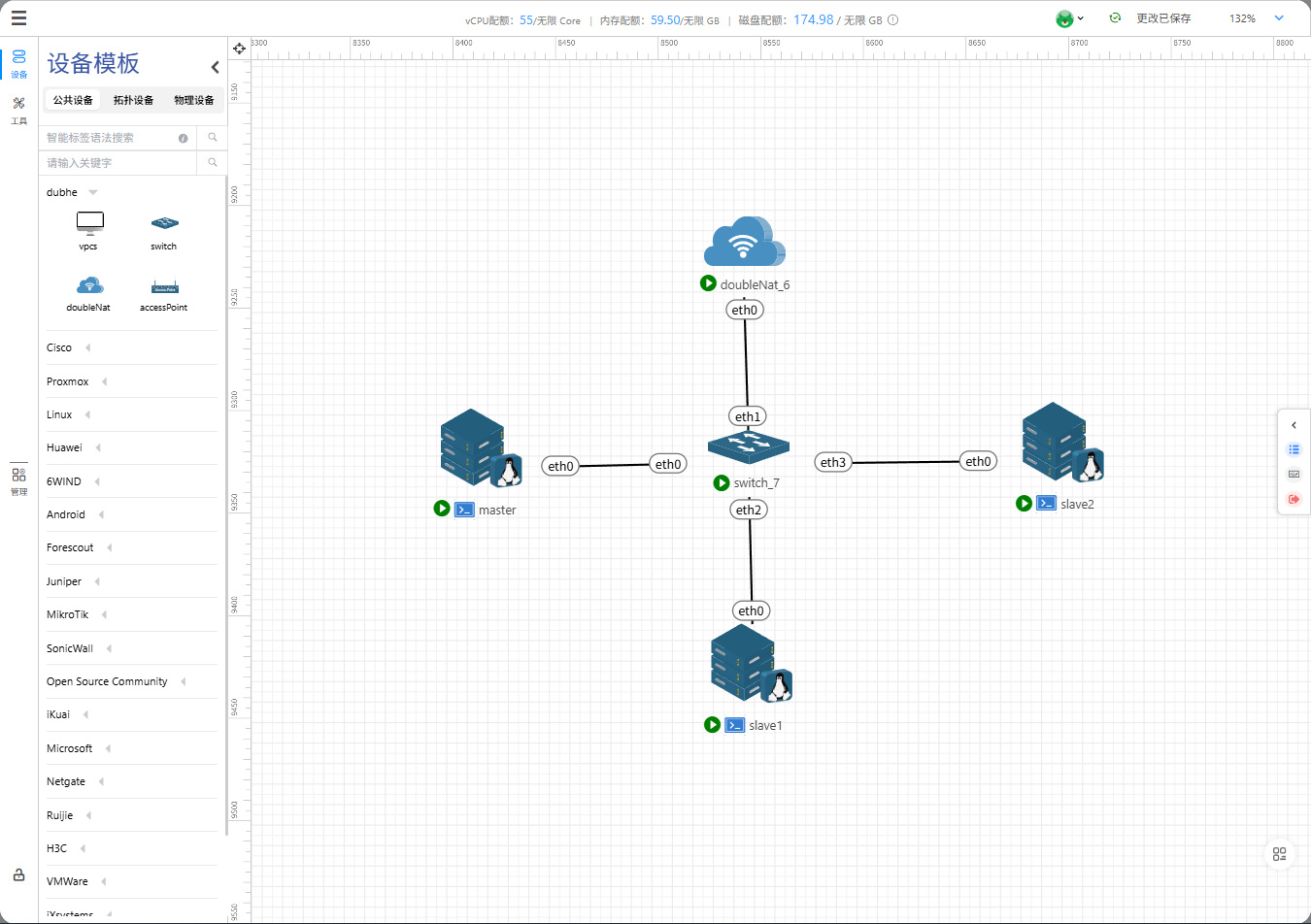
一、集群架构规划
1. 节点角色分配
|-------------|----------------------------------|------------------|--------------------------|
| 节点 hostname | IP 地址(示例) | 角色 | 核心进程 |
| master | 192.168.0.100(192.168.0.100) | 主节点(NameNode+RM) | NameNode、ResourceManager |
| slave1 | 192.168.0.101(192.168.0.101) | 从节点(DataNode+NM) | DataNode、NodeManager |
| slave2 | 192.168.0.102(192.168.0.102) | 从节点(DataNode+NM) | DataNode、NodeManager |
2. 环境要求(每个节点均需满足)
- 操作系统: 22.03 LTS
- 实验平台:天枢一体化虚拟仿真平台
- 网络要求:三节点互通(关闭防火墙或开放必要端口)、DNS 解析正常
- 依赖软件:JDK 8(所有节点版本一致)
- 管理用户:统一使用 hadoopd 普通用户(替代root用户,提升安全性)
二、所有节点前置环境准备
1. 统一系统基础配置(3个节点均执行,初始需用root用户操作)
(1)创建hadoopd管理用户并授权
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| # 创建hadoopd用户(设置密码时输入自定义密码,牢记) useradd hadoopd passwd hadoopd # 授予hadoopd免密sudo权限(避免执行系统命令反复输入密码) echo "hadoopd ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers # 验证sudo权限(切换用户测试,无密码即可执行sudo命令) su - hadoopd sudo ls /root # 无报错即授权成功 |
(2)设置主机名(分别在对应节点执行,hadoopd用户下用sudo)
- master 节点:
|--------------------------------------|
| sudo hostnamectl set-hostname master |
- slave1 节点:
|--------------------------------------|
| sudo hostnamectl set-hostname slave1 |
- slave2 节点:
|--------------------------------------|
| sudo hostnamectl set-hostname slave2 |
(3)配置主机名解析(3个节点均执行,hadoopd用户下)
|-----------------------------------------------------------------------|
| # 安装vim(若未安装) sudo dnf install -y vim # 编辑hosts文件 sudo vim /etc/hosts |
添加内容(替换为实际IP):
|----------------------------------------------------------------|
| 192.168.1.100 master 192.168.1.101 slave1 192.168.1.102 slave2 |
验证解析:
|---------------------------------------------------|
| ping master -c 2 && ping slave1 -c 2 # 互通无丢包即正常 |
(4)关闭防火墙与 SELinux(3个节点均执行,hadoopd用户下用sudo)
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| # 关闭防火墙(永久关闭,避免重启失效) sudo systemctl stop firewalld sudo systemctl disable firewalld # 关闭 SELinux(临时+永久) sudo setenforce 0 sudo sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config |
