本文记录一次做Linux作业的过程;
题目和要求是: Limux下的python多线程爬虫程序
设计基于Linux的多线程爬虫程序(可利用Scrapy、selenium等爬虫框架)将爬取的数据按照需要进行处理和分析。要求:有目的的爬取相关数据,根据需要对数据进行处理,数据量不能太少保存数据库,并设计web界面展示、进行必要的分析。

我使用的是ubuntu22.04系统;
文章目录
-
- 一、环境准备
-
- [1. 打开终端(按Ctrl+Alt+T)](#1. 打开终端(按Ctrl+Alt+T))
- [2. 更新系统包列表](#2. 更新系统包列表)
- [3. 安装Python和相关工具](#3. 安装Python和相关工具)
- [4. 安装Chrome浏览器(用于Selenium)](#4. 安装Chrome浏览器(用于Selenium))
- 二、创建项目目录结构
-
- [1. 创建项目文件夹](#1. 创建项目文件夹)
- [2. 创建项目目录结构](#2. 创建项目目录结构)
- [3. 查看完整目录结构](#3. 查看完整目录结构)
- 三、创建虚拟环境并安装依赖
-
- [1. 创建虚拟环境](#1. 创建虚拟环境)
- [2. 激活虚拟环境](#2. 激活虚拟环境)
- [3. 创建requirements.txt文件](#3. 创建requirements.txt文件)
- [4. 安装所有依赖](#4. 安装所有依赖)
- 四、配置数据库
-
- [1. 创建数据库配置文件](#1. 创建数据库配置文件)
- [2. 创建数据库初始化脚本](#2. 创建数据库初始化脚本)
- [3. 初始化数据库](#3. 初始化数据库)
- 五、创建爬虫程序
-
- [1. 创建基于Scrapy的爬虫项目](#1. 创建基于Scrapy的爬虫项目)
- [2. 创建爬虫文件](#2. 创建爬虫文件)
- [3. 创建items.py文件](#3. 创建items.py文件)
- [4. 创建pipelines.py文件(数据处理)](#4. 创建pipelines.py文件(数据处理))
- [5. 修改settings.py配置文件](#5. 修改settings.py配置文件)
- 六、创建多线程爬虫管理器
- [七、创建Flask Web应用](#七、创建Flask Web应用)
- 八、创建运行脚本
-
- [1. 创建运行爬虫的脚本](#1. 创建运行爬虫的脚本)
- [2. 创建运行Web应用的脚本](#2. 创建运行Web应用的脚本)
- [3. 创建一键安装脚本](#3. 创建一键安装脚本)
- 九、项目部署和运行
-
- [1. 首次运行安装](#1. 首次运行安装)
- [2. 运行爬虫程序](#2. 运行爬虫程序)
- [3. 运行Web应用](#3. 运行Web应用)
- [4. 访问Web界面](#4. 访问Web界面)
- [5. 图书数据为空的解决办法:](#5. 图书数据为空的解决办法:)
-
- [5.1 先解决路径问题](#5.1 先解决路径问题)
- [5.2 解决爬取的数据为空的问题](#5.2 解决爬取的数据为空的问题)
- 十、项目结构总览
- 十一、常见问题解决
-
- [1. 如果虚拟环境激活失败](#1. 如果虚拟环境激活失败)
- [2. 如果端口5000被占用](#2. 如果端口5000被占用)
- [3. 如果爬虫无法连接](#3. 如果爬虫无法连接)
- [4. 查看日志文件](#4. 查看日志文件)
- 十二、项目特点
- 十三、项目运行流程详解总结
- [十四 如何快速在虚拟机上运行](#十四 如何快速在虚拟机上运行)
一、环境准备
1. 打开终端(按Ctrl+Alt+T)
2. 更新系统包列表
bash
sudo apt update
sudo apt upgrade -y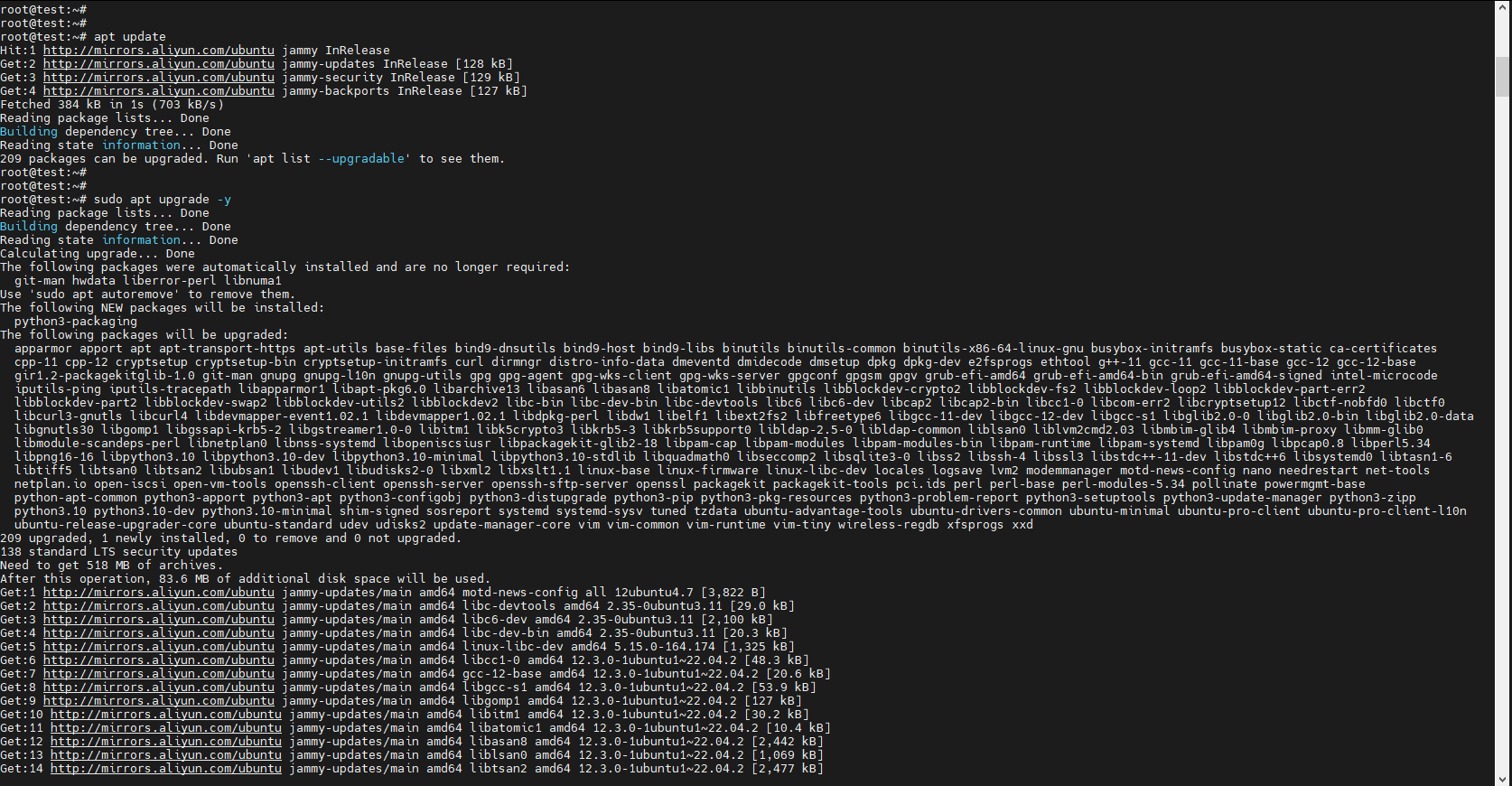
3. 安装Python和相关工具
bash
sudo apt install python3 python3-pip python3-venv -y
sudo apt install git curl wget -y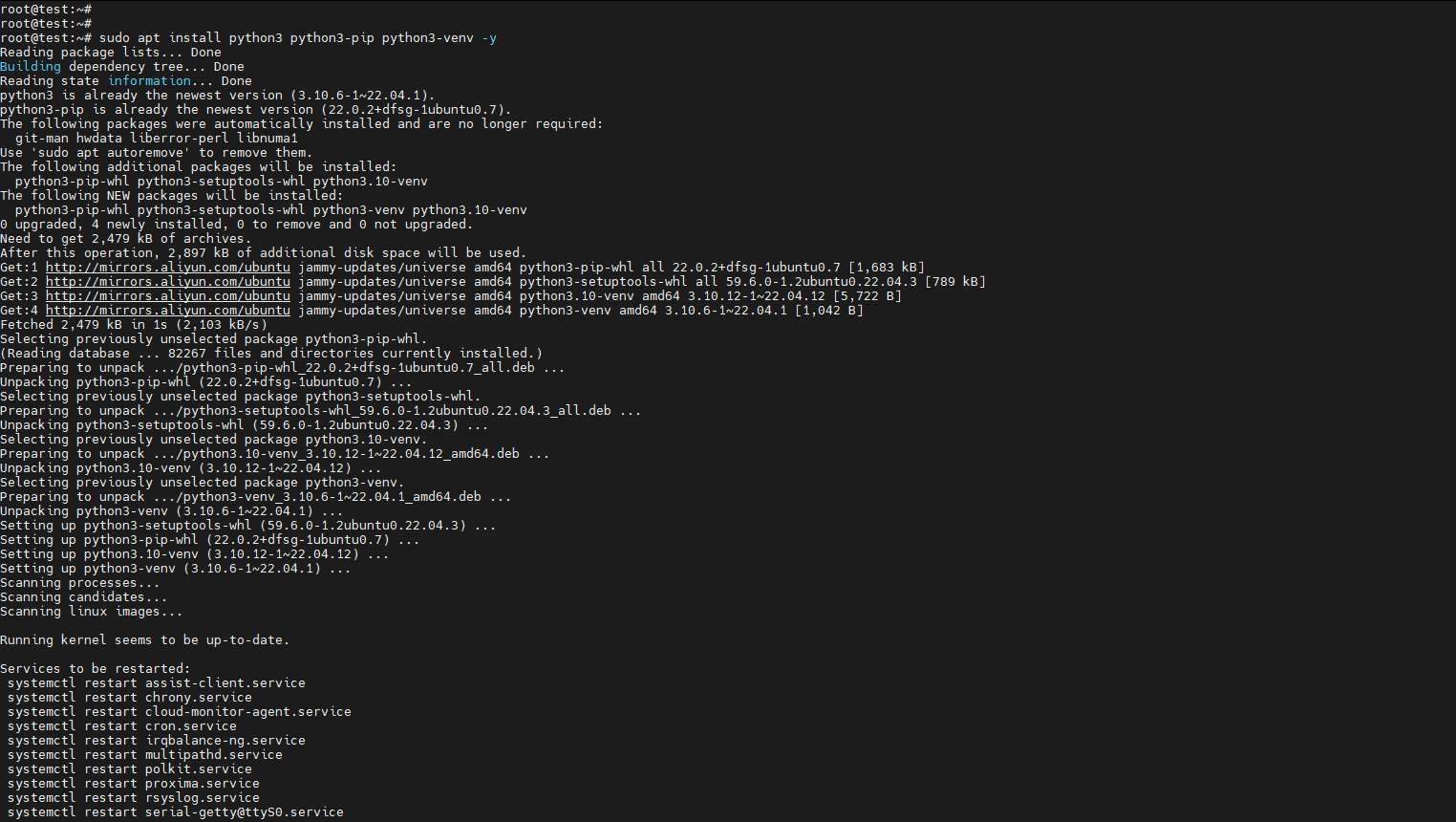
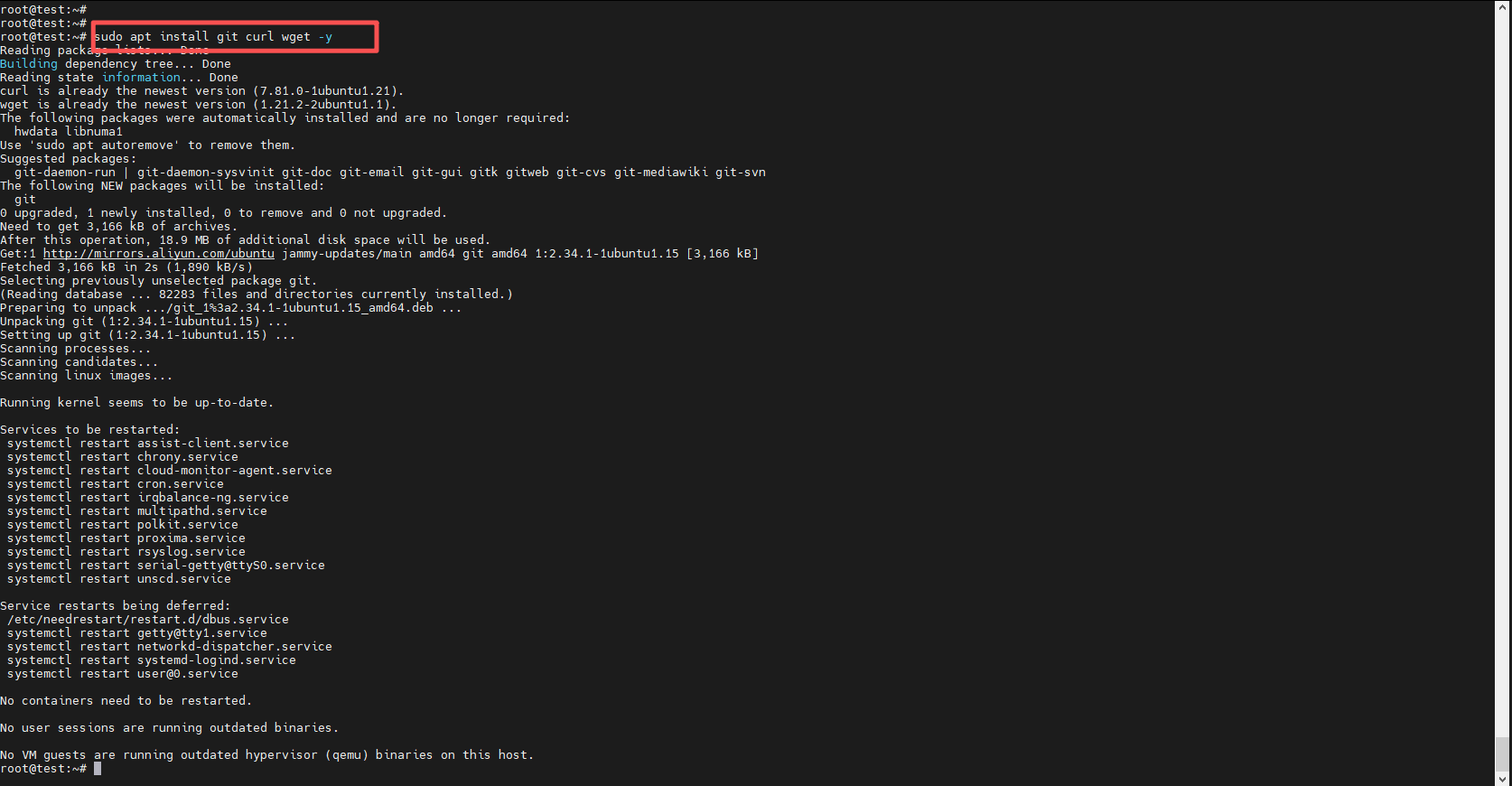
4. 安装Chrome浏览器(用于Selenium)
bash
wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
sudo sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list'
sudo apt update
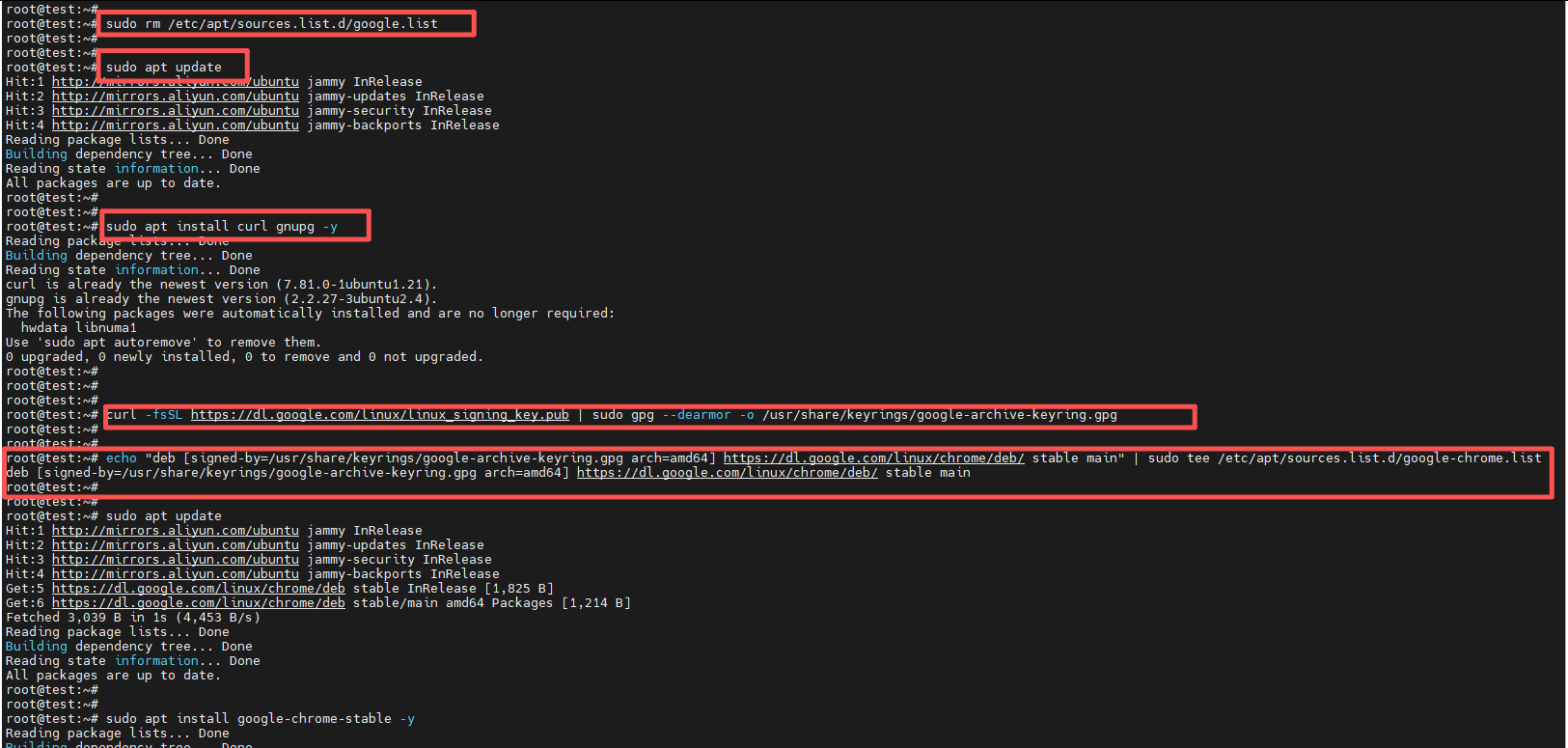
sudo apt install google-chrome-stable -y遇到错误如下:
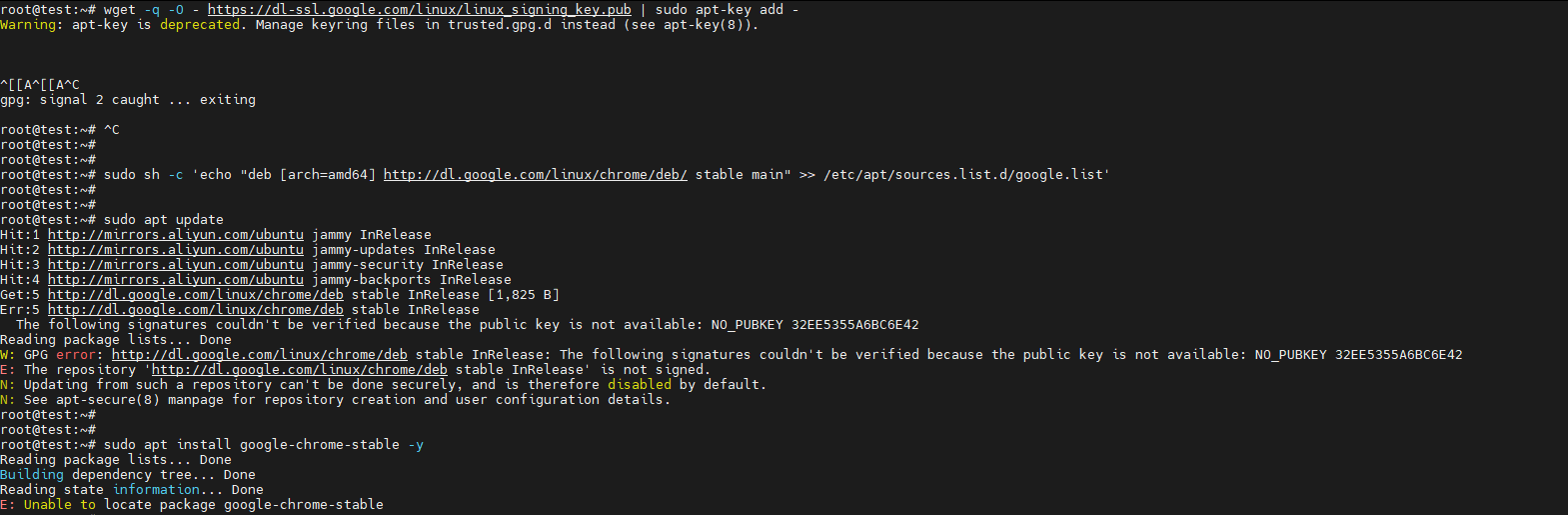
出错原因:
根据错误信息,核心问题是谷歌的GPG公钥(密钥)没有正确导入 ,导致系统无法验证谷歌软件源(http://dl.google.com/linux/chrome/deb)的签名,因此直接禁用了该源。这最终导致了"E: Unable to locate package google-chrome-stable"。
解决方案:按步骤修复并重新安装
需要先清理之前未完成的配置,然后使用新的、官方推荐的方式导入密钥。请按顺序执行以下命令:
-
清理之前的配置
将之前添加的谷歌源文件移除。
bashsudo rm /etc/apt/sources.list.d/google.list -
安装必要的依赖
bashsudo apt update sudo apt install curl gnupg -y -
【关键步骤】正确导入谷歌的GPG公钥
这是与旧方法 (
apt-key add) 的区别所在。使用curl下载密钥并正确存放在/usr/share/keyrings/目录下。bashcurl -fsSL https://dl.google.com/linux/linux_signing_key.pub | sudo gpg --dearmor -o /usr/share/keyrings/google-archive-keyring.gpg -
重新添加谷歌Chrome软件源
在添加源时,通过
signed-by参数指定我们刚刚导入的密钥文件位置。bashecho "deb [signed-by=/usr/share/keyrings/google-archive-keyring.gpg arch=amd64] https://dl.google.com/linux/chrome/deb/ stable main" | sudo tee /etc/apt/sources.list.d/google-chrome.list -
更新软件包列表并安装
bashsudo apt update sudo apt install google-chrome-stable -y -
验证安装
安装完成后,可以通过以下命令查看版本,这表示安装成功:
bashgoogle-chrome-stable --version

二、创建项目目录结构
1. 创建项目文件夹
bash
mkdir ~/python_crawler_project
cd ~/python_crawler_project
2. 创建项目目录结构
bash
mkdir -p {scrapy_crawler,flask_web/{static/css,static/js,templates},database,scripts,logs}
3. 查看完整目录结构
bash
tree ~/python_crawler_project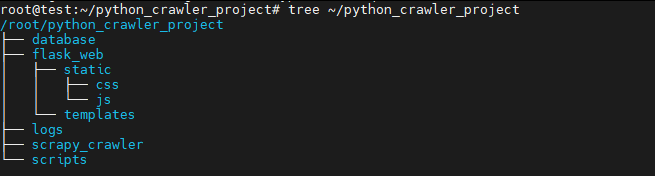
三、创建虚拟环境并安装依赖
1. 创建虚拟环境
bash
cd ~/python_crawler_project
python3 -m venv venv
2. 激活虚拟环境
bash
source venv/bin/activate
3. 创建requirements.txt文件
bash
cat > requirements.txt << 'EOF'
# 爬虫相关
scrapy>=2.8.0
selenium>=4.10.0
beautifulsoup4>=4.12.0
requests>=2.31.0
lxml>=4.9.0
# 数据库相关
sqlalchemy>=2.0.0
pymysql>=1.0.0
sqlite3
# Web框架相关
flask>=2.3.0
flask-sqlalchemy>=3.0.0
flask-bootstrap>=3.3.0
# 数据处理相关
pandas>=2.0.0
numpy>=1.24.0
matplotlib>=3.7.0
# 其他工具
python-dotenv>=1.0.0
fake-useragent>=1.4.0
schedule>=1.2.0
webdriver-manager>=4.0.0
EOF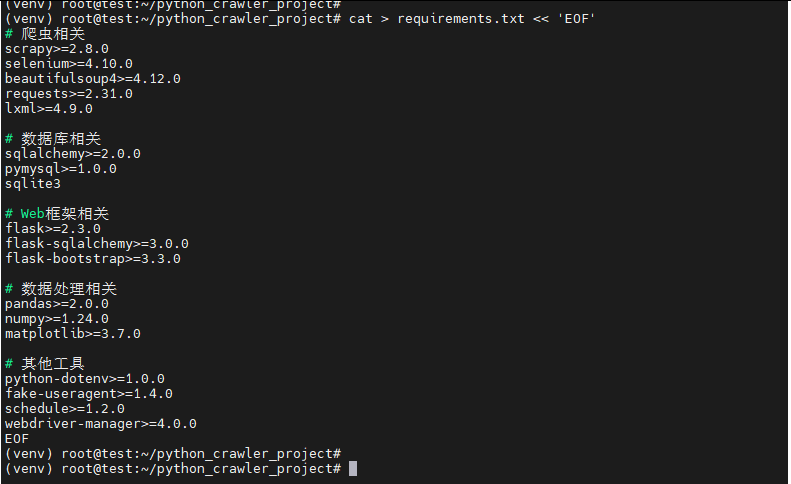
4. 安装所有依赖
bash
pip install --upgrade pip
pip install -r requirements.txt安装时报错:
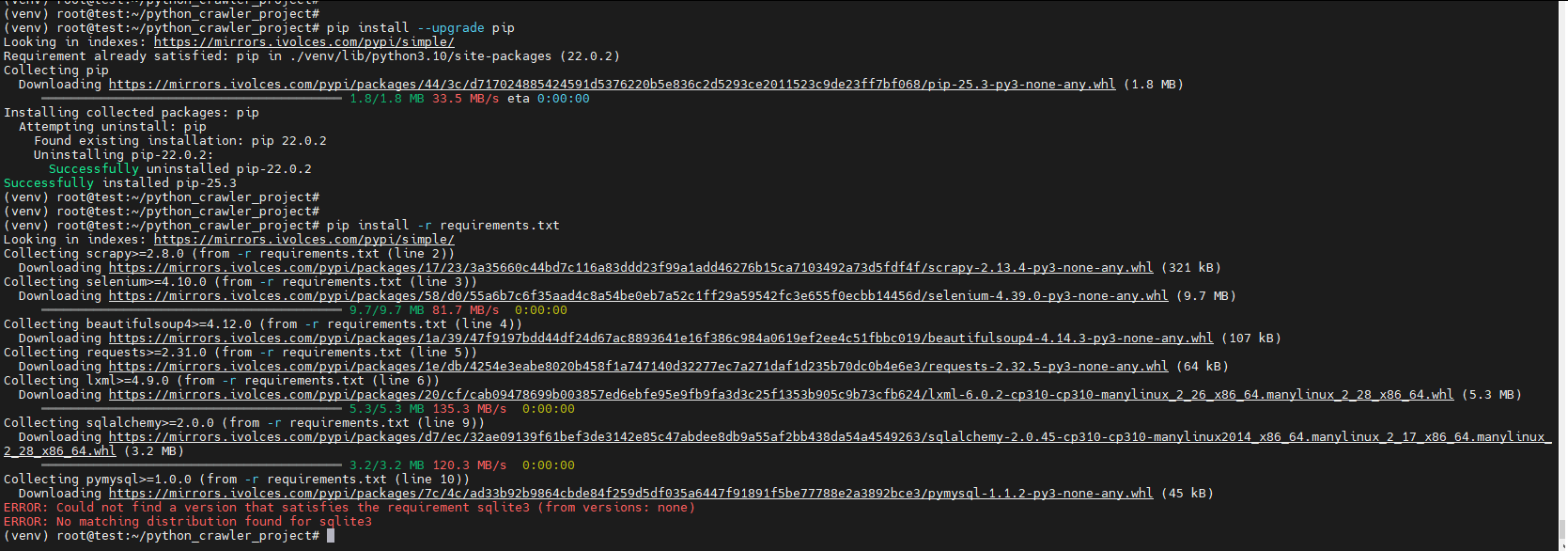
这个错误的原因:sqlite3 是 Python 的标准库,不是需要通过 pip 安装的第三方包。因此,在 requirements.txt 中列出它会导致 pip 在公共仓库中找不到这个包而报错。
解决方案
你需要从 requirements.txt 文件中移除 sqlite3 这一行。请按照以下步骤操作:
第一步:修改 requirements.txt 文件
将文件中的 sqlite3 依赖项删除。你可以使用 sed 命令快速完成,或者手动编辑文件。
bash
# 使用sed命令删除包含 'sqlite3' 的那一行
sed -i '/sqlite3/d' requirements.txt第二步:重新安装依赖
删除该行后,重新运行安装命令即可。
bash
pip install -r requirements.txt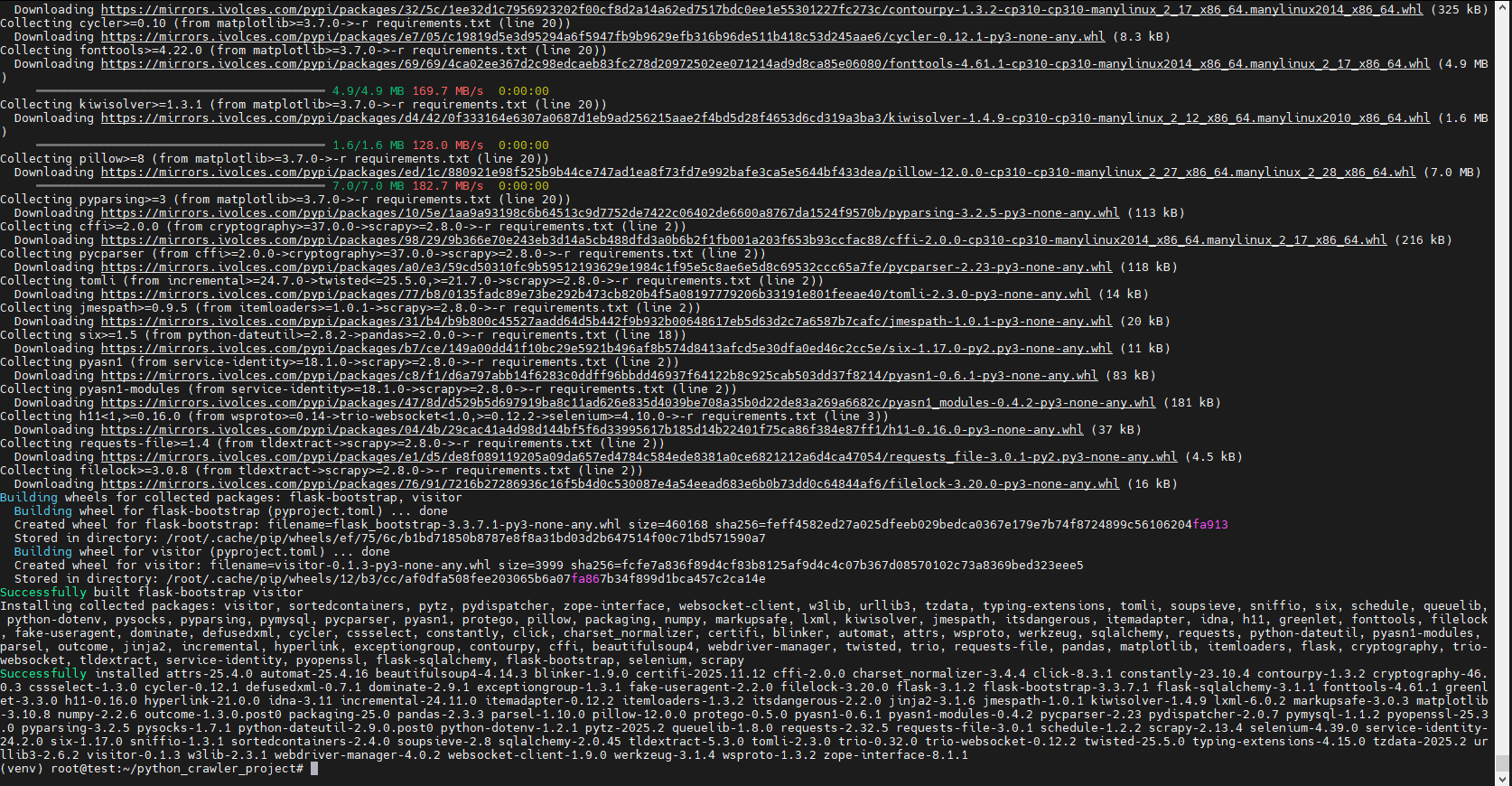
四、配置数据库
1. 创建数据库配置文件
bash
cat > database/config.py << 'EOF'
import os
from dotenv import load_dotenv
load_dotenv()
class Config:
# 数据库配置
SQLALCHEMY_DATABASE_URI = 'sqlite:///../database/crawler_data.db'
SQLALCHEMY_TRACK_MODIFICATIONS = False
# 爬虫配置
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36'
