在近期的 Streaming Lakehouse Meetup · Online EP.2|Paimon × StarRocks 共话实时湖仓 直播中,Apache Paimon PMC 成员/阿里云数据湖资深工程师叶俊豪带来了关于 Paimon 多模态数据湖的深度技术分享。
随着大模型训练对数据规模与多样性的要求不断提升,传统以批处理为中心的数据湖架构已难以满足 AI 工作负载对实时性、灵活性和成本效率的综合需求。特别是在推荐系统、AIGC 等典型场景中,工程师既要高频迭代结构化特征,又要高效管理图像、音频、视频等非结构化数据。面对这一挑战,Paimon 作为新一代流式数据湖存储引擎,正通过一系列底层创新,构建面向 AI 原生时代的统一数据基础设施。
一、结构化场景下的"列变更"困境
在推荐、广告等 AI 应用中,特征工程是一个持续演进的过程。例如,电商团队可能今天新增"用户近7日点击品类分布",明天又加入"跨端行为一致性评分"。这种动态列变更导致"列爆炸"问题:表结构频繁扩展,而历史数据需与新特征对齐。 
然而,已知的解决方案在此场景下仍然存在一些问题:
-
主键表 partial-update:虽支持按主键更新部分列,但其基于 LSM 树的实现会在写入频繁时产生大量小文件,查询性能急剧下降;Compaction 虽可合并文件,却带来数倍的临时存储开销。
-
odps 存新特征值 + Join 拼接方案:将新特征写入独立表,查询时通过主键 Join 合并。看似避免了重写,但 Join 操作本身在 PB 级数据上开销巨大,且难以优化。
-
Append 表 + MERGE INTO:SQL 语法简洁,但底层仍需重写整个数据文件。对于每天增量达 PB 级的训练集,全量重写不仅成本高昂,还显著拖慢特征上线周期。
这些方案本质上都未能解耦"列"的物理存储,导致灵活性与效率不可兼得。
二、Paimon 的列分离架构:以全局 Row ID 为核心
Paimon 提出了 列分离存储架构 ,其核心是引入 全局唯一且连续的 Row ID。每行数据在首次写入时被分配一个在整个表生命周期内不变的 ID,且每个数据文件内的 Row ID 是连续的,元数据会记录该文件的起始 Row ID。
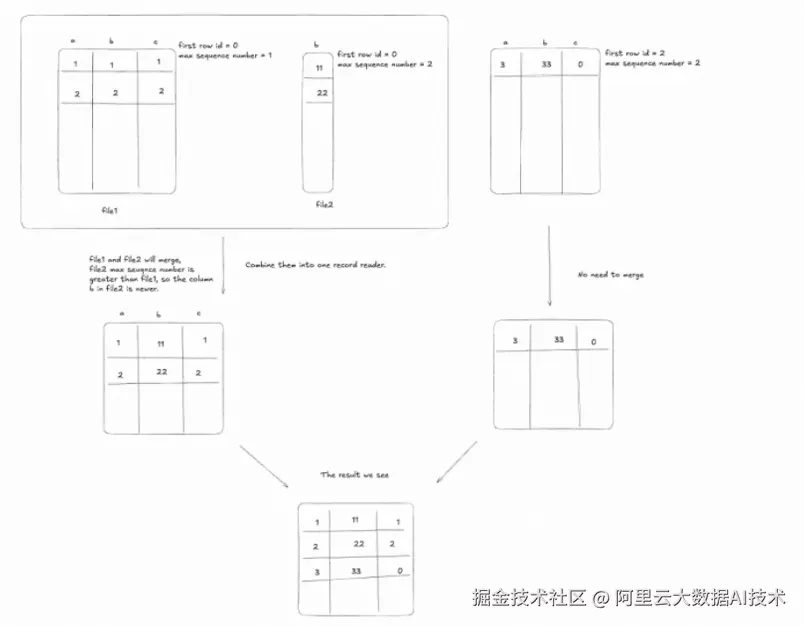
这一设计带来两个关键能力:
-
精准定位任意行:通过 Row ID 可直接定位到具体文件及偏移;
-
