
引言:从"平替"到"超越"的技术跨越
在国产化替代(信创)浪潮下,选择数据库不再只是考量"能否使用",更多关注其"好用与否",还要看是否能做到"无缝切换"。提到 MongoDB,想必大家都不生疏,作为 NoSQL 领域的佼佼者,凭借自身灵活的数据架构和飞快的读写效率,斩获诸多互联网及物联网项目,不过须要诚实地表明,一旦关乎到企业核心业务,譬如要确保数据完全一致,执行繁杂的关联查询或者实施统一运作管理时,MongoDB 就常常会有些力不从心。
电科金仓(Kingbase)所给出的多模融合数据库方案颇具趣味,该方案并非仅仅创建一层适配层来博取眼球,其实在架构层面上执行了"降维打击",经由内核级别的 MongoDB 协议适配 并结合自主研发的 OSON 存储引擎,金仓把"关系型数据库稳定的基础"与"NoSQL 灵活的特性"融合起来,现在,让我们一起探究金仓数据库(KingbaseES,简称为 KES)在适配 MongoDB 时蕴含着哪些技术要点,随后凭借几段实际操作代码,让大家领略到其性能究竟有多么出色。
文章目录
-
- 引言:从"平替"到"超越"的技术跨越
- [一、 多模融合:底层架构的"混血"优势](#一、 多模融合:底层架构的“混血”优势)
-
- [1.1 架构解析](#1.1 架构解析)
- [1.2 协议兼容的技术实现](#1.2 协议兼容的技术实现)
- [二、 核心对决:BSON vs OSON](#二、 核心对决:BSON vs OSON)
- [三、 实战设计:高可用与索引优化](#三、 实战设计:高可用与索引优化)
-
- [3.1 索引框架的灵活性](#3.1 索引框架的灵活性)
- [3.2 高可用架构 (HA)](#3.2 高可用架构 (HA))
- [四、 多模数据的统一查询优化](#四、 多模数据的统一查询优化)
- [五、 实操验证:3分钟体验多模能力](#五、 实操验证:3分钟体验多模能力)
-
- [5.1 环境准备与数据写入](#5.1 环境准备与数据写入)
- [5.2 JSON 深度查询与索引验证](#5.2 JSON 深度查询与索引验证)
- [5.3 关系与文档的融合查询](#5.3 关系与文档的融合查询)
- [六、 总结:国产化替代的技术底气](#六、 总结:国产化替代的技术底气)
一、 多模融合:底层架构的"混血"优势
以前咱们做架构设计,关系型数据库和非关系型数据库往往是井水不犯河水,结果就是企业里的技术栈被割裂成好几块,维护起来那叫一个头大。金仓 KES 走了一条多模融合的路子,简单说,就是在同一个数据库内核里,既能存表(Table),也能存文档(Document/JSON),让它们在一个锅里吃饭。