REQUEST_DELAY = 1 # 请求延迟(秒)
MAX_THREADS = 5 # 最大线程数
TIMEOUT = 10 # 请求超时时间
# 文件路径
DATA_DIR = os.path.join(os.path.dirname(__file__), '..', 'data')
LOG_DIR = os.path.join(os.path.dirname(__file__), '..', 'logs')
@staticmethod
def init_app(app):
# 确保目录存在
os.makedirs(Config.DATA_DIR, exist_ok=True)
os.makedirs(Config.LOG_DIR, exist_ok=True)
EOF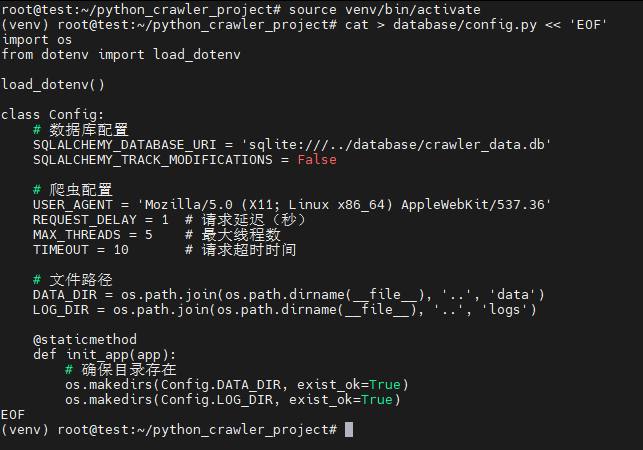
2. 创建数据库初始化脚本
bash
cat > database/init_db.py << 'EOF'
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import create_engine, Column, Integer, String, Text, DateTime, Float
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
from datetime import datetime
import os
# 创建基类
Base = declarative_base()
class Book(Base):
"""图书数据表"""
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
title = Column(String(200), nullable=False)
author = Column(String(100))
price = Column(Float)
rating = Column(Float)
category = Column(String(50))
description = Column(Text)
image_url = Column(String(500))
source_url = Column(String(500))
crawled_at = Column(DateTime, default=datetime.utcnow)
def __repr__(self):
return f"<Book {self.title}>"
def init_database():
"""初始化数据库"""
# 创建数据库目录
os.makedirs('../database', exist_ok=True)
# 创建数据库引擎
engine = create_engine('sqlite:///../database/crawler_data.db')
# 创建所有表
Base.metadata.create_all(engine)
print("数据库初始化完成!")
print(f"数据库位置: {os.path.abspath('../database/crawler_data.db')}")
if __name__ == '__main__':
init_database()
EOF3. 初始化数据库
bash
cd ~/python_crawler_project
python database/init_db.py
五、创建爬虫程序
1. 创建基于Scrapy的爬虫项目
bash
cd ~/python_crawler_project
scrapy startproject book_crawler
cd book_crawler
2. 创建爬虫文件
bash
cat > book_crawler/spiders/book_spider.py << 'EOF'
import scrapy
from scrapy.http import Request
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from book_crawler.items import BookItem
from urllib.parse import urljoin
import logging
class BookSpider(CrawlSpider):
name = 'books'
allowed_domains = ['books.toscrape.com']
start_urls = ['http://books.toscrape.com/']
# 设置爬取规则
rules = (
Rule(LinkExtractor(allow=r'catalogue/category/books/'), follow=True),
Rule(LinkExtractor(allow=r'catalogue/.*\.html'), callback='parse_book'),
)
def parse_book(self, response):
"""解析图书详情页"""
item = BookItem()
# 提取图书信息
item['title'] = response.css('h1::text').get()
item['price'] = response.css('p.price_color::text').get()
item['description'] = response.xpath('//article[@class="product_page"]/p/text()').get()
item['category'] = response.css('ul.breadcrumb li:nth-last-child(2) a::text').get()
item['rating'] = response.css('p.star-rating::attr(class)').get().split()[-1]
item['image_url'] = urljoin(response.url, response.css('img::attr(src)').get())
item['source_url'] = response.url
# 提取表格信息
table_rows = response.css('table.table-striped tr')
for row in table_rows:
header = row.css('th::text').get()
value = row.css('td::text').get()
if header == 'UPC':
item['upc'] = value
elif header == 'Product Type':
item['product_type'] = value
elif header == 'Price (excl. tax)':
item['price_excl_tax'] = value
elif header == 'Price (incl. tax)':
item['price_incl_tax'] = value
elif header == 'Tax':
item['tax'] = value
elif header == 'Availability':
item['availability'] = value
elif header == 'Number of reviews':
item['review_count'] = value
yield item
EOF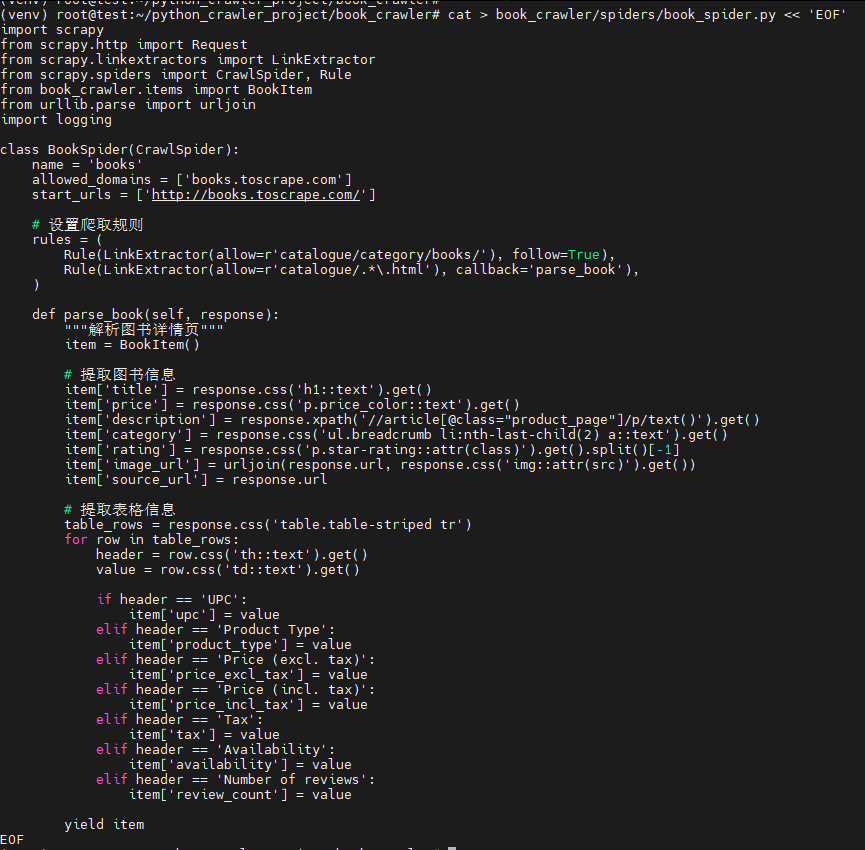
3. 创建items.py文件
bash
cat > book_crawler/items.py << 'EOF'
import scrapy
class BookItem(scrapy.Item):
# 定义数据字段
title = scrapy.Field()
price = scrapy.Field()
description = scrapy.Field()
category = scrapy.Field()
rating = scrapy.Field()
image_url = scrapy.Field()
source_url = scrapy.Field()
upc = scrapy.Field()
product_type = scrapy.Field()
price_excl_tax = scrapy.Field()
price_incl_tax = scrapy.Field()
tax = scrapy.Field()
availability = scrapy.Field()
review_count = scrapy.Field()
EOF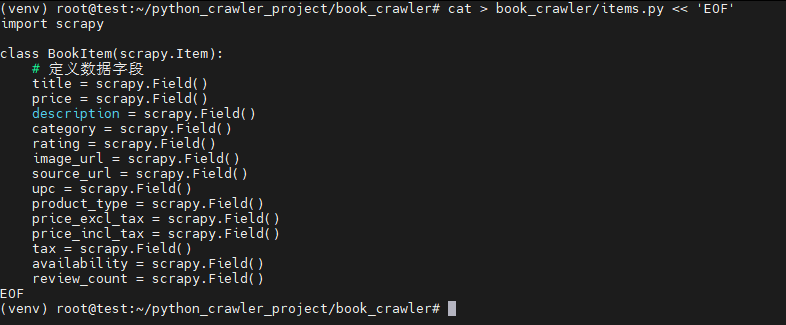
4. 创建pipelines.py文件(数据处理)
bash
cat > book_crawler/pipelines.py << 'EOF'
import sqlite3
from datetime import datetime
import logging
class BookPipeline:
def __init__(self):
self.con = sqlite3.connect('../database/crawler_data.db')
self.cur = self.con.cursor()
self.create_table()
def create_table(self):
"""创建数据库表"""
self.cur.execute('''
CREATE TABLE IF NOT EXISTS books(
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT,
price REAL,
description TEXT,
category TEXT,
rating TEXT,
image_url TEXT,
source_url TEXT,
upc TEXT,
product_type TEXT,
price_excl_tax TEXT,
price_incl_tax TEXT,
tax TEXT,
availability TEXT,
review_count INTEGER,
crawled_at TIMESTAMP
)
''')
self.con.commit()
def process_item(self, item, spider):
"""处理爬取的数据"""
# 清洗价格数据
if item.get('price'):
try:
item['price'] = float(item['price'].replace('£', ''))
except:
item['price'] = 0.0
# 插入数据库
self.cur.execute('''
INSERT INTO books VALUES (
NULL, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?
