi
coredns-66f779496c-26pcb 2m 64Mi
coredns-66f779496c-wpc57 2m 17Mi
etcd-master 39m 406Mi
kube-apiserver-master 82m 410Mi
kube-controller-manager-master 35m 173Mi
kube-proxy-cd8gk 30m 79Mi
kube-proxy-q8prd 27m 79Mi
kube-proxy-xtfxw 23m 81Mi
kube-scheduler-master 5m 77Mi
metrics-server-57999c5cf7-bxjn7 8m 87Mi
[root@master ~]# kubectl edit configmap kube-proxy -n kube-system
......
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
strictARP: true #修改为true
#重启kube-proxy
[root@master ~]# kubectl rollout restart daemonset kube-proxy -n kube-system
daemonset.apps/kube-proxy restartedmetallb部署
bash
[root@master hpa]# kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.15.2/config/manifests/metallb-native.yamlnamespace/metallb-system created
customresourcedefinition.apiextensions.k8s.io/bfdprofiles.metallb.io unchanged
customresourcedefinition.apiextensions.k8s.io/bgpadvertisements.metallb.io unchanged
customresourcedefinition.apiextensions.k8s.io/bgppeers.metallb.io unchanged
customresourcedefinition.apiextensions.k8s.io/communities.metallb.io unchanged
customresourcedefinition.apiextensions.k8s.io/ipaddresspools.metallb.io unchanged
customresourcedefinition.apiextensions.k8s.io/l2advertisements.metallb.io unchanged
customresourcedefinition.apiextensions.k8s.io/servicebgpstatuses.metallb.io unchanged
customresourcedefinition.apiextensions.k8s.io/servicel2statuses.metallb.io unchanged
serviceaccount/controller created
serviceaccount/speaker created
role.rbac.authorization.k8s.io/controller created
role.rbac.authorization.k8s.io/pod-lister created
clusterrole.rbac.authorization.k8s.io/metallb-system:controller unchanged
clusterrole.rbac.authorization.k8s.io/metallb-system:speaker unchanged
rolebinding.rbac.authorization.k8s.io/controller created
rolebinding.rbac.authorization.k8s.io/pod-lister created
clusterrolebinding.rbac.authorization.k8s.io/metallb-system:controller unchanged
clusterrolebinding.rbac.authorization.k8s.io/metallb-system:speaker unchanged
configmap/metallb-excludel2 created
secret/metallb-webhook-cert created
service/metallb-webhook-service created
deployment.apps/controller created
daemonset.apps/speaker created
validatingwebhookconfiguration.admissionregistration.k8s.io/metallb-webhook-configuration configured配置二层网络
bash
[root@master hpa]# cat ipaddresspool.yaml
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: first-pool
namespace: metallb-system
spec:
addresses:
- 192.168.100.210-192.168.100.220
#开启二层通告
[root@master hpa]# cat l2.yaml
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: example
namespace: metallb-system
#应用前,查看环境是否准备就绪
[root@master hpa]# kubectl get pods -n metallb-system
NAME READY STATUS RESTARTS AGE
controller-8666ddd68b-k75b9 1/1 Running 0 5m11s
speaker-492qf 1/1 Running 0 5m11s
speaker-dpbhf 1/1 Running 0 5m11s
speaker-hz9xn 1/1 Running 0 5m11s
[root@master hpa]# kubectl apply -f ipaddresspool.yaml -f l2.yaml
ipaddresspool.metallb.io/first-pool created
l2advertisement.metallb.io/example created
#查看地址池
[root@master hpa]# kubectl get ipaddresspool -n metallb-system
NAME AUTO ASSIGN AVOID BUGGY IPS ADDRESSES
first-pool true false ["192.168.100.210-192.168.100.220"]ingress nginx部署
bash
#获取ingress nginx部署文件
[root@master new]# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.13.2/deploy/static/provider/cloud/deploy.yaml
--2025-12-01 14:32:09-- https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.13.2/deploy/static/provider/cloud/deploy.yaml
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.109.133, 185.199.110.133, 185.199.108.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.109.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 16384 (16K) [text/plain]
Saving to: 'deploy.yaml'
100%[========================================================================================>] 16,384 6.73KB/s in 2.4s
2025-12-01 14:32:27 (6.73 KB/s) - 'deploy.yaml' saved [16384/16384]
[root@master new]# ls
deploy.yaml ipaddresspool.yaml l2.yaml
[root@master new]# vim deploy.yaml
...
spec:
externalTrafficPolicy: Cluster #347行位置把Local修改为Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
...
[root@master new]# kubectl apply -f deploy.yaml
namespace/ingress-nginx created
serviceaccount/ingress-nginx created
serviceaccount/ingress-nginx-admission created
role.rbac.authorization.k8s.io/ingress-nginx created
role.rbac.authorization.k8s.io/ingress-nginx-admission created
clusterrole.rbac.authorization.k8s.io/ingress-nginx created
clusterrole.rbac.authorization.k8s.io/ingress-nginx-admission created
rolebinding.rbac.authorization.k8s.io/ingress-nginx created
rolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
configmap/ingress-nginx-controller created
service/ingress-nginx-controller created
service/ingress-nginx-controller-admission created
deployment.apps/ingress-nginx-controller created
job.batch/ingress-nginx-admission-create created
job.batch/ingress-nginx-admission-patch created
ingressclass.networking.k8s.io/nginx created
validatingwebhookconfiguration.admissionregistration.k8s.io/ingress-nginx-admission created
[root@master new]# kubectl get ns
NAME STATUS AGE
default Active 18d
ingress-nginx Active 5s #已创建
kube-node-lease Active 18d
kube-public Active 18d
kube-system Active 18d
kubernetes-dashboard Active 16d
metallb-system Active 29m
ns1 Active 2d23h
ns2 Active 2d23h
#等待创建
Every 2.0s: kubectl get pod -n ingress-nginx Mon Dec 1 14:38:24 2025
NAME READY STATUS RESTARTS AGE
ingress-nginx-admission-create-mhsqt 0/1 ErrImagePull 0 5m21s
ingress-nginx-admission-patch-fk9xl 0/1 ErrImagePull 0 5m21s
ingress-nginx-controller-555c8f5ff6-dblc6 0/1 ContainerCreating 0 5m21s
#可以了
Every 2.0s: kubectl get pod -n ingress-nginx Mon Dec 1 14:42:26 2025
NAME READY STATUS RESTARTS AGE
ingress-nginx-controller-555c8f5ff6-dblc6 0/1 Running 0 9m23s
#验证结果
[root@master new]# kubectl get pods,svc -n ingress-nginx
NAME READY STATUS RESTARTS AGE
pod/ingress-nginx-controller-555c8f5ff6-dblc6 1/1 Running 0 10m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/ingress-nginx-controller LoadBalancer 10.111.103.215 192.168.100.210 80:30222/TCP,443:31186/TCP 10m
service/ingress-nginx-controller-admission ClusterIP 10.102.209.189 <none> 443/TCP 10m
[root@master new]# kubectl get all -n ingress-nginx
NAME READY STATUS RESTARTS AGE
pod/ingress-nginx-controller-555c8f5ff6-dblc6 1/1 Running 0 56m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/ingress-nginx-controller LoadBalancer 10.111.103.215 192.168.100.210 80:30222/TCP,443:31186/TCP 56m
service/ingress-nginx-controller-admission ClusterIP 10.102.209.189 <none> 443/TCP 56m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/ingress-nginx-controller 1/1 1 1 56m
NAME DESIRED CURRENT READY AGE
replicaset.apps/ingress-nginx-controller-555c8f5ff6 1 1 1 56m
#去节点验证
#webhook两个节点都要存在
#controller只有一个节点就可以了
[root@node1 ~]# docker images | grep ingress
registry.k8s.io/ingress-nginx/kube-webhook-certgen <none> 8c217da6734d 3 months ago 70MB
[root@node2 ~]# docker images | grep ingress
registry.k8s.io/ingress-nginx/controller <none> 1bec18b3728e 3 months ago 324MB
registry.k8s.io/ingress-nginx/kube-webhook-certgen <none> 8c217da6734d 3 months ago 70MBPrometheus部署
helm添加Prometheus仓库
bash
[root@master new]# rz -E
rz waiting to receive.
