在大模型应用的深水区,很多开发者都会遇到这样的窘境:原生 RAG 面对复杂逻辑像个人工智障,只会根据语义相似度乱翻书;而 Microsoft GraphRAG 效果虽好,价格高出天际,处理几万字文档就要数美金,且索引速度慢如牛。
垂直领域需要的是既能看懂复杂关系,又能精准溯源,且成本可控的方案。
今天,我们将拆解一套全新的架构:Agentic-GraphRAG。这不只是一个技术 Demo,而是一套可以真正跑在生产环境中的闭环方案。
一、 为什么你的 RAG 总是不给力?Agentic-GraphRAG 的破局之道
RAG 核心逻辑是 切片 + 向量检索。但在医疗、法律等垂直领域,这种逻辑会遭遇两大致命伤:
- 碎片化信息的孤岛效应:当答案分散在多份文档中,需要多步推理时,语义相似度往往无法串联起这些逻辑点。
- 上下文中毒:检索到的片段混入了大量无关噪音,导致大模型生成的答案混入无关信息。
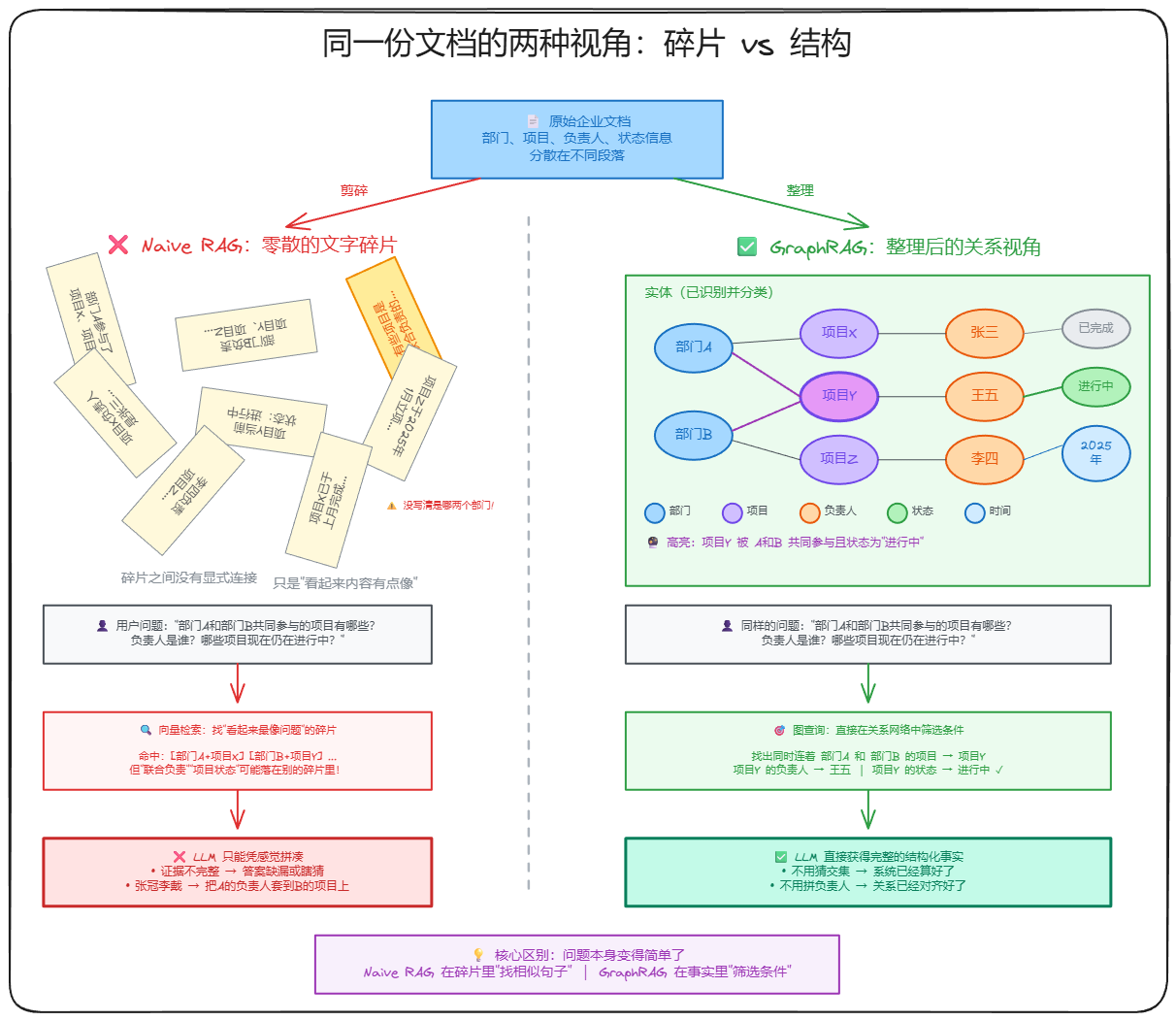
为了解决这个问题,GraphRAG 应运而生。它将文档解析为 实体-关系-实体 的图谱。然而,目前的开源 GraphRAG 方案往往成本极高。以处理 3.2 万字的小说为例,用 GPT-4 构建图谱可能耗费 6-7 美金。
我们要做的,是利用 Agent 的决策能力,配合轻量级的结构化提取工具,打造平替版但更高性能的 Agentic-GraphRAG。
二、 数据基础:为 Agentic-GraphRAG 打好底座
在垂直领域,数据质量决定了一切。如果你的 RAG 系统连复杂的 PDF 表格和公式都读不懂,后面的 Agent 再聪明也没用。
1. OCR 文档解析
目前企业级最优选是 MinerU 或 PaddleOCR-VL。
- MinerU:上海人工智能实验室开源,强项在于将 PDF 转换为保留层级结构的 Markdown。
- PaddleOCR-VL:百度出品,通过布局分析(PP-DocLayoutV2)和元素识别(PaddleOCR-VL-0.9B)的解耦,实现了 A100 上 1.22 页/秒的高速解析。

2. LangExtract 信息抽取
很多人问:我直接写 Prompt 让 LLM 提取不行吗?
不行。纯 Prompt 提取存在三大死穴:输出格式不可控、容易遗漏细节、无法溯源。
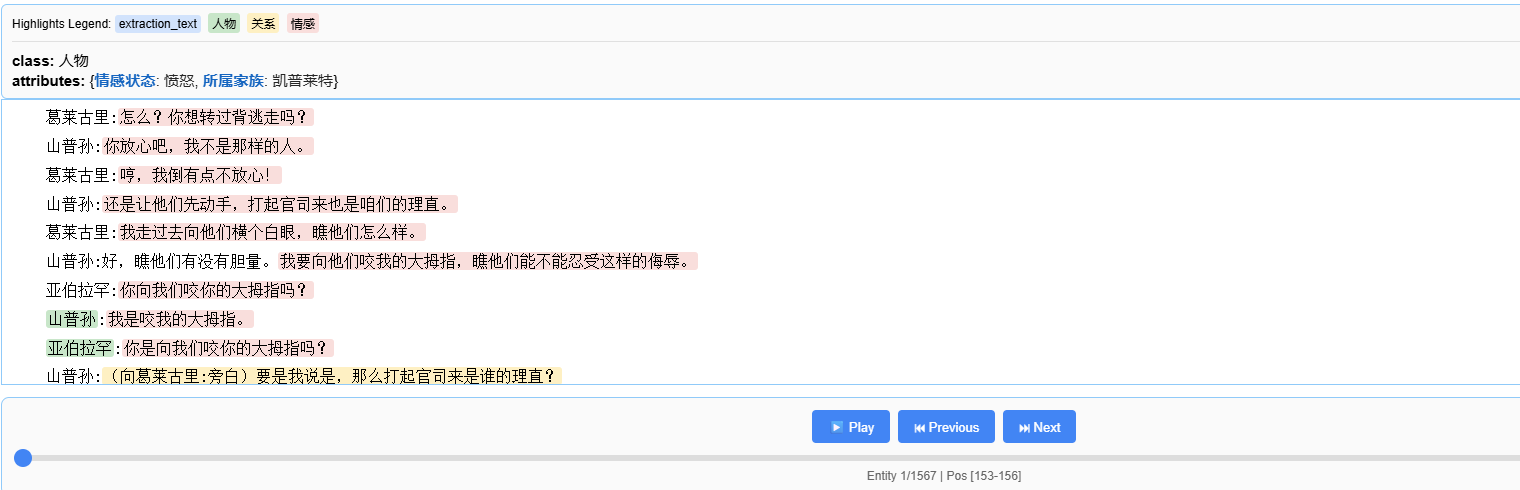
Google 开源的 LangExtract 是这一架构中的秘密武器。它的核心能力是:
- 零代码定义任务:用自然语言描述提取类别。
- 精确来源定位:每个提取出的实体都会自动标注在原文中的起始字符偏移量。
- 多轮扫描:针对长文档,它能像漏斗一样多轮过滤,确保不会遗漏任何细节。
- 结构化输出:会利用模型原生的 schema 约束功能,强制要求输出必须符合预定义的 JSON Schema,方便后续处理。
有了干净的结构化数据和精准的知识提取,接下来就是如何利用这些数据构建智能检索系统。传统的 RAG 面对复杂推理问题时往往力不从心,我们需要将 Agent 的决策能力、知识图谱的关联能力与向量检索的语义能力深度融合,才能真正释放数据的潜力。
三、 Agentic-GraphRAG 核心架构:Agent + 知识图谱 + RAG
这套架构通过 Agent 智能决策 + 知识图谱关联推理 + 向量检索语义匹配 的深度协同,将传统死板的检索升级为多维动态的智能问答系统。
