1. 什么是"图像识别"?
识别不仅仅是给图片打个标签,它包含多个层级的任务:
- 单目标分类:这是什么?(例如:那是一盏灯吗?)
- 目标检测:它在哪里?(例如:哪里有人?)
- 验证:是特定的那个吗?(例如:那是布达拉宫吗?)
- 场景分类:这是什么地方?(例如:户外、城市)
- 事件理解:发生了什么?(例如:这些人在做什么?)
2. 识别面临的巨大挑战
为什么识别很难?课件列举了一系列干扰因素:
- 类内差异大:同一种物体(如椅子)形态各异。
- 视角变化、光照变化、尺度变化、形变、遮挡。
- 背景干扰。
- 细粒度分类:例如区分不同种类的鸟。
- 少样本学习:如何仅从少量例子中归纳出规律。
3. 识别的关键环节
图像识别的核心流程通常包含两个关键步骤,:
- 特征表示 (Feature Representation):
- 人工设计特征:梯度、边缘、色彩直方图、HOG、SIFT 等。
- 深度学习特征:通过神经网络自动学习到的特征。
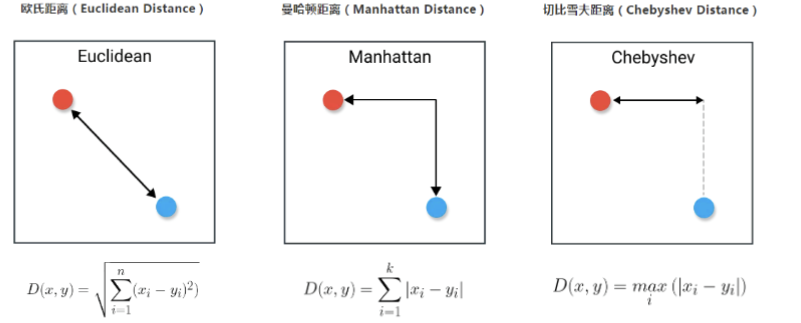
- 相似度/距离度量 (Similarity/Distance):
- 人工设计距离:欧式距离、曼哈顿距离、余弦距离等。
- 学习得到的度量 :通过深度学习获得的相似度度量。