)
''', (
item.get('title'),
item.get('price'),
item.get('description'),
item.get('category'),
item.get('rating'),
item.get('image_url'),
item.get('source_url'),
item.get('upc'),
item.get('product_type'),
item.get('price_excl_tax'),
item.get('price_incl_tax'),
item.get('tax'),
item.get('availability'),
item.get('review_count'),
datetime.now()
))
self.con.commit()
logging.info(f"保存图书: {item.get('title')}")
return item
def close_spider(self, spider):
self.con.close()
EOF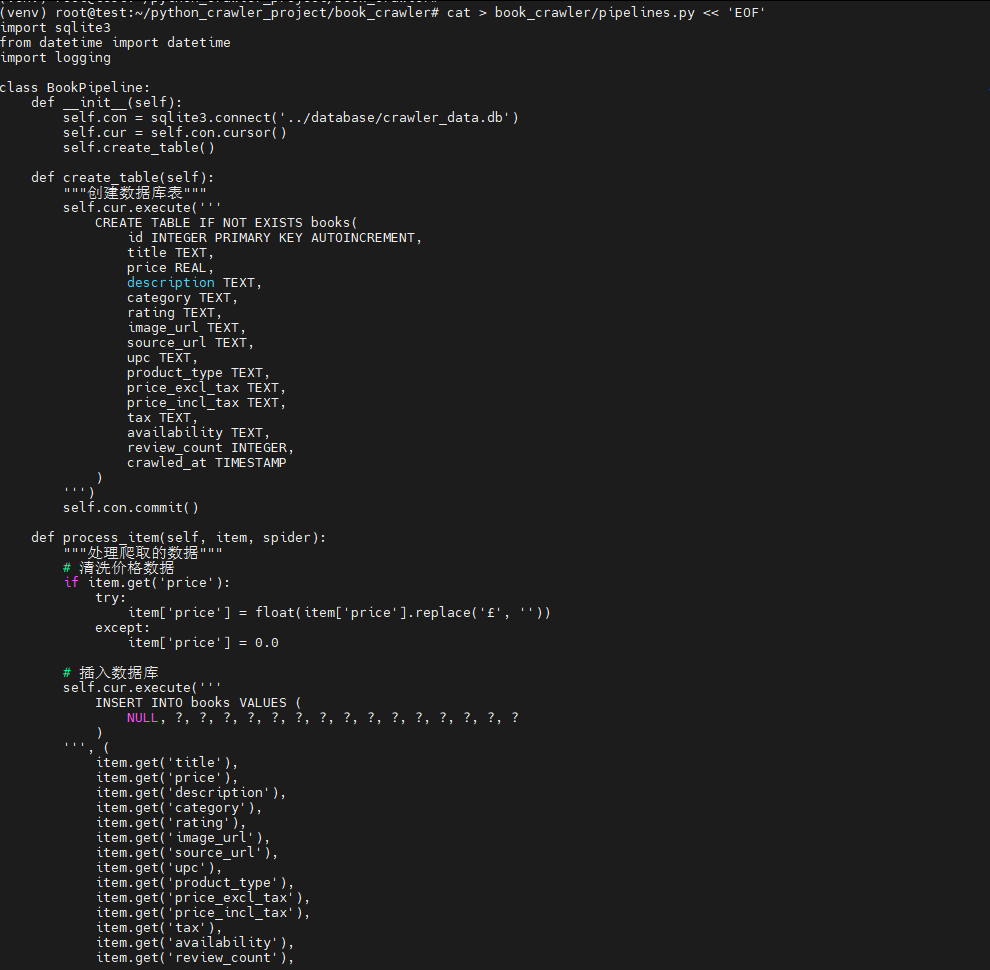
5. 修改settings.py配置文件
bash
cat > book_crawler/settings.py << 'EOF'
BOT_NAME = 'book_crawler'
SPIDER_MODULES = ['book_crawler.spiders']
NEWSPIDER_MODULE = 'book_crawler.spiders'
# 遵守robots协议
ROBOTSTXT_OBEY = True
# 并发设置
CONCURRENT_REQUESTS = 16
CONCURRENT_REQUESTS_PER_DOMAIN = 8
CONCURRENT_REQUESTS_PER_IP = 0
# 下载延迟
DOWNLOAD_DELAY = 0.5
# 启用pipelines
ITEM_PIPELINES = {
'book_crawler.pipelines.BookPipeline': 300,
}
# 启用中间件
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 400,
}
# 日志设置
LOG_LEVEL = 'INFO'
LOG_FILE = '../logs/crawler.log'
# 自动限速
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_START_DELAY = 1
AUTOTHROTTLE_MAX_DELAY = 60
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
EOF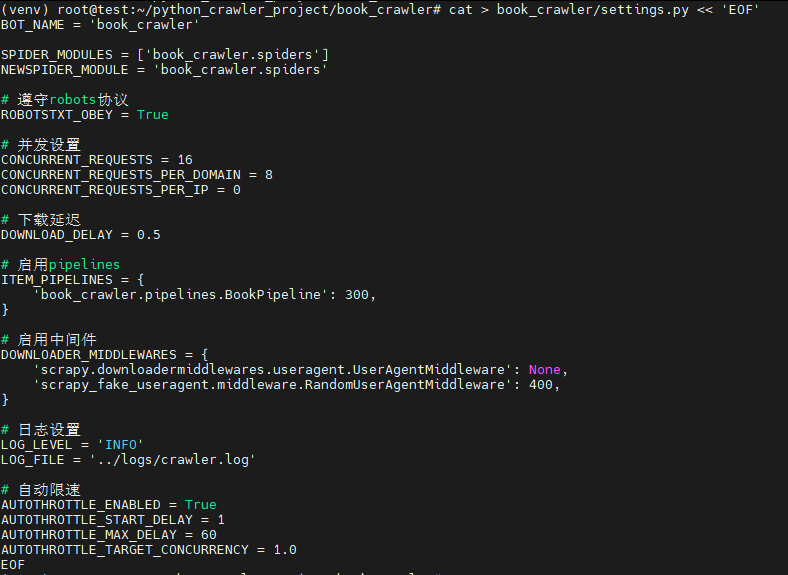
六、创建多线程爬虫管理器
bash
cat > ~/python_crawler_project/scripts/crawler_manager.py << 'EOF'
#!/usr/bin/env python3
"""
多线程爬虫管理器
"""
import threading
import queue
import time
from datetime import datetime
import logging
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
import subprocess
import sys
import os
# 添加项目路径
sys.path.append(os.path.join(os.path.dirname(__file__), '..'))
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('../logs/crawler_manager.log'),
logging.StreamHandler()
]
)
logger = logging.getLogger(__name__)
class MultiThreadCrawler:
"""多线程爬虫管理器"""
def __init__(self, num_threads=3):
self.num_threads = num_threads
self.queue = queue.Queue()
self.results = []
self.lock = threading.Lock()
def run_spider(self, spider_name, start_urls):
"""运行单个爬虫"""
try:
logger.info(f"启动爬虫: {spider_name}")
# 使用subprocess运行Scrapy命令
cmd = [
'scrapy', 'crawl', spider_name,
'-a', f'start_urls={",".join(start_urls)}'
]
result = subprocess.run(
cmd,
cwd='../book_crawler',
capture_output=True,
text=True
)
with self.lock:
if result.returncode == 0:
self.results.append({
'spider': spider_name,
'status': 'success',
'output': result.stdout
})
logger.info(f"爬虫 {spider_name} 完成")
else:
self.results.append({
'spider': spider_name,
'status': 'failed',
'error': result.stderr
})
logger.error(f"爬虫 {spider_name} 失败: {result.stderr}")
except Exception as e:
with self.lock:
self.results.append({
'spider': spider_name,
'status': 'error',
'error': str(e)
})
logger.error(f"爬虫 {spider_name} 异常: {str(e)}")
def worker(self):
"""工作线程"""
while True:
try:
task = self.queue.get(timeout=5)
if task is None:
break
spider_name, start_urls = task
self.run_spider(spider_name, start_urls)
self.queue.task_done()
except queue.Empty:
break
except Exception as e:
logger.error(f"工作线程异常: {str(e)}")
break
def start(self, tasks):
"""启动多线程爬虫"""
logger.info(f"开始多线程爬虫,线程数: {self.num_threads}")
# 添加任务到队列
for task in tasks:
self.queue.put(task)
# 创建工作线程
threads = []
for i in range(self.num_threads):
thread = threading.Thread(target=self.worker, name=f"CrawlerThread-{i+1}")
thread.start()
threads.append(thread)
# 等待所有任务完成
self.queue.join()
# 停止工作线程
for _ in range(self.num_threads):
self.queue.put(None)
for thread in threads:
thread.join()
logger.info("所有爬虫任务完成")
# 打印结果
self.print_results()
def print_results(self):
"""打印爬取结果"""
print("\n" + "="*50)
print("爬虫执行结果:")
print("="*50)
success_count = sum(1 for r in self.results if r['status'] == 'success')
failed_count = sum(1 for r in self.results if r['status'] == 'failed')
error_count = sum(1 for r in self.results if r['status'] == 'error')
print(f"成功: {success_count}")
print(f"失败: {failed_count}")
print(f"错误: {error_count}")
for result in self.results:
print(f"\n爬虫: {result['spider']}")
print(f"状态: {result['status']}")
if result['status'] == 'success':
print("输出: 成功完成")
else:
print(f"错误: {result.get('error', 'Unknown error')}")
print("\n" + "="*50)
def main():
"""主函数"""
# 定义爬虫任务
tasks = [
('books', ['http://books.toscrape.com/catalogue/category/books/travel_2/index.html']),
('books', ['http://books.toscrape.com/catalogue/category/books/mystery_3/index.html']),
('books', ['http://books.toscrape.com/catalogue/category/books/historical-fiction_4/index.html']),
('books', ['http://books.toscrape.com/catalogue/category/books/science-fiction_16/index.html']),
('books', ['http://books.toscrape.com/catalogue/category/books/fantasy_19/index.html']),
]
# 创建并启动多线程爬虫
crawler = MultiThreadCrawler(num_threads=3)
crawler.start(tasks)
if __name__ == '__main__':
main()
EOF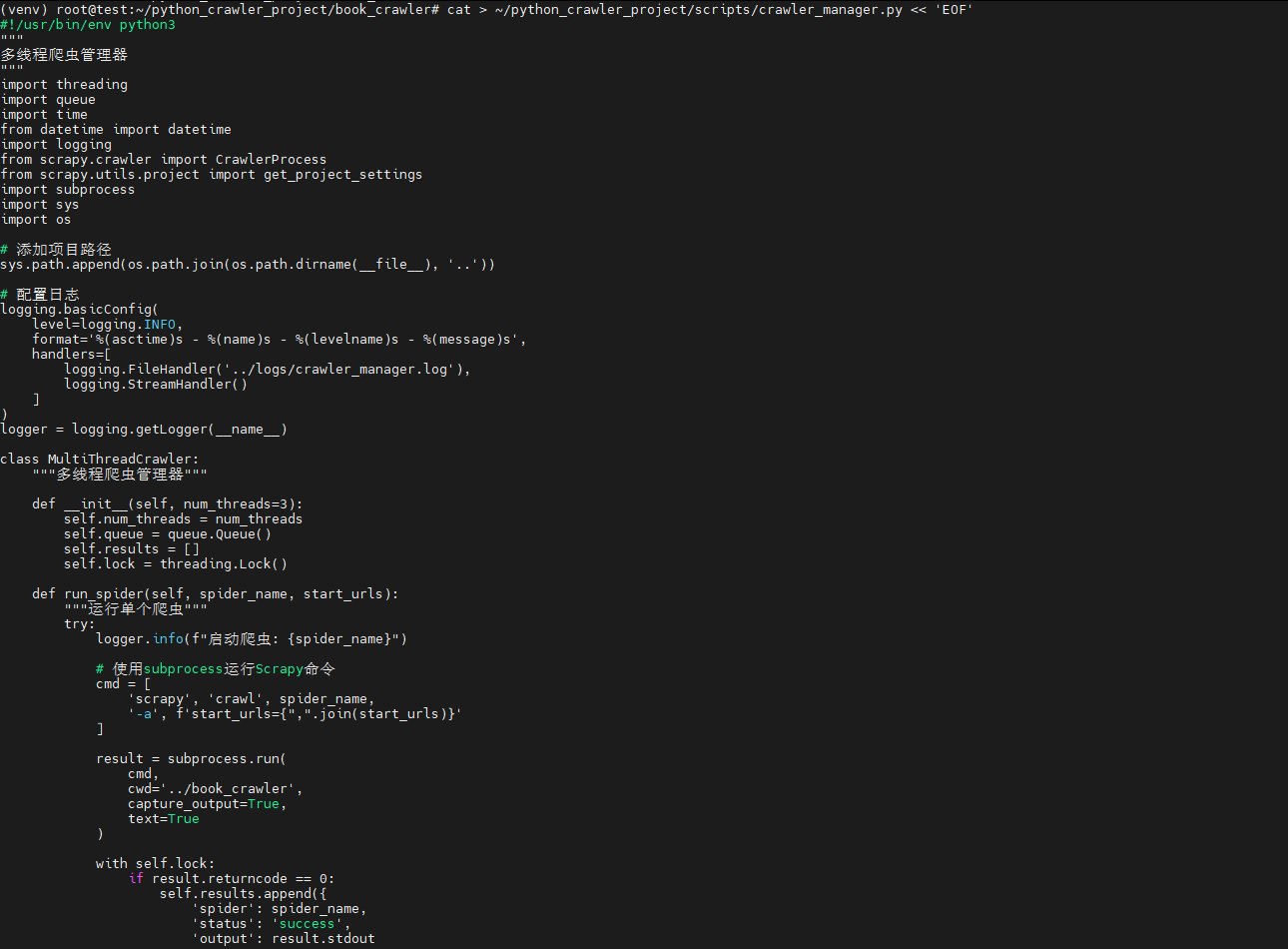
七、创建Flask Web应用
1. 创建Flask主应用
bash
cat > ~/python_crawler_project/flask_web/app.py << 'EOF'
#!/usr/bin/env python3
"""
Flask Web应用 - 展示爬取的数据
"""
from flask import Flask, render_template, request, jsonify, send_file
from flask_sqlalchemy import SQLAlchemy
from flask_bootstrap import Bootstrap
import pandas as pd
import matplotlib.pyplot as plt
import io
import base64
from datetime import datetime, timedelta
import json
import os
# 创建Flask应用
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///../database/crawler_data.db'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SECRET_KEY'] = 'your-secret-key-here'
# 初始化扩展
db = SQLAlchemy(app)
Bootstrap(app)
# 定义数据库模型
class Book(db.Model):
__tablename__ = 'books'
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(200), nullable=False)
price = db.Column(db.Float)
description = db.Column(db.Text)
category = db.Column(db.String(50))
rating = db.Column(db.String(10))
image_url = db.Column(db.String(500))
source_url = db.Column(db.String(500))
upc = db.Column(db.String(50))
product_type = db.Column(db.String(50))
price_excl_tax = db.Column(db.String(20))
price_incl_tax = db.Column(db.String(20))
tax = db.Column(db.String(20))
availability = db.Column(db.String(50))
review_count = db.Column(db.Integer)
crawled_at = db.Column(db.DateTime)
# 路由
@app.route('/')
def index():
"""首页"""
# 获取统计数据
total_books = Book.query.count()
categories = db.session.query(Book.category, db.func.count(Book.id)).group_by(Book.category).all()
avg_price = db.session.query(db.func.avg(Book.price)).scalar() or 0
# 获取最新图书
recent_books = Book.query.order_by(Book.crawled_at.desc()).limit(10).all()
return render_template('index.html',
total_books=total_books,
categories=categories,
avg_price=round(avg_price, 2),
recent_books=recent_books)
@app.route('/books')
def books():
"""图书列表页"""
page = request.args.get('page', 1, type=int)
per_page = 20
category = request.args.get('category', '')
# 构建查询
query = Book.query
if category:
query = query.filter_by(category=category)
# 分页
pagination = query.order_by(Book.title).paginate(page=page, per_page=per_page, error_out=False)
books = pagination.items
# 获取所有分类
categories = db.session.query(Book.category).distinct().all()
categories = [c[0] for c in categories if c[0]]
return render_template('books.html',
books=books,
pagination=pagination,
categories=categories,
selected_category=category)
@app.route('/analysis')
def analysis():
"""数据分析页"""
# 获取所有数据
books = Book.query.all()
if not books:
return render_template('analysis.html', charts=[])
# 转换为DataFrame
data = []
for book in books:
data.append({
'title': book.title,
'price': book.price,
'category': book.category,
'rating': book.rating,
'review_count': book.review_count or 0
})
df = pd.DataFrame(data)
# 生成图表
charts = []
# 1. 价格分布图
plt.figure(figsize=(10, 6))
df['price'].hist(bins=20, edgecolor='black')
plt.title('图书价格分布')
plt.xlabel('价格 (£)')
plt.ylabel('数量')
plt.tight_layout()
price_chart = get_chart_base64()
charts.append({'title': '价格分布', 'image': price_chart})
# 2. 分类统计
plt.figure(figsize=(12, 6))
category_counts = df['category'].value_counts().head(10)
category_counts.plot(kind='bar')
plt.title('图书分类统计(Top 10)')
plt.xlabel('分类')
plt.ylabel('数量')
plt.xticks(rotation=45)
plt.tight_layout()
category_chart = get_chart_base64()
charts.append({'title': '分类统计', 'image': category_chart})
# 3. 评分分布
plt.figure(figsize=(10, 6))
rating_counts = df['rating'].value_counts()
rating_counts.plot(kind='pie', autopct='%1.1f%%')
plt.title('图书评分分布')
plt.ylabel('')
plt.tight_layout()
rating_chart = get_chart_base64()
charts.append({'title': '评分分布', 'image': rating_chart})
# 4. 价格与评分关系
plt.figure(figsize=(10, 6))
rating_price = df.groupby('rating')['price'].mean()
rating_price.plot(kind='bar')
plt.title('不同评分的平均价格')
plt.xlabel('评分')
plt.ylabel('平均价格 (£)')
plt.tight_layout()
relation_chart = get_chart_base64()
charts.append({'title': '评分与价格关系', 'image': relation_chart})
return render_template('analysis.html', charts=charts)
@app.route('/api/books')
def api_books():
"""API接口 - 获取图书数据"""
page = request.args.get('page', 1, type=int)
per_page = request.args.get('per_page', 10, type=int)
query = Book.query
pagination = query.paginate(page=page, per_page=per_page)
books = []
for book in pagination.items:
books.append({
'id': book.id,
'title': book.title,
'price': book.price,
'category': book.category,
'rating': book.rating,
'description': book.description[:100] + '...' if book.description and len(book.description) > 100 else book.description
})
return jsonify({
'books': books,
'total': pagination.total,
'pages': pagination.pages,
'current_page': pagination.page
})
@app.route('/api/stats')
def api_stats():
"""API接口 - 获取统计数据"""
total_books = Book.query.count()
categories = db.session.query(Book.category, db.func.count(Book.id)).group_by(Book.category).all()
avg_price = db.session.query(db.func.avg(Book.price)).scalar() or 0
# 价格范围统计
price_ranges = {
'0-5': Book.query.filter(Book.price.between(0, 5)).count(),
'5-10': Book.query.filter(Book.price.between(5, 10)).count(),
'10-20': Book.query.filter(Book.price.between(10, 20)).count(),
'20+': Book.query.filter(Book.price > 20).count()
}
return jsonify({
'total_books': total_books,
'avg_price': round(avg_price, 2),
'categories': dict(categories),
'price_ranges': price_ranges
})
def get_chart_base64():
"""将matplotlib图表转换为base64编码"""
buffer = io.BytesIO()
plt.savefig(buffer, format='png')
buffer.seek(0)
image_base64 = base64.b64encode(buffer.getvalue()).decode('utf-8')
plt.close()
return image_base64
@app.route('/export/csv')
def export_csv():
"""导出数据为CSV"""
books = Book.query.all()
data = []
for book in books:
data.append({
'标题': book.title,
'价格': book.price,
'分类': book.category,
'评分': book.rating,
'描述': book.description,
'URL': book.source_url,
'爬取时间': book.crawled_at
})
df = pd.DataFrame(data)
# 创建CSV文件
csv_buffer = io.StringIO()
df.to_csv(csv_buffer, index=False, encoding='utf-8-sig')
# 发送文件
csv_buffer.seek(0)
return send_file(
io.BytesIO(csv_buffer.getvalue().encode('utf-8-sig')),
mimetype='text/csv',
as_attachment=True,
download_name=f'books_{datetime.now().strftime("%Y%m%d_%H%M%S")}.csv'
)
if __name__ == '__main__':
# 确保数据库存在
with app.app_context():
db.create_all()
print("Flask应用启动中...")