[root@master new]# tar zxvf helm-v3.19.0-linux-amd64.tar.gz
linux-amd64/
linux-amd64/README.md
linux-amd64/LICENSE
linux-amd64/helm
[root@master new]# cd linux-amd64/
[root@master linux-amd64]# ls
helm LICENSE README.md
[root@master linux-amd64]# mv helm /usr/bin/
[root@master linux-amd64]# helm version
version.BuildInfo{Version:"v3.19.0", GitCommit:"3d8990f0836691f0229297773f3524598f46bda6", GitTreeState:"clean", GoVersion:"go1.24.7"}添加helm包的仓库源
bash
[root@master linux-amd64]# helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
"prometheus-community" has been added to your repositories
#查看资源路径
[root@master linux-amd64]# helm repo list
NAME URL
prometheus-community https://prometheus-community.github.io/helm-charts
#仓库软件更新
[root@master linux-amd64]# helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "prometheus-community" chart repository
Update Complete. ⎈Happy Helming!⎈使用helm安装Prometheus全家桶
bash
[root@master linux-amd64]# cd ..
[root@master new]#
[root@master new]#
[root@master new]# mkdir promedir
[root@master new]# cd promedir/
[root@master promedir]# helm show values prometheus-community/kube-prometheus-stack --version 79.11.0 > kube-prometheus-stack.yaml
[root@master promedir]# ls
kube-prometheus-stack.yaml
[root@master promedir]# vim kube-prometheus-stack.yaml
...
serviceMonitorSelectorNilUsesHelmValues: false #4138行
#安装部署Prometheus,命名为kps
[root@master promedir]# helm install kps prometheus-community/kube-prometheus-stack --version 79.11.0 -f ./kube-prometheus-stack.yaml -n monitoring --create-namespace --debug
#检查资源
[root@master promedir]# kubectl --namespace monitoring get pods -l "release=kps"
NAME READY STATUS RESTARTS AGE
kps-kube-prometheus-stack-operator-c9ffdc7d-27v69 1/1 Running 0 4m16s
kps-kube-state-metrics-bcd5b8dfc-9b22c 1/1 Running 0 4m16s
kps-prometheus-node-exporter-mxkqg 1/1 Running 0 4m16s
kps-prometheus-node-exporter-nzrxl 1/1 Running 0 4m16s
kps-prometheus-node-exporter-snbkd 1/1 Running 0 4m16s
[root@master promedir]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 2m11s
kps-grafana ClusterIP 10.107.2.9 <none> 80/TCP 4m32s
kps-kube-prometheus-stack-alertmanager ClusterIP 10.111.53.144 <none> 9093/TCP,8080/TCP 4m32s
kps-kube-prometheus-stack-operator ClusterIP 10.97.110.234 <none> 443/TCP 4m32s
kps-kube-prometheus-stack-prometheus ClusterIP 10.111.185.159 <none> 9090/TCP,8080/TCP 4m32s
kps-kube-state-metrics ClusterIP 10.108.217.110 <none> 8080/TCP 4m32s
kps-prometheus-node-exporter ClusterIP 10.96.123.38 <none> 9100/TCP 4m32s
prometheus-operated ClusterIP None <none> 9090/TCP 2m11s
#全部running
[root@master promedir]# kubectl get pods,svc -n monitoring
NAME READY STATUS RESTARTS AGE
pod/alertmanager-kps-kube-prometheus-stack-alertmanager-0 2/2 Running 0 64m
pod/kps-grafana-58c8ff8f9b-gdvhw 3/3 Running 0 66m
pod/kps-kube-prometheus-stack-operator-c9ffdc7d-27v69 1/1 Running 0 66m
pod/kps-kube-state-metrics-bcd5b8dfc-9b22c 1/1 Running 0 66m
pod/kps-prometheus-node-exporter-mxkqg 1/1 Running 0 66m
pod/kps-prometheus-node-exporter-nzrxl 1/1 Running 0 66m
pod/kps-prometheus-node-exporter-snbkd 1/1 Running 0 66m
pod/prometheus-kps-kube-prometheus-stack-prometheus-0 2/2 Running 0 64m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 64m
service/kps-grafana ClusterIP 10.107.2.9 <none> 80/TCP 66m
service/kps-kube-prometheus-stack-alertmanager ClusterIP 10.111.53.144 <none> 9093/TCP,8080/TCP 66m