跨文件自动关联:当查询涉及多个列时,系统能根据 Row ID 范围自动将分散在不同文件中的列数据在存储层合并。
例如,当新增"用户兴趣标签"列时,Paimon 仅需写入一个包含该列与对应 Row ID 的新文件,无需修改原始特征文件。查询时,引擎透明地将两组文件按 Row ID 对齐合并,无需 SQL 层 Join,也无需重写历史数据。这种机制将列变更的存储成本从 O(N) 降至 O(ΔN),极大提升了特征迭代效率,同时节省了数十倍的存储空间。
三、迈向多模态:Blob 数据类型的三大突破
AI 训练不再局限于结构化特征。AIGC、多模态大模型等场景要求数据湖能高效处理图像、短视频、长音频等非结构化数据。这类数据具有两大特点:体积差异大 (几 MB 到数十 GB)、访问稀疏(训练时通常只读取片段)。
传统列式格式(如 Parquet)将多模态数据与结构化字段混存,导致即使只查用户 ID,也需加载整个含视频的大文件,I/O 效率极低。
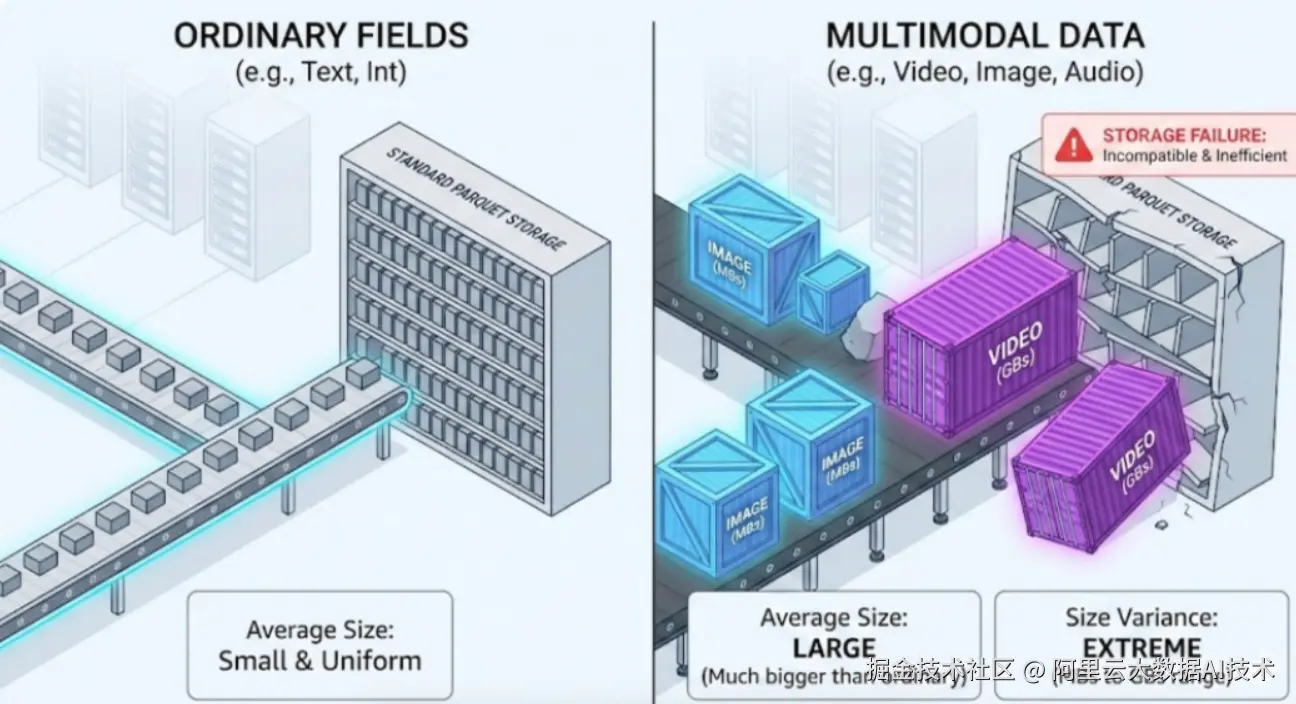
Paimon 引入 Blob 数据类型,实现三大突破:
-
物理分离存储:Blob 列独立成文件,与结构化数据完全解耦。查询结构化字段时,Blob 文件完全不参与 I/O,避免资源浪费。
-
多引擎统一抽象 :无论使用 Spark、Flink、Java SDK 还是 Python 客户端,均可通过标准的
BYTES或BINARY或 BLOB 类型定义 Blob 字段,接口一致,降低接入成本。 -
blob-as-descriptor 机制:针对超大非结构化数据(如十几GB的视频/日志文件),传统计算引擎(如Flink/Spark)无法将其全量加载到内存中处理。为此,系统引入了 blob-as-descriptor 机制------它是一种协议,通过记录数据在外部存储(如OSS)中的位置、文件路径、起始偏移和长度等元信息,将实际数据读取任务交给下游系统按需流式加载。这样避免了内存溢出,实现了大文件高效入湖。
四、生产验证与未来演进
当前,Paimon Blob 已在淘宝、天猫等核心业务中实现大规模落地,每天有近 10PB 的多模态数据(如视频、音频、图像)通过 Blob Descriptor 协议高效写入 Paimon 湖,避免了 Flink 或 Spark 将大文件全量加载到内存的问题。然而,在实际使用中仍面临三大关键挑战:
-
数据重复与删除问题,用户常因多次上传相同内容导致大量冗余(预估约 1PB/天的重复数据),亟需高效的去重与删除机制;
