CPU与DCU互连架构
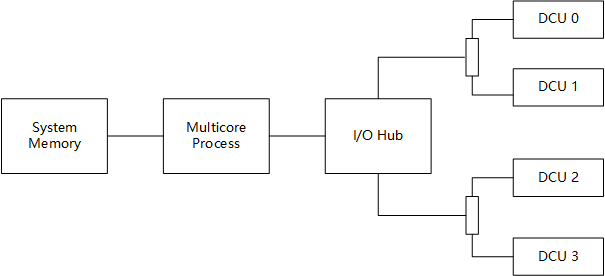
常见的异构计算节点体系结构主要由四个部分组成:主存、多核处理器、I/O Hub和DCU加速器,下图描述了这种体系结构互连关系。主存(System Memory)与多核处理器之间通过Memory Bus互连,常用的物理接口有SIMM、DIMM、RIMM等。多核处理器借助I/O Hub链接多种外部设备,I/O Hub通过PCI-E总线链接,以树状结构链接各种功能设备,在异构计算节点中,主要的设备就是DCU加速器,由于处理器直接支持的PCI-E链路有最大数量限制,因此在I/O Hub与DCU加速器之间还会增加PCI-E Switch,从而扩展PCI-E链路链接更多的设备。高级PCI-E Switch支持多种链接结构,并可以在其内部完成数据转发而无需多核处理器参与,这情况下数据传输往往可以获得更高的效率。
如果异构计算节点拥有多个多核处理器,那么这些多核处理器将通过专用总线进行互连,如GMI、QPI等(intel QPI(QuickPath Interconnect),AMD GMI(Global Memory Interconnect), 属于CPU间互联方式),与其对应I/O Hub相连的外部设备在进行数据传输时,将会受到协议的影响,最糟糕的情况是,分属于不同多核处理器的外部设备之间无法通信。因此需要合理的选择多核处理器、主存、DCU加速器之间的使用关系,这种结构在计算机体系结构中被定义为NUMA。
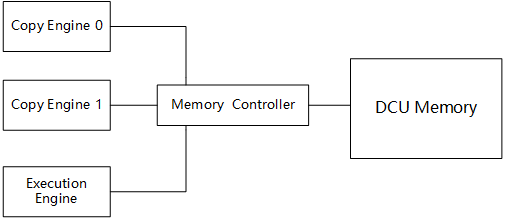
DCU加速器根据其主要功能可以划分为四个主要组件:执行引擎(Execution Engine),一个或多个DMA拷贝引擎(Copy Engine),内存控制器(Memory Controller)和DCU显存(DCU Memory)。 DMA拷贝引擎可以接收内存控制器的数据传输请求,处理系统内存与DCU显存之间、DCU显存之间的传输数据。 由于PCI-E是全双工的互连协议,DCU加速器拥有2个拷贝引擎,可以同时进行数据传入和数据传出的双向通信。 合理利用DCU加速器各组件的执行特点将大幅度提高程序的性能。
DCU之间通过PCI-E互连并完成数据传输,在高级DCU加速器上,同时还支持xGMI链路。xGMI(inter-chip global memory interconnect)是一种开放标准全局内存互连协议的点对点高速互连。通过xGMI链路互连的DCU加速器可以获得高带宽、低延时的传输性能,并且可以支持DCU加速器之间的缓存一致性,从而实现共享显存。
在一个给定的服务器里、每个节点都借由一个高速交换机连接到所有其他的节点。这种连接开关与以太网一样简单。大多数节点的主板附带两个以太网端口:一个负责内部连接,另一个负责外部连接。所有的外部连接通向一个共同交换机。交换机本身处在诸如InfiniBand 的高速的主干网上。
而节点间使用InfiniBand实现高速互连,而InfiniBand是一种网络通信协议,它提供了一种基于交换的架构,由处理器节点和输入/输出节点(如磁盘或存储)之间的点对点双向串行链路构成。
InfiniBand通过交换机在节点之间直接创建一个私有的、受保护的通道,进行数据和消息的传输通道。适配器通过PCI-E接口一端连接到CPU,另一端通过InfiniBand网络端口连接到InfiniBand子网。与其他网络通信协议相比,这提供了明显的优势,包括更高的带宽、更低的延迟和增强的可伸缩性。