print("访问地址: http://127.0.0.1:5000")
print("按 Ctrl+C 停止应用")
app.run(host='0.0.0.0', port=5000, debug=True)
EOF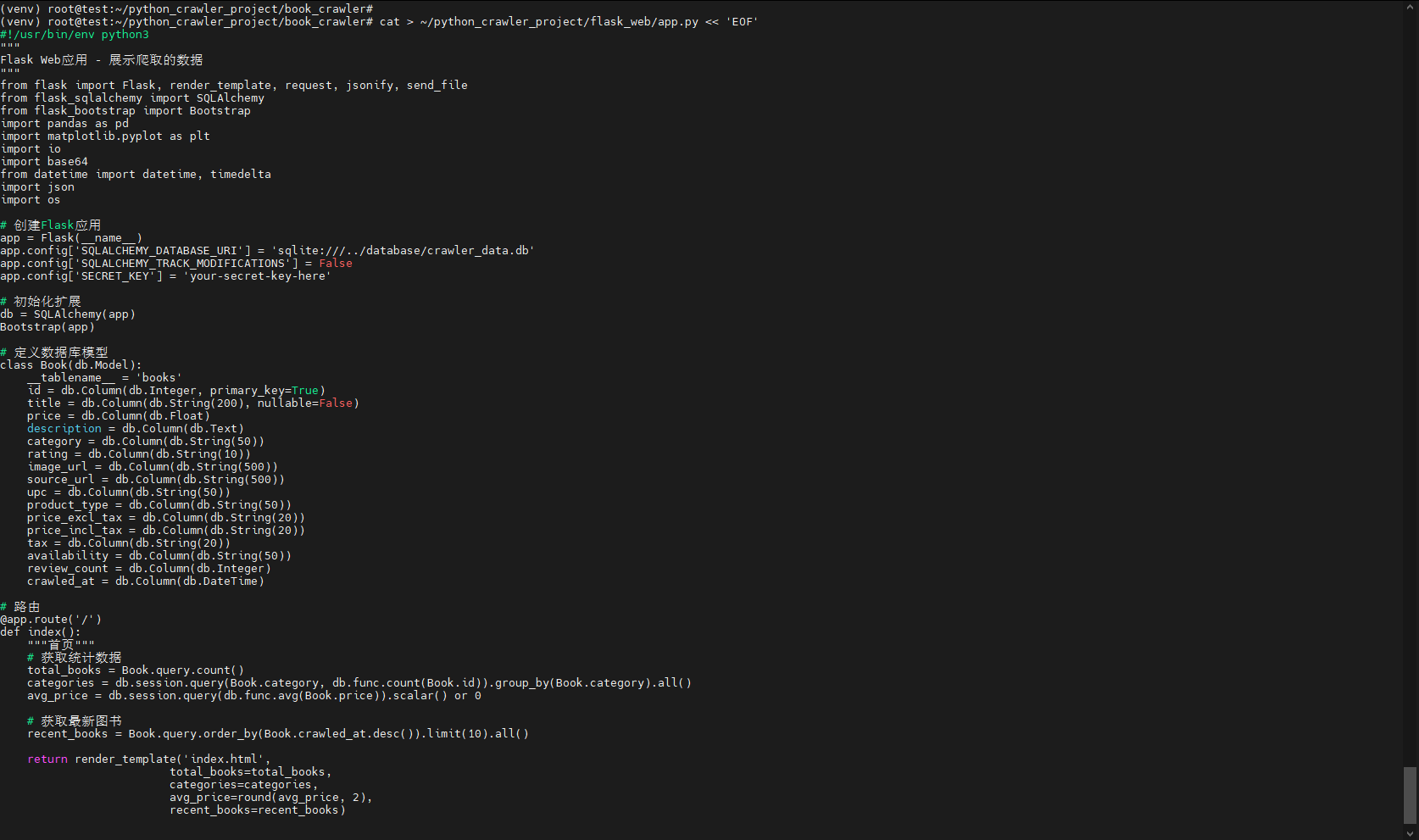
2. 创建HTML模板
创建基础模板
bash
cat > ~/python_crawler_project/flask_web/templates/base.html << 'EOF'
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>{% block title %}图书爬虫数据展示{% endblock %}</title>
<link rel="stylesheet" href="https://cdn.bootcdn.net/ajax/libs/twitter-bootstrap/4.6.0/css/bootstrap.min.css">
<link rel="stylesheet" href="https://cdn.bootcdn.net/ajax/libs/font-awesome/5.15.3/css/all.min.css">
<style>
body {
background-color: #f8f9fa;
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;
}
.navbar {
box-shadow: 0 2px 4px rgba(0,0,0,.1);
}
.card {
box-shadow: 0 2px 4px rgba(0,0,0,.1);
border: none;
margin-bottom: 20px;
transition: transform 0.3s;
}
.card:hover {
transform: translateY(-5px);
}
.stat-card {
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
color: white;
}
.footer {
background-color: #343a40;
color: white;
padding: 20px 0;
margin-top: 50px;
}
.book-image {
height: 200px;
object-fit: cover;
}
.chart-container {
background: white;
border-radius: 10px;
padding: 20px;
margin-bottom: 30px;
box-shadow: 0 2px 10px rgba(0,0,0,.1);
}
</style>
{% block extra_css %}{% endblock %}
</head>
<body>
<!-- 导航栏 -->
<nav class="navbar navbar-expand-lg navbar-dark bg-dark">
<div class="container">
<a class="navbar-brand" href="/">
<i class="fas fa-spider"></i> 图书爬虫系统
</a>
<button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarNav">
<span class="navbar-toggler-icon"></span>
</button>
<div class="collapse navbar-collapse" id="navbarNav">
<ul class="navbar-nav ml-auto">
<li class="nav-item">
<a class="nav-link" href="/">
<i class="fas fa-home"></i> 首页
</a>
</li>
<li class="nav-item">
<a class="nav-link" href="/books">
<i class="fas fa-book"></i> 图书列表
</a>
</li>
<li class="nav-item">
<a class="nav-link" href="/analysis">
<i class="fas fa-chart-bar"></i> 数据分析
</a>
</li>
<li class="nav-item">
<a class="nav-link" href="/export/csv">
<i class="fas fa-download"></i> 导出数据
</a>
</li>
</ul>
</div>
</div>
</nav>
<!-- 主要内容 -->
<div class="container mt-4">
{% with messages = get_flashed_messages() %}
{% if messages %}
{% for message in messages %}
<div class="alert alert-info alert-dismissible fade show">
{{ message }}
<button type="button" class="close" data-dismiss="alert">
<span>×</span>
</button>
</div>
{% endfor %}
{% endif %}
{% endwith %}
{% block content %}{% endblock %}
</div>
<!-- 页脚 -->
<footer class="footer">
<div class="container text-center">
<p>© 2023 图书爬虫系统 | 基于Linux的Python多线程爬虫项目</p>
<p class="mb-0">
<i class="fas fa-code"></i> 使用 Python, Scrapy, Flask, SQLite 构建
</p>
</div>
</footer>
<!-- 脚本 -->
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.6.0/jquery.min.js"></script>
<script src="https://cdn.bootcdn.net/ajax/libs/twitter-bootstrap/4.6.0/js/bootstrap.bundle.min.js"></script>
<script src="https://cdn.bootcdn.net/ajax/libs/Chart.js/3.5.0/chart.min.js"></script>
{% block extra_js %}{% endblock %}
</body>
</html>
EOF
创建首页模板
bash
cat > ~/python_crawler_project/flask_web/templates/index.html << 'EOF'
{% extends "base.html" %}
{% block title %}首页 - 图书爬虫系统{% endblock %}
{% block content %}
<div class="row mb-4">
<div class="col-12">
<div class="jumbotron bg-primary text-white">
<h1 class="display-4">
<i class="fas fa-spider"></i> 图书爬虫数据展示系统
</h1>
<p class="lead">基于Linux的Python多线程爬虫项目,实时展示爬取的图书数据</p>
<hr class="my-4 bg-white">
<p>本系统使用Scrapy框架进行多线程爬虫,数据存储于SQLite数据库,通过Flask Web框架进行展示和分析。</p>
<a class="btn btn-light btn-lg" href="/books" role="button">
<i class="fas fa-book"></i> 查看图书列表
</a>
</div>
</div>
</div>
<!-- 统计卡片 -->
<div class="row mb-4">
<div class="col-md-4">
<div class="card stat-card">
<div class="card-body text-center">
<h1 class="display-4">{{ total_books }}</h1>
<h5 class="card-title">总图书数量</h5>
<i class="fas fa-book fa-2x mb-3"></i>
</div>
</div>
</div>
<div class="col-md-4">
<div class="card stat-card" style="background: linear-gradient(135deg, #f093fb 0%, #f5576c 100%);">
<div class="card-body text-center">
<h1 class="display-4">£{{ avg_price }}</h1>
<h5 class="card-title">平均价格</h5>
<i class="fas fa-pound-sign fa-2x mb-3"></i>
</div>
</div>
</div>
<div class="col-md-4">
<div class="card stat-card" style="background: linear-gradient(135deg, #4facfe 0%, #00f2fe 100%);">
<div class="card-body text-center">
<h1 class="display-4">{{ categories|length }}</h1>
<h5 class="card-title">分类数量</h5>
<i class="fas fa-tags fa-2x mb-3"></i>
</div>
</div>
</div>
</div>
<!-- 分类统计 -->
<div class="row">
<div class="col-md-6">
<div class="card">
<div class="card-header">
<h5 class="mb-0">
<i class="fas fa-chart-pie"></i> 图书分类统计
</h5>
</div>
<div class="card-body">
<div class="chart-container">
<canvas id="categoryChart"></canvas>
</div>
</div>
</div>
</div>
<div class="col-md-6">
<div class="card">
<div class="card-header">
<h5 class="mb-0">
<i class="fas fa-book-reader"></i> 最新爬取的图书
</h5>
</div>
<div class="card-body">
<div class="list-group">
{% for book in recent_books %}
<a href="#" class="list-group-item list-group-item-action">
<div class="d-flex w-100 justify-content-between">
<h6 class="mb-1">{{ book.title }}</h6>
<small class="text-success">£{{ book.price }}</small>
</div>
<p class="mb-1 text-muted small">
<i class="fas fa-tag"></i> {{ book.category }}
<span class="ml-3">
<i class="fas fa-star text-warning"></i> {{ book.rating }}
</span>
</p>
<small>{{ book.crawled_at.strftime('%Y-%m-%d %H:%M') }}</small>
</a>
{% endfor %}
</div>
</div>
</div>
</div>
</div>
<!-- 系统信息 -->
<div class="row mt-4">
<div class="col-12">
<div class="card">
<div class="card-header">
<h5 class="mb-0">
<i class="fas fa-info-circle"></i> 系统信息
</h5>
</div>
<div class="card-body">
<div class="row">
<div class="col-md-3 text-center">
<i class="fas fa-linux fa-3x text-primary mb-3"></i>
<h6>Ubuntu 22.04</h6>
</div>
<div class="col-md-3 text-center">
<i class="fab fa-python fa-3x text-primary mb-3"></i>
<h6>Python 3.x</h6>
</div>
<div class="col-md-3 text-center">
<i class="fas fa-database fa-3x text-primary mb-3"></i>
<h6>SQLite 数据库</h6>
</div>
<div class="col-md-3 text-center">
<i class="fas fa-globe fa-3x text-primary mb-3"></i>
<h6>Flask Web框架</h6>
</div>
</div>
</div>
</div>
</div>
</div>
{% endblock %}
{% block extra_js %}
<script>
// 分类统计图表
$(document).ready(function() {
var ctx = document.getElementById('categoryChart').getContext('2d');
// 获取分类数据
var categories = [
{% for category, count in categories %}
"{{ category or '未分类' }}",
{% endfor %}
];
var counts = [
{% for category, count in categories %}
{{ count }},
{% endfor %}
];
var colors = [
'#FF6384', '#36A2EB', '#FFCE56', '#4BC0C0',
'#9966FF', '#FF9F40', '#C9CBCF', '#FF6384',
'#36A2EB', '#FFCE56', '#4BC0C0', '#9966FF'
];
var chart = new Chart(ctx, {
type: 'pie',
data: {
labels: categories,
datasets: [{
data: counts,
backgroundColor: colors.slice(0, categories.length),
borderWidth: 1
}]
},
options: {
responsive: true,
plugins: {
legend: {
position: 'right',
},
title: {
display: true,
text: '图书分类分布'
}
}
}
});
});
</script>
{% endblock %}
EOF
创建图书列表模板
bash
cat > ~/python_crawler_project/flask_web/templates/books.html << 'EOF'
{% extends "base.html" %}
{% block title %}图书列表 - 图书爬虫系统{% endblock %}
{% block content %}
<div class="row">
<div class="col-12">
<div class="card">
<div class="card-header d-flex justify-content-between align-items-center">
<h5 class="mb-0">
<i class="fas fa-book"></i> 图书列表
</h5>
<div>
<span class="badge badge-primary">共 {{ pagination.total }} 本图书</span>
</div>
</div>
<div class="card-body">
<!-- 筛选表单 -->
<form method="get" class="mb-4">
<div class="form-row">
<div class="col-md-4 mb-3">
<label for="category">按分类筛选:</label>
<select class="form-control" id="category" name="category" onchange="this.form.submit()">
<option value="">所有分类</option>
{% for cat in categories %}
<option value="{{ cat }}" {% if cat == selected_category %}selected{% endif %}>
{{ cat }}
</option>
{% endfor %}
</select>
</div>
<div class="col-md-8 mb-3 d-flex align-items-end">
<button type="submit" class="btn btn-primary">
<i class="fas fa-filter"></i> 筛选
</button>
<a href="/books" class="btn btn-secondary ml-2">
<i class="fas fa-redo"></i> 重置
</a>
</div>
</div>
</form>
<!-- 图书表格 -->
<div class="table-responsive">
<table class="table table-hover">
<thead class="thead-dark">
<tr>
<th>#</th>
<th>标题</th>
<th>分类</th>
<th>价格</th>
<th>评分</th>
<th>评价数</th>
<th>操作</th>
</tr>
</thead>
<tbody>
{% for book in books %}
<tr>
<td>{{ (pagination.page - 1) * pagination.per_page + loop.index }}</td>
<td>
<strong>{{ book.title }}</strong>
{% if book.description %}
<br>
<small class="text-muted">{{ book.description[:100] }}...</small>
{% endif %}
</td>
<td>
<span class="badge badge-info">{{ book.category or '未分类' }}</span>
</td>
<td>
<span class="badge badge-success">£{{ book.price }}</span>
</td>
<td>
{% if book.rating %}
{% set stars = {'One': 1, 'Two': 2, 'Three': 3, 'Four': 4, 'Five': 5} %}
{% set star_count = stars.get(book.rating, 0) %}
{% for i in range(5) %}
{% if i < star_count %}
<i class="fas fa-star text-warning"></i>
{% else %}
<i class="far fa-star text-warning"></i>
{% endif %}
{% endfor %}
{% endif %}
</td>
<td>{{ book.review_count or 0 }}</td>
<td>
<button class="btn btn-sm btn-outline-info"
data-toggle="modal"
data-target="#bookModal{{ book.id }}">
<i class="fas fa-eye"></i> 详情
</button>
</td>
</tr>
<!-- 详情模态框 -->
<div class="modal fade" id="bookModal{{ book.id }}" tabindex="-1">
<div class="modal-dialog modal-lg">
<div class="modal-content">
<div class="modal-header">
<h5 class="modal-title">{{ book.title }}</h5>
<button type="button" class="close" data-dismiss="modal">
<span>×</span>
</button>
</div>
<div class="modal-body">
<div class="row">
<div class="col-md-4">
{% if book.image_url %}
<img src="{{ book.image_url }}"
class="img-fluid rounded"
alt="{{ book.title }}">
{% else %}
<div class="text-center p-4 bg-light rounded">
<i class="fas fa-book fa-5x text-muted"></i>
</div>
{% endif %}
</div>
<div class="col-md-8">
<table class="table table-sm">
<tr>
<th width="30%">标题:</th>
<td>{{ book.title }}</td>
</tr>
<tr>
<th>价格:</th>
<td>£{{ book.price }}</td>
</tr>
<tr>
<th>分类:</th>
<td>{{ book.category or '未分类' }}</td>
</tr>
<tr>
<th>评分:</th>
<td>
{% if book.rating %}
{{ book.rating }}
{% endif %}
</td>
</tr>
<tr>
<th>UPC:</th>
<td>{{ book.upc or 'N/A' }}</td>
</tr>
<tr>
<th>库存:</th>
<td>{{ book.availability or 'N/A' }}</td>
</tr>
<tr>
<th>描述:</th>
<td>{{ book.description or '无描述' }}</td>
</tr>
<tr>
<th>爬取时间:</th>
<td>{{ book.crawled_at.strftime('%Y-%m-%d %H:%M:%S') }}</td>
</tr>
</table>
</div>
</div>
</div>
<div class="modal-footer">
{% if book.source_url %}
<a href="{{ book.source_url }}"
target="_blank"
class="btn btn-primary">
<i class="fas fa-external-link-alt"></i> 查看源网页
</a>
{% endif %}
<button type="button" class="btn btn-secondary" data-dismiss="modal">
关闭
</button>
</div>
</div>
</div>
</div>
{% endfor %}
</tbody>
</table>
</div>
<!-- 分页 -->
{% if pagination.pages > 1 %}
<nav aria-label="Page navigation">
<ul class="pagination justify-content-center">
{% if pagination.has_prev %}
<li class="page-item">
<a class="page-link" href="{{ url_for('books', page=pagination.prev_num, category=selected_category) }}">
上一页
</a>
</li>
{% endif %}
{% for page_num in pagination.iter_pages(left_edge=2, left_current=2, right_current=3, right_edge=2) %}
{% if page_num %}
{% if page_num == pagination.page %}
<li class="page-item active">
<span class="page-link">{{ page_num }}</span>
</li>
{% else %}
<li class="page-item">
<a class="page-link" href="{{ url_for('books', page=page_num, category=selected_category) }}">
{{ page_num }}
</a>
</li>
{% endif %}
{% else %}
<li class="page-item disabled">
<span class="page-link">...</span>
</li>
{% endif %}
{% endfor %}
{% if pagination.has_next %}
<li class="page-item">
<a class="page-link" href="{{ url_for('books', page=pagination.next_num, category=selected_category) }}">
下一页
</a>
</li>
{% endif %}
</ul>
</nav>
{% endif %}
</div>
</div>
</div>
</div>
{% endblock %}
EOF
创建数据分析模板
bash
cat > ~/python_crawler_project/flask_web/templates/analysis.html << 'EOF'
{% extends "base.html" %}
{% block title %}数据分析 - 图书爬虫系统{% endblock %}
{% block content %}
<div class="row">
<div class="col-12">
<div class="card">
<div class="card-header">
<h5 class="mb-0">
<i class="fas fa-chart-line"></i> 数据统计分析
</h5>
</div>
<div class="card-body">
<p class="lead">
基于爬取的图书数据进行多维度的统计和分析,帮助理解数据特征和趋势。
</p>
{% if charts %}
<!-- 图表展示 -->
<div class="row">
{% for chart in charts %}
<div class="col-md-6 mb-4">
<div class="chart-container">
<h5 class="text-center mb-3">{{ chart.title }}</h5>
<img src="data:image/png;base64,{{ chart.image }}"
class="img-fluid rounded"
alt="{{ chart.title }}">
</div>
</div>
{% endfor %}
</div>
<!-- 数据统计 -->
<div class="row mt-4">
<div class="col-12">
<div class="card">
<div class="card-header">
<h5 class="mb-0">
<i class="fas fa-table"></i> 实时数据统计
</h5>
</div>
<div class="card-body">
<div id="statsContainer" class="row">
<!-- 这里通过JavaScript动态加载统计信息 -->
<div class="col-12 text-center">
<div class="spinner-border text-primary" role="status">
<span class="sr-only">加载中...</span>
</div>
<p>正在加载统计信息...</p>
</div>
</div>
</div>
</div>
</div>
</div>
{% else %}
<div class="alert alert-warning text-center">
<h4><i class="fas fa-exclamation-triangle"></i> 暂无数据</h4>
<p>还没有爬取到数据,请先运行爬虫程序。</p>
<a href="/" class="btn btn-primary">
<i class="fas fa-home"></i> 返回首页
</a>
</div>
{% endif %}
</div>
</div>
</div>
</div>
<!-- 数据分析说明 -->
<div class="row mt-4">
<div class="col-12">
<div class="card">
<div class="card-header">
<h5 class="mb-0">
<i class="fas fa-info-circle"></i> 分析说明
</h5>
</div>
<div class="card-body">
<div class="row">
<div class="col-md-4">
<div class="text-center p-3">
<i class="fas fa-chart-bar fa-3x text-primary mb-3"></i>
<h6>价格分析</h6>
<p class="small text-muted">
展示图书价格的分布情况,了解不同价格区间的图书数量
</p>
</div>
</div>
<div class="col-md-4">
<div class="text-center p-3">
<i class="fas fa-pie-chart fa-3x text-primary mb-3"></i>
<h6>分类分析</h6>
<p class="small text-muted">
统计不同分类的图书数量,了解各分类的分布比例
</p>
</div>
</div>
<div class="col-md-4">
<div class="text-center p-3">
<i class="fas fa-star fa-3x text-primary mb-3"></i>
<h6>评分分析</h6>
<p class="small text-muted">
分析图书的评分分布,以及评分与价格的关系
</p>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
{% endblock %}
{% block extra_js %}
<script>
// 加载统计数据
$(document).ready(function() {
// 获取统计数据
$.ajax({
url: '/api/stats',
type: 'GET',
success: function(data) {
var html = `
<div class="col-md-3 text-center">
<div class="p-3 bg-primary text-white rounded mb-3">
<h2>${data.total_books}</h2>
<p class="mb-0">总图书数</p>
</div>
</div>
<div class="col-md-3 text-center">
<div class="p-3 bg-success text-white rounded mb-3">
<h2>£${data.avg_price}</h2>
<p class="mb-0">平均价格</p>
</div>
</div>
<div class="col-md-3 text-center">
<div class="p-3 bg-info text-white rounded mb-3">
<h2>${Object.keys(data.categories).length}</h2>
<p class="mb-0">分类数量</p>
</div>
</div>
<div class="col-md-3 text-center">
<div class="p-3 bg-warning text-white rounded mb-3">
<h2>${data.price_ranges['0-5']}</h2>
<p class="mb-0">低价图书(0-5£)</p>
</div>
</div>
`;
$('#statsContainer').html(html);
// 创建价格区间图表
createPriceRangeChart(data.price_ranges);
},
error: function() {
$('#statsContainer').html(`
<div class="col-12">
<div class="alert alert-danger">
无法加载统计信息
</div>
</div>
`);
}
});
});
// 创建价格区间图表
function createPriceRangeChart(priceRanges) {
var html = `
<div class="col-12 mt-4">
<div class="chart-container">
<h5 class="text-center mb-3">价格区间分布</h5>
<canvas id="priceRangeChart"></canvas>
</div>
</div>
`;
$('#statsContainer').append(html);
var ctx = document.getElementById('priceRangeChart').getContext('2d');
var chart = new Chart(ctx, {
type: 'bar',
data: {
labels: Object.keys(priceRanges),
datasets: [{
label: '图书数量',
data: Object.values(priceRanges),
backgroundColor: [
'rgba(255, 99, 132, 0.7)',
'rgba(54, 162, 235, 0.7)',
'rgba(255, 206, 86, 0.7)',
'rgba(75, 192, 192, 0.7)'
],
borderColor: [
'rgba(255, 99, 132, 1)',
'rgba(54, 162, 235, 1)',
'rgba(255, 206, 86, 1)',
'rgba(75, 192, 192, 1)'
],
borderWidth: 1
}]
},
options: {
responsive: true,
scales: {
y: {
beginAtZero: true,
title: {
display: true,
text: '图书数量'
}
},
x: {
title: {
display: true,
text: '价格区间 (£)'
}
}
}
}
});
}
</script>
{% endblock %}
EOF
八、创建运行脚本
1. 创建运行爬虫的脚本
bash
cat > ~/python_crawler_project/run_crawler.sh << 'EOF'
#!/bin/bash
# 图书爬虫运行脚本
echo "========================================="
echo " 图书爬虫系统 - 开始运行爬虫"
echo "========================================="
# 激活虚拟环境
source venv/bin/activate
# 进入项目目录
cd ~/python_crawler_project
# 运行爬虫管理器
echo "正在启动多线程爬虫..."