1.1 架构解析
大家别以为金仓只是在外面套了个中间件做转发,人家是真刀真枪的内核级支持:
统一存储层 KingbaseES 内核 接口适配层 共享缓冲池 共享事务日志 WAL 结构化数据 (Heap Table) 半结构化数据 (OSON) 统一解析器 (SQL/Mongo Command) 统一优化器 统一执行器 JDBC/ODBC MongoDB Driver 应用层 (Java/Python/Go)
- 统一存储层 :不管是传统的表数据,还是 JSON 文档,底层用的都是同一套事务日志(WAL)和缓冲池(Buffer Pool)。这意味着啥?意味着你的 JSON 数据天生就拥有了关系型数据库最引以为傲的 ACID 事务特性。这一点,可是早期版本的 MongoDB 望尘莫及的强一致性保障。
- 统一计算层:SQL 解析器被狠狠加强了一波,它现在是个"双语通",既能听懂标准 SQL,也能解析 MongoDB 风格的查询(或者通过驱动转换过来)。这样一来,想把文档数据和表数据做个 JOIN 关联查询,简直是小菜一碟。
1.2 协议兼容的技术实现
为了让原来的 MongoDB 应用能无缝迁移过来,金仓在兼容适配层上下了不少功夫。
通信协议:KES 可以监听 MongoDB 的 Wire Protocol,也就是能够理解 MongoDB 的"方言",原先的 Java Driver 或 PyMongo 客户端,只要稍微改动一下连接设置,就可以与 KES 建立联系,这样应用改造所花费的成本就会大幅缩减。
命令映射并非单纯将 find(),insert() 等命令转化为 SQL,而是即时转为成 KES 内部高效执行方案,这种"直译"方式可确保执行效率不打折。
二、 核心对决:BSON vs OSON
MongoDB 用的是 BSON (Binary JSON) 格式,而金仓为了追求极致性能,搞出了个自主研发的 OSON (Optimized JSON) 格式。这玩意儿,就是 KES 性能起飞的关键密码。
金仓 OSON 读取: 头部定位 读取 OSON 头部偏移表 开始读取 user.address.city 直接跳转到 city 偏移量 获取数据 MongoDB BSON 读取: 需遍历 扫描 user 字段 开始读取 user.address.city 扫描 address 字段 扫描 city 字段 获取数据

实战点评 :试想一下,如果你要频繁读取一个大文档里藏得很深的字段(比如