(5)安装基础依赖(3个节点均执行,hadoopd用户下用sudo)
|----------------------------------------------------------------------------------------|
| sudo dnf update -y sudo dnf install -y openssh-server openssh-clients rsync which wget |
2. 安装 JDK 8(3个节点均执行,hadoopd用户下用sudo)
(1)安装 JDK
|-----------------------------------------------------------------|
| sudo dnf install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel |
(2)配置 JAVA_HOME 环境变量(全局生效,所有用户可用)
|-----------------------|
| sudo vim /etc/profile |
添加内容:
|-----------------------------------------------------------------------------------|
| export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk export PATH=PATH:JAVA_HOME/bin |
生效并验证(hadoopd用户下):
|--------------------------------------------------|
| source /etc/profile java -version # 输出 1.8.x 即正确 |
3. 配置 SSH 免密登录(关键:master节点hadoopd用户到所有节点hadoopd用户免密)
(1)启动 SSH 服务(3个节点均执行,hadoopd用户下用sudo)
|------------------------------------------------------|
| sudo systemctl start sshd sudo systemctl enable sshd |
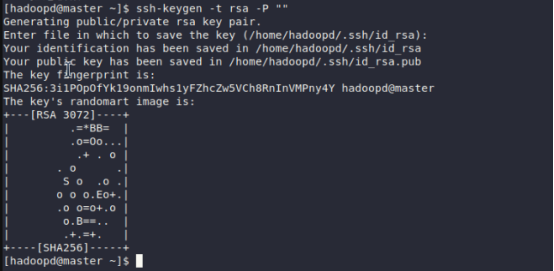
(2)master节点hadoopd用户生成密钥对(仅master节点hadoopd用户执行)
|-----------------------------------------------------------------------------------------------------------|
| # 切换到hadoopd用户(若当前为root) su - hadoopd # 生成RSA密钥对(一路回车,无密码) ssh-keygen -t rsa -P "" # 密钥存于 ~hadoopd/.ssh/ |
(3)配置免密登录所有节点(仅master节点hadoopd用户执行)
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| # 免密登录自身(master节点hadoopd) cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys # 修复密钥文件权限(必须严格配置,否则SSH免密失效) chmod 700 ~/.ssh # .ssh目录仅当前用户可访问 chmod 600 ~/.ssh/id_rsa # 私钥仅当前用户可读写 chmod 644 ~/.ssh/id_rsa.pub # 公钥仅当前用户可写、其他用户可读 chmod 600 ~/.ssh/authorized_keys # 授权文件仅当前用户可读写 # 免密登录slave1节点hadoopd用户 ssh-copy-id -i ~/.ssh/id_rsa.pub hadoopd@slave1 # 免密登录slave2节点hadoopd用户 ssh-copy-id -i ~/.ssh/id_rsa.pub hadoopd@slave2 |