python scripts/crawler_manager.py
# 显示爬取结果
echo ""
echo "========================================="
echo " 爬虫运行完成!"
echo "========================================="
echo ""
echo "数据已保存到: database/crawler_data.db"
echo "日志文件: logs/crawler_manager.log"
echo ""
echo "可以运行以下命令启动Web界面:"
echo " ./run_web.sh"
echo ""
EOF
chmod +x ~/python_crawler_project/run_crawler.sh
2. 创建运行Web应用的脚本
bash
cat > ~/python_crawler_project/run_web.sh << 'EOF'
#!/bin/bash
# Flask Web应用运行脚本
echo "========================================="
echo " 图书爬虫系统 - 启动Web应用"
echo "========================================="
# 激活虚拟环境
source venv/bin/activate
# 进入项目目录
cd ~/python_crawler_project
# 启动Flask应用
echo "正在启动Flask Web应用..."
echo "请稍等..."
cd flask_web
python app.py
echo ""
echo "========================================="
echo " Web应用已停止"
echo "========================================="
EOF
chmod +x ~/python_crawler_project/run_web.sh
3. 创建一键安装脚本
bash
cat > ~/python_crawler_project/setup.sh << 'EOF'
#!/bin/bash
# 项目一键安装脚本
echo "========================================="
echo " 图书爬虫系统 - 安装脚本"
echo "========================================="
# 检查是否在项目目录
if [ ! -f "requirements.txt" ]; then
echo "错误:请在项目根目录运行此脚本"
exit 1
fi
# 安装系统依赖
echo "安装系统依赖..."
sudo apt update
sudo apt install -y python3 python3-pip python3-venv
# 创建虚拟环境
echo "创建虚拟环境..."
python3 -m venv venv
# 激活虚拟环境
source venv/bin/activate
# 安装Python依赖
echo "安装Python依赖..."
pip install --upgrade pip
pip install -r requirements.txt
# 初始化数据库
echo "初始化数据库..."
python database/init_db.py
# 创建必要的目录
echo "创建目录结构..."
mkdir -p data logs
# 设置文件权限
chmod +x run_crawler.sh run_web.sh
echo ""
echo "========================================="
echo " 安装完成!"
echo "========================================="
echo ""
echo "接下来可以运行:"
echo "1. 运行爬虫: ./run_crawler.sh"
echo "2. 运行Web应用: ./run_web.sh"
echo ""
echo "访问地址: http://127.0.0.1:5000"
echo ""
EOF
chmod +x ~/python_crawler_project/setup.sh
九、项目部署和运行
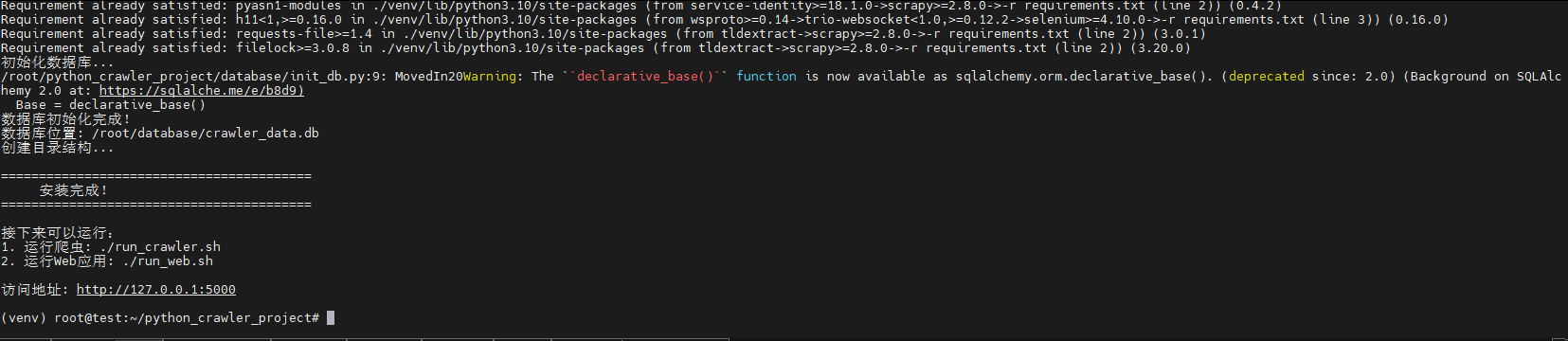
1. 首次运行安装
bash
cd ~/python_crawler_project
./setup.sh
2. 运行爬虫程序
bash
cd ~/python_crawler_project
./run_crawler.sh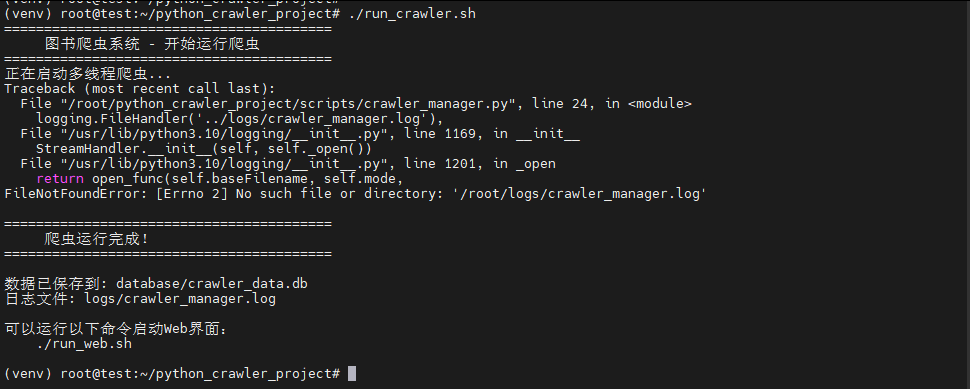
3. 运行Web应用
bash
cd ~/python_crawler_project
./run_web.sh运行时报错:
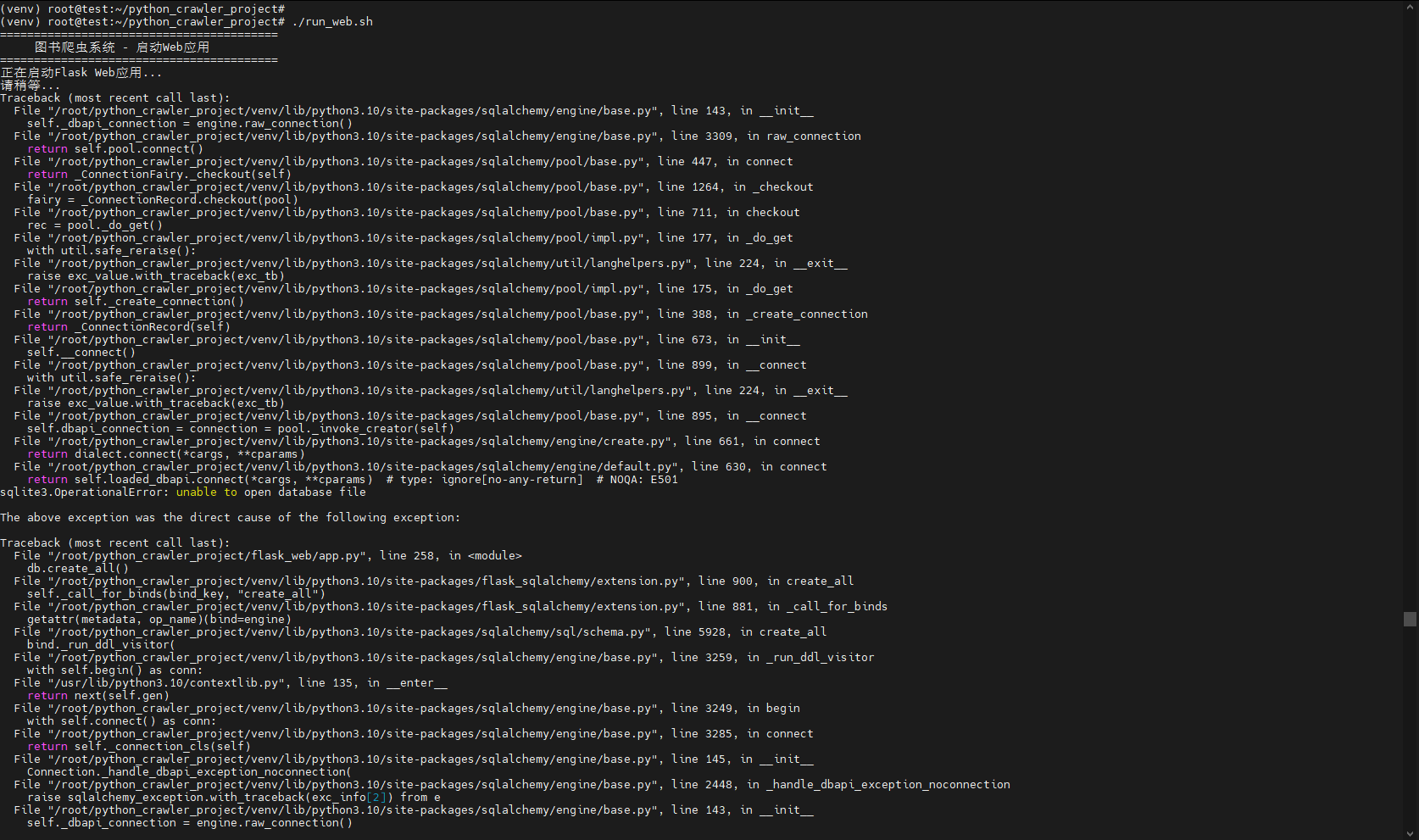
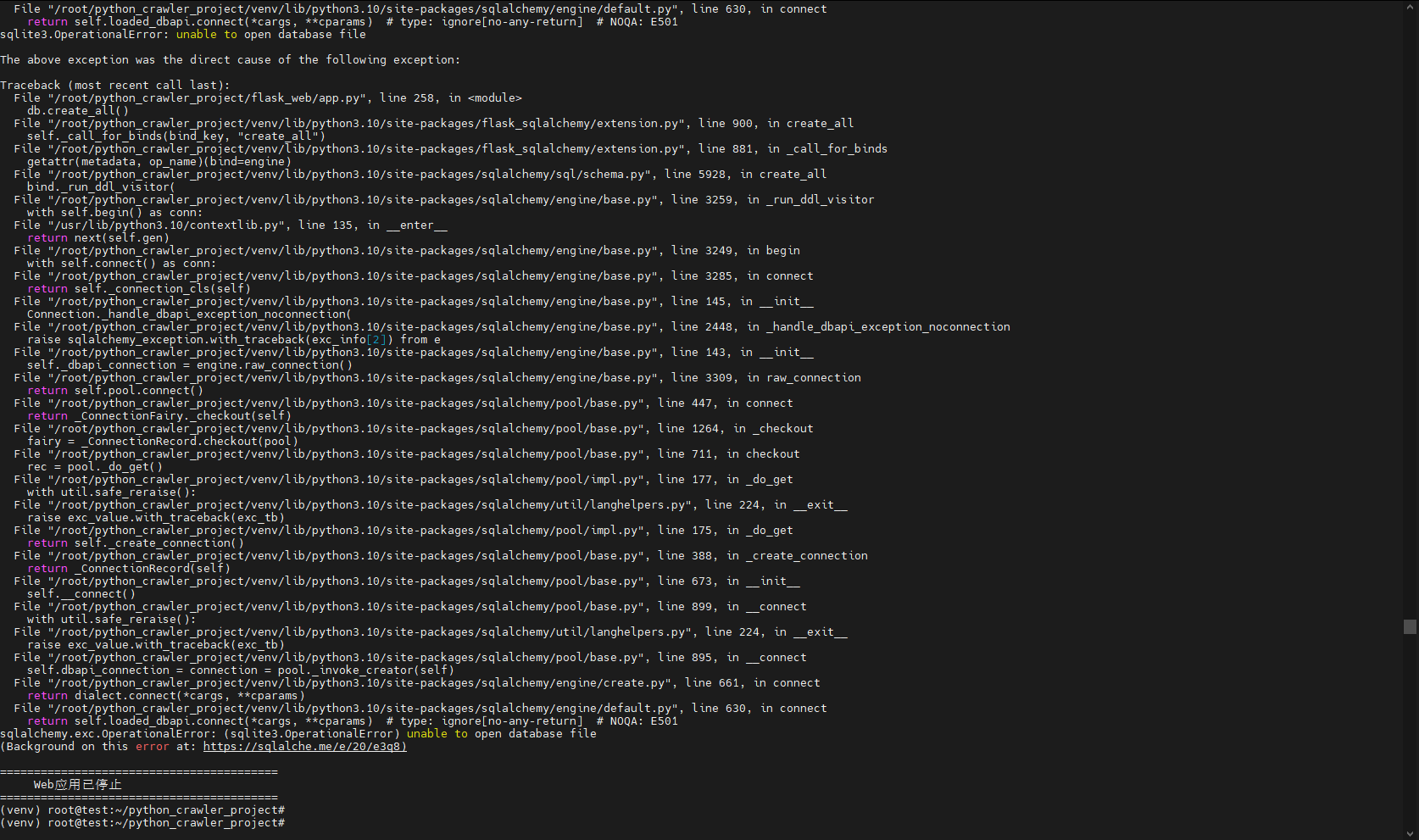
问题原因:
数据库路径有问题,我们查看一下database目录下,会发现下面没有所需的crawler_date.db:

原来是在初始化数据库的时候,数据库的位置没在这个目录,而是被创建在了 /root/database/crawler_data.db

这显然是不对的,我们需要修改一下;
我们需要对database/init_db.py和flask_web/app.py进行修改,直接删除原来的,把下面新的内容复制进去:
修正后的database/init_db.py:
bash
# database/init_db.py
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import create_engine, Column, Integer, String, Text, DateTime, Float
from sqlalchemy.orm import declarative_base
from sqlalchemy.orm import sessionmaker
from datetime import datetime
import os
# 获取项目根目录的绝对路径 (即 init_db.py 所在目录的上一级)
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# 构建数据库文件的绝对路径
DATABASE_PATH = os.path.join(BASE_DIR, 'database', 'crawler_data.db')
DATABASE_URI = f'sqlite:///{DATABASE_PATH}'
print(f"项目根目录: {BASE_DIR}")
print(f"数据库文件将创建于: {DATABASE_PATH}")
# 创建基类
Base = declarative_base()
class Book(Base):
"""图书数据表"""
__tablename__ = 'books'
id = Column(Integer, primary_key=True)
title = Column(String(200), nullable=False)
author = Column(String(100))
price = Column(Float)
rating = Column(Float)
category = Column(String(50))
description = Column(Text)
image_url = Column(String(500))
source_url = Column(String(500))
upc = Column(String(50))
product_type = Column(String(50))
price_excl_tax = Column(String(20))
price_incl_tax = Column(String(20))
tax = Column(String(20))
availability = Column(String(50))
review_count = Column(Integer)
crawled_at = Column(DateTime, default=datetime.utcnow)
def __repr__(self):
return f"<Book {self.title}>"
def init_database():
"""初始化数据库"""
# 创建数据库目录
os.makedirs(os.path.dirname(DATABASE_PATH), exist_ok=True)
# 创建数据库引擎
engine = create_engine(DATABASE_URI)
# 创建所有表
Base.metadata.create_all(engine)
print(f"数据库初始化完成!")
print(f"数据库位置: {DATABASE_PATH}")
if __name__ == '__main__':
init_database()修正后的 flask_web/app.py:
bash
#!/usr/bin/env python3
"""
Flask Web应用 - 展示爬取的数据
"""
from flask import Flask, render_template, request, jsonify, send_file
from flask_sqlalchemy import SQLAlchemy
from flask_bootstrap import Bootstrap
import pandas as pd
import matplotlib.pyplot as plt
import io
import base64
from datetime import datetime, timedelta
import json
import os
# --- 核心修复:动态计算数据库路径,与 init_db.py 保持一致 ---
# 获取项目根目录的绝对路径 (即 app.py 所在目录的上一级)
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# 构建数据库文件的绝对路径
DATABASE_PATH = os.path.join(BASE_DIR, 'database', 'crawler_data.db')
DATABASE_URI = f'sqlite:///{DATABASE_PATH}'
print(f"项目根目录: {BASE_DIR}")
print(f"数据库文件位置: {DATABASE_PATH}")
# 创建Flask应用
app = Flask(__name__)
# 使用计算出的绝对路径
app.config['SQLALCHEMY_DATABASE_URI'] = DATABASE_URI
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SECRET_KEY'] = 'your-secret-key-here'
# 初始化扩展
db = SQLAlchemy(app)
Bootstrap(app)
# 定义数据库模型 (与 init_db.py 中的一致)
class Book(db.Model):
__tablename__ = 'books'
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(200), nullable=False)
price = db.Column(db.Float)
description = db.Column(db.Text)
category = db.Column(db.String(50))
rating = db.Column(db.String(10))
image_url = db.Column(db.String(500))
source_url = db.Column(db.String(500))
upc = db.Column(db.String(50))
product_type = db.Column(db.String(50))
price_excl_tax = db.Column(db.String(20))
price_incl_tax = db.Column(db.String(20))
tax = db.Column(db.String(20))
availability = db.Column(db.String(50))
review_count = db.Column(db.Integer)
crawled_at = db.Column(db.DateTime)
# 路由
@app.route('/')
def index():
"""首页"""
# 获取统计数据
total_books = Book.query.count()
categories = db.session.query(Book.category, db.func.count(Book.id)).group_by(Book.category).all()
avg_price = db.session.query(db.func.avg(Book.price)).scalar() or 0
# 获取最新图书
recent_books = Book.query.order_by(Book.crawled_at.desc()).limit(10).all()
return render_template('index.html',
total_books=total_books,
categories=categories,
avg_price=round(avg_price, 2),
recent_books=recent_books)
@app.route('/books')
def books():
"""图书列表页"""
page = request.args.get('page', 1, type=int)
per_page = 20
category = request.args.get('category', '')
# 构建查询
query = Book.query
if category:
query = query.filter_by(category=category)
# 分页
pagination = query.order_by(Book.title).paginate(page=page, per_page=per_page, error_out=False)
books = pagination.items
# 获取所有分类
categories = db.session.query(Book.category).distinct().all()
categories = [c[0] for c in categories if c[0]]
return render_template('books.html',
books=books,
pagination=pagination,
categories=categories,
selected_category=category)
@app.route('/analysis')
def analysis():
"""数据分析页"""
# 获取所有数据
books = Book.query.all()
if not books:
return render_template('analysis.html', charts=[])
# 转换为DataFrame
data = []
for book in books:
data.append({
'title': book.title,
'price': book.price,
'category': book.category,
'rating': book.rating,
'review_count': book.review_count or 0
})
df = pd.DataFrame(data)
# 生成图表
charts = []
# 1. 价格分布图
plt.figure(figsize=(10, 6))
df['price'].hist(bins=20, edgecolor='black')
plt.title('图书价格分布')
plt.xlabel('价格 (£)')
plt.ylabel('数量')
plt.tight_layout()
price_chart = get_chart_base64()
charts.append({'title': '价格分布', 'image': price_chart})
# 2. 分类统计
plt.figure(figsize=(12, 6))
category_counts = df['category'].value_counts().head(10)
category_counts.plot(kind='bar')
plt.title('图书分类统计(Top 10)')
plt.xlabel('分类')
plt.ylabel('数量')
plt.xticks(rotation=45)
plt.tight_layout()
category_chart = get_chart_base64()
charts.append({'title': '分类统计', 'image': category_chart})
# 3. 评分分布
plt.figure(figsize=(10, 6))
rating_counts = df['rating'].value_counts()
rating_counts.plot(kind='pie', autopct='%1.1f%%')
plt.title('图书评分分布')
plt.ylabel('')
plt.tight_layout()
rating_chart = get_chart_base64()
charts.append({'title': '评分分布', 'image': rating_chart})
# 4. 价格与评分关系
plt.figure(figsize=(10, 6))
rating_price = df.groupby('rating')['price'].mean()
rating_price.plot(kind='bar')
plt.title('不同评分的平均价格')
plt.xlabel('评分')
plt.ylabel('平均价格 (£)')
plt.tight_layout()
relation_chart = get_chart_base64()
charts.append({'title': '评分与价格关系', 'image': relation_chart})
return render_template('analysis.html', charts=charts)
@app.route('/api/books')
def api_books():
"""API接口 - 获取图书数据"""
page = request.args.get('page', 1, type=int)
per_page = request.args.get('per_page', 10, type=int)
query = Book.query
pagination = query.paginate(page=page, per_page=per_page)
books = []
for book in pagination.items:
books.append({
'id': book.id,
'title': book.title,
'price': book.price,
'category': book.category,
'rating': book.rating,
'description': book.description[:100] + '...' if book.description and len(book.description) > 100 else book.description
})
return jsonify({
'books': books,
'total': pagination.total,
'pages': pagination.pages,
'current_page': pagination.page
})
@app.route('/api/stats')
def api_stats():
"""API接口 - 获取统计数据"""
total_books = Book.query.count()
categories = db.session.query(Book.category, db.func.count(Book.id)).group_by(Book.category).all()
avg_price = db.session.query(db.func.avg(Book.price)).scalar() or 0
# 价格范围统计
price_ranges = {
'0-5': Book.query.filter(Book.price.between(0, 5)).count(),
'5-10': Book.query.filter(Book.price.between(5, 10)).count(),
'10-20': Book.query.filter(Book.price.between(10, 20)).count(),
'20+': Book.query.filter(Book.price > 20).count()
}
return jsonify({
'total_books': total_books,
'avg_price': round(avg_price, 2),
'categories': dict(categories),
'price_ranges': price_ranges
})
def get_chart_base64():
"""将matplotlib图表转换为base64编码"""
buffer = io.BytesIO()
plt.savefig(buffer, format='png')
buffer.seek(0)
image_base64 = base64.b64encode(buffer.getvalue()).decode('utf-8')
plt.close()
return image_base64
@app.route('/export/csv')
def export_csv():
"""导出数据为CSV"""
books = Book.query.all()
data = []
for book in books:
data.append({
'标题': book.title,
'价格': book.price,
'分类': book.category,
'评分': book.rating,
'描述': book.description,
'URL': book.source_url,
'爬取时间': book.crawled_at
})
df = pd.DataFrame(data)
# 创建CSV文件
csv_buffer = io.StringIO()
df.to_csv(csv_buffer, index=False, encoding='utf-8-sig')
# 发送文件
csv_buffer.seek(0)
return send_file(
io.BytesIO(csv_buffer.getvalue().encode('utf-8-sig')),
mimetype='text/csv',
as_attachment=True,
download_name=f'books_{datetime.now().strftime("%Y%m%d_%H%M%S")}.csv'
)
if __name__ == '__main__':
# 确保数据库存在
with app.app_context():
db.create_all()
print("Flask应用启动中...")