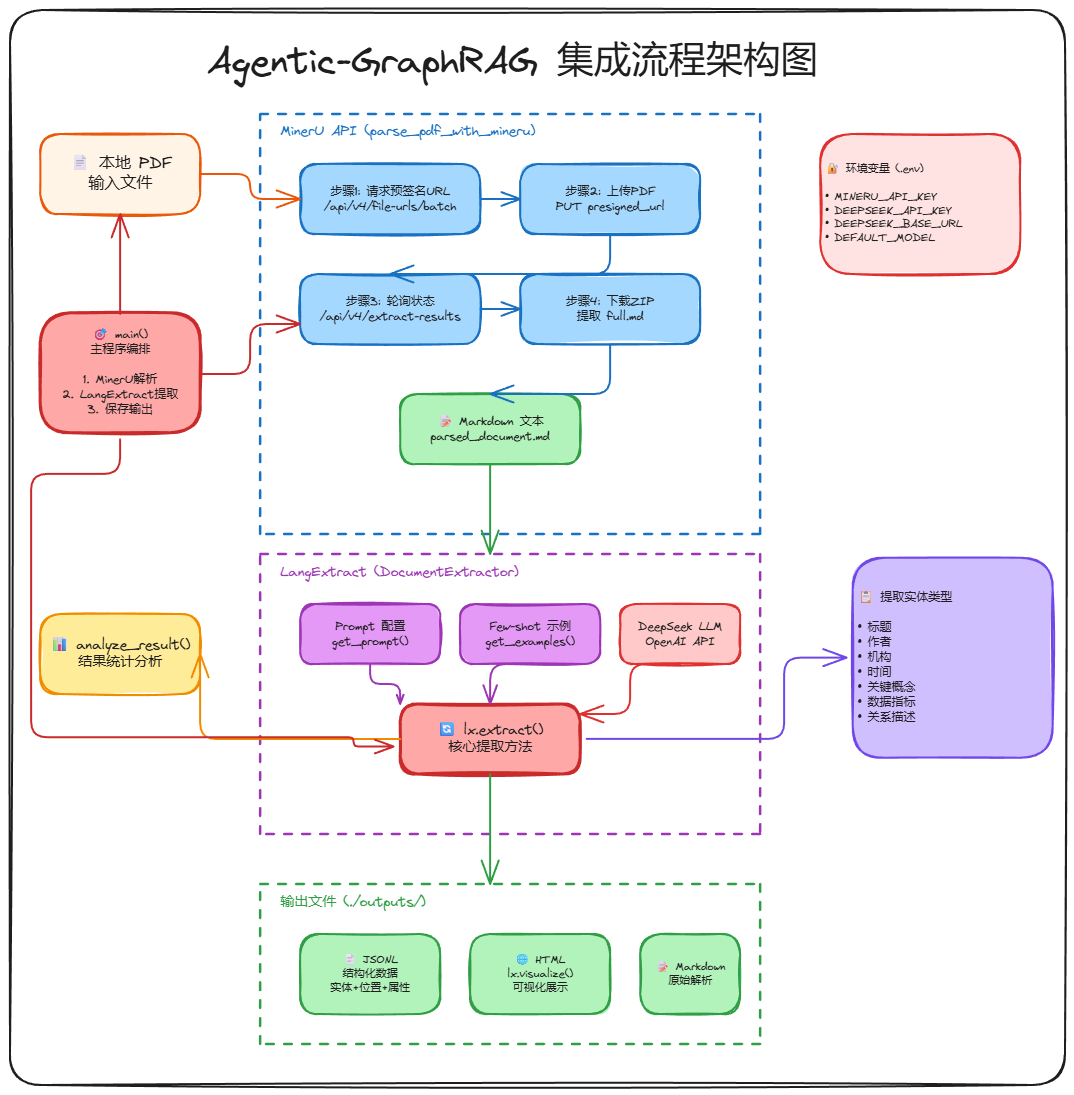
1. 三大检索工具
通过这三大检索工具,实现 Agent 动态决策的多维检索体系:
- Vector Search Tool:负责语义相似度检索,找有关联的答案。
- Graph Search Tool:负责在知识图谱中按图索骥,找有关系的实体。
- Hybrid Search Tool:混合检索,处理最复杂的推理。
2. 决策大脑
我们基于 LangChain 1.1 构建 Agent 决策链。当用户提问:民间借贷的利率上限是多少?时,Agent 的思考路径如下:
- 识别意图:这是一个需要法律条文精确数值的问题。
- 调用混合检索:先通过向量检索锁定《民法典》相关章节。
- 图谱补全:发现"借贷利率"与"LPR(贷款市场报价利率)"存在关联关系。
- 汇总输出:整合两方信息,给出准确答案。
💡 想深入学习 AI Agent 与 RAG 技术?
如果你对 AI Agent 开发 、RAG 系统 、知识图谱 、大模型微调 、企业项目实战 等前沿技术感兴趣,欢迎关注我们!
我们提供系统的课程体系,帮助你从零开始掌握:
- AI Agent 开发:深入理解 Agent 架构与实战,打造智能体应用
- RAG 技术:构建高性能的企业级知识库问答系统
- 大模型微调:掌握 Fine-tuning 技术,打造专属垂直领域模型
- 企业项目实战:15+ 项目实战(多模态RAG、实时语音助手、文档审核、智能客服系统等),将理论知识应用到实际项目中,解决真实业务问题
立即加入👉 赋范空间,开启你的 AI 进阶之旅!
四、 实战演练:构建带溯源能力的问答系统
实战步骤一:PDF解析
使用MinerU API将PDF转换为结构化Markdown:
python
# 步骤1:请求上传URL
response = requests.post(
"https://mineru.net/api/v4/file-urls/batch",
headers={"Authorization": f"Bearer {API_KEY}"},
json={
"files": [{"name": "document.pdf"}],
"model_version": "vlm" # 使用视觉语言模型
}
)
upload_url = response.json()["data"]["file_urls"][0]
# 步骤2:上传PDF
with open("document.pdf", "rb") as f:
requests.put(upload_url, data=f.read())
# 步骤3:轮询等待解析
while True:
status = requests.get(
f"https://mineru.net/api/v4/extract-results/batch/{batch_id}",
headers={"Authorization": f"Bearer {API_KEY}"}
).json()
if status["data"]["extract_result"][0]["state"] == "done":
break
time.sleep(3)
# 步骤4:下载Markdown
markdown_text = extract_markdown_from_zip(status["data"]["extract_result"][0]["full_zip_url"])输出示例:
markdown
# 民间借贷司法解释
## 第一条
借贷双方约定的利率未超过年利率24%,出借人请求借款人按照约定的利率支付利息的,人民法院应予支持。
...实战步骤二:知识提取(带溯源)
使用LangExtract提取结构化知识:
python
import langextract as lx
# 定义提取任务
extraction_prompt = """
从文档中提取以下结构化知识:
- 实体: 人物、机构、地点、时间、概念、技术术语
- 数据指标: 数值、百分比、统计数据
- 关系描述: 实体之间的关系(合作、隶属、引用等)
- 事件: 重要事件和行为
要求:
1. extraction_text 必须是原文的精确子串
2. 为每个提取添加丰富的属性信息
3. 关系类型必须在 attributes 中标注涉及的主体
"""
# 定义Few-shot示例
examples = [
lx.data.ExampleData(
text="利率未超过年利率24%,人民法院应予支持。",
extractions=[
lx.data.Extraction(
extraction_class="数据指标",
extraction_text="年利率24%",
attributes={"指标": "利率上限", "类型": "阈值"}
),
lx.data.Extraction(
extraction_class="实体",
extraction_text="人民法院",
attributes={"类型": "机构", "角色": "司法机构"}
)
]
)
]
# 执行提取
result = lx.extract(
text_or_documents=markdown_text,
prompt_description=extraction_prompt,
examples=examples,
model=langextract_model,
extraction_passes=3, # 多轮提取提高召回率
max_workers=20, # 并行处理加速
max_char_buffer=1000 # 分块大小
)
# 每个提取结果都包含精确的原文位置
for ext in result.extractions:
print(f"[{ext.extraction_class}] {ext.extraction_text}")
print(f" 位置: {ext.char_interval.start_pos}-{ext.char_interval.end_pos}")
print(f" 属性: {ext.attributes}")输出示例:
[数据指标] 年利率24%
位置: 1234-1240
属性: {'指标': '利率上限', '类型': '阈值'}
[实体] 人民法院
位置: 1245-1250
属性: {'类型': '机构', '角色': '司法机构'}溯源验证:
python
# 验证:从Markdown中提取对应位置的文本
original_text = markdown_text[1234:1240]
assert original_text == "年利率24%" # ✓ 验证通过实战步骤三:向量存储与知识图谱构建
向量存储(保留溯源信息)
python
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
import uuid