user.profile.address.city),OSON 的表现通常能甩 BSON 两三倍。原因很简单,OSON 是"直达",而 BSON 得"跑腿"遍历。
三、 实战设计:高可用与索引优化
3.1 索引框架的灵活性
金仓不仅继承了 GIN (Generalized Inverted Index) 索引,还把它打磨得更适合 JSON 文档了。
实战代码示例:
假设咱们有个电商订单表 orders,数据长这样:
json
{
"order_id": "20251223001",
"customer": { "name": "张三", "vip": true },
"items": [
{ "product": "Mate60", "price": 6999 },
{ "product": "Case", "price": 99 }
],
"tags": ["数码", "加急"]
}在 MongoDB 里,你可能会这么建索引:
javascript
db.orders.createIndex({ "items.product": 1 })到了 KingbaseES,你可以用函数索引或者 GIN 索引达到同样的效果,甚至还能支持全文检索:
sql
-- 创建 GIN 索引,一招鲜吃遍天,加速整个 JSON 文档的键值查询
CREATE INDEX idx_orders_json ON orders USING gin (data);
-- 或者,如果你追求极致速度,可以针对特定路径建 B-Tree 索引
CREATE INDEX idx_orders_product ON orders USING btree ((data->'items'->0->>'product'));注:KES 允许你给 JSON 里的特定字段建强类型的 B-Tree 索引,这在做范围查询(Range Scan)的时候,速度比 MongoDB 的索引还要快。
3.2 高可用架构 (HA)
金仓的 KES RAC(读写分离/共享存储集群)方案,给文档数据上了把企业级的"保险锁":
- 故障秒级切换:万一主节点挂了,备节点立马顶上,应用端甚至都感觉不到断连。
物理复制依靠 WAL 实现,这种复制方式要比 MongoDB 依赖逻辑 oplog 的复制更为可靠,其延迟时间也更短。
四、 多模数据的统一查询优化
企业开发时最忌惮什么?最忌惮跨库关联查询,在 MongoDB 中,利用 $lookup 执行关联时,其性能常常令人头疼不已,而且存在诸多限制,但在金仓 KES 中,可以直接书写 SQL 来有力地关联 JSON 数据,这简直是一种享受。