print("访问地址: http://127.0.0.1:5000")
print("按 Ctrl+C 停止应用")
app.run(host='0.0.0.0', port=5000, debug=True)然后需要彻底重置数据库并重启
bash
cd ~/python_crawler_project
# 1. 再次删除旧数据库
rm -f database/crawler_data.db
# 2. 用新模型重新初始化
python database/init_db.py观察输出,确认"数据库初始化完成!"。
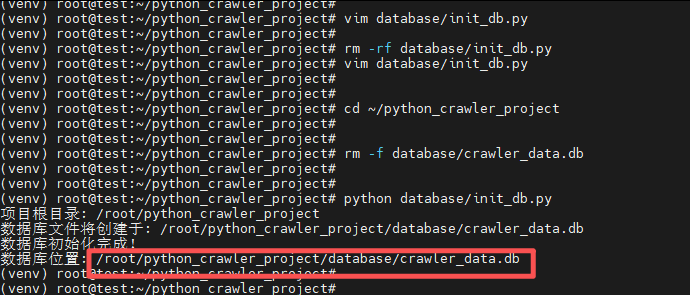
可以看到数据库是被创建在正确的目录: /root/python_crawler_project/database/crawler_data.db
然后重新运行./run_web.sh
4. 访问Web界面
打开浏览器,访问:http://127.0.0.1:5000
5. 图书数据为空的解决办法:
5.1 先解决路径问题
打开一个新的终端,执行./run_crawler.sh对数据进行填充:
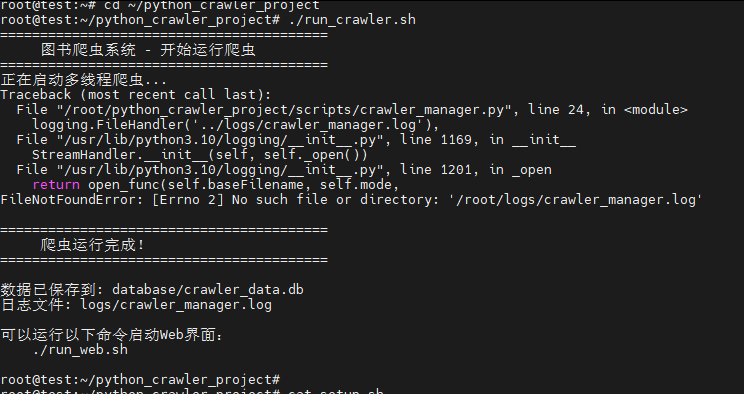
这里报错了,核心问题是日志路径错误 和潜在的Scrapy项目路径问题 ,导致爬虫管理器刚启动就崩溃,根本没能执行爬虫
解决过程:
第一步:创建缺失的目录(立即生效)
在项目根目录运行以下命令,创建日志和数据的存放目录:
bash
cd ~/python_crawler_project
mkdir -p logs data第二步:替换为修复后的 crawler_manager.py
用下面的完整代码替换你现有的 scripts/crawler_manager.py 文件。这个版本修复了两个关键问题:
- 日志路径 :使用基于项目根目录的绝对路径,彻底杜绝路径歧义。
- Scrapy路径 :同样使用绝对路径来定位
book_crawler项目,确保scrapy命令在正确的目录下执行。
python
#!/usr/bin/env python3
"""
多线程爬虫管理器 (修复版)
"""
import threading
import queue
import time
from datetime import datetime
import logging
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
import subprocess
import sys
import os
# --- 核心修复1:计算项目根目录的绝对路径 ---
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
PROJECT_ROOT = os.path.dirname(SCRIPT_DIR)
LOG_DIR = os.path.join(PROJECT_ROOT, 'logs')
SCRAPY_PROJECT_DIR = os.path.join(PROJECT_ROOT, 'book_crawler')
print(f"[初始化] 项目根目录: {PROJECT_ROOT}")
print(f"[初始化] 日志目录: {LOG_DIR}")
print(f"[初始化] Scrapy项目目录: {SCRAPY_PROJECT_DIR}")
# 确保日志目录存在
os.makedirs(LOG_DIR, exist_ok=True)
# --- 核心修复2:配置日志,使用绝对路径 ---
LOG_FILE = os.path.join(LOG_DIR, 'crawler_manager.log')
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler(LOG_FILE), # 使用绝对路径
logging.StreamHandler()
]
)
logger = logging.getLogger(__name__)
logger.info(f"爬虫管理器启动,日志将写入: {LOG_FILE}")
class MultiThreadCrawler:
"""多线程爬虫管理器"""
def __init__(self, num_threads=3):
self.num_threads = num_threads
self.queue = queue.Queue()
self.results = []
self.lock = threading.Lock()
def run_spider(self, spider_name, start_urls):
"""运行单个爬虫"""
try:
logger.info(f"启动爬虫: {spider_name},起始URL: {start_urls}")
# 构建 scrapy 命令
cmd = ['scrapy', 'crawl', spider_name]
if start_urls:
cmd.extend(['-a', f'start_urls={",".join(start_urls)}'])
# --- 核心修复3:确保在正确的Scrapy项目目录下运行命令 ---
logger.debug(f"执行命令: {' '.join(cmd)}")
result = subprocess.run(
cmd,
cwd=SCRAPY_PROJECT_DIR, # 切换到Scrapy项目目录
capture_output=True,
text=True,
timeout=300 # 设置5分钟超时,防止卡死
)
with self.lock:
if result.returncode == 0:
self.results.append({
'spider': spider_name,
'status': 'success',
'output': result.stdout[-500:] # 只保存最后500字符
})
logger.info(f"爬虫 {spider_name} 完成")
else:
self.results.append({
'spider': spider_name,
'status': 'failed',
'error': result.stderr[-1000:] if result.stderr else 'Unknown error'
})
logger.error(f"爬虫 {spider_name} 失败。返回码: {result.returncode}")
logger.debug(f"错误详情: {result.stderr}")
except subprocess.TimeoutExpired:
error_msg = f"爬虫 {spider_name} 执行超时"
logger.error(error_msg)
with self.lock:
self.results.append({
'spider': spider_name,
'status': 'timeout',
'error': error_msg
})
except Exception as e:
error_msg = f"爬虫 {spider_name} 异常: {str(e)}"
logger.error(error_msg, exc_info=True)
with self.lock:
self.results.append({
'spider': spider_name,
'status': 'error',
'error': error_msg
})
def worker(self):
"""工作线程"""
thread_name = threading.current_thread().name
logger.debug(f"工作线程 {thread_name} 启动")
while True:
try:
task = self.queue.get(timeout=10)
if task is None: # 退出信号
logger.debug(f"工作线程 {thread_name} 收到退出信号")
break
spider_name, start_urls = task
logger.debug(f"工作线程 {thread_name} 处理任务: {spider_name}")
self.run_spider(spider_name, start_urls)
self.queue.task_done()
except queue.Empty:
logger.debug(f"工作线程 {thread_name} 队列已空,退出")
break
except Exception as e:
logger.error(f"工作线程 {thread_name} 异常: {str(e)}", exc_info=True)
break
logger.debug(f"工作线程 {thread_name} 退出")
def start(self, tasks):
"""启动多线程爬虫"""
logger.info(f"开始多线程爬虫,线程数: {self.num_threads},任务数: {len(tasks)}")
# 添加任务到队列
for task in tasks:
self.queue.put(task)
# 创建工作线程
threads = []
for i in range(self.num_threads):
thread = threading.Thread(target=self.worker, name=f"CrawlerThread-{i+1}")
thread.start()
threads.append(thread)
logger.debug(f"创建并启动工作线程: {thread.name}")
# 等待所有任务完成
self.queue.join()
logger.info("所有爬虫任务已完成,正在清理线程...")
# 停止工作线程
for _ in range(self.num_threads):
self.queue.put(None)
for thread in threads:
thread.join()
logger.info("多线程爬虫执行完毕")
self.print_results()
def print_results(self):
"""打印爬取结果"""
print("\n" + "="*60)
print("爬虫执行结果汇总:")
print("="*60)
success_count = sum(1 for r in self.results if r['status'] == 'success')
failed_count = sum(1 for r in self.results if r['status'] == 'failed')
error_count = sum(1 for r in self.results if r['status'] == 'error')
timeout_count = sum(1 for r in self.results if r['status'] == 'timeout')
print(f"✅ 成功: {success_count}")
print(f"❌ 失败: {failed_count}")
print(f"⚠️ 错误: {error_count}")
print(f"⏱️ 超时: {timeout_count}")
print(f"📊 总计: {len(self.results)}")
if self.results:
print("\n详细结果:")
for i, result in enumerate(self.results, 1):
status_icon = "✅" if result['status'] == 'success' else "❌"
print(f"\n{i}. {status_icon} 爬虫: {result['spider']}")
print(f" 状态: {result['status']}")
if result['status'] != 'success' and 'error' in result:
print(f" 错误: {result['error'][:200]}...")
print("\n" + "="*60)
logger.info(f"结果汇总: 成功={success_count}, 失败={failed_count}, 错误={error_count}, 超时={timeout_count}")
def main():
"""主函数"""
# 定义爬虫任务
tasks = [
('books', ['http://books.toscrape.com/catalogue/category/books/travel_2/index.html']),
('books', ['http://books.toscrape.com/catalogue/category/books/mystery_3/index.html']),
('books', ['http://books.toscrape.com/catalogue/category/books/historical-fiction_4/index.html']),
('books', ['http://books.toscrape.com/catalogue/category/books/science-fiction_16/index.html']),
('books', ['http://books.toscrape.com/catalogue/category/books/fantasy_19/index.html']),
]
print("="*60)
print("图书爬虫系统 - 多线程爬虫启动")
print("="*60)
print(f"任务数量: {len(tasks)}")
print(f"目标网站: books.toscrape.com")
print("="*60)
# 创建并启动多线程爬虫
crawler = MultiThreadCrawler(num_threads=3)
crawler.start(tasks)
if __name__ == '__main__':
main()如何替换文件:
bash
cd ~/python_crawler_project
# 备份旧文件(可选)
mv scripts/crawler_manager.py scripts/crawler_manager.py.bak
# 创建新文件
cat > scripts/crawler_manager.py << 'EOF'
[将上面的完整代码粘贴到这里]
EOF
第三步:重新运行爬虫并验证
完成上述替换后,在新的终端窗口中运行爬虫:
bash
cd ~/python_crawler_project