service/kps-kube-prometheus-stack-operator ClusterIP 10.97.110.234 <none> 443/TCP 66m
service/kps-kube-prometheus-stack-prometheus ClusterIP 10.111.185.159 <none> 9090/TCP,8080/TCP 66m
service/kps-kube-state-metrics ClusterIP 10.108.217.110 <none> 8080/TCP 66m
service/kps-prometheus-node-exporter ClusterIP 10.96.123.38 <none> 9100/TCP 66m
service/prometheus-operated ClusterIP None <none> 9090/TCP 64m
[root@master promedir]# 配置Prometheus及grafana通过ingress访问
bash
[root@master ~]# kubectl api-resources | grep ingress
ingressclasses networking.k8s.io/v1 false IngressClass
ingresses ing networking.k8s.io/v1 true Ingress配置Prometheus访问
bash
[root@master promedir]# cat prometheus-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-prometheus
namespace: monitoring
spec:
ingressClassName: nginx
rules:
- host: prometheus.abner.com #企业中注册的域名
http:
paths:
- backend:
service:
name: kps-kube-prometheus-stack-prometheus #service名称
port:
number: 9090
pathType: Prefix
path: "/" #http://prometheus.abner.com:9090/
[root@master promedir]#
[root@master promedir]#
[root@master promedir]# cat grafana-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-grafana
namespace: monitoring
spec:
ingressClassName: nginx
rules:
- host: grafana.abner.com #企业中注册的域名
http:
paths:
- backend:
service:
name: kps-grafana #service名称
port:
number: 80
pathType: Prefix
path: "/" #http://prometheus.abner.com:9090/
[root@master promedir]# kubectl apply -f prometheus-ingress.yaml -f grafana-ingress.yaml
ingress.networking.k8s.io/ingress-prometheus created
ingress.networking.k8s.io/ingress-grafana created
#执行完验证
[root@master promedir]# kubectl get ingress -n monitoring
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress-grafana nginx grafana.abner.com 80 20s
ingress-prometheus nginx prometheus.abner.com 80 20s
#地址出现了
[root@master promedir]# kubectl get ingress -n monitoring
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress-grafana nginx grafana.abner.com 192.168.100.210 80 2m43s
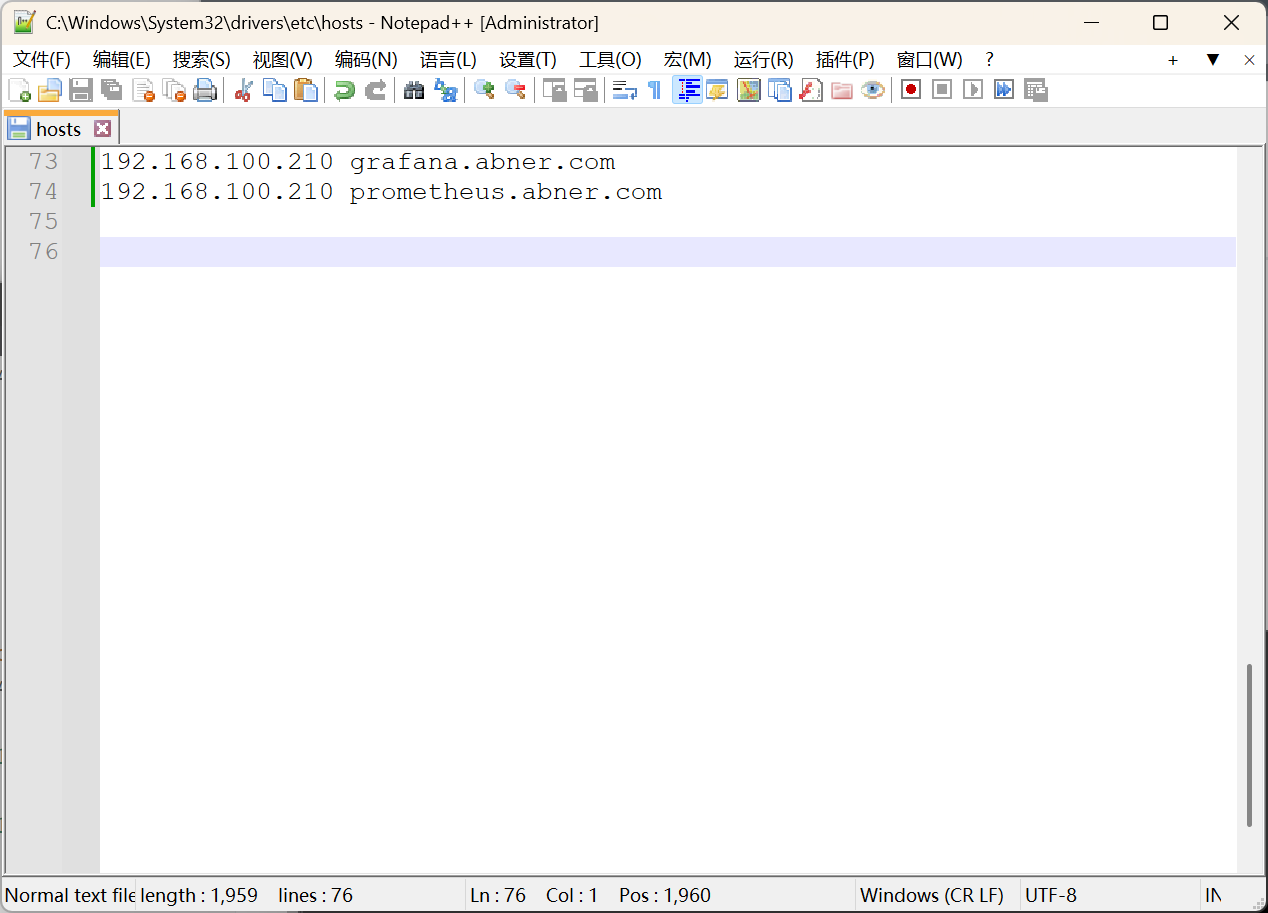
ingress-prometheus nginx prometheus.abner.com 192.168.100.210 80 2m43s配置hosts解析
配置完后进行浏览器验证
查看用户名和密码
bash
[root@master promedir]# kubectl get secret kps-grafana -n monitoring -o yaml
apiVersion: v1
data:
admin-password: cHJvbS1vcGVyYXRvcg==
admin-user: YWRtaW4=
ldap-toml: ""
kind: Secret
metadata:
annotations:
meta.helm.sh/release-name: kps
meta.helm.sh/release-namespace: monitoring
creationTimestamp: "2025-12-01T08:02:07Z"
labels:
app.kubernetes.io/instance: kps
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: grafana
app.kubernetes.io/version: 12.1.1
helm.sh/chart: grafana-9.4.5
name: kps-grafana
namespace: monitoring
resourceVersion: "490834"
uid: e1a19561-8c2e-4c63-a1b1-475248efa369
type: Opaque
#admin-password: cHJvbS1vcGVyYXRvcg==
#admin-user: YWRtaW4=
#使用base64进行密文解析
[root@master promedir]# echo -n "YWRtaW4=" | base64 --decode
admin
[root@master promedir]# echo -n "cHJvbS1vcGVyYXRvcg==" | base64 --decode
prom-operator
#用户名和密码再上面
#下面去浏览器登录
部署web类应用nginx
部署nginx应用
bash
[root@master promedir]# cd ..
[root@master new]#
[root@master new]#
[root@master new]# mkdir nginxdir
[root@master new]# cd nginxdir/
[root@master nginxdir]#
[root@master nginxdir]# vim nginx.conf
[root@master nginxdir]# cat nginx.conf
worker_processes 1;
events {
worker_connections 1024;
}
http {
server {
listen 80;
location / {