# 初始化
embeddings = OpenAIEmbeddings(model="text-embedding-v4")
vectorstore = Chroma(
collection_name="legal_knowledge",
embedding_function=embeddings
)
# 存储提取结果(关键:在metadata中保存溯源信息)
texts = []
metadatas = []
ids = []
for ext in extractions:
texts.append(ext.to_searchable_text())
metadatas.append({
"doc_id": ext.doc_id,
"extraction_class": ext.extraction_class,
"extraction_text": ext.extraction_text,
"char_interval": json.dumps(ext.char_interval), # ← 溯源关键
"attributes": json.dumps(ext.attributes)
})
ids.append(str(uuid.uuid4()))
vectorstore.add_texts(texts=texts, metadatas=metadatas, ids=ids)知识图谱构建
python
knowledge_graph = {
"entities": {},
"relations": []
}
for ext in extractions:
if ext.extraction_class == "关系描述":
# 提取关系
knowledge_graph["relations"].append({
"text": ext.extraction_text,
"type": ext.attributes.get("类型"),
"subject": ext.attributes.get("主体1"),
"object": ext.attributes.get("主体2"),
"source": ext.doc_id
})
elif ext.extraction_class in ["实体", "数据指标"]:
# 提取实体(保留溯源信息)
entity_name = ext.extraction_text
if entity_name not in knowledge_graph["entities"]:
knowledge_graph["entities"][entity_name] = {
"type": ext.extraction_class,
"attributes": ext.attributes,
"mentions": [] # 存储所有提及位置
}
# 添加提及位置
knowledge_graph["entities"][entity_name]["mentions"].append({
"source": ext.doc_id,
"position": ext.char_interval # ← 溯源关键
})实战步骤四:构建智能Agent
定义检索工具
python
from langchain.tools import tool
# 工具1:向量语义检索
@tool
def vector_search_tool(query: str) -> str:
"""向量语义检索:根据问题搜索相关知识片段"""