./run_crawler.sh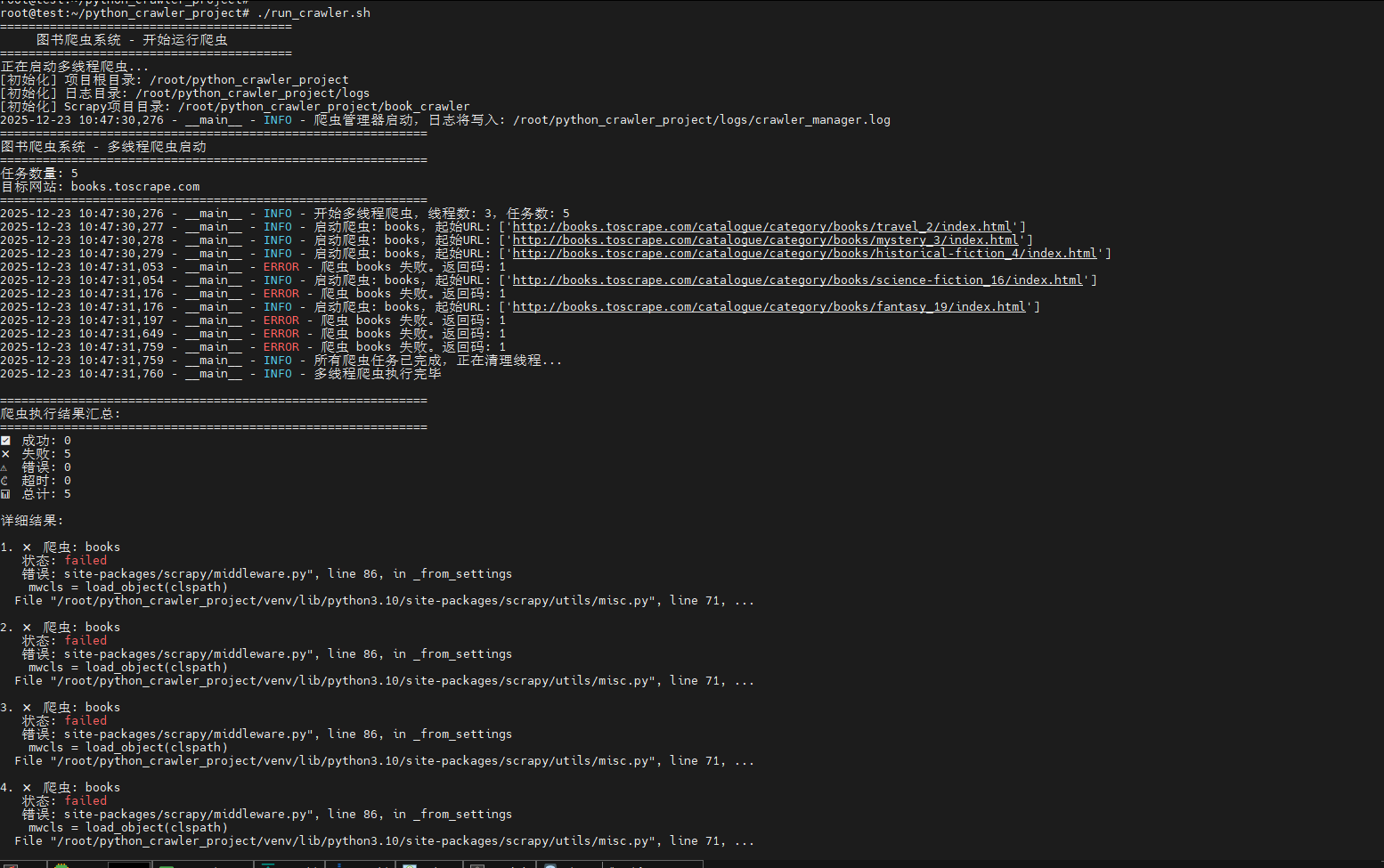
这里有报错:
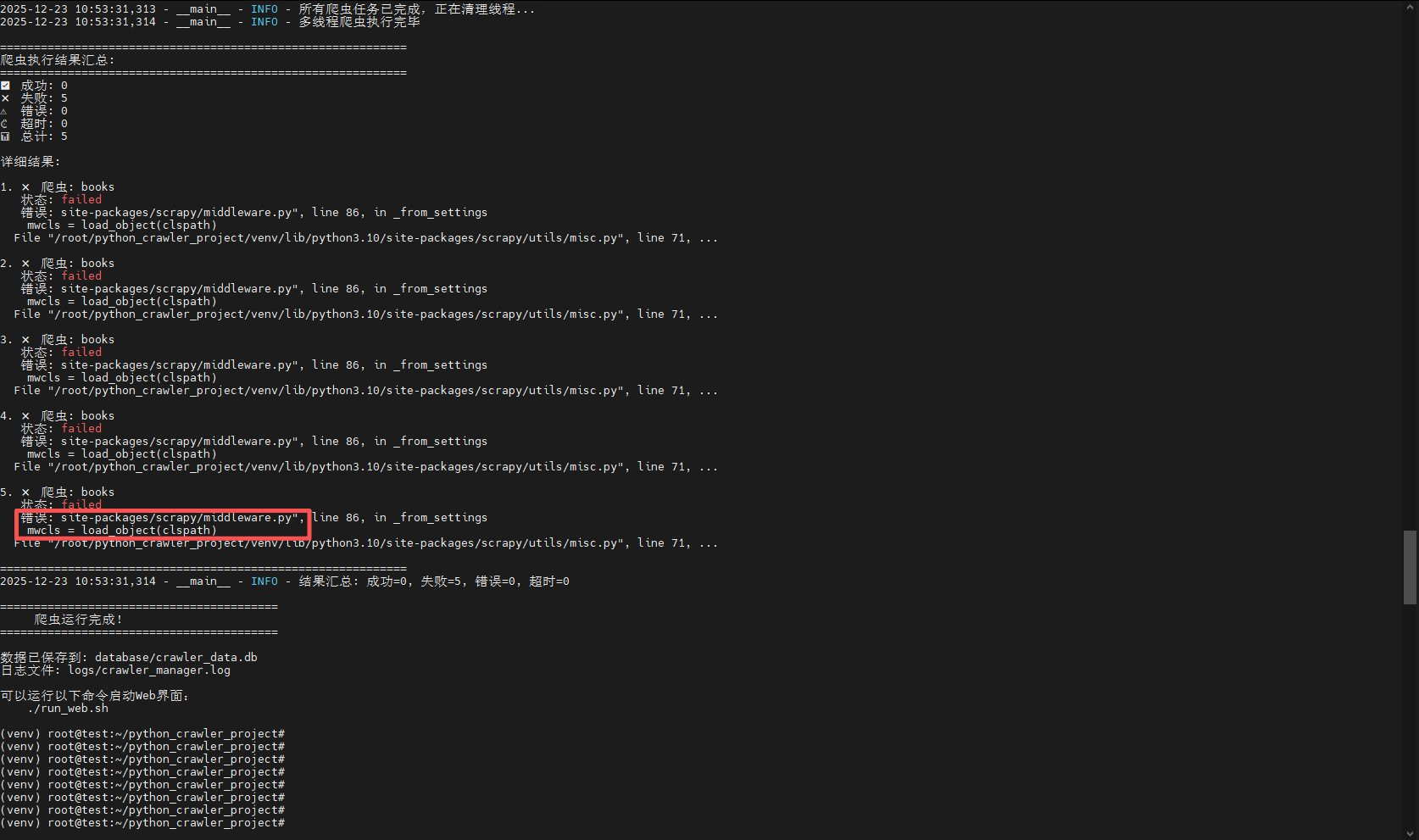
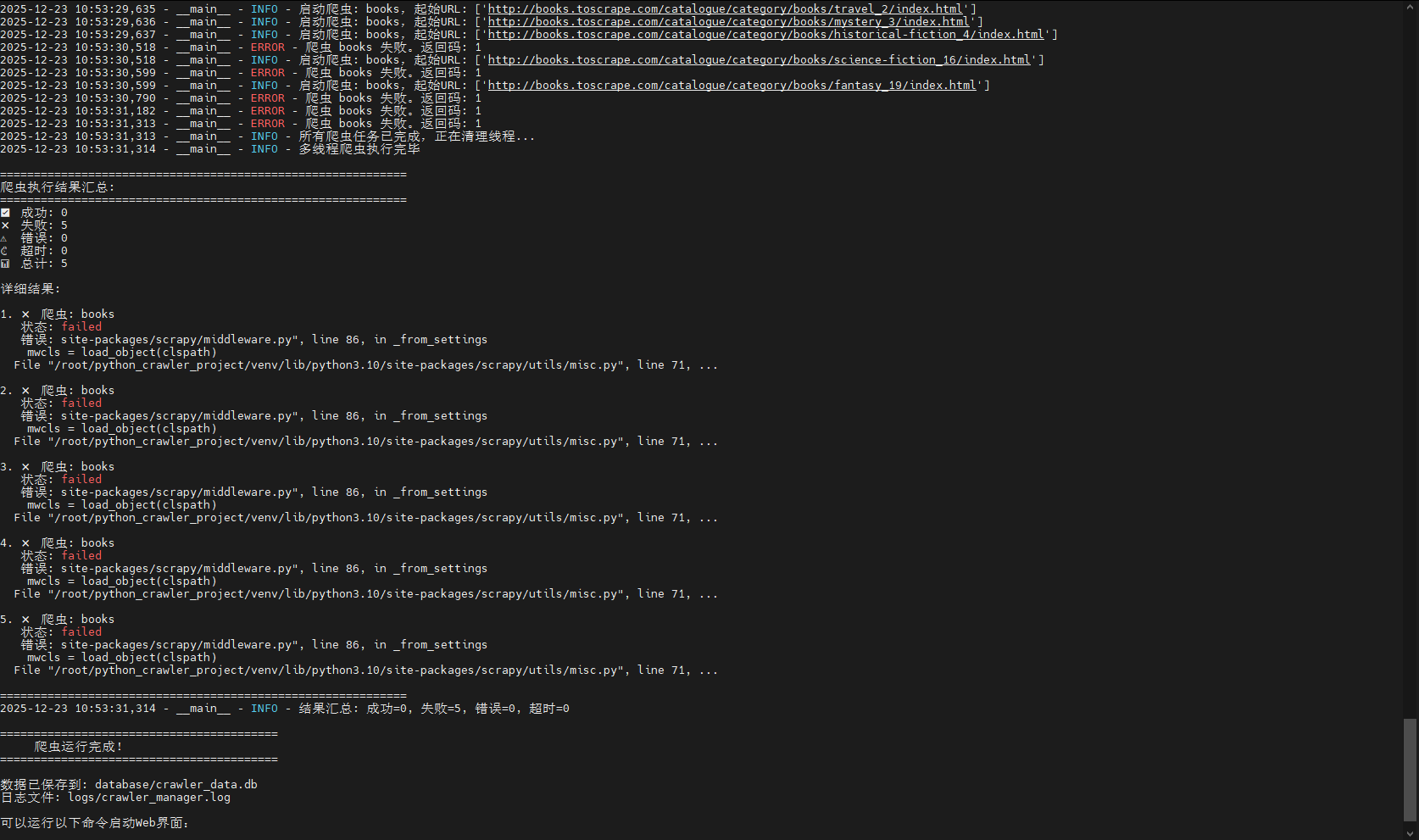
这表示 Scrapy 在尝试加载 scrapy_fake_useragent 中间件时失败了,既然缺失scrapy-fake-useragent 包,那就安装它:
bash
cd ~/python_crawler_project
source venv/bin/activate
pip install scrapy-fake-useragent
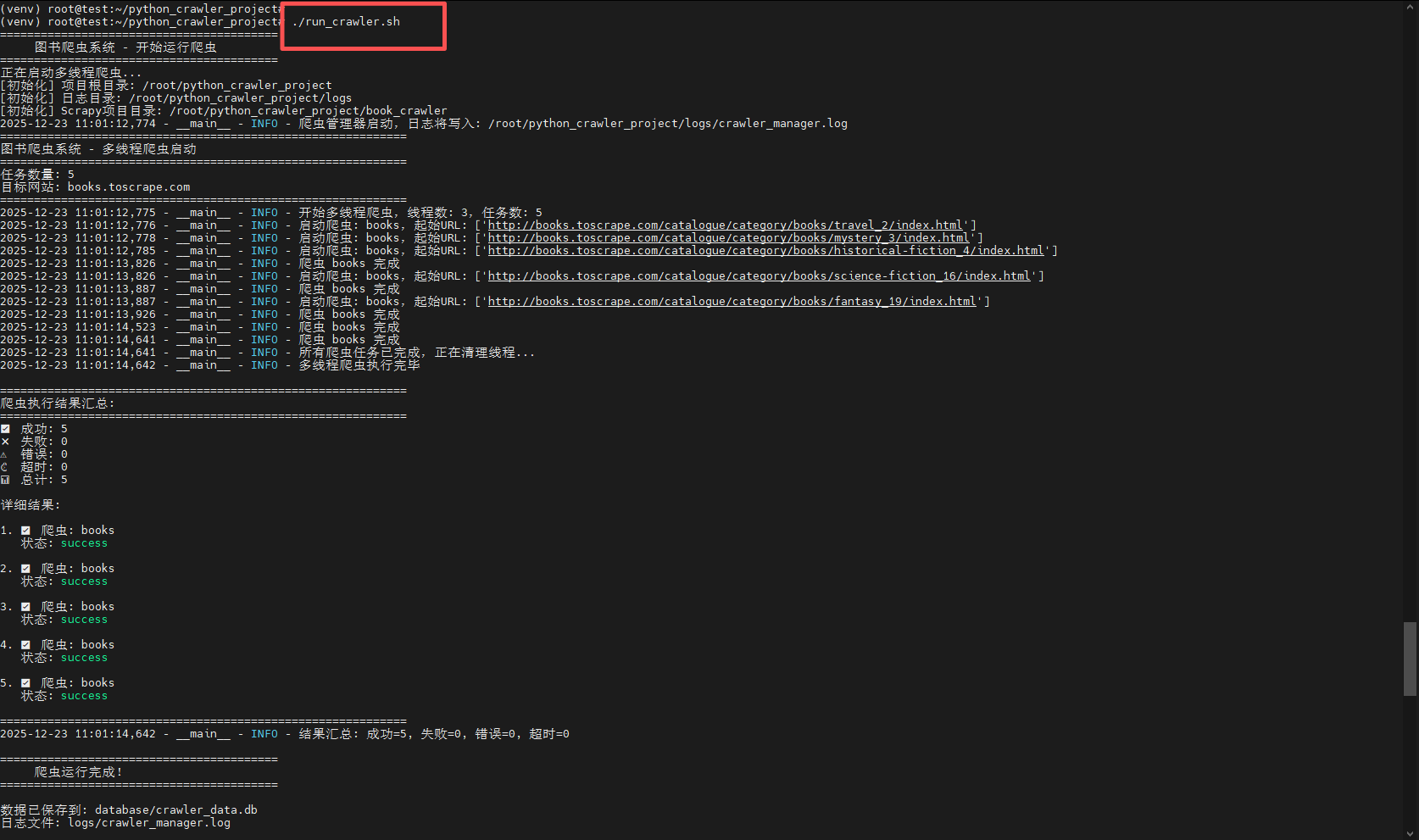
然后再运行爬虫脚本,就可以付发现成功了:
5.2 解决爬取的数据为空的问题
虽然前面成功了,但是爬取结果的数据库仍旧是空的,也就是说虽然爬虫脚步显示运行成功了,但是并没有成功爬取到数据。

记录一下解决过程:
问题分析:数据库是空的 ,这说明Scrapy爬虫虽然运行了,但数据根本没有保存到数据库里。核心原因是 book_crawler 项目不完整 (缺失关键的 settings.py 文件),导致Scrapy无法加载正确的配置,特别是数据处理管道(pipeline)。
修复方案:重建Scrapy项目
我们将删除不完整的旧项目,重新创建一个配置正确的Scrapy项目,并确保管道(pipeline)能正常工作。
严格按顺序执行以下步骤:
第一步:备份并清理旧Scrapy项目
bash
cd ~/python_crawler_project
# 备份旧项目(如果有需要保留的代码)
mv book_crawler book_crawler_old
第二步:重新创建Scrapy项目结构
bash
# 确保在项目根目录
cd ~/python_crawler_project
# 1. 创建Scrapy项目
scrapy startproject book_crawler
# 2. 创建爬虫文件
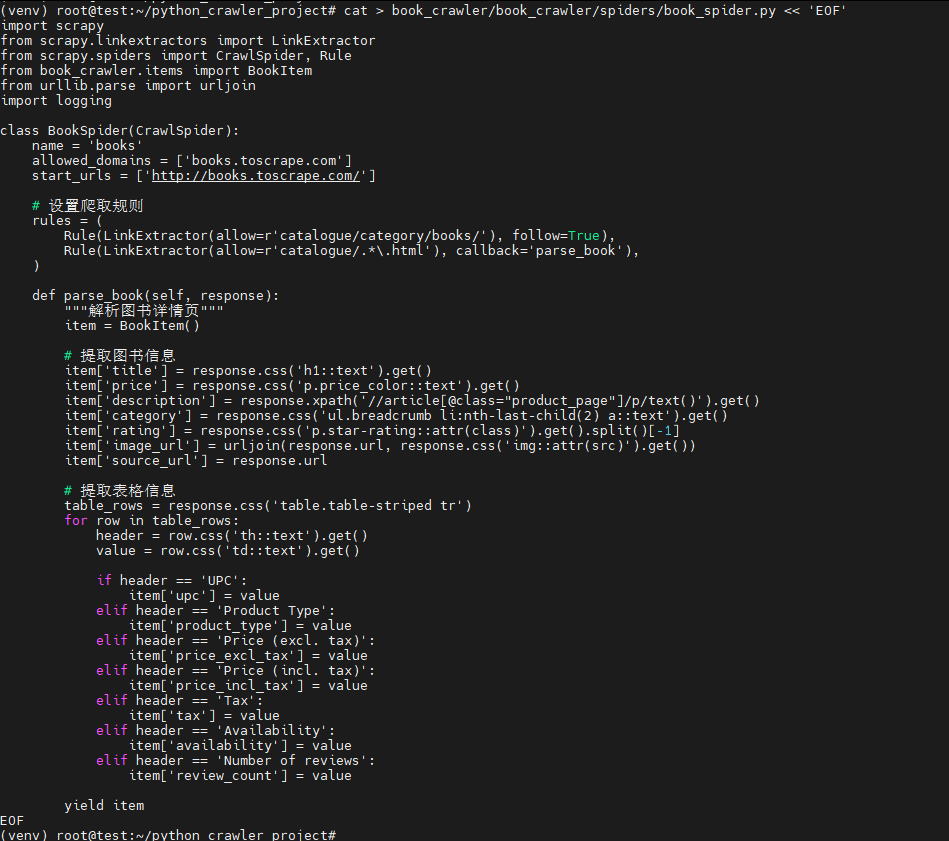
cat > book_crawler/book_crawler/spiders/book_spider.py << 'EOF'
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from book_crawler.items import BookItem
from urllib.parse import urljoin
import logging
class BookSpider(CrawlSpider):
name = 'books'
allowed_domains = ['books.toscrape.com']
start_urls = ['http://books.toscrape.com/']
# 设置爬取规则
rules = (
Rule(LinkExtractor(allow=r'catalogue/category/books/'), follow=True),
Rule(LinkExtractor(allow=r'catalogue/.*\.html'), callback='parse_book'),
)
def parse_book(self, response):
"""解析图书详情页"""
item = BookItem()
# 提取图书信息
item['title'] = response.css('h1::text').get()
item['price'] = response.css('p.price_color::text').get()
item['description'] = response.xpath('//article[@class="product_page"]/p/text()').get()
item['category'] = response.css('ul.breadcrumb li:nth-last-child(2) a::text').get()
item['rating'] = response.css('p.star-rating::attr(class)').get().split()[-1]
item['image_url'] = urljoin(response.url, response.css('img::attr(src)').get())
item['source_url'] = response.url
# 提取表格信息
table_rows = response.css('table.table-striped tr')
for row in table_rows:
header = row.css('th::text').get()
value = row.css('td::text').get()
if header == 'UPC':
item['upc'] = value
elif header == 'Product Type':
item['product_type'] = value
elif header == 'Price (excl. tax)':
item['price_excl_tax'] = value
elif header == 'Price (incl. tax)':
item['price_incl_tax'] = value
elif header == 'Tax':
item['tax'] = value
elif header == 'Availability':
item['availability'] = value
elif header == 'Number of reviews':
item['review_count'] = value
yield item
EOF
第三步:创建items.py文件
bash
cat > book_crawler/book_crawler/items.py << 'EOF'
import scrapy
class BookItem(scrapy.Item):
# 定义数据字段(与数据库模型完全对应)
title = scrapy.Field()
price = scrapy.Field()
description = scrapy.Field()
category = scrapy.Field()
rating = scrapy.Field()
image_url = scrapy.Field()
source_url = scrapy.Field()
upc = scrapy.Field()
product_type = scrapy.Field()
price_excl_tax = scrapy.Field()
price_incl_tax = scrapy.Field()
tax = scrapy.Field()
availability = scrapy.Field()
review_count = scrapy.Field()
EOF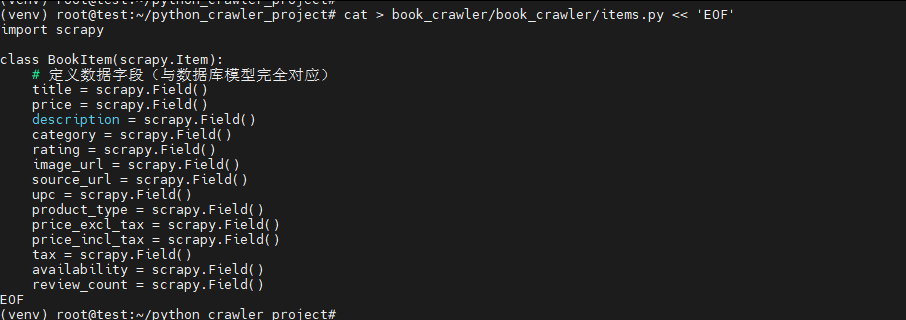
第四步:创建pipeline.py文件(关键!)
这是将数据保存到数据库的核心:
bash
cat > book_crawler/book_crawler/pipelines.py << 'EOF'
import sqlite3
from datetime import datetime
import logging
class BookPipeline:
def open_spider(self, spider):
"""爬虫启动时调用"""
self.db_path = '/root/python_crawler_project/database/crawler_data.db'
self.connection = sqlite3.connect(self.db_path)
self.cursor = self.connection.cursor()
self.create_table()
logging.info(f"数据库管道已连接: {self.db_path}")
def create_table(self):
"""创建数据库表(如果不存在)"""
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS books (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT,
price REAL,
description TEXT,
category TEXT,
rating TEXT,
image_url TEXT,
source_url TEXT,
upc TEXT,
product_type TEXT,
price_excl_tax TEXT,
price_incl_tax TEXT,
tax TEXT,
availability TEXT,
review_count INTEGER,
crawled_at TIMESTAMP
)
''')
self.connection.commit()
def process_item(self, item, spider):
"""处理每个爬取到的项目"""
try:
# 清理价格数据
price_str = item.get('price', '£0.00')
if price_str:
try:
price = float(str(price_str).replace('£', ''))
except ValueError:
price = 0.0
else:
price = 0.0
# 插入数据库
self.cursor.execute('''
INSERT INTO books (
title, price, description, category, rating,
image_url, source_url, upc, product_type,
price_excl_tax, price_incl_tax, tax,
availability, review_count, crawled_at
) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (
item.get('title', ''),
price,
item.get('description', ''),
item.get('category', ''),
item.get('rating', ''),
item.get('image_url', ''),
item.get('source_url', ''),
item.get('upc', ''),
item.get('product_type', ''),
item.get('price_excl_tax', ''),
item.get('price_incl_tax', ''),
item.get('tax', ''),
item.get('availability', ''),
item.get('review_count', 0),
datetime.now()
))
self.connection.commit()
logging.info(f"✅ 保存图书: {item.get('title', 'Unknown')[:50]}")
except Exception as e:
logging.error(f"❌ 保存图书失败: {e}")
logging.error(f" 数据: {dict(item)}")
return item
def close_spider(self, spider):
"""爬虫关闭时调用"""
self.connection.close()
logging.info("数据库连接已关闭")
EOF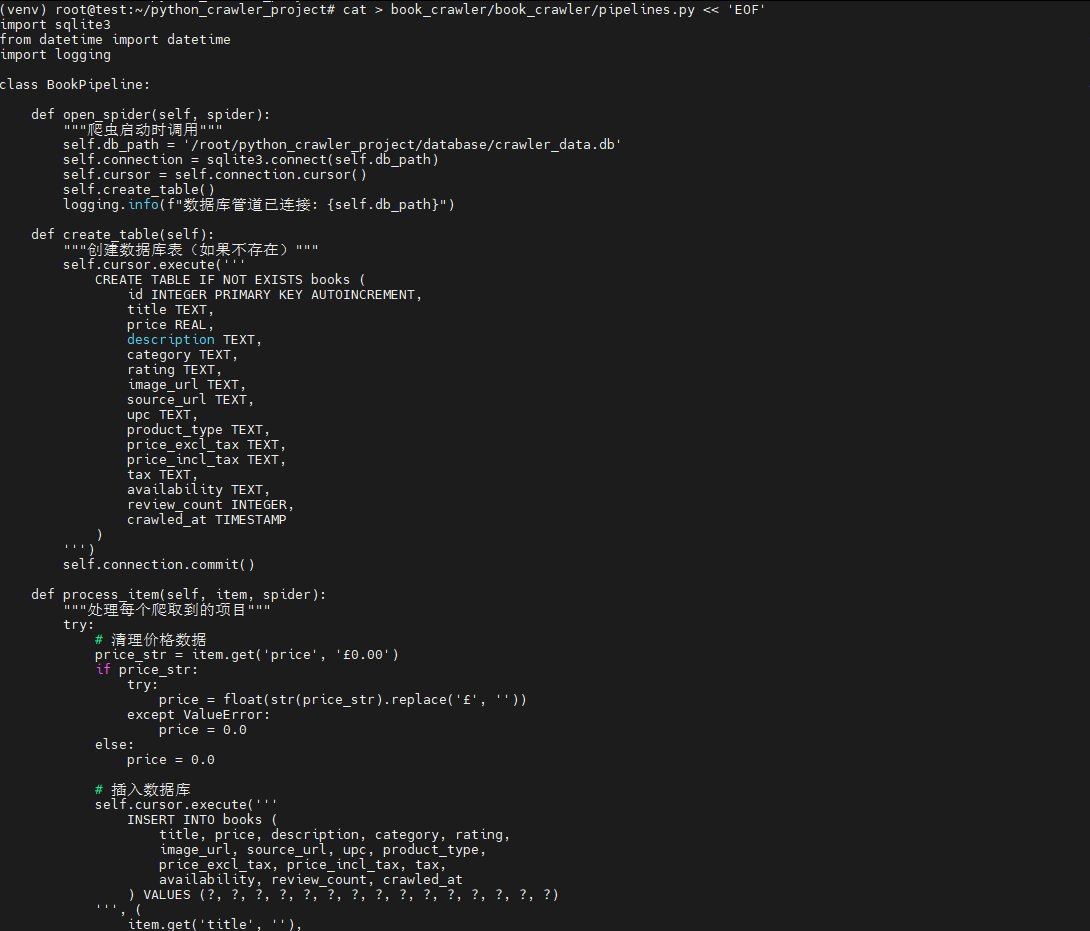

第五步:创建settings.py文件(配置pipeline)
bash
cat > book_crawler/book_crawler/settings.py << 'EOF'
BOT_NAME = 'book_crawler'
SPIDER_MODULES = ['book_crawler.spiders']
NEWSPIDER_MODULE = 'book_crawler.spiders'
# 遵守robots协议
ROBOTSTXT_OBEY = True
# 并发设置
CONCURRENT_REQUESTS = 16
CONCURRENT_REQUESTS_PER_DOMAIN = 8
CONCURRENT_REQUESTS_PER_IP = 0
# 下载延迟
DOWNLOAD_DELAY = 0.5
# 启用pipelines(关键配置!)
ITEM_PIPELINES = {
'book_crawler.pipelines.BookPipeline': 300,
}
# 日志设置
LOG_LEVEL = 'INFO'
LOG_FILE = '/root/python_crawler_project/logs/scrapy.log'
# 自动限速
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_START_DELAY = 1
AUTOTHROTTLE_MAX_DELAY = 60
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# 避免某些网站封锁
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 400,
}
# 默认请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
EOF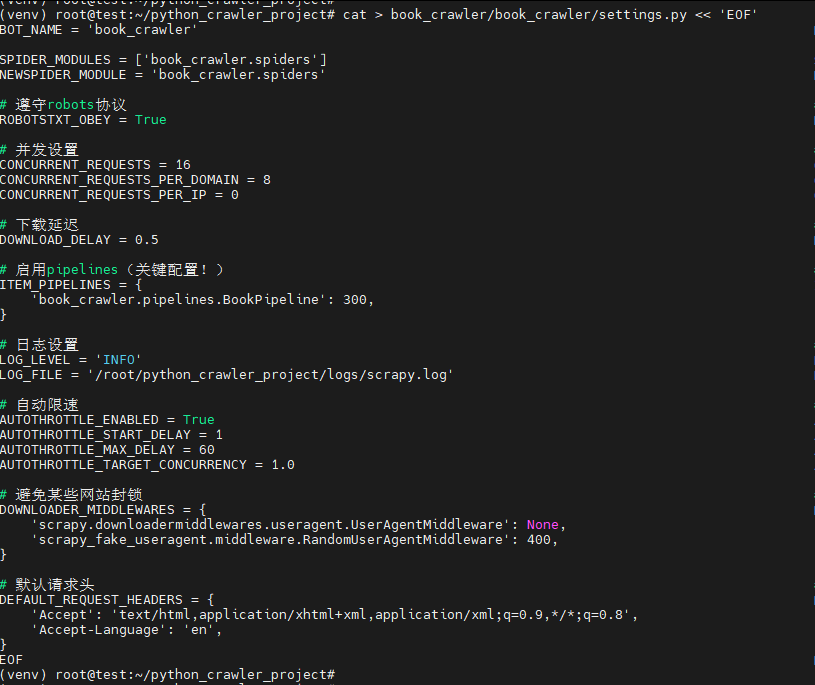
第六步:测试并运行
-
先测试单个爬虫:
bashcd ~/python_crawler_project/book_crawler scrapy crawl books -a start_urls=http://books.toscrape.com/catalogue/category/books/travel_2/index.html观察输出中是否有
✅ 保存图书: ...的日志信息。

并没有输出
-
检查数据库:
bashcd ~/python_crawler_project sqlite3 database/crawler_data.db "SELECT COUNT(*) FROM books;" sqlite3 database/crawler_data.db "SELECT title, price FROM books LIMIT 3;"现在应该有数据了?