若没有 authorized_keys需执行命令:
touch ~/.ssh/authorized_keys,生成空的authorized_keys文件
在将客户端公钥追加到该文件中,例如本地公钥的添加命令:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
(4)验证免密登录(仅master节点hadoopd用户执行)
|----------------------------------------------------------------------------------------------|
| ssh hadoopd@master # 无需密码,直接登录 ssh hadoopd@slave1 # 无需密码,直接登录 ssh hadoopd@slave2 # 无需密码,直接登录 |
(若提示输入密码,重新检查authorized_keys权限:chmod 600 ~/.ssh/authorized_keys)
三、Hadoop 安装与配置(master节点hadoopd用户操作,后同步到从节点)
1. master节点安装 Hadoop(hadoopd用户下执行)
(1)下载并解压 Hadoop
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| # 下载Hadoop 3.3.6(稳定版) wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz # 解压到/usr/local/(需sudo权限) sudo tar -zxvf hadoop-3.3.6.tar.gz -C /usr/local/ # 重命名简化目录 sudo mv /usr/local/hadoop-3.3.6 /usr/local/hadoop # 授权hadoopd用户为目录所有者(关键:避免权限不足) sudo chown -R hadoopd:hadoopd /usr/local/hadoop |
(2)配置 Hadoop 环境变量(hadoopd用户级配置,仅hadoopd可用)
|-----------------------------|
| # 编辑用户环境变量文件 vim ~/.bashrc |
添加内容:
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| export HADOOP_HOME=/usr/local/hadoop export PATH=PATH:HADOOP_HOME/bin:HADOOP_HOME/sbin export HADOOP_CONF_DIR=HADOOP_HOME/etc/hadoop export HADOOP_MAPRED_HOME=HADOOP_HOME export HADOOP_COMMON_HOME=HADOOP_HOME export HADOOP_HDFS_HOME=HADOOP_HOME export YARN_HOME=HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=HADOOP_HOME/lib" |
生效并验证:
|--------------------------------------------------------|
| source ~/.bashrc hadoop version # 显示Hadoop 3.3.6版本即成功 |
2. 核心配置文件修改(master节点hadoopd用户,路径:$HADOOP_HOME/etc/hadoop/)
(1)修改 hadoop-env.sh(hadoop-env.sh)(指定JDK路径和用户)
|-------------------------------------------|
| vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh |
添加/修改:
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk export HADOOP_PID_DIR=HADOOP_HOME/pids export HADOOP_LOG_DIR=HADOOP_HOME/logs export HADOOP_USER_NAME=hadoopd # 指定Hadoop运行用户为hadoopd |