results = vectorstore.similarity_search_with_score(query, k=5)
output = []
for doc, score in results:
char_interval = json.loads(doc.metadata.get("char_interval", "{}"))
output.append(f"""
[向量检索] 相似度: {1/(1+score):.2f}
内容: {doc.metadata['extraction_text']}
位置: 字符 {char_interval['start_pos']}-{char_interval['end_pos']}
来源: {doc.metadata['doc_id']}
""")
return "\n".join(output)
# 工具2:知识图谱检索
@tool
def graph_search_tool(entity: str) -> str:
"""知识图谱检索:根据实体名称查找相关实体和关系"""
# 查找实体
matched_entities = [e for e in knowledge_graph["entities"] if entity in e]
# 查找关系
relations = []
for rel in knowledge_graph["relations"]:
if entity in str(rel.get("subject", "")) or entity in str(rel.get("object", "")):
relations.append(rel)
return f"匹配实体: {matched_entities}\n相关关系: {relations}"
# 工具3:混合检索
@tool
def hybrid_search_tool(query: str) -> str:
"""混合检索:同时进行向量检索和图谱检索"""
vector_result = vector_search_tool.invoke(query)
graph_result = graph_search_tool.invoke(query.split()[0])
return f"=== 向量检索 ===\n{vector_result}\n\n=== 图谱检索 ===\n{graph_result}"创建Agent
python
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="deepseek-chat", temperature=0.3)
agent = create_agent(
model=llm,
tools=[vector_search_tool, graph_search_tool, hybrid_search_tool],
system_prompt="""
你是一个知识图谱问答助手。你有以下工具:
1. vector_search_tool - 向量语义检索
2. graph_search_tool - 知识图谱检索
3. hybrid_search_tool - 混合检索
回答策略:
- 简单查询:用 vector_search_tool
- 关系查询:用 graph_search_tool
- 复杂推理:用 hybrid_search_tool
重要:回答时必须标注信息来源和原文位置!
"""
)实战步骤五:问答与溯源
python