-
小文件碎片化问题,频繁的小规模写入产生海量微小 Blob 文件,严重影响读取性能和存储效率;
-
点查召回延迟高,缺乏对主键(如 UID)或向量特征的快速索引支持,难以满足毫秒级实时查询需求。
针对上述问题,团队已规划清晰的演进路径。
-
点查性能优化 方面,推进热 ID 下推能力,并构建统一的全局索引框架,同时支持标量索引(如字符串、数值)和向量索引(用于 AI 召回),其中基础版标量索引预计本月在开源 Master 分支可用。
-
多模态数据管理方面,启动两项核心功能:
-
一是基于 Deletion Vector + 占位符 的逻辑删除方案,在 Compaction 阶段安全清理重复或无效数据;
-
二是开发 Blob Compaction 机制,自动合并小文件以提升读性能和存储密度。
-
此外,团队还前瞻性地提出跨表 Blob 复用的构想------多个表引用同一视频时仅存储一份物理数据,虽因涉及多表状态同步与一致性保障而技术难度较高,但已列入长期优化方向。整体目标是打造一个高效、紧凑、可快速检索的多模态数据湖底座,支撑未来 AIGC 与智能推荐等场景的规模化应用。
结语
Paimon 的技术演进,从结构化场景的列分离,到多模态数据的 Blob 抽象,每一项创新都源于真实业务痛点,并反哺于工程效率的提升。它不再只是"存储数据的地方",而是成为 AI 原生时代的数据操作系统------高效、灵活、智能。
Paimon 将长期、持续且大力投入全模态数据湖建设,全面支持图像、音视频等非结构化数据的高效入湖、去重、合并与毫秒级点查。通过 Deletion Vector、Compaction 优化和全局索引等能力,Paimon 正构建面向 AI 时代的统一数据底座。作为开放湖表格式。
阿里云DLF 在云上提供全托管的Paimon存储服务,支持Paimon的智能存储优化与冷热分层。同时,DLF提供安全、开放、支持全模态数据的一体化Lakehouse管理平台,深度融入兼容其他例如 Iceberg、Lance 等主流格式,无缝对接 Flink、Spark 等计算引擎,,为 AIGC 与多模态智能应用提供高性能、低成本、易治理的数据基础设施。 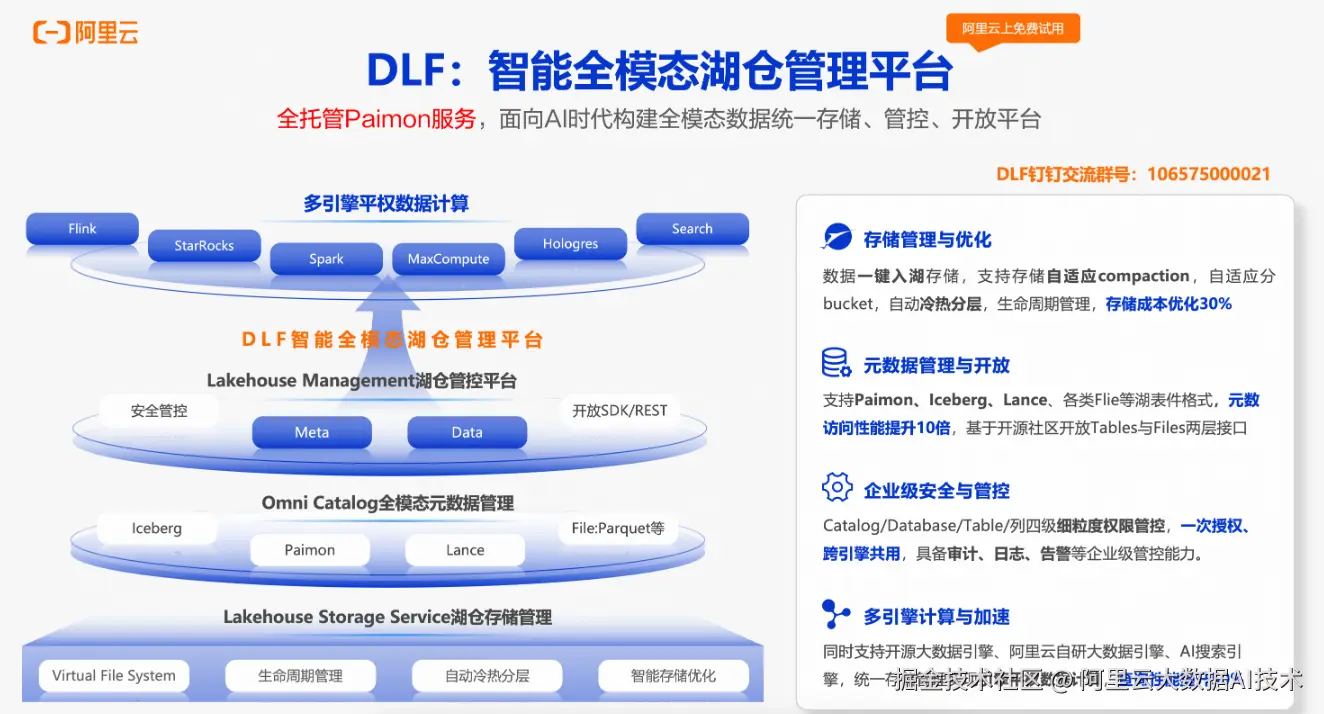
在数据驱动的 AI 时代,基础设施的价值,最终要体现在对业务效率的实质性推动上。 Paimon 的实践,正为整个行业提供一条通往高效、统一、智能数据湖的新路径。