(2)修改 core-site.xml(核心通信配置,替换root为hadoopd)
|-------------------------------------------|
| vim $HADOOP_HOME/etc/hadoop/core-site.xml |
在 <configuration> 内添加:
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <property> <!-- 指定NameNode地址(master主机名+端口) --> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <!-- Hadoop临时目录(自定义,避免/tmp被系统清理) --> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> <property> <!-- 允许hadoopd用户操作Hadoop(替换原root) --> <name>hadoop.http.staticuser.user</name> <value>hadoopd</value> </property> <property> <!-- 解决跨节点访问HDFS权限问题 --> <name>hadoop.proxyuser.hadoopd.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoopd.groups</name> <value>*</value> </property> |
(3)修改 hdfs-site.xml(HDFS存储配置)
|-------------------------------------------|
| vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml |
添加:
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <property> <!-- 数据副本数(2个从节点,设为2,避免副本不足) --> <name>dfs.replication</name> <value>2</value> </property> <property> <!-- NameNode元数据存储目录 --> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop/hdfs/name</value> </property> <property> <!-- DataNode数据存储目录 --> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop/hdfs/data</value> </property> <property> <!-- 开启WebHDFS访问 --> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <!-- 关闭HDFS权限检查(测试环境,生产环境建议开启) --> <name>dfs.permissions.enabled</name> <value>false</value> </property> <property> <!-- NameNode Web UI端口(默认9870) --> <name>dfs.namenode.http-address</name> <value>master:9870</value> </property> |
(4)修改 mapred-site.xml(MapReduce配置)
复制模板并修改:
|---------------------------------------------|
| vim $HADOOP_HOME/etc/hadoop/mapred-site.xml |
添加:
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <property> <!-- 指定MapReduce运行在YARN上 --> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <!-- 任务历史服务器地址(master节点) --> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <!-- 任务历史Web UI地址 --> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> <property> <!-- 每个Map任务内存分配(根据节点内存调整) --> <name>mapreduce.map.memory.mb</name> <value>1024</value> </property> <property> <!-- 每个Reduce任务内存分配 --> <name>mapreduce.reduce.memory.mb</name> <value>2048</value> </property> |
(5)修改 yarn-site.xml(YARN资源管理配置)
|-------------------------------------------|
| vim $HADOOP_HOME/etc/hadoop/yarn-site.xml |
添加:
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <property> <!-- ResourceManager地址(master节点) --> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <!-- ResourceManager调度地址 --> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <!-- ResourceManager资源跟踪地址 --> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> <property> <!-- NodeManager辅助服务(MapReduce shuffle) --> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <!-- YARN Web UI地址 --> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> <property> <!-- 关闭内存检查(避免OpenEuler内存误判) --> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <property> <!-- 每个节点可用内存(总内存-系统占用,示例:4GB节点设为3072MB) --> <name>yarn.nodemanager.resource.memory-mb</name> <value>3072</value> </property> <property> <!-- 每个CPU核心内存分配(1024MB/核) --> <name>yarn.scheduler.minimum-allocation-mb</name> <value>1024</value> </property> |
(6)修改 workers(指定从节点列表)
|-------------------------------------|
| vim $HADOOP_HOME/etc/hadoop/workers |
删除默认内容,添加从节点主机名(每行一个):
|---------------|
| slave1 slave2 |
3. 同步 Hadoop 到所有从节点(master节点hadoopd用户执行)
(1)同步安装目录(免密登录已配置,直接同步)
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| # 同步到slave1节点(hadoopd用户目录) /usr/local/是系统级目录,默认仅 root 用户拥有写入权限,hadoop 用户对该目录无写入权限需先传输到用户主目录,再移动(无需修改系统目录权限) #将文件先传输到 slave1 的 hadoop 用户主目录(主目录默认对 hadoop 用户有写入权限) scp -r /usr/local/hadoop hadoop@slave1:~ # 登录slave1 ssh hadoopd@slave1# 移动文件(需输入slave1的root密码) sudo mv ~/hadoop /usr/local/ # 同步到slave2节点(步骤与slave1相同) |