def agent_query(question: str):
# 调用Agent
result = agent.invoke({"messages": [HumanMessage(content=question)]})
answer = result["messages"][-1].content
# 提取工具调用记录(溯源证据)
evidence = []
for msg in result["messages"]:
if hasattr(msg, "tool_calls") and msg.tool_calls:
for tc in msg.tool_calls:
evidence.append({
"tool": tc["name"],
"args": tc["args"],
"result": get_tool_result(tc["id"])
})
return {
"question": question,
"answer": answer,
"evidence": evidence # ← 溯源链路
}
# 测试
result = agent_query("民间借贷的利率上限是多少?")
print(f"问题: {result['question']}")
print(f"回答: {result['answer']}")
print(f"溯源: {result['evidence']}")输出示例:
问题: 民间借贷的利率上限是多少?
回答: 根据司法解释,民间借贷的利率上限为年利率24%。
该信息来自 document.pdf,字符位置 1234-1240。
溯源:
- 工具: vector_search_tool
- 检索结果: [数据指标] 年利率24%
位置: 字符 1234-1240
来源: document.pdf五、 为什么这套方案能省下 90% 的成本?
- 按需提取:我们不需要像微软 GraphRAG 那样一次性把整个图谱全量构建(索引成本高昂),而是通过 LangExtract 的轻量化策略进行增量更新。
- Agent 剪枝:Agent 在决策时,只有复杂问题才会触发高成本的图检索,简单问题直接走向量库。
- 端到端国产适配:这套方案与模型无关,可以适配国产模型,避开昂贵的海外 API 调用。
六、 结语:从实验室走向生产
RAG 的下半场,拼的不是谁的模型参数大,而是谁数据处理的更干净、谁检索链路更智能。Agentic-GraphRAG 通过 OCR 结构化 + LangExtract 精准抽取 + Agent 动态决策 三部曲,为企业提供了一个高性价比、可落地的选择。
如果你正在为医疗病历分析、法律合规审核或海量财报分析发愁,这套方案或许就是你要找的那个最优解。
🚀 掌握 AI Agent + RAG 核心技术,成为稀缺的 AI 应用工程师
垂直领域的 AI 应用正在爆发式增长,掌握 Agentic-GraphRAG 这类前沿架构的开发者将成为企业争抢的核心人才。
在我们的课程中,你将学到:
- 企业级 RAG 架构设计:从基础向量检索到高级 GraphRAG 的完整演进路径
- Agent 智能决策系统:构建能够自主选择工具、多步推理的智能体
- 知识图谱实战:掌握实体抽取、关系建模、图谱存储的全流程
- 生产级项目经验:医疗问答、法律助手、财报分析等真实案例,带源码交付
不要让技术停留在 Demo 阶段,让我们一起将 AI 落地到生产环境!
👉 点击加入 赋范空间,开启 AI 进阶之旅!!