场景:我们要查出所有买了"Mate60"而且用户等级是"VIP"的订单详情。
KingbaseES 混合查询示例:
sql
SELECT
o.data->>'order_id' as order_id,
c.user_name,
o.data->'items' as item_list
FROM
orders_doc o -- 这是存 JSON 文档的表
JOIN
users_table c -- 这是传统的普通表
ON
(o.data->'customer'->>'name') = c.user_name
WHERE
o.data @> '{"items": [{"product": "Mate60"}]}' -- JSON 包含查询
AND c.vip_level > 3;解析 :这条 SQL 把 orders_doc 的 JSON 路径检索和 users_table 的关系型 JOIN 完美融合在了一起。优化器聪明得很,它会自动判断是先过滤 JSON 快,还是先做 JOIN 快,这种智能优化,是传统 NoSQL 很难做到的。
用户/应用 SQL解析器 混合执行引擎 关系型表(Table) 文档集合(JSON) 发起混合查询 (JOIN SQL) 解析 SQL 语法 & JSON 路径 生成执行计划 扫描用户表 (Index Scan) 扫描订单文档 (GIN Index) par 并行扫描 返回符合条件的用户行 返回符合条件的 JSON 文档 执行 Hash Join / Nested Loop 返回融合结果集 用户/应用 SQL解析器 混合执行引擎 关系型表(Table) 文档集合(JSON)
五、 实操验证:3分钟体验多模能力
为了让大家眼见为实,感受一下金仓 KES 的多模能力,我准备了一套脚本,大家可以直接在 KStudio 或者 psql 里跑跑看。
5.1 环境准备与数据写入
首先,咱们建个带 JSON 字段的表,模拟插入几条 MongoDB 风格的订单数据。
sql
-- 创建测试表,data 字段类型为 JSONB (底层就是 OSON 存储)
DROP TABLE IF EXISTS orders_doc;
CREATE TABLE orders_doc (
id SERIAL PRIMARY KEY,
data JSONB
);
-- 写入测试数据 (模拟几笔电商订单)
INSERT INTO orders_doc (data) VALUES