(2)同步环境变量(slave1、slave2节点hadoopd用户执行)
在slave1和slave2节点分别执行:
|-----------------------------|
| # 编辑用户环境变量文件 vim ~/.bashrc |
添加与master节点hadoopd用户一致的Hadoop环境变量:
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| export HADOOP_HOME=/usr/local/hadoop export PATH=PATH:HADOOP_HOME/bin:HADOOP_HOME/sbin export HADOOP_CONF_DIR=HADOOP_HOME/etc/hadoop export HADOOP_MAPRED_HOME=HADOOP_HOME export HADOOP_COMMON_HOME=HADOOP_HOME export HADOOP_HDFS_HOME=HADOOP_HOME export YARN_HOME=HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=HADOOP_HOME/lib" |
生效并验证:
|---------------------------------------------------|
| source ~/.bashrc hadoop version # 显示3.3.6版本即同步成功 |
4. 创建数据目录并授权(3个节点hadoopd用户均执行)
根据配置文件路径创建目录(hadoopd用户拥有完整权限):
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| # 创建临时目录、数据目录、日志目录等 mkdir -p HADOOP_HOME/tmp mkdir -p HADOOP_HOME/hdfs/name mkdir -p HADOOP_HOME/hdfs/data mkdir -p HADOOP_HOME/pids mkdir -p HADOOP_HOME/logs # 确保目录权限(hadoopd用户可读写执行) chmod -R 755 HADOOP_HOME/ |
四、集群启动与验证
1. 格式化 HDFS(首次启动必需,仅执行一次!仅master节点)
|-----------------------|
| hdfs namenode -format |
2. 启动集群服务 ( 仅master节点 )
(1)一键启动所有服务
|--------------|
| start-all.sh |
3. 集群状态验证 ( 任意节点登录 )
( 1 )Web界面验证(浏览器访问,替换为master实际IP)
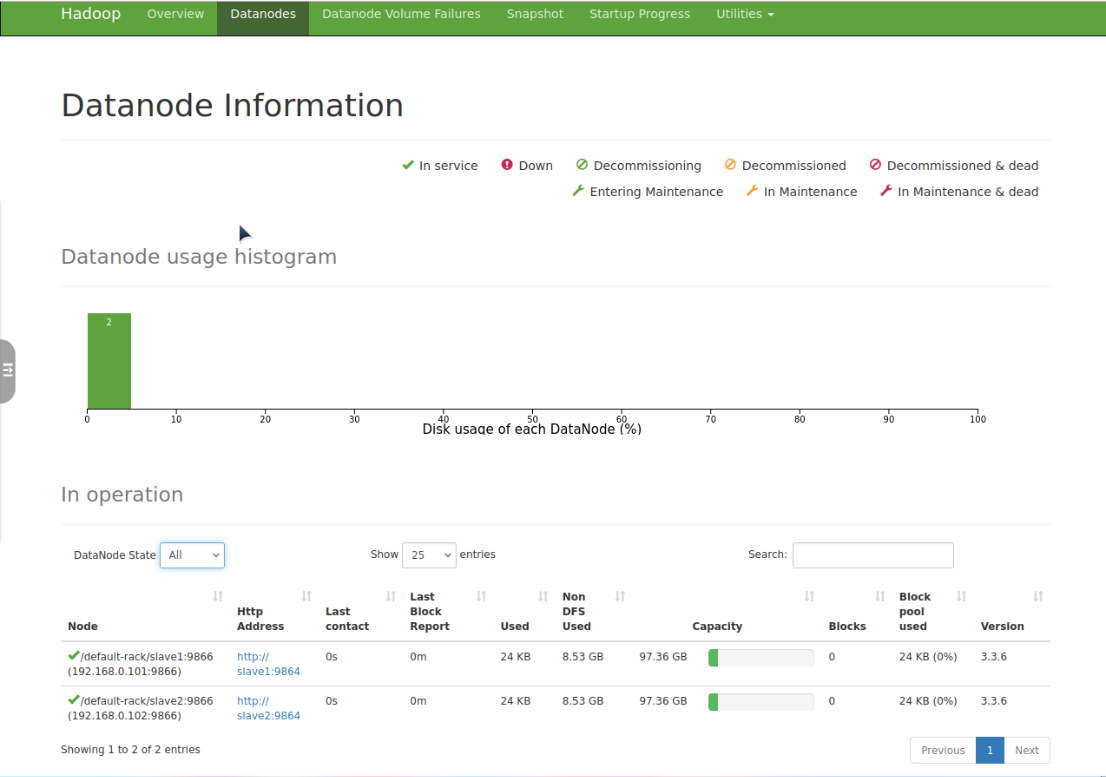
- HDFS集群状态:http://master:9870
- 左侧「Datanodes」:显示slave1、slave2两个节点(状态为In Service)
- 右侧「Summary」:副本数2,可用空间正常
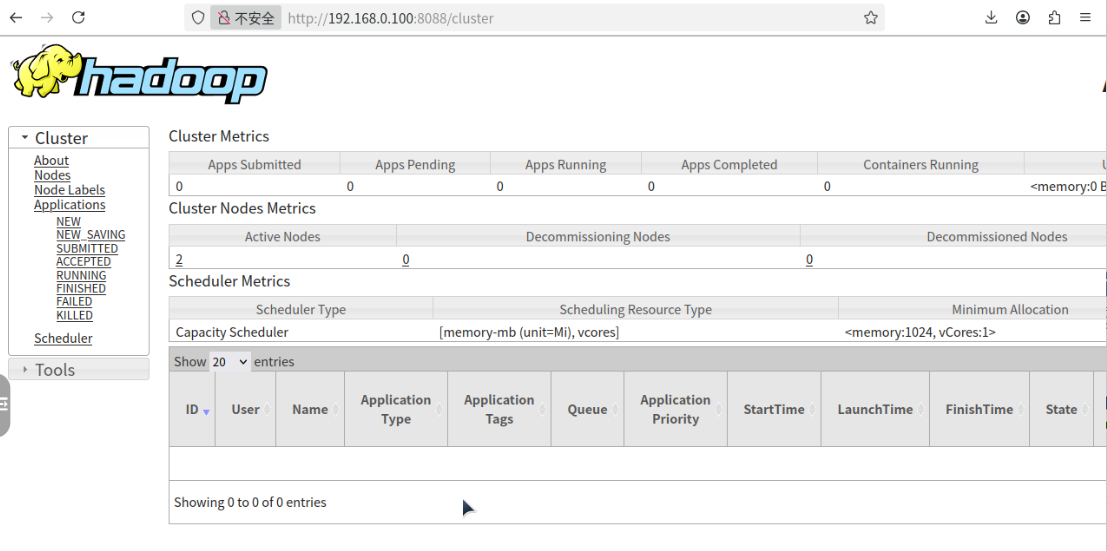
- YARN集群状态:http://master:8088
- 左侧「Nodes」:显示2个活跃节点(slave1、slave2)
- 「Cluster Metrics」:内存、CPU资源正常
- 任务历史界面:http://master:19888(需启动历史服务器)
五、生产环境优化建议
- 权限收紧:移除hadoopd用户的免密sudo权限,仅授权必要命令(如systemctl)
- 日志轮转:配置Hadoop日志轮转(修改$HADOOP_HOME/etc/hadoop/log4j.properties),避免日志占满磁盘
- 数据备份:定期备份NameNode元数据(hdfs dfsadmin -saveNamespace),备份目录权限设为hadoopd所有
- 资源调整:根据节点硬件配置优化yarn-site.xml和mapred-site.xml中的内存、CPU分配
- 防火墙精细化配置:开放必要端口(9000、9870、8088、19888、10020),禁止无关端口访问