看了一下,并没有,还是没有数据。
咋整,继续排查吧:
先验证Scrapy命令是不是能正常工作?
从前面可以看到,Scrapy爬虫运行后没有输出任何信息,这通常意味着爬虫没有被正确执行或者有配置问题。需要先确保Scrapy项目结构正确,然后一步步排查。
我先测试一个最简单的爬虫,看看Scrapy本身是否正常:
bash
cd ~/python_crawler_project
# 创建一个最简单的测试爬虫
cat > test_spider.py << 'EOF'
import scrapy
class TestSpider(scrapy.Spider):
name = "test"
start_urls = ["http://books.toscrape.com"]
def parse(self, response):
# 打印页面标题,验证爬虫正常工作
title = response.css('title::text').get()
print(f"✅ 页面标题: {title}")
# 提取第一本书的信息
book_title = response.css('article.product_pod h3 a::attr(title)').get()
book_price = response.css('article.product_pod p.price_color::text').get()
print(f"✅ 第一本书: {book_title} - {book_price}")
EOF
# 运行测试爬虫
cd book_crawler
scrapy runspider ../test_spider.py --loglevel=INFO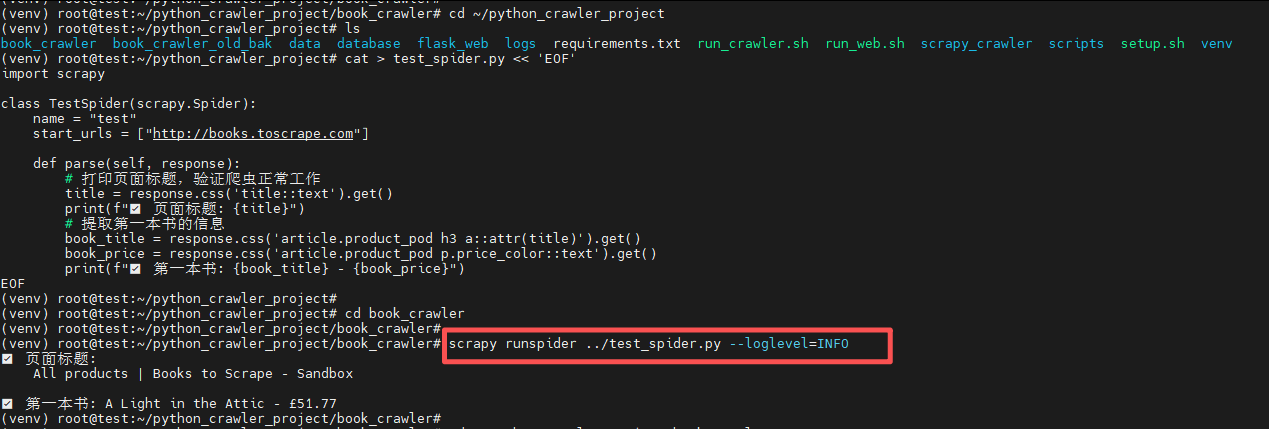
第三步:检查Scrapy配置
查看settings.py是否正确配置了pipeline:
bash
cd ~/python_crawler_project/book_crawler
grep -A5 -B5 "ITEM_PIPELINES" book_crawler/settings.py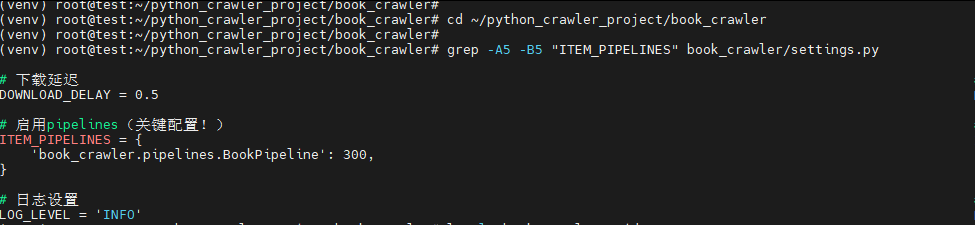
第四步:检查爬虫文件是否存在且正确
bash
ls -la book_crawler/spiders/
cat book_crawler/spiders/book_spider.py | head -20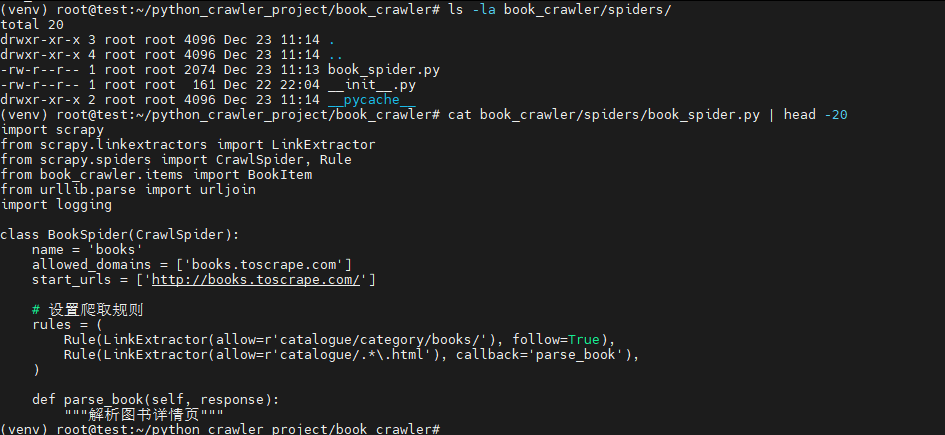
第五步:运行爬虫并查看详细日志
bash
# 使用DEBUG级别查看详细输出
scrapy crawl books -a start_urls=http://books.toscrape.com/catalogue/category/books/travel_2/index.html --loglevel=DEBUG
可以看到,测试爬虫能工作,说明Scrapy框架和网络都没问题。但正式爬虫没输出,这揭示了核心问题:我们当前的 BookSpider 是一个 CrawlSpider,它的工作方式依赖 rules 规则,并且可能和我传递的 start_urls 参数有冲突。
问题分析:我的 book_spider.py 使用了 CrawlSpider,它默认从 start_urls = ['http://books.toscrape.com/'] 开始,并用 rules 自动发现链接。但当我用 -a start_urls=... 传递参数时,它覆盖了类属性,直接从你给的分类页面开始,而 rules 可能在这些页面上匹配不到链接,导致爬虫立刻结束,什么都不做。
解决方案是:将 CrawlSpider 改为更可控的普通 Spider,并确保它能接收我们指定的 start_urls 参数。 这样逻辑更清晰,也完全适配我设计的多线程管理器。
直接对上面的问题进行修复:
用以下代码完全替换 现有的 book_crawler/book_crawler/spiders/book_spider.py:
python
# book_crawler/book_crawler/spiders/book_spider.py
import scrapy
from scrapy import Request
from book_crawler.items import BookItem
import logging
class BookSpider(scrapy.Spider):
name = 'books'
allowed_domains = ['books.toscrape.com']
def __init__(self, start_urls=None, *args, **kwargs):
"""
关键:接收外部传入的 start_urls 参数。
格式应为逗号分隔的URL字符串。
"""
super(BookSpider, self).__init__(*args, **kwargs)
# 处理传入的URL参数
if start_urls:
self.start_urls = [url.strip() for url in start_urls.split(',')]
else:
# 如果没有提供,使用一个默认分类页面
self.start_urls = ['http://books.toscrape.com/catalogue/category/books/travel_2/index.html']
self.logger.info(f"📌 爬虫启动,起始URL: {self.start_urls}")
def start_requests(self):
"""为每个起始URL生成请求,指向分类页面解析方法。"""
for url in self.start_urls:
yield Request(url, callback=self.parse_category_page)
def parse_category_page(self, response):
"""
解析分类列表页,提取该分类下所有图书的详情页链接。
"""
self.logger.info(f"📂 正在解析分类页面: {response.url}")
# 1. 提取当前页所有图书详情页链接
book_links = response.css('h3 a::attr(href)').getall()
self.logger.info(f" 找到 {len(book_links)} 个图书链接")
for relative_link in book_links:
# 构建绝对URL
book_url = response.urljoin(relative_link)
# 请求图书详情页
yield Request(book_url, callback=self.parse_book_detail)
# 2. (可选) 处理分页 - 查找并跟踪"Next"按钮
next_page = response.css('li.next a::attr(href)').get()
if next_page:
next_page_url = response.urljoin(next_page)
self.logger.info(f" 发现下一页: {next_page_url}")
yield Request(next_page_url, callback=self.parse_category_page)
def parse_book_detail(self, response):
"""
解析图书详情页,提取信息并生成BookItem。
"""
self.logger.info(f"📖 正在解析图书详情页: {response.url}")
item = BookItem()
# 核心信息提取
item['title'] = response.css('h1::text').get(default='').strip()
item['price'] = response.css('p.price_color::text').get(default='£0.00').strip()
item['description'] = response.xpath('//article[@class="product_page"]/p/text()').get(default='').strip()
item['category'] = response.css('ul.breadcrumb li:nth-last-child(2) a::text').get(default='').strip()
# 处理评分(从class中提取)
rating_class = response.css('p.star-rating::attr(class)').get(default='')
item['rating'] = rating_class.split()[-1] if rating_class else ''
# 图片和URL
img_src = response.css('img::attr(src)').get(default='')
item['image_url'] = response.urljoin(img_src) if img_src else ''
item['source_url'] = response.url
# 从产品信息表格中提取详细数据
table_rows = response.css('table.table-striped tr')
for row in table_rows:
header = row.css('th::text').get()
value = row.css('td::text').get()
if not header or not value:
continue
header = header.strip()
value = value.strip()
if header == 'UPC':
item['upc'] = value
elif header == 'Product Type':
item['product_type'] = value
elif header == 'Price (excl. tax)':
item['price_excl_tax'] = value
elif header == 'Price (incl. tax)':
item['price_incl_tax'] = value
elif header == 'Tax':
item['tax'] = value
elif header == 'Availability':
item['availability'] = value
elif header == 'Number of reviews':
try:
item['review_count'] = int(value)
except ValueError:
item['review_count'] = 0
# 确保所有字段都有默认值
for field in item.fields:
if field not in item:
item[field] = ''
self.logger.info(f"✅ 成功提取: {item['title'][:40] if item['title'] else '未知图书'}")
yield item
替换文件后,按顺序执行以下测试:
-
手动测试爬虫 (在
book_crawler目录下):bashscrapy crawl books -a start_urls=http://books.toscrape.com/catalogue/category/books/travel_2/index.html --loglevel=INFO观察 :你应该立刻看到日志输出,如
📌 爬虫启动、📂 正在解析分类页面、📖 正在解析图书详情页和✅ 成功提取。

这里有两个book_crawler文件夹,我全都执行了一次测试的指令,但是都没有预期的输出。没关系,继续往下
-
检查数据库 (回到项目根目录):
bashcd ~/python_crawler_project sqlite3 database/crawler_data.db "SELECT COUNT(*) FROM books;" sqlite3 database/crawler_data.db "SELECT title, price FROM books LIMIT 3;"如果一切正常,现在
COUNT(*)应该大于0。

果然,数据库里有数据了。
-
运行完整的爬虫管理器 :
bash./run_crawler.sh观察输出,应该所有5个任务都成功。
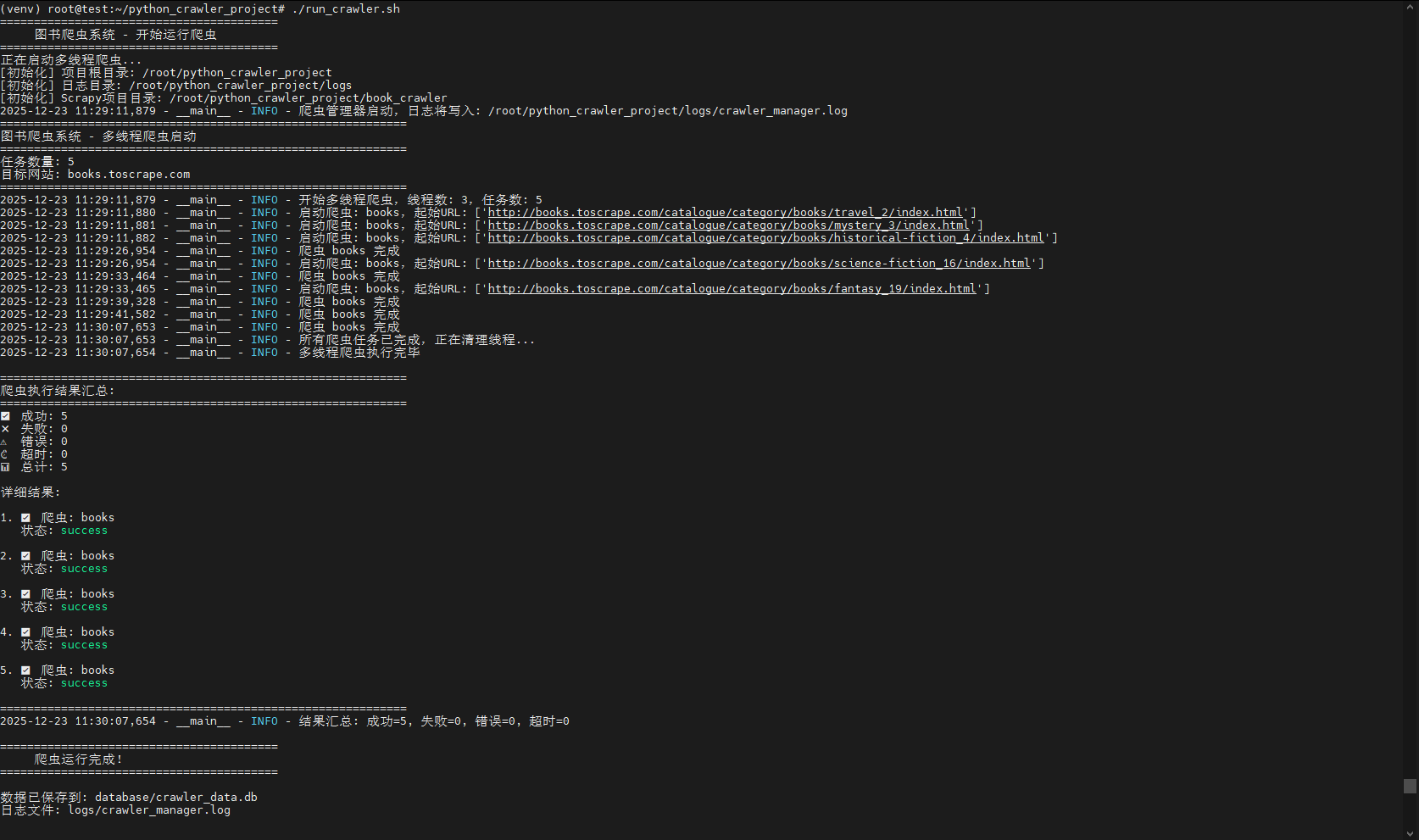
这下可以看到不仅运行成功了,而且运行过程很慢,说明在写数据了。
再次查看下数据库:

可以发现数据确实多了很多。
此时再去查看我们的网页:
搞定
十、项目结构总览
python_crawler_project/
├── venv/ # Python虚拟环境
├── book_crawler/ # Scrapy爬虫项目
│ ├── book_crawler/
│ │ ├── spiders/ # 爬虫文件
│ │ ├── items.py # 数据模型
│ │ ├── pipelines.py # 数据处理管道
│ │ └── settings.py # 爬虫配置
│ └── scrapy.cfg # Scrapy配置文件
├── flask_web/ # Flask Web应用
│ ├── static/ # 静态文件
│ ├── templates/ # HTML模板
│ └── app.py # Flask主应用
├── database/ # 数据库相关
│ ├── config.py # 数据库配置
│ ├── init_db.py # 数据库初始化
│ └── crawler_data.db # SQLite数据库文件
├── scripts/ # 脚本文件
│ └── crawler_manager.py # 爬虫管理器
├── logs/ # 日志文件
├── data/ # 数据文件
├── requirements.txt # Python依赖
├── run_crawler.sh # 运行爬虫脚本
├── run_web.sh # 运行Web脚本
└── setup.sh # 安装脚本十一、常见问题解决
1. 如果虚拟环境激活失败
bash
cd ~/python_crawler_project
source venv/bin/activate2. 如果端口5000被占用
修改flask_web/app.py中的端口号:
python
app.run(host='0.0.0.0', port=5001, debug=True) # 改为5001或其他端口3. 如果爬虫无法连接
检查网络连接,并确保可以访问:http://books.toscrape.com
4. 查看日志文件
bash
cd ~/python_crawler_project
cat logs/crawler_manager.log
cat logs/crawler.log十二、项目特点
- 完整的多线程爬虫:使用Scrapy框架实现高效爬取
- 数据库存储:使用SQLite存储爬取的数据
- Web界面展示:使用Flask框架创建美观的Web界面
- 数据分析功能:使用matplotlib生成统计图表
- 模块化设计:代码结构清晰,易于维护和扩展
- 一键运行:提供方便的脚本文件
十三、项目运行流程详解总结
📊 项目架构总览
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Web前端展示 │←──→│ Flask后端服务 │←──→│ SQLite数据库 │
│ (浏览器) │ │ (app.py) │ │ (crawler_data.db)│
└─────────────────┘ └────────┬────────┘ └────────┬────────┘
│ │
│ │
┌───────▼────────┐ ┌───────▼────────┐
│ 多线程爬虫管理器 │ │ Scrapy爬虫 │
│ (crawler_manager)│ │ (book_spider) │
└─────────────────┘ └─────────────────┘🔄 完整的运行流程(按顺序)
阶段1:环境准备(一次性)
bash
./setup.sh目的:搭建Python运行环境
- 创建Python虚拟环境(隔离依赖)
- 安装所有Python包(Scrapy、Flask等)
- 初始化空数据库(创建表结构)
- 创建日志和数据的存储目录
阶段2:数据采集(按需执行)
bash
./run_crawler.sh目的:从互联网抓取图书数据并保存到数据库
详细执行过程:
- 启动爬虫管理器 (
scripts/crawler_manager.py) - 创建多线程任务:为每个图书分类创建爬虫任务
- 启动Scrapy爬虫:每个线程运行一个Scrapy实例
- 爬取网页数据 :访问
books.toscrape.com,解析HTML - 数据清洗存储:通过Pipeline处理数据,存入SQLite数据库
关键文件:
book_crawler/spiders/book_spider.py- 定义如何爬取网页、提取数据book_crawler/pipelines.py- 定义如何处理和保存爬取的数据
阶段3:数据展示
bash
./run_web.sh目的:提供Web界面查看和分析数据
详细执行过程:
- 启动Flask服务器 (
flask_web/app.py) - 连接数据库:读取之前爬取的数据
- 处理HTTP请求 :
/首页:显示统计数据/books图书列表:分页显示所有图书/analysis数据分析:生成统计图表
- 渲染HTML模板:将数据库数据填充到HTML页面
🕐 数据流向时间线
时间点 操作 数据状态
───── ────────────────── ──────────────────────────────
T0 运行 ./setup.sh 空数据库(只有表结构)
T1 运行 ./run_crawler.sh 爬虫开始工作
T1+1min 爬虫完成 数据库中有50-100本图书数据
T2 运行 ./run_web.sh Web服务器启动
T3 浏览器访问 看到完整的图书数据📋 各脚本功能总结
| 脚本文件 | 作用 | 运行时机 | 输出结果 |
|---|---|---|---|
setup.sh |
环境搭建 | 首次部署时 | Python环境、数据库表 |
run_crawler.sh |
数据采集 | 需要更新数据时 | 数据库中的图书数据 |
run_web.sh |
数据展示 | 想查看数据时 | Web服务器(:5000端口) |
🔍 页面内容来源详解
当你在浏览器看到页面时:
-
统计数据(图书总数、平均价格等)
- 来源:Flask查询数据库实时计算
- 代码位置 :
flask_web/app.py中的index()函数
-
图书列表(标题、价格、分类等)
- 来源 :数据库
books表的直接查询 - 代码位置 :
flask_web/app.py中的books()函数
- 来源 :数据库
-
分析图表(价格分布、分类统计等)
- 来源:Flask用matplotlib实时生成
- 代码位置 :
flask_web/app.py中的analysis()函数
💡 关键理解点
-
数据是静态的 :页面显示的数据来自数据库,不是实时爬取的。爬虫只在运行
./run_crawler.sh时工作。 -
更新数据流程:
bash# 需要更新数据时 ./run_crawler.sh # 重新爬取,会覆盖/追加数据 # 刷新浏览器页面即可看到新数据 -
项目亮点:
- 前后端分离:Python后端 + HTML前端
- 模块化设计:爬虫、Web、数据库各自独立
- 多线程爬虫:提高数据采集效率
- 数据分析:自动生成可视化图表
十四 如何快速在虚拟机上运行
下载我的源码包:
https://download.csdn.net/download/AnChenliang_1002/92492537
解压密码:crawler
把解压的文件放到根目录下:
cd
cd python_crawler_project_deploy/
./setup.sh
source venv/bin/activate
./run_crawler.sh
./run_web.sh
出现ip信息后,在虚拟机里打开火狐浏览器,输入http://127.0.0.1:5000