root /usr/share/nginx/html;
index index.html;
}
location /basic_status {
stub_status;
allow 127.0.0.1;
deny all;
}
}
}
#创建nginx配置资源
[root@master nginxdir]# kubectl create configmap nginx-config --from-file=nginx.conf
configmap/nginx-config created
#验证
[root@master nginxdir]# kubectl get cm
NAME DATA AGE
kube-root-ca.crt 1 18d
nginx-config 1 20s
tomcat-web-content 1 14d
#如果你的nginx.conf文件创建后发现文件内容错了,修改内容后可以用以下命令覆盖旧文件:kubectl create configmap nginx-config --from-file=nginx.conf --dry-run=client -o yaml | kubectl replace -f -创建nginx的YAML
bash
[root@master nginxdir]# cat nginx-with-exporter.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: default
name: nginx-with-exporter
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
#著容器:nginx
- name: nginx-container
image: nginx:1.26-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
resources:
requests:
cpu: 200m
memory: 150Mi
#挂载configmap资源
volumeMounts:
- mountPath: /etc/nginx/nginx.conf #挂载路径
name: nginx-configure
subPath: nginx.conf #用到的文件
#边车容器:nginx-exporter,监控代理
- name: nginx-prometheus-exporter
image: nginx/nginx-prometheus-exporter:latest
imagePullPolicy: IfNotPresent
args: ["-nginx.scrape-uri=http://localhost/basic_status"]
ports:
- containerPort: 9113
name: exporter-port
resources:
requests:
cpu: 50m
memory: 100Mi
#配置文件资源
volumes:
- name: nginx-configure
configMap:
name: nginx-config #configmap名称
---
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
namespace: default
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
selector:
app: nginx
[root@master nginxdir]# kubectl apply -f nginx-with-exporter.yaml
deployment.apps/nginx-with-exporter created
service/nginx-svc unchanged
[root@master nginxdir]# kubectl get pods,svc
NAME READY STATUS RESTARTS AGE
pod/nginx-with-exporter-68f95bb446-kmkp8 2/2 Running 0 33s
pod/nginx-with-exporter-68f95bb446-z4mrl 2/2 Running 0 33s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 19d
service/nginx NodePort 10.109.182.190 <none> 80:30578/TCP 18d
service/nginx-svc NodePort 10.96.54.71 <none> 80:32435/TCP 33s
#去浏览器可以看到nginx首页
在Prometheus中添加nginx监控配置
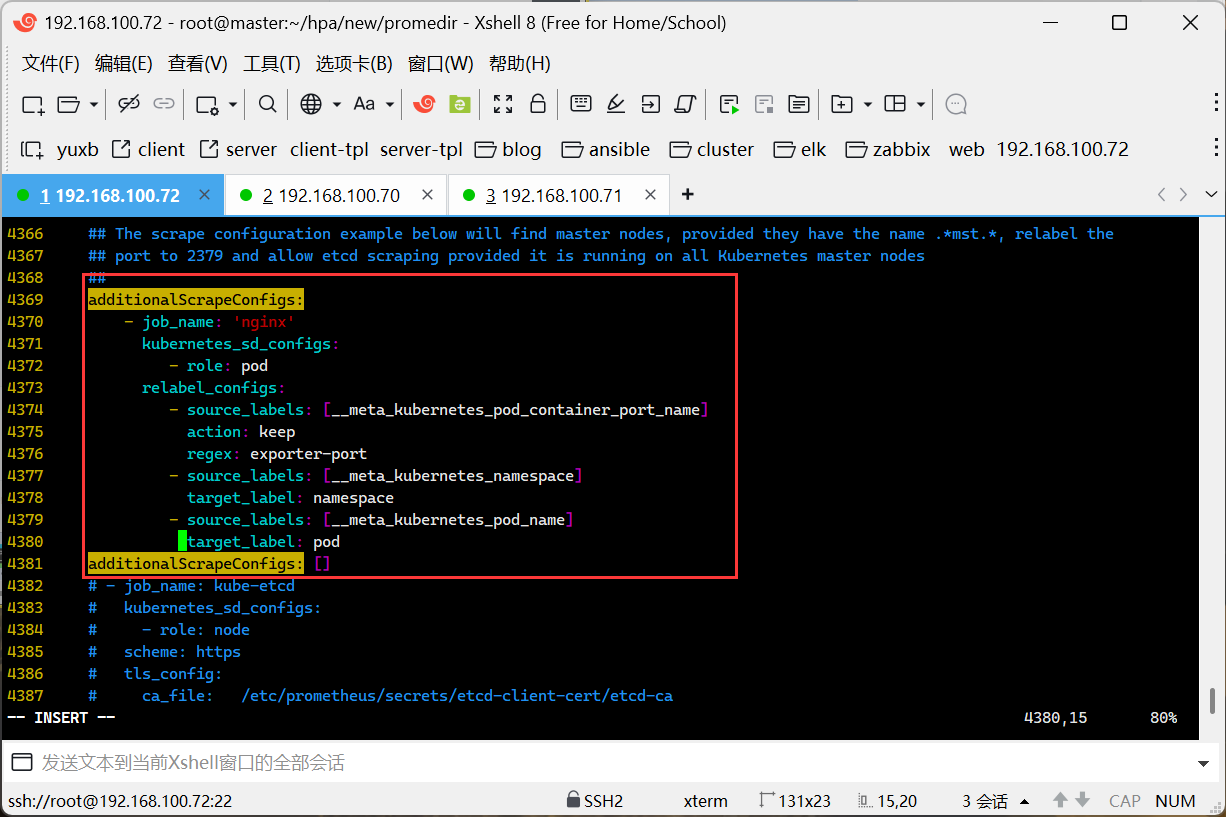
更新配置如下
bash
[root@master promedir]# helm upgrade kps prometheus-community/kube-prometheus-stack --version 79.9.0 -f ./kube-prometheus-stack.yaml -n monitoring
Release "kps" has been upgraded. Happy Helming!
NAME: kps
LAST DEPLOYED: Tue Dec 2 15:35:13 2025
NAMESPACE: monitoring
STATUS: deployed
REVISION: 3
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace monitoring get pods -l "release=kps"
Get Grafana 'admin' user password by running:
kubectl --namespace monitoring get secrets kps-grafana -o jsonpath="{.data.admin-password}" | base64 -d ; echo
Access Grafana local instance:
export POD_NAME=$(kubectl --namespace monitoring get pod -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=kps" -oname)
kubectl --namespace monitoring port-forward $POD_NAME 3000
Get your grafana admin user password by running:
kubectl get secret --namespace monitoring -l app.kubernetes.io/component=admin-secret -o jsonpath="{.items[0].data.admin-password}" | base64 --decode ; echo
Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
#去浏览器查看变化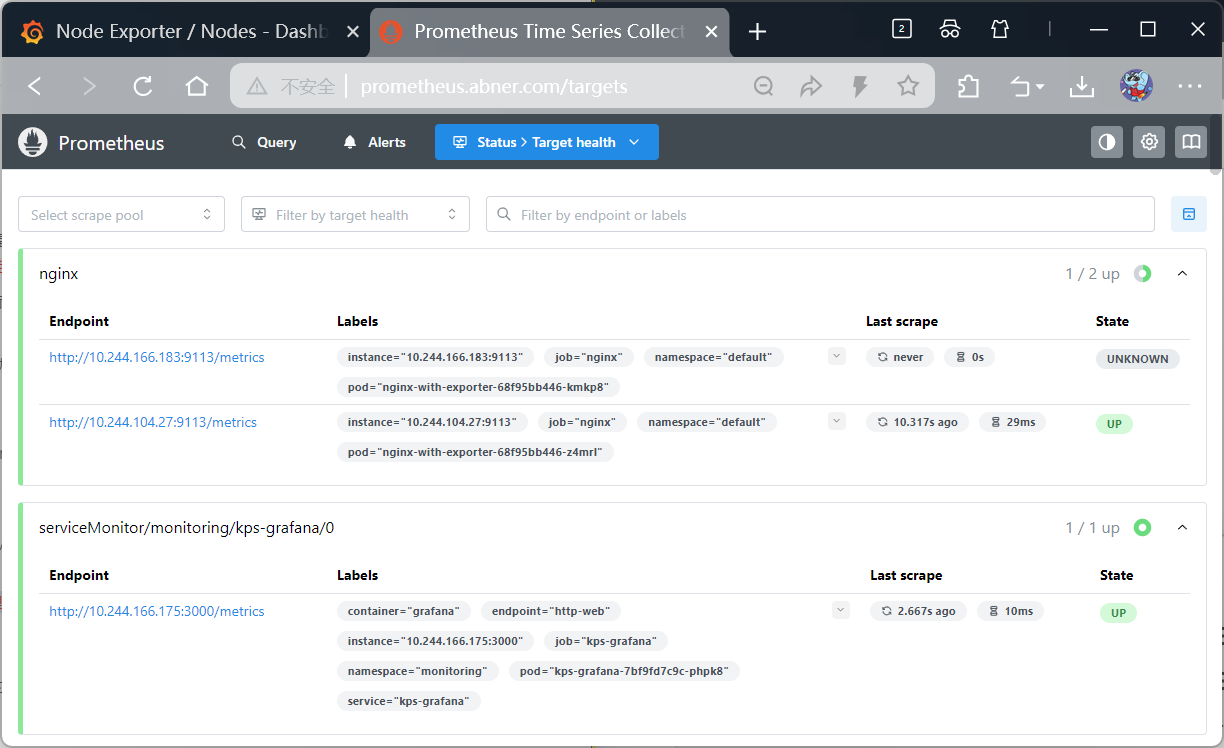
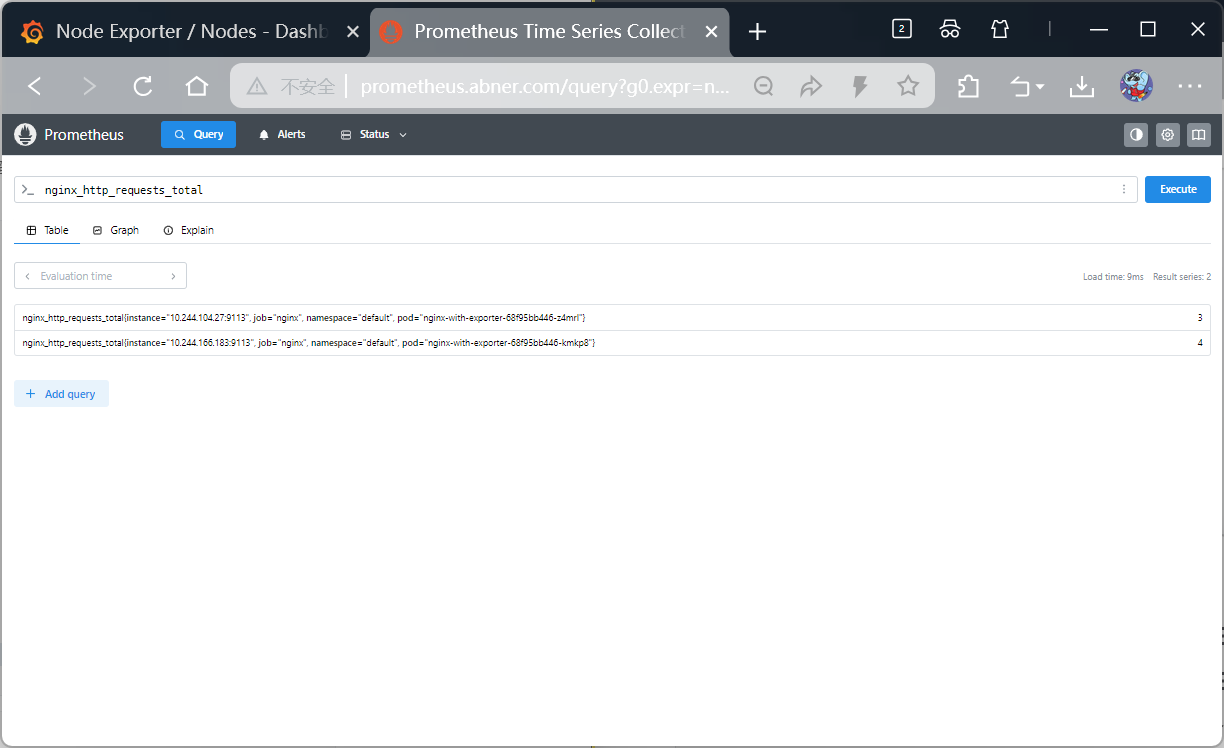
Prometheus-adapter
介绍
Prometheus-Adapter 是Prometheus 与 K8s 弹性组件(HPA/VPA)的专用桥接适配器,核心解决 K8s HPA 无法直接读取 Prometheus 指标的问题,通过提供 K8s 自定义指标 API,让 HPA 能基于 Prometheus 的丰富指标实现弹性伸缩。