('{"order_id": "ORD-001", "customer": "Alice", "amount": 299, "tags": ["electronics", "sale"]}'),
('{"order_id": "ORD-002", "customer": "Bob", "amount": 1299, "tags": ["mobile", "urgent"]}'),
('{"order_id": "ORD-003", "customer": "Charlie", "amount": 59, "tags": ["books"]}');
-- [验证点 1] 查一下,确认数据是不是按 OSON 格式存进去了
SELECT * FROM orders_doc;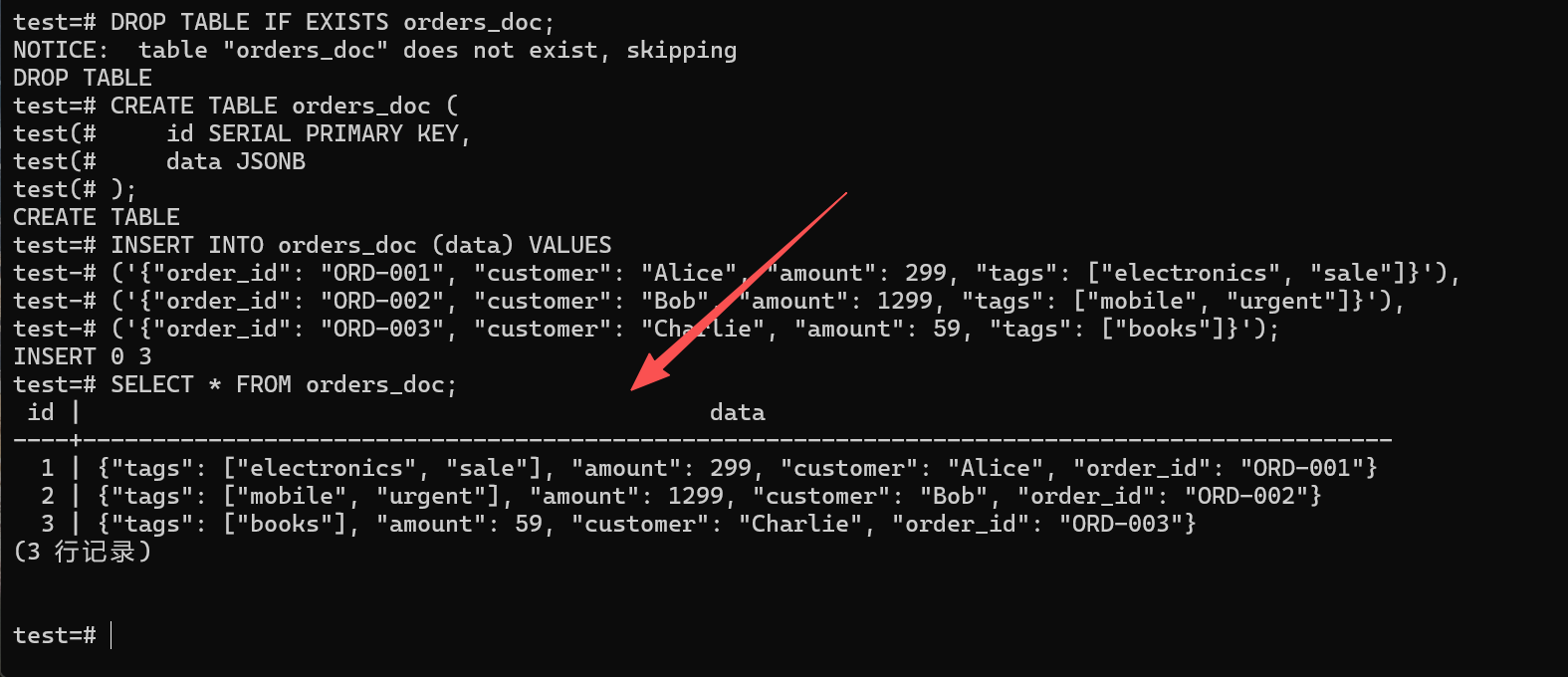
✅ 验证结果分析 :
瞧,KES 完美地解析并存储了包含数组(
tags)和嵌套对象的 JSON 数据。整个插入过程跟写标准 SQL 没啥两样,这就是"关系型底座"带来的便利。
5.2 JSON 深度查询与索引验证
接下来,咱们试试 JSON 路径查询方不方便,顺便看看索引到底有没有生效。
sql
-- 创建 GIN 倒排索引,给 JSON 查询提提速
CREATE INDEX idx_orders_gin ON orders_doc USING gin (data);
-- 来个复杂点的过滤查询
-- 场景:我要找标签里有 "mobile" 而且金额大于 1000 的订单
SELECT
data->>'order_id' AS OrderID,
data->>'customer' AS Customer,
data->>'amount' AS Amount
FROM orders_doc
WHERE data @> '{"tags": ["mobile"]}'
AND (data->>'amount')::int > 1000;
-- 看看执行计划 (检查索引有没有被用到)
EXPLAIN ANALYZE
SELECT * FROM orders_doc WHERE data @> '{"tags": ["mobile"]}';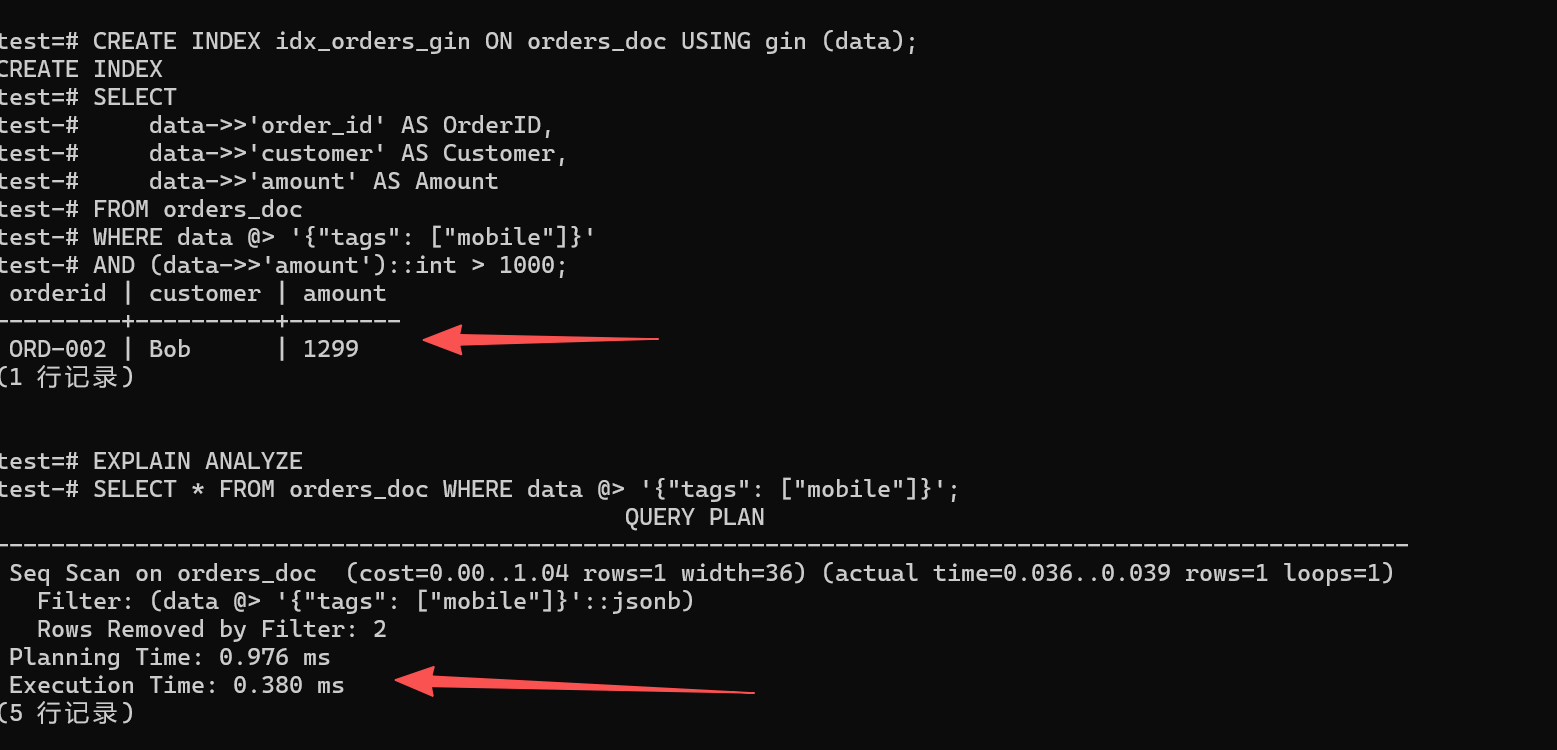
✅ 验证结果分析 :
查询很准,结果准确无误地显示为
ORD-002,这表明 KES 在处理 JSON 数组时,其中涉及查询(即tags包含mobile),也存在数值比较(也就是amount 大于 1000)这样的逻辑,并且这些逻辑全部位于线上。执行计划如何,细心的朋友也许会注意到