4. 前沿案例:行人重识别 (Person Re-ID)
课件详细介绍了一个具体的难点任务:行人重识别。即在跨摄像头的监控网络中,自动匹配同一个行人。
- 核心难点:
- 类内差异 > 类间差异:同一个人在不同摄像头下(光照、角度不同)看起来差异很大;而不同的人在穿类似衣服时看起来很像。
- 关键技术:
- 特征变换:通过学习投影矩阵,让同一个人的特征距离变近,不同人的变远。
- 距离度量学习:针对不同外貌差异的行人学习不同的距离函数(如马氏距离)。
- 排序优化:利用正向和反向查询的一致性来优化初步的排序结果。
5. 基础分类器算法
在了解了识别的复杂性后,课件回归到了最基础的分类算法:
A. 最近邻分类器 (Nearest Neighbor)
- 原理:测试时,将图像与训练集中所有的图像进行比较,找到最相似(距离最近)的那张,直接复用它的标签。
- k-最近邻 (kNN):找最近的 k 个邻居进行投票。
B. 线性分类器 (Linear Classifier)
- 原理 :定义一个评分函数(Score Function),通常形式为 f(x,W)=Wx+bf(x, W) = Wx + bf(x,W)=Wx+b。
- 几何解释 :可以看作是在高维空间中学习一个超平面,将不同的类别划分开。
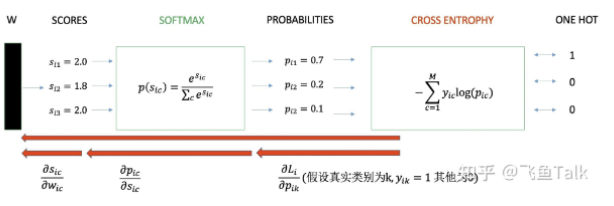
- 参数学习 :通过定义损失函数 (Loss Function) 来衡量分类器的好坏。
- Softmax / 交叉熵损失 (Cross-entropy Loss) :衡量实际输出概率与期望输出概率的距离,主要用于神经网络和 Softmax 分类器。
C. 支持向量机 (SVM)
- 课件简要提及了 SVM,它试图找到一个决策边界,使得分类间隔最大化,。
总结: 本课件作为识别部分的导论,强调了识别任务的核心在于**"特征"与"度量"**。虽然传统的最近邻和线性分类器提供了基础思路,但面对复杂的现实世界(如行人重识别中的光照、姿态变化),我们需要更强大的特征提取和度量学习方法,这也为接下来的深度学习(神经网络)课程做了铺垫。
1. 为什么要使用神经网络?
在上一讲(lec08)中我们学习了线性分类器。然而,线性分类器存在局限性:
- 非线性问题: 比如经典的 异或 (XOR) 问题,或者红蓝点无法用一条直线分开的情况,单层感知机(线性分类器)无法解决。
- 解决方案: 神经网络通过将线性函数连接在一起,并由非线性(激活)函数分隔,从而能够拟合复杂的非线性函数。这被称为"多层感知器" (MLP)。
2. 神经元与激活函数
A. 生物学启发
神经网络的设计灵感来源于生物神经元(树突接收输入,轴突输出信息,通过突触连接)。虽然现代神经网络与生物大脑有很大不同,但基本单元的概念是类似的。
B. 激活函数 (Activation Functions)
激活函数决定了神经元是否"被激活"。课件介绍了几种关键类型:
- Sigmoid/Tanh: 输出范围分别为 0 到 1 和 -1 到 1。缺点是存在梯度消失问题,且计算较慢(指数运算)。
- ReLU (Rectified Linear Unit): f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x)。计算速度快,解决了梯度消失问题,是目前最常用的。缺点是负区间梯度为零(Dead ReLU)。
- Leaky ReLU / ELU: 旨在解决 Dead ReLU 问题,在负区间给出一个很小的斜率或曲线。
3. 卷积神经网络 (CNN) ------ 视觉的核心
这是本课件的重点。为什么不用全连接层处理图像?
- 全连接层 (FC) 的问题: 它将图像拉伸成一维向量(例如 32×32×3→3072×132 \times 32 \times 3 \rightarrow 3072 \times 132×32×3→3072×1),这不仅参数量巨大,而且破坏了图像的空间结构。
A. 卷积层 (Convolution Layer)
- 机制: 保持图像的 3D 结构(宽、高、通道)。使用小的滤波器(Filter/Kernel)在图像上滑动并计算点积。
- 参数共享: 相比全连接层,卷积层通过在不同位置共享同一个卷积核,大大减少了参数数量。
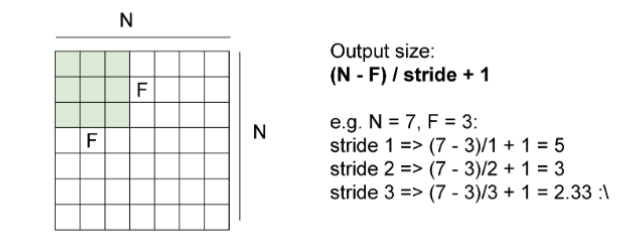
- 填充 (Padding): 为了控制输出尺寸,常用的模式有 Full (尺寸变大)、Same (尺寸不变,补0)、Valid(不补0,尺寸变小)。
- 步长:
0填充(保持卷积前后尺寸不变)
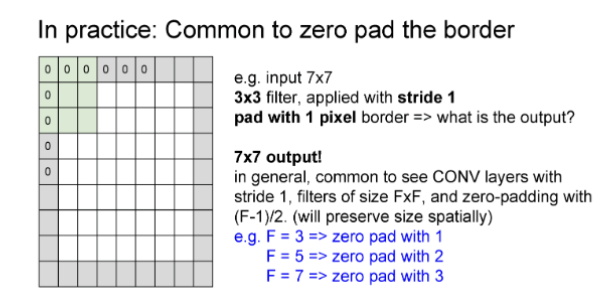
输出尺寸=(N+2P)−FS+1\text{输出尺寸} = \frac{(N + 2P) - F}{S} + 1输出尺寸=S(N+2P)−F+1
由于保持前后尺寸不变 所以这里 输出尺寸=N\text{输出尺寸} =N输出尺寸=N
由此可以解出所需填充的层数 PPP
FFF为卷积核大小,SSS为步长
B. 池化层 (Pooling Layer)
- 作用: 进行下采样,减小特征图尺寸,从而减少计算量并提高感受野。
C. 归一化层 (Normalization)
- Batch Normalization (BN): 对批次内的数据进行标准化。它能让模型中间层的输入分布稳定,加快收敛速度,并提升抗干扰能力。
4. 经典网络架构与演进
A. LeNet
早期的经典网络,使用 5×55 \times 55×5 卷积核和 Sigmoid/Tanh 激活函数。虽然结构完整(卷积+池化+全连接),但不足以拟合复杂的 CIFAR-10 等任务,。
B. 卷积核的演变:越小越好?
早期网络(如 AlexNet)使用 11×1111 \times 1111×11 或 5×55 \times 55×5 的大卷积核。
- VGG 的洞察: 后来的网络倾向于使用堆叠的 3×33 \times 33×3 小卷积核。
- 原因: 两个 3×33 \times 33×3 卷积核的感受野等于一个 5×55 \times 55×5 卷积核,但参数量更少 (3×3×2+1<5×5×1+13 \times 3 \times 2 + 1 < 5 \times 5 \times 1 + 13×3×2+1<5×5×1+1),且增加了非线性变换能力。
5. 如何训练?(优化器与梯度)
A. 梯度计算
- 数值梯度: 近似计算,慢,但易于实现(用于检验)。
- 解析梯度: 利用导数公式精确计算,快,但容易出错(实际训练中使用)。
B. 优化器 (Optimizers)
为了让损失函数最小化,我们需要更新参数。课件介绍了一系列优化算法:
-
GD:Gradient descent 每次使用整个数据集计算损失后来更新参数,计算很慢,占用内存大且不能实时更新,优点是能够收敛到全局最小点,对异常数据不敏感
-
SGD (随机梯度下降): 每次随机取一个样本更新。缺点是容易震荡,容易陷入局部极小值。
-
SGDM (带动量的 SGD): 加入"惯性"(Momentum),像小球滚下山坡一样,不仅看当前梯度,还看之前的方向,能冲出局部极小值。