核心作用
- 格式转换:将 Prometheus 采集的各类指标(如 nginx_http_requests_total、接口响应时间、队列数),转换成 K8s 可识别的标准格式;
- API 暴露:通过 K8s 自定义指标 API 对外提供转换后的指标,供 HPA、VPA 或 KEDA 调用;
- 核心价值:让 HPA 脱离仅依赖 CPU / 内存的局限,实现基于业务、网络等自定义指标的精准扩缩容。
bash
[root@master promedir]# helm search repo prometheus-adapter
NAME CHART VERSION APP VERSION DESCRIPTION
prometheus-community/prometheus-adapter 5.2.0 v0.12.0 A Helm chart for k8s prometheus adapter下载适配器YAML并修改
bash
[root@master promedir]# helm show values prometheus-community/prometheus-adapter --version 5.2.0 > prometheus-adapter.yaml
[root@master promedir]# vim prometheus-adapter.yaml
37 url: http://kps-kube-prometheus-stack-prometheus.monitoring.svc.cluster.local.
129 rules:
130 default: true
131 custom:
132 - seriesQuery: 'nginx_http_requests_total{namespace!="",pod!=""}'
133 resources:
134 overrides:
135 namespace: {resource: "namespace"}
136 pod: {resource: "pod"}
137 name:
138 as: "nginx_http_requests"
139 metricsQuery: 'sum(rate(nginx_http_requests_total{<<.LabelMatchers>>}[2m])) by (<<.GroupBy>>)' 执行安装部署
bash
[root@master promedir]# helm install prometheus-adapter prometheus-community/prometheus-adapter --namespace monitoring --version 5.2.0 -f ./prometheus-adapter.yaml
NAME: prometheus-adapter
LAST DEPLOYED: Tue Dec 2 15:49:04 2025
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
prometheus-adapter has been deployed.
In a few minutes you should be able to list metrics using the following command(s):
kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1查看资源
bash
[root@master promedir]# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-kps-kube-prometheus-stack-alertmanager-0 2/2 Running 0 21m
kps-grafana-7bf9fd7c9c-phpk8 3/3 Running 0 22m
kps-kube-prometheus-stack-operator-57f6f84bdb-6z2wk 1/1 Running 0 22m
kps-kube-state-metrics-85f785f68-kcwn8 1/1 Running 0 22m
kps-prometheus-node-exporter-4ggt9 1/1 Running 0 22m
kps-prometheus-node-exporter-7ddkz 1/1 Running 0 21m
kps-prometheus-node-exporter-r8gqc 1/1 Running 0 18m
prometheus-adapter-68554f5cdf-wfwtx 1/1 Running 0 69s
prometheus-kps-kube-prometheus-stack-prometheus-0 2/2 Running 0 21m使用jq查看,安装工具
bash
wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo
[root@master promedir]# wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo
--2025-12-02 16:12:19-- https://mirrors.aliyun.com/repo/epel-7.repo
Resolving mirrors.aliyun.com (mirrors.aliyun.com)... 28.0.0.69
Connecting to mirrors.aliyun.com (mirrors.aliyun.com)|28.0.0.69|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 664 [application/octet-stream]
Saving to: '/etc/yum.repos.d/epel.repo'
100%[=========================================================================================>] 664 --.-K/s in 0s
2025-12-02 16:12:19 (112 MB/s) - '/etc/yum.repos.d/epel.repo' saved [664/664]
[root@master promedir]# yum install jq -y
[root@master promedir]# kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .
#查看default命名空间pod的每秒请求数
[root@master promedir]# kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/nginx_http_requests" | jq .创建HPA对象并实现自动伸缩
bash
[root@master promedir]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-with-exporter 2/2 2 2 109m
#创建hpa资源
[root@master promedir]# cd ..
[root@master new]# cd nginxdir/
[root@master nginxdir]#
[root@master nginxdir]#
[root@master nginxdir]# rz -E
rz waiting to receive.