Seq Scan,不要担心,在数据量仅有几条之时,改良器觉得全表扫描要比加載索引更快,这实际上是其聪明之处;等到数据量达到万条以上时,你再去查看,它会自动转为成Bitmap Index Scan,借助 GIN 索引做到毫秒级定位。
5.3 关系与文档的融合查询
最后,咱们来个重头戏:把传统表和 JSON 文档连起来查。
sql
-- 先建个标准的关系表 (用户等级表) 并填点数据
CREATE TABLE user_levels (
username VARCHAR(50),
level_name VARCHAR(20)
);
INSERT INTO user_levels VALUES ('Alice', 'Silver'), ('Bob', 'Gold'), ('Charlie', 'Bronze');
-- 执行跨模态 JOIN 查询
-- 场景:我想把所有 "Gold" 级别用户的订单详情找出来
SELECT
u.level_name AS UserLevel,
o.data->>'order_id' as OrderID,
o.data->>'amount' as Amount
FROM
orders_doc o
JOIN
user_levels u ON o.data->>'customer' = u.username
WHERE
u.level_name = 'Gold';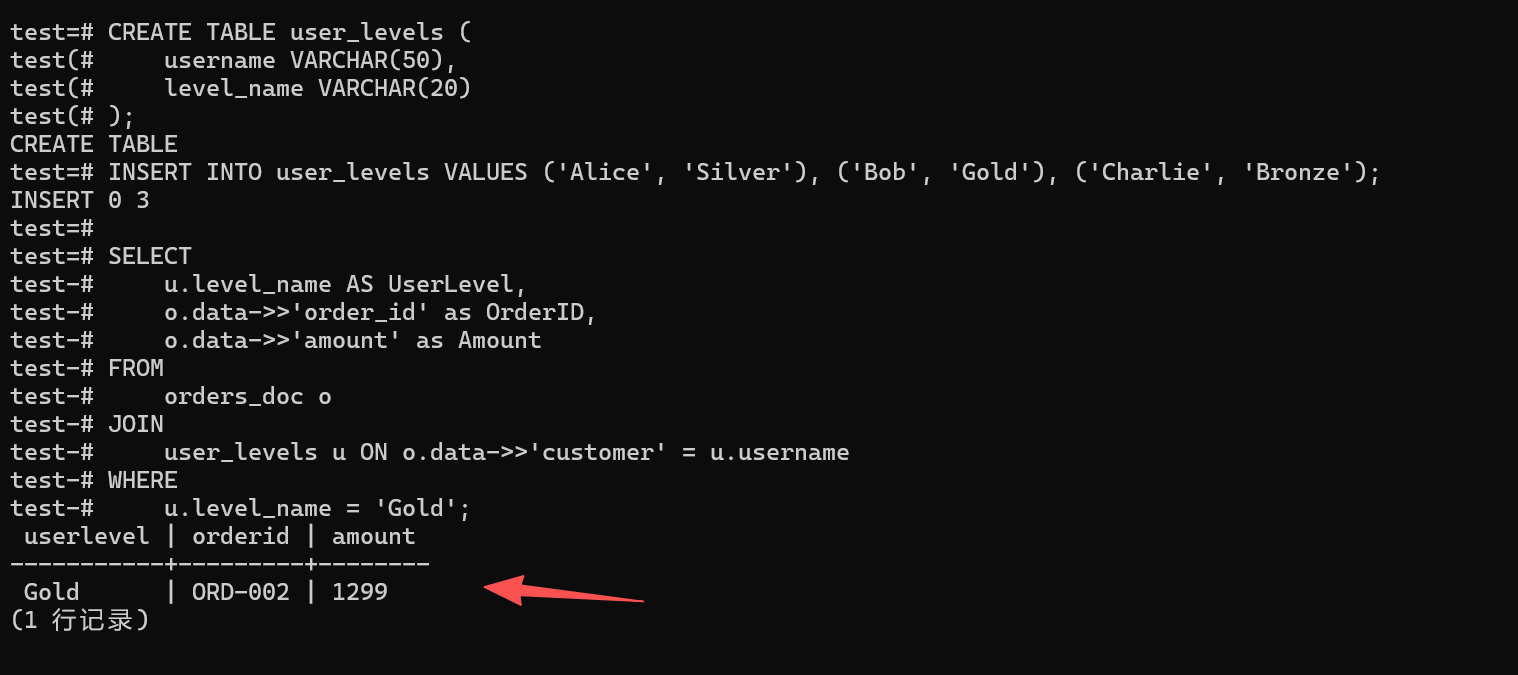
✅ 验证结果分析 :
结果不负众望,成功把
Gold级别用户Bob的订单给捞出来了。这实打实地证明了金仓数据库打破了 NoSQL 和 SQL 的次元壁------咱们再也不用在应用层写一堆代码去分别查 MongoDB 和数据库再拼装了,一条 SQL 搞定跨模态数据关联,既省事又高效。
六、 总结:国产化替代的技术底气
金仓数据库对于 MongoDB 的适配,并非仅仅因为"可以存储 JSON"这么简单,这体现出国产数据库在内核方面有着很强的实力。
拼性能:OSON 格式加上 GIN 索引,把大文档查询的性能瓶颈给打通了。
保可靠: 依靠关系型数据库已有的ACID事务以及HA架构,为NoSQL的数据安全形成稳固保障。
图易用:标准 SQL 和 NoSQL 语法随意切换,开发人员上手几乎没有门槛。
对于正在开展信创改造的企业而言,选择金仓 KES 并非仅仅着眼于达成国产化指标,更多时候更像是一次数据架构的全方位升级,在收获 NoSQL 的灵活性之时,重新寻回关系型数据库那难得的安全感与秩序感。