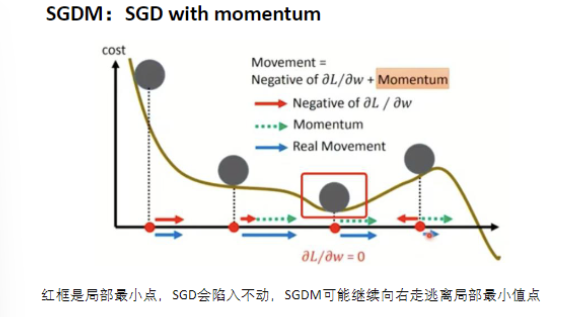
-
NAG :NAG可以理解为SDGM中添加了一个校正因子。在SDGM中小球会盲目地跟从下坡的梯度,容易发生错误。所以需要一个更聪明的小球,能提前知道它要去哪里,还要知道走到坡底的时候速度慢下来而不是又冲上另一个坡。

-
Adagrad / RMSprop: 自适应学习率算法。对更新频率低的参数给大步长,高的给小步长。

-
Adam: 结合了动量(一阶矩)和自适应学习率(二阶矩),是目前最常用的优化器之一。

6. 防止过拟合 (Overfitting)
当模型在训练集表现很好但在测试集表现差时,发生了过拟合。解决方案包括,:
- 增加数据量: 数据扩增(翻转、裁剪、生成虚拟数据)。
- 简化模型: 减少层数或参数。
- Early Stopping: 当验证集误差开始上升时提前停止训练。
- 正则化 (Regularization): L1/L2 正则化(惩罚大的权重)。
- Dropout: 训练时随机让一部分神经元"失活",强迫网络不依赖特定神经元,提高鲁棒性。
总结: 本课件详细解构了卷积神经网络的内部机制。我们从神经元出发,了解了卷积如何提取空间特征,小卷积核的优势,以及如何使用 Adam 等优化器和 Dropout 等策略来训练一个强大且泛化能力好的模型。
至此,我们已经掌握了识别分类的核心技术。接下来的挑战是:如果我们不仅想知道图里有"什么",还想知道它在"哪个像素"呢?