[root@master nginxdir]# cat nginx-prometheus-hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
namespace: default
spec:
minReplicas: 1
maxReplicas: 10
scaleTargetRef:
kind: Deployment
name: nginx-with-exporter
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: AverageValue
averageValue: 150Mi
- type: Pods
pods:
metric:
name: nginx_http_requests
target:
type: AverageValue
averageValue: 50
[root@master nginxdir]# kubectl apply -f nginx-prometheus-hpa.yaml
horizontalpodautoscaler.autoscaling/nginx-hpa created
[root@master nginxdir]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-hpa Deployment/nginx-with-exporter <unknown>/70%, <unknown>/150Mi + 1 more... 1 10 0 14s
[root@master nginxdir]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-with-exporter-68f95bb446-kmkp8 2/2 Running 0 143m
nginx-with-exporter-68f95bb446-z4mrl 2/2 Running 0 143m
#查看变化
Every 2.0s: kubectl get pods Tue Dec 2 16:54:05 2025
NAME READY STATUS RESTARTS AGE
nginx-with-exporter-68f95bb446-kmkp8 2/2 Running 0 145m
nginx-with-exporter-68f95bb446-z4mrl 2/2 Running 0 145m
#5分钟后
Every 2.0s: kubectl get pods Tue Dec 2 16:56:58 2025
NAME READY STATUS RESTARTS AGE
nginx-with-exporter-68f95bb446-z4mrl 2/2 Running 0 148m
[root@master nginxdir]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-with-exporter-68f95bb446-z4mrl 2/2 Running 0 148m进行压测
bash
#得到cluster ip
[root@master nginxdir]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 19d
nginx NodePort 10.109.182.190 <none> 80:30578/TCP 19d
nginx-svc NodePort 10.96.54.71 <none> 80:32435/TCP 134m
#开始压测
[root@master nginxdir]# ab -c 1000 -n 1000000 http://10.96.54.71/
This is ApacheBench, Version 2.3 <$Revision: 1430300 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 10.96.54.71 (be patient)
#查看pods变化
Every 2.0s: kubectl get pods Tue Dec 2 16:58:02 2025
NAME READY STATUS RESTARTS AGE
nginx-with-exporter-68f95bb446-z4mrl 2/2 Running 0 149m
#开始变化
Every 2.0s: kubectl get pods Tue Dec 2 16:58:23 2025
NAME READY STATUS RESTARTS AGE
nginx-with-exporter-68f95bb446-5sv4s 2/2 Running 0 14s
nginx-with-exporter-68f95bb446-z4mrl 2/2 Running 0 150m
#继续变化
Every 2.0s: kubectl get pods Tue Dec 2 16:58:35 2025
NAME READY STATUS RESTARTS AGE
nginx-with-exporter-68f95bb446-5sv4s 2/2 Running 0 26s
nginx-with-exporter-68f95bb446-674jh 2/2 Running 0 11s
nginx-with-exporter-68f95bb446-z4mrl 2/2 Running 0 150m
#继续变化,这次变化剧烈
Every 2.0s: kubectl get pods Tue Dec 2 16:59:13 2025
NAME READY STATUS RESTARTS AGE
nginx-with-exporter-68f95bb446-2sddh 2/2 Running 0 4s
nginx-with-exporter-68f95bb446-5sv4s 2/2 Running 0 64s
nginx-with-exporter-68f95bb446-674jh 2/2 Running 0 49s
nginx-with-exporter-68f95bb446-7scdr 2/2 Running 0 4s
nginx-with-exporter-68f95bb446-xj45x 2/2 Running 0 4s
nginx-with-exporter-68f95bb446-z4mrl 2/2 Running 0 150m
#继续变化
Every 2.0s: kubectl get pods Tue Dec 2 16:59:42 2025
NAME READY STATUS RESTARTS AGE
nginx-with-exporter-68f95bb446-2sddh 2/2 Running 0 33s
nginx-with-exporter-68f95bb446-5sv4s 2/2 Running 0 93s
nginx-with-exporter-68f95bb446-674jh 2/2 Running 0 78s
nginx-with-exporter-68f95bb446-7scdr 2/2 Running 0 33s
nginx-with-exporter-68f95bb446-rwdzz 2/2 Running 0 3s
nginx-with-exporter-68f95bb446-xj45x 2/2 Running 0 33s
nginx-with-exporter-68f95bb446-z4mrl 2/2 Running 0 151m
#再发生变化
Every 2.0s: kubectl get pods Tue Dec 2 16:59:57 2025
NAME READY STATUS RESTARTS AGE
nginx-with-exporter-68f95bb446-2sddh 2/2 Running 0 48s
nginx-with-exporter-68f95bb446-5sv4s 2/2 Running 0 108s
nginx-with-exporter-68f95bb446-674jh 2/2 Running 0 93s
nginx-with-exporter-68f95bb446-7scdr 2/2 Running 0 48s
nginx-with-exporter-68f95bb446-md7rv 2/2 Running 0 3s
nginx-with-exporter-68f95bb446-rwdzz 2/2 Running 0 18s
nginx-with-exporter-68f95bb446-xj45x 2/2 Running 0 48s
nginx-with-exporter-68f95bb446-z4mrl 2/2 Running 0 151m
#变化完毕,因为设定了最大副本数量为10,所以最大变化就扩容到10个
Every 2.0s: kubectl get pods Tue Dec 2 17:00:31 2025
NAME READY STATUS RESTARTS AGE
nginx-with-exporter-68f95bb446-295g9 2/2 Running 0 7s
nginx-with-exporter-68f95bb446-2sddh 2/2 Running 0 82s
nginx-with-exporter-68f95bb446-5sv4s 2/2 Running 0 2m22s
nginx-with-exporter-68f95bb446-674jh 2/2 Running 0 2m7s
nginx-with-exporter-68f95bb446-7scdr 2/2 Running 0 82s
nginx-with-exporter-68f95bb446-d9v6d 2/2 Running 0 7s
nginx-with-exporter-68f95bb446-md7rv 2/2 Running 0 37s
nginx-with-exporter-68f95bb446-rwdzz 2/2 Running 0 52s
nginx-with-exporter-68f95bb446-xj45x 2/2 Running 0 82s
nginx-with-exporter-68f95bb446-z4mrl 2/2 Running 0 152m
#查看压测变化
[root@master nginxdir]# ab -c 1000 -n 1000000 http://10.96.54.71/
This is ApacheBench, Version 2.3 <$Revision: 1430300 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 10.96.54.71 (be patient)
Completed 100000 requests
Completed 200000 requests
Completed 300000 requests
Completed 400000 requests
Completed 500000 requests
Completed 600000 requests
Completed 700000 requests
Completed 800000 requests
Completed 900000 requests
Completed 1000000 requests
Finished 1000000 requests
Server Software: nginx/1.26.3
Server Hostname: 10.96.54.71
Server Port: 80
Document Path: /
Document Length: 615 bytes
Concurrency Level: 1000
Time taken for tests: 998.428 seconds
Complete requests: 1000000
Failed requests: 0
Write errors: 0
Total transferred: 848000000 bytes
HTML transferred: 615000000 bytes
Requests per second: 1001.57 [#/sec] (mean)
Time per request: 998.428 [ms] (mean)
Time per request: 0.998 [ms] (mean, across all concurrent requests)
Transfer rate: 829.43 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 994 125.0 1003 3032
Processing: 0 4 46.3 1 2374
Waiting: 0 3 45.9 1 2374
Total: 2 998 138.2 1004 4229
Percentage of the requests served within a certain time (ms)
50% 1004
66% 1005
75% 1005
80% 1005
90% 1007
95% 1009
98% 1017
99% 1035
100% 4229 (longest request)
#压测完之后观察pod变化
#压测完的状态
Every 2.0s: kubectl get pods Tue Dec 2 17:15:06 2025
NAME READY STATUS RESTARTS AGE
nginx-with-exporter-68f95bb446-295g9 2/2 Running 0 14m
nginx-with-exporter-68f95bb446-2sddh 2/2 Running 0 15m
nginx-with-exporter-68f95bb446-5sv4s 2/2 Running 0 16m
nginx-with-exporter-68f95bb446-674jh 2/2 Running 0 16m
nginx-with-exporter-68f95bb446-7scdr 2/2 Running 0 15m
nginx-with-exporter-68f95bb446-d9v6d 2/2 Running 0 14m
nginx-with-exporter-68f95bb446-md7rv 2/2 Running 0 15m
nginx-with-exporter-68f95bb446-rwdzz 2/2 Running 0 15m
nginx-with-exporter-68f95bb446-xj45x 2/2 Running 0 15m
nginx-with-exporter-68f95bb446-z4mrl 2/2 Running 0 166m
#等会一会的状态
Every 2.0s: kubectl get pods Tue Dec 2 17:23:03 2025
NAME READY STATUS RESTARTS AGE
nginx-with-exporter-68f95bb446-295g9 2/2 Running 0 22m
nginx-with-exporter-68f95bb446-2sddh 2/2 Running 0 23m
nginx-with-exporter-68f95bb446-674jh 2/2 Running 0 24m
nginx-with-exporter-68f95bb446-rwdzz 2/2 Running 0 23m
nginx-with-exporter-68f95bb446-z4mrl 2/2 Running 0 174m
#最后的状态,最后会缩容到1个,因为yaml文件里面设置了最小副本数量为1
Every 2.0s: kubectl get pods Tue Dec 2 17:24:28 2025
NAME READY STATUS RESTARTS AGE
nginx-with-exporter-68f95bb446-z4mrl 2/2 Running 0 176m垂直自动伸缩 VPA
介绍
VPA(Vertical Pod Autoscaler,Pod 垂直自动伸缩)是 Kubernetes 弹性伸缩组件,核心作用是根据容器实际资源使用率,动态调整 Pod 的 CPU / 内存 requests/limits------ 资源过剩时缩容(降低请求值),资源不足时扩容(提高请求值),实现资源精准匹配,提升节点资源利用率。
核心适配场景:无法通过增加 Pod 数量扩容的服务(如数据库、单机版中间件),需通过提升单 Pod 资源规格满足负载需求。
优缺点
优点
- 资源利用率最优:Pod 按需分配资源,避免过度请求导致的资源浪费,提升节点承载能力;
- 调度更合理:调整后的 requests 让 Kubernetes 能将 Pod 调度到资源充足的节点,减少资源争抢;
- 减少运维成本:无需手动做基准测试或调整资源配置,自动适配负载变化;
- 适配特殊服务:解决数据库、单机中间件等 "无法水平扩容" 服务的资源弹性需求。
缺点
- 与 HPA 冲突:不能同时与 HPA 作用于同一个 Deployment/ReplicaSet(两者调整逻辑互斥,会导致扩缩容异常);
- 服务中断风险:调整资源规格时,VPA 会重启 Pod(需重新调度),可能导致短时间服务不可用;
- 支持范围有限:仅适配无状态服务和部分有状态服务(如数据库),不支持 DaemonSet 等不可扩缩对象;
- 资源调整有上限:需提前配置资源上下限(如
minAllowed/maxAllowed),避免单 Pod 占用过多节点资源。
与 HPA 区别
| 特性 | VPA(垂直伸缩) | HPA(水平伸缩) |
|---|---|---|
| 调整方式 | 改变单 Pod 的 CPU / 内存规格 | 改变 Pod 副本数量 |
| 服务影响 | 调整时需重启 Pod,可能中断服务 | 新增 / 删除 Pod,不影响现有服务 |
| 适配场景 | 数据库、单机中间件(无法水平扩) | Web 服务、API 服务(无状态) |
| 资源利用率 | 单 Pod 资源精准匹配 | 集群整体负载均衡 |
| 兼容性 | 不能与 HPA 混用 | 独立使用,无明显冲突 |
部署metircs-server
bash
#实验前提
[root@master new]# kubectl get hpa
No resources found in default namespace.
#
[root@master new]# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master 276m 6% 1331Mi 36%
node1 202m 5% 1437Mi 39%
node2 233m 5% 1088Mi 29% 升级openssl
bash
#所有节点操作
[root@master new]# wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo
--2025-12-03 09:27:58-- https://mirrors.aliyun.com/repo/epel-7.repo
Resolving mirrors.aliyun.com (mirrors.aliyun.com)... 180.97.214.191, 180.97.214.189, 122.247.211.16, ...
Connecting to mirrors.aliyun.com (mirrors.aliyun.com)|180.97.214.191|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 664 [application/octet-stream]
Saving to: '/etc/yum.repos.d/epel.repo'
100%[==========================================================================================>] 664 --.-K/s in 0s
2025-12-03 09:27:59 (260 MB/s) - '/etc/yum.repos.d/epel.repo' saved [664/664]
[root@master new]# yum install -y openssl-devel openssl11 openssl11-devel
#查看
[root@master new]# which openssl
/usr/bin/openssl
[root@master new]# which openssl11
/usr/bin/openssl11
#把原来的删除,新的openssl11建立软连接
[root@master ~]# rm -rf `which openssl`
[root@master ~]# ln -s /usr/bin/openssl11 /usr/bin/openssl
[root@master ~]# ls -l /usr/bin/openssl
lrwxrwxrwx 1 root root 18 Dec 3 09:36 /usr/bin/openssl -> /usr/bin/openssl11
#查看版本
[root@master ~]# openssl version
OpenSSL 1.1.1k FIPS 25 Mar 2021部署VPA
bash
#克隆项目
[root@master ~]# mkdir vpa
[root@master ~]# cd vpa/
[root@master vpa]# git clone https://github.com/kubernetes/autoscaler.git
Cloning into 'autoscaler'...
remote: Enumerating objects: 232427, done.
remote: Counting objects: 100% (1447/1447), done.
remote: Compressing objects: 100% (1028/1028), done.
remote: Total 232427 (delta 914), reused 419 (delta 419), pack-reused 230980 (from 1)
Receiving objects: 100% (232427/232427), 253.19 MiB | 365.00 KiB/s, done.
Resolving deltas: 100% (151073/151073), done.
Checking out files: 100% (8216/8216), done.
[root@master vpa]# ls
autoscaler
yum install gettext-devel perl-CPAN perl-devel zlib-devel curl-devel expat-devel -y
[root@master vertical-pod-autoscaler]# yum install gettext-devel perl-CPAN perl-devel zlib-devel curl-devel expat-devel -y
[root@master ~]# rz -E
rz waiting to receive.
[root@master ~]# ls
anaconda-ks.cfg Desktop kubeadm-init.log pod_dir statefulset
calico.yaml Documents kubeadm-init.yaml probe Templates
components.yaml Downloads lb Public test
controller_dir git-2.28.0.tar.gz metrics-server-components.yaml rbac.yaml Videos
core.100218 hpa Music recommended.yaml vpa
cri-dockerd-0.3.4-3.el7.x86_64.rpm initial-setup-ks.cfg Pictures service
[root@master ~]# tar zxvf git-2.28.0.tar.gz
[root@master ~]# cd git-2.28.0/
[root@master git-2.28.0]# make prefix=/usr/local all
[root@master git-2.28.0]# make prefix=/usr/local install
[root@master git-2.28.0]# ln -s /usr/local/bin/git /usr/bin/git
ln: failed to create symbolic link '/usr/bin/git': File exists
[root@master git-2.28.0]# git --version
git version 1.8.3.1
[root@master git-2.28.0]# rm -rf /usr/bin/git
[root@master git-2.28.0]# ln -s /usr/local/bin/git /usr/bin/git
[root@master git-2.28.0]# git --version
git version 2.28.0
[root@master git-2.28.0]# cd
[root@master ~]# cd vpa/
[root@master vpa]# cd autoscaler/
[root@master autoscaler]# cd hack/
[root@master hack]# cd ..
[root@master autoscaler]# cd vertical-pod-autoscaler/
[root@master vertical-pod-autoscaler]#
[root@master vertical-pod-autoscaler]#
[root@master vertical-pod-autoscaler]# cd hack/
[root@master hack]#
[root@master hack]# bash vpa-up.sh
#查看vpa资源
#最后三个已经running
[root@master hack]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-658d97c59c-tk2pk 1/1 Running 24 (62m ago) 19d
calico-node-7c5d5 1/1 Running 3 (15h ago) 2d1h
calico-node-bx9tp 1/1 Running 3 (15h ago) 2d1h
calico-node-m5kkc 1/1 Running 4 (64m ago) 2d1h
coredns-66f779496c-26pcb 1/1 Running 22 (15h ago) 19d
coredns-66f779496c-wpc57 1/1 Running 22 (15h ago) 19d
etcd-master 1/1 Running 23 (64m ago) 19d
kube-apiserver-master 1/1 Running 41 (63m ago) 19d
kube-controller-manager-master 1/1 Running 30 (62m ago) 19d
kube-proxy-cd8gk 1/1 Running 22 (15h ago) 19d
kube-proxy-q8prd 1/1 Running 23 (64m ago) 19d
kube-proxy-xtfxw 1/1 Running 22 (15h ago) 19d
kube-scheduler-master 1/1 Running 23 (64m ago) 19d
metrics-server-57999c5cf7-bxjn7 1/1 Running 25 (15h ago) 18d
vpa-admission-controller-cd698f44d-hcgn6 1/1 Running 0 13m
vpa-recommender-796d45bfdf-85rfz 1/1 Running 0 13m
vpa-updater-7548dbc57d-n8d8j 1/1 Running 0 13m案例:VPA应用updateMode:"Off"
updateMode 是 VPA 的核心配置项,用于定义 VPA 对资源推荐值的应用策略,决定了资源建议是仅查看、仅初始化应用,还是动态更新 Pod 资源配置。
四种 updateMode 模式
| 模式 | 核心行为 |
|---|---|
| Off | 不应用任何资源推荐,仅采集、计算并展示最优资源建议(只读模式) |
| Initial | 仅在 Pod 首次创建时应用资源推荐,Pod 运行后不再更新 |
| Recreate | 生成新推荐时,终止旧 Pod 并重建新 Pod 应用配置(会导致服务短暂中断) |
| Auto | 默认模式,优先在线调整 Pod 资源(无需重启),无法在线调整时则重建 Pod |
创建应用实例
此模式仅获取资源推荐不更新Pod
bash
[root@master vpa]# cat nginx-dep.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx-deploy
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: c1
image: nginx:1.26-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
resources:
requests:
cpu: 100m
memory: 250Mi
---
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
namespace: default
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
selector:
app: nginx
[root@master vpa]# kubectl apply -f nginx-dep.yaml
deployment.apps/nginx-deploy created
service/nginx-svc created
[root@master vpa]# kubectl get pods,svc
NAME READY STATUS RESTARTS AGE
pod/nginx-deploy-9bbd4fc54-9c4rt 1/1 Running 0 9s
pod/nginx-deploy-9bbd4fc54-wnbvh 1/1 Running 0 9s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 19d
service/nginx NodePort 10.109.182.190 <none> 80:30578/TCP 19d
service/nginx-svc NodePort 10.96.21.132 <none> 80:30906/TCP 9s创建vpa资源
bash
[root@master vpa]# cat nginx-vpa.yaml
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: nginx-vpa
namespace: default
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: nginx-deploy
#垂直伸缩策略
updatePolicy:
updateMode: "Off" #只显示推荐值,而不应用
#资源策略
resourcePolicy:
containerPolicies:
- containerName: "c1"
minAllowed:
cpu: "250m"
memory: "100Mi"
maxAllowed:
cpu: "2000m"
memory: "2048Mi"
[root@master vpa]# kubectl apply -f nginx-vpa.yaml
verticalpodautoscaler.autoscaling.k8s.io/nginx-vpa created
#查看推荐值
[root@master vpa]# kubectl get vpa
NAME MODE CPU MEM PROVIDED AGE
nginx-vpa Off 250m 250Mi True 85s案例:VPA应用案例 updateMode:"Auto"
此模式当目前运行的pod的资源达不到VPA的推销值,就会执行pod驱逐,重新部署新的足够资源的服务
创建应用
bash
[root@master vpa]# kubectl delete -f nginx-vpa.yaml
verticalpodautoscaler.autoscaling.k8s.io "nginx-vpa" deleted
[root@master vpa]# kubectl apply -f nginx-dep.yaml
deployment.apps/nginx-deploy unchanged
service/nginx-svc unchanged
[root@master vpa]# kubectl get pods,svc
NAME READY STATUS RESTARTS AGE
pod/nginx-deploy-9bbd4fc54-9c4rt 1/1 Running 0 75m
pod/nginx-deploy-9bbd4fc54-wnbvh 1/1 Running 0 75m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 20d
service/nginx NodePort 10.109.182.190 <none> 80:30578/TCP 19d
service/nginx-svc NodePort 10.96.21.132 <none> 80:30906/TCP 75m
#更改现成的vpa文件进行试验
[root@master vpa]# cat nginx-vpa.yaml
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: nginx-vpa-auto
namespace: default
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: nginx-deploy
#垂直伸缩策略
updatePolicy:
updateMode: "Auto" #只显示推荐值,而不应用
#资源策略
resourcePolicy:
containerPolicies:
- containerName: "c1"
minAllowed:
cpu: "250m"
memory: "100Mi"
maxAllowed:
cpu: "2000m"
memory: "2048Mi"
[root@master vpa]# kubectl apply -f nginx-vpa.yaml
Warning: UpdateMode "Auto" is deprecated and will be removed in a future API version. Use explicit update modes like "Recreate", "Initial", or "InPlaceOrRecreate" instead. See https://github.com/kubernetes/autoscaler/issues/8424 for more details.
verticalpodautoscaler.autoscaling.k8s.io/nginx-vpa-auto created
[root@master vpa]# kubectl get vpa
NAME MODE CPU MEM PROVIDED AGE
nginx-vpa-auto Auto 17s
[root@master vpa]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deploy-9bbd4fc54-9c4rt 1/1 Running 0 81m
nginx-deploy-9bbd4fc54-wnbvh 1/1 Running 0 81m
[root@master vpa]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deploy-9bbd4fc54-v6cxn 1/1 Running 0 41s
nginx-deploy-9bbd4fc54-wnbvh 1/1 Running 0 82m
[root@master vpa]# kubectl describe pod nginx-deploy-9bbd4fc54-v6cxn
Name: nginx-deploy-9bbd4fc54-v6cxn
Namespace: default
Priority: 0
Service Account: default
Node: node1/192.168.100.70
Start Time: Wed, 03 Dec 2025 15:07:01 +0800
Labels: app=nginx
pod-template-hash=9bbd4fc54
Annotations: cni.projectcalico.org/containerID: 2dbfc5e05343888bd4206b4684cfb8b410b16d1e493a7e15cd381350f5a7d608
cni.projectcalico.org/podIP: 10.244.166.152/32
cni.projectcalico.org/podIPs: 10.244.166.152/32
vpaObservedContainers: c1
vpaUpdates: Pod resources updated by nginx-vpa-auto: container 0: cpu request, memory request
Status: Running
IP: 10.244.166.152
IPs:
IP: 10.244.166.152
Controlled By: ReplicaSet/nginx-deploy-9bbd4fc54
Containers:
c1:
Container ID: docker://b6c129f3e166c61e1718208fe9ddddbe26ca6c519c05022d8663367e232548e8
Image: nginx:1.26-alpine
Image ID: docker-pullable://nginx@sha256:1eadbb07820339e8bbfed18c771691970baee292ec4ab2558f1453d26153e22d
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Wed, 03 Dec 2025 15:07:02 +0800
Ready: True
Restart Count: 0
Requests:
cpu: 250m
memory: 250Mi
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-6hkbt (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-6hkbt:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 57s default-scheduler Successfully assigned default/nginx-deploy-9bbd4fc54-v6cxn to node1
Normal Pulled 56s kubelet Container image "nginx:1.26-alpine" already present on machine
Normal Created 56s kubelet Created container c1
Normal Started 56s kubelet Started container c1
[root@master vpa]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deploy-9bbd4fc54-8jg5v 1/1 Running 0 31s
nginx-deploy-9bbd4fc54-v6cxn 1/1 Running 0 91s6153e22d
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Wed, 03 Dec 2025 15:07:02 +0800
Ready: True
Restart Count: 0
Requests:
cpu: 250m
memory: 250Mi
Environment:
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-6hkbt (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-6hkbt:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional:
DownwardAPI: true
QoS Class: Burstable
Node-Selectors:
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
Normal Scheduled 57s default-scheduler Successfully assigned default/nginx-deploy-9bbd4fc54-v6cxn to node1
Normal Pulled 56s kubelet Container image "nginx:1.26-alpine" already present on machine
Normal Created 56s kubelet Created container c1
Normal Started 56s kubelet Started container c1
root@master vpa# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deploy-9bbd4fc54-8jg5v 1/1 Running 0 31s
nginx-deploy-9bbd4fc54-v6cxn 1/1 